用糟糕的方法交易,就像在暴風中的小船上練雜耍——可以做到,但站在堅實的地面上絕對容易得多。
本章要回答的核心問題#
讀完前一章,你大概會問:
- 我實際上能做到什麼程度?
- 怎麼避開第 13 章列出的陷阱?
- 怎麼樣才算「正確的回測」?
在最好的情況下,回測也只能給你對未來模糊的概念。但即使是模糊概念,對好的交易者也已經足夠賺到很多錢。本章要讓那個「模糊」更精準一點。
統計取樣:回測的數學基礎#
回測的預測力,根植於從樣本推論母體這個統計領域。
兩個關鍵因素#
- 樣本量(sample size)
- 樣本是否具代表性(representative)
多數系統測試者只把「樣本量」理解為「總交易次數」。他們忽略了:
- 即使一個測試包含上千筆交易,只要某條規則只在少數幾筆中發揮作用,那些規則的統計效力就極低
- 樣本是否代表母體更難量化、需要主觀判斷,因此被多數人忽視
「在民主黨大會上民調」的比喻#
民調公司知道:
- 隨機抽樣 500 人,可以推論全美選民意向,誤差只有 2%
- 在民主黨大會上抽 500 人,結果與真實母體完全脫節——這稱為「樣本不代表母體」
多數交易者犯的就是同樣的錯:
- 只用最近一段時間的資料做回測 / 紙上交易
- 等於只在「民主黨大會上民調」
- 那段期間市場可能只處於「穩定且波動」狀態,反趨勢策略大放異彩
- 一旦市場狀態改變,這些方法可能瞬間失效,甚至大虧
既有指標都不夠「穩健」#
回測時用的 MAR ratio、CAGR%、Sharpe ratio 都不穩健(not robust):
- 它們對測試的起訖日期太敏感
- 對少於 10 年的測試特別嚴重
- 一些參數變動 1% 就足以讓績效大幅改變
統計上的「穩健」(robust):改動資料中很小一部分,統計量不會出現顯著變化。
Bill 在面試作者時問過:「你知道什麼是 robust statistical estimator 嗎?」當時作者答不出來——但這個問題已經顯示 Rich 與 Bill 在 1983 年就遠遠超前同業,深諳「資訊永遠不完美」這件事。
起訖日期的敏感度示例#
把測試從 1996/1/1–2006/6/30 微幅調整為 1996/2/1–2006/4/30:
| 系統 | 原始 | 微調 |
|---|---|---|
| Triple Moving Average | 43.2% / MAR 1.39 / Sharpe 1.25 | 46.2% / 1.61 / 1.37 |
| ATR Channel Breakout | 51.7% / MAR 1.31 / Sharpe 1.39 | 54.9% / 1.49 / 1.47 |
只是把幾個月切掉,所有指標都跳動明顯。原因在於:
- CAGR% 是「測試起點到終點」的對數圖斜率
- 起訖日期變動會直接影響斜率
- MAR 又把兩個敏感量(CAGR、最大回檔)相除——敏感度被相乘
圖示:CAGR% 的不穩定(Figure 12-1)#
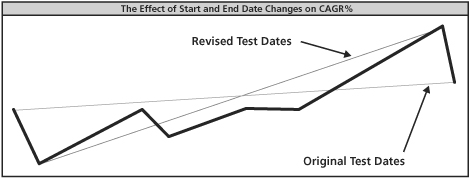
Figure 12-1: The Effect of Changes in the Start and End Dates on CAGR%
把測試起點 1996/1 與終點 2006/5–6 兩段「壞月份」切掉後:
- 線的斜率明顯抬升
- 同樣的系統、同樣的策略,卻像變了一套
穩健替代方案:作者提出的新指標#
RAR%(Regressed Annual Return)#
CAGR% 只看頭尾兩點;RAR% 改用整條權益曲線的線性回歸(linear regression):
- 通俗說法是「最佳擬合線」(best fit line)
- 想像把曲線拉直、保留整體方向
- 取這條直線的斜率作為年化報酬
對起訖日期的敏感度#
- CAGR% 改變了 3.0 個百分點(43.2 → 46.2)
- RAR% 只改變 0.11(54.67 → 54.78)
- CAGR% 的敏感度大約是 RAR% 的 30 倍
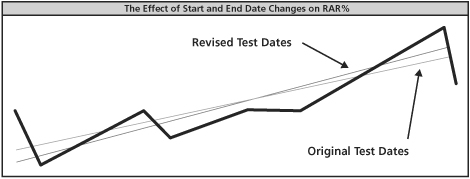
Figure 12-2: The Effect of Changes in the Start and End Dates on RAR%
R-Cubed:Robust Risk/Reward Ratio#
最大回檔只是「曲線上一個點」,太局限。考慮:
- 五次大回檔分別為 32%、34%、35%、35%、36% 的系統
- vs. 五次大回檔分別為 20%、25%、26%、29%、36% 的系統
- 兩者最大回檔相同,但難度天差地別
此外,**回檔的「持續時間」**也很重要:
- 兩個月就創新高 vs. 兩年才創新高
- 同樣 30% 對心理的衝擊完全不同
R-cubed 的計算#
- 分子:RAR%
- 分母:長度加權的平均最大回檔
- 平均最大回檔 = 取最大 5 次回檔的平均
- 平均最大回檔長度 = 取最長 5 次回檔的天數平均
- 長度調整 = 平均最大回檔長度 ÷ 365 × 平均最大回檔
範例:RAR% 50%、平均最大回檔 25%、平均最大回檔長度 365 天 → R-cubed = 50% ÷ (25% × 365/365) = 2.0
Robust Sharpe Ratio#
= RAR% ÷ 月報酬的年化標準差。同理可大幅降低敏感度。
結果(Tables 12-1、12-2、12-3)#
- 原始指標 vs. 穩健指標:穩健指標對改動的反應遠小於非穩健指標
- 加上 2006/7–11 那段差勁時期:
- RAR% 的變動只有 CAGR% 的 1/6 以下
- R-cubed 的變動約為 MAR 的一半
穩健指標的另兩個重要特性:
- 較不易被「運氣」操弄:例如剛好錯過某次最大回檔的人,MAR 會異常亮眼,但 R-cubed 不會
- 較不易因「曲線擬合」而暴升:第 13 章那條人為加上的「縮倉規則」讓 CAGR%、MAR 大幅變好,但 RAR% 只升 0.4%、R-cubed 只升 17.3%
樣本是否具代表性:兩個關鍵維度#
要讓回測樣本有機會代表未來:
- 市場數量:跨越足夠多市場,自然包含波動度與趨勢度的多樣狀態
- 測試期間長度:拉得夠長,才能涵蓋更多市場狀態
作者建議:用你能拿到的所有資料來測試。買資料的成本,遠低於「沒測夠長就出事」的虧損成本。
年輕交易者特別容易犯這個錯——他們以為自己看過的就是「市場常態」。網路泡沫時人人都是當沖天才;崩盤一來,多數人才意識到他們原本依賴的環境已不存在。
樣本量的實務指引#
- 沒有魔法數字,「越大越好、越小越糟」
- 少於 20 筆 → 大誤差
- 多於 100 筆 → 預測力較佳
- 數百筆 → 多數情況下足夠
- 真正麻煩的不是「總筆數」,而是「那條規則只觸發過幾次?」
兩個常見的「縮減有效樣本」做法,會讓樣本量不足的問題雪上加霜:
- 單市場最佳化(single-market optimization):對每個市場單獨最佳化,自然樣本量大減
- 過度複雜的系統(complex systems):規則太多時很難判斷某條規則到底貢獻多少
因此作者不推薦單市場最佳化,並偏好「統計意義較強」的簡單想法。
「我實際能做到什麼?」的答案#
真正的答案是:你不知道,也無法精準預測。
你能做的,是用工具去理解:
- 真實表現可能落在什麼範圍
- 哪些因子會推動或縮減這個範圍
- 市場漂移(drift)會放大這個不確定性——即使是經驗豐富者打造的系統,績效也會起伏
注意「幸運的系統」#
最近表現特別好的系統,可能:
- 純粹是運氣
- 或剛好遇上對它有利的市場狀態
之後常常會跟著一段「相對辛苦」的期間。不要期待延續這份運氣。
參數擾動測試(Parameter Scrambling)#
開始實盤前,作者強烈建議做的測試:
- 把幾個系統參數強制偏離最佳值 20–25%
- 選擇明顯位於最佳化曲線下坡處的點
- 看看績效會變多差
Bollinger Breakout 範例:
- 最佳值:350 天 / 出場閾值 −0.8
- 偏移後:250 天 / 出場閾值 0.0
- RAR%:59% → 58%(小變化)
- R-cubed:3.67 → 2.18(戲劇性下降)
這個落差,正是你從回測搬到實盤時要有心理準備的現實。
滾動最佳化窗口(Rolling Optimization Windows)#
更貼近「實盤」的測試方法:
- 假裝你只擁有 8–10 年前以前的資料
- 用平常的最佳化方法、做出當時應有的判斷
- 找出那當下「最佳的參數」
- 然後用這些參數對「之後的兩年」實際資料做模擬
- 把這個流程往後推進、重複
範例:對 Bollinger Breakout 系統做 5 段不同的 10 年滾動測試(Table 12-4):
- 每一段的「最佳參數」都不一樣
- 「最佳化結果」與「之後一年的實際 RAR%」常常相去甚遠
滾動最佳化窗口示範了:回測本身有結構性誤差,而從測試走進實盤的變動,往往比你想像得更大。
蒙地卡羅模擬(Monte Carlo Simulation)#
蒙地卡羅模擬是用「隨機數」研究現象的一類方法:
- 命名來自摩納哥賭城蒙地卡羅,因賭場的隨機特性著名
- 曼哈頓計畫時代就被用來估計鈾原子核分裂特性
- 費曼(Richard Feynman)發現:他無法預測整個過程,但可以用「隨機數模擬中子的多種可能」累積出鈾的整體裂變特徵
市場比核分裂更複雜,但相同概念可用:透過隨機操作模擬出大量「可能的另類交易宇宙」。
兩種常見做法#
- 交易擾動(trade scrambling):把實際模擬出的交易隨機重新排序、改變起始日,重組權益
- 權益曲線擾動(equity curve scrambling):取原始權益曲線的隨機片段重新拼出新的曲線
兩種方法的優劣#
交易擾動會嚴重低估回檔的嚴重性:
- 大趨勢結束時,市場相關性遠高於平日
- 期貨與股票都一樣
- 交易擾動把這個共振關係打散,使回檔分散到不同時點
- 例如 2006 春黃金、白銀、糖三市同時回落 20 天,被打散後回檔變得遠為和緩
- 1987 年的歐元美元跳空時,許多平日不相關的市場同步反向也是同樣道理
權益曲線擾動的進一步細節#
- 多數軟體只用「單日淨變化」打散
- 但大趨勢尾段的壞日子常連續發生(serial correlation)
- 如果只用「單日」隨機,會切散這些連續性
- Trading Blox 的做法:以「多日區塊」(作者使用 20 天)為單位來擾動,保留自相關性
Monte Carlo 報告(Figure 12-3)#
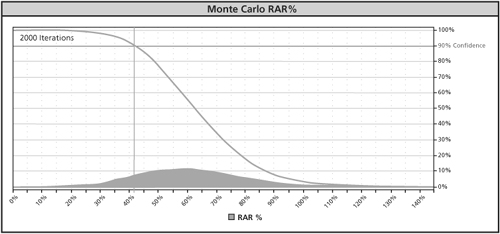
Figure 12-3: Monte Carlo Distribution of RAR%
模擬 2,000 條替代權益曲線、計算每條的 RAR%、再畫出分布:
- 「90% 的曲線 RAR% 都超過 42%」這種敘述,比單一數字更貼近真實風險
- 但不要過度解讀:分布建立在歷史回測之上,回測本身的所有問題(最佳化、過擬合等)都會被繼承
- 垃圾進、垃圾出:Monte Carlo 不會把爛測試變好
結語:粗糙是常態#
回測終究只是「對未來的粗糙近似」。
- 穩健指標好過敏感指標,但仍非精準
- 任何告訴你「能達到某個確切績效」的人,不是在說謊就是不懂自己在說什麼
- 如果他正在賣你東西,前者的可能性更高
下一章會討論:如何讓你的交易更「穩健」(robust)——也就是讓績效不容易劇烈擺盪。