既然我們從高層次理解了交易所的運作,讓我們研究現代交易所如何演進成今日的樣貌。一個現代交易所看起來如何?答案可能會讓很多讀者驚訝。
一些大型交易所幾乎所有東西都跑在一台巨型伺服器上。雖然這聽起來很極端,但我們可以從中學到許多寶貴的教訓。
讓我們深入。
Performance#
如非功能性需求中所討論的,延遲對交易所非常重要。不只平均延遲要低,整體延遲也必須穩定。一個好的穩定性衡量是 99 百分位數延遲。
延遲可以分解為其組成部分,如下式所示:
Latency = ∑executionTimeAlongCriticalPath有兩種方式可以減少延遲:
- 減少關鍵路徑上的任務數量。
- 縮短每個任務所花的時間:
- 透過減少或消除網路與磁碟使用
- 透過減少每個任務的執行時間
讓我們檢視第一點。如高層次設計所示,交易關鍵路徑包含以下:
gateway -> order manager -> sequencer -> matching engine關鍵路徑上只包含必要的元件,連 logging 都從關鍵路徑中移除以達成低延遲。
現在我們看第二點。在高層次設計中,關鍵路徑上的元件跑在以網路連線的個別伺服器上。網路往返延遲約 500 微秒。當有多個元件都在關鍵路徑上透過網路通訊時,網路延遲總和會累加到單位數毫秒。此外,排序器是個事件儲存,會把事件持久化到磁碟。即使假設一個利用循序寫入效能優勢的高效設計,磁碟存取的延遲仍以數十毫秒計算。要進一步了解網路與磁碟存取延遲,請參考「Latency Numbers Every Programmer Should Know」[16]。
把網路與磁碟存取延遲都算進來,端對端延遲總和為數十毫秒。雖然這個數字在交易所早期是值得尊敬的,但隨著交易所為超低延遲而競爭,它已不再足夠。
為了領先競爭對手,交易所隨時間演進他們的設計,把關鍵路徑上的端對端延遲降低到數十微秒,主要是透過探索減少或消除網路與磁碟存取延遲的選項。一個經過時間考驗的設計是把所有東西放到同一台伺服器上以消除網路跳躍。當所有元件都在同一台伺服器上時,它們可以透過 mmap [17] 作為事件儲存來通訊(稍後會詳述)。
圖 15 顯示一個所有元件都在單一伺服器上的低延遲設計:

有一些值得仔細看的有趣設計決策。
讓我們先聚焦於上圖中的應用迴圈(application loops)。應用迴圈是個有趣的概念。它在 while 迴圈中不斷輪詢任務以執行,是主要的任務執行機制。為了符合嚴格的延遲預算,只有最關鍵的任務才應該由應用迴圈處理。
它的目標是減少每個元件的執行時間,並保證高度可預測的執行時間(亦即低 99 百分位數延遲)。圖中每個方塊代表一個元件。一個元件是伺服器上的一個 process。為了最大化 CPU 效率,每個應用迴圈(把它想成主處理迴圈)是單執行緒的,且該執行緒被釘到固定的 CPU 核心上。以訂單管理員為例,看起來像下圖(圖 16)。

在這個圖中,訂單管理員的應用迴圈被釘在 CPU 1。把應用迴圈釘到 CPU 的好處很大:
- 沒有 context switch [18]。CPU 1 完全分配給訂單管理員的應用迴圈。
- 沒有鎖,因此沒有鎖競爭,因為只有一個執行緒更新狀態。
兩者都有助於低 99 百分位數延遲。
CPU pinning 的取捨是讓寫程式變得更複雜。工程師需要仔細分析每個任務所需的時間,以避免它佔用應用迴圈執行緒過久,這可能會阻塞後續任務。
接下來,讓我們把注意力放到圖 15 中央標示為「mmap」的長矩形。「mmap」指的是符合 POSIX 標準的 UNIX 系統呼叫 mmap(2),它把檔案映射到 process 的記憶體中。
mmap(2) 提供了一種在 process 之間高效分享記憶體的機制。當後備檔案位於 /dev/shm 中時,效能優勢加倍。/dev/shm 是一個記憶體支援的檔案系統。當 mmap(2) 在 /dev/shm 中的檔案上完成時,對共享記憶體的存取完全不會導致任何磁碟存取。
現代交易所利用這點,盡可能消除關鍵路徑上的磁碟存取。mmap(2) 在伺服器中用於實作訊息匯流排(message bus),讓關鍵路徑上的元件透過它通訊。這個通訊路徑沒有網路或磁碟存取,在這個 mmap 訊息匯流排上送一則訊息花不到一微秒。透過利用 mmap 來建構事件儲存,搭配我們接下來要討論的事件溯源設計範式,現代交易所可以在伺服器內建構低延遲微服務。
Event sourcing#
我們在「Digital Wallet」一章討論過事件溯源。請參考該章對事件溯源的深入回顧。
事件溯源的概念並不難理解。在傳統應用中,狀態被持久化在資料庫中。當出問題時,很難追溯問題的源頭。資料庫只保留目前狀態,沒有導致目前狀態的事件紀錄。
在事件溯源中,它不儲存目前狀態,而是保留所有狀態變更事件的不可變 log。這些事件是真理的黃金來源。詳見圖 17 的比較。

- 左邊是經典的資料庫綱要。它追蹤訂單的訂單狀態,但不包含訂單如何到達目前狀態的任何資訊。
- 右邊是事件溯源的對應版本。它追蹤所有改變訂單狀態的事件,並可以透過依序重播所有事件來恢復訂單狀態。
圖 18 顯示一個使用 mmap 事件儲存作為訊息匯流排的事件溯源設計。這看起來很像 Kafka 中的 Pub-Sub 模型。事實上,如果沒有嚴格的延遲要求,可以使用 Kafka。

在圖中,外部領域使用我們在 Business Knowledge 101 一節介紹的 FIX 與交易領域通訊。
- 閘道將 FIX 轉換為「FIX over Simple Binary Encoding」(SBE)以快速且緊湊地編碼,並以預先定義的格式(見圖中的 event store entry)透過 Event Store Client 把每筆訂單作為
NewOrderEvent送出。 - 訂單管理員(內嵌於撮合引擎中)從事件儲存接收
NewOrderEvent,驗證它,並把它加到內部的訂單狀態。然後訂單被送到撮合核心。 - 如果訂單被撮合,會產生
OrderFilledEvent並送到事件儲存。 - 其他元件(例如市場資料處理器與回報器)訂閱事件儲存並相應地處理這些事件。
這個設計緊密遵循高層次設計,但有些調整以使其在事件溯源範式下更有效率。
第一個差別是訂單管理員。訂單管理員變成可重用的函式庫,被嵌入不同的元件中。這對這個設計是合理的,因為訂單的狀態對多個元件都很重要。讓其他元件透過集中式的訂單管理員去更新或查詢訂單狀態會傷害延遲,特別是如果這些元件不在交易關鍵路徑上(例如圖中的回報器)。雖然每個元件自己維護訂單狀態,但有了事件溯源,狀態保證是相同且可重播的。
另一個關鍵差別是排序器在哪?發生了什麼事?
在事件溯源設計中,所有訊息都有單一的事件儲存。注意 event store entry 包含一個「sequence」欄位,這個欄位由排序器注入。
每個事件儲存只有一個排序器。有多個排序器是壞做法,因為它們會爭奪寫入事件儲存的權利。在交易所這類繁忙的系統中,大量時間會浪費在鎖競爭上。
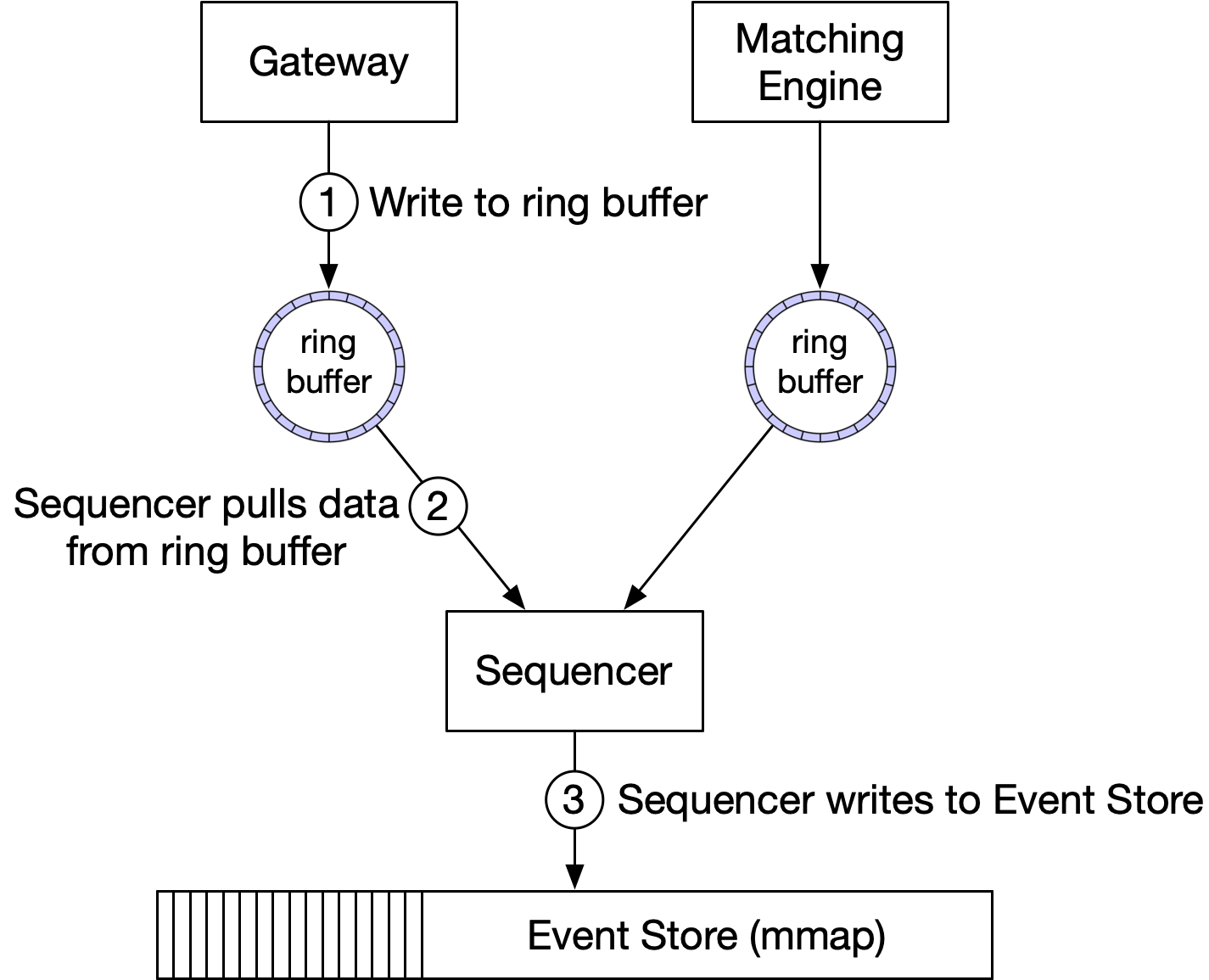
因此,排序器是單一寫入者,在把事件送到事件儲存之前對其排序。與高層次設計中也作為訊息儲存的排序器不同,這裡的排序器只做一件簡單的事,速度超快。圖 19 顯示在 mmap 環境中排序器的設計。
排序器從每個元件本地的環形緩衝區拉取事件。對每個事件,它在事件上蓋一個 sequence ID 並送到事件儲存。我們可以為高可用設置備用排序器,以防主排序器當機。
High availability#
對於高可用,我們的設計目標是 4 個 9(99.99%)。這意味著交易所每天只能有 8.64 秒的當機時間。如果服務當機,它要求幾乎立即的恢復。
要達成高可用,考量以下:
- 首先,識別交易所架構中的單點故障。例如,撮合引擎的故障對交易所可能是一場災難。因此,我們在主要實例旁設置冗餘實例。
- 其次,故障的偵測與切換到備用實例的決策應該要快。
對於無狀態服務(例如客戶端閘道),可以透過增加伺服器來輕易水平擴展。對於有狀態元件(例如訂單管理員與撮合引擎),我們需要能在複本之間複製狀態資料。
圖 20 顯示如何複製資料的範例。熱(hot)撮合引擎作為主要實例運作,而暖(warm)引擎接收並處理完全相同的事件,但不會把任何事件送到事件儲存。當主要實例當機時,暖實例可以立即接手作為主要並送出事件。當暖備用實例當機時,重啟後它總是可以從事件儲存恢復所有狀態。
事件溯源非常適合交易所架構。其內在的確定性讓狀態恢復容易且準確。

我們需要設計一個機制來偵測主要實例中的潛在問題。除了正常的硬體與 process 監控,我們還可以從撮合引擎發送心跳(heartbeat)。如果心跳沒有及時收到,撮合引擎可能正在出問題。
這個 hot-warm 設計的問題是它只在單一伺服器的範圍內運作。要達成高可用,我們必須把這個概念擴展到多台機器,甚至跨資料中心。在這個設定中,整台伺服器要嘛是熱的要嘛是暖的,整個事件儲存都從熱伺服器複製到所有暖複本。在機器之間複製整個事件儲存需要時間。我們可以使用可靠 UDP(reliable UDP)[19] 高效地把事件訊息廣播到所有暖伺服器。請參考 Aeron [20] 的設計作為範例。
下一節中,我們討論對 hot-warm 設計的改善以達成高可用。
Fault tolerance#
上述 hot-warm 設計相對簡單,運作得相當好,但如果暖實例也當機呢?這是低機率但災難性的事件,所以我們應該為它做準備。
這是大型科技公司面對的問題。他們透過把核心資料複製到多個城市的資料中心來解決。它減輕了地震或大規模停電等自然災害的風險。要讓系統具備容錯,我們必須回答許多問題:
- 如果主要實例當機,我們如何以及何時決定切換到備用實例?
- 我們如何在備用實例中選出 leader?
- 所需的恢復時間(RTO - Recovery Time Objective)是多少?
- 哪些功能需要被恢復(RPO - Recovery Point Objective)?我們的系統可以在降級條件下運作嗎?
讓我們逐一回答這些問題。
首先,我們必須了解「down」真正的意思。這沒有看起來那麼直接。考量以下情境:
- 系統可能發出誤報,造成不必要的切換。
- 程式碼中的 bug 可能讓主要實例當機。同樣的 bug 可能在切換後又讓備用實例當機。當所有備用實例都被 bug 擊倒時,系統就不再可用。
這些是難解的問題。當我們首次發布一個新系統時,可能需要手動執行切換。只有當我們收集到足夠的訊號與運維經驗、並對系統有更多信心後,才將故障偵測流程自動化。混沌工程(Chaos engineering)[21] 是一種好的實踐,可以讓邊界案例浮出來,並更快獲得運維經驗。
一旦正確地做出切換的決策,我們如何決定哪個伺服器接手?幸運的是,這是個被理解得很清楚的問題。有許多經過實戰驗證的 leader-election 演算法。我們以 Raft [22] 為例。
圖 21 顯示一個有 5 台伺服器、各自有事件儲存的 Raft 叢集。當前的 leader 把資料送到所有其他實例(followers)。Raft 中執行操作所需的最小投票數是 (N/2 + 1),其中 N 是叢集中的成員數。在這個例子中最小值是 3。
下圖(圖 21)顯示 followers 透過 RPC 從 leader 接收新事件。事件被儲存到 follower 自己的 mmap 事件儲存中。

讓我們簡單檢視 leader 選舉流程:
- Leader 對其 followers 發送心跳訊息(如圖 21 所示,沒有內容的
AppendEntries)。 - 如果一個 follower 在一段時間內沒有收到心跳訊息,它會觸發一個選舉逾時,啟動新的選舉。
- 第一個達到選舉逾時的 follower 變成 candidate,並要求其餘的 followers 投票(
RequestVote)。 - 如果第一個 follower 收到多數票,它就成為新的 leader。
- 如果第一個 follower 的
term值比新節點低,它就不能成為 leader。 - 如果多個 followers 同時變成 candidates,這稱為「split vote」。在這種情況下,選舉逾時,並啟動新的選舉。
圖 22 解釋了「term」。在 Raft 中,時間被分成任意區間以代表正常運作與選舉。
![圖 22 Raft terms(來源:[23])](figure-22-raft-terms-PGF2N5J6.svg)
接下來,讓我們看恢復時間。恢復時間目標(Recovery Time Objective, RTO)指應用可以當機而不會對業務造成重大損害的時間量。對於股票交易所,我們需要達到秒級的 RTO,這絕對需要服務的自動切換。為此,我們根據優先順序對服務分類,並定義降級策略以維持最低服務水準。
最後,我們需要弄清楚對資料遺失的容忍度。恢復點目標(Recovery Point Objective, RPO)指可以遺失而不對業務造成重大損害的資料量,亦即遺失容忍度。實務上,這意味著頻繁地備份資料。
對於股票交易所,資料遺失是不可接受的,所以 RPO 接近零。有了 Raft,我們有許多份資料副本,它保證叢集節點之間達成狀態共識。如果當前的 leader 當機,新的 leader 應該能立即開始運作。
Matching algorithms#
讓我們稍微繞個路深入撮合演算法。下面的虛擬碼從高層次解釋撮合是如何運作的。
Context handleOrder(OrderBook orderBook, OrderEvent orderEvent) {
if (orderEvent.getSequenceId() != nextSequence) {
return Error(OUT_OF_ORDER, nextSequence);
}
if (!validateOrder(symbol, price, quantity)) {
return ERROR(INVALID_ORDER, orderEvent);
}
Order order = createOrderFromEvent(orderEvent);
switch (msgType):
case NEW:
return handleNew(orderBook, order);
case CANCEL:
return handleCancel(orderBook, order);
default:
return ERROR(INVALID_MSG_TYPE, msgType);
}
Context handleNew(OrderBook orderBook, Order order) {
if (BUY.equals(order.side)) {
return match(orderBook.sellBook, order);
} else {
return match(orderBook.buyBook, order);
}
}
Context handleCancel(OrderBook orderBook, Order order) {
if (!orderBook.orderMap.contains(order.orderId)) {
return ERROR(CANNOT_CANCEL_ALREADY_MATCHED, order);
}
removeOrder(order);
setOrderStatus(order, CANCELED);
return SUCCESS(CANCEL_SUCCESS, order);
}
Context match(OrderBook book, Order order) {
Quantity leavesQuantity = order.quantity - order.matchedQuantity;
Iterator<Order> limitIter = book.limitMap.get(order.price).orders;
while (limitIter.hasNext() && leavesQuantity > 0) {
Quantity matched = min(limitIter.next.quantity, order.quantity);
order.matchedQuantity += matched;
leavesQuantity = order.quantity - order.matchedQuantity;
remove(limitIter.next);
generateMatchedFill();
}
return SUCCESS(MATCH_SUCCESS, order);
}這個虛擬碼使用 FIFO(First In First Out)撮合演算法。在某個價格層級先進入的訂單先被撮合,最後進入的最後被撮合。
撮合演算法有許多種,這些演算法常用於期貨交易。例如,FIFO with LMM(Lead Market Maker)演算法根據預先定義的比例分配一定數量給 LMM,比 FIFO 佇列更優先,這是 LMM 公司與交易所協商的特權。更多撮合演算法可參考 CME 網站 [24]。撮合演算法在許多其他場景中也有使用,一個典型的是暗池(dark pool)[25]。
Determinism#
確定性有功能確定性與延遲確定性兩種。我們在前面幾節已涵蓋功能確定性。我們做出的設計選擇(例如排序器與事件溯源)保證如果事件以相同順序被重播,結果會相同。
有了功能確定性,事件實際發生的時間在大多數情況下並不重要,重要的是事件的順序。在圖 23 中,事件時間戳從時間維度上離散不均勻的點被轉換為連續的點,重播/恢復所花的時間可以大幅減少。

延遲確定性指系統中每筆交易的延遲幾乎相同。這對業務至關重要。有一個數學方式來衡量它:99 百分位數延遲,或更嚴格地,99.99 百分位數延遲。我們可以利用 HdrHistogram [26] 計算延遲。如果 99 百分位數延遲很低,交易所幾乎所有交易都能提供穩定的效能。
調查大幅延遲波動的原因很重要。例如,在 Java 中,safe points 經常是原因。HotSpot JVM [27] 的 Stop-the-World 垃圾回收是個眾所周知的例子。
至此結束我們對交易關鍵路徑的深入探討。本章其餘部分,我們仔細看看交易所其他部分一些更有趣的面向。
Market data publisher optimizations#
從撮合演算法可以看到,L3 訂單簿資料給我們更好的市場檢視。我們可以從 Google Finance 取得免費的一日 K 線資料,但取得更詳細的 L2/L3 訂單簿資料是昂貴的。許多對沖基金透過交易所即時 API 自己記錄資料,以建構自己的 K 線圖與其他用於技術分析的圖表。
市場資料發布者(MDP)從撮合引擎接收撮合結果,並基於此重建訂單簿與 K 線圖。然後它把資料發布給訂閱者。
訂單簿的重建類似於上面撮合演算法一節提到的虛擬碼。MDP 是一個有許多層級的服務。例如,零售客戶預設只能檢視 5 個 L2 層級,需要付費才能取得 10 個層級。MDP 的記憶體不能無限擴張,所以我們需要對 K 線設定上限。請參考 Data Models 一節對 K 線圖的回顧。MDP 的設計如圖 24。
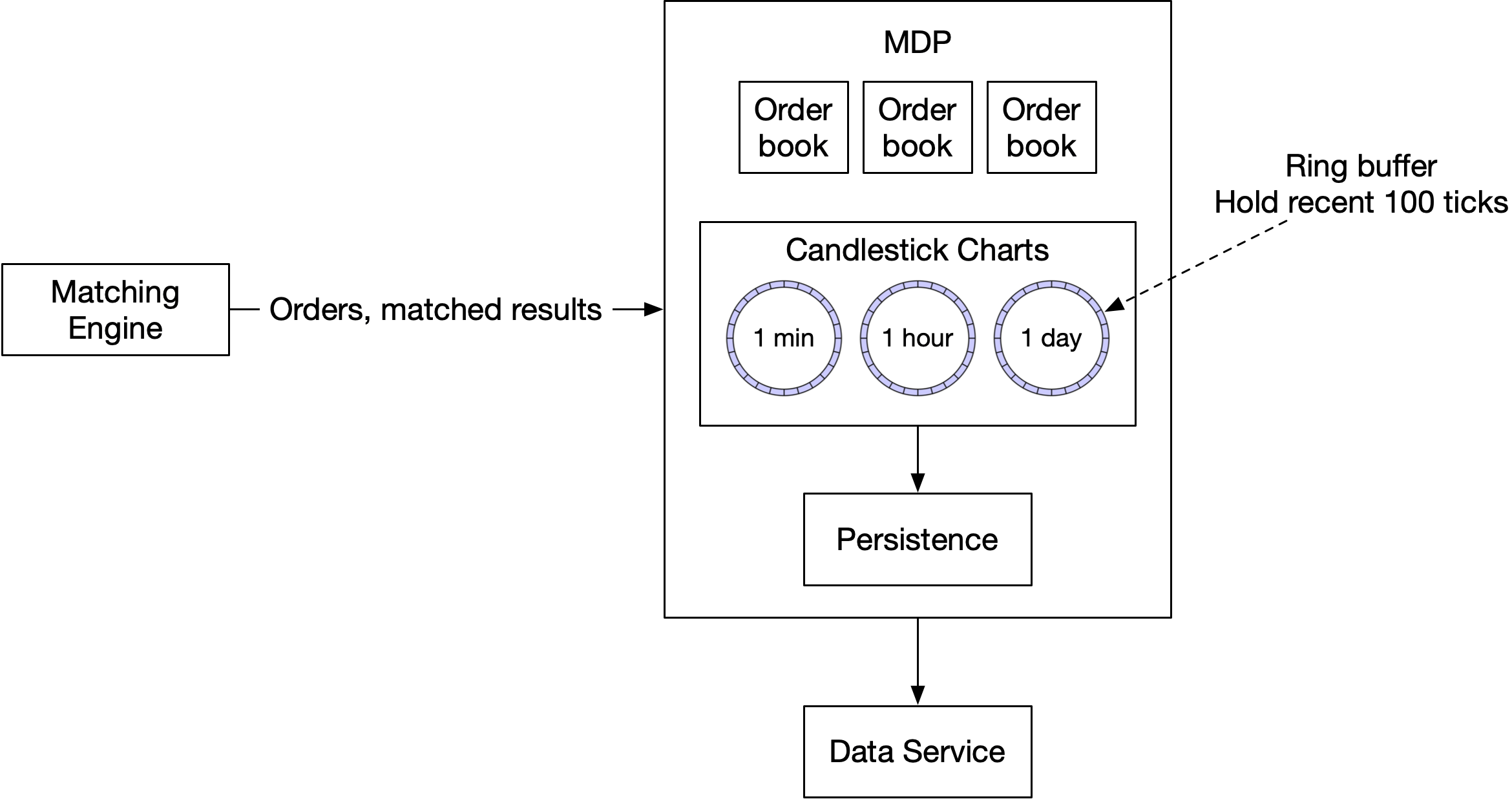
這個設計利用環形緩衝區。環形緩衝區(ring buffer),也稱為循環緩衝區(circular buffer),是一個固定大小、頭尾相連的佇列。生產者持續產生資料,一個或多個消費者從中拉取資料。環形緩衝區中的空間是預先配置的,沒有物件創建或釋放的必要。這個資料結構也是無鎖的(lock-free)。
還有其他技術可以讓這個資料結構更有效率。例如,padding 確保環形緩衝區的序列號永遠不會與其他東西在同一個 cache line 中。詳見 [28]。
Distribution fairness of market data#
在股票交易中,比別人有較低的延遲就像有個能看到未來的神諭。對於受監管的交易所,必須保證所有市場資料的接收者同時收到資料,這非常重要。
為什麼這很重要?例如,MDP 持有一份資料訂閱者名單,訂閱者的順序由他們連線到發布者的順序決定,第一個總是先收到資料。猜猜會發生什麼?聰明的客戶會在開盤時爭著排在名單第一位。
有一些方式可以緩解這個問題:
- 使用可靠 UDP 的多播(multicast)是個好方案,可以同時向許多參與者廣播更新。
- MDP 也可以在訂閱者連線時指派隨機順序。
我們仔細看看多播。
Multicast#
資料可以透過三種不同類型的協定在網際網路上傳輸。讓我們快速看看:
- Unicast:從一個來源到一個目的地。
- Broadcast:從一個來源到整個子網路。
- Multicast:從一個來源到一組可能位於不同子網路上的主機。
多播是交易所設計中常用的協定。透過將多個接收者設定在同一個多播群組中,理論上他們會同時收到資料。
然而,UDP 是不可靠的協定,資料包可能無法到達所有接收者。有處理重傳的解法 [29]。
Colocation#
談到公平性,事實上很多交易所提供 colocation 服務,把對沖基金或券商的伺服器放在與交易所相同的資料中心。下單到撮合引擎的延遲基本上與電纜長度成正比。Colocation 並不破壞公平性的概念,可以視為付費的 VIP 服務。
Network security#
交易所通常提供一些公開介面,DDoS 攻擊是個真實的挑戰。以下是對抗 DDoS 的幾種技術:
- 把公開服務與資料和私有服務隔離,這樣 DDoS 攻擊就不會影響最重要的客戶。在提供相同資料的情況下,我們可以有多個唯讀副本以隔離問題。
- 使用快取層儲存不常更新的資料。有了好的快取,多數查詢不會打到資料庫。
- 加固 URL 以對抗 DDoS 攻擊。例如,對於像
https://my.website.com/data?from=123&to=456這樣的 URL,攻擊者可以輕易地透過改變 query string 產生許多不同的請求。相對地,像https://my.website.com/data/recent這樣的 URL 較好,它也可以在 CDN 層被快取。 - 需要有效的 safelist/blocklist 機制。許多網路閘道產品提供這類功能。
- 速率限制經常被用於防禦 DDoS 攻擊。