在我們深入高層次設計之前,先簡單討論一些對設計交易所有幫助的基本概念與術語。
Business Knowledge 101#
Broker
大多數零售客戶透過券商(broker)與交易所交易。一些你可能熟悉的券商包括 Charles Schwab、Robinhood、Etrade、Fidelity 等。這些券商為零售使用者提供友善的使用者介面以下單與檢視市場資料。
Institutional client
機構客戶(institutional client)使用專門的交易軟體進行大量交易。不同的機構客戶有不同的需求:
- 退休基金追求穩定收入,他們交易頻率不高,但一旦交易,量都很大。他們需要訂單拆分(order splitting)等功能來最小化大額訂單的市場衝擊(market impact)[7]。
- 一些對沖基金專精於做市(market making),透過手續費回扣賺取收入。他們需要低延遲交易能力,所以顯然不能像零售客戶那樣只在網頁或行動 App 上檢視市場資料。
Limit order
限價單(limit order)是一種帶有固定價格的買單或賣單。它可能無法立即找到撮合,或可能只被部分撮合。
Market order
市價單(market order)不指定價格。它會立即以當下市場價格成交。市價單犧牲成本以保證成交。在某些快速變動的市場條件下很有用。
Market data levels
美國股市的價格報價有三個層級:L1(level 1)、L2、L3。
L1 市場資料包含最佳買價(bid)、賣價(ask)與數量(圖 2)。Bid price 指買家願意為一檔股票支付的最高價格。Ask price 指賣家願意賣出該股票的最低價格。

L2 包含比 L1 更多的價格層級(圖 3)。

L3 顯示價格層級以及每個價格層級上排隊的數量(圖 4)。

Candlestick chart
K 線圖(candlestick chart)代表某段期間的股票價格。一個典型的 K 線看起來是這樣(圖 5)。K 線顯示某個時間區間市場的開盤、收盤、最高與最低價。常見的時間區間有一分鐘、五分鐘、一小時、一天、一週與一個月。

FIX
FIX 協定(Financial Information eXchange protocol)[8] 創建於 1991 年。它是一個與廠商無關的通訊協定,用於交換證券交易資訊。下面是以 FIX 編碼的一筆證券交易範例。
8=FIX.4.2 | 9=176 | 35=8 | 49=PHLX | 56=PERS | 52=20071123-05:30:00.000 | 11=ATOMNOCCC9990900 | 20=3 | 150=E | 39=E | 55=MSFT | 167=CS | 54=1 | 38=15 | 40=2 | 44=15 | 58=PHLX EQUITY TESTING | 59=0 | 47=C | 32=0 | 31=0 | 151=15 | 14=0 | 6=0 | 10=128 |範例 FIX [8]
High-level design#
既然我們對關鍵概念有了基本的理解,讓我們看看高層次設計,如圖 6 所示。
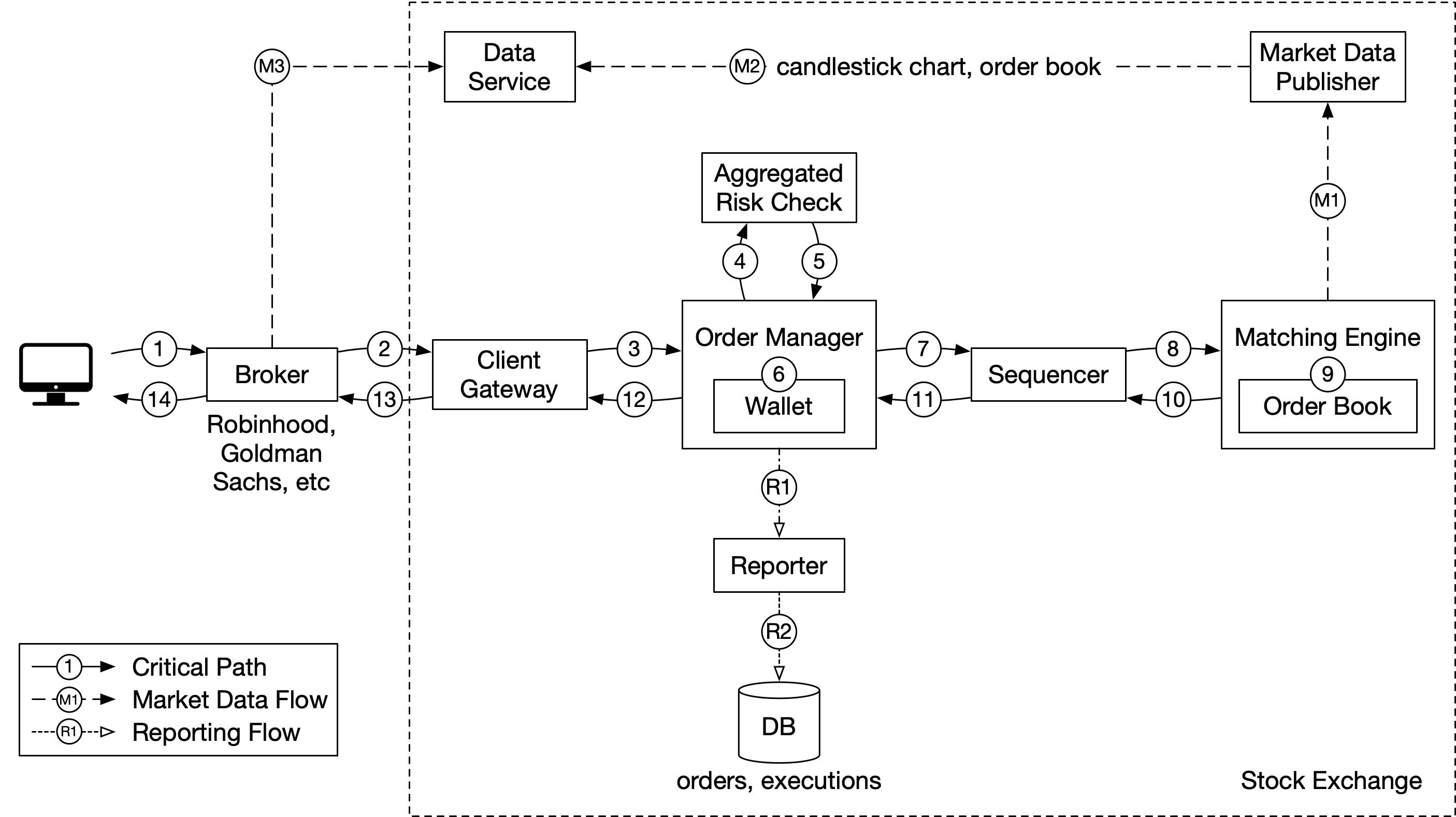
讓我們追蹤一筆訂單在圖中各元件間的生命週期,看看各部分如何組合在一起。
首先,我們追蹤訂單通過交易流(trading flow)。這是有嚴格延遲要求的關鍵路徑(critical path)。流程中的每一步都必須快速:
- 步驟 1:客戶透過券商的 web 或行動 App 下訂單。
- 步驟 2:券商把訂單送到交易所。
- 步驟 3:訂單透過客戶端閘道(client gateway)進入交易所。客戶端閘道執行基本的把關功能,例如輸入驗證、速率限制、認證、正規化等。然後客戶端閘道把訂單轉發給訂單管理員(order manager)。
- 步驟 4 - 5:訂單管理員根據風險管理員(risk manager)設定的規則執行風險檢查。
- 步驟 6:通過風險檢查後,訂單管理員驗證錢包中是否有足夠的資金支付訂單。
- 步驟 7 - 9:訂單被送到撮合引擎(matching engine)。當找到撮合時,撮合引擎發出兩筆執行(execution,也稱 fill),分別對應買方與賣方。為了保證撮合結果在重播時是確定性的,訂單與執行都會在排序器(sequencer)中被排序(稍後會詳述排序器)。
- 步驟 10 - 14:執行回傳給客戶。
接下來,我們追蹤市場資料流(market data flow),追蹤訂單執行從撮合引擎透過資料服務(data service)到券商的過程。
- 步驟 M1:撮合引擎在撮合進行時產生一串執行(fill)流。該串流被送到市場資料發布者(market data publisher)。
- 步驟 M2:市場資料發布者從執行與訂單的串流中建構 K 線圖與訂單簿,作為市場資料。然後它把市場資料送到資料服務。
- 步驟 M3:市場資料被儲存到專門的儲存中以供即時分析。券商連線到資料服務以取得即時市場資料,並把市場資料轉發給他們的客戶。
最後,我們檢視回報流(reporter flow)。
- 步驟 R1 - R2(回報流):回報器(reporter)從訂單與執行中收集所有必要的回報欄位(例如
client_id、price、quantity、order_type、filled_quantity、remaining_quantity),並把整合後的紀錄寫入資料庫。
交易流(步驟 1 到 14)位於關鍵路徑上,而市場資料流與回報流則不是。它們有不同的延遲要求。
現在讓我們更詳細地檢視這三個流程。
Trading flow#
交易流位於交易所的關鍵路徑上。每一步都必須快速。交易流的核心是撮合引擎。讓我們先談這個。
Matching engine
撮合引擎也稱為 cross engine。撮合引擎的主要職責有:
- 為每個標的維護訂單簿(order book)。訂單簿是某個標的買單與賣單的列表。我們會在後面的 Data models 一節說明訂單簿的構造。
- 撮合買單與賣單。一次撮合產生兩筆執行(fill),分別對應買方與賣方。撮合功能必須快速且準確。
- 將執行串流以市場資料的形式分發出去。
高可用的撮合引擎實作必須能以確定性順序產生撮合。也就是說,給定一個已知順序的訂單作為輸入,當該順序被重播時,撮合引擎必須產生相同順序的執行(fill)作為輸出。這種確定性是高可用性的基礎,我們會在 deep dive 一節詳細討論。
Sequencer
排序器(sequencer)是讓撮合引擎具備確定性的關鍵元件。它在訂單被撮合引擎處理之前為每筆進來的訂單蓋上 sequence ID。它也為撮合引擎完成的每對執行(fill)蓋上 sequence ID。
換句話說,排序器有 inbound 與 outbound 兩個實例,各自維護自己的序列。每個排序器產生的序列必須是連續的數字,這樣任何缺漏的數字都能被輕易偵測到。詳見圖 7。

進來的訂單與出去的執行都被蓋上 sequence ID 是基於以下原因:
- 即時性與公平性
- 快速恢復/重播
- Exactly-once 保證
排序器不只產生 sequence ID。它也作為訊息佇列運作:
- 一個用於把訊息(進來的訂單)送到撮合引擎
- 另一個用於把訊息(執行)送回訂單管理員
它也是訂單與執行的事件儲存。它類似於把兩條 Kafka 事件流連到撮合引擎,一條用於進來的訂單,另一條用於出去的執行。
事實上,如果 Kafka 的延遲更低且更可預測,我們其實可以使用 Kafka。我們會在 deep dive 一節討論排序器在低延遲交易所環境中的實作。
Order manager
訂單管理員一端接收訂單,另一端接收執行。它管理訂單的狀態。讓我們仔細看看。
訂單管理員從客戶端閘道接收進來的訂單,並執行以下動作:
- 它把訂單送去做風險檢查。我們的風險檢查需求很簡單。例如,我們驗證使用者的交易量低於每天 100 萬美元。
- 它根據使用者的錢包檢查訂單,並驗證有足夠的資金支付這筆交易。錢包在「Digital Wallet」一章中有詳細討論,可以參考該章中能用於交易所的實作。
- 它把訂單送到排序器,在那裡訂單被蓋上 sequence ID。經排序的訂單接著由撮合引擎處理。新訂單中有許多屬性,但不需要把所有屬性都送給撮合引擎。為了減少資料傳輸的訊息大小,訂單管理員只送必要的屬性。
另一端,訂單管理員透過排序器從撮合引擎接收執行。訂單管理員透過客戶端閘道把已成交訂單的執行回傳給券商。
訂單管理員應該快速、有效率且準確。它維護訂單的目前狀態。事實上,管理各種狀態轉換的挑戰是訂單管理員主要的複雜性來源。在實際的交易所系統中可能涉及上萬個案例。事件溯源(event sourcing)[9] 非常適合用於訂單管理員的設計。我們會在 deep dive 一節討論一個事件溯源設計。
Client gateway
客戶端閘道是交易所的把關者。它接收客戶下的訂單並把它們路由到訂單管理員。閘道提供如圖 8 所示的功能。

客戶端閘道位於關鍵路徑上,對延遲敏感。它應該保持輕量。它應該盡可能快地把訂單傳遞到正確的目的地。上述功能雖然關鍵,但必須盡快完成。決定要把哪些功能放在客戶端閘道、哪些不放,是個設計取捨。
一般原則是,我們應該把複雜的功能留給撮合引擎與風險檢查。
零售與機構客戶有不同類型的客戶端閘道。主要考量是延遲、交易量與安全要求。例如,做市商等機構為交易所提供大量流動性,他們需要非常低的延遲。圖 9 顯示交易所的不同客戶端閘道連線。
一個極端的例子是 colocation(colo)引擎。它是跑在券商於交易所資料中心租用的伺服器上的交易引擎軟體。延遲基本上就是光從同地伺服器傳到交易所伺服器所需的時間 [10]。

Market data flow#
市場資料發布者(market data publisher, MDP)從撮合引擎接收執行(fill),並從執行串流建構訂單簿與 K 線圖。訂單簿與 K 線圖(我們稍後在 Data Models 一節討論)統稱為市場資料。市場資料被送到資料服務,在那裡可被訂閱者使用。圖 10 顯示 MDP 的實作以及它如何與市場資料流中的其他元件配合。

Reporting flow#
交易所的一個關鍵部分是回報。回報器並不在交易關鍵路徑上,但它是系統的重要部分。它提供交易歷史、稅務回報、合規回報、結算等。
效率與延遲對交易流至關重要,但回報器對延遲較不敏感。準確性與合規性是回報器的關鍵因素。
常見做法是從進來的訂單與出去的執行兩邊把屬性拼湊起來:
- 一筆進來的新訂單只包含訂單細節
- 出去的執行通常只包含訂單 ID、價格、數量與執行狀態
回報器合併兩邊的屬性以產生報表。圖 11 顯示回報流中的元件如何配合。

細心的讀者可能注意到「Step 2 - Propose High-Level Design and Get Buy-In」的小節順序與其他章節稍有不同。本章中,API 設計與資料模型小節在高層次設計之後。這些小節這樣安排是因為它們需要一些在高層次設計中介紹的概念。
API Design#
既然我們了解了高層次設計,讓我們看看 API 設計。
客戶透過券商與股票交易所互動,以下單、檢視執行、檢視市場資料、下載歷史資料供分析等。我們對下面的 API 採用 RESTful 慣例,以指定券商與客戶端閘道之間的介面。下方提到的資源請參考「Data models」一節。
注意 REST API 可能無法滿足對沖基金等機構客戶的延遲需求。為這些機構打造的專用軟體可能使用不同的協定,但無論是哪種協定,下方所述的基本功能都需要被支援。
Order
POST /v1/order此端點下訂單。需要認證。
參數:
symbol: the stock symbol. String
side: buy or sell. String
price: the price of the limit order. Long
orderType: limit or market (note we only support limit orders in our design). String
quantity: the quantity of the order. Long回應 Body:
id: the ID of the order. Long
creationTime: the system creation time of the order. Long
filledQuantity: the quantity that has been successfully executed. Long
remainingQuantity: the quantity still to be executed. Long
status: new/canceled/filled. String
rest of the attributes are the same as the input parametersCode:
200: successful
40x: parameter error/access denied/unauthorized
500: server errorExecution
GET /execution?symbol={:symbol}&orderId={:orderId}&startTime={:startTime}&endTime={:endTime}此端點查詢執行資訊。需要認證。
參數:
symbol: the stock symbol. String
orderId: the ID of the order. Optional. String
startTime: query start time in epoch \[11\]. Long
endTime: query end time in epoch. Long回應 Body:
executions: array with each execution in scope (see attributes below). Array
id: the ID of the execution. Long
orderId: the ID of the order. Long
symbol: the stock symbol. String
side: buy or sell. String
price: the price of the execution. Long
orderType: limit or market. String
quantity: the filled quantity. LongCode:
200: successful
40x: parameter error/not found/access denied/unauthorized
500: server errorOrder book
GET /marketdata/orderBook/L2?symbol={:symbol}&depth={:depth}此端點以指定深度查詢某個標的的 L2 訂單簿資訊。
參數:
symbol: the stock symbol. String
depth: order book depth per side. Int回應 Body:
bids: array with price and size. Array
asks: array with price and size. ArrayCode:
200: successful
40x: parameter error/not found/access denied/unauthorized
500: server errorHistorical prices (candlestick charts)
GET /marketdata/candles?symbol={:symbol}&resolution={:resolution}&startTime={:startTime}&endTime={:endTime}此端點根據指定時間範圍與解析度查詢某個標的的 K 線圖資料(見資料模型一節中的 K 線圖)。
參數:
symbol: the stock symbol. String
resolution: window length of the candlestick chart in seconds. Long
startTime: start time of the window in epoch. Long
endTime: end time of the window in epoch. Long回應 Body:
candles: array with each candlestick data (attributes listed below). Array
open: open price of each candlestick. Double
close: close price of each candlestick. Double
high: high price of each candlestick. Double
low: low price of each candlestick. DoubleCode:
200: successful
40x: parameter error/not found/access denied/unauthorized
500: server errorData models#
股票交易所中有三種主要資料類型。讓我們逐一探索:
- Product、order 與 execution
- Order book
- Candlestick chart
Product, order, execution#
Product 描述被交易標的的屬性,例如商品類型、交易代號、UI 顯示代號、結算貨幣、每手單位數(lot size)、最小跳動單位(tick size)等。這個資料不常變動,主要用於 UI 顯示。資料可以儲存在任何資料庫中,且高度可快取。
Order 代表買單或賣單的進來指令。Execution 代表出去的撮合結果。Execution 也稱為 fill。並非每筆訂單都有 execution。撮合引擎的輸出包含兩筆執行,分別代表已撮合訂單的買方與賣方。
圖 12 為邏輯模型圖,顯示這三個實體之間的關係。注意它不是資料庫綱要(schema)。
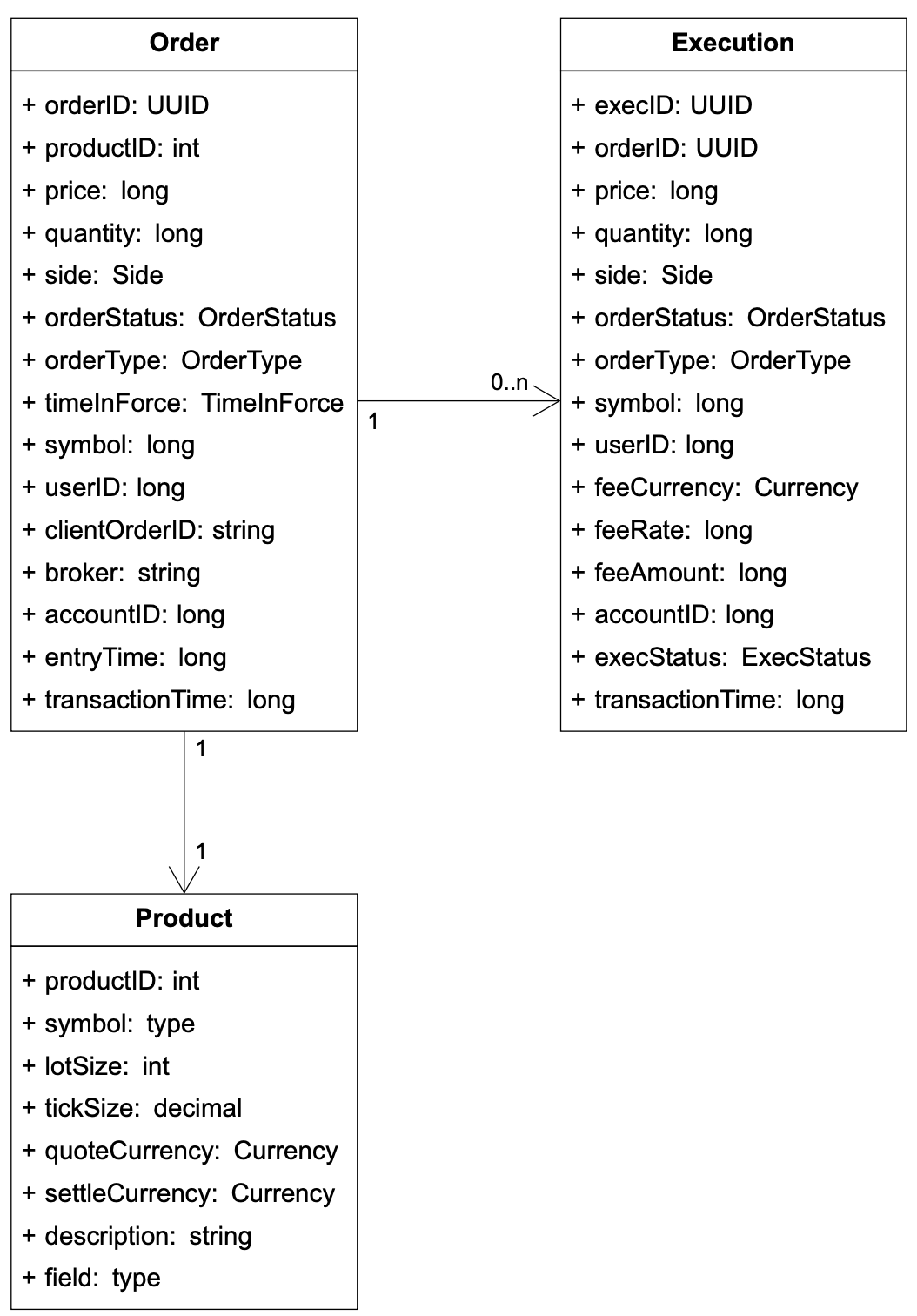
Orders 與 executions 是交易所中最重要的資料。我們在高層次設計中提到的三個流程裡都會遇到它們,只是形式略有不同:
- 在交易關鍵路徑中,orders 與 executions 不會儲存在資料庫中。為了達成高效能,這條路徑在記憶體中執行交易,並利用硬碟或共享記憶體來持久化與分享 orders 與 executions。具體來說,orders 與 executions 儲存在排序器中以便快速恢復,資料在收盤後被歸檔。我們會在 deep dive 一節討論排序器的高效實作。
- 回報器把 orders 與 executions 寫入資料庫供對帳與稅務回報等回報用例使用。
- Executions 被轉發到市場資料處理器(market data processor)以重建訂單簿與 K 線圖資料。我們接下來討論這些資料類型。
Order book#
訂單簿是某個特定證券或金融工具的買單與賣單列表,依價格層級組織 [12] [13]。它是撮合引擎中用於快速撮合訂單的關鍵資料結構。一個高效的訂單簿資料結構必須滿足以下需求:
- 常數時間查找。操作包含:取得某個價格層級或價格層級之間的成交量。
- 快速 add/cancel/execute 操作,最好是 O(1) 時間複雜度。操作包含:下新訂單、取消訂單、撮合訂單。
- 快速更新。操作:替換訂單。
- 查詢最佳買價/賣價。
- 遍歷價格層級。
讓我們透過圖 13 走過一個訂單針對訂單簿執行的範例。

在上述例子中,有一筆 2700 股 Apple 的大型市價買單。買單撮合了最佳賣價佇列中的所有賣單,以及 100.11 價格佇列中的第一筆賣單。在滿足這筆大訂單後,買賣價差(bid/ask spread)擴大,價格上升一個層級(最佳賣價現在是 100.11)。
下面的程式碼片段顯示訂單簿的一個實作。
class PriceLevel{
private Price limitPrice;
private long totalVolume;
private List<Order> orders;
}
class Book<Side> {
private Side side;
private Map<Price, PriceLevel> limitMap;
}
class OrderBook {
private Book<Buy> buyBook;
private Book<Sell> sellBook;
private PriceLevel bestBid;
private PriceLevel bestOffer;
private Map<OrderID, Order> orderMap;
}這段程式碼是否符合上述所有設計需求?例如,當新增/取消限價單時,時間複雜度是 O(1) 嗎?答案是不,因為我們在這裡使用普通 list(*private List
要有更有效率的訂單簿,把「orders」的資料結構改為雙向鏈結串列(doubly-linked list),這樣刪除類型的操作(取消與撮合)也是 O(1)。
讓我們看看我們如何為這些操作達成 O(1) 時間複雜度:
- 下新訂單意味著把一個新的 Order 加到 PriceLevel 的尾端。對於雙向鏈結串列,這是 O(1) 時間複雜度。
- 撮合一筆訂單意味著從 PriceLevel 的頭部刪除一個 Order。對於雙向鏈結串列,這是 O(1) 時間複雜度。
- 取消一筆訂單意味著從 OrderBook 中刪除一個 Order。我們利用 OrderBook 中的輔助資料結構 Map<OrderID, Order> orderMap,在 O(1) 時間內找到要取消的 Order。一旦找到訂單,如果「orders」list 是單向鏈結串列,程式碼就必須遍歷整個串列以找到前一個指標才能刪除訂單,那會花 O(n) 時間。由於串列現在是雙向的,訂單本身有指向前一筆訂單的指標,這讓程式碼能在不遍歷整個訂單串列的情況下刪除訂單。
圖 14 解釋這三個操作如何運作。

更多細節見參考資料 [14]。
值得注意的是,訂單簿資料結構在市場資料處理器中也大量使用,用於從撮合引擎產生的執行串流中重建 L1、L2、L3 資料。
Candlestick chart#
K 線圖是市場資料處理器中除了訂單簿之外,另一個產生市場資料的關鍵資料結構。
我們以 Candlestick class 與 CandlestickChart class 來建模。當 K 線的時間區間經過時,會為下個區間實例化新的 Candlestick class,並加到 CandleStickChart 實例的鏈結串列中。
class Candlestick {
private long openPrice;
private long closePrice;
private long highPrice;
private long lowPrice;
private long volume;
private long timestamp;
private int interval;
}
class CandlestickChart {
private LinkedList<Candlestick> sticks;
}為許多標的、許多時間區間追蹤 K 線圖中的價格歷史會消耗大量記憶體。我們如何優化?這裡有兩個方法:
- 使用預先配置的環形緩衝區(ring buffer)來保存 K 線,以減少新物件的配置數量。
- 限制記憶體中的 K 線數量,並把其餘部分持久化到磁碟。
我們會在 deep dive 中的「Market data publisher」一節檢視這些優化。
市場資料通常持久化到記憶體型欄式資料庫(in-memory columnar database,例如 KDB [15])以供即時分析。市場關閉後,資料持久化到歷史資料庫。