本章中,我們將討論為線上手機遊戲設計排行榜(leaderboard)的挑戰。
什麼是排行榜?排行榜在遊戲與其他領域中很常見,用來顯示誰在某個競賽或比賽中領先。使用者完成任務或挑戰可獲得積分,而擁有最多積分的人會在排行榜的頂端。圖 1 顯示一個手機遊戲排行榜的範例。排行榜顯示領先選手的排名,並顯示使用者在排行榜上的位置。

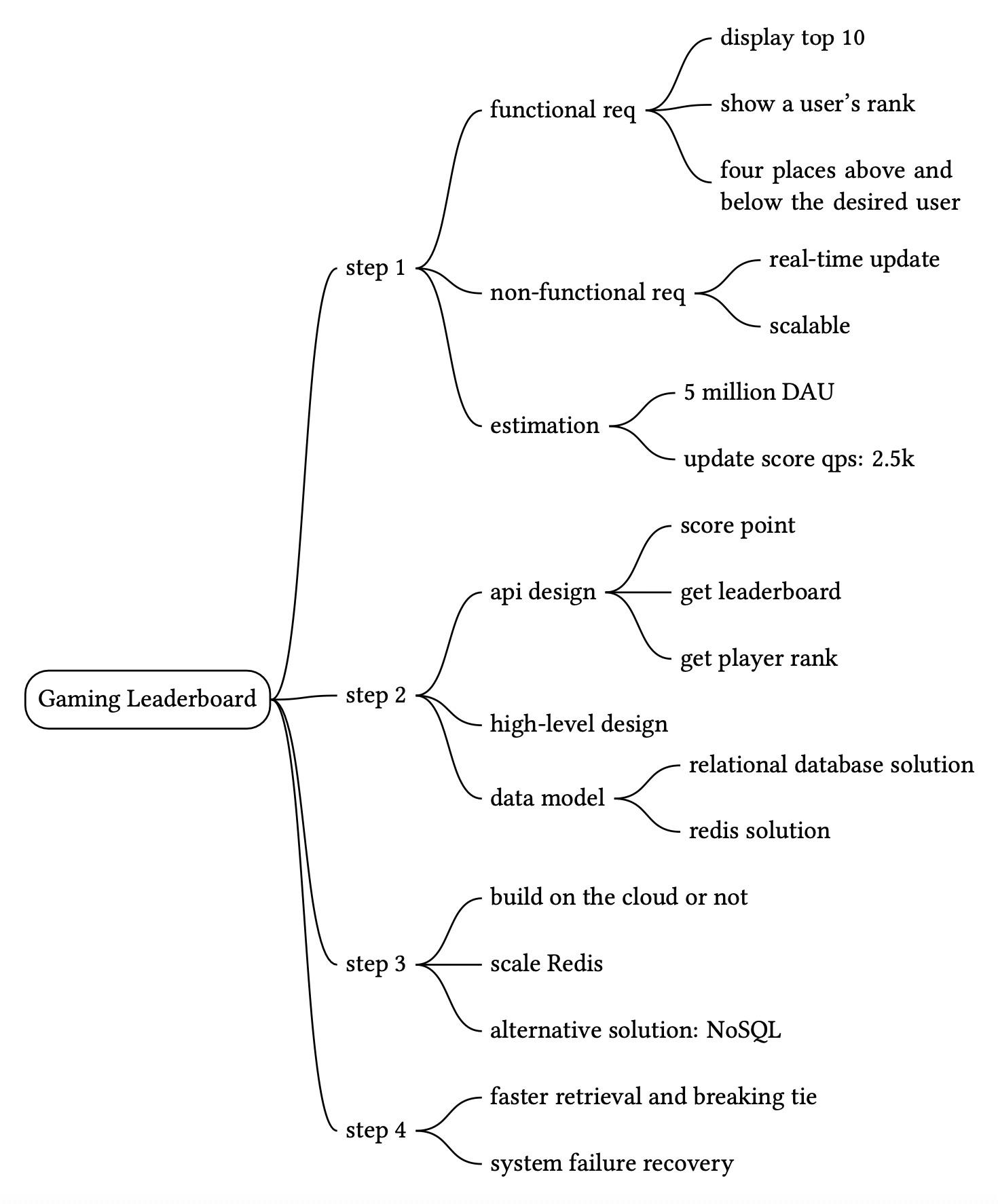
Step 1 - 理解問題並確立設計範圍#
排行榜可能相當直接,但有許多不同的事項可能增加複雜度。我們應釐清需求。
應徵者: 排行榜的分數如何計算?
面試官: 使用者贏得一場比賽時獲得 1 分。我們可以使用簡單的積分系統,每位使用者有一個關聯的分數。每次使用者贏得比賽,我們應將 1 分加到他們的總分。
應徵者: 所有玩家都包含在排行榜中嗎?
面試官: 是的。
應徵者: 排行榜有時間區段嗎?
面試官: 每個月會啟動一個新的錦標賽,開啟一個新的排行榜。
應徵者: 我們可以假設只關心前 10 名使用者嗎?
面試官: 我們希望顯示前 10 名使用者,以及特定使用者在排行榜上的位置。如果時間允許,也讓我們討論如何回傳特定使用者上下各 4 名的玩家。
應徵者: 一場錦標賽中有多少使用者?
面試官: 平均 500 萬日活躍使用者(DAU)與 2,500 萬月活躍使用者(MAU)。
應徵者: 一場錦標賽中平均進行多少場比賽?
面試官: 每位玩家平均每天玩 10 場比賽。
應徵者: 如果兩位玩家分數相同,我們如何決定排名?
面試官: 在這種情況下,他們的排名相同。如果時間允許,我們可以討論打破平手的方式。
應徵者: 排行榜需要即時嗎?
面試官: 是的,我們希望呈現即時結果,或盡可能接近即時。呈現批次歷史結果是不可接受的。
現在我們已收集所有需求,讓我們列出功能性需求。
- 顯示排行榜上前 10 名玩家。
- 顯示使用者的特定排名。
- 顯示目標使用者上下各 4 名的玩家(加分項目)。
除了釐清功能性需求之外,理解非功能性需求也很重要。
非功能性需求
- 分數即時更新。
- 分數更新即時反映在排行榜上。
- 一般的可擴展性、可用性與可靠性需求。
粗略估算#
讓我們做些粗略計算來判斷潛在規模與我們的解決方案需要處理的挑戰。
擁有 500 萬 DAU,如果遊戲在 24 小時期間玩家分佈均勻,我們平均每秒會有 50 位使用者(5,000,000 DAU / 10^5 秒 = ~50)。然而,我們知道使用情況很可能不是均勻分佈的,且可能在傍晚有高峰,因為許多跨時區的人有時間玩遊戲。為此,我們可以假設高峰負載是平均的 5 倍。因此我們想要允許每秒 250 位使用者的高峰負載。
- 使用者得分的 QPS:如果使用者每天平均玩 10 場遊戲,使用者得分的 QPS 為:50 _ 10 = ~500。高峰 QPS 是平均的 5 倍:500 _ 5 = 2,500。
- 擷取前 10 名排行榜的 QPS:假設使用者每天打開遊戲一次,前 10 名排行榜只在使用者首次開啟遊戲時載入。此 QPS 大約為 50。
Step 2 - 提出高層級設計並取得認可#
本節中,我們將討論 API 設計、高層級架構與資料模型。
API 設計#
從高層級來看,我們需要以下三個 API:
POST /v1/scores
當使用者贏得遊戲時更新其在排行榜上的位置。請求參數列於下方。
這應該是內部 API,只能由遊戲伺服器呼叫。客戶端不應能直接更新排行榜分數。
| 欄位 | 描述 |
|---|---|
| user_id | 贏得遊戲的使用者。 |
| points | 使用者贏得遊戲所獲得的點數。 |
表 1
回應:
| 名稱 | 描述 |
|---|---|
| 200 OK | 成功更新使用者分數。 |
| 400 Bad Request | 更新使用者分數失敗。 |
表 2
GET /v1/scores
從排行榜擷取前 10 名玩家。
回應範例:
{
"data": [
{
"user_id": "user_id1",
"user_name": "alice",
"rank": 1,
"score": 12543
},
{
"user_id": "user_id2",
"user_name": "bob",
"rank": 2,
"score": 11500
}
],
...
"total": 10
}GET /v1/scores/{:user_id}
擷取特定使用者的排名。
| 欄位 | 描述 |
|---|---|
| user_id | 我們想擷取排名的使用者 ID。 |
表 3
回應範例:
{
"user_info": {
"user_id": "user5",
"score": 1000,
"rank": 6
}
}高層級架構#
高層級設計圖如圖 2 所示。此設計中有兩個服務。遊戲服務允許使用者玩遊戲,而排行榜服務建立並顯示排行榜。

當玩家贏得遊戲時,客戶端發送請求到遊戲服務。
遊戲服務確認勝利有效並呼叫排行榜服務以更新分數。
排行榜服務在排行榜儲存中更新使用者的分數。
玩家直接呼叫排行榜服務以擷取排行榜資料,包括:
a. 前 10 名排行榜。
b. 玩家在排行榜上的排名。
在採用此設計之前,我們考慮了幾個替代方案並決定不採用它們。檢視這個思考過程並比較不同選項可能會有幫助。
客戶端應該直接與排行榜服務通訊嗎?

在替代設計中,分數由客戶端設定。此選項並不安全,因為它易遭中間人攻擊(man-in-the-middle attack)[x],玩家可以透過代理隨意修改分數。因此,我們需要分數在伺服器端設定。
請注意,對於伺服器主導的遊戲(例如線上撲克),客戶端可能不需要明確呼叫遊戲伺服器來設定分數。遊戲伺服器處理所有遊戲邏輯,知道遊戲何時結束,並可在無需客戶端介入的情況下設定分數。
我們是否需要在遊戲服務與排行榜服務之間放置訊息佇列?
這個問題的答案高度取決於遊戲分數如何被使用。如果資料在其他地方使用或支援多種功能,那麼將資料放入 Kafka 可能是合理的,如圖 4 所示。這樣,相同的資料可以被多個消費者使用,例如排行榜服務、分析服務、推送通知服務等。當遊戲是回合制或多人遊戲,需要通知其他玩家分數更新時尤其如此。由於這不是與面試官對話中明確的需求,我們在設計中不使用訊息佇列。

資料模型#
系統的關鍵元件之一是排行榜儲存。我們將討論三種潛在解決方案:關聯式資料庫、Redis 與 NoSQL(NoSQL 解決方案在深入探討中說明)。
關聯式資料庫解決方案#
首先,讓我們退一步,從最簡單的解決方案開始。如果規模不重要,且我們只有少量使用者呢?
我們最有可能選擇使用關聯式資料庫系統(RDS)的簡單排行榜解決方案。每個月的排行榜可以表示為一個包含 user id 與 score 欄位的資料庫表。當使用者贏得比賽時,如果他們是新使用者就給予 1 分,否則將既有分數加 1。為了決定使用者在排行榜上的排名,我們會將表依分數降序排序。詳細說明如下。
排行榜資料庫表:
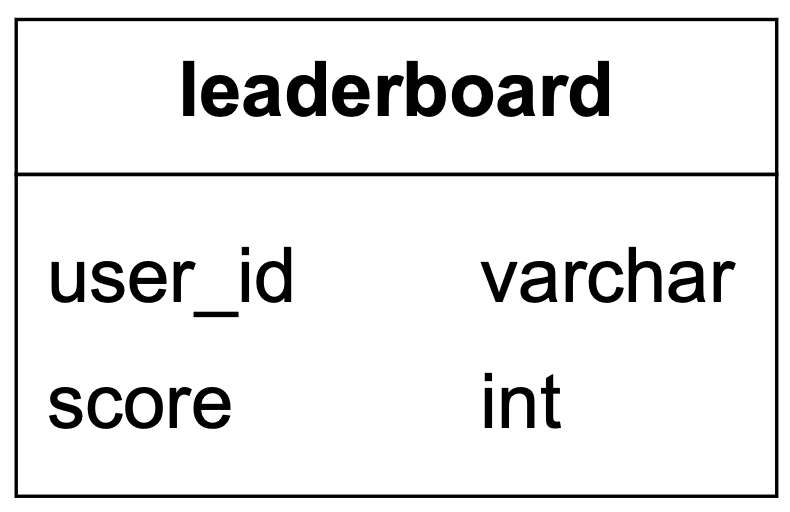
實際上,排行榜表會有額外資訊,例如 game_id、時間戳等。然而,查詢與更新排行榜的底層邏輯保持不變。為求簡單,我們假設只有當月的排行榜資料儲存在排行榜表中。
使用者贏得 1 分:

假設每次分數更新都是加 1。如果使用者本月在排行榜上還沒有條目,第一次插入會是:
INSERT INTO leaderboard (user_id, score) VALUES ('mary1934', 1);更新使用者分數會是:
UPDATE leaderboard set score=score + 1 where user_id='mary1934';找出使用者的排行榜位置:

要擷取使用者排名,我們會將排行榜表排序並按分數排名:
SELECT (@rownum := @rownum + 1) AS rank, user_id, score
FROM leaderboard
ORDER BY score DESC;SQL 查詢結果看起來像這樣:
| rank | user_id | score |
|---|---|---|
| 1 | happy_tomato | 987 |
| 2 | mallow | 902 |
| 3 | smith | 870 |
| 4 | mary1934 | 850 |
表 4 依分數排序的結果
此解決方案在資料集小時可行,但當有數百萬列時查詢會變得非常慢。讓我們看看為什麼。
要找出使用者的排名,我們需要將每個玩家排序到排行榜上的正確位置,這樣我們才能精確地決定正確的排名。請記住,分數也可能重複,所以排名不只是使用者在清單中的位置。
當我們必須處理大量持續變動的資訊時,SQL 資料庫表現不佳。試圖對數百萬列執行排名操作將需要數十秒,這對於所需的即時方式是不可接受的。由於資料持續變動,使用快取也不可行。
關聯式資料庫並非設計用來處理此實作所需的高讀取查詢負載。RDS 若以批次操作執行則可成功使用,但這不符合為使用者回傳即時排行榜位置的需求。
我們可以做的一個最佳化是新增索引並使用 LIMIT 子句限制掃描的頁數。查詢看起來像這樣:
SELECT (@rownum := @rownum + 1) AS rank, user_id, score
FROM leaderboard
ORDER BY score DESC
LIMIT 10然而,這方法擴展性不佳。首先,找出使用者排名效能不佳,因為它本質上需要全表掃描來決定排名。其次,這方法並未提供直接的方式來決定不在排行榜頂部使用者的排名。
Redis 解決方案#
我們想找一個即使對數百萬使用者也能提供可預測效能的解決方案,並讓我們能輕鬆存取常見的排行榜操作,而不必依賴複雜的資料庫查詢。
Redis 提供了一個潛在的解決方案。Redis 是支援鍵值對的記憶體內資料儲存。由於它在記憶體中運作,允許快速讀寫。Redis 有一個特殊的資料類型叫做 sorted sets(排序集合),非常適合解決排行榜系統設計問題。
什麼是 sorted sets?#
Sorted set 是類似於 set 的資料類型。Sorted set 的每個成員都關聯一個分數。Set 的成員必須是唯一的,但分數可以重複。分數用來將 sorted set 依升序排序。
我們的排行榜使用情境完美對應到 sorted sets。內部上,sorted set 由兩種資料結構實作:hash table 與 skip list(跳躍表)[1]。Hash table 將使用者對應到分數,skip list 將分數對應到使用者。在 sorted sets 中,使用者依分數排序。理解 sorted set 的好方法是將其想像成一個有 score 與 member 欄位的表,如圖 8 所示。表依分數降序排序。
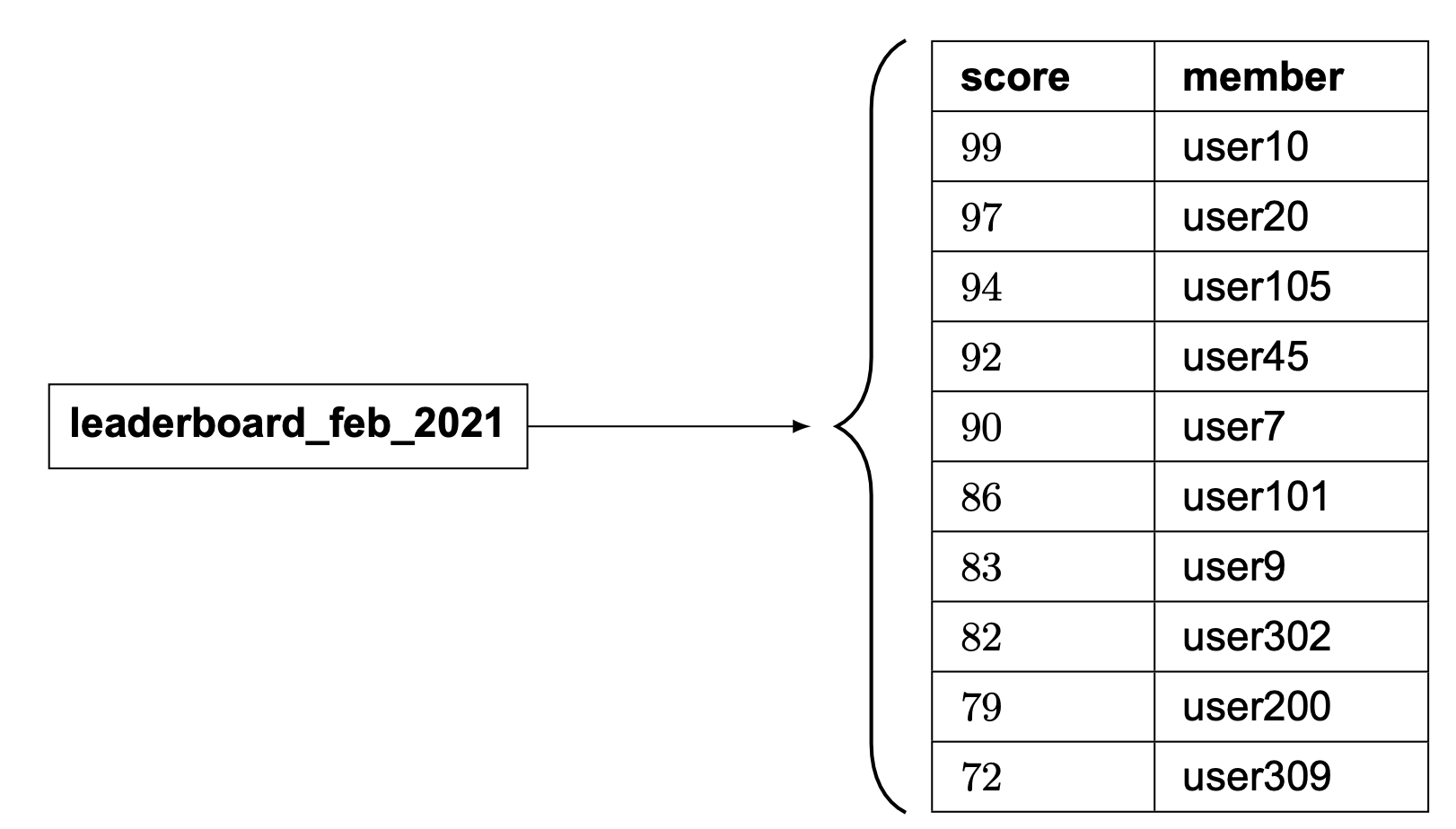
本章不會深入 sorted set 實作的全部細節,但我們會討論高層級的概念。
Skip list 是允許快速搜尋的清單結構。它由一個基礎排序鏈結串列與多層索引組成。讓我們看一個例子。在圖 9 中,基礎清單是排序的單向鏈結串列。插入、移除與搜尋操作的時間複雜度為 O(n)。
我們如何讓這些操作更快?一個想法是快速到達中間,就像二分搜尋演算法那樣。為此,我們新增一個 level 1 索引,跳過每隔一個節點,然後新增一個 level 2 索引,跳過 level 1 索引中每隔一個節點。我們持續引入更多層級,每個新層級跳過上一層每隔一個節點。當節點之間的距離為 n/2 - 1(其中 n 為節點總數)時,我們停止增加。如圖 9 所示,當我們有多層索引時,搜尋數字 45 快得多。

當資料集較小時,使用 skip list 的速度提升並不明顯。圖 10 顯示一個有 5 層索引的 skip list 範例。在基礎鏈結串列中,需要走過 62 個節點才能到達正確的節點。在 skip list 中,只需走過 11 個節點 [2]。

Sorted sets 比關聯式資料庫表現更好,因為每個元素在插入或更新時自動定位到正確順序,且 sorted set 中新增或尋找操作的複雜度是對數的:O(logn)。
相比之下,要在關聯式資料庫中計算特定使用者的排名,我們需要執行巢狀查詢:
SELECT *,(SELECT COUNT(*) FROM leaderboard lb2
WHERE lb2.score >= lb1.score) RANK
FROM leaderboard lb1
WHERE lb1.user_id = {:user_id};使用 Redis sorted sets 實作#
現在我們知道 sorted sets 很快,讓我們看看建立排行榜會用到的 Redis 操作 [3] [4] [5] [6]:
- ZADD:如果使用者尚不存在,將使用者插入 set。否則,更新使用者的分數。執行需要 O(log(n))。
- ZINCRBY:將使用者的分數增加指定的增量。如果使用者不存在於 set 中,則假設分數從 0 開始。執行需要 O(log(n))。
- ZRANGE/ZREVRANGE:擷取依分數排序的使用者範圍。我們可以指定順序(range vs. revrange)、條目數量與起始位置。執行需要 O(log(n)+m),其中 m 是要擷取的條目數(在我們的情況下通常很小),n 是 sorted set 中的條目數。
- ZRANK/ZREVRANK:以對數時間擷取任何使用者依升序/降序排序的位置。
Sorted sets 的工作流程
使用者得 1 分

每個月我們建立新的排行榜 sorted set,先前的 set 被移到歷史資料儲存。當使用者贏得一場比賽時,他們得 1 分;所以我們呼叫 ZINCRBY 將使用者的分數在當月排行榜中加 1,或在使用者尚不在排行榜 set 中時將其加入。ZINCRBY 的語法為:
ZINCRBY <key> <increment> <user>以下指令在使用者「mary1934」贏得比賽後加 1 分。
ZINCRBY leaderboard_feb_2021 1 'mary1934'使用者擷取全球前 10 名排行榜

我們會呼叫 ZREVRANGE 以降序取得成員,因為我們想要最高分數,並傳遞「WITHSCORES」屬性以確保它也回傳每位使用者的總分以及最高分使用者的集合。以下指令擷取 Feb-2021 排行榜上前 10 名玩家。
ZREVRANGE leaderboard_feb_2021 0 9 WITHSCORES這會回傳如下清單:
[(user2,score2),(user1,score1),(user5,score5)...]使用者想擷取自己的排行榜位置

要擷取使用者在排行榜上的位置,我們呼叫 ZREVRANK 來擷取他們在排行榜上的排名。同樣地,我們呼叫 rev 版本的指令,因為我們想要從高到低排序分數。
ZREVRANK leaderboard_feb_2021 'mary1934'擷取使用者在排行榜中的相對位置。範例如圖 14 所示。

雖然不是明確的需求,我們可以輕鬆地利用 ZREVRANGE 並指定目標玩家上下方的結果數來擷取使用者的相對位置。例如,如果使用者 Mallow007 的排名是 361,且我們想擷取上下各 4 名玩家,我們會執行下列指令。
ZREVRANGE leaderboard_feb_2021 357 365
儲存需求#
至少,我們需要儲存使用者 ID 與分數。最壞情況是所有 2,500 萬月活躍使用者都至少贏過一場比賽,且都在當月排行榜中有條目。假設 ID 是 24 字元字串,分數是 16 位元整數(即 2 bytes),我們每筆排行榜條目需要 26 bytes 的儲存。給定每位 MAU 一筆排行榜條目的最壞情況,Redis 快取的排行榜儲存需要 26 bytes * 2,500 萬 = 6.5 億 bytes,約 650 MB。即使我們將記憶體使用量加倍以考慮 skip list 與 sorted set 的 hash 開銷,一台現代 Redis 伺服器也綽綽有餘容納資料。
另一個相關因素是 CPU 與 I/O 使用量。我們從粗略估算得到的高峰 QPS 為 2,500 次更新/秒。這完全在單一 Redis 伺服器的效能範圍內。
關於 Redis 快取的一個顧慮是持久性,因為 Redis 節點可能會故障。幸運的是,Redis 確實支援持久性,但從磁碟重新啟動大型 Redis 實例很慢。通常 Redis 會配置一個唯讀副本,當主實例失敗時,唯讀副本被提升,並附加新的唯讀副本。
此外,我們需要在像 MySQL 這樣的關聯式資料庫中有 2 個支援表(user 與 point)。User 表會儲存使用者 ID 與使用者顯示名稱(在實際應用中會包含更多資料)。Point 表會包含使用者 ID、分數與贏得遊戲的時間戳。這可用於其他遊戲功能,例如遊玩歷史,也可在基礎設施故障時用來重建 Redis 排行榜。
作為一個小型效能最佳化,建立額外的使用者詳細資訊快取可能合理,特別是針對前 10 名玩家,因為他們最常被擷取。然而,這的資料量並不大。
Step 3 - 設計深入探討#
現在我們已經討論了高層級設計,讓我們深入以下內容:
- 是否使用雲端供應商
- 自行管理服務
- 利用雲端服務供應商如 Amazon Web Services(AWS)
- 擴展 Redis
- 替代方案:NoSQL
- 其他考量
是否使用雲端供應商#
依照現有基礎設施而定,我們通常有兩種部署解決方案的選項。讓我們逐一看看。
自行管理服務#
在這種方式中,我們會在每個月建立一個排行榜 sorted set 來儲存該期間的排行榜資料。Sorted set 儲存成員與分數資訊。其他關於使用者的詳細資訊,例如名稱與個人資料圖片,儲存在 MySQL 資料庫中。擷取排行榜時,除了排行榜資料外,API 伺服器也會查詢資料庫以擷取對應使用者的名稱與個人資料圖片以顯示在排行榜上。如果這在長期變得效率不佳,我們可以利用使用者個人資料快取來儲存前 10 名玩家的使用者詳細資訊。設計如圖 15 所示。
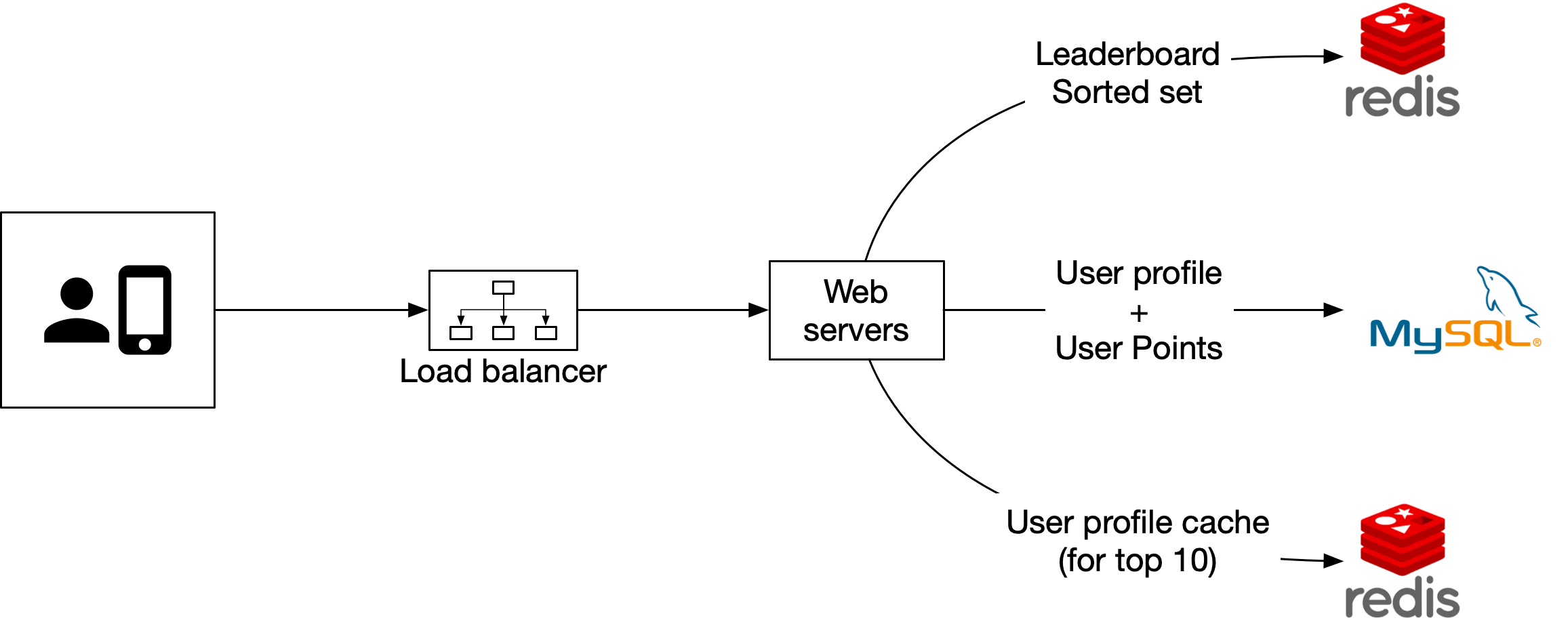
建立在雲端#
第二種方式是利用雲端基礎設施。本節中,我們假設我們的現有基礎設施建立在 AWS 上,且自然適合在雲端建立排行榜。我們在此設計中將使用兩項主要的 AWS 技術:Amazon API Gateway 與 AWS Lambda function [7]。Amazon API Gateway 提供一種定義 RESTful API 的 HTTP 端點並將其連接到任何後端服務的方式。我們使用它來連接到 AWS lambda 函式。RESTful API 與 lambda 函式之間的對應如表 5 所示。
| APIs | Lambda function |
|---|---|
| GET /v1/scores | LeaderboardFetchTop10 |
| GET /v1/scores/{:user_id} | LeaderboardFetchPlayerRank |
| POST /v1/scores | LeaderboardUpdateScore |
表 5 Lambda 函式
AWS Lambda 是最熱門的無伺服器運算平台之一。它讓我們可以執行程式碼而不必自行配置或管理伺服器。它只在需要時執行,並會根據流量自動擴展。無伺服器是雲端服務中最熱門的話題之一,所有主要雲端服務供應商都支援。例如,Google Cloud 有 Google Cloud Functions [8],Microsoft 將其產品命名為 Microsoft Azure Functions [9]。
從高層級來看,我們的遊戲呼叫 Amazon API Gateway,後者再呼叫適當的 lambda 函式。我們會使用 AWS Lambda 函式呼叫儲存層(包括 Redis 與 MySQL)上的適當指令,將結果回傳給 API Gateway,然後回傳給應用程式。
我們可利用 Lambda 函式執行所需的查詢,而不必啟動伺服器實例。AWS 提供對 Redis 客戶端的支援,可從 Lambda 函式呼叫。這也允許隨 DAU 成長根據需要自動擴展。使用者得分與擷取排行榜的設計圖如下:
使用情境 1:得分

使用情境 2:擷取排行榜

Lambda 很棒,因為它們是無伺服器方式,基礎設施會根據需要自動擴展函式。這意味著我們不需要管理擴展和環境設置與維護。基於此,如果我們從零開始建立遊戲,我們建議採用無伺服器方式。
擴展 Redis#
擁有 500 萬 DAU,從儲存與 QPS 角度來看,一台 Redis 快取就夠了。然而,讓我們想像我們有 5 億 DAU,這是我們原始規模的 100 倍。現在我們排行榜大小的最壞情況上升到 65 GB(650 MB _ 100),且 QPS 上升到 250,000(2,500 _ 100)次查詢/秒。這需要分片解決方案。
資料分片#
我們考慮以下兩種方式之一進行分片:固定分區(fixed)或雜湊分區(hash partitions)。
固定分區
理解固定分區的一種方式是看排行榜上點數的整體範圍。假設一個月內贏得的點數範圍是 1 到 1000,我們依範圍分割資料。例如,我們可以有 10 個 shard,每個 shard 有 100 分的範圍(例如 1-100、101-200、201-300…),如圖 18 所示。

要讓這方法可行,我們希望確保排行榜上的分數分佈均勻。否則,我們需要調整每個 shard 的分數範圍以確保相對均勻的分佈。在這方法中,我們在應用程式碼中自行分片資料。
當我們插入或更新使用者的分數時,需要知道他們在哪個 shard。我們可以從 MySQL 資料庫計算使用者目前的分數來完成這個動作。這可以運作,但更高效能的選項是建立一個次要快取來儲存使用者 ID 到分數的對應。我們需要小心使用者增加分數並在 shard 之間移動的情況。在這種情況下,我們需要將使用者從目前 shard 中移除並移到新 shard。
要擷取排行榜上前 10 名玩家,我們會從分數最高的 shard(sorted set)擷取前 10 名玩家。在圖 18 中,分數為 [901, 1000] 的最後一個 shard 包含前 10 名玩家。
要擷取使用者的排名,我們需要計算他們在目前 shard 中的排名(local rank),以及所有 shard 中分數較高的玩家總數。請注意,可以透過執行「info keyspace」指令以 O(1) 取得 shard 中的玩家總數 [10]。
雜湊分區
第二種方式是使用 Redis cluster,這在分數非常聚集或群集時是理想的。Redis cluster 提供一種跨多個 Redis 節點自動分片資料的方式。它不使用一致性雜湊,而是使用不同形式的分片,每個鍵都屬於一個 hash slot。共有 16384 個 hash slot [11],我們可以透過 CRC16(key) % 16384 [12] 計算給定鍵的 hash slot。這讓我們可以輕鬆在叢集中新增與移除節點,無需重新分配所有鍵。在圖 19 中,我們有 3 個節點,其中:
- 第一個節點包含 hash slot [0, 5500]。
- 第二個節點包含 hash slot [5501, 11000]。
- 第三個節點包含 hash slot [11001, 16383]。
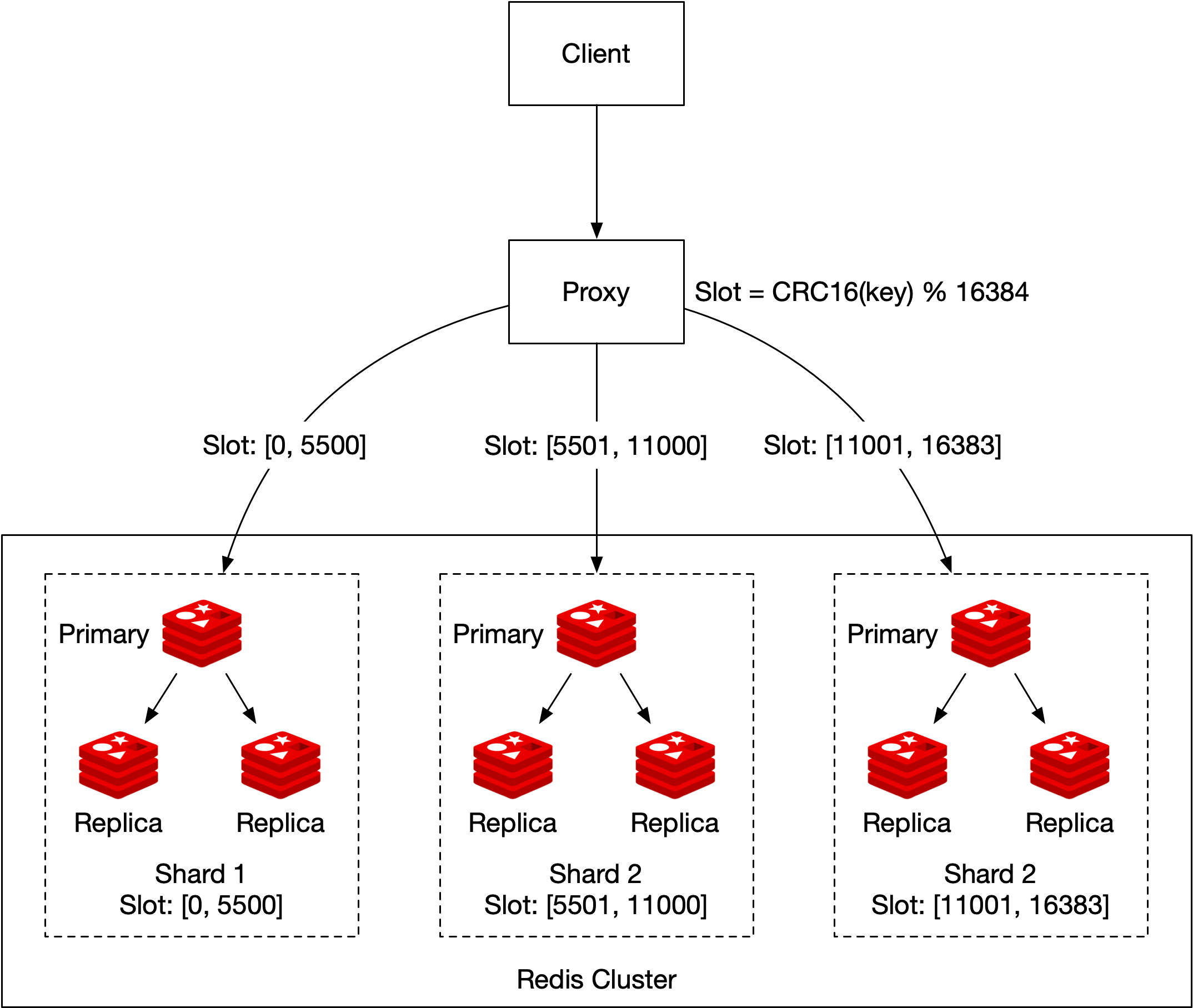
更新只需在對應的 shard(由 CRC16(key)%16384 決定)中變更使用者的分數。擷取排行榜前 10 名玩家更為複雜。我們需要從每個 shard 收集前 10 名玩家,並讓應用程式對資料排序。具體範例如圖 20 所示。這些查詢可以平行化以降低延遲。
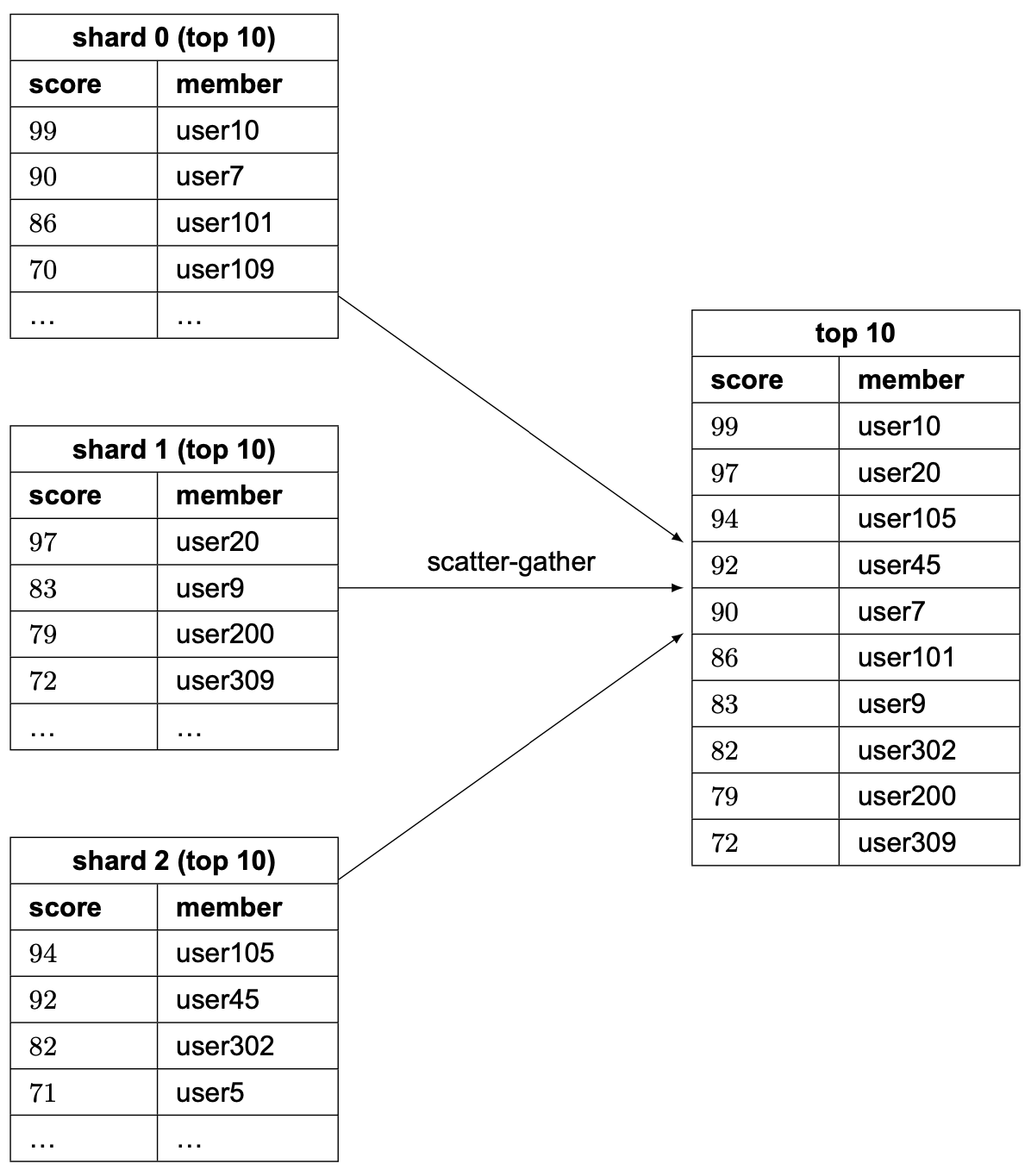
此方式有些限制:
- 當我們需要在排行榜上回傳前 K 個結果(K 是非常大的數字)時,由於每個 shard 回傳許多條目並需要排序,延遲很高。
- 如果我們有大量分區,由於查詢必須等待最慢的分區,延遲很高。
- 此方式的另一個問題是它沒有提供決定特定使用者排名的直接解決方案。
因此,我們傾向於第一個提案:固定分區。
Redis 節點規模設定#
設定 Redis 節點大小時有多個考量 [13]。寫入密集應用需要更多可用記憶體,因為我們需要能夠容納所有寫入以在故障時建立快照。
為求安全,為寫入密集應用配置兩倍的記憶體。
Redis 提供一個叫做 Redis-benchmark 的工具,讓我們可以對 Redis 設置進行基準測試,透過模擬多個客戶端執行多個查詢並回傳給定硬體下的每秒請求數。要了解更多關於 Redis-benchmark 的資訊,請參閱 [14]。
替代方案:NoSQL#
要考慮的替代方案是 NoSQL 資料庫。我們應使用哪種 NoSQL?理想情況下,我們希望選擇具有以下屬性的 NoSQL:
- 為寫入最佳化。
- 在同一分區中依分數有效排序項目。
NoSQL 資料庫如 Amazon DynamoDB [15]、Cassandra 或 MongoDB 都可以是不錯的選擇。本章中,我們以 DynamoDB 作為範例。DynamoDB 是完全託管的 NoSQL 資料庫,提供可靠效能與強大可擴展性。為了允許以主鍵以外的屬性高效存取資料,我們可在 DynamoDB 中利用 global secondary indexes [16]。Global secondary index 包含父表中的部分屬性,但它們以不同的主鍵組織。讓我們看一個範例。
更新後的系統圖如圖 21 所示。Redis 與 MySQL 被 DynamoDB 取代。

假設我們為西洋棋設計排行榜,初始表如圖 22 所示。它是排行榜表與使用者表的反正規化檢視,包含渲染排行榜所需的所有內容。

此表結構可運作,但擴展性不佳。隨著新增更多列,我們必須掃描整個表才能找到最高分。
為了避免線性掃描,我們需要新增索引。我們的第一次嘗試是使用「game_name#{year-month}」作為 partition key 並以 score 作為 sort key,如圖 23 所示。

這可運作,但在高負載下會遇到問題。DynamoDB 使用一致性雜湊跨多個節點分割資料。每個項目根據其 partition key 存在於對應節點。我們希望結構化資料,使資料均勻分佈於分區之間。在我們的表設計(圖 23)中,最近一個月的所有資料會儲存在一個分區中,該分區會成為熱點分區。我們如何解決這個問題?
我們可以將資料分割成 N 個分區,並將分區編號(user_id % number_of_partitions)附加到 partition key。此模式稱為 write sharding。Write sharding 為讀寫操作增加了複雜度,因此我們應仔細考慮權衡。
我們需要回答的第二個問題是,我們應有多少分區?這可以根據寫入量或 DAU 決定。重點是要記住分區負載與讀取複雜度之間有權衡。因為同一個月的資料均勻分佈於多個分區,單一分區的負載輕得多。然而,要讀取給定月份的項目,我們必須查詢所有分區並合併結果,這增加了讀取複雜度。
Partition key 看起來像這樣:「game_name#{year-month}#p{partition_number}」。圖 24 顯示更新後的表結構。

Global secondary index 使用「game_name#{year-month}#p{partition_number}」作為 partition key 並以 score 作為 sort key。我們最終會有 N 個分區,每個分區內部是排序的(local sorted)。如果我們假設有 3 個分區,那麼為了擷取前 10 名排行榜,我們會使用前面提到的「scatter-gather」方式。我們會在每個分區中擷取前 10 名結果(這是「scatter」部分),然後讓應用程式在所有分區之間排序結果(這是「gather」部分)。範例如圖 25 所示。
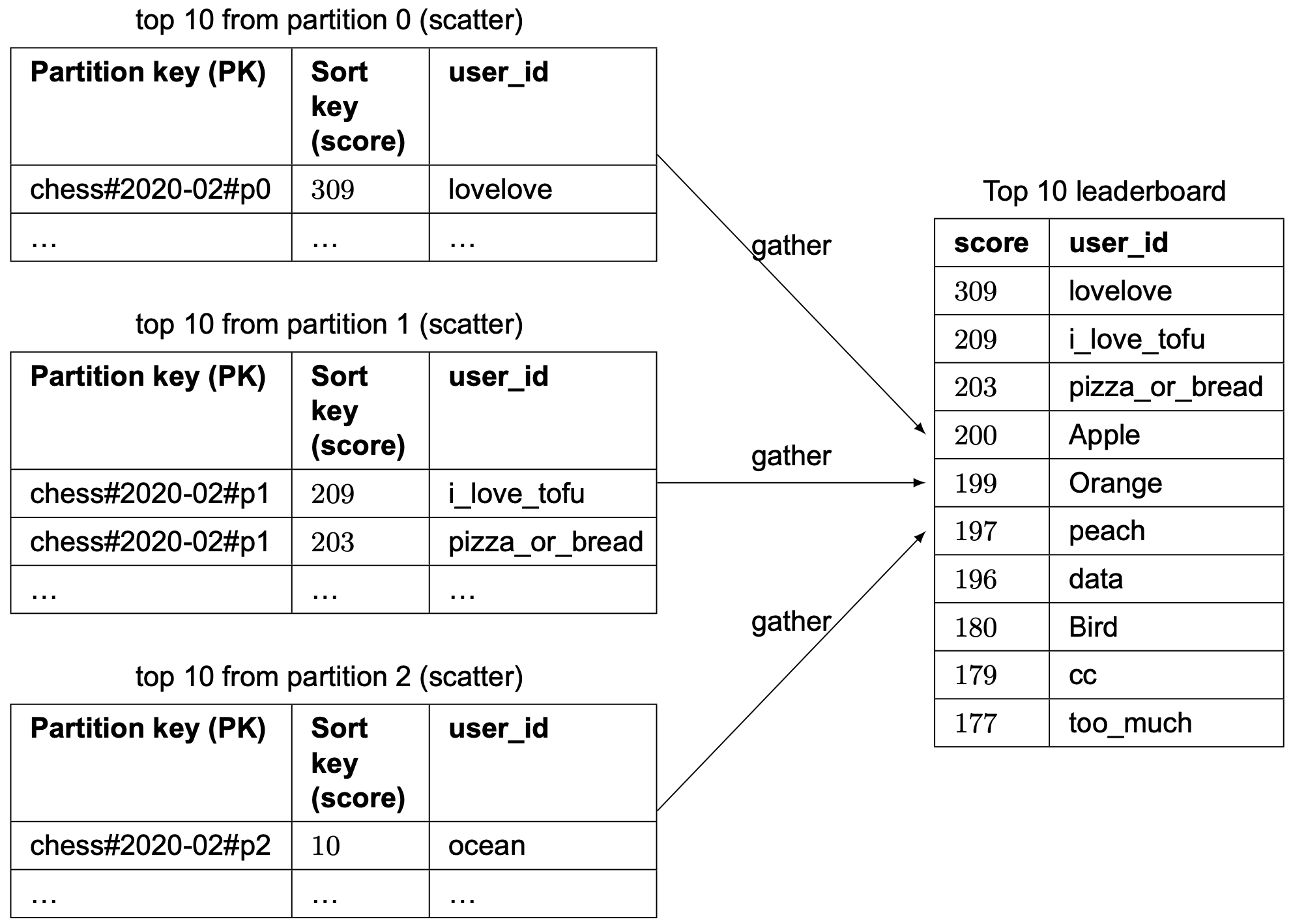
我們如何決定分區數量?這可能需要一些謹慎的基準測試。更多分區降低每個分區的負載但增加複雜度,因為我們需要 scatter 到更多分區來建立最終的排行榜。透過基準測試,我們可以更清楚地看到權衡。
然而,類似於前面提到的 Redis 分區解決方案,此方式並未提供決定使用者相對排名的直接解決方案。但可以取得使用者位置的百分位數,這可能已經夠用了。實際上,告訴玩家他們在前 10-20% 可能比顯示確切排名(例如 1,200,001)更好。
因此,如果規模大到我們需要分片,我們可以假設分數分佈在所有 shard 之間大致相同。如果這個假設成立,我們可以有一個 cron job 分析每個 shard 的分數分佈,並快取該結果。
結果看起來像這樣:
10th percentile = score < 100
20th percentile = score < 500
...
90th percentile = score < 6500然後我們可以快速回傳使用者的相對排名(例如第 90 個百分位數)。
Step 4 - 總結#
本章中,我們建立了一個適用於數百萬 DAU 規模的即時遊戲排行榜解決方案。我們探索了使用 MySQL 資料庫的直接解決方案,並拒絕了該方式,因為它無法擴展到數百萬使用者。我們接著使用 Redis sorted sets 設計排行榜。我們也看了如何透過跨不同 Redis 快取進行分片,將解決方案擴展到 5 億 DAU。我們也提出了替代的 NoSQL 解決方案。
如果你在面試結束時還有額外時間,可以涵蓋更多主題:
更快的擷取與打破平手
Redis Hash 提供字串欄位與值之間的對應。我們可以利用 hash 用於 2 個使用情境:
- 儲存使用者 ID 到使用者物件的對應,可顯示在排行榜上。這比每次都到資料庫擷取使用者物件更快。
- 在兩位玩家分數相同的情況下,我們可以根據誰先獲得該分數來排名使用者。當我們增加使用者分數時,也可以儲存使用者 ID 到最近贏得遊戲的時間戳的對應。在平手的情況下,時間戳較舊的使用者排名較高。
系統故障復原
Redis cluster 可能會經歷大規模故障。給定上述設計,我們可以建立一個指令稿,利用 MySQL 資料庫每次使用者贏得遊戲時記錄帶有時間戳的條目這一事實。我們可以遍歷每位使用者的所有條目,並為每位使用者每個條目呼叫一次 ZINCRBY。這讓我們可以在大規模中斷的情況下,必要時離線重建排行榜。
恭喜你看到這裡!現在拍拍自己的背。做得好!
章節摘要#