本章中,我們設計一個類似 Amazon Simple Storage Service(S3)的物件儲存服務。S3 是 Amazon Web Services(AWS)提供的服務,透過 RESTful API 介面提供物件儲存。以下是有關 AWS S3 的一些事實:
- 於 2006 年 6 月推出。
- S3 在 2010 年新增版本控管、bucket policy 與多部分上傳支援。
- S3 在 2011 年新增伺服器端加密、多物件刪除與物件過期功能。
- Amazon 在 2013 年回報 S3 中已儲存 2 兆個物件。
- 生命週期政策、事件通知與跨區域複寫支援於 2014 年與 2015 年引入。
- Amazon 在 2021 年回報 S3 中已儲存超過 100 兆個物件。
在我們深入物件儲存之前,先回顧一下儲存系統並定義一些術語。
儲存系統 101#
從高層級來看,儲存系統可分為三大類:
- 區塊儲存(Block storage)
- 檔案儲存(File storage)
- 物件儲存(Object storage)
區塊儲存#
區塊儲存最早出現於 1960 年代。常見的儲存裝置如硬碟(HDD)與固態硬碟(SSD)實體連接到伺服器,都被視為區塊儲存。
區塊儲存將原始區塊以 volume 的形式呈現給伺服器。這是最具彈性且最多用途的儲存形式。伺服器可以將原始區塊格式化並當作檔案系統使用,或將那些區塊的控制權交給應用程式。某些應用程式如資料庫或虛擬機器引擎會直接管理這些區塊,以榨乾每一滴效能。
區塊儲存不限於實體連接的儲存。區塊儲存可透過高速網路或 Fibre Channel(FC)[1] 與 iSCSI [2] 等業界標準連接協定連接到伺服器。概念上,網路連接的區塊儲存仍呈現原始區塊。對伺服器而言,它與實體連接的區塊儲存運作方式相同。
檔案儲存#
檔案儲存建立在區塊儲存之上。它提供了更高層級的抽象,讓檔案與目錄的處理更容易。資料以檔案的形式儲存在階層式目錄結構之下。檔案儲存是最常見的通用儲存解決方案。檔案儲存可透過 SMB/CIFS [3] 與 NFS [4] 等常見的檔案層級網路協定供大量伺服器存取。存取檔案儲存的伺服器不需要處理管理區塊、格式化 volume 等複雜性。檔案儲存的簡單性使其成為組織內共享大量檔案與資料夾的絕佳解決方案。
物件儲存#
物件儲存是新的。它做出非常刻意的權衡,犧牲效能以換取高耐久性、巨大規模與低成本。它針對相對「冷」的資料,主要用於封存與備份。物件儲存將所有資料儲存為扁平結構中的物件。沒有階層式目錄結構。資料存取通常透過 RESTful API 提供。它與其他儲存類型相比相對較慢。大多數公有雲服務供應商都有物件儲存產品,例如 AWS S3、Google object storage 與 Azure blob storage。
比較#

表 1 比較區塊儲存、檔案儲存與物件儲存。
| 區塊儲存 | 檔案儲存 | 物件儲存 | |
|---|---|---|---|
| 內容可變更 | Y | Y | N(支援物件版本控管,不支援原地更新) |
| 成本 | 高 | 中至高 | 低 |
| 效能 | 中至高,極高 | 中至高 | 低至中 |
| 一致性 | 強一致性 | 強一致性 | 強一致性 [5] |
| 資料存取 | SAS [6]/iSCSI/FC | 標準檔案存取,CIFS/SMB 與 NFS | RESTful API |
| 可擴展性 | 中等可擴展性 | 高可擴展性 | 巨大可擴展性 |
| 適用於 | 虛擬機器(VM)、高效能應用如資料庫 | 通用檔案系統存取 | 二進位資料、非結構化資料 |
表 1 儲存選項
術語#
要設計類似 S3 的物件儲存,我們需要先理解一些核心物件儲存概念。本節提供物件儲存相關術語的概述。
- Bucket:物件的邏輯容器。Bucket 名稱是全域唯一的。要上傳資料到 S3,我們必須先建立一個 bucket。
- Object:物件是我們儲存在 bucket 中的個別資料片段。它包含物件資料(也稱為 payload)與 metadata。物件資料可以是我們想儲存的任何位元組序列。Metadata 是描述物件的一組名稱-值對。
- 版本控管(Versioning):在同一個 bucket 中保留物件多個版本的功能。它在 bucket 層級啟用。此功能讓使用者可以復原意外刪除或覆寫的物件。
- 統一資源識別碼(URI):物件儲存提供 RESTful API 存取其資源,亦即 buckets 與 objects。每個資源都由其 URI 唯一識別。
- 服務等級協議(SLA):服務等級協議是服務供應商與客戶之間的契約。例如,Amazon S3 Standard-Infrequent Access 儲存類別提供以下 SLA [7]:
- 設計用於跨多個可用性區域達成 99.999999999% 的物件耐久性。
- 在整個可用性區域被毀壞的事件中資料仍具韌性。
- 設計用於 99.9% 可用性。
Step 1 - 理解問題並確立設計範圍#
以下問題有助於釐清需求並縮小範圍。
應徵者:設計中應包含哪些功能?
面試官:我們希望你設計一個類似 S3 的物件儲存系統,具備以下功能:
- 建立 bucket。
- 物件上傳與下載。
- 物件版本控管。
- 列出 bucket 中的物件。類似於「aws s3 ls」指令 [8]。
應徵者:典型的資料大小是多少?
面試官:我們需要高效地儲存巨大物件(數 GB 或更大)以及大量小物件(數十 KB)。
應徵者:一年內我們需要儲存多少資料?
面試官:100 PB(petabytes)。
應徵者:我們可以假設資料耐久性為 6 個 9(99.9999%)且服務可用性為 4 個 9(99.99%)嗎?
面試官:可以,這聽起來合理。
非功能性需求#
- 100 PB 的資料
- 資料耐久性為 6 個 9
- 服務可用性為 4 個 9
- 儲存效率。在維持高可靠度與效能的同時降低儲存成本。
粗略估算#
物件儲存可能會在磁碟容量或每秒磁碟 IO(IOPS)上有瓶頸。讓我們看看。
- 磁碟容量:讓我們假設物件遵循以下分佈:
- 20% 的所有物件是小物件(小於 1 MB)。
- 60% 的物件是中等大小物件(1 MB ~ 64 MB)。
- 20% 是大物件(大於 64 MB)。
- IOPS:假設一顆硬碟(SATA 介面、7200 rpm)每秒可進行 100~150 次隨機尋道(100-150 IOPS)。
有了這些假設,我們可以估算系統可持久化的物件總數。為簡化計算,讓我們對每種物件類型使用中位數大小(小物件 0.5 MB、中等物件 32 MB、大物件 200 MB)。40% 的儲存使用率讓我們得到:
- 100 PB = 10010001000*1000 MB = 10^11 MB
- 10^110.4/( 0.20.5MB + 0.6 32MB + 0.2200MB) = 6.8 億個物件。
- 如果我們假設物件的 metadata 大小約為 1 KB,則需要 0.68 TB 的空間來儲存所有 metadata 資訊。
即使我們不會使用這些數字,對系統的規模與限制有大致的概念是好的。
Step 2 - 提出高層級設計並取得認可#
在深入設計之前,讓我們探索物件儲存的一些有趣特性,因為它們可能會影響設計。
- 物件不可變性:物件儲存與其他兩種儲存系統的主要差異之一是儲存在物件儲存中的物件是不可變的。我們可以刪除它們或用新版本完全取代,但無法做增量變更。
- 鍵值儲存(Key-value store):我們可以使用物件 URI 來擷取物件資料(Listing 1)。物件 URI 是 key,物件資料是 value。
Listing 1 使用物件 URI 擷取物件資料
- 寫入一次,讀取多次:物件資料的存取模式是寫入一次,讀取多次。根據 LinkedIn 所做的研究,95% 的請求是讀取操作 [9]。
- 同時支援小物件與大物件:物件大小可能不同,我們需要兩者都支援。
物件儲存的設計哲學與 UNIX 檔案系統非常相似。在 UNIX 中,當我們將檔案儲存在本機檔案系統時,並不會將檔名與檔案資料一起儲存。相反地,檔名儲存在一個名為「inode」[10] 的資料結構中,檔案資料則儲存在不同的磁碟位置。Inode 包含一個檔案區塊指標清單,指向檔案資料的磁碟位置。當我們存取本機檔案時,我們先擷取 inode 中的 metadata。然後我們透過跟隨檔案區塊指標到實際磁碟位置來讀取檔案資料。
物件儲存的運作方式類似。Inode 變成儲存所有物件 metadata 的 metadata 儲存。硬碟變成儲存物件資料的資料儲存。在 UNIX 檔案系統中,inode 使用檔案區塊指標記錄資料在硬碟上的位置。在物件儲存中,metadata 儲存使用物件的 ID,透過網路請求在資料儲存中找到對應的物件資料。圖 2 顯示 UNIX 檔案系統與物件儲存。

分離 metadata 與物件資料簡化了設計。資料儲存包含不可變資料,而 metadata 儲存包含可變資料。這種分離讓我們能夠獨立實作與最佳化這兩個元件。
圖 3 顯示 bucket 與 object 看起來像什麼。

高層級設計#
圖 4 顯示高層級設計。

讓我們逐一檢視元件。
- 負載平衡器(Load balancer):將 RESTful API 請求分配到多個 API 伺服器。
- API 服務:協調對身分與存取管理服務、metadata 服務與儲存的遠端程序呼叫。此服務無狀態,因此可水平擴展。
- 身分與存取管理(Identity and access management,IAM):處理認證、授權與存取控制的中心。認證驗證你是誰,授權驗證根據你是誰能執行哪些操作。
- 資料儲存:儲存與擷取實際資料。所有與資料相關的操作都基於物件 ID(UUID)。
- Metadata 儲存:儲存物件的 metadata。
請注意,metadata 與資料儲存只是邏輯元件,有不同的實作方式。例如,在 Ceph 的 Rados Gateway [11] 中,沒有獨立的 metadata 儲存。包括 object bucket 在內的一切都被持久化為一個或多個 Rados 物件。
現在我們對高層級設計有了基本理解,讓我們探索物件儲存中一些最重要的工作流程。
- 上傳物件。
- 下載物件。
- 物件版本控管與列出 bucket 中的物件。它們會在「深入探討」段落中說明。
上傳物件#

物件必須位於 bucket 中。在此範例中,我們先建立一個名為「bucket-to-share」的 bucket,然後上傳一個名為「script.txt」的檔案到該 bucket。圖 5 解釋此流程如何在 7 個步驟中運作。
- 客戶端發送 HTTP PUT 請求建立名為「bucket-to-share」的 bucket。請求轉送到 API 服務。
- API 服務呼叫 IAM 確保使用者已授權且擁有 WRITE 權限。
- API 服務呼叫 metadata 儲存在 metadata 資料庫中建立含 bucket 資訊的條目。一旦條目建立,成功訊息會回傳給客戶端。
- Bucket 建立後,客戶端發送 HTTP PUT 請求建立名為「script.txt」的物件。
- API 服務驗證使用者身分並確保使用者擁有該 bucket 的 WRITE 權限。
- 一旦驗證成功,API 服務將 HTTP PUT payload 中的物件資料發送到資料儲存。資料儲存將 payload 持久化為物件並回傳該物件的 UUID。
- API 服務呼叫 metadata 儲存在 metadata 資料庫中建立新條目。它包含重要的 metadata,例如 object_id(UUID)、bucket_id(物件屬於哪個 bucket)、object_name 等。範例條目顯示在表 2。
| object_name | object_id | bucket_id |
|---|---|---|
| script.txt | 239D5866-0052-00F6-014E-C914E61ED42B | 82AA1B2E-F599-4590-B5E4-1F51AAE5F7E4 |
表 2 範例條目
上傳物件的 API 看起來像這樣:
Listing 2 上傳物件
下載物件#
Bucket 沒有目錄階層。然而,我們可以透過串接 bucket 名稱與物件名稱來建立邏輯階層以模擬資料夾結構。例如,我們將物件命名為「bucket-to-share/script.txt」而非「script.txt」。要取得物件,我們在 GET 請求中指定物件名稱。下載物件的 API 看起來像這樣:
Listing 3 下載物件

如先前所述,資料儲存不儲存物件名稱,且只透過 object_id(UUID)支援物件操作。為了下載物件,我們先將物件名稱對應到 UUID。下載物件的工作流程如下:
- 客戶端發送 HTTP GET 請求到負載平衡器:GET /bucket-to-share/script.txt
- API 服務查詢 IAM 驗證使用者擁有該 bucket 的 READ 存取權。
- 一旦驗證通過,API 服務從 metadata 儲存擷取對應物件的 UUID。
- 接下來,API 服務透過物件的 UUID 從資料儲存擷取物件資料。
- API 服務在 HTTP GET 回應中將物件資料回傳給客戶端。
Step 3 - 設計深入探討#
在本節中,我們深入探討幾個領域:
- 資料儲存
- Metadata 資料模型
- 列出 bucket 中的物件
- 物件版本控管
- 大型檔案上傳的最佳化
- 垃圾回收
資料儲存#
讓我們仔細看看資料儲存的設計。如先前所討論,API 服務處理來自使用者的外部請求並呼叫不同的內部服務以完成這些請求。為了持久化或擷取物件,API 服務呼叫資料儲存。圖 7 顯示 API 服務與資料儲存之間在上傳與下載物件時的互動。

資料儲存的高層級設計#
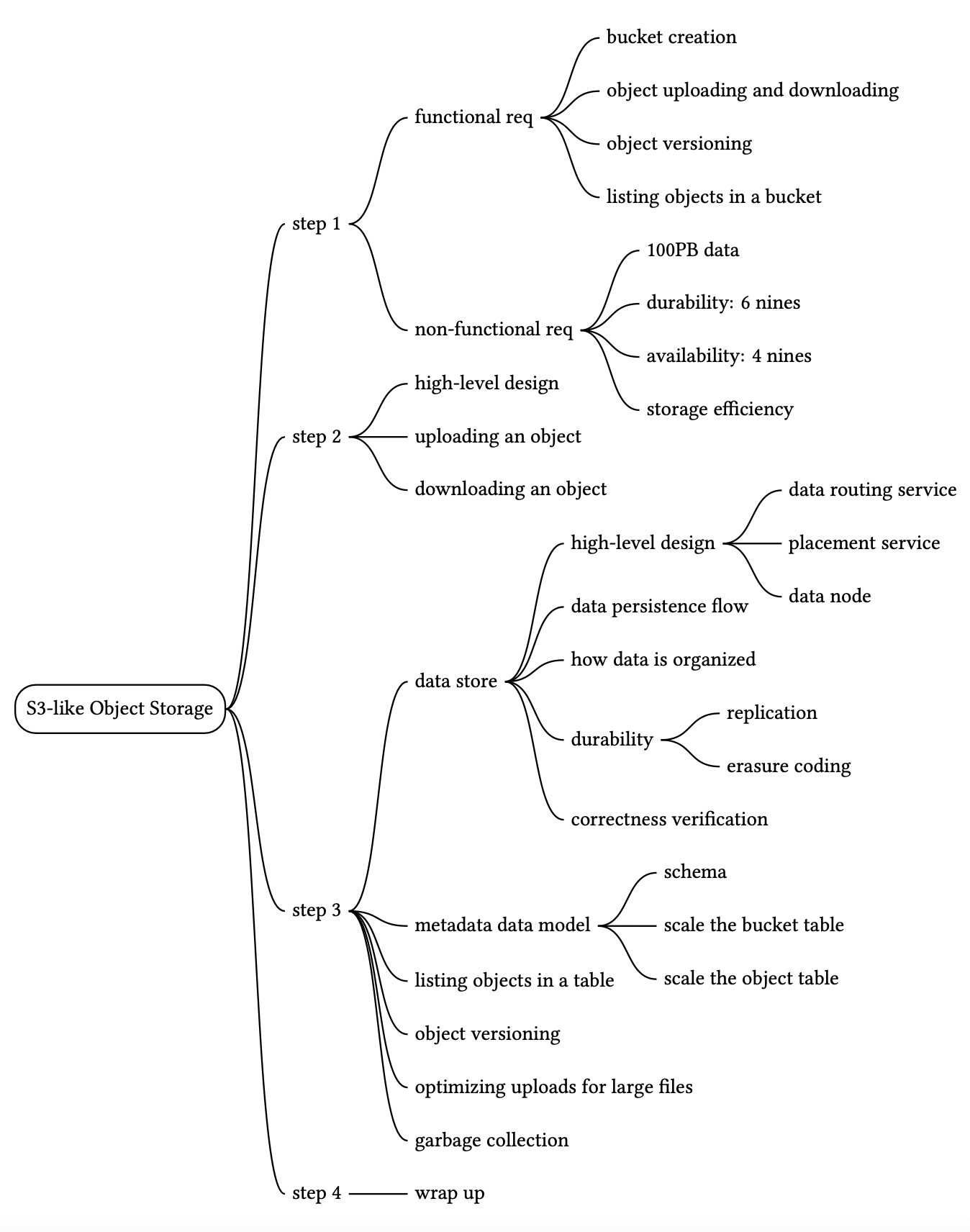
資料儲存有三個主要元件,如圖 8 所示。
資料路由服務(Data routing service)
資料路由服務提供 RESTful 或 gRPC [12] API 來存取資料節點叢集。它是無狀態服務,可透過增加更多伺服器來擴展。此服務有以下職責:
- 查詢放置服務(placement service)以取得儲存資料的最佳資料節點。
- 從資料節點讀取資料並回傳給 API 服務。
- 將資料寫入資料節點。
放置服務(Placement service)
放置服務決定應選擇哪些資料節點(主節點與副本)來儲存物件。它維護一個虛擬叢集地圖(virtual cluster map),提供叢集的實體拓撲。虛擬叢集地圖包含每個資料節點的位置資訊,放置服務使用該資訊確保副本實體上分離。這種分離是高耐久性的關鍵。詳細請見下方「耐久性」段落。圖 9 顯示虛擬叢集地圖的範例。

放置服務透過心跳持續監控所有資料節點。如果資料節點在可設定的 15 秒寬限期內未發送心跳,放置服務會在虛擬叢集地圖中將該節點標記為「下線」。
這是個關鍵服務,所以我們建議使用 Paxos [13] 或 Raft [14] 共識協定建立 5 或 7 個節點的放置服務叢集。共識協定確保只要超過半數節點健康,整個服務就能繼續運作。例如,如果放置服務叢集有 7 個節點,它可以容忍 3 個節點故障。要了解更多關於共識協定的內容,請參閱參考資料 [13] [14]。
資料節點(Data node)
資料節點儲存實際的物件資料。它透過將資料複寫到多個資料節點(也稱為複寫群組)來確保可靠性與耐久性。
每個資料節點上都有一個資料服務 daemon 在運行。資料服務 daemon 持續向放置服務發送心跳。心跳訊息包含以下基本資訊:
- 資料節點管理多少個磁碟(HDD 或 SSD)?
- 每個磁碟上儲存多少資料?
當放置服務首次接收到心跳時,它會為這個資料節點分配一個 ID,將其新增到虛擬叢集地圖,並回傳以下資訊:
- 資料節點的唯一 ID
- 虛擬叢集地圖
- 資料應複寫到何處
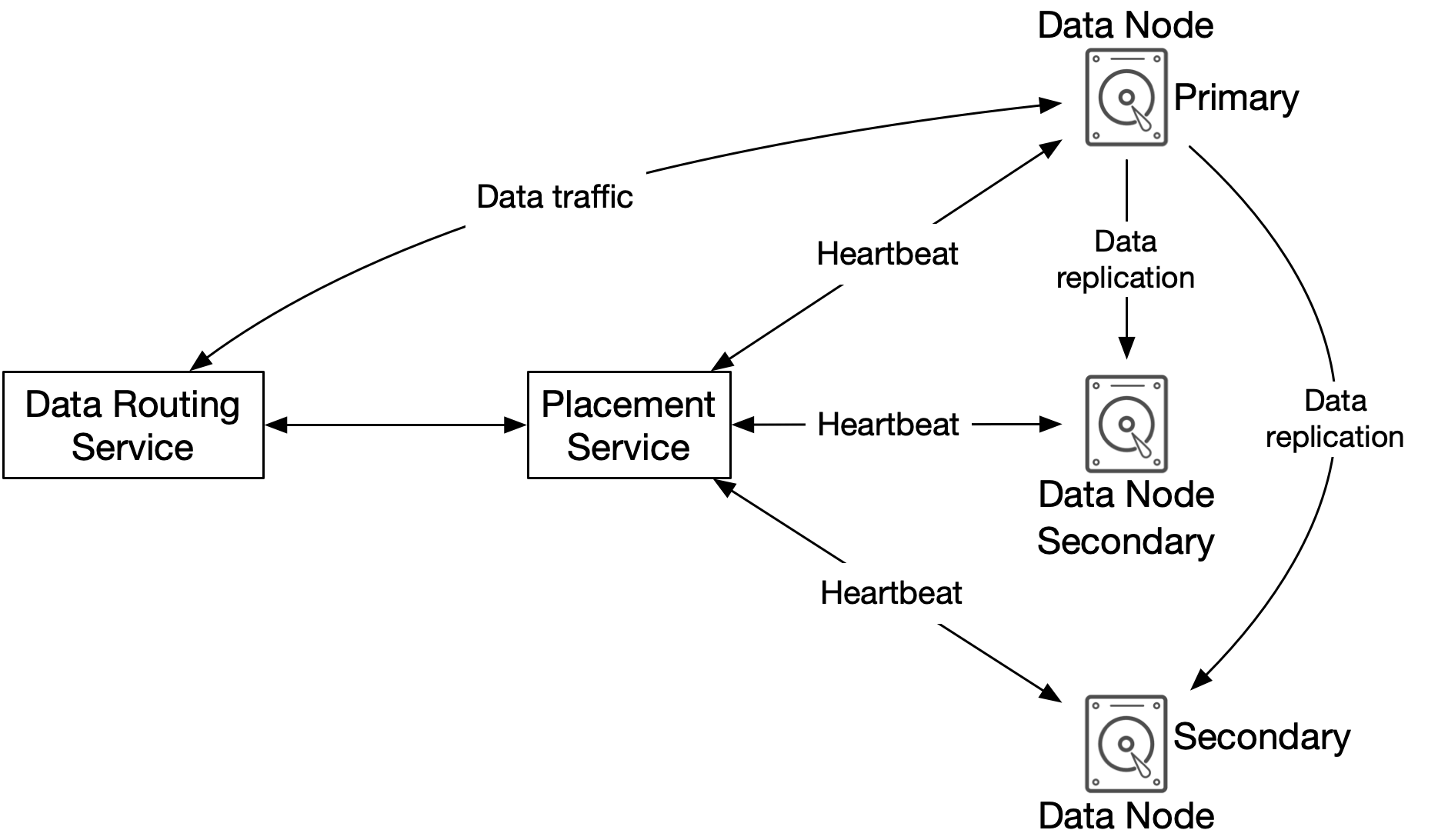
資料持久化流程#
現在讓我們看看資料如何在資料節點中持久化。
- API 服務將物件資料轉送到資料儲存。
- 資料路由服務為此物件產生 UUID,並查詢放置服務以取得儲存此物件的資料節點。放置服務檢查虛擬叢集地圖並回傳主資料節點。
- 資料路由服務直接將資料連同其 UUID 發送到主資料節點。
- 主資料節點將資料儲存在本機並複寫到兩個次要資料節點。當資料成功複寫到所有次要節點後,主節點回應資料路由服務。
- 物件的 UUID(ObjId)回傳給 API 服務。
在步驟 2 中,給定物件的 UUID 作為輸入,放置服務回傳該物件的複寫群組。放置服務如何做到?請記住此查詢必須是確定性的,且必須在新增或移除複寫群組後仍能運作。一致性雜湊是這類查詢函式的常見實作。請參閱 [15] 以獲得更多資訊。
在步驟 4 中,主資料節點在回傳回應之前將資料複寫到所有次要節點。這使所有資料節點之間的資料具有強一致性。這種一致性帶來延遲成本,因為我們必須等到最慢的副本完成。圖 11 顯示一致性與延遲之間的權衡。

- 資料在所有三個節點儲存資料後才被視為成功儲存。此方式有最佳的一致性但最高的延遲。
- 資料在主節點與其中一個次要節點儲存資料後即被視為成功儲存。此方式有中等的一致性與中等的延遲。
- 資料在主節點持久化後即被視為成功儲存。此方式有最差的一致性但最低的延遲。
第 2 與第 3 都是最終一致性的形式。
資料如何組織#
現在讓我們看看每個資料節點如何管理資料。一個簡單的解決方案是將每個物件儲存在獨立的檔案中。這可行,但當有許多小檔案時效能會受影響。在檔案系統上有太多小檔案會產生兩個問題。
首先,它浪費許多資料區塊。檔案系統將檔案儲存在離散的磁碟區塊中。磁碟區塊大小相同,且大小在 volume 初始化時固定。典型的區塊大小約為 4 KB。對於小於 4 KB 的檔案,它仍會消耗整個磁碟區塊。如果檔案系統包含大量小檔案,會浪費大量磁碟區塊,每個區塊只填入小檔案。
其次,它可能超出系統的 inode 容量。檔案系統將檔案的位置與其他資訊儲存在一種特殊類型的區塊中,稱為 inode。對大多數檔案系統而言,inode 數量在磁碟初始化時固定。有數百萬個小檔案時,有耗盡所有 inode 的風險。此外,作業系統並不擅長處理大量 inode,即使有積極的檔案系統 metadata 快取。
基於這些原因,將小物件儲存為個別檔案在實務上效果不佳。
為了解決這些問題,我們可以將許多小物件合併為一個較大的檔案。它在概念上的運作方式類似於 write-ahead log(WAL)。當我們儲存一個物件時,它會被附加到既有的讀寫檔案。當讀寫檔案達到其容量閾值(通常設定為數 GB)時,讀寫檔案被標記為唯讀,並建立新的讀寫檔案來接收新物件。一旦檔案被標記為唯讀,它只能服務讀取請求。圖 12 解釋此程序如何運作。

請注意,對讀寫檔案的寫入存取必須序列化。如圖 12 所示,物件依序儲存在讀寫檔案中,一個接一個。為了維持這種磁碟版面,平行處理進來寫入請求的多個核心必須輪流寫入讀寫檔案。對於有大量核心並行處理大量進來請求的現代伺服器,這嚴重限制了寫入吞吐量。為了修復這個問題,我們可以提供專屬的讀寫檔案,每個處理進來請求的核心一個。
物件查詢#
每個資料檔案包含許多小物件,資料節點如何透過 UUID 定位物件?資料節點需要以下資訊:
- 包含該物件的資料檔案
- 物件在資料檔案中的起始偏移量
- 物件的大小
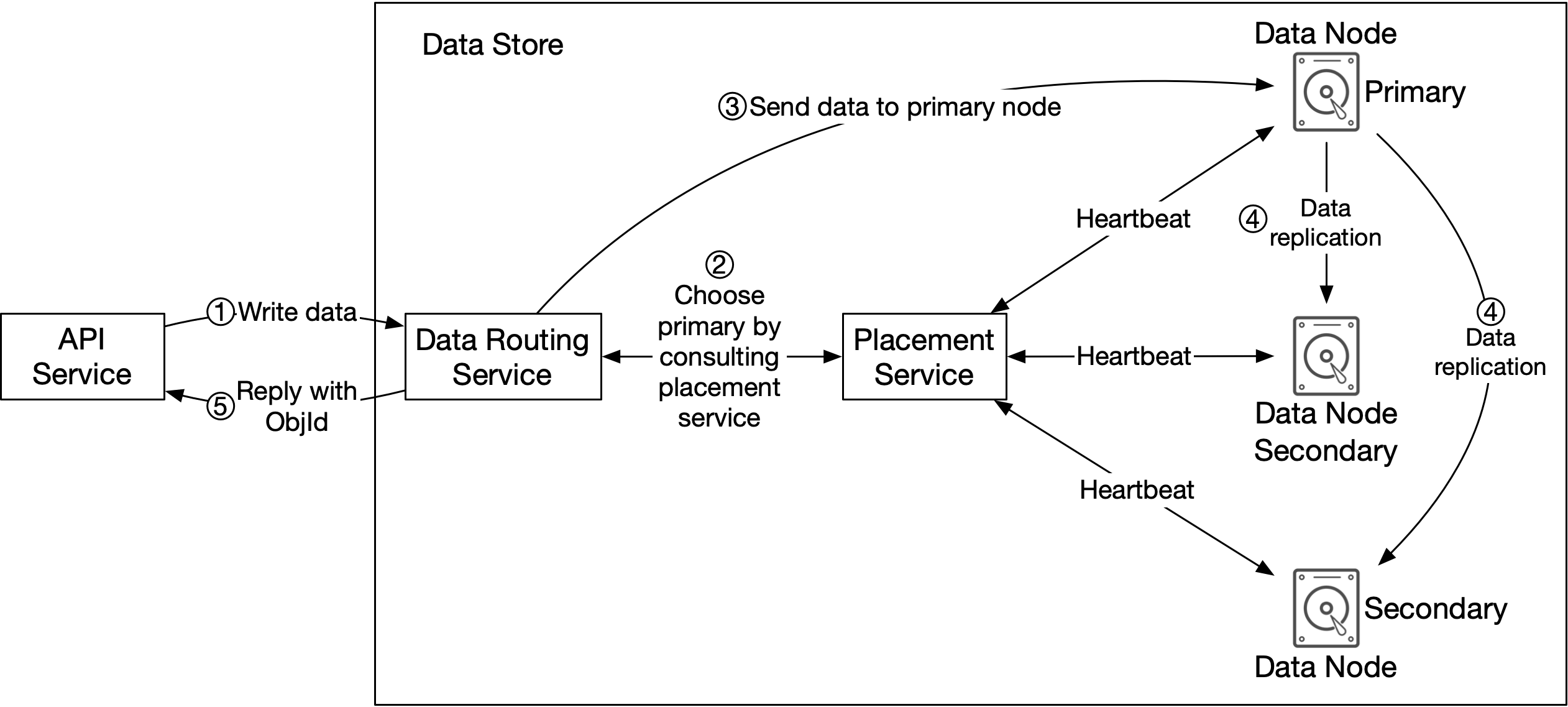
支援此查詢的資料庫綱要顯示在表 3。
| 欄位 | 描述 |
|---|---|
| object_id | 物件的 UUID |
| file_name | 包含該物件的檔案名稱 |
| start_offset | 物件在檔案中的起始位址 |
| object_size | 物件的位元組數 |
表 4 Object_mapping 欄位
我們考慮了兩種儲存此對應的選項:基於檔案的鍵值儲存(如 RocksDB [16])或關聯式資料庫。RocksDB 基於 SSTable [17],寫入快但讀取較慢。關聯式資料庫通常使用基於 B+ tree [18] 的儲存引擎,讀取快但寫入較慢。如先前所述,資料存取模式是寫入一次,讀取多次。由於關聯式資料庫提供更好的讀取效能,它比 RocksDB 更適合。
我們應如何部署此關聯式資料庫?以我們的規模而言,對應表的資料量很龐大。部署一個大叢集來支援所有資料節點可能可行,但難以管理。請注意,這份對應資料在每個資料節點內是隔離的。沒必要跨資料節點共享。為了利用此特性,我們可以簡單地在每個資料節點上部署一個簡單的關聯式資料庫。SQLite [19] 在此是個不錯的選擇。它是基於檔案的關聯式資料庫,有著良好聲譽。
更新後的資料持久化流程#
由於我們對資料節點做了不少變更,讓我們重新檢視如何在資料節點中儲存新物件(圖 13)。
- API 服務發送請求儲存名為「object 4」的新物件。
- 資料節點服務將名為「object 4」的物件附加到名為「/data/c」的讀寫檔案結尾。
- 在 object_mapping 表中插入一筆新的「object 4」記錄。
- 資料節點服務將 UUID 回傳給 API 服務。

耐久性#
資料可靠性對資料儲存系統極其重要。我們如何建立提供 6 個 9 耐久性的儲存系統?每個故障案例都必須仔細考慮,且資料必須適當複寫。
硬體故障與故障域#
無論我們使用哪種媒介,硬碟故障都不可避免。某些儲存媒介可能比其他媒介有更好的耐久性,但我們無法依賴單一硬碟達到耐久性目標。提升耐久性的有效方法是將資料複寫到多個硬碟,這樣單一磁碟故障不會影響整體資料可用性。在我們的設計中,我們將資料複寫三次。
讓我們假設旋轉式硬碟的年故障率為 0.81% [20]。這個數字高度取決於型號與廠牌。製作 3 份資料副本給我們 1-(0.0081)^3=~0.999999 的可靠性。這是非常粗略的估計。如需更複雜的計算,請閱讀 [20]。
為了進行完整的耐久性評估,我們也需要考慮不同故障域的影響。故障域是環境中的實體或邏輯區段,當關鍵服務遇到問題時會受到負面影響。在現代資料中心,伺服器通常放在機架(rack)中 [21],機架被分組到列/樓層/房間。由於每個機架共享網路交換器與電源,機架中所有伺服器都在機架層級故障域中。現代伺服器共享主機板、處理器、電源、HDD 等元件。伺服器中的元件在節點層級故障域中。
這裡有個大規模故障域隔離的好範例。通常,資料中心將不共享任何東西的基礎設施分割到不同的可用性區域(Availability Zones,AZs)。我們將資料複寫到不同的 AZ 以最小化故障影響(圖 14)。請注意,故障域層級的選擇並未直接增加資料的耐久性,但會在大規模停電、冷卻系統故障、自然災害等極端情況下帶來更好的可靠性。

Erasure coding#
製作三份完整的資料副本給我們大約 6 個 9 的資料耐久性。是否還有其他選項可進一步增加耐久性?是的,erasure coding 是個選項。Erasure coding [22] 以不同的方式處理資料耐久性。它將資料切成更小的片段(放在不同的伺服器上)並建立 parity(校驗)以提供冗餘。在故障的事件中,我們可以使用 chunk data 與 parities 重建資料。讓我們看一個具體範例(4 + 2 erasure coding),如圖 15 所示。

- 資料被分成四個大小相等的資料 chunk d1、d2、d3 與 d4。
- 數學公式 [23] 用來計算 parities p1 與 p2。給個簡化的範例,p1 = d1 + 2d2 - d3 + 4d4 且 p2 = -d1 + 5d2 + d3 - 3d4 [24]。
- 由於節點當機,資料 d3 與 d4 遺失。
- 數學公式用來重建遺失的資料 d3 與 d4,使用 d1、d2、p1 與 p2 的已知值。
讓我們看另一個範例(圖 16)以更好地了解 erasure coding 與故障域如何運作。一個 (8+4) erasure coding 設定將原始資料平均分成 8 個 chunk,並計算 4 個 parity。所有 12 片資料大小相同。所有 12 個 chunk 分佈在 12 個不同的故障域。Erasure coding 背後的數學確保當最多 4 個節點下線時,原始資料仍可重建。

相較於複寫只需資料路由器從一個健康節點讀取物件資料,在 erasure coding 中資料路由器必須從至少 8 個健康節點讀取資料。這是個架構設計上的權衡。我們使用較複雜的解決方案以較慢的存取速度,換取更高的耐久性與更低的儲存成本。對於主要成本是儲存的物件儲存而言,這個權衡可能是值得的。
Erasure coding 需要多少額外空間?對每兩個資料 chunk,我們需要一個 parity block,所以儲存開銷為 50%(圖 17)。而在 3 副本複寫中,儲存開銷為 200%(圖 17)。

Erasure coding 是否增加資料耐久性?讓我們假設一個節點的年故障率為 0.81%。根據 Backblaze 的計算 [20],erasure coding 可達到 11 個 9 的耐久性。計算需要複雜的數學。如果你感興趣,請參閱 [20] 取得詳細資訊。
表 5 比較複寫與 erasure coding 的優缺點。
| **** | 複寫 | Erasure coding |
|---|---|---|
| 耐久性 | 6 個 9 的耐久性(資料複製 3 次) | 11 個 9 的耐久性(8+4 erasure coding)。Erasure coding 勝。 |
| 儲存效率 | 200% 儲存開銷。 | 50% 儲存開銷。Erasure coding 勝。 |
| 計算資源 | 不需要計算。複寫勝。 | 計算 parity 需要更高的計算資源使用。 |
| 寫入效能 | 將資料複寫到多個節點。不需要計算。 | |
| 複寫勝。 | 寫入延遲增加,因為需要在資料寫入磁碟前計算 parity。 | |
| 讀取效能 | 在正常運作下,讀取從同一副本服務。故障模式下的讀取 | |
| 不受影響,因為讀取可從非故障副本服務。複寫勝。 | 在正常運作下,每個讀取必須來自叢集中的多個節點。故障模式下的讀取 | |
| 較慢,因為遺失的資料必須先重建。 |
表 5 複寫 vs erasure coding
總結來說,複寫廣泛用於延遲敏感的應用,而 erasure coding 通常用於最小化儲存成本。Erasure coding 因其成本效率與耐久性而具吸引力,但它大幅增加了資料節點設計的複雜度。因此,本設計中,我們主要專注於複寫。
正確性驗證#
Erasure coding 在相當的儲存成本下增加資料耐久性。現在我們可以繼續解決另一個困難的挑戰:資料損毀。
如果磁碟完全故障且故障可被偵測,可被視為資料節點故障。在此情況下,我們可以使用 erasure coding 重建資料。然而,記憶體中的資料損毀在大規模系統中是常見的事件。
此問題可透過在程序邊界之間驗證 checksum [25] 來處理。Checksum 是用來偵測資料錯誤的小型資料塊。圖 18 說明 checksum 如何產生。

如果我們知道原始資料的 checksum,我們可以計算傳輸後資料的 checksum:
- 如果它們不同,資料已損毀。
- 如果它們相同,資料未損毀的機率非常高。機率不是 100%,但實務上我們可以假設它們相同。

有許多 checksum 演算法,例如 MD5 [26]、SHA1 [27]、HMAC [28] 等。一個好的 checksum 演算法即使對輸入做很小的變更也會輸出顯著不同的值。本章中,我們選擇簡單的 checksum 演算法如 MD5。
在我們的設計中,我們在每個物件結尾附加 checksum。在檔案被標記為唯讀之前,我們在結尾新增整個檔案的 checksum。圖 20 顯示版面。

有了 (8+4) erasure coding 與 checksum 驗證,當我們讀取資料時會發生以下情況:
擷取物件資料與 checksum。
對接收到的資料計算 checksum。
(a) 如果兩個 checksum 相符,資料無錯誤。
(b) 如果 checksum 不同,資料已損毀。我們會嘗試從其他故障域讀取資料以復原。
重複步驟 1 與 2 直到所有 8 片資料都被回傳。然後我們重建資料並回傳給客戶端。
Metadata 資料模型#
本節中,我們先討論資料庫綱要,然後深入擴展資料庫。
綱要#
資料庫綱要需要支援以下 3 個查詢:
- Query 1:依物件名稱查詢物件 ID。
- Query 2:依物件名稱插入與刪除物件。
- Query 3:列出 bucket 中共享相同前綴的物件。
圖 21 顯示綱要設計。我們需要兩個資料庫表:bucket 與 object。
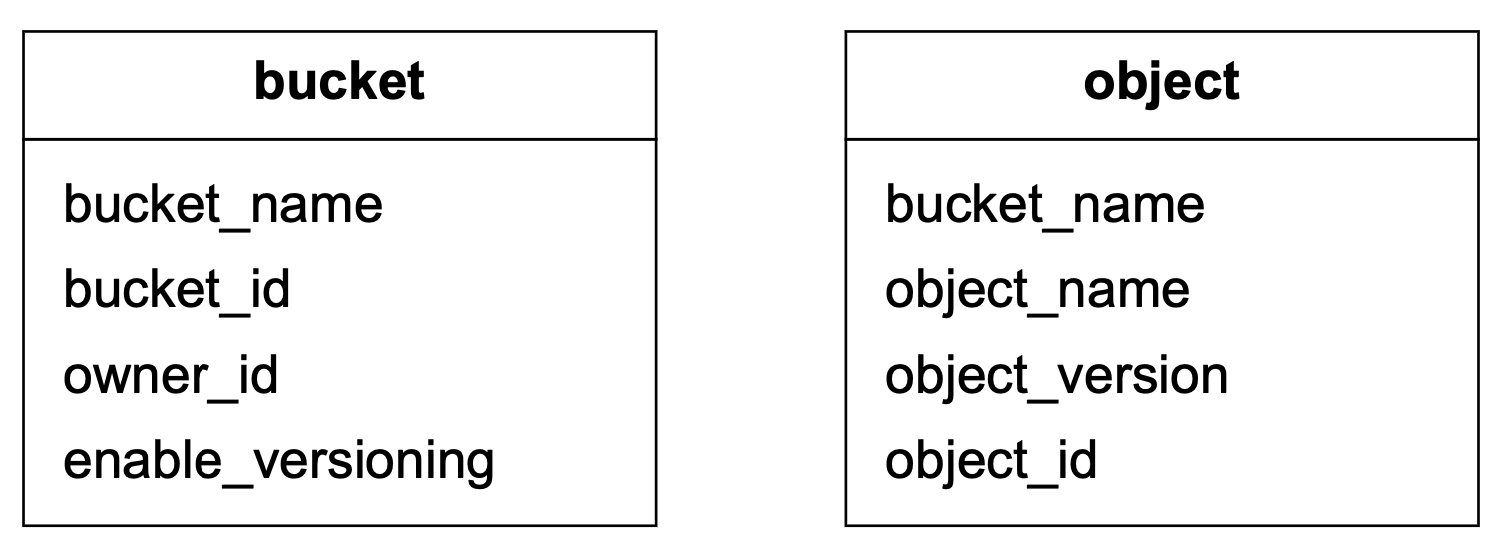
擴展 bucket 表#
由於通常會限制使用者可建立的 bucket 數量,bucket 表的大小很小。讓我們假設我們有 100 萬客戶,每位客戶擁有 10 個 bucket,每筆記錄佔 1 KB。也就是說我們需要 10 GB(100 萬 _ 10 _ 1 KB)的儲存空間。整個表可以輕鬆放入現代資料庫伺服器。然而,單一資料庫伺服器可能沒有足夠的 CPU 或網路頻寬處理所有讀取請求。如果是這樣,我們可以將讀取負載分散到多個資料庫副本上。
擴展 object 表#
Object 表保存物件 metadata。我們設計規模下的資料集很可能無法放入單一資料庫實例中。我們可以透過分片擴展 object 表。
一個選項是依 bucket_id 分片,使同一 bucket 下的所有物件儲存在一個 shard 中。這不可行,因為它會造成熱點 shard,因為一個 bucket 可能包含數十億個物件。
另一個選項是依 object_id 分片。此分片方案的好處是它均勻分配負載。但我們無法有效執行 query 1 與 query 2,因為這兩個查詢是基於 URI 的。
我們選擇依 bucket_name 與 object_name 的組合分片。這是因為大多數 metadata 操作是基於物件 URI,例如透過 URI 找到物件 ID 或透過 URI 上傳物件。為了均勻分佈資料,我們可以使用 (bucket_name, object_name) 的雜湊作為分片鍵。
使用此分片方案,支援前兩個查詢很簡單,但最後一個查詢就比較不明顯了。讓我們看看。
列出 bucket 中的物件#
物件儲存以扁平結構排列檔案而非檔案系統中的階層。物件可以使用此格式的路徑存取:s3://bucket-name/object-name。例如 s3://mybucket/abc/d/e/f/file.txt 包含:
- Bucket 名稱:mybucket
- 物件名稱:abc/d/e/f/file.txt
為了協助使用者組織 bucket 中的物件,S3 引入了「prefixes」的概念。Prefix 是物件名稱開頭的字串。S3 使用 prefix 以類似目錄的方式組織資料。然而,prefix 不是目錄。依 prefix 列出 bucket 會將結果限制為僅以該 prefix 開頭的物件名稱。
在上面以路徑 s3://mybucket/abc/d/e/f/file.txt 為例的範例中,prefix 為 abc/d/e/f/。
AWS S3 列出指令有 3 種典型用法:
列出使用者擁有的所有 bucket。指令看起來像這樣:
aws s3 list-buckets列出 bucket 中與指定 prefix 在同一層級的所有物件。指令看起來像這樣:
aws s3 ls s3://mybucket/abc/在此模式下,名稱中在 prefix 後有更多斜線的物件會被滾入共同前綴。例如,bucket 中有以下物件:
CA/cities/losangeles.txt CA/cities/sanfrancisco.txt NY/cities/ny.txt federal.txt以「/」prefix 列出 bucket 會回傳這些結果,CA/ 與 NY/ 下的所有東西都被滾入它們:
CA/ NY/ federal.txt
遞迴列出 bucket 中共享相同 prefix 的所有物件。指令看起來像這樣:
aws s3 ls s3://mybucket/abc/ --recursive使用上述相同範例,以
CA/prefix 列出 bucket 會回傳這些結果:CA/cities/losangeles.txt CA/cities/sanfrancisco.txt
單一資料庫#
讓我們先探討如何使用單一資料庫支援列出指令。要列出使用者擁有的所有 bucket,我們執行以下查詢:
SELECT * FROM bucket WHERE owner_id={id}要列出 bucket 中共享相同 prefix 的所有物件,我們執行如下查詢:
SELECT * FROM object WHERE bucket_id = "123" AND object_name LIKE `abc/%`在此範例中,我們找到 bucket_id 等於「123」且共享 prefix「abc/」的所有物件。如使用情境 2 先前所述,名稱中在指定 prefix 後有更多斜線的物件會在應用程式碼中被滾入。
相同查詢會支援使用情境 3 先前所述的遞迴列出模式。應用程式碼會列出共享相同 prefix 的每個物件,不執行任何滾入。
分散式資料庫#
當 metadata 表被分片時,實作列出功能很困難,因為我們不知道哪些 shard 包含資料。最明顯的解決方案是在所有 shard 上執行搜尋查詢,然後彙整結果。為了達成這一點,我們可以做以下事情:
Metadata 服務透過執行以下查詢查詢每個 shard:
SELECT * FROM object WHERE bucket_id = "123" AND object_name LIKE `a/b/%`Metadata 服務將從每個 shard 回傳的所有物件彙整,並將結果回傳給呼叫方。
此解決方案可運作,但實作分頁有點複雜。在我們解釋為什麼之前,先回顧分頁如何在單一資料庫的簡單情況下運作。要回傳每頁含 10 個物件的列出頁面,SELECT 查詢會以這個開始:
SELECT * FROM object WHERE
bucket_id = "123" AND object_name LIKE `a/b/%`
ORDER BY object_name OFFSET 0 LIMIT 10OFFSET 與 LIMIT 會將結果限制為前 10 個物件。在下一個呼叫中,使用者向伺服器發送請求並附帶提示,使其知道為第二頁建構 OFFSET 為 10 的查詢。此提示通常透過 cursor 完成,伺服器在每頁與客戶端一起回傳該 cursor。Offset 資訊編碼在 cursor 中。客戶端會在下一頁的請求中包含該 cursor。伺服器解碼 cursor 並使用嵌入其中的 offset 資訊建構下一頁的查詢。延續上面的例子,第二頁的查詢看起來像這樣:
SELECT * FROM metadata
WHERE bucket_id = "123" AND object_name LIKE `a/b/%`
ORDER BY object_name OFFSET 10 LIMIT 10此客戶端-伺服器請求迴圈會持續,直到伺服器回傳標記整個列出結束的特殊 cursor。
現在,讓我們探討為什麼支援分片資料庫的分頁很複雜。由於物件分佈在 shard 之間,shard 很可能回傳不同數量的結果。某些 shard 會包含完整的 10 個物件頁面,而其他則可能是部分或空的。應用程式碼會接收每個 shard 的結果,彙整與排序它們,並只回傳我們範例中的 10 個一頁。未包含在當前回合的物件必須在下一回合再次被考慮。這意味著每個 shard 很可能會有不同的 offset。伺服器必須追蹤所有 shard 的 offset 並將那些 offset 與 cursor 關聯。如果有數百個 shard,就會有數百個 offset 需要追蹤。
我們有一個可以解決問題的解決方案,但有些權衡。由於物件儲存針對巨大規模與高耐久性最佳化,物件列出效能很少是優先考量。事實上,所有商業物件儲存都以次優的效能支援物件列出。為了利用這一點,我們可以將列出資料反正規化到一個依 bucket ID 分片的獨立表。此表只用於列出物件。有了這個設置,即使有數十億個物件的 bucket 也能提供可接受的效能。這將列出查詢隔離到單一資料庫,大幅簡化實作。
物件版本控管#
版本控管是在 bucket 中保留物件多個版本的功能。有了版本控管,我們可以復原意外刪除或覆寫的物件。例如,我們可能會修改文件並以相同名稱儲存在相同的 bucket 中。沒有版本控管時,舊版本的文件 metadata 在 metadata 儲存中被新版本取代。舊版本的文件被標記為已刪除,所以其儲存空間將被垃圾回收器回收。有版本控管時,物件儲存會在 metadata 儲存中保留所有先前版本的文件,舊版本的文件在物件儲存中永遠不會被標記為已刪除。
圖 22 解釋如何上傳版本化物件。為了讓這可運作,我們首先需要在 bucket 上啟用版本控管。

- 客戶端發送 HTTP PUT 請求上傳名為「script.txt」的物件。
- API 服務驗證使用者的身分並確保使用者擁有 bucket 的 WRITE 權限。
- 一旦驗證通過,API 服務將資料上傳到資料儲存。資料儲存將資料持久化為新物件並回傳新的 UUID 給 API 服務。
- API 服務呼叫 metadata 儲存以儲存此物件的 metadata 資訊。
- 為了支援版本控管,metadata 儲存的 object 表有一個名為 object_version 的欄位,僅在啟用版本控管時使用。新記錄會以與舊記錄相同的 bucket_id 與 object_name 插入,而非覆寫既有記錄,但有新的 object_id 與 object_version。Object_id 是步驟 3 回傳的新物件的 UUID。Object_version 是新行插入時產生的 TIMEUUID [29]。無論我們為 metadata 儲存選擇哪種資料庫,查詢物件目前版本應該是高效的。目前版本是與相同 object_name 的所有條目中具有最大 TIMEUUID 的那個。請參閱圖 23 以了解我們如何儲存版本化 metadata 的說明。

除了上傳版本化物件外,它也可以被刪除。讓我們看看。
當我們刪除一個物件時,所有版本仍保留在 bucket 中,我們插入一個刪除標記,如圖 24 所示。

刪除標記是物件的新版本,一旦插入即成為物件的目前版本。當物件的目前版本是刪除標記時執行 GET 請求會回傳 404 Object Not Found 錯誤。
大型檔案上傳的最佳化#
在粗略估算中,我們估計 20% 的物件是大型物件。某些可能大於數 GB。直接上傳這麼大的物件檔案是可能的,但可能花費很長時間。如果網路連線在上傳途中失敗,我們必須從頭開始。更好的解決方案是將大型物件切片成較小的部分,並獨立上傳。所有部分上傳完後,物件儲存從這些部分重新組裝物件。此過程稱為多部分上傳(multipart upload)。
圖 25 說明多部分上傳如何運作:

- 客戶端呼叫物件儲存以發起多部分上傳。
- 資料儲存回傳一個 uploadID,唯一識別此上傳。
- 客戶端將大檔案分割為小物件並開始上傳。讓我們假設檔案大小為 1.6 GB,客戶端將其分割為 8 部分,所以每部分為 200 MB。客戶端將第一部分連同步驟 2 中收到的 uploadID 上傳到資料儲存。
- 當部分上傳完成後,資料儲存回傳一個 ETag,本質上是該部分的 md5 checksum。它用於驗證多部分上傳。
- 所有部分上傳完成後,客戶端發送一個完成多部分上傳的請求,包括 uploadID、part numbers 與 ETags。
- 資料儲存根據 part number 從其部分重新組裝物件。由於物件真的很大,此過程可能需要幾分鐘。重新組裝完成後,它回傳成功訊息給客戶端。
此方式的一個潛在問題是物件從這些部分重新組裝後,舊部分就不再有用。為了解決此問題,我們可以引入垃圾回收服務,負責從不再需要的部分釋放空間。
垃圾回收#
垃圾回收是自動回收不再使用的儲存空間的過程。有幾種方式資料可能變成垃圾:
- 延遲物件刪除:物件在刪除時被標記為已刪除,但實際上未被刪除。
- 孤兒資料(Orphan data):例如,半上傳的資料或被遺棄的多部分上傳。
- 損毀的資料:未通過 checksum 驗證的資料。
垃圾回收器不會立即從資料儲存移除物件。已刪除的物件會透過壓縮機制定期清理。
垃圾回收器也負責回收副本中的未使用空間。對於複寫,我們從主節點與備份節點都刪除物件。對於 erasure coding,如果我們使用 (8+4) 設定,我們會從所有 12 個節點刪除物件。
圖 26 顯示壓縮如何運作的範例。
- 垃圾回收器將物件從「/data/b」複製到名為「/data/d」的新檔案。請注意垃圾回收器跳過「Object 2」與「Object 5」,因為它們的 delete flag 設為 true。
- 所有物件複製完成後,垃圾回收器更新 object_mapping 表。例如,「Object 3」的 obj_id 與 object_size 欄位保持不變,但 file_name 與 start_offset 更新以反映其新位置。為了確保資料一致性,將更新 file_name 與 start_offset 的操作包裝在資料庫交易中是個好主意。

如圖 26 所示,壓縮後新檔案的大小比舊檔案小。為了避免建立大量小檔案,垃圾回收器通常會等到有大量唯讀檔案才壓縮,且壓縮過程會將許多唯讀檔案的物件附加到少數幾個大型新檔案中。
Step 4 - 總結#
本章中,我們描述了類似 S3 的物件儲存的高層級設計。我們比較了區塊儲存、檔案儲存與物件儲存之間的差異。
本次面試的重點在物件儲存的設計上,所以我們列出了在物件儲存中通常如何完成上傳、下載、列出 bucket 中的物件與物件版本控管。
然後我們深入設計。物件儲存由資料儲存與 metadata 儲存組成。我們解釋了資料如何持久化到資料儲存中,並討論了兩種增加可靠性與耐久性的方法:複寫與 erasure coding。對於 metadata 儲存,我們解釋了多部分上傳如何執行以及如何設計資料庫綱要以支援典型使用情境。最後,我們解釋了如何分片 metadata 儲存以支援更大的資料量。
恭喜你看到這裡!現在拍拍自己的背。做得好!
章節摘要#