本章我們設計一個大規模電子郵件服務,例如 Gmail、Outlook 或 Yahoo Mail。網際網路的成長導致電子郵件數量爆炸性增長。2020 年時,Gmail 全球擁有超過 18 億活躍使用者,Outlook 則擁有超過 4 億使用者 [1] [2]。

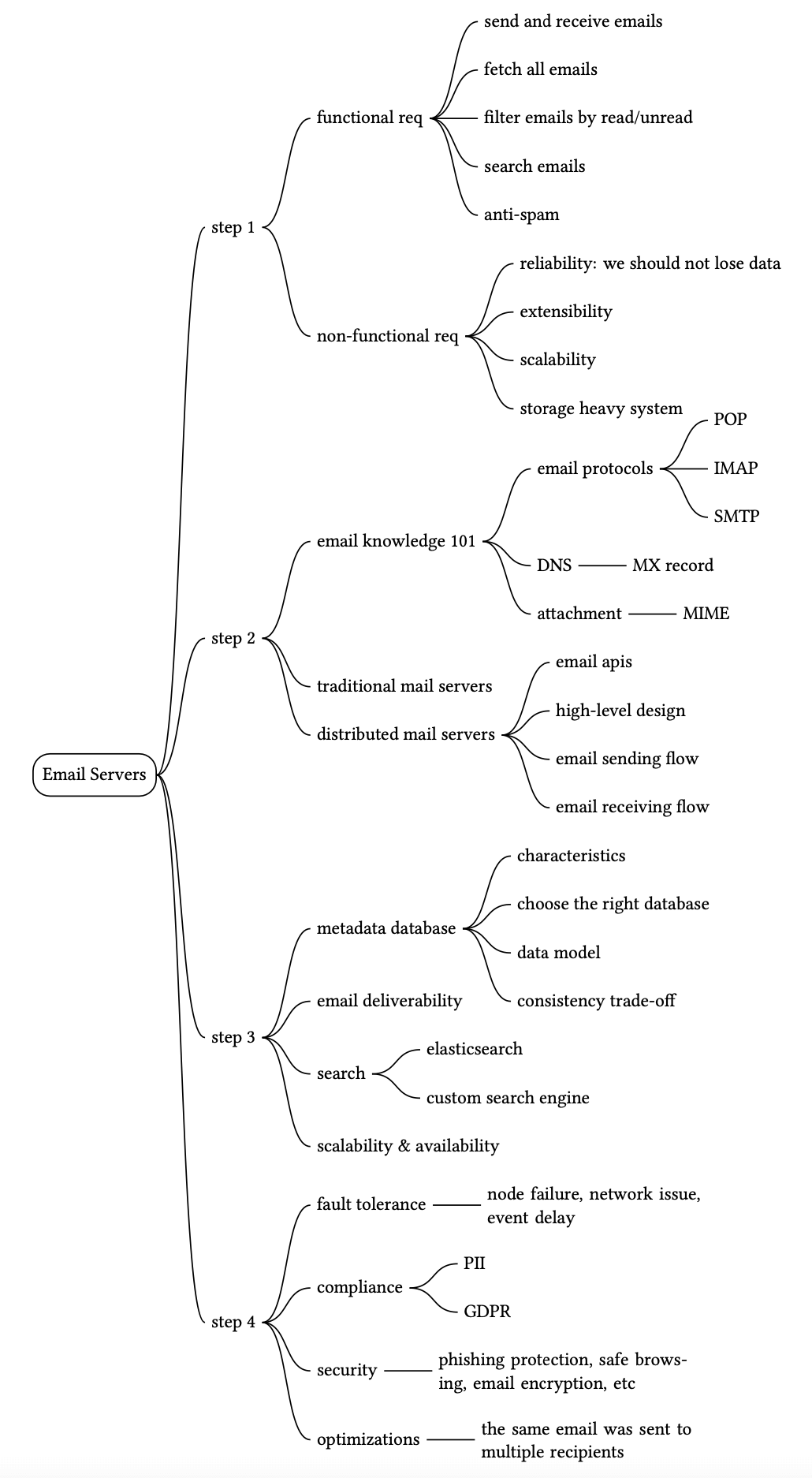
Step 1 - 理解問題並確立設計範圍#
多年來,電子郵件服務在複雜度與規模上都有顯著的變化。現代電子郵件服務是一個具備眾多功能的複雜系統。我們不可能在 45 分鐘內設計出真實世界的系統。所以在進入設計之前,我們絕對要先提出釐清問題的問題以縮小範圍。
應徵者:有多少人使用這個產品?
面試官:十億使用者。
應徵者:我認為以下功能很重要:
- 認證(Authentication)。
- 寄送與接收電子郵件。
- 取得所有電子郵件。
- 依已讀/未讀狀態篩選郵件。
- 依主旨、寄件者、內文搜尋郵件。
- 反垃圾郵件與防毒。
面試官:這份清單很好。我們不需要擔心認證。讓我們專注在你提到的其他功能。
應徵者:使用者如何與郵件伺服器連線?
面試官:傳統上,使用者透過原生客戶端透過 SMTP、POP、IMAP 與廠商特有協定連線郵件伺服器。這些協定在某種程度上算是遺留協定,但仍然非常普及。本次面試中,我們假設客戶端與伺服器之間使用 HTTP 通訊。
應徵者:郵件可以有附件嗎?
面試官:可以。
非功能性需求#
接下來,我們來看看最重要的非功能性需求。
- 可靠性(Reliability):我們不應該遺失郵件資料。
- 可用性(Availability):郵件與使用者資料應自動複寫到多個節點以確保可用性。此外,系統應在部分故障時仍能持續運作。
- 可擴展性(Scalability):隨著使用者數量成長,系統應能處理日益增加的使用者與郵件數量。系統效能不應隨更多使用者或郵件而下降。
- 彈性與可擴展性(Flexibility and extensibility):具備彈性/可擴展性的系統可讓我們透過新增元件輕鬆加入新功能或提升效能。傳統電子郵件協定如 POP 與 IMAP 功能十分有限(高層級設計中會詳述)。因此,為了滿足彈性與可擴展性需求,我們可能需要自訂協定。
粗略估算#
讓我們做個粗略計算來判斷規模並發現解決方案需要處理的挑戰。從設計上來看,電子郵件是儲存密集型應用。
- 10 億使用者。
- 假設一個人每天平均寄送 10 封郵件。寄送郵件的 QPS = 10^9 * 10 / (10^5) = 100,000。
- 假設一個人每天平均接收 40 封郵件 [3],且郵件 metadata 平均大小為 50 KB。Metadata 是指與郵件相關的所有資訊,不包含附件檔案。
- 假設 metadata 儲存在資料庫中。一年內維護 metadata 所需的儲存空間:10 億使用者 _ 40 封郵件 / 天 _ 365 天 * 50 KB = 730 PB。
- 假設 20% 的郵件包含附件,平均附件大小為 500 KB。
- 一年內附件的儲存空間為:10 億使用者 _ 40 封郵件 / 天 _ 365 天 _ 20% _ 500 KB = 1,460 PB。
從這個粗略計算中,明顯可知我們將處理大量資料。因此很可能需要分散式資料庫解決方案。
Step 2 - 提出高層級設計並取得認可#
本節中,我們先討論一些電子郵件伺服器的基礎知識以及它們如何隨時間演進。然後我們看看分散式電子郵件伺服器的高層級設計。內容結構如下:
- 電子郵件知識 101
- 傳統郵件伺服器
- 分散式郵件伺服器
電子郵件知識 101#
有各種電子郵件協定可用來寄送與接收郵件。歷史上,大多數郵件伺服器使用 POP、IMAP 與 SMTP 等電子郵件協定。
電子郵件協定#
SMTP:簡單郵件傳輸協定(Simple Mail Transfer Protocol,SMTP)是用於從一個郵件伺服器寄送郵件到另一個郵件伺服器的標準協定。
最熱門的取得郵件的協定是郵局協定(Post Office Protocol,POP)與網際網路郵件存取協定(Internet Mail Access Protocol,IMAP)。
POP 是用於從遠端郵件伺服器接收並下載郵件至本機郵件客戶端的標準郵件協定。一旦郵件下載到電腦或手機,它們就會從郵件伺服器中刪除,這意味著你只能在一台電腦或手機上存取郵件。POP 的細節在 RFC 1939 中說明 [4]。POP 要求郵件客戶端下載整封郵件。如果郵件包含大型附件,這可能需要很長時間。
IMAP 也是用於本機郵件客戶端接收郵件的標準郵件協定。當你閱讀郵件時,你連線到外部郵件伺服器,資料會傳輸到本機裝置。IMAP 只在你點擊郵件時才下載訊息,且郵件不會從郵件伺服器中刪除,也就是說你可以從多個裝置存取郵件。IMAP 是個人電子郵件帳號最廣泛使用的協定。它在連線速度慢時也能良好運作,因為在開啟之前只下載郵件標頭資訊。
HTTPS 嚴格來說不是郵件協定,但可用於存取你的信箱,特別是網頁版電子郵件。例如,Microsoft Outlook 透過 HTTPS 與行動裝置溝通是很常見的做法,使用一個名為 ActiveSync 的自訂協定 [5]。
網域名稱服務(DNS)#
DNS 伺服器用來查詢收件者網域的郵件交換器記錄(MX record)。如果你從命令列對 gmail.com 執行 DNS 查詢,可能會得到如圖 2 所示的 MX 記錄。
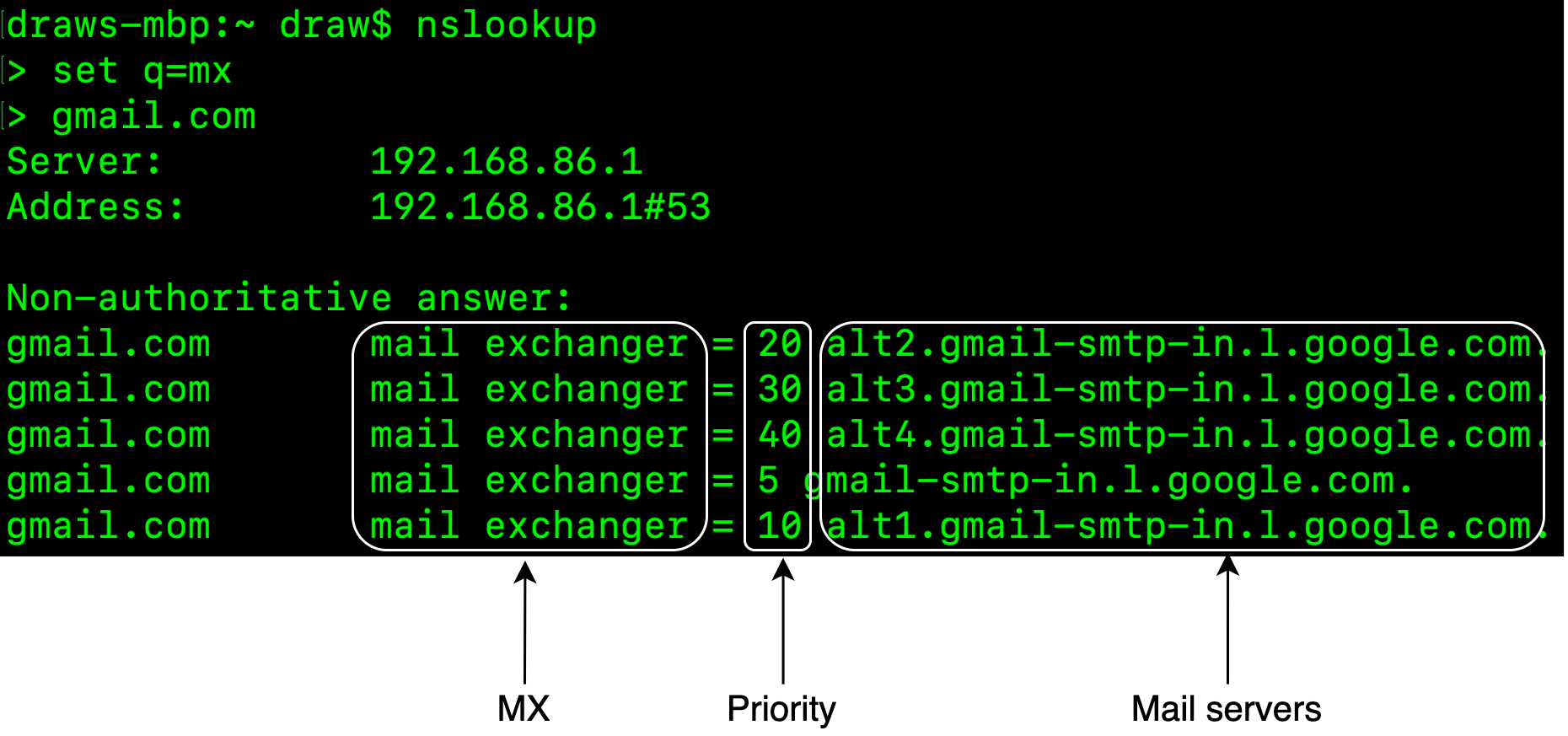
優先序數字代表偏好程度,數字越小的郵件伺服器越優先。在圖 2 中,gmail-smtp-in.l.google.com 會被首先使用(優先序 5)。寄送端郵件伺服器會先嘗試連線並寄送訊息給此郵件伺服器。如果連線失敗,寄送端郵件伺服器會嘗試連線優先序次低的郵件伺服器,也就是 alt1.gmail-smtp-in.l.google.com(優先序 10)。
附件#
電子郵件附件會與郵件訊息一同寄送,通常使用 Base64 編碼 [6]。附件通常會有大小限制。例如,截至 2021 年 6 月,Outlook 與 Gmail 分別將附件大小限制為 20 MB 與 25 MB。這個數字可高度設定,並依個人帳號或企業帳號而不同。多用途網際網路郵件擴充(Multipurpose Internet Mail Extension,MIME)[7] 是一個允許附件透過網際網路寄送的規範。
傳統郵件伺服器#
在我們深入分散式郵件伺服器之前,讓我們稍微挖掘歷史,看看傳統郵件伺服器如何運作,因為這樣做能提供如何擴展電子郵件伺服器系統的良好教訓。你可以將傳統郵件伺服器視為當電子郵件使用者數量有限時運作的系統,通常運作於單一伺服器上。
傳統郵件伺服器架構#
圖 3 描述了當 Alice 使用傳統電子郵件伺服器寄送郵件給 Bob 時所發生的情況。
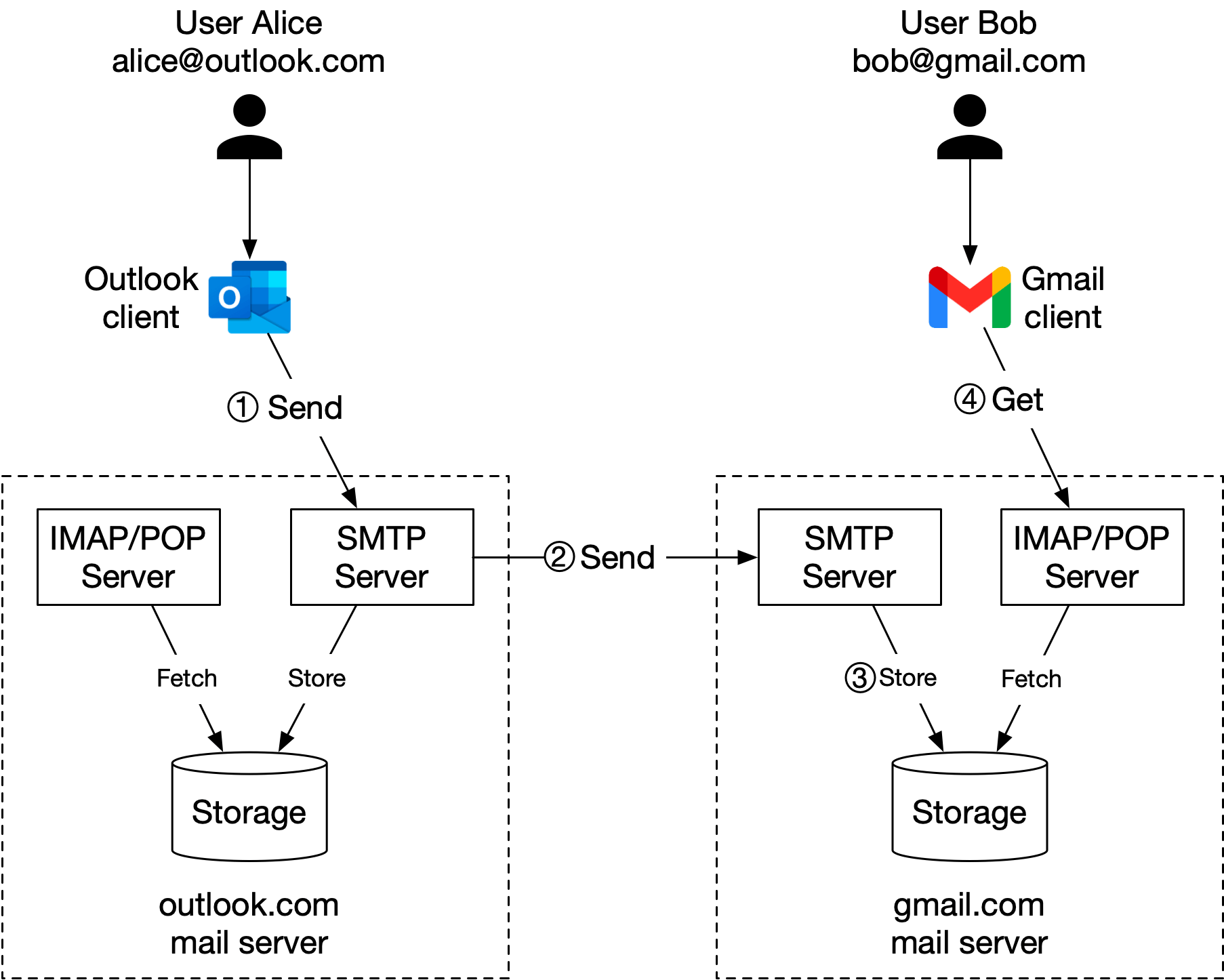
整個流程包含 4 個步驟:
- Alice 登入她的 Outlook 客戶端,撰寫郵件並按下「寄送」按鈕。郵件被寄送到 Outlook 郵件伺服器。Outlook 客戶端與郵件伺服器之間的通訊協定是 SMTP。
- Outlook 郵件伺服器查詢 DNS(圖中未顯示)以尋找收件者 SMTP 伺服器的位址。在此案例中,是 Gmail 的 SMTP 伺服器。接著它將郵件轉送到 Gmail 郵件伺服器。郵件伺服器之間的通訊協定是 SMTP。
- Gmail 伺服器儲存郵件並讓收件者 Bob 可以存取。
- 當 Bob 登入 Gmail 時,Gmail 客戶端透過 IMAP/POP 伺服器擷取新郵件。
儲存#
在傳統郵件伺服器中,郵件儲存在本機檔案目錄中,每封郵件儲存在獨立檔案中並有獨特名稱。每個使用者維護一個使用者目錄來儲存設定資料與信箱。Maildir 是郵件伺服器上儲存郵件訊息的熱門方式(圖 4)。

當使用者基數較小時,檔案目錄運作良好,但要擷取與備份數十億封郵件就具有挑戰性。隨著郵件量成長以及檔案結構變得更複雜,磁碟 I/O 成為瓶頸。本機目錄也無法滿足我們的高可用性與可靠性需求。磁碟可能損壞,伺服器可能當機。我們需要更可靠的分散式儲存層。
電子郵件功能自 1960 年代發明以來已有長足進步,從純文字格式發展到多媒體、討論串 [8]、搜尋、標籤等豐富功能。但電子郵件協定(POP、IMAP 與 SMTP)是很久以前發明的,並未設計來支援這些新功能,也不具備支援數十億使用者的可擴展性。
分散式郵件伺服器#
分散式郵件伺服器設計用來支援現代使用情境並解決規模與韌性的問題。本節涵蓋電子郵件 API、分散式郵件伺服器架構、郵件寄送與郵件接收流程。
電子郵件 API#
電子郵件 API 對不同的郵件客戶端,或在郵件生命週期的不同階段,可能意味著非常不同的東西。例如:
- 給原生行動客戶端的 SMTP/POP/IMAP API。
- 寄送端與接收端郵件伺服器之間的 SMTP 通訊。
- 給功能完整且具互動性的網頁版電子郵件應用程式的 RESTful API over HTTP。
由於本書篇幅限制,我們只涵蓋對網頁版郵件最重要的部分 API。網頁版郵件常見的通訊方式是透過 HTTP 協定。
1. Endpoint:POST /v1/messages
寄送訊息給 To、Cc 與 Bcc 標頭中的收件者。
2. Endpoint:GET /v1/folders
回傳郵件帳號的所有資料夾。
Response:
[{id: string Unique folder identifier.
name: string Name of the folder.
According to RFC6154 [9], the default folders can be one of
the following: All, Archive, Drafts, Flagged, Junk, Sent,
and Trash.
user_id: string Reference to the account owner
}]3. Endpoint:GET /v1/folders/{:folder_id}/messages
回傳資料夾下的所有訊息。請注意這是高度簡化的 API。實際上,這需要支援分頁。
Response:
訊息物件清單。
4. Endpoint:GET /v1/messages/{:message_id}
取得特定訊息的所有資訊。訊息是電子郵件應用程式的核心建構基石,包含寄件者、收件者、訊息主旨、內文、附件等資訊。
Response:
一個訊息物件。
{
user_id: string // Reference to the account owner.
from: {name: string, email: string} // <name, email> pair of the sender.
to: [{name: string, email: string}] // A list of <name, email> paris
subject: string // Subject of an email
body: string // Message body
is_read: boolean // Indicate if a message is read or not.
}分散式郵件伺服器架構#
雖然要建立一個處理少量使用者的電子郵件伺服器很容易,但要擴展到單一伺服器之外則很困難。這主要是因為傳統電子郵件伺服器只設計用於單一伺服器。跨伺服器同步資料可能很困難,避免郵件被收件者郵件伺服器誤判為垃圾郵件也非常具挑戰性。本節我們探討如何利用雲端技術讓事情變得更簡單。高層級設計如圖 5 所示。
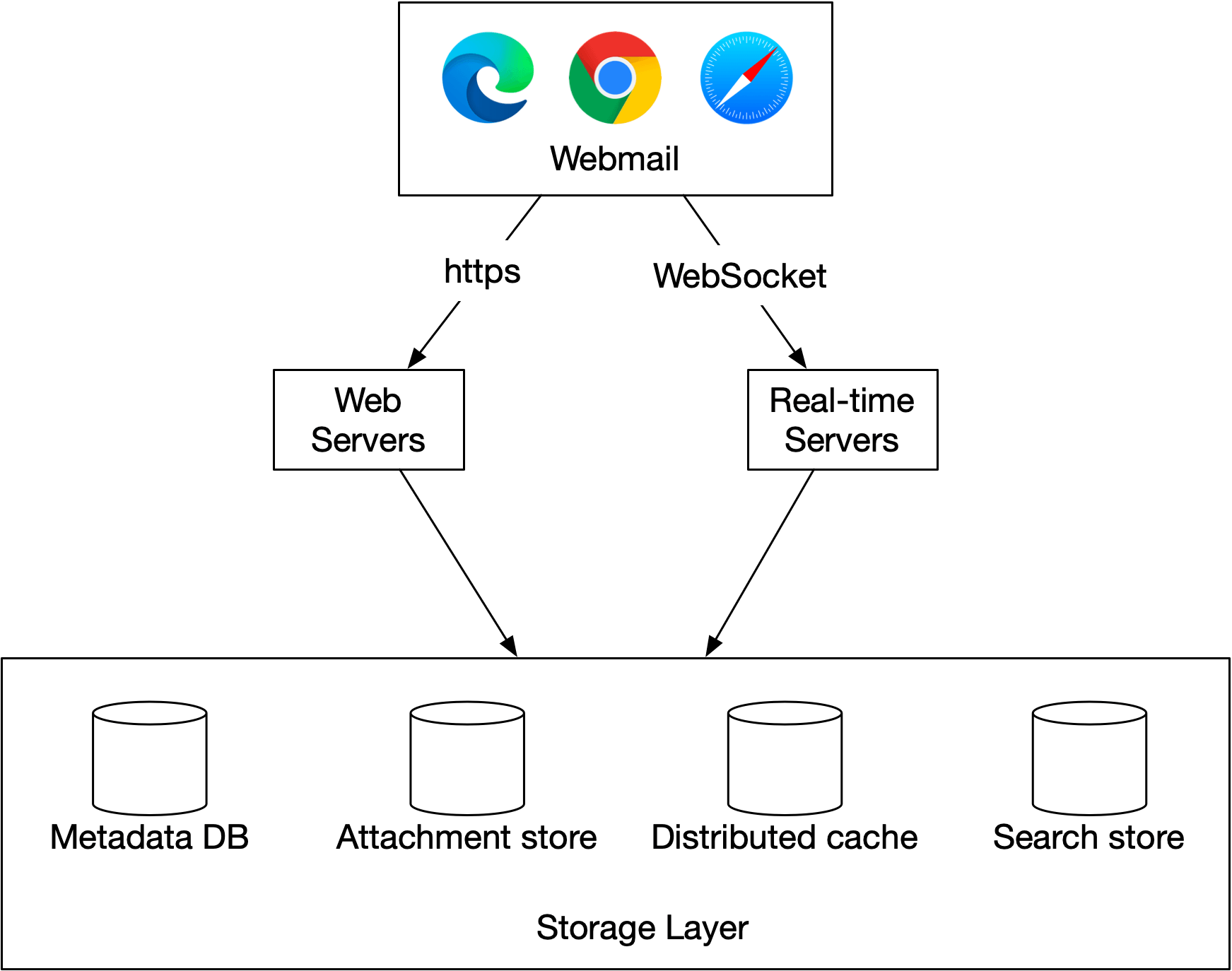
讓我們仔細看看每個元件。
- Webmail:使用者使用網頁瀏覽器來接收與寄送郵件。
- Web 伺服器:Web 伺服器是面向公眾的請求/回應服務,用來管理登入、註冊、使用者個人資料等功能。在我們的設計中,所有電子郵件 API 請求,例如寄送郵件、載入郵件資料夾、載入資料夾中的所有郵件等,都會經過 Web 伺服器。
- 即時伺服器(Real-time servers):即時伺服器負責即時推送新郵件更新給客戶端。即時伺服器是有狀態(stateful)伺服器,因為它們需要維持持久連線。要支援即時通訊,我們有幾個選項,例如長輪詢(long polling)與 WebSocket。WebSocket 是更優雅的解決方案,但它的一個缺點是瀏覽器相容性。一個可行的解決方案是盡可能建立 WebSocket 連線,並使用長輪詢作為備援。
這裡有個現實世界的郵件伺服器範例(Apache James [10]),實作了透過 WebSocket 的 JSON Meta Application Protocol(JMAP)子協定 [11]。
- Metadata 資料庫:此資料庫儲存郵件 metadata,包括郵件主旨、內文、寄件人、收件人等。我們會在深入探討段落討論資料庫選擇。
- 附件儲存(Attachment store):我們選擇 Amazon Simple Storage Service(S3)等物件儲存作為附件儲存。S3 是可擴展的儲存基礎設施,適合儲存圖片、影片、檔案等大型檔案。附件大小可達 25 MB。Cassandra 等 NoSQL 欄族資料庫可能不適合,原因有以下兩點:
- 雖然 Cassandra 支援 blob 資料類型,且其 blob 理論最大值為 2 GB,但實際上限小於 1 MB [12]。
- 將附件放在 Cassandra 中的另一個問題是我們無法使用 row cache,因為附件佔用太多記憶體空間。
- 分散式快取:由於最近的郵件會被客戶端反覆載入,將最近的郵件快取在記憶體中可大幅改善載入時間。我們可以使用 Redis,因為它提供清單等豐富功能且容易擴展。
- 搜尋儲存(Search store):搜尋儲存是分散式文件儲存。它使用一種稱為倒排索引(inverted index)[13] 的資料結構,支援非常快速的全文搜尋。我們會在深入探討段落更詳細地討論這個。
現在我們已經討論了建立分散式郵件伺服器最重要的元件,讓我們組合兩個主要工作流程。
- 郵件寄送流程。
- 郵件接收流程。
郵件寄送流程#
郵件寄送流程如圖 6 所示。
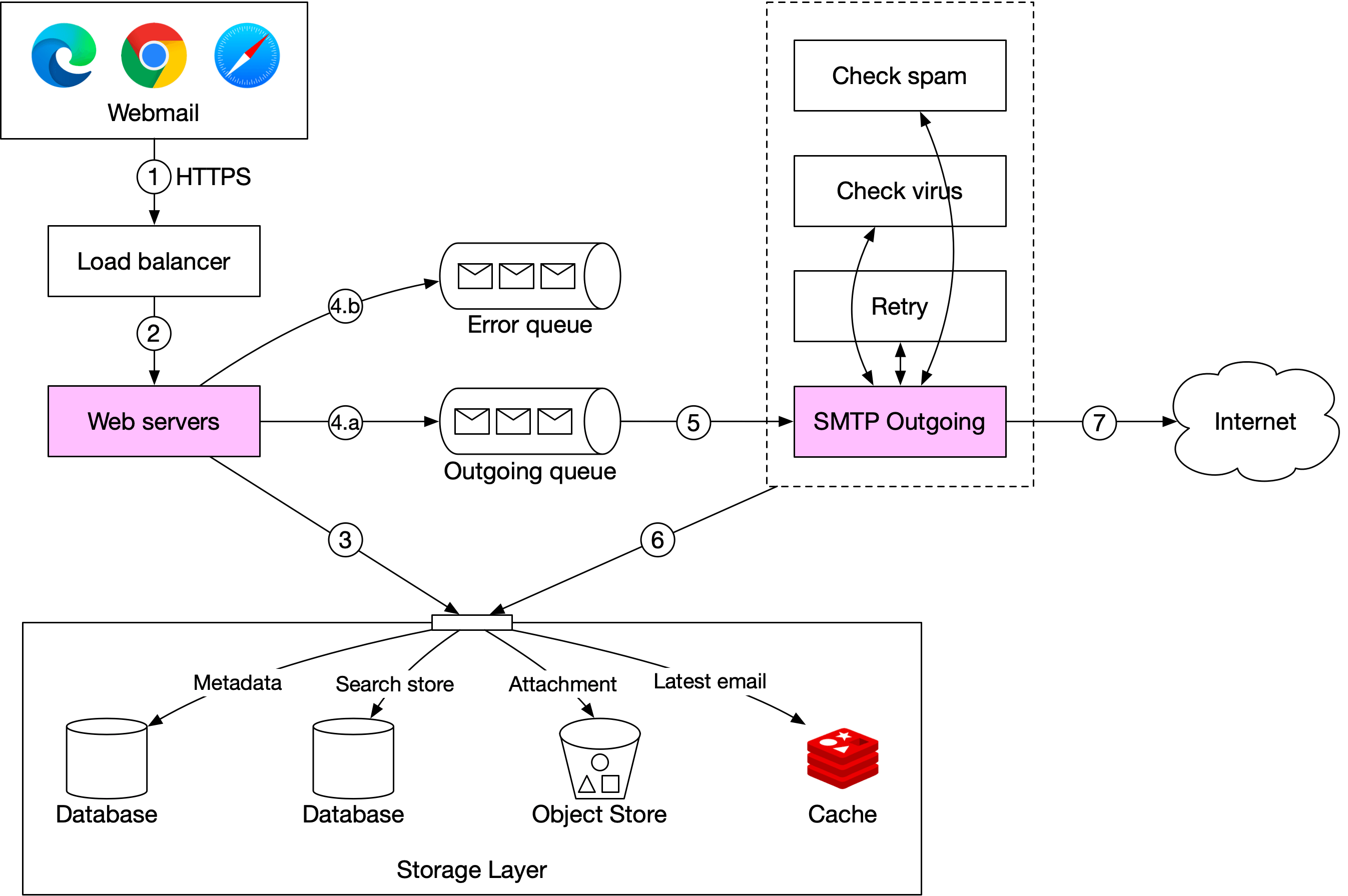
使用者在 webmail 上撰寫郵件並按下「寄送」按鈕。請求被送到負載平衡器。
負載平衡器確保未超過速率限制,並將流量路由到 Web 伺服器。
Web 伺服器負責:
3a. 基本郵件驗證。每封進來的郵件會根據預先定義的規則檢查,例如郵件大小限制。
3b. 檢查收件者郵件位址的網域是否與寄件者相同。如果相同,Web 伺服器會確保郵件資料無垃圾郵件與病毒。如果通過,郵件資料被插入到寄件者的「寄件備份」與收件者的「收件匣」資料夾。收件者可直接透過 RESTful API 擷取郵件。無需進入步驟 4。
訊息佇列。
4a. 如果基本郵件驗證成功,郵件資料被傳到外送佇列。如果附件太大無法放入佇列,我們可將附件儲存到物件儲存中,並在佇列訊息中儲存物件引用。
4b. 如果基本郵件驗證失敗,郵件被放入錯誤佇列。
SMTP 外送 worker 從外送佇列中拉取訊息,並確保郵件無垃圾郵件與病毒。
外送郵件被儲存在儲存層的「寄件備份」中。
SMTP 外送 worker 將郵件寄送到收件者郵件伺服器。
外送佇列中的每個訊息包含建立郵件所需的所有 metadata。分散式訊息佇列是允許非同步郵件處理的關鍵元件。透過將 SMTP 外送 worker 與 Web 伺服器解耦,我們可以獨立擴展 SMTP 外送 worker。
我們會密切監控外送佇列的大小。如果有許多郵件卡在佇列中,我們需要分析問題的原因。以下是一些可能性:
- 收件者的郵件伺服器無法使用。在這種情況下,我們需要稍後重試寄送郵件。指數退避(Exponential backoff)[14] 可能是不錯的重試策略。
- 沒有足夠的消費者來寄送郵件。在這種情況下,我們可能需要更多的消費者來縮短處理時間。
郵件接收流程#
下圖展示郵件接收流程。
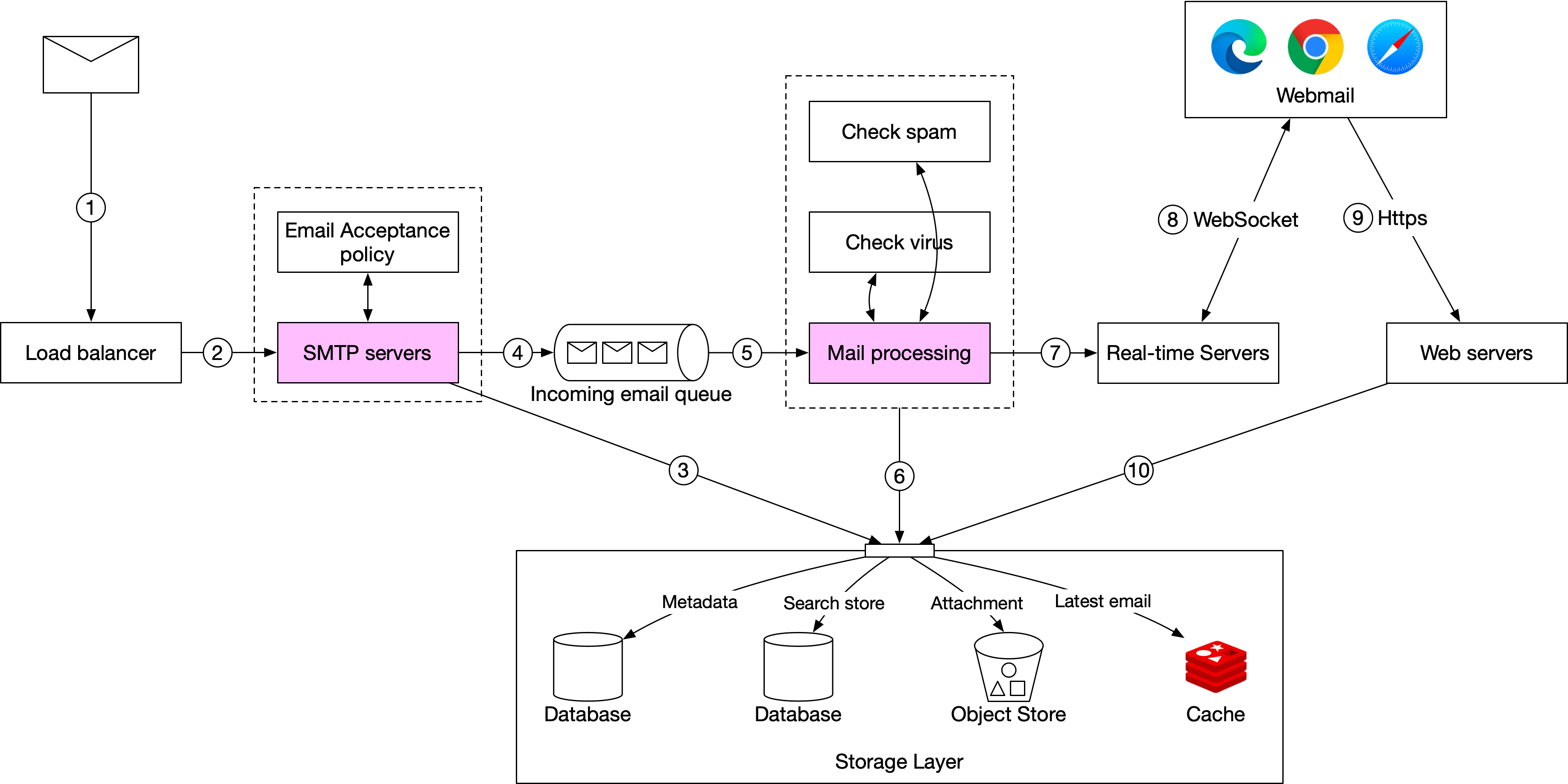
- 進來的郵件抵達 SMTP 負載平衡器。
- 負載平衡器在 SMTP 伺服器之間分配流量。郵件接受策略可以在 SMTP 連線層級設定與套用。例如,無效的郵件會被退回以避免不必要的郵件處理。
- 如果郵件的附件太大無法放入佇列,我們可以將其放入附件儲存(s3)。
- 郵件被放入進來郵件佇列。佇列將郵件處理 worker 與 SMTP 伺服器解耦,使它們可以獨立擴展。此外,佇列在郵件量激增時可作為緩衝區。
- 郵件處理 worker 負責許多任務,包括過濾垃圾郵件、阻擋病毒等。以下步驟假設郵件通過驗證。
- 郵件被儲存在郵件儲存、快取與物件資料儲存中。
- 如果收件者目前在線,郵件被推送到即時伺服器。
- 即時伺服器是 WebSocket 伺服器,允許客戶端即時接收新郵件。
- 對於離線使用者,郵件儲存在儲存層中。當使用者重新上線時,webmail 客戶端透過 RESTful API 連線到 Web 伺服器。
- Web 伺服器從儲存層拉取新郵件並回傳給客戶端。
Step 3 - 設計深入探討#
現在我們已經談過電子郵件伺服器的所有部分,讓我們更深入地探討一些關鍵元件,並檢視如何擴展系統。
- Metadata 資料庫
- 搜尋
- 送達率(Deliverability)
- 可擴展性
Metadata 資料庫#
本節中,我們討論郵件 metadata 的特性、選擇正確的資料庫、資料模型以及對話串(加分題)。
郵件 metadata 的特性#
- 郵件標頭通常很小且經常被存取。
- 郵件內文大小可大可小,但較少被存取。一封郵件通常只會被讀一次。
- 大多數郵件操作,例如擷取郵件、將郵件標記為已讀以及搜尋,都僅限於單一使用者。換句話說,使用者擁有的郵件只能由該使用者存取,所有的郵件操作都由同一使用者執行。
- 資料新鮮度影響資料使用。使用者通常只閱讀最近的郵件。82% 的讀取查詢是針對 16 天內的資料 [15]。
- 資料有高可靠性需求。資料遺失是不可接受的。
選擇正確的資料庫#
在 Gmail 或 Outlook 規模下,資料庫系統通常是客製化的,以降低每秒輸入/輸出操作(IOPS)[16],因為這很容易成為系統的主要限制。選擇正確的資料庫並不容易。在決定最合適的選項之前,將所有可能的選項考量進去會有幫助。
- 關聯式資料庫:這背後的主要動機是為了高效搜尋郵件。我們可以為郵件標頭與內文建立索引。有了索引,簡單的搜尋查詢會很快。然而,關聯式資料庫通常針對小型資料項目最佳化,並不適合大型資料項目。一封典型的郵件通常大於數 KB,當包含 HTML 時很容易超過 100 KB。你可能會說 BLOB 資料類型是設計來支援大型資料項目的。然而,對非結構化的 BLOB 資料類型進行搜尋查詢效率不彰。所以 MySQL 或 PostgreSQL 等關聯式資料庫並不適合。
- 分散式物件儲存:另一個潛在解決方案是將原始郵件儲存在 Amazon S3 等雲端儲存中,這對備份儲存而言是個不錯的選擇,但很難有效支援將郵件標記為已讀、依關鍵字搜尋郵件、串接郵件等功能。
- NoSQL 資料庫:Google Bigtable 被 Gmail 所使用,所以絕對是個可行的解決方案。然而,Bigtable 沒有開源,且電子郵件搜尋如何實作仍是個謎。Cassandra 也可能是個不錯的選擇,但我們還沒看到任何大型電子郵件供應商使用它。
基於上述分析,似乎很少有現成解決方案完美符合我們的需求。大型電子郵件服務供應商傾向於建立自己的高度客製化資料庫。然而,在面試情境下,我們不會有時間設計一個新的分散式資料庫,但解釋資料庫應具備的下列特性是很重要的。
- 單一欄位可達數 MB。
- 強一致性。
- 設計為降低磁碟 I/O。
- 應具備高可用性與容錯性。
- 應易於建立增量備份。
資料模型#
一種儲存資料的方式是使用 user_id 作為 partition key,使一個使用者的資料儲存在單一 shard 上。此資料模型的一個限制是訊息無法在多個使用者之間共享。由於這在本次面試中並非需求,所以不需擔心。
現在讓我們定義表格。主鍵包含兩個元件:partition key 與 clustering key。
- Partition key:負責跨節點分配資料。一般來說,我們希望均勻散佈資料。
- Clustering key:負責在 partition 內排序資料。
從高層級來看,電子郵件服務需要在資料層支援以下查詢:
- 第一個查詢是取得使用者的所有資料夾。
- 第二個查詢是顯示特定資料夾的所有郵件。
- 第三個查詢是建立/刪除/取得特定郵件。
- 第四個查詢是擷取所有已讀或未讀郵件。
- 加分題:取得對話串。
讓我們一個一個來看。
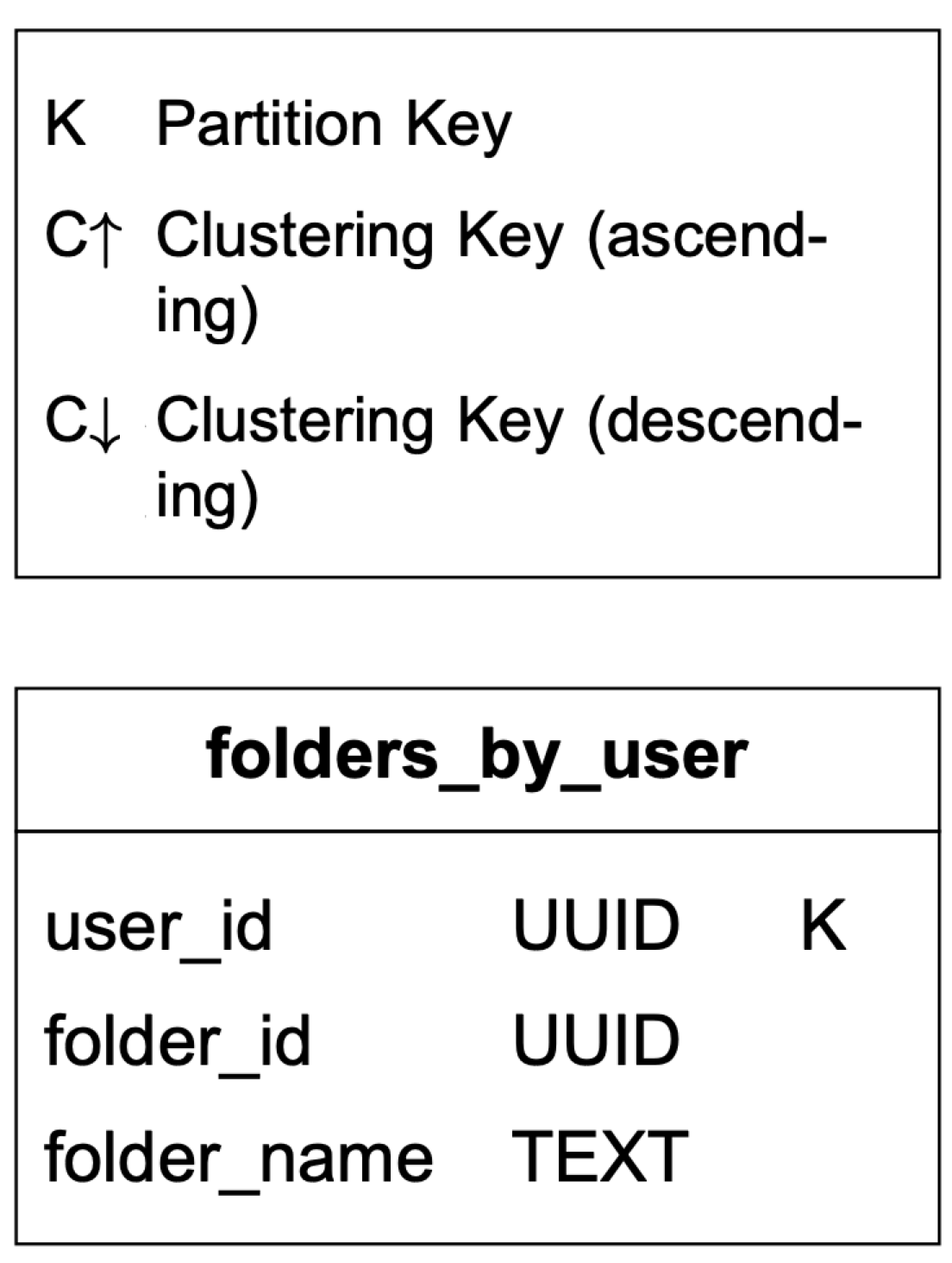
Query 1:取得使用者的所有資料夾。
如表 1 所示,user_id 是 partition key,所以同一使用者擁有的資料夾會位於同一個 partition。
Query 2:顯示特定資料夾的所有郵件。
當使用者載入收件匣時,郵件通常會依時間戳排序,最新的在最上面。為了將同一資料夾的所有郵件儲存在同一個 partition 中,使用複合 partition key <user_id, folder_id>。另一個值得注意的欄位是 email_id。其資料類型為 TIMEUUID [17],它是用來依時序排列郵件的 clustering key。

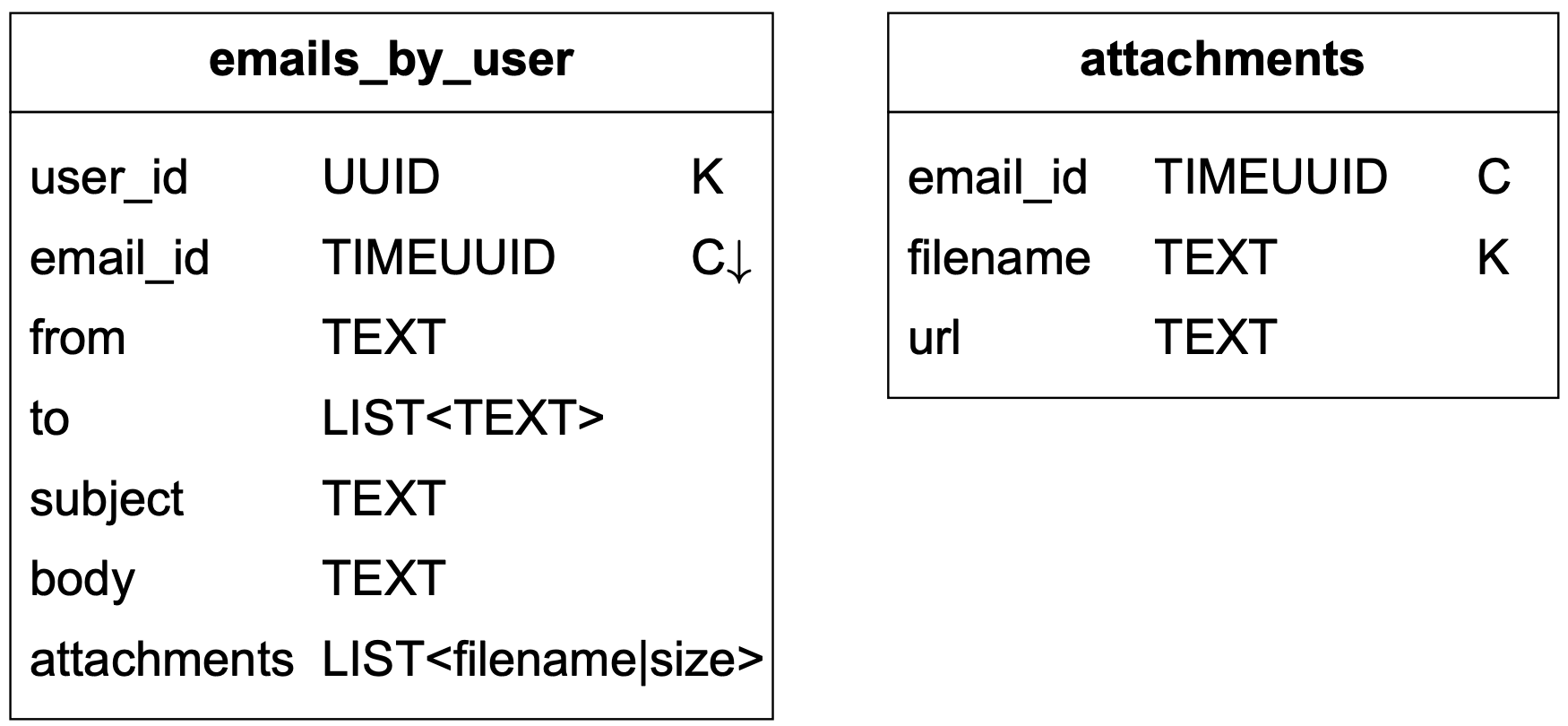
Query 3:建立/刪除/取得郵件
由於篇幅限制,我們只解釋如何取得郵件的詳細資訊。表 3 中的兩個表格設計來支援此查詢。簡單的查詢看起來像這樣:
SELECT * FROM emails_by_user WHERE email_id = 123;一封郵件可以有多個附件,可透過 email_id 與 filename 欄位的組合擷取。
Query 4:擷取所有已讀或未讀郵件
如果我們的領域模型是針對關聯式資料庫,擷取所有已讀郵件的查詢看起來像這樣:
SELECT * FROM emails_by_folder
WHERE user_id = <user_id> and folder_id = <folder_id> and is_read = true
ORDER BY email_id;擷取所有未讀郵件的查詢看起來非常類似。我們只需將上面查詢中的「is_read = true」改為「is_read = false」。
然而,我們的資料模型是針對 NoSQL 設計的。NoSQL 資料庫通常只支援基於 partition 與 cluster keys 的查詢。由於 emails_by_folder 表中的 is_read 都不是這兩種,大多數 NoSQL 資料庫會拒絕此查詢。
一種繞過此限制的方式是擷取使用者的整個資料夾並在應用程式中執行篩選。這對小型電子郵件服務可能可行,但在我們的設計規模下並不適合。
這個問題在 NoSQL 中通常以反正規化(denormalization)解決。為了支援已讀/未讀查詢,我們將 emails_by_folder 資料反正規化為兩個表格,如表 4 所示。
- read_emails:儲存所有已讀狀態的郵件。
- unread_emails:儲存所有未讀狀態的郵件。
要將一封 UNREAD 郵件標記為 READ,該郵件會從 unread_emails 中刪除,然後插入到 read_emails。
要擷取特定資料夾的所有未讀郵件,我們可執行如下查詢:
SELECT * FROM unread_emails
WHERE user_id = <user_id> and folder_id = <folder_id>
ORDER BY email_id;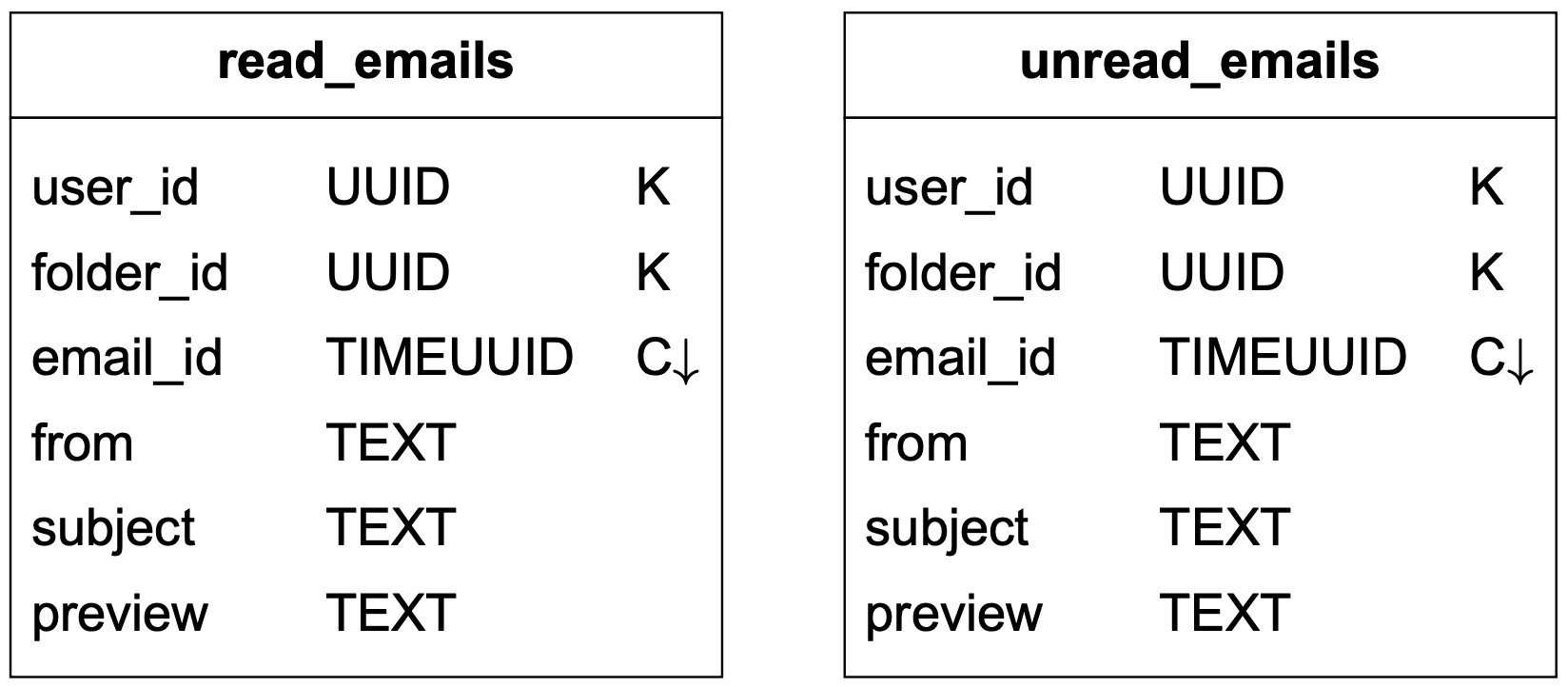
如上所示的反正規化是常見做法。它使應用程式碼更複雜且更難維護,但在大規模時改善了這些查詢的讀取效能。
加分題:對話串
討論串是許多電子郵件客戶端支援的功能。它將郵件回覆與其原始訊息歸為同一群組 [8]。這讓使用者能擷取一個對話相關的所有郵件。傳統上,討論串使用 JWZ 演算法 [18] 等演算法實作。我們不會深入演算法的細節,只解釋背後的核心概念。郵件標頭通常包含以下三個欄位:
{
"headers" {
"Message-Id": "<7BA04B2A-430C-4D12-8B57-862103C34501@gmail.com>",
"In-Reply-To": "<CAEWTXuPfN=LzECjDJtgY9Vu03kgFvJnJUSHTt6TW@gmail.com>",
"References": ["<7BA04B2A-430C-4D12-8B57-862103C34501@gmail.com>"]
}
}| Message-Id | 訊息 ID 的值。由客戶端在寄送訊息時產生。 |
|---|---|
| In-Reply-To | 此訊息回覆的父訊息 Message-Id。 |
| References | 與一個討論串相關的訊息 ID 清單。 |
表 5 郵件標頭
有了這些欄位,如果回覆鏈中的所有訊息都已預先載入,電子郵件客戶端就能從訊息中重建郵件對話。
一致性權衡#
依靠複寫達到高可用性的分散式資料庫必須在一致性與可用性之間做出根本性的權衡。正確性對電子郵件系統非常重要,所以從設計上我們希望任一信箱有單一主要副本。在容錯切換(failover)的事件中,信箱無法被客戶端存取,所以它們的同步/更新操作會暫停直到容錯切換結束。這以可用性換取一致性。
郵件送達率#
設置郵件伺服器並開始寄送郵件很容易。困難的部分是讓郵件實際送達使用者的收件匣。如果郵件最終進入垃圾郵件資料夾,意味著收件者不會閱讀的機率很高。
垃圾郵件是個巨大的問題。根據 Statista 的研究 [19],所有寄送的郵件中超過 50% 是垃圾郵件。如果我們設置一個新的郵件伺服器,我們的郵件最有可能會進入垃圾郵件資料夾,因為新的郵件伺服器沒有信譽。
有幾個因素可以考量來改善郵件送達率。
- 專用 IP:建議使用專用 IP 位址寄送郵件。電子郵件供應商較不可能接受沒有歷史記錄的新 IP 位址寄出的郵件。
- 分類郵件:從不同 IP 位址寄送不同類別的郵件。例如,你可能想避免從相同伺服器寄送行銷與重要郵件,因為這可能讓 ISP 將所有郵件標記為促銷郵件。
- 郵件寄件者信譽:慢慢預熱新的郵件伺服器 IP 位址以建立良好信譽,使 Office365、Gmail、Yahoo Mail 等大型供應商較不可能將我們的郵件放入垃圾郵件資料夾。根據 Amazon Simple Email Service [20],預熱新的 IP 位址大約需要 2 到 6 週。
- 快速封禁垃圾郵件發送者:應在垃圾郵件發送者對伺服器信譽造成顯著影響之前快速封禁。
- 回饋處理:設置與 ISP 的回饋迴路非常重要,這樣我們才能保持低投訴率並快速封禁垃圾郵件帳號。如果一封郵件送達失敗或使用者投訴,會發生以下其中一種結果:
- 硬退(Hard bounce):這意味著郵件被 ISP 拒絕,因為收件者的郵件位址無效。
- 軟退(Soft bounce):軟退表示郵件因暫時情況送達失敗,例如 ISP 太忙。
- 投訴(Complaint):這意味著收件者點擊了「檢舉垃圾郵件」按鈕。
圖 8 顯示收集與處理退件/投訴的流程。我們對軟退、硬退與投訴使用獨立的佇列,使它們可以分別管理。

郵件認證。根據 Verizon 提供的 2018 年資料外洩調查報告,網路釣魚與假冒情境佔資料外洩的 93% [21]。一些對抗網路釣魚的常見技術包括:寄件者政策框架(Sender Policy Framework,SPF)[22]、網域金鑰識別郵件(DomainKeys Identified Mail,DKIM)[23] 與基於網域的訊息認證、回報與符合性(Domain-based Message Authentication, Reporting and Conformance,DMARC)[24]。
圖 9 顯示一個 Gmail 訊息標頭的範例。如你所見,寄件者 @info6.citi.com 通過 SPF、DKIM 與 DMARC 驗證。
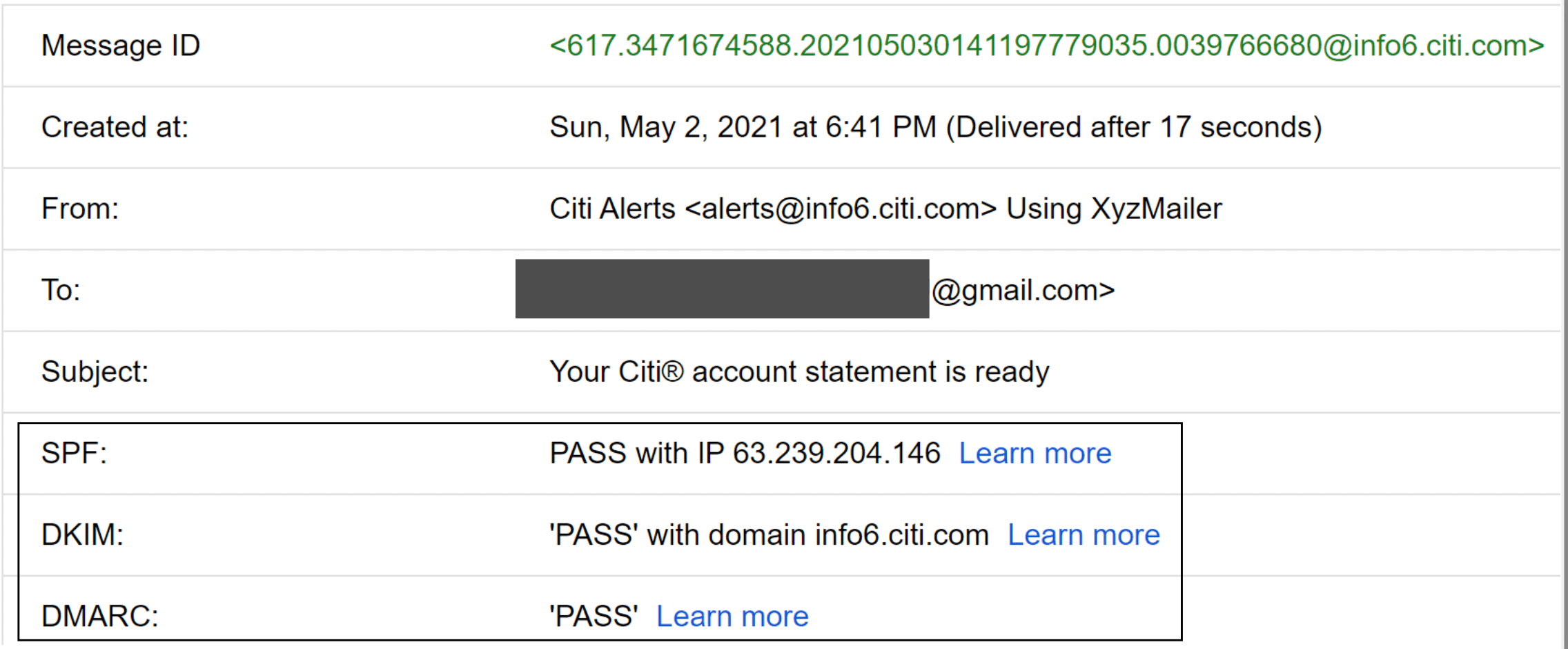
你不需要記住所有這些術語。重要的是要記住,讓郵件如預期運作很困難。它不僅需要領域知識,還需要與 ISP 的良好關係。
搜尋#
基本的郵件搜尋指的是搜尋主旨或內文中包含任何輸入關鍵字的郵件。更進階的功能包括依「寄件者」、「主旨」、「未讀」或其他屬性篩選。一方面,每當寄送、接收或刪除郵件時,我們都需要重新建立索引。另一方面,搜尋查詢只會在使用者按下「搜尋」按鈕時執行。這意味著電子郵件系統的搜尋功能寫入次數遠多於讀取次數。與 Google 搜尋相比,電子郵件搜尋有相當不同的特性,如表 6 所示。
| 範圍 | 排序 | 準確性 | |
|---|---|---|---|
| Google 搜尋 | 整個網際網路 | 依相關性排序 | 索引一般需要時間,所以某些項目可能不會立即出現在 |
| 搜尋結果中。 | |||
| 電子郵件搜尋 | 使用者自己的信箱 | 依時間、是否有附件、日期範圍、是否未讀 | |
| 等屬性排序 | 索引應接近即時,且結果必須準確。 |
表 6 Google 搜尋 vs 電子郵件搜尋
要支援搜尋功能,我們比較兩種方式:Elasticsearch 與內嵌於資料儲存的原生搜尋。
選項 1:Elasticsearch
使用 Elasticsearch 進行郵件搜尋的高層級設計如圖 10 所示。由於查詢主要在使用者自己的郵件伺服器上執行,我們可以使用 user_id 作為 partition key 將底層文件分組到同一節點。

當使用者點擊「搜尋」按鈕時,使用者會等待直到收到搜尋回應。搜尋請求是同步的。當「寄送郵件」、「接收郵件」或「刪除郵件」等事件被觸發時,沒有與搜尋相關的東西需要回傳給客戶端。需要重新建立索引,這可以透過離線工作來完成。設計中使用 Kafka 將觸發重新索引的服務與實際執行重新索引的服務解耦。
Elasticsearch 是截至 2021 年 6 月最熱門的搜尋引擎資料庫 [25],且非常良好地支援郵件全文搜尋。加入 Elasticsearch 的一個挑戰是讓我們的主要郵件儲存與其保持同步。中國最大的電子郵件供應商之一騰訊 QQ 郵箱使用 Elasticsearch [26]。
選項 2:自訂搜尋方案
大規模電子郵件供應商通常會開發自己的自訂搜尋引擎以滿足特定需求。設計郵件搜尋引擎是非常複雜的任務,超出本章範圍。這裡我們只簡單觸及磁碟 I/O 瓶頸,這是自訂搜尋引擎將面臨的主要挑戰。
如粗略估算所示,每天新增的 metadata 與附件大小達 PB 級。同時,一個電子郵件帳號可以輕易擁有超過 50 萬封郵件。索引伺服器的主要瓶頸通常是磁碟 I/O。
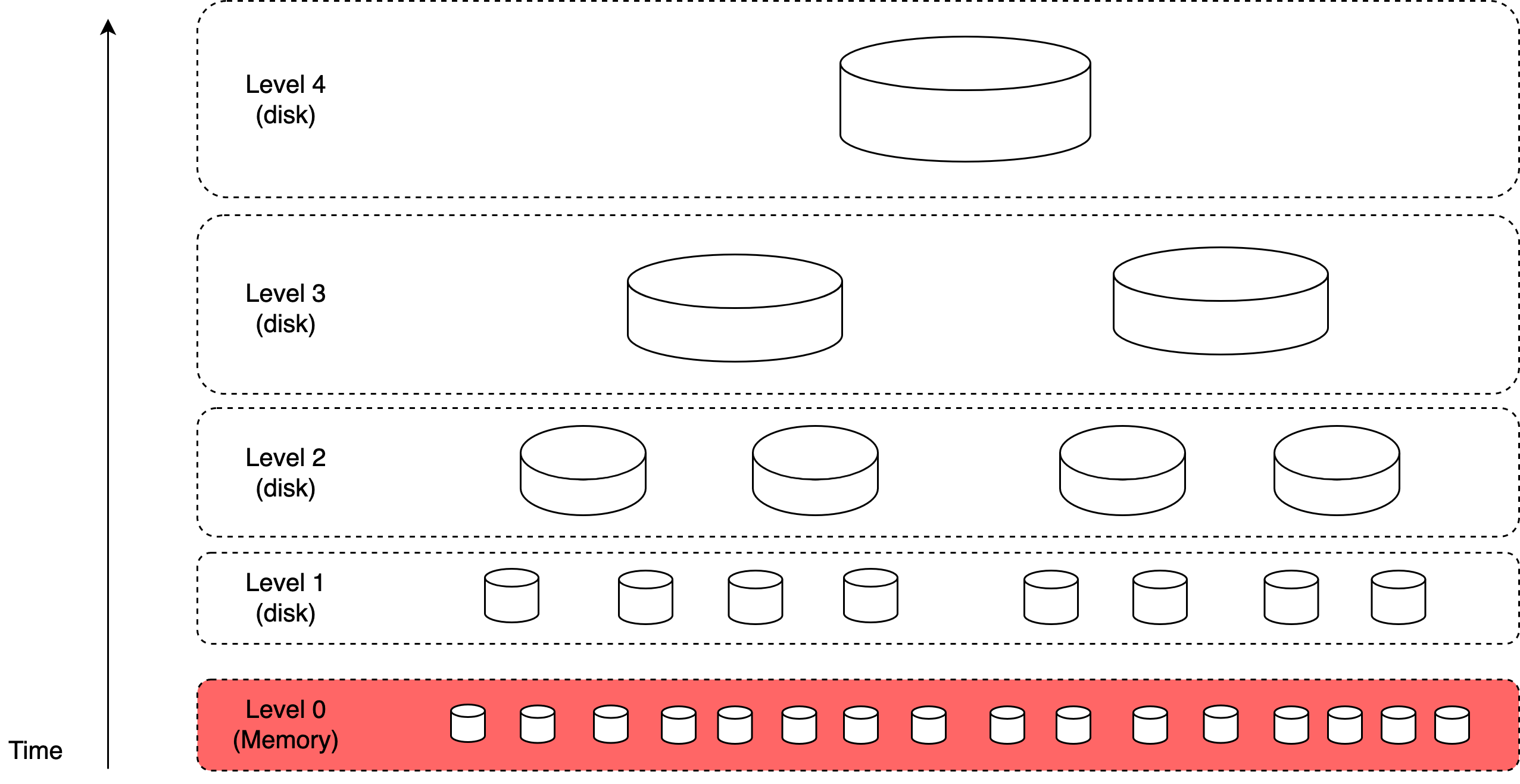
由於建立索引的過程是寫入密集的,一個好策略可能是使用 Log-Structured Merge-Tree(LSM)[27] 在磁碟上組織索引資料(圖 11)。寫入路徑透過只執行循序寫入來最佳化。LSM 樹是 BigTable、Cassandra 與 RocksDB 等資料庫背後的核心資料結構。當新郵件抵達時,它先被加入到 level 0 記憶體內快取,當記憶體中的資料大小達到預先定義的閾值時,資料被合併到下一個層級。使用 LSM 的另一個原因是將經常變動的資料與不變動的資料分開。例如,郵件資料通常不會改變,但資料夾資訊由於不同的篩選規則而較常變動。在這種情況下,我們可以將它們分隔到兩個不同的區段,這樣如果請求與資料夾變更相關,我們就只變更資料夾而不動郵件資料。
如果你有興趣閱讀更多關於郵件搜尋的內容,強烈建議看看 Microsoft Exchange 伺服器中搜尋是如何運作的 [28]。
每種方式各有優缺點:
| 特性 | Elasticsearch | 自訂搜尋引擎 |
|---|---|---|
| 可擴展性 | 在某種程度上可擴展。 | 較容易擴展,因為我們可以針對郵件使用情境最佳化系統。 |
| 系統複雜度 | 需要維護兩個不同的系統:資料儲存與 Elasticsearch。 | 一個系統。 |
| 資料一致性 | 兩份資料副本。一份在 metadata 資料儲存中,另一份在 Elasticsearch 中。資料一致性難以維持。 | 在 metadata 資料儲存中只有一份資料副本。 |
| 是否可能資料遺失 | 否。發生故障時可從主要儲存重建 Elasticsearch 索引。 | 否。 |
| 開發工作量 | 容易整合。要支援大規模電子郵件搜尋,可能需要專屬的 Elasticsearch 團隊。 | 需要大量工程努力來開發自訂郵件搜尋引擎。 |
表 7 Elasticsearch vs 自訂搜尋引擎
一般經驗法則是:對於較小規模的電子郵件系統,Elasticsearch 是不錯的選擇,因為容易整合且不需要顯著的工程努力。對於較大規模,Elasticsearch 也許可行,但我們可能需要專屬團隊來開發與維護電子郵件搜尋基礎設施。要支援 Gmail 或 Outlook 規模的電子郵件系統,將原生搜尋內嵌在資料庫中可能比獨立索引方式更好。
可擴展性與可用性#
由於個別使用者的資料存取模式彼此獨立,我們預期系統中大多數元件可水平擴展。
為了更好的可用性,資料會跨多個資料中心複寫。使用者與網路拓撲上實體上較接近他們的郵件伺服器通訊。在網路分割期間,使用者可以從其他資料中心存取訊息(圖 12)。

Step 4 - 總結#
本章中,我們呈現了建立大規模電子郵件伺服器的設計。我們從收集需求並做粗略計算開始,以對規模有良好的了解。在高層級設計中,我們討論了傳統電子郵件伺服器是如何設計的,以及為何它們無法滿足現代使用情境。我們也討論了電子郵件 API 以及寄送與接收流程的高層級設計。最後,我們深入探討了 metadata 資料庫設計、郵件送達率、搜尋與可擴展性。
如果面試結束時還有額外時間,這裡有一些額外的討論點:
- 容錯:系統的許多部分都可能失敗,你可以談談如何處理節點故障、網路問題、事件延遲等。
- 法規遵循:電子郵件服務在世界各地運作,且有需要遵守的法律法規。例如,我們需要以符合一般資料保護規範(GDPR)[29] 的方式處理與儲存來自歐洲的個人可識別資訊(PII)。合法攔截是此領域中另一個典型的功能 [30]。
- 安全性:電子郵件安全很重要,因為郵件包含敏感資訊。Gmail 提供安全功能,例如網路釣魚保護、安全瀏覽、主動警示、帳號安全、機密模式與郵件加密 [31]。
- 最佳化:有時,相同的郵件被寄送給多個收件者,且相同的郵件附件在群組郵件中於物件儲存(S3)內被儲存好幾次。我們可以做的一個最佳化是在執行昂貴的儲存操作之前,先檢查附件是否已存在於儲存中。
恭喜你看到這裡!現在拍拍自己的背。做得好!
章節摘要#