本章我們將為像 Marriott International 這類的連鎖飯店設計一個飯店訂房系統。本章使用的設計與技術也適用於其他熱門的訂位相關面試題目:
- 設計 Airbnb
- 設計航班訂位系統
- 設計電影票訂票系統
Step 1 - Understand the Problem and Establish Design Scope#
飯店訂房系統相當複雜,其元件會隨業務使用情境而異。在深入設計之前,你應該向面試官提出釐清問題,以縮小範圍。
應徵者:系統的規模有多大?
面試官:假設我們在為一個擁有 5,000 間飯店、總共 100 萬間客房的連鎖飯店建立網站。
應徵者:客戶在訂房時付款,還是抵達飯店時付款?
面試官:為求簡化,他們在訂房時就全額付款。
應徵者:客戶只透過飯店網站訂房嗎?我們需要支援其他訂房選項,例如電話訂房嗎?
面試官:假設人們可以透過飯店網站或 app 訂房。
應徵者:客戶可以取消訂房嗎?
面試官:可以。
應徵者:還有其他需要考慮的事情嗎?
面試官:有,我們允許 10% 的超賣(overbooking)。如果你不知道,超賣是指飯店銷售比實際擁有的更多房間。飯店這麼做是預期某些客戶會取消訂房。
應徵者:因為時間有限,我假設飯店房間搜尋不在範圍內。我們專注於以下功能:
- 顯示飯店相關頁面。
- 顯示飯店房間相關的詳細頁面。
- 預訂房間。
- 管理介面,用以新增/移除/更新飯店或房間資訊。
- 支援超賣功能。
面試官:聽起來不錯。
面試官:還有一件事,飯店房價是動態變化的。飯店房間的價格取決於該日期飯店預期的滿房程度。在這次面試中,我們可以假設每天的價格都可能不同。
應徵者:我會記住這一點。
接下來,你可能會想討論最重要的非功能性需求。
Non-functional requirements#
- 支援高併發。在旺季或大型活動期間,某些熱門飯店可能會有大量客戶嘗試訂同一個房間。
- 中等延遲。當使用者進行訂房時擁有快速回應時間是理想的,但系統花幾秒鐘處理訂房請求也是可以接受的。
Back-of-the-envelope estimation#
- 5000 間飯店,總共 100 萬間客房。
- 假設 70% 的房間被入住,平均住宿時間為 3 天。
- 預估每日訂房數:(100 萬 * 0.7) / 3 = 233,333(取整數約 240,000)
- 每秒訂房數 = 240,000 / 10^5 seconds in a day = ~3。如我們所見,平均每秒訂房交易數(TPS)並不高。
接下來,讓我們大略計算一下系統中所有頁面的 QPS。一個典型的客戶流程有三個步驟:
- 檢視飯店/房間詳細頁面。使用者瀏覽此頁面(query)。
- 檢視訂房頁面。使用者可以在訂房前確認訂房細節,例如日期、住客人數、付款資訊(query)。
- 預訂房間。使用者點擊「book」按鈕來訂房,房間就被預訂下來(transaction)。
讓我們假設約有 10% 的使用者進入下一步,90% 的使用者在到達最後一步之前會跳出流程。我們也可以假設沒有實作任何預先擷取功能(在使用者抵達下一步之前就預先擷取內容)。圖 1 顯示了不同步驟的 QPS 概略估算。我們知道最後的訂房 TPS 是 3,所以可以沿著漏斗反推回來。訂單確認頁面的 QPS 是 30,詳細頁面的 QPS 是 300。

Step 2 - Propose High-Level Design and Get Buy-In#
本節我們將討論:
- API 設計
- 資料模型
- 高階設計
API design#
我們來探討飯店訂房系統的 API 設計。下面以 RESTful 慣例列出最重要的 API。
本章專注於飯店訂房系統的設計。對於完整的飯店網站,設計需要提供直觀的功能讓客戶能依大量條件搜尋房間。這些搜尋功能的 API 雖然重要,但在技術上沒有太大挑戰,因此不在本章範圍內。
Hotel-related APIs
| API | Detail |
|---|---|
| GET /v1/hotels/ID | 取得飯店的詳細資訊。 |
| POST /v1/hotels | 新增一間飯店。此 API 僅限飯店員工使用。 |
| PUT /v1/hotels/ID | 更新飯店資訊。此 API 僅限飯店員工使用。 |
| DELETE /v1/hotels/ID | 刪除一間飯店。此 API 僅限飯店員工使用。 |
表 1 飯店相關 API
Room-related APIs
| API | Detail |
|---|---|
| GET /v1/hotels/ID/rooms/ID | 取得房間的詳細資訊。 |
| POST /v1/hotels/ID/rooms | 新增房間。此 API 僅限飯店員工使用。 |
| PUT /v1/hotels/ID/rooms/ID | 更新房間資訊。此 API 僅限飯店員工使用。 |
| DELETE /v1/hotels/ID/rooms/ID | 刪除房間。此 API 僅限飯店員工使用。 |
表 2 房間相關 API
Reservation related APIs
| API | Detail |
|---|---|
| GET /v1/reservations | 取得登入使用者的訂房紀錄。 |
| GET /v1/reservations/ID | 取得訂房的詳細資訊。 |
| POST /v1/reservations | 建立新訂房。 |
| DELETE /v1/reservations/ID | 取消訂房。 |
表 3 訂房相關 API
建立新訂房是個非常重要的功能。建立新訂房(POST /v1/reservations)的請求參數可能長這樣。
{
"startDate": "2021-04-28",
"endDate": "2021-04-30",
"hotelID": "245",
"roomID": "U12354673389",
"reservationID": "13422445"
}請注意 reservationID 被用作 idempotency key,以避免重複訂房。重複訂房意指同一個房間在同一天被建立了多個訂單。詳細內容會在「Deep Dive」章節的「Concurrency issue」中說明。
Data model#
在決定使用哪個資料庫之前,讓我們仔細看看資料存取模式。對於飯店訂房系統,我們需要支援以下查詢:
- Query 1:檢視某間飯店的詳細資訊。
- Query 2:給定日期區間,找出可用的房型。
- Query 3:建立一筆訂房紀錄。
- Query 4:查詢一筆訂房或過去的訂房歷史紀錄。
從概略估算我們知道系統規模並不大,但我們需要為大型活動期間的流量激增做準備。考量這些需求後,我們選擇關聯式資料庫,原因如下:
- 關聯式資料庫對於讀取偏重且寫入較不頻繁的工作流程運作良好。這是因為造訪飯店網站/app 的使用者人數比實際進行訂房的人數高出幾個數量級。NoSQL 資料庫一般是針對寫入做最佳化,而關聯式資料庫對於讀取偏重的工作流程運作得夠好。
- 關聯式資料庫提供 ACID(atomicity、consistency、isolation、durability)保證。ACID 屬性對於訂房系統很重要。沒有這些屬性,要避免像是負餘額、重複扣款、重複訂房等問題並不容易。ACID 屬性讓應用程式碼大為簡化,並讓整個系統更容易推理。關聯式資料庫通常會提供這些保證。
- 關聯式資料庫可以輕易地建模資料。業務資料的結構非常清晰,不同實體(hotel、room、room_type 等)之間的關係穩定。這種資料模型很容易用關聯式資料庫建模。
既然我們選擇了關聯式資料庫作為資料儲存,讓我們來探討 schema 設計。圖 2 展示了一個直觀的 schema 設計,這是許多應徵者最自然會用來建模飯店訂房系統的方式。
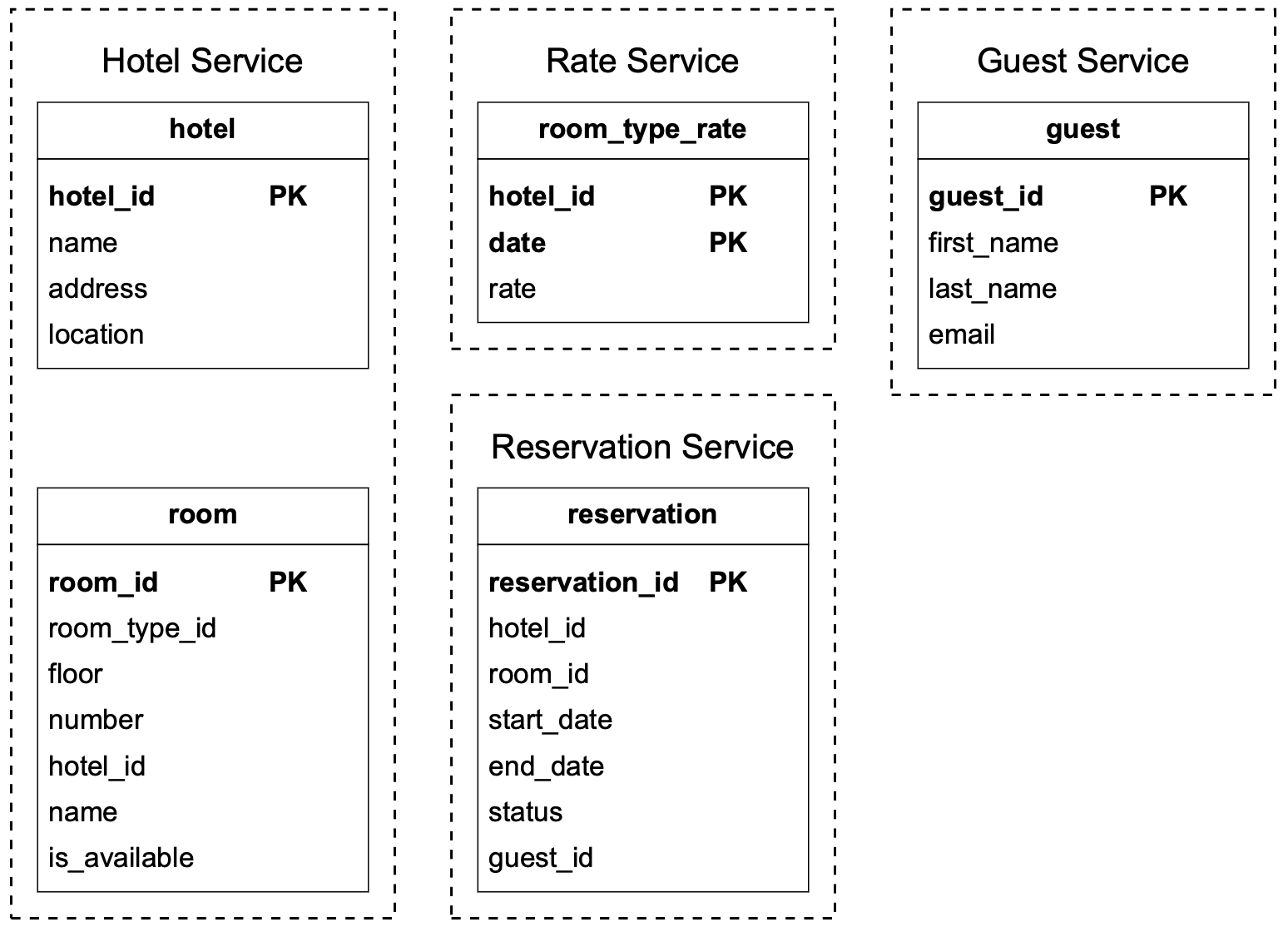
大部分屬性不言自明,這裡我們只解釋 reservation 表中的 status 欄位。status 欄位可以處於以下狀態之一:pending、paid、refunded、canceled、rejected。狀態機如圖 3 所示。

這個 schema 設計有一個重大問題。這個資料模型適用於像 Airbnb 這樣的公司,因為使用者訂房時會給定 room_id(可能稱為 listing_id)。但對飯店來說並非如此。使用者實際上是在某間飯店訂一種房型,而不是一個特定的房間。例如,房型可以是標準房、king-size 房、有兩張 queen 床的 queen-size 房等。房號是在客人入住時才給的,而不是在訂房時。
我們需要更新資料模型以反映這個新需求。詳情請見「Deep Dive」章節的「Improved data model」。
High-level design#
我們為這個飯店訂房系統採用 microservice 架構。過去幾年來,microservice 架構大為流行。使用 microservice 的公司包括 Amazon、Netflix、Uber、Airbnb、Twitter 等。如果你想了解更多 microservice 架構的好處,可以參考一些不錯的資源 [1] [2]。
我們的設計以 microservice 架構建模,高階設計圖如圖 4 所示。

我們將從上而下簡要介紹系統的每個元件。
- User:使用者透過手機或電腦訂飯店房間。
- Admin(飯店員工):經授權的飯店員工執行管理操作,例如退款給客戶、取消訂房、更新房間資訊等。
- CDN(content delivery network):為了更好的載入時間,使用 CDN 來快取所有靜態資源,包括 JavaScript bundle、圖片、影片、HTML 等。
- Public API Gateway:這是個全託管服務,支援限流、認證等。API gateway 被設定為依據端點將請求導向特定服務。例如,載入飯店首頁的請求會被導向 hotel service,而訂飯店房的請求會被路由到 reservation service。
- Internal APIs:這些 API 僅供經授權的飯店員工使用。它們透過內部軟體或網站存取,通常會額外受到 VPN(virtual private network)保護。
- Hotel Service:提供飯店與房間的詳細資訊。飯店與房間資料一般是靜態的,所以可以輕易地被快取。
- Rate Service:提供未來不同日期的房價。飯店業有個有趣的事實是房間的價格取決於該日期飯店預期的滿房程度。
- Reservation Service:接收訂房請求並預訂飯店房間。此服務也會在房間被預訂或訂房被取消時追蹤房間庫存。
- Payment Service:執行客戶的付款,並在付款交易成功時將訂房狀態更新為「paid」,或在交易失敗時更新為「rejected」。
- Hotel Management Service:僅供經授權的飯店員工使用。飯店員工有資格使用以下功能:檢視即將到來的訂房紀錄、為客戶預訂房間、取消訂房等。
為了清晰起見,圖 4 省略了 microservice 之間許多互動箭頭。例如,如圖 5 所示,Reservation service 與 Rate service 之間應該要有一個箭頭。Reservation service 會向 Rate service 查詢房價,這用來計算一筆訂房的總房費。另一個例子是,Hotel Management Service 與大部分其他服務之間應該要有許多箭頭。當 admin 透過 Hotel Management Service 進行變更時,請求會被轉發到實際擁有資料的服務,以處理變更。

對於正式環境系統,跨服務通訊通常採用現代且高效能的 remote procedure call(RPC)框架,例如 gRPC。使用這類框架有許多好處。如果想特別了解 gRPC,請參考 [3]。
Step 3 - Design Deep Dive#
現在我們已經談過高階設計,讓我們深入下列內容。
- 改進的資料模型
- 併發問題
- 系統擴展
- 解決 microservice 架構中的資料不一致問題
Improved data model#
如同高階設計中提到的,當我們訂飯店房間時,實際上訂的是一個房型,而非特定房間。我們需要對 API 與 schema 做哪些變更來配合這一點?
對於訂房 API,請求參數中的 roomID 被 roomTypeID 取代。建立訂房的 API 看起來像這樣:
POST /v1/reservations請求參數:
{
"startDate": "2021-04-28",
"endDate": "2021-04-30",
"hotelID": "245",
"roomTypeID": "12354673389",
"roomCount": "3",
"reservationID": "13422445"
}更新後的 schema 如圖 6 所示。
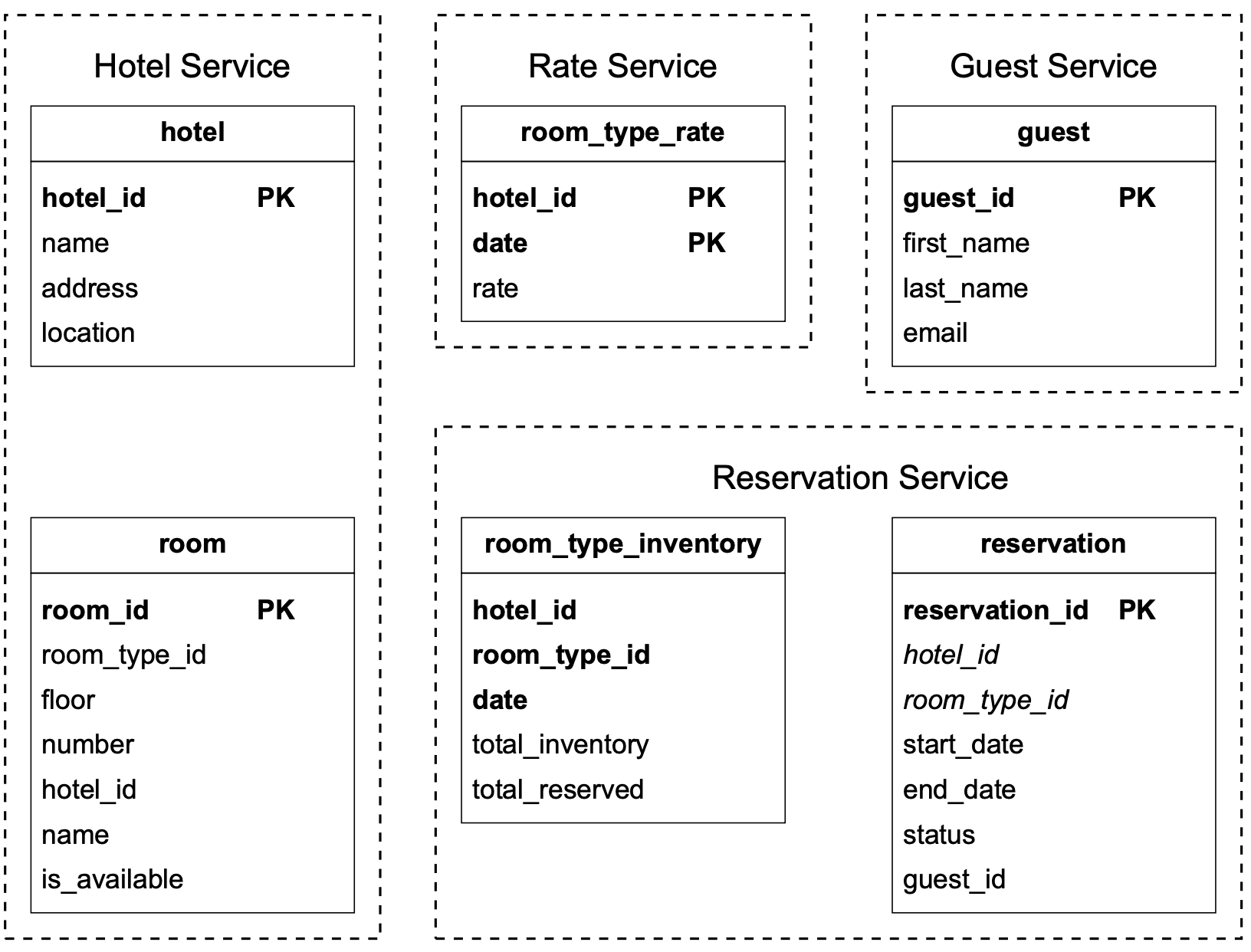
我們將簡要介紹幾個最重要的表。
- room:包含房間的資訊。
- room_type_rate:儲存特定房型未來日期的價格資料。
- reservation:記錄客人訂房資料。
- room_type_inventory:儲存飯店房間的庫存資料。此表對訂房系統非常重要,所以讓我們仔細看看每個欄位。
room_type_inventory 表的欄位說明如下:
- hotel_id:飯店的 ID
- room_type_id:房型的 ID。
- date:單一日期。
- total_inventory:總房間數,扣除暫時下架的房間。某些房間可能會因維修而從市場上下架。
- total_reserved:在指定的 hotel_id、room_type_id 與 date 下,已被預訂的房間總數。
設計 room_type_inventory 表還有其他方式,但每個日期一行的設計能讓在日期區間內管理訂房與查詢都變得容易。如圖 6 所示,(hotel_id, room_type_id, date) 是複合主鍵(composite primary key)。表中的列是透過查詢未來 2 年內所有日期的庫存資料預先填入的。我們有個排程的每日工作會在日期前推時預先填入庫存資料。
既然 schema 設計已經完成,讓我們對儲存量做點估算。如概略估算所提到的,我們有 5,000 間飯店。假設每間飯店有 20 種房型。那就是 (5000 hotels _ 20 types of rooms_ 2 years * 365 days) = 7300 萬列。
7300 萬列並不算多資料,單一資料庫就足以儲存這些資料。然而,單一伺服器代表單點故障。為了達到高可用性,我們可以跨多個區域或可用區設定資料庫複寫。
表 4 顯示「room_type_inventory」表的範例資料。
| hotel_id | room_type_id | date | total_inventory | total_reserved |
|---|---|---|---|---|
| 211 | 1001 | 2021-06-01 | 100 | 80 |
| 211 | 1001 | 2021-06-02 | 100 | 82 |
| 211 | 1001 | 2021-06-03 | 100 | 86 |
| 211 | 1001 | … | … | |
| 211 | 1001 | 2023-05-31 | 100 | 0 |
| 211 | 1002 | 2021-06-01 | 200 | 16 |
| 2210 | 101 | 2021-06-01 | 30 | 23 |
| 2210 | 101 | 2021-06-02 | 30 | 25 |
表 4 「room_type_inventory」表的範例資料
room_type_inventory 表用來檢查客戶能否預訂特定房型。一筆訂房的輸入與輸出可能像這樣:
- Input:startDate (2021-07-01)、endDate (2021-07-03)、roomTypeId、hotelId、numberOfRoomsToReserve
- Output:如果指定房型有庫存且使用者可以訂房,則為 True。否則回傳 false。
從 SQL 觀點來看,它包含以下兩個步驟:
- 選取日期區間內的列
SELECT date, total_inventory, total_reservedFROM room_type_inventoryWHERE room_type_id = ${roomTypeId} AND hotel_id = ${hotelId}AND date between ${startDate} and ${endDate}這個查詢回傳的資料像這樣:
| date | total_inventory | total_reserved |
|---|---|---|
| 2021-07-01 | 100 | 97 |
| 2021-07-02 | 100 | 96 |
| 2021-07-03 | 100 | 95 |
表 5 飯店庫存 2. 對每一筆紀錄,應用程式檢查以下條件:
if (total_reserved + ${numberOfRoomsToReserve}) <= total_inventory如果所有紀錄的條件都回傳 true,代表日期區間內每天都有足夠的房間。
其中一個需求是支援 10% 的超賣。有了新的 schema,這很容易實作:
if (total_reserved + ${numberOfRoomsToReserve}) <= 110% * total_inventory此時,面試官可能會問追加問題:「如果訂房資料對單一資料庫來說太大,你會怎麼做?」有幾種策略:
- 只儲存當前與未來的訂房資料。訂房歷史紀錄不常被存取,所以可以歸檔,有些甚至可以移到冷儲存。
- 資料庫分片(database sharding)。最常見的查詢包括建立訂房或依姓名查詢訂房。在這兩種查詢中,我們都需要先選擇飯店,意味著 hotel_id 是個好的 sharding key。資料可以依 hash(hotel_id) % number_of_servers 進行分片。
Concurrency issues#
另一個值得關注的重要問題是重複訂房。我們需要解決兩個問題:
- 同一個使用者多次點擊「book」按鈕。
- 多個使用者同時嘗試訂同一個房間。
讓我們先看第一個情境。如圖 7 所示,建立了兩筆訂房。

解決這個問題有兩種常見方法:
- 客戶端實作。客戶端可以在送出請求後將「submit」按鈕變灰、隱藏或停用。這應該大多數時候能避免重複點擊問題。然而,這個方法不太可靠。例如,使用者可以停用 JavaScript,從而繞過客戶端檢查。
- 冪等 API(Idempotent APIs)。在訂房 API 請求中加入 idempotency key。如果一個 API 呼叫無論呼叫多少次都會產生相同的結果,那它就是冪等的。圖 8 展示了如何使用 idempotency key(reservation_id)來避免重複訂房問題。詳細步驟如下說明。

產生一筆訂房單。在客戶輸入訂房的詳細資訊(房型、入住日期、退房日期等)並點擊「continue」按鈕後,由 reservation service 產生一筆訂房單。
系統為客戶產生一筆訂房單供其檢視。獨一無二的 reservation_id 由全域唯一 ID 產生器產生,並作為 API 回應的一部分回傳。此步驟的 UI 可能像這樣:
![圖 9 確認頁面(來源:[4])](figure-9-confirmation-page-EUDNWWUU.png)
3a. 提交訂房 1。reservation_id 作為請求的一部分被帶入。它是 reservation 表的主鍵(圖 6)。請注意,idempotency key 不一定要是 reservation_id。我們選擇 reservation_id 是因為它已經存在,且很適合我們的設計。
3b. 如果使用者第二次點擊「Complete my booking」按鈕,訂房 2 就會被提交。因為 reservation_id 是 reservation 表的主鍵,我們可以仰賴主鍵的唯一性限制來確保不會發生重複訂房。
圖 10 解釋了為什麼可以避免重複訂房。

情境 2:當只剩一間房時,多個使用者同時訂同一房型會發生什麼?讓我們考慮如圖 11 所示的情境。

- 假設資料庫的隔離等級不是 serializable [5]。User 1 和 User 2 同時嘗試訂同一房型,但只剩 1 間房。我們把 User 1 的執行稱為「transaction 1」,把 User 2 的執行稱為「transaction 2」。此時飯店有 100 間房,已預訂 99 間。
- Transaction 2 透過檢查 (total_reserved + rooms_to_book) <= total_inventory 來檢查是否有足夠的房間。由於還剩 1 間房,它回傳 true。
- Transaction 1 透過檢查 (total_reserved + rooms_to_book) <= total_inventory 來檢查是否有足夠的房間。由於還剩 1 間房,它也回傳 true。
- Transaction 1 預訂房間並更新庫存:reserved_room 變為 100。
- 接著 transaction 2 預訂房間。ACID 中的 isolation 屬性意味著資料庫交易必須獨立於其他交易完成各自的任務。所以在 transaction 1 完成(committed)之前,transaction 1 所做的資料變更對 transaction 2 是不可見的。因此 transaction 2 仍看到 total_reserved 為 99,並透過更新庫存來預訂房間:reserved_room 變為 100。這導致系統允許兩位使用者訂房,即使只剩 1 間房。
- Transaction 1 成功 commit 變更。
- Transaction 2 成功 commit 變更。
這個問題的解決方案通常需要某種形式的鎖定機制。我們探討以下技術:
- 悲觀鎖(Pessimistic locking)
- 樂觀鎖(Optimistic locking)
- 資料庫限制(Database constraints)
在跳到修正方案之前,讓我們先看看用來預訂房間的 SQL 虛擬碼。SQL 有兩個部分:
- 檢查房間庫存
- 預訂房間
# step 1: check room inventory
SELECT date, total_inventory, total_reserved
FROM room_type_inventory
WHERE room_type_id = ${roomTypeId} AND hotel_id = ${hotelId}
AND date between ${startDate} and ${endDate}
# For every entry returned from step 1
if((total_reserved + ${numberOfRoomsToReserve}) > 110% * total_inventory) {
Rollback
}
# step 2: reserve rooms
UPDATE room_type_inventory
SET total_reserved = total_reserved + ${numberOfRoomsToReserve}
WHERE room_type_id = ${roomTypeId}
AND date between ${startDate} and ${endDate}
CommitOption 1: Pessimistic locking#
悲觀鎖 [6],也稱為悲觀並行控制(pessimistic concurrency control),會在使用者開始更新記錄時就在該記錄上加鎖,以防止同時更新。其他試圖更新該記錄的使用者必須等到第一個使用者釋放鎖(commit 變更)後才能繼續。
對於 MySQL,「SELECT … FOR UPDATE」語句的運作方式是鎖定選取查詢回傳的列。假設由「transaction 1」啟動了一個交易。其他交易必須等 transaction 1 結束才能開始另一個交易。詳細說明如圖 12 所示。

在圖 12 中,transaction 2 的「SELECT … FOR UPDATE」語句會等待 transaction 1 完成,因為 transaction 1 鎖定了那些列。當 transaction 1 完成後,total_reserved 變為 100,意味著沒有房間給 user 2 訂了。
Pros:
- 防止應用程式更新正在被或已被變更的資料。
- 易於實作,且透過序列化更新來避免衝突。當資料競爭嚴重時,悲觀鎖很有用。
Cons:
- 鎖定多個資源時可能發生 deadlock。撰寫無 deadlock 的應用程式碼可能很有挑戰性。
- 此方法不具擴展性。如果一個交易被鎖定太久,其他交易就無法存取該資源。這對資料庫效能有重大影響,特別是當交易長時間存活或涉及大量實體時。
由於這些限制,我們不建議在訂房系統中使用悲觀鎖。
Option 2: Optimistic locking#
樂觀鎖 [7],也稱為樂觀並行控制(optimistic concurrency control),允許多個併發使用者嘗試更新同一個資源。
實作樂觀鎖有兩種常見方式:版本號(version number)與時間戳(timestamp)。一般認為版本號是較好的選項,因為伺服器時鐘長期下來可能不準確。我們解釋樂觀鎖如何透過版本號運作。
圖 13 展示了一個成功的案例與一個失敗的案例。

- 在資料庫表中加入新欄位「version」。
- 在使用者修改資料庫列之前,應用程式讀取該列的版本號。
- 當使用者更新該列時,應用程式將版本號加 1 並寫回資料庫。
- 加入資料庫驗證檢查;下一個版本號應該比目前版本號大 1。如果驗證失敗,交易就會中止,使用者從步驟 2 重試。
樂觀鎖通常比悲觀鎖快,因為我們不會鎖定資料庫。然而,當併發很高時,樂觀鎖的效能會劇烈下降。
要了解原因,考慮一下許多客戶端同時試圖訂同一飯店房間的情況。因為對多少客戶端可以讀取可用房間數沒有限制,所有客戶端都會讀回相同的可用房間數與目前版本號。當不同的客戶端進行訂房並把結果寫回資料庫時,只有一個會成功,其餘客戶端會收到版本檢查失敗訊息。這些客戶端必須重試。在後續的重試中,又只有一個成功的客戶端,其餘的必須再重試。雖然最終結果是正確的,但反覆重試會造成非常糟糕的使用者體驗。
Pros:
- 防止應用程式編輯過時的資料。
- 我們不需要鎖定資料庫資源。從資料庫的觀點來看,實際上沒有任何鎖定。完全由應用程式以版本號處理邏輯。
- 樂觀鎖一般用於資料競爭較低時。當衝突很罕見時,交易可以在不必管理鎖的開銷下完成。
Cons:
- 當資料競爭嚴重時效能很差。
樂觀鎖對於飯店訂房系統是個好選項,因為訂房的 QPS 通常不高。
Option 3: Database constraints#
這個方法與樂觀鎖非常相似。讓我們看看它如何運作。在 room_type_inventory 表中,加入以下限制:
CONSTRAINT `check_room_count` CHECK((`total_inventory - total_reserved` >= 0))如圖 14 所示的相同範例,當 user 2 嘗試訂房時,total_reserved 變為 101,這違反了 total_inventory (100) - total_reserved (101) >= 0 的限制。交易就會被回滾。

Pros
- 易於實作。
- 在資料競爭極低時運作良好。
Cons
- 與樂觀鎖類似,當資料競爭嚴重時,可能導致大量失敗。使用者可能看到還有房間,但當他們嘗試訂房時,得到「無可用房間」的回應。這種體驗對使用者來說可能很挫折。
- 資料庫限制不像應用程式碼那樣容易被版本控制。
- 並非所有資料庫都支援限制。當我們從一種資料庫方案遷移到另一種時,可能會造成問題。
由於這個方法易於實作,且飯店訂房的資料競爭通常不高(QPS 低),它是飯店訂房系統的另一個好選項。
Scalability#
通常飯店訂房系統的負載並不高。然而,面試官可能會問追加問題:「如果這個飯店訂房系統不只是用於連鎖飯店,而是用於像 booking.com 或 expedia.com 這樣的熱門旅遊網站呢?」在這種情況下,QPS 可能會高出 1,000 倍。
當系統負載很高時,我們需要了解什麼可能成為瓶頸。我們的所有服務都是無狀態的,因此可以透過增加更多伺服器輕易擴展。然而,資料庫包含所有狀態,無法單純透過增加更多資料庫來向上擴展。讓我們探討如何擴展資料庫。
Database sharding#
擴展資料庫的一個方法是套用資料庫分片(database sharding)。其想法是把資料拆分到多個資料庫,使每個資料庫只包含一部分資料。
當我們對資料庫進行分片時,需要考慮如何分配資料。從資料模型章節我們可以看到,大多數查詢都需要依 hotel_id 進行篩選。所以一個自然的結論是依 hotel_id 對資料進行分片。在圖 15 中,負載分散在 16 個分片中。假設 QPS 是 30,000。資料庫分片後,每個分片處理 30,000 / 16 = 1875 QPS,這在單一 MySQL 伺服器的負載能力範圍內。

Caching#
飯店庫存資料有個有趣的特性;只有當前與未來的飯店庫存資料是有意義的,因為客戶只能訂近期的房間。
所以在儲存的選擇上,理想上我們希望有 time-to-live(TTL)機制可以自動讓舊資料過期。歷史資料可以查詢另一個資料庫。Redis 是個好選擇,因為 TTL 與最近最少使用(Least Recently Used,LRU)的快取淘汰策略可以幫我們最佳化記憶體使用。
如果載入速度與資料庫擴展性成為問題(例如,我們是在 booking.com 或 expedia.com 的規模下設計),我們可以在資料庫之上加入一層快取,並把檢查房間庫存與預訂房間的邏輯移到快取層,如圖 16 所示。在這個設計中,只有少量百分比的請求會打到庫存資料庫,因為大多數不符合條件的請求都被庫存快取攔下。
值得一提的是,即使 Redis 中顯示有足夠庫存,我們仍需在資料庫端重新檢查庫存以防萬一。資料庫是庫存資料的真實來源(source of truth)。
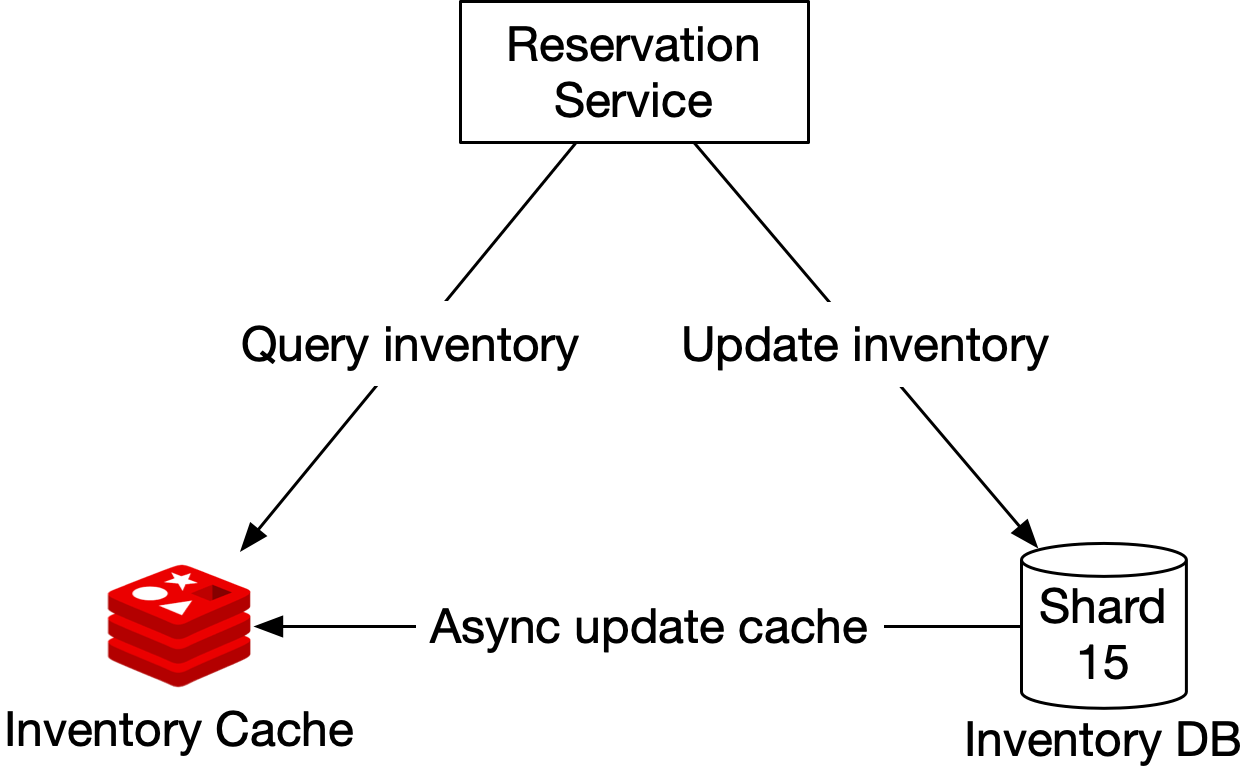
讓我們先檢視這個系統的每個元件。
Reservation service:支援以下庫存管理 API:
- 查詢給定 hotel ID、房型與日期區間的可用房間數。
- 透過執行 total_reserved + 1 來預訂房間。
- 當使用者取消訂房時更新庫存。
Inventory cache:所有庫存管理查詢操作都被移到 inventory cache(Redis),我們需要把庫存資料預先填到快取中。快取是個 key-value 儲存,結構如下:
key: hotelID_roomTypeID_{date}
value: 給定 hotel ID、房型 ID 與日期下的可用房間數。對於飯店訂房系統,讀取操作(檢查房間庫存)的數量比寫入操作高出一個數量級。大多數讀取操作由快取回應。
Inventory DB:儲存庫存資料作為真實來源。
New challenges posed by the cache
加入快取層大幅提升了系統的擴展性與吞吐量,但也引入了一個新挑戰:如何維持資料庫與快取之間的資料一致性。
當使用者訂房時,在 happy path 中會執行兩個操作:
- 查詢房間庫存以了解是否還有足夠的房間。查詢在 Inventory cache 上執行。
- 更新庫存資料。先更新 Inventory DB。變更接著非同步傳播到快取。這個非同步快取更新可以由應用程式碼觸發,在資料儲存到資料庫後更新 inventory cache。也可以使用 change data capture(CDC)[8] 來傳播。CDC 是一種從資料庫讀取資料變更並將變更套用到另一個資料系統的機制。一個常見的方案是 Debezium [9]。它使用 source connector 從資料庫讀取變更並套用到像 Redis 之類的快取方案 [10]。
由於庫存資料是先在資料庫上更新,因此快取有可能無法反映最新的庫存資料。例如,當資料庫顯示沒有房間時,快取可能仍報告有空房,反之亦然。
如果你仔細思考,會發現只要資料庫做最終的庫存驗證檢查,inventory cache 與資料庫之間的不一致實際上並不重要。
讓我們看個例子。假設快取顯示還有空房,但資料庫說沒有。在這種情況下,當使用者查詢房間庫存時,他們發現還有房間可用,所以嘗試訂房。當請求抵達庫存資料庫時,資料庫進行驗證並發現沒有剩餘房間。在這種情況下,客戶端收到錯誤,指示有別人剛在他們之前訂走了最後一間房。當使用者重新整理網站時,他們可能看到沒有剩餘房間,因為在他們點擊重新整理按鈕之前,資料庫已將庫存資料同步到快取。
Pros
- 減少資料庫負載。由於讀取查詢由快取層回應,資料庫負載大幅減少。
- 高效能。讀取查詢非常快,因為結果是從記憶體擷取的。
Cons
- 維持資料庫與快取之間的資料一致性很困難。我們需要仔細思考這種不一致如何影響使用者體驗。
Data consistency among services#
在傳統的單體式架構(monolithic architecture)[11] 中,使用共用的關聯式資料庫來確保資料一致性。在我們的 microservice 設計中,我們選擇了一個混合方法,讓 Reservation Service 同時處理訂房與庫存 API,使庫存與訂房資料庫表儲存在同一個關聯式資料庫中。如「Concurrency Issues」章節所說明的,這種安排讓我們得以利用關聯式資料庫的 ACID 屬性,優雅地處理在訂房流程中出現的許多併發問題。
然而,如果你的面試官是 microservice 純粹主義者,他們可能會挑戰這種混合方法。在他們心中,對於 microservice 架構,每個 microservice 都應該有自己的資料庫,如圖 17 右側所示。

這種純粹的設計會引入許多資料一致性問題。由於這是我們第一次涵蓋 microservice,讓我們解釋這如何發生以及為何發生。為了更易於理解,這個討論中只用了兩個服務。在現實世界中,一家公司內可能有數百個 microservice。在單體架構中,如圖 18 所示,不同的操作可以包裝在單一交易中以確保 ACID 屬性。

然而,在 microservice 架構中,每個服務都有自己的資料庫。一個邏輯上的原子操作可能跨越多個服務。這意味著我們無法用單一交易來確保資料一致性。如圖 19 所示,如果在 reservation 資料庫中的更新操作失敗,我們需要在 inventory 資料庫中回滾已預訂的房間數。一般來說只有一條 happy path,但有許多失敗情境可能造成資料不一致。

為了解決資料不一致,這裡是業界證實有效的技術的高階摘要。如果想閱讀細節,請參考參考資料。
- 兩階段提交(Two-phase commit,2PC)[12]。2PC 是一種資料庫協定,用來保證跨多個節點的原子交易提交,亦即所有節點全部成功或全部失敗。因為 2PC 是阻塞式協定,單一節點故障會阻擋進度,直到該節點復原。它的效能不佳。
- Saga。saga 是一系列的本地交易。每筆交易都會更新並發布訊息來觸發下一個交易步驟。如果某個步驟失敗,saga 會執行補償交易來撤銷之前交易所做的變更 [13]。2PC 作為單一 commit 來執行 ACID 交易,而 Saga 由多個步驟組成且依賴最終一致性。
值得注意的是,解決 microservice 間資料不一致需要一些複雜的機制,這會大幅增加整體設計的複雜度。架構師要決定增加的複雜度是否值得。對於這個問題,我們認為不值得,所以採取了更務實的方法,把訂房與庫存資料儲存在同一個關聯式資料庫之下。
Step 4 - Wrap Up#
本章我們提出了飯店訂房系統的設計。我們從蒐集需求並計算概略估算開始,以了解規模。在高階設計中,我們提出了 API 設計、資料模型的初稿與系統架構圖。在深入探討中,我們探索了替代的資料庫 schema 設計,因為我們意識到訂房應該以房型為單位,而非特定房間。我們深入討論了競態條件並提出了幾個可能的解決方案:
- 悲觀鎖
- 樂觀鎖
- 資料庫限制
我們接著討論了擴展系統的不同方法,包括資料庫分片與使用 Redis 快取。最後,我們處理了 microservice 架構中的資料一致性問題,並簡要瀏覽了幾種解決方案。
恭喜你看到這裡!現在請給自己拍拍背。做得很好!
#
Chapter Summary#