隨著 Facebook、YouTube、TikTok 與線上媒體經濟的興起,數位廣告在整體廣告支出中所佔的比重越來越大。因此,追蹤廣告點擊事件變得相當重要。本章我們將探討如何在 Facebook 或 Google 規模下設計廣告點擊事件聚合系統。
在深入技術設計之前,先了解線上廣告的核心概念,有助於我們更好地理解這個主題。線上廣告的核心優勢之一,就是其可衡量性,可以透過即時資料來量化。
數位廣告有一個核心流程稱為即時競價(Real-Time Bidding,RTB),數位廣告版位在此流程中被買賣。圖 1 展示了線上廣告流程的運作方式。

RTB 流程的速度非常重要,通常在不到一秒內就要完成。
資料準確性同樣非常重要。廣告點擊事件聚合在衡量線上廣告成效上扮演關鍵角色,這實際上影響了廣告主要支付多少費用。根據點擊聚合結果,廣告活動經理可以控制預算或調整競價策略,例如改變目標受眾群、關鍵字等。線上廣告中使用的關鍵指標,包括點擊率(click-through rate,CTR)[1] 與轉換率(conversion rate,CVR)[2],都依賴於聚合後的廣告點擊資料。
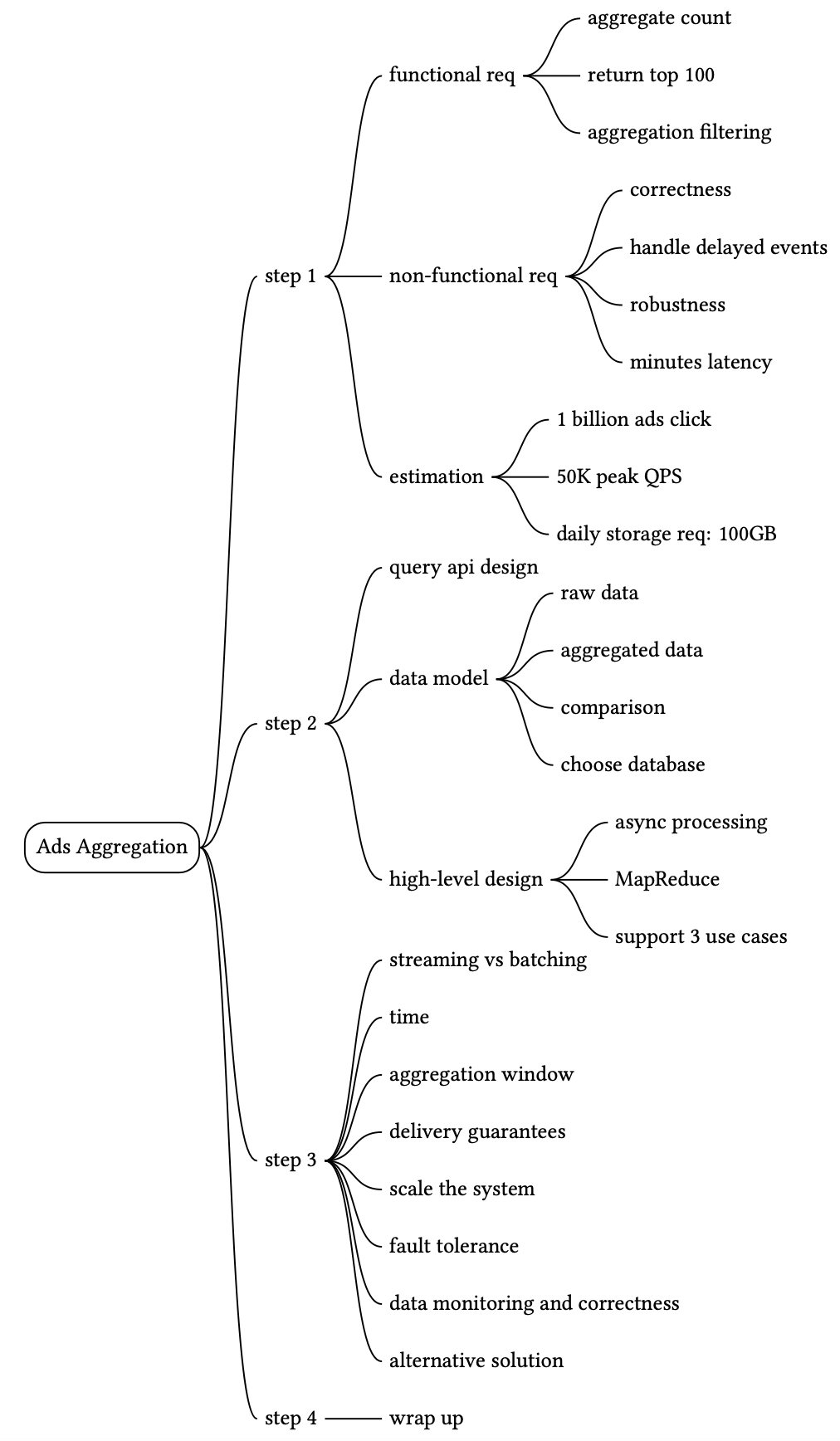
Step 1 - Understand the Problem and Establish Design Scope#
下列問題有助於釐清需求並縮小範圍。
應徵者:輸入資料的格式是什麼?
面試官:是位於不同伺服器上的 log 檔,最新的點擊事件會被附加到 log 檔的尾端。事件包含以下屬性:ad_id、click_timestamp、user_id、ip 與 country。
應徵者:資料量有多大?
面試官:每日 10 億次廣告點擊,總共 200 萬個廣告。廣告點擊事件數量每年成長 30%。
應徵者:需要支援哪些重要的查詢?
面試官:系統需要支援以下 3 種查詢:
- 回傳特定廣告在過去 M 分鐘內的點擊事件數量。
- 回傳過去 1 分鐘內被點擊次數最多的前 100 個廣告。兩個參數都應可設定。每分鐘進行一次聚合。
- 上述兩種查詢需支援以 ip、user_id 或 country 進行資料篩選。
應徵者:我們需要考慮邊界情況嗎?我能想到以下幾點:
- 可能會有比預期更晚抵達的事件。
- 可能會有重複的事件。
- 系統的不同部分可能在任何時間發生故障,因此我們需要考慮系統復原。
面試官:這是個不錯的清單。是的,請把這些都納入考量。
應徵者:延遲需求是什麼?
面試官:端到端延遲在幾分鐘以內。請注意,RTB 與廣告點擊聚合的延遲需求非常不同。RTB 由於響應性的需求,延遲通常少於一秒;而廣告點擊事件聚合主要用於廣告計費與報表,因此幾分鐘的延遲是可接受的。
根據以上收集到的資訊,我們同時擁有功能性與非功能性需求。
Functional requirements#
- 聚合 ad_id 在過去 M 分鐘內的點擊次數。
- 每分鐘回傳被點擊次數最多的前 100 個 ad_id。
- 支援以不同屬性進行聚合篩選。
- 資料集規模達到 Facebook 或 Google 等級(詳細的系統規模需求請參閱下方的概略估算章節)。
Non-functional requirements#
- 聚合結果的正確性很重要,因為資料會用於 RTB 與廣告計費。
- 妥善處理延遲或重複事件。
- 健壯性。系統應能容忍部分故障。
- 延遲需求。端到端延遲最多應為幾分鐘。
Back-of-the-envelope estimation#
讓我們做個估算,以了解系統規模以及將來必須處理的潛在挑戰。
- 10 億 DAU。
- 假設平均每位使用者每天點擊 1 個廣告。也就是每天 10 億次廣告點擊事件。
- 廣告點擊 QPS = 10^9 events / 10^5 seconds in a day = 10,000
- 假設尖峰廣告點擊 QPS 是平均值的 5 倍。尖峰 QPS = 50,000 QPS。
- 假設單一廣告點擊事件佔用 0.1 KB 儲存空間。每日儲存需求為:0.1 KB * 10 億 = 100 GB。每月儲存需求約為 3 TB。
Step 2 - Propose High-Level Design and Get Buy-In#
本節我們將討論查詢 API 設計、資料模型與高階設計。
Query API design#
API 設計的目的是要在客戶端與伺服器之間建立共識。在消費者應用中,客戶端通常是使用產品的終端使用者。然而在我們的案例中,客戶端是針對聚合服務執行查詢的儀表板使用者(資料科學家、產品經理、廣告主等)。
讓我們回顧功能性需求,以便更好地設計 API:
- 聚合 ad_id 在過去 M 分鐘內的點擊次數。
- 回傳過去 M 分鐘內被點擊次數最多的前 N 個 ad_id。
- 支援以不同屬性進行聚合篩選。
我們只需要兩個 API 即可支援這三種使用情境,因為篩選功能(最後一項需求)可以透過在請求中加入查詢參數來支援。
API 1:聚合 ad_id 在過去 M 分鐘內的點擊次數。
| API | Detail |
|---|---|
| GET /v1/ads/{:ad_id}/aggregated_count | 回傳指定 ad_id 的聚合事件數 |
表 1 用於聚合點擊次數的 API
請求參數為:
| Field | Description | Type |
|---|---|---|
| from | 起始分鐘(預設為現在減 1 分鐘) | long |
| to | 結束分鐘(預設為現在) | long |
| filter | 不同篩選策略的識別碼。例如,filter = 001 會過濾掉非美國的點擊 | long |
表 2 /v1/ads/{:ad_id}/aggregated_count 的請求參數
回應:
| Field | Description | Type |
|---|---|---|
| ad_id | 廣告的識別碼 | string |
| count | 起始與結束分鐘之間的聚合計數 | long |
表 3 /v1/ads/{:ad_id}/aggregated_count 的回應
API 2:回傳過去 M 分鐘內被點擊次數最多的前 N 個 ad_id
| API | Detail |
|---|---|
| GET /v1/ads/popular_ads | 回傳過去 M 分鐘內被點擊次數最多的前 N 個廣告 |
表 4 /v1/ads/popular_ads 的 API
請求參數為:
| Field | Description | Type |
|---|---|---|
| count | 被點擊次數最多的前 N 個廣告 | integer |
| window | 聚合視窗大小(M),以分鐘為單位 | integer |
| filter | 不同篩選策略的識別碼 | long |
表 5 /v1/ads/popular_ads 的請求參數
回應:
| Field | Description | Type |
|---|---|---|
| ad_ids | 被點擊次數最多的廣告清單 | array |
表 6 /v1/ads/popular_ads 的回應
Data model#
系統中有兩種資料:原始資料與聚合資料。
Raw data#
下面顯示原始資料在 log 檔中的樣子:
[AdClickEvent] ad001, 2021-01-01 00:00:01, user 1, 207.148.22.22, USA表 7 以結構化方式列出資料欄位的樣子。資料分散在不同的應用伺服器上。
| ad_id | click_timestamp | user | ip | country |
|---|---|---|---|---|
| ad001 | 2021-01-01 00:00:01 | user1 | 207.148.22.22 | USA |
| ad001 | 2021-01-01 00:00:02 | user1 | 207.148.22.22 | USA |
| ad002 | 2021-01-01 00:00:02 | user2 | 209.153.56.11 | USA |
表 7 原始資料
Aggregated data#
假設廣告點擊事件每分鐘聚合一次。表 8 顯示聚合後的結果。
| ad_id | click_minute | count |
|---|---|---|
| ad001 | 202101010000 | 5 |
| ad001 | 202101010001 | 7 |
表 8 聚合資料
為了支援廣告篩選,我們在表中加入額外的欄位 filter_id。具有相同 ad_id 與 click_minute 的記錄會依 filter_id 分組,如表 9 所示,篩選器則定義於表 10。
| ad_id | click_minute | filter_id | count |
|---|---|---|---|
| ad001 | 202101010000 | 0012 | 2 |
| ad001 | 202101010000 | 0023 | 3 |
| ad001 | 202101010001 | 0012 | 1 |
| ad001 | 202101010001 | 0023 | 6 |
表 9 帶有篩選器的聚合資料
| filter_id | region | IP | user_id |
|---|---|---|---|
| 0012 | US | * | * |
| 0013 | * | 123.1.2.3 | * |
表 10 篩選器表
為了支援查詢「過去 M 分鐘內被點擊次數最多的前 N 個廣告」,我們使用以下結構。
| most_clicked_ads | ||
|---|---|---|
| window_size | integer | 聚合視窗大小(M),以分鐘為單位 |
| update_time_minute | timestamp | 最後更新時間戳(粒度為 1 分鐘) |
| most_clicked_ads | array | JSON 格式的廣告 ID 清單。 |
表 11 支援過去 M 分鐘內被點擊次數最多的前 N 個廣告
Comparison#
儲存原始資料與聚合資料的比較如下:
| Raw data only | Aggregated data only | |
|---|---|---|
| Pros | - 完整資料集 | |
| - 支援資料篩選與重新計算 | - 較小的資料集 | |
| - 查詢快速 | ||
| Cons | - 龐大的資料儲存 | |
| - 查詢緩慢 | - 資料遺失。這是衍生資料。例如,10 筆紀錄 | |
| 可能被聚合為 1 筆 |
表 12 原始資料 vs 聚合資料
我們應該儲存原始資料還是聚合資料呢?我們的建議是兩者都儲存。讓我們看看為什麼。
- 保留原始資料是個好主意。如果出了問題,我們可以使用原始資料來除錯。如果聚合資料因嚴重的 bug 而毀損,我們可以在 bug 修復後從原始資料重新計算聚合資料。
- 聚合資料也應該儲存。原始資料的資料量很大。龐大的資料量讓直接查詢原始資料變得非常沒有效率。為緩解此問題,我們在聚合資料上執行讀取查詢。
- 原始資料作為備份資料。除非需要重新計算,否則通常不需要查詢原始資料。舊的原始資料可以移到冷儲存以降低成本。
- 聚合資料則作為活躍資料。它經過調整以獲得查詢效能。
Choose the right database#
在選擇合適的資料庫時,我們需要評估以下幾點:
- 資料長什麼樣?資料是關聯式的嗎?是文件還是 blob?
- 工作流程是讀取偏重、寫入偏重,還是兩者皆是?
- 是否需要交易支援?
- 查詢是否依賴許多線上分析處理(OLAP)函式 [3],例如 SUM、COUNT?
讓我們先檢視原始資料。雖然在正常運作期間我們不需要查詢原始資料,但對資料科學家或機器學習工程師來說,研究使用者反應預測、行為定向、相關性回饋等議題時,這些資料是很有用的 [4]。
如概略估算所示,平均寫入 QPS 為 10,000,尖峰 QPS 可達 50,000,因此系統屬於寫入偏重。在讀取方面,原始資料用作備份與重新計算的來源,因此理論上讀取量很低。
關聯式資料庫可以勝任,但擴展寫入會很有挑戰性。NoSQL 資料庫,例如 Cassandra 與 InfluxDB 更為適合,因為它們針對寫入與時間範圍查詢做了最佳化。
另一個選項是將資料以欄式資料格式(例如 ORC [5]、Parquet [6] 或 AVRO [7])儲存在 Amazon S3 上。我們可以對每個檔案的大小設定上限(例如 10GB),負責寫入原始資料的串流處理器在達到大小上限時可以處理檔案輪替。由於這種設定對許多人來說可能不熟悉,本設計中我們以 Cassandra 為例。
至於聚合資料,本質上是時間序列資料,工作流程同時讀取與寫入偏重。這是因為對每個廣告,我們需要每分鐘查詢資料庫以向客戶顯示最新的聚合計數。此功能對於儀表板自動更新或及時觸發警示很有用。由於總共有 200 萬個廣告,因此工作流程屬於讀取偏重。資料由聚合服務每分鐘聚合並寫入,因此也是寫入偏重。我們可以使用相同類型的資料庫來儲存原始資料與聚合資料。
現在我們已經討論完查詢 API 設計與資料模型,讓我們把高階設計組合起來。
High-level design#
在即時大數據 [8] 處理中,資料通常以無界資料串流的形式流入與流出處理系統。聚合服務也以同樣的方式運作;輸入是原始資料(無界資料串流),輸出是聚合結果(請見圖 2)。

Asynchronous processing#
我們目前的設計是同步的。這並不好,因為生產者與消費者的容量並不總是相等。考慮以下情況;如果流量突然增加,產生的事件數量遠超過消費者能處理的範圍,消費者可能會發生記憶體不足錯誤或非預期的關閉。如果同步鏈中的某個元件故障,整個系統就會停止運作。
常見的解決方案是採用訊息佇列(Kafka)來解耦生產者與消費者。這讓整個流程變成非同步,且生產者與消費者可以獨立擴展。
把我們已經討論過的內容都組合起來,可以得到圖 3 所示的高階設計。Log watcher、聚合服務與資料庫透過兩個訊息佇列解耦。資料庫寫入器從訊息佇列輪詢資料,將資料轉換為資料庫格式,並寫入資料庫。

第一個訊息佇列中儲存什麼?它包含廣告點擊事件資料,如表 13 所示。
| ad_id | click_timestamp | user_id | ip | country |
|---|
表 13 第一個訊息佇列中的資料
第二個訊息佇列中儲存什麼?第二個訊息佇列包含兩種資料:
- 以每分鐘粒度聚合的廣告點擊次數。
| ad_id | click_minute | count |
|---|
表 14 第二個訊息佇列中的資料
- 以每分鐘粒度聚合的被點擊次數最多的前 N 個廣告。
| update_time_minute | most_clicked_ads |
|---|
表 15 第二個訊息佇列中的資料
你可能會疑惑為什麼我們不直接把聚合結果寫入資料庫。簡短的答案是,我們需要像 Kafka 這樣的第二個訊息佇列來達成端到端的 exactly-once 語意(atomic commit)。

接下來,讓我們深入了解聚合服務的細節。
Aggregation service#
MapReduce 框架是聚合廣告點擊事件的好選項。有向無環圖(directed acyclic graph,DAG)是它的好模型 [9]。DAG 模型的關鍵在於將系統拆解為小的計算單元,例如 Map/Aggregate/Reduce 節點,如圖 5 所示。

每個節點負責一項單一任務,並把處理結果送給其下游節點。
Map node
Map 節點從資料來源讀取資料,然後篩選並轉換資料。例如,Map 節點將 ad_id % 2 = 0 的廣告送到節點 1,其他廣告送到節點 2,如圖 6 所示。

你可能會疑惑為什麼需要 Map 節點。另一個替代選項是設定 Kafka 分區或標籤,讓 aggregate 節點直接訂閱 Kafka。這是可行的,但輸入資料可能需要被清理或正規化,這些操作可以由 Map 節點完成。另一個原因是我們可能無法控制資料如何被產生,因此具有相同 ad_id 的事件可能落到不同的 Kafka 分區中。
Aggregate node
Aggregate 節點每分鐘在記憶體中依 ad_id 計算廣告點擊事件的數量。在 MapReduce 範式中,Aggregate 節點是 Reduce 的一部分。所以 map-aggregate-reduce 流程實際上是 map-reduce-reduce。
Reduce node
Reduce 節點將所有「Aggregate」節點的聚合結果歸約為最終結果。例如,如圖 7 所示,有三個 aggregation 節點,每個節點包含該節點內被點擊次數最多的前 3 個廣告。Reduce 節點將被點擊次數最多的廣告總數歸約為 3 個。

DAG 模型代表了眾所周知的 MapReduce 範式。它的設計目的是接收大數據,並使用平行分散式計算將大數據轉換為小型或常規大小的資料。
在 DAG 模型中,中間資料可以儲存在記憶體中,不同節點之間透過 TCP(節點在不同的程序中執行)或共享記憶體(節點在不同的執行緒中執行)相互通訊。
Main use cases#
現在我們已經高層次地理解了 MapReduce 的運作方式,接下來看看如何利用它來支援主要使用情境:
- 聚合 ad_id 在過去 M 分鐘內的點擊次數。
- 回傳過去 M 分鐘內被點擊次數最多的前 N 個 ad_id。
- 資料篩選。
Use case 1: aggregate the number of clicks#
如圖 8 所示,輸入事件在 Map 節點中以 ad_id 進行分區(ad_id % 3),然後由 Aggregation 節點進行聚合。

Use case 2: return top N most clicked ads#
圖 9 展示了取得被點擊次數最多的前 3 個廣告的簡化設計,可以擴展為前 N 個。輸入事件以 ad_id 進行 map,每個 Aggregate 節點維護一個 heap 資料結構,以有效率地取得該節點內前 3 名的廣告。在最後一步,Reduce 節點將 9 個廣告(每個 aggregate 節點的前 3 個)歸約為每分鐘被點擊次數最多的前 3 個廣告。

Use case 3: data filtering#
為了支援像「只顯示美國境內 ad001 的聚合點擊計數」這樣的資料篩選,我們可以預先定義篩選條件並依此進行聚合。例如,ad001 與 ad002 的聚合結果如下:
| ad_id | click_minute | country | count |
|---|---|---|---|
| ad001 | 202101010001 | USA | 100 |
| ad001 | 202101010001 | GPB | 200 |
| ad001 | 202101010001 | others | 3000 |
| ad002 | 202101010001 | USA | 10 |
| ad002 | 202101010001 | GPB | 25 |
| ad002 | 202101010001 | others | 12 |
表 16 聚合結果(依國家篩選)
這種技術稱為星型結構(star schema)[11],廣泛用於資料倉儲。篩選欄位稱為維度(dimension)。這種方法有以下優點:
- 易於理解與建構。
- 現有的聚合服務可以重複使用,以建立星型結構中更多的維度。不需要額外的元件。
- 基於篩選條件存取資料很快,因為結果是預先計算的。
這種方法的限制是會建立更多的桶與紀錄,特別是當我們有許多篩選條件時。
Step 3 - Design Deep Dive#
本節我們將深入探討以下內容:
- 串流 vs 批次
- 時間與聚合視窗
- 傳遞保證
- 系統擴展
- 資料監控與正確性
- 最終設計圖
- 容錯
Streaming vs batching#
我們在圖 3 提出的高階架構是一種串流處理系統。表 17 展示了三種類型系統的比較 [12]:
| Services (Online system) | Batch system (offline system) | Streaming system (near real-time system) | |
|---|---|---|---|
| Responsiveness | 快速回應客戶端 | 不需要回應客戶端 | 不需要回應客戶端 |
| Input | 使用者請求 | 有限大小的有界輸入。大量資料 | 沒有邊界的輸入(無限串流) |
| Output | 對客戶端的回應 | 物化檢視、聚合指標等 | 物化檢視、聚合指標等 |
| Performance measurement | 可用性、 |
延遲 | 吞吐量 | 吞吐量、延遲 | | Example | 線上購物 | MapReduce | Flink [13] |
表 17 三種類型系統的比較
在我們的設計中,串流處理與批次處理都會用到。我們利用串流處理在資料抵達時立即處理,並以接近即時的方式產生聚合結果。我們利用批次處理進行歷史資料備份。
對於同時包含兩條處理路徑(批次與串流)的系統,這種架構稱為 lambda [14]。lambda 架構的缺點是有兩條處理路徑,意味著需要維護兩套程式碼。Kappa 架構 [15] 將批次與串流合併在一條處理路徑中,解決了這個問題。其關鍵想法是使用單一串流處理引擎來處理即時資料處理與持續資料重新處理。圖 10 展示了 lambda 與 kappa 架構的比較。

我們的高階設計使用 Kappa 架構,歷史資料的重新處理也會經過即時聚合服務。詳情請見下方的「資料重新計算」章節。
Data recalculation
有時我們必須重新計算聚合資料,這也稱為歷史資料重播。例如,如果我們發現聚合服務中有重大 bug,我們需要從 bug 引入的時間點開始,從原始資料重新計算聚合資料。圖 11 展示了資料重新計算流程:
- 重新計算服務從原始資料儲存中取得資料。這是個批次工作。
- 取得的資料被送到專用的聚合服務,這樣即時處理就不會受到歷史資料重播的影響。
- 聚合結果被送到第二個訊息佇列,然後更新到聚合資料庫。

重新計算流程重複使用資料聚合服務,但使用不同的資料來源(原始資料)。
Time#
我們需要時間戳來執行聚合。時間戳可以在兩個不同的地方產生:
- Event time:廣告點擊發生的時間。
- Processing time:處理點擊事件的聚合伺服器系統時間。
由於網路延遲與非同步環境(資料會經過訊息佇列),事件時間與處理時間之間的差距可能很大。如圖 12 所示,event 1 抵達聚合服務的時間非常晚(晚了 5 小時)。

如果使用 event time 進行聚合,我們必須處理延遲事件。如果使用 processing time 進行聚合,聚合結果可能不夠準確。沒有完美的解決方案,所以我們需要考慮取捨。
| Pros | Cons | |
|---|---|---|
| Event time | 聚合結果更準確,因為客戶端確切知道廣告何時被點擊 | 它依賴於客戶端產生的時間戳。客戶端可能時間錯誤,或時間戳可能由惡意使用者產生 |
| Processing time | 伺服器時間戳更可靠 | 如果事件抵達系統的時間晚很多,時間戳就不準確 |
表 18:Event time vs processing time
由於資料準確性非常重要,我們建議使用 event time 進行聚合。在這種情況下,我們要如何妥善處理延遲事件呢?通常會使用一種稱為「watermark」的技術來處理輕微延遲的事件。
在圖 13 中,廣告點擊事件以一分鐘的滾動視窗(tumbling window)進行聚合(詳情見「聚合視窗」章節)。如果使用 event time 來決定事件是否屬於視窗,window 1 會錯過 event 2,window 3 會錯過 event 5,因為它們抵達的時間略晚於其聚合視窗的結束時間。

緩解此問題的方法之一是使用「watermark」(圖 14 中延伸的矩形),它被視為聚合視窗的延伸。這提升了聚合結果的準確性。透過額外延伸 15 秒(可調整)的聚合視窗,window 1 能夠包含 event 2,window 3 能夠包含 event 5。
watermark 設定的值取決於業務需求。較長的 watermark 可以捕捉到非常晚抵達的事件,但會為系統增加更多延遲。較短的 watermark 意味著資料準確性較低,但會為系統增加較少延遲。

請注意,watermark 技術無法處理長時間延遲的事件。我們可以主張,為低機率事件設計複雜的方案不值得投資報酬率(ROI)。我們可以隨時透過日終對帳(請見對帳章節)來修正那一點點的不準確性。需要考慮的取捨是,使用 watermark 雖然提升了資料準確性,但因為等待時間延長,整體延遲也會增加。
Aggregation window#
根據 Martin Kleppmann 的著作《Designing data-intensive applications》[16],視窗函式有四種類型:
- 滾動視窗(tumbling window,也稱為固定視窗)
- 跳動視窗(hopping window)
- 滑動視窗(sliding window)
- 會話視窗(session window)
我們將討論滾動視窗與滑動視窗,因為它們與我們的系統最相關。
在滾動視窗(圖 15 中標記)中,時間被切分成相同長度、不重疊的區塊。滾動視窗很適合每分鐘聚合廣告點擊事件(使用情境 1)。

在滑動視窗(圖 16 中標記)中,事件依指定的間隔在資料串流上滑動的視窗內被分組。滑動視窗可以是重疊的。這是滿足我們第二個使用情境(取得過去 M 分鐘內被點擊次數最多的前 N 個廣告)的好策略。

#
Delivery guarantees#
由於聚合結果用於計費,資料的準確性與完整性非常重要。系統需要能夠回答以下問題:
- 如何避免處理重複事件?
- 如何確保所有事件都被處理?
像 Kafka 這樣的訊息佇列通常提供三種傳遞語意:at-most once、at-least once 與 exactly once。
我們應該選擇哪種傳遞方法?
在大多數情況下,如果可以接受少量百分比的重複,at-least once 處理就已經足夠好了。
然而,這對我們的系統來說並不適用。資料中幾個百分點的差異就可能造成數百萬美元的差距。因此,我們建議系統使用 exactly-once 傳遞。如果你有興趣了解真實的廣告聚合系統,可以看看 Yelp 是怎麼實作的 [17]。
Data deduplication#
最常見的資料品質問題之一就是重複資料。重複資料可能來自各種來源,本節我們將討論兩種常見來源。
- 客戶端。例如,客戶端可能多次重送相同的事件。出於惡意意圖的重複事件最好由廣告詐騙/風險控管元件處理。如果有興趣,請參考參考資料 [18]。
- 伺服器中斷。如果聚合服務節點在聚合過程中故障,且上游服務尚未收到確認,相同的事件可能會被再次傳送與聚合。讓我們仔細看看。
圖 17 展示了聚合服務節點(Aggregator)中斷如何導致重複資料。Aggregator 透過儲存上游 Kafka 的 offset 來管理資料消費的狀態。

如果第 6 步失敗,可能因為 Aggregator 中斷,事件 100 到 110 已經被送到下游,但新的 offset 110 並未持久化到上游 Kafka。在這種情況下,新的 Aggregator 會再次從 offset 100 開始消費,即使這些事件已經被處理過,造成重複資料。
最直接的解決方案(圖 18)是使用外部檔案儲存,例如 HDFS 或 S3,來記錄 offset。然而,這個方案也有問題。

在第 3 步中,aggregator 只有在外部儲存中儲存的最後 offset 是 100 的情況下,才會處理 offset 100 到 110 的事件。如果儲存中儲存的 offset 是 110,aggregator 會忽略 offset 110 之前的事件。
但這個設計有個重大問題:offset 在聚合結果送到下游之前(步驟 3.2)就已經儲存到 HDFS / S3。如果第 4 步因為 Aggregator 中斷而失敗,事件 100 到 110 將永遠不會被新啟動的 aggregator 節點處理,因為外部儲存中儲存的 offset 是 110。
為了避免資料遺失,我們需要在收到下游的確認回覆後才儲存 offset。更新後的設計如圖 19 所示。

在這個設計中,如果 Aggregator 在步驟 5.1 執行之前故障,事件 100 到 110 會再次被送到下游。為了達成「exactly-once」處理,我們需要把第 4 步到第 6 步之間的操作放在一個分散式交易中。分散式交易是跨多個節點運作的交易。如果任何一個操作失敗,整個交易就會被回滾。

如你所見,在大規模系統中對資料進行去重並不容易。如何達成 exactly-once 處理是個進階主題。如果你對細節有興趣,請參考參考資料 [19]。
Scale the system#
從概略估算我們得知業務每年成長 30%,每 3 年流量翻倍。我們要如何處理這種成長?讓我們看看。
我們的系統包含三個獨立的元件:訊息佇列、聚合服務與資料庫。由於這些元件是解耦的,我們可以獨立擴展每一個。
Scale the message queue#
我們已在「Distributed Message Queue」章節廣泛討論過如何擴展訊息佇列,所以這裡只會簡要提及幾點。
Producers。我們不限制生產者實例的數量,所以生產者的可擴展性很容易達成。
Consumers。在 consumer group 內,rebalancing 機制透過增加或移除節點來協助擴展消費者。如圖 21 所示,再加入兩個消費者後,每個消費者只處理來自一個分區的事件。

當系統中有數百個 Kafka 消費者時,consumer rebalance 可能會相當緩慢,可能需要幾分鐘甚至更久。因此,如果需要加入更多消費者,盡量在離峰時段進行,以將影響最小化。
Brokers
Hashing key
使用 ad_id 作為 Kafka 分區的雜湊鍵,以將相同 ad_id 的事件儲存在相同的 Kafka 分區中。在這種情況下,聚合服務可以從單一分區訂閱相同 ad_id 的所有事件。
The number of partitions
如果分區數量改變,相同 ad_id 的事件可能會被映射到不同的分區。因此,建議事先預先配置足夠的分區,避免在生產環境中動態增加分區數量。
Topic physical sharding
單一 topic 通常不夠用。我們可以依地理位置(topic_north_america、topic_europe、topic_asia 等)或依業務類型(topic_web_ads、topic_mobile_ads 等)切分資料。
- Pros:將資料切分到不同的 topic 有助於提升系統吞吐量。單一 topic 的消費者較少時,rebalance consumer group 的時間會減少。
- Cons:引入額外的複雜度並增加維護成本。
Scale the aggregation service#
在高階設計中,我們提到聚合服務是個 map/reduce 操作。圖 22 展示了各部分如何串接在一起。

如果你對細節有興趣,請參考參考資料 [20]。聚合服務透過增加或移除節點來水平擴展。這裡有個有趣的問題;我們要如何提升聚合服務的吞吐量?有兩個選項。
選項 1:將具有不同 ad_id 的事件分配到不同的執行緒,如圖 23 所示。

選項 2:將聚合服務節點部署在資源提供者上,例如 Apache Hadoop YARN [21]。你可以把這個方法視為利用多程序處理。
選項 1 較易於實作,且不依賴資源提供者。然而在實務上,選項 2 的使用更為廣泛,因為我們可以透過增加更多計算資源來擴展系統。
Scale the database#
Cassandra 原生支援水平擴展,方式類似於 consistent hashing。
![圖 24 虛擬節點 [22]](figure-24-virtual-nodes-MDUN2MVN.png)
資料以適當的 replication factor 平均分佈到每個節點。每個節點根據雜湊值儲存環的自有部分,並儲存來自其他虛擬節點的副本。
如果我們在叢集中加入新節點,它會自動在所有節點之間重新平衡虛擬節點。不需要手動 resharding。詳情請見 Cassandra 的官方文件 [22]。
Hotspot issue#
接收到比其他 shard 或服務多很多資料的 shard 或服務稱為熱點(hotspot)。這種情況之所以發生,是因為大公司有數百萬美元的廣告預算,他們的廣告被點擊得更頻繁。由於事件以 ad_id 進行分區,某些聚合服務節點可能會接收到比其他節點多很多的廣告點擊事件,可能造成伺服器過載。
這個問題可以透過為熱門廣告分配更多聚合節點來緩解。讓我們看看圖 25 所示的範例。假設每個聚合節點只能處理 100 個事件。
- 由於該聚合節點中有 300 個事件(超過該節點能處理的容量),它透過 resource manager 申請額外資源。
- Resource manager 配置更多資源(例如,再加入兩個聚合節點),以避免原始聚合節點過載。
- 原始聚合節點將事件分成 3 組,每個聚合節點處理 100 個事件。
- 結果寫回原始 aggregate 節點。

還有更精細的方法可以處理這個問題,例如 Global-Local Aggregation 或 Split Distinct Aggregation。詳情請參考 [23]。
Fault tolerance#
讓我們討論聚合服務的容錯。由於聚合在記憶體中進行,當聚合節點故障時,聚合結果也會遺失。我們可以透過從上游 Kafka brokers 重播事件來重建計數。
從 Kafka 開頭重播資料很慢。一個好做法是把「系統狀態」(例如上游 offset)儲存到快照中,並從上次儲存的狀態復原。在我們的設計中,「系統狀態」不只是上游 offset,因為我們還需要儲存像是過去 M 分鐘內被點擊次數最多的前 N 個廣告之類的資料。
圖 26 展示了快照中資料的簡單範例。

有了快照,聚合服務的故障切換流程就相當簡單。如果一個聚合服務節點故障,我們啟動一個新節點並從最新的快照復原資料(圖 27)。如果有新的事件在最後一次快照之後抵達,新的聚合節點會從 Kafka broker 拉取這些資料進行重播。

Data monitoring and correctness#
如前所述,聚合結果可以用於 RTB 與計費目的。監控系統健康狀況並確保正確性至關重要。
Continuous monitoring#
以下是我們可能想要監控的一些指標:
- 延遲。由於延遲可能在每個階段引入,追蹤事件流經系統不同部分時的時間戳非常有價值。這些時間戳之間的差異可以作為延遲指標公開。
- 訊息佇列大小。如果佇列大小突然增加,我們可能需要加入更多聚合節點。請注意,Kafka 是一種以分散式 commit log 實作的訊息佇列,所以我們需要監控的是 records-lag 指標。
- 聚合節點上的系統資源:CPU、磁碟、JVM 等。
Reconciliation#
對帳意指比較不同的資料集,以確保資料完整性。與銀行業的對帳不同(你可以將自己的紀錄與銀行的紀錄做比較),廣告點擊聚合的結果沒有第三方結果可以對帳。
我們能做的是在每天結束時,使用批次工作將每個分區內的廣告點擊事件依 event time 排序,並與即時聚合結果進行對帳。如果我們有更高的準確性需求,可以使用更小的聚合視窗,例如一小時。請注意,無論使用哪種聚合視窗,批次工作的結果可能與即時聚合結果不完全相符,因為某些事件可能晚到(請見「時間」章節)。
圖 28 展示了支援對帳的最終設計圖。

Alternative design#
在通才型的系統設計面試中,並不期望你了解大數據管線中各種專門軟體的內部細節。解釋你的思考過程並討論取捨非常重要,這也是為什麼我們提出了一個通用的解決方案。
另一個選項是把廣告點擊資料儲存在 Hive 中,並建立一個 ElasticSearch 層以加快查詢速度。聚合通常在 OLAP 資料庫中完成,例如 ClickHouse [24] 或 Druid [25]。圖 29 展示了該架構。

#
更多細節請參考參考資料 [26]。
Step 4 - Wrap Up#
本章我們走過了在 Facebook 或 Google 規模下設計廣告點擊事件聚合系統的過程。我們涵蓋了:
- 資料模型與 API 設計。
- 使用 MapReduce 範式聚合廣告點擊事件。
- 擴展訊息佇列、聚合服務與資料庫。
- 緩解熱點問題。
- 持續監控系統。
- 使用對帳確保正確性。
- 容錯。
廣告點擊事件聚合系統是典型的大數據處理系統。如果你之前對 Apache Kafka、Apache Flink 或 Apache Spark 等業界標準解決方案有所了解或經驗,將會更容易理解與設計。
恭喜你看到這裡!現在請給自己拍拍背。做得很好!
Chapter Summary#