在本章中,我們將探討一個可擴展的指標監控與告警系統(metrics monitoring and alerting system)的設計。一個良好設計的監控與告警系統在提供基礎設施健康狀態的清晰可視性方面扮演關鍵角色,以確保高可用性與可靠性。
圖 1 顯示了市場上一些最受歡迎的指標監控與告警服務。在本章中,我們將設計一個類似的服務,可供大型公司內部使用。

Step 1 - 理解問題並界定設計範圍#
指標監控與告警系統對不同公司可能代表不同的事物,因此首先必須與面試官釐清確切的需求。例如,如果面試官心中只想要基礎設施指標,你就不會想要設計一個專注於 log(如 web server error log 或 access log)的系統。
讓我們先完整理解問題並界定設計範圍,再深入細節。
應徵者:我們是為誰建構這個系統?是為像 Facebook 或 Google 這樣的大型公司建構內部系統,還是設計像 Datadog [1]、Splunk [2] 等 SaaS 服務?
面試官:好問題。我們是建構僅供內部使用的系統。
應徵者:我們想要收集哪些指標?
面試官:我們想要收集營運系統指標。它們可以是作業系統的低階使用資料,例如 CPU 負載、記憶體用量與磁碟空間使用量,也可以是高階概念,例如服務的每秒請求數或 web pool 中執行中的伺服器數量。業務指標不在本設計範圍內。
應徵者:我們用這個系統監控的基礎設施規模有多大?
面試官:1 億日活躍使用者、1,000 個 server pool,每個 pool 100 台機器。
應徵者:資料應該保留多久?
面試官:假設我們希望保留 1 年。
應徵者:我們可以為了長期儲存而降低指標資料的解析度嗎?
面試官:好問題。我們希望新接收到的資料可以保留 7 天。7 天之後,你可以將其匯總(roll up)為 1 分鐘解析度,保留 30 天。30 天之後,你可以再進一步匯總為 1 小時解析度。
應徵者:支援哪些告警通道?
面試官:Email、電話、PagerDuty 或 webhook(HTTP endpoint)。
應徵者:我們需要收集 log 嗎,例如 error log 或 access log?
面試官:不需要。
應徵者:我們需要支援分散式系統追蹤(distributed system tracing)嗎?
面試官:不需要。
高層需求與假設#
現在你已經完成了從面試官那裡收集需求的工作,並對設計範圍有清晰的概念。需求如下:
- 被監控的基礎設施規模龐大:
- 1 億日活躍使用者
- 假設我們有 1,000 個 server pool,每個 pool 100 台機器,每台機器 100 個指標 => 約 1,000 萬個指標
- 1 年資料保存
- 資料保存政策:原始形式 7 天、1 分鐘解析度 30 天、1 小時解析度 1 年
- 可監控多種指標,例如:
- CPU 使用率
- 請求數
- 記憶體使用量
- 訊息佇列中的訊息數
非功能性需求#
- 可擴展性。系統應能擴展以容納日益增長的指標與告警量。
- 低延遲。系統需要對 dashboard 與告警有低查詢延遲。
- 可靠性。系統應高度可靠,避免漏掉關鍵告警。
- 彈性。技術不斷變動,pipeline 應有足夠彈性,未來能輕易整合新技術。
哪些需求不在範圍內?
- Log 監控。Elasticsearch、Logstash、Kibana(ELK)stack 是收集與監控 log 的非常熱門選擇[3]。
- 分散式系統追蹤[4][5]。分散式追蹤指的是在請求流經分散式系統時追蹤服務請求的解決方案。它在請求從一個服務流向另一個服務時收集資料。
Step 2 - 提出高階設計並取得共識#
在本節中,我們討論建構系統的一些基礎、資料模型與高階設計。
基礎#
指標監控與告警系統一般包含五個元件,如圖 2 所示。
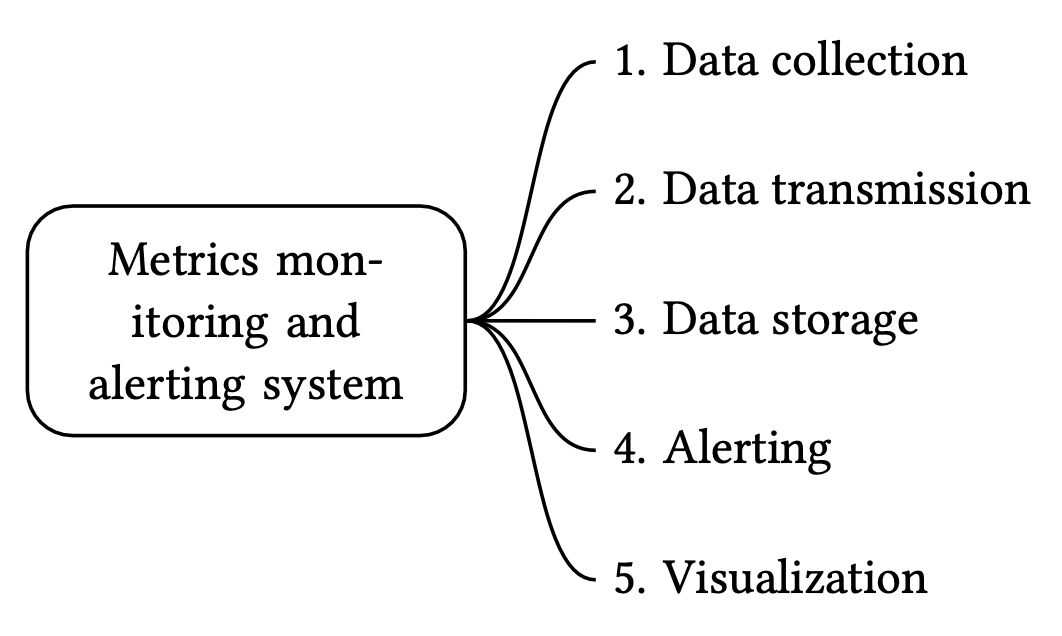
- 資料收集(Data collection):從不同來源收集指標資料。
- 資料傳輸(Data transmission):將資料從來源傳輸到指標監控系統。
- 資料儲存(Data storage):組織並儲存進來的資料。
- 告警(Alerting):分析進來的資料、偵測異常並產生告警。系統必須能夠將告警送到不同的通訊通道。
- 視覺化(Visualization):以圖表等形式呈現資料。當資料以視覺方式呈現時,工程師更容易識別模式、趨勢或問題,因此我們需要視覺化功能。
資料模型#
指標資料通常記錄為時間序列(time series),包含一組值與其關聯的時間戳。時間序列本身可以由其名稱唯一識別,並可選擇性地由一組標籤識別。
我們來看兩個範例。
範例 1:在 20:00 時,生產伺服器實例 i631 的 CPU 負載是多少?

圖 3 中標示的資料點可以用表 1 來表示。
| metric_name | cpu.load |
|---|---|
| labels | host:i631,env:prod |
| timestamp | 1613707265 |
| value | 0.29 |
表 1 以表格表示的資料點
在這個範例中,時間序列由 metric 名稱、labels(host:i631,env:prod)以及特定時間的單一點值表示。
範例 2:us-west 區域所有 web server 過去 10 分鐘的平均 CPU 負載是多少?概念上,我們會從儲存中拉取類似這樣的資料,其中 metric 名稱為 “CPU.load”,region label 為 “us-west”:
CPU.load host=webserver01,region=us-west 1613707265 50
CPU.load host=webserver01,region=us-west 1613707265 62
CPU.load host=webserver02,region=us-west 1613707265 43
CPU.load host=webserver02,region=us-west 1613707265 53
…
CPU.load host=webserver01,region=us-west 1613707265 76
CPU.load host=webserver01,region=us-west 1613707265 83
平均 CPU 負載可以透過對每行末尾的數值取平均來計算。上面範例中各行的格式稱為 line protocol,是市面上許多監控軟體常見的輸入格式。Prometheus [6] 與 OpenTSDB [7] 是兩個例子。
每個時間序列由以下組成[8]:
| Name | Type |
|---|---|
| A metric name | String |
| A set of tags/labels | List of key:value pairs |
| An array of values and their timestamps | An array of <value, timestamp> pairs |
表 2 時間序列
資料存取模式#

在圖 4 中,y 軸上的每個 label 代表一個時間序列(由名稱與 labels 唯一識別),而 x 軸代表時間。
寫入負載很重。如你所見,任何時刻都可能有許多時間序列資料點被寫入。如同我們在「高層需求」一節提到的,每天寫入約 1,000 萬個營運指標,且許多指標會以高頻率被收集,因此流量無疑是寫入密集的。
同時,讀取負載是尖峰式的。視覺化與告警服務都會向資料庫送出查詢,根據圖表與告警的存取模式不同,讀取量可能是突發性的。
換句話說,系統處於持續高寫入負載下,而讀取負載則是尖峰式的。
資料儲存系統#
資料儲存系統是設計的核心。不建議自行建構儲存系統,也不建議使用通用儲存系統(例如 MySQL)來做這個工作。
理論上,通用資料庫可以支援時間序列資料,但需要專家級的調校才能在我們的規模下運作。具體來說,關聯式資料庫並未針對時間序列資料常見的操作做最佳化。例如,計算滾動時間視窗中的移動平均需要複雜且難以閱讀的 SQL(在 deep dive 一節中有範例)。此外,要支援 tag/label 資料,我們需要為每個 tag 加上索引。再者,通用關聯式資料庫在持續高寫入負載下表現不佳。在我們的規模下,需要花費大量心力調校資料庫,即使如此可能仍不夠好。
那 NoSQL 呢?理論上,市面上有幾種 NoSQL 資料庫可以有效處理時間序列資料。例如 Cassandra 與 Bigtable [9] 都可以用於時間序列資料。然而這需要對每個 NoSQL 內部運作有深入了解,以設計可擴展的 schema 來有效儲存與查詢時間序列資料。在已有業界級時間序列資料庫可用的情況下,使用通用 NoSQL 資料庫並不吸引人。
市面上有許多針對時間序列資料最佳化的儲存系統。這種最佳化讓我們可以用少得多的伺服器處理同樣的資料量。許多這類資料庫還具備專為時間序列資料分析設計的自訂查詢介面,比 SQL 更容易使用,有些甚至提供管理資料保存與資料聚合的功能。以下是幾個時間序列資料庫的例子。
OpenTSDB 是一個分散式時間序列資料庫,但它基於 Hadoop 與 HBase,運作 Hadoop/HBase 叢集會增加複雜度。Twitter 使用 MetricsDB [10],Amazon 提供 Timestream 作為時間序列資料庫[11]。根據 DB-engines [12],最受歡迎的兩個時間序列資料庫是 InfluxDB [13] 與 Prometheus,它們的設計是儲存大量時間序列資料並對其進行快速即時分析。兩者主要依賴記憶體快取與磁碟儲存,且耐久性與效能都處理得相當好。如圖 5 所示,一個 8 核心、32GB RAM 的 InfluxDB 每秒可處理超過 250,000 次寫入。
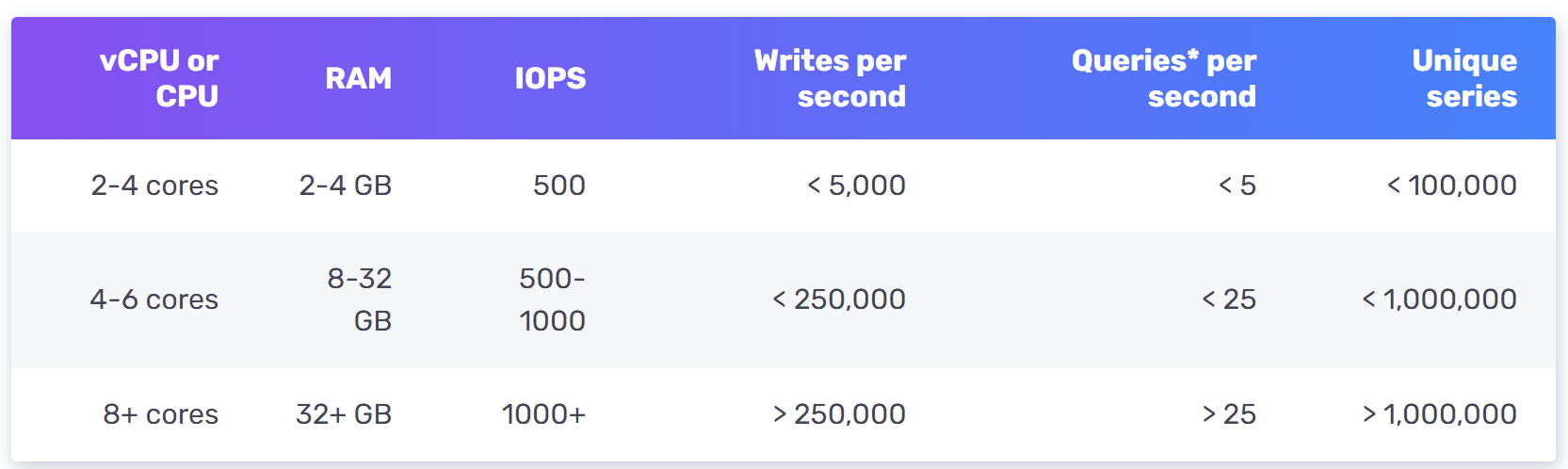
由於時間序列資料庫是專門資料庫,除非你在履歷上明確提及,否則在面試中不會被預期理解其內部機制。在面試中,重要的是理解指標資料本質上是時間序列,且我們可以選擇 InfluxDB 等時間序列資料庫來儲存它們。
強大的時間序列資料庫的另一個特性是依 label(在某些資料庫中也稱為 tag)對大量時間序列資料進行高效聚合與分析。例如,InfluxDB 在 label 上建立索引,以便快速依 label 查找時間序列[13],並提供關於如何使用 label(且不會使資料庫負擔過重)的明確最佳實踐指南。關鍵是確保每個 label 是低基數(low cardinality,可能值的集合較小)的。這個特性對視覺化至關重要,且要在通用資料庫上建構這個功能會耗費許多心力。
高階設計#
高階設計圖如圖 6 所示。

- Metrics source:可以是應用伺服器、SQL 資料庫、訊息佇列等。
- Metrics collector:收集指標資料並寫入時間序列資料庫。
- Time-series database:將指標資料以時間序列的形式儲存。它通常提供自訂查詢介面以分析與彙總大量時間序列資料,並在 label 上維護索引以便快速依 label 查找時間序列資料。
- Query service:Query service 讓查詢與從時間序列資料庫擷取資料變得容易。如果我們選擇了一個好的時間序列資料庫,這應該是非常薄的封裝層,甚至可以完全被時間序列資料庫自身的查詢介面取代。
- Alerting system:將告警通知送到各種告警目的地。
- Visualization system:以各種圖表的形式顯示指標。
Step 3 - 設計深入探討#
在系統設計面試中,應徵者被預期會深入探討幾個關鍵元件或流程。在本節中,我們將詳細探討以下主題:
- 指標收集
- 擴展指標傳輸 pipeline
- Query service
- 儲存層
- 告警系統
- 視覺化系統
指標收集#
對於像計數器或 CPU 使用率這類指標收集,偶爾的資料遺失並不是世界末日。Client 端可以採取「fire and forget(送出後不管)」的方式。現在來看看指標收集流程。系統的這個部分位於虛線方框內(圖 7)。

Pull 與 push 模型#
收集指標資料有兩種方式:pull 或 push。哪一種比較好是常見的爭論,沒有明確答案。讓我們仔細看看。
Pull 模型#
圖 8 顯示透過 HTTP 的 pull 模型資料收集。我們有專門的 metric collector,定期從執行中的應用程式拉取指標值。

在這個方法中,metrics collector 需要知道要拉取資料的服務 endpoint 完整列表。一個天真的方法是在「metric collector」伺服器上用一個檔案保存每個服務 endpoint 的 DNS/IP 資訊。雖然概念簡單,但這個方法在大規模環境中難以維護,因為伺服器經常被新增或移除,而我們希望確保 metric collector 不會錯過從任何新伺服器收集指標。
好消息是我們有可靠、可擴展且可維護的解決方案,由 etcd [14]、Zookeeper [15] 等提供的 Service Discovery,服務在其中註冊其可用性,且當服務 endpoint 列表變更時,metrics collector 會被 Service Discovery 元件通知。
Service discovery 包含關於何時與何地收集指標的設定規則,如圖 9 所示。

圖 10 詳細解釋 pull 模型。

- Metrics collector 從 Service Discovery 取得服務 endpoint 的設定 metadata。Metadata 包含拉取間隔、IP 位址、逾時與重試參數等。
- Metrics collector 透過預先定義的 HTTP endpoint(例如 /metrics)拉取指標資料。為了暴露這個 endpoint,通常需要在服務中加入一個 client library。在圖 10 中,服務是 Web Servers。
- 可選地,metrics collector 向 Service Discovery 註冊變更事件通知,以在服務 endpoint 變更時收到更新。或者 metrics collector 可以定期輪詢 endpoint 變更。
在我們的規模下,單一 metrics collector 無法處理數千台伺服器。我們必須使用一池 metrics collector 來處理需求。當有多個 collector 時,一個常見問題是多個實例可能試圖從同一資源拉取資料而產生重複資料。實例之間必須有某種協調機制以避免這個問題。
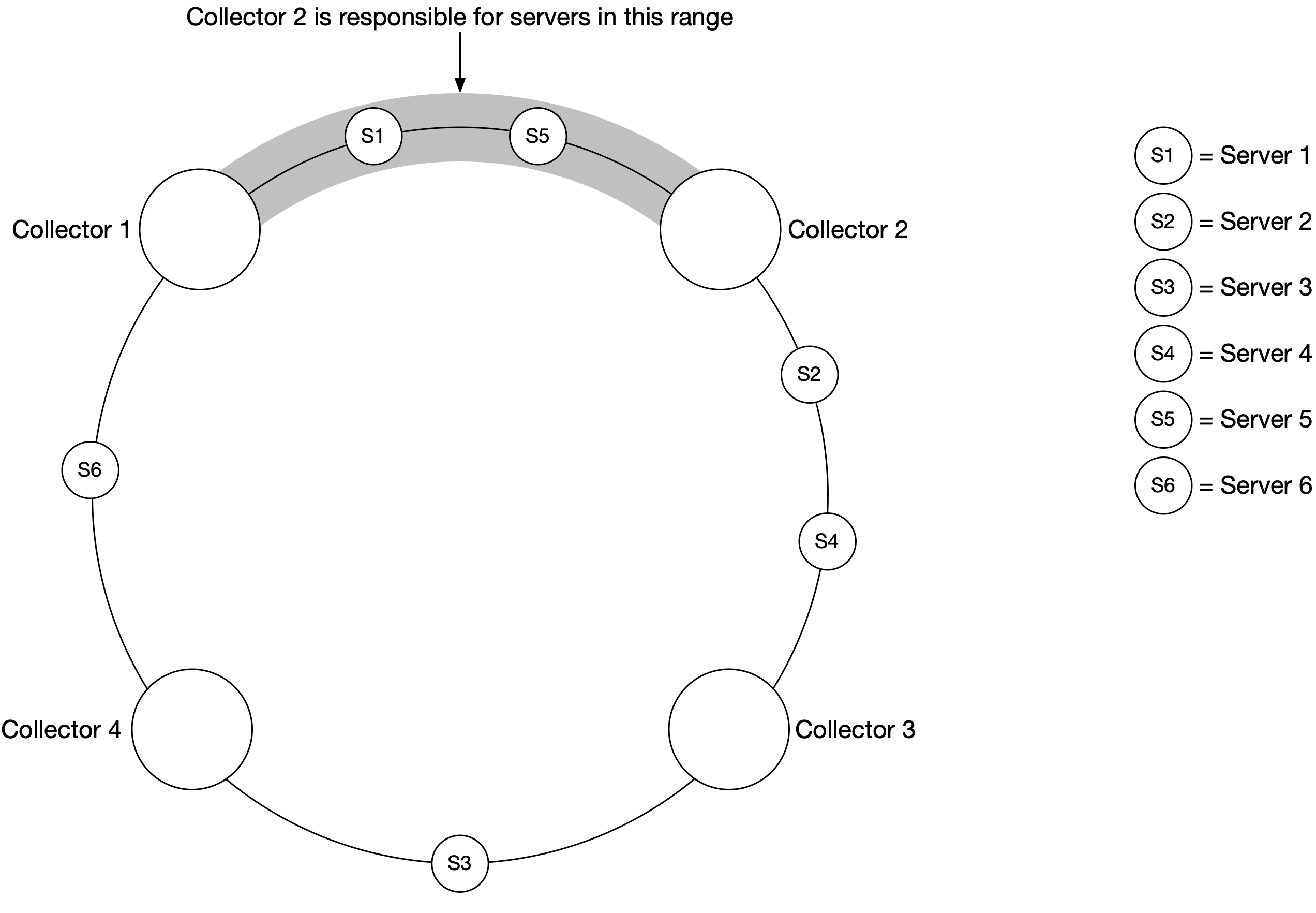
一個可能的方法是將每個 collector 指派到 consistent hash ring 的某個範圍,然後將每台被監控的伺服器以其唯一名稱對應到 hash ring 上。這確保一個 metric source 伺服器只由一個 collector 處理。讓我們看一個範例。
如圖 11 所示,有 4 個 collector 與 6 個 metric source 伺服器。每個 collector 負責從一組不同的伺服器收集指標。Collector 2 負責從 server 1 與 server 5 收集指標。
Push 模型#
如圖 12 所示,在 push 模型中,各種 metric source(例如 web server、database server 等)直接將指標送到 metrics collector。

在 push 模型中,每台被監控的伺服器上通常會安裝一個 collection agent。Collection agent 是一個長時間執行的軟體,從伺服器上執行的服務收集指標,並定期將這些指標推送到 metrics collector。Collection agent 也可能在送到 metric collector 之前在本地聚合指標(特別是簡單的計數器)。
聚合是減少送到 metrics collector 資料量的有效方法。如果 push 流量很高且 metrics collector 以錯誤拒絕推送,agent 可以在本地保留一個小型 buffer 的資料(可能儲存在本地磁碟上)並稍後重送。
如果伺服器位於頻繁輪換的 auto-scaling group 中,那麼將資料保留在本地(即使是暫時的)可能在 metrics collector 落後時導致資料遺失。
為了防止 push 模型中的 metrics collector 落後,metrics collector 應該位於一個前面有 load balancer 的 auto-scaling cluster 中(圖 13)。叢集應根據 metric collector 伺服器的 CPU 負載做擴展或縮減。

Pull 還是 push?#
那麼,哪一個對我們來說是較好的選擇?就像生活中許多事情一樣,沒有明確的答案。兩邊都有廣泛採用的真實使用案例。
- Pull 架構的例子包括 Prometheus。
- Push 架構的例子包括 Amazon CloudWatch [16] 與 Graphite [17]。
了解每種方法的優缺點比在面試中挑出贏家更重要。表 3 比較了 push 與 pull 架構的優缺點[18][19][20][21]。
| Pull | Push | |
|---|---|---|
| 易於除錯 | 應用伺服器上用於拉取指標的 /metrics endpoint 可隨時用來檢視指標。你甚至可以在自己的筆電上做。Pull 勝出。 | 如果 metrics collector 沒有收到指標,問題可能是由網路問題引起。 |
| 健康檢查 | 如果應用伺服器不回應 pull,你可以快速判斷該應用伺服器是否故障。Pull 勝出。 | 如果 metrics collector 沒有收到指標,問題可能是由網路問題引起。 |
| 短時間任務 | 某些 batch job 可能是短時間的,存在時間不夠久而無法被拉取。Push 勝出。在 pull 模型中可以透過引入 push gateway 來解決[22]。 | |
| 防火牆或複雜網路設定 | 讓伺服器拉取指標需要所有 metric endpoint 都可達。在多資料中心設定中可能有問題,可能需要更複雜的網路基礎設施。 | 如果 metrics collector 設定為帶 load balancer 與 auto-scaling group,就有可能從任何地方接收資料。Push 勝出。 |
| 效能 | Pull 方法通常使用 TCP。 | Push 方法通常使用 UDP,這代表 push 方法提供較低延遲的指標傳輸。反方論點是建立 TCP 連線的成本比起傳送指標酬載來說很小。 |
| 資料真實性 | 要從哪些應用伺服器收集指標是預先在設定檔中定義的。從這些伺服器收集到的指標保證是真實的。 | 任何 client 都可以將指標推送到 metrics collector。可以透過白名單伺服器或要求驗證來解決。 |
表 3 Pull 與 push 比較
如前所述,pull 與 push 是個常見的爭論話題,沒有明確答案。大型組織可能需要同時支援兩者,特別是現在 serverless [23] 越來越流行,可能根本沒有辦法安裝可以推送資料的 agent。
擴展指標傳輸 pipeline#

讓我們聚焦在 metrics collector 與時間序列資料庫上。無論你使用 push 或 pull 模型,metrics collector 都是一個伺服器叢集,且該叢集會接收大量資料。對於 push 或 pull,metrics collector 叢集都設定為自動擴展,以確保有足夠數量的 collector 實例處理需求。
然而,如果時間序列資料庫無法使用,存在資料遺失的風險。為了減輕這個問題,我們引入一個排隊元件,如圖 15 所示。

在這個設計中,metrics collector 將指標資料送到 Kafka 等排隊系統。然後 consumer 或像 Apache Storm、Flink、Spark 等串流處理服務處理並將資料推送到時間序列資料庫。這個方法有幾個優點:
- Kafka 作為高可靠且可擴展的分散式訊息平台被使用。
- 它將資料收集服務與資料處理服務彼此解耦。
- 它可以透過將資料保留在 Kafka 中,輕鬆防止資料庫無法使用時的資料遺失。
透過 Kafka 擴展#
我們可以透過幾種方式利用 Kafka 內建的 partition 機制來擴展系統:
- 根據吞吐量需求設定 partition 的數量。
- 依 metric 名稱對指標資料分區,讓 consumer 可以依 metric 名稱聚合資料。

- 進一步以 tag/label 對指標資料分區。
- 對指標分類並設定優先順序,讓重要指標可以先被處理。
Kafka 的替代方案#
維護一個生產級別的 Kafka 系統絕非小事。你可能會在這方面收到面試官的反駁。有些大規模監控資料攝取系統並未使用中介佇列。Facebook 的 Gorilla [24] 記憶體時間序列資料庫就是一個典型例子;它的設計即使在部分網路故障時也能保持高可用的寫入。可以說這樣的設計與使用 Kafka 等中介佇列同樣可靠。
聚合可以發生在哪裡#
指標可以在不同地方聚合:collection agent(client 端)、攝取 pipeline(寫入儲存之前)以及查詢端(寫入儲存之後)。讓我們仔細看看每一個。
- Collection agent:安裝在 client 端的 collection agent 只支援簡單的聚合邏輯。例如,每分鐘聚合一個計數器後再送到 metrics collector。
- 攝取 pipeline:在寫入儲存之前聚合資料,我們通常需要像 Flink 這類串流處理引擎。寫入量會大幅減少,因為只有計算後的結果被寫入資料庫。然而,處理遲到事件可能是個挑戰,另一個缺點是我們會失去資料精度與一些彈性,因為我們不再儲存原始資料。
- 查詢端:原始資料可以在查詢時依指定時間區間聚合。這個方法不會有資料遺失,但查詢速度可能較慢,因為查詢結果是在查詢時計算且要對整個資料集執行。
Query service#
Query service 由一群 query server 組成,它們存取時間序列資料庫並處理來自視覺化或告警系統的請求。擁有一組專屬的 query server 將時間序列資料庫與 client(視覺化與告警系統)解耦。這給了我們在需要時更換時間序列資料庫或視覺化與告警系統的彈性。
快取層#
為了減少時間序列資料庫的負載並讓 query service 更高效,加入了快取伺服器來儲存查詢結果,如圖 17 所示。

反對 query service 的論點#
可能沒有迫切的需要引入我們自己的抽象(一個 query service),因為大多數業界級別的視覺化與告警系統都有強大的外掛可以與市場上知名的時間序列資料庫介接。而且選擇一個好的時間序列資料庫之後,也不需要加入我們自己的快取。
時間序列資料庫查詢語言#
像 Prometheus 與 InfluxDB 這類最受歡迎的指標監控系統都不使用 SQL,而有自己的查詢語言。一個主要原因是用 SQL 查詢時間序列資料很困難。例如,如此處[25]提到的,計算指數移動平均的 SQL 看起來可能像這樣:
select id,
temp,
avg(temp) over (partition by group_nr order by time_read) as rolling_avg
from (
select id,
temp,
time_read,
interval_group,
id - row_number() over (partition by interval_group order by time_read) as group_nr
from (
select id,
time_read,
"epoch"::timestamp + "900 seconds"::interval * (extract(epoch from time_read)::int4 / 900) as interval_group,
temp
from readings
) t1
) t2
order by time_read;而在 Flux(針對時間序列分析最佳化的語言,InfluxDB 中使用)中,看起來像這樣。如你所見,這要好理解得多。
from(db:"telegraf")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "foo")
|> exponentialMovingAverage(size:-10s)儲存層#
現在讓我們深入儲存層。
謹慎選擇時間序列資料庫#
根據 Facebook 發表的一篇研究論文[24],營運資料儲存中至少 85% 的查詢針對的是過去 26 小時內收集的資料。如果我們使用利用此特性的時間序列資料庫,可能會對整體系統效能產生重大影響。如果你對儲存引擎的設計有興趣,請參閱 InfluxDB 儲存引擎的設計文件[26]。
空間最佳化#
如同高層需求所述,要儲存的指標資料量非常龐大。以下是處理此問題的幾個策略。
資料編碼與壓縮#
資料編碼與壓縮可以顯著減少資料大小。這些功能通常內建於好的時間序列資料庫中。以下是一個簡單的例子。

如上圖所示,1610087371 與 1610087381 只相差 10 秒,僅需 4 bit 即可表示,而非完整 32 bit 的時間戳。所以與其儲存絕對值,可以儲存差量值與一個基準值,例如:1610087371, 10, 10, 9, 11
降採樣(Downsampling)#
降採樣是將高解析度資料轉換為低解析度以減少整體磁碟使用量的過程。由於我們的資料保存期是 1 年,我們可以對舊資料進行降採樣。例如,我們可以讓工程師與資料科學家為不同指標定義規則。以下是一個例子:
- 保存:7 天,不採樣
- 保存:30 天,降採樣到 1 分鐘解析度
- 保存:1 年,降採樣到 1 小時解析度
讓我們看另一個具體例子。它將 10 秒解析度的資料聚合為 30 秒解析度的資料。
| metric | timestamp | hostname | Metric_value |
|---|---|---|---|
| cpu | 2021-10-24T19:00:00Z | host-a | 10 |
| cpu | 2021-10-24T19:00:10Z | host-a | 16 |
| cpu | 2021-10-24T19:00:20Z | host-a | 20 |
| cpu | 2021-10-24T19:00:30Z | host-a | 30 |
| cpu | 2021-10-24T19:00:40Z | host-a | 20 |
| cpu | 2021-10-24T19:00:50Z | host-a | 30 |
表 4 10 秒解析度資料
從 10 秒解析度資料 roll up 為 30 秒解析度資料。
| metric | timestamp | hostname | Metric_value (avg) |
|---|---|---|---|
| cpu | 2021-10-24T19:00:00Z | host-a | 19 |
| cpu | 2021-10-24T19:00:30Z | host-a | 25 |
表 5 30 秒解析度資料
冷儲存(Cold storage)#
冷儲存是指儲存很少使用的非活躍資料。冷儲存的財務成本要低得多。
簡而言之,我們大概應該使用第三方視覺化與告警系統,而不是自行建構。
告警系統#
為了面試的目的,讓我們看看圖 19 所示的告警系統。

告警流程如下:
將設定檔載入快取伺服器。規則被定義為磁碟上的設定檔。YAML [27] 是常用於定義規則的格式。以下是告警規則的範例:
- name: instance_down rules: # Alert for any instance that is unreachable for >5 minutes. - alert: instance_down expr: up == 0 for: 5m labels: severity: pageAlert manager 從快取取得告警設定。
根據設定的規則,alert manager 會以預先定義的間隔呼叫 query service。如果值違反閾值,就會建立一個告警事件。Alert manager 負責以下事情:
過濾、合併與去重告警。以下是一個合併在短時間內由同一個實例(instance1)觸發的告警的範例(圖 20)。

存取控制。為了避免人為錯誤並維護系統安全,必須將某些告警管理操作限制給授權人員。
重試。Alert manager 檢查告警狀態,並確保通知至少被傳送一次。
Alert store 是一個 key-value 資料庫(例如 Cassandra),用於保存所有告警的狀態(inactive、pending、firing、resolved)。它確保通知至少被傳送一次。
符合條件的告警被插入 Kafka。
Alert consumer 從 Kafka 拉取告警事件。
Alert consumer 處理來自 Kafka 的告警事件,並透過不同通道送出通知,例如 email、簡訊、PagerDuty 或 HTTP endpoint。
告警系統 - build vs buy#
市面上有許多現成的業界級告警系統,且大多與熱門的時間序列資料庫有緊密整合。許多這些告警系統與既有通知通道(例如 email 與 PagerDuty)整合良好。
在現實世界中,要說服自己建構自己的告警系統是個艱難的決定。在面試情境下,特別是針對資深職位,要準備好為你的決定辯護。
視覺化系統#
視覺化建構在資料層之上。指標可以在指標 dashboard 上以各種時間尺度顯示,告警可以在告警 dashboard 上顯示。圖 21 顯示一個 dashboard,顯示一些指標如目前伺服器請求、記憶體/CPU 使用率、頁面載入時間、流量與登入資訊[28]。
高品質的視覺化系統很難建構。使用現成系統的論點非常強。例如,Grafana 可以是個非常好的選擇,它與許多熱門的時間序列資料庫整合良好。
Step 4 - 收尾#
在本章中,我們呈現了指標監控與告警系統的設計。在高層上,我們談到了資料收集、時間序列資料庫、告警與視覺化。然後我們深入探討了一些最重要的技術/元件:
- 收集指標資料的 pull 與 push 模型。
- 利用 Kafka 擴展系統。
- 選擇正確的時間序列資料庫。
- 使用降採樣減少資料大小。
- 告警與視覺化系統的 build vs buy 選項。
我們經過幾次迭代精煉設計,最終設計如下:

恭喜你看到這裡!現在給自己拍拍背,做得好!
Chapter Summary#