在本章中,我們將探討系統設計面試中一個熱門題目:設計分散式訊息佇列(distributed message queue)。在現代架構中,系統被拆解為小且獨立的構件,構件之間以明確定義的介面溝通。訊息佇列為這些構件提供溝通與協調機制。
訊息佇列帶來哪些好處?
- 解耦(Decoupling):訊息佇列消除了元件之間的緊耦合,使它們可以獨立更新。
- 提升可擴展性(Scalability):我們可以根據流量負載獨立擴展生產者(producer)與消費者(consumer)。例如在尖峰時段,可以增加更多消費者來處理增加的流量。
- 提高可用性(Availability):如果系統的某一部分離線,其他元件仍可以繼續與佇列互動。
- 更好的效能:訊息佇列讓非同步通訊變得容易。生產者可以將訊息加入佇列而無需等待回應,消費者則在訊息可用時消費它們。雙方不需要互相等待。
圖 1 顯示市面上一些最受歡迎的分散式訊息佇列。

訊息佇列與事件串流平台(event streaming platform)#
嚴格來說,Apache Kafka 與 Pulsar 並不是訊息佇列,而是事件串流平台。然而功能上的趨同正在模糊訊息佇列(RocketMQ、ActiveMQ、RabbitMQ、ZeroMQ 等)與事件串流平台(Kafka、Pulsar)之間的界線。
例如,RabbitMQ 是典型的訊息佇列,它新增了可選的串流功能,以支援重複消費訊息與長期保存訊息,其實作使用的是 append-only log,與事件串流平台類似。Apache Pulsar 主要是 Kafka 的競爭者,但它也具備足夠的彈性與效能,可作為典型的分散式訊息佇列使用。
在本章中,我們將設計一個分散式訊息佇列,並具備長期資料保存、訊息重複消費等附加功能,這些功能通常只在事件串流平台中提供。這些附加功能讓設計變得更複雜。在本章中,我們會特別指出哪些地方在傳統分散式訊息佇列的設計中可以被簡化。
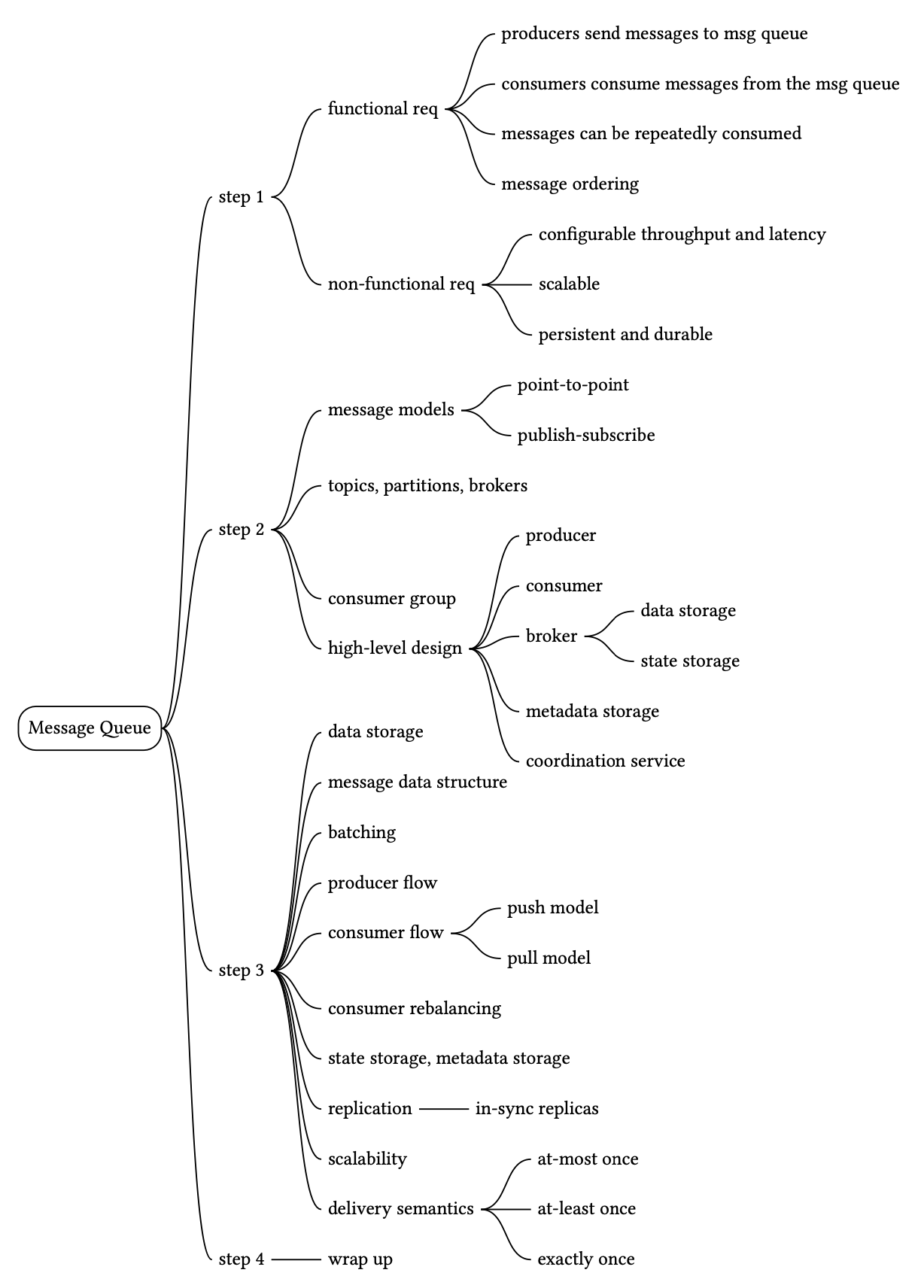
Step 1 - 理解問題並界定設計範圍#
簡而言之,訊息佇列的基本功能很直觀:生產者將訊息傳送到佇列,消費者從佇列中消費訊息。除了這個基本功能之外,還有效能、訊息傳遞語意(message delivery semantics)、資料保存等其他考量。以下這組問題可以協助釐清需求並縮小範圍。
應徵者:訊息的格式與平均大小為何?是否只支援文字?是否允許多媒體?
面試官:只支援文字訊息。訊息的大小通常以 KB(kilobytes)為單位。
應徵者:訊息可以被重複消費嗎?
面試官:可以,訊息可以被不同消費者重複消費。請注意這是一個附加功能。傳統的分散式訊息佇列在訊息成功送達消費者後就不會保留它,因此傳統訊息佇列中訊息無法被重複消費。
應徵者:訊息是否依照產生順序被消費?
面試官:是的,訊息應該依照產生的順序被消費。請注意這是一個附加功能。傳統的分散式訊息佇列通常不保證傳遞順序。
應徵者:資料是否需要持久化?保存期限多久?
面試官:是的,假設資料保存期為兩週。這也是附加功能。傳統的分散式訊息佇列不會保留訊息。
應徵者:我們需要支援多少生產者與消費者?
面試官:越多越好。
應徵者:我們需要支援哪種資料傳遞語意?例如 at-most-once、at-least-once 或 exactly-once。
面試官:我們一定要支援 at-least-once。理想上應該全部支援,並讓使用者可以設定。
應徵者:目標吞吐量與端對端延遲為何?
面試官:對於像 log 聚合這類使用情境,需要支援高吞吐量。對於更傳統的訊息佇列使用情境,也需要支援低延遲傳遞。
根據上述對話,我們假設有以下功能需求:
- 生產者將訊息傳送到訊息佇列。
- 消費者從訊息佇列中消費訊息。
- 訊息可以被重複消費或只消費一次。
- 歷史資料可以被截斷(truncated)。
- 訊息大小在 KB 範圍內。
- 能夠依照訊息加入佇列的順序傳遞給消費者。
- 資料傳遞語意(at-least-once、at-most-once 或 exactly-once)可由使用者設定。
非功能性需求#
- 可根據使用情境設定為高吞吐量或低延遲。
- 可擴展。系統本質上應為分散式,能夠應付突發的訊息流量。
- 持久且耐用。資料應持久化到磁碟,並在多個節點間複製。
傳統訊息佇列的調整#
像 RabbitMQ 這類傳統訊息佇列對保存(retention)的需求並不像事件串流平台那麼強烈。傳統佇列只在訊息被消費前的短時間內保留在記憶體中。它們提供的磁碟溢位(on-disk overflow)容量[1]比事件串流平台所需容量小好幾個數量級。
傳統訊息佇列通常也不維持訊息順序,訊息可能以與生產順序不同的順序被消費。這些差異大幅簡化了設計,我們會在適當的地方加以討論。
Step 2 - 提出高階設計並取得共識#
首先,讓我們討論訊息佇列的基本功能。圖 2 顯示了訊息佇列的關鍵元件以及這些元件之間的簡化互動。

- 生產者將訊息傳送到訊息佇列。
- 消費者訂閱佇列並消費所訂閱的訊息。
- 訊息佇列是中間的服務,它將生產者與消費者解耦,讓兩者可以獨立運作與擴展。
- 生產者與消費者皆是 client/server 模型中的 client,而訊息佇列是 server。Client 與 server 透過網路通訊。
訊息傳遞模型(Messaging models)#
最常見的訊息傳遞模型是 point-to-point 與 publish-subscribe。
Point-to-point#
這個模型常見於傳統訊息佇列。在 point-to-point 模型中,訊息被送到一個佇列中,並只由一個消費者消費。佇列中可能有多個消費者等待消費訊息,但每則訊息只能被單一消費者消費。在圖 3 中,訊息 A 只被消費者 1 消費。

當消費者確認訊息已被消費後,它就會從佇列中被移除。Point-to-point 模型沒有資料保存。相對而言,我們的設計包含一個持久層,會將訊息保留兩週,使訊息可以被重複消費。
雖然我們的設計可以模擬 point-to-point 模型,但它的能力更自然地對應到 publish-subscribe 模型。
Publish-subscribe#
首先,讓我們介紹一個新概念:topic。Topic 是用來組織訊息的類別。每個 topic 在整個訊息佇列服務中都有唯一的名稱。訊息會被傳送到並從特定 topic 讀取。
在 publish-subscribe 模型中,訊息會被傳送到一個 topic,並被訂閱該 topic 的消費者接收。如圖 4 所示,訊息 A 被消費者 1 與消費者 2 同時消費。

我們的分散式訊息佇列支援這兩種模型。Publish-subscribe 模型由 topic 實現,而 point-to-point 模型可以透過 consumer group 概念來模擬,consumer group 將在後續章節介紹。
Topic、partition 與 broker#
如前所述,訊息是依 topic 持久化的。如果 topic 中的資料量過大,單一伺服器無法處理怎麼辦?
解決這個問題的方法之一稱為 partition(sharding)。如圖 5 所示,我們將 topic 切分為多個 partition,並把訊息平均分配到各 partition。可以將 partition 視為 topic 訊息的一個小子集。
Partition 平均分佈在訊息佇列叢集的各個伺服器上,這些持有 partition 的伺服器稱為 broker。Partition 在 broker 之間的分佈是支援高可擴展性的關鍵元素。我們可以透過擴展 partition 的數量來擴展 topic 的容量。

每個 topic partition 都以 FIFO(first in, first out)機制的佇列形式運作。這代表我們可以保持 partition 內訊息的順序。訊息在 partition 中的位置稱為 offset。
當生產者傳送訊息時,訊息實際上會被送到該 topic 的某一個 partition。每則訊息有一個可選的 message key(例如使用者 ID),所有具有相同 message key 的訊息會被送到同一個 partition。如果沒有 message key,訊息會被隨機送到其中一個 partition。
當消費者訂閱一個 topic 時,它會從一個或多個 partition 中拉取資料。當有多個消費者訂閱同一個 topic 時,每個消費者負責該 topic 的一個 partition 子集。這些消費者組成 topic 的 consumer group。
包含 broker 與 partition 的訊息佇列叢集如圖 6 所示。

Consumer group#
如前所述,我們需要同時支援 point-to-point 與 publish-subscribe 模型。Consumer group 是一組共同消費 topic 訊息的消費者集合。
消費者可以被組織成群組。每個 consumer group 可以訂閱多個 topic 並維護自己的消費 offset。例如,我們可以依使用情境將消費者分組,一組用於計費(billing),另一組用於會計(accounting)。
同一群組內的實例可以平行消費流量,如圖 7 所示。
- Consumer group 1 訂閱 topic A。
- Consumer group 2 同時訂閱 topic A 與 topic B。
- Topic A 同時被 consumer group 1 與 2 訂閱,這代表同一則訊息會被多個消費者消費。這個模式支援 subscribe/publish 模型。

然而這裡有一個問題。平行讀取資料能提升吞吐量,但同一 partition 內訊息的消費順序無法被保證。例如,如果 consumer 1 與 consumer 2 都從 partition 1 讀取,我們將無法保證 partition 1 的訊息消費順序。
好消息是我們可以加入一個限制來解決這個問題:在同一群組內,一個 partition 只能被一個消費者消費。如果群組內的消費者數量大於 topic 的 partition 數量,則某些消費者將無法從該 topic 取得資料。例如在圖 7 中,group 2 中的 consumer 3 無法從 topic B 消費訊息,因為 topic B 已經被同一群組中的 Consumer-4 消費了。
有了這個限制,如果我們把所有消費者都放在同一個 consumer group 中,那麼同一 partition 中的訊息只會被一個消費者消費,這就等同於 point-to-point 模型。由於 partition 是最小的儲存單位,我們可以預先分配足夠多的 partition,以避免動態增加 partition 數量的需要。要應付高流量,只需要新增消費者即可。
高階架構#
圖 8 顯示更新後的高階設計。

Clients:
- Producer:將訊息推送到特定的 topic。
- Consumer group:訂閱 topic 並消費訊息。
核心服務與儲存:
- Broker:持有多個 partition。一個 partition 持有一個 topic 的訊息子集。
- Storage:
- Data storage:訊息以 partition 形式持久化於 data storage 中。
- State storage:消費者狀態由 state storage 管理。
- Metadata storage:topic 的設定與屬性持久化於 metadata storage 中。
- Coordination service:
- Service discovery:哪些 broker 是存活的。
- Leader election:其中一個 broker 被選為當前 controller。叢集中只會有一個 active controller,負責分派 partition。
- Apache Zookeeper [2] 或 etcd [3] 常被用來選舉 controller。
Step 3 - 設計深入探討#
為了在滿足高資料保存需求的同時達成高吞吐量,我們做了三個重要的設計選擇,現在我們會詳細說明。
- 我們選擇了一種磁碟資料結構,以充分利用旋轉式磁碟卓越的循序存取效能,以及現代作業系統積極的磁碟快取策略。
- 我們設計訊息資料結構,使訊息可以從生產者傳到佇列,再傳到消費者,全程不需修改。這最小化了複製的需求,而複製在高量、高流量的系統中是非常昂貴的。
- 我們將系統設計為偏好批次處理(batching)。小型 I/O 是高吞吐量的大敵。所以我們的設計盡可能鼓勵批次處理:生產者以批次傳送訊息,訊息佇列以更大的批次持久化訊息,消費者也盡可能以批次方式抓取訊息。
Data storage#
現在讓我們更詳細地探討持久化訊息的選項。為了找到最佳選擇,先考慮訊息佇列的流量模式:
- 寫入密集,讀取也密集。
- 沒有更新或刪除操作。順帶一提,傳統訊息佇列除非佇列落後,否則不會持久化訊息;當佇列追上時會有「刪除」操作。我們這裡討論的是資料串流平台的持久化。
- 主要是循序的讀寫存取。
選項 1:資料庫#
第一個選項是使用資料庫。
- 關聯式資料庫:建立一個 topic 表並將訊息以 row 的形式寫入表中。
- NoSQL 資料庫:建立一個 collection 作為 topic,並以 document 的形式寫入訊息。
資料庫可以處理儲存需求,但它們並不理想,因為要設計一個能在大規模下同時支援寫入密集與讀取密集存取模式的資料庫很困難。資料庫方案不太符合我們具體的資料使用模式。
這代表資料庫不是最佳選擇,可能成為系統的瓶頸。
選項 2:Write-ahead log(WAL)#
第二個選項是 write-ahead log(WAL)。WAL 只是一個普通的檔案,新項目以 append-only 方式附加到 log 中。WAL 在許多系統中被使用,例如 MySQL 中的 redo log 與 ZooKeeper 中的 WAL。
我們建議將訊息以 WAL log 檔的形式持久化到磁碟上。WAL 具有純循序的讀寫存取模式,磁碟在循序存取下的效能非常好[4]。此外,旋轉式磁碟有大容量且價格相當實惠。
如圖 9 所示,新訊息會以單調遞增的 offset 附加到 partition 的尾端。最簡單的選項是用 log 檔的行號作為 offset。然而檔案不能無限成長,因此將其切分為多個 segment 是個好主意。
有了 segment 之後,新訊息只會附加到 active segment 檔案中。當 active segment 達到一定大小,就會建立新的 active segment 來接收新訊息,原本的 active segment 變為 inactive,與其他非 active segment 一樣。非 active segment 只服務讀取請求。舊的非 active segment 檔案在超過保存或容量限制時可以被截斷。

同一 partition 的 segment 檔案會被組織在一個名為 “Partition-{:partition_id}” 的資料夾中,結構如圖 10 所示。

關於磁碟效能的補充
為了滿足高資料保存需求,我們的設計大量依賴磁碟機來保存大量資料。常見的誤解是旋轉式磁碟很慢,但其實這只在隨機存取下成立。對我們的工作負載而言,只要設計磁碟資料結構以利用循序存取模式,現代的磁碟機在 RAID 配置下(即多顆磁碟串起以提升效能)可以輕鬆達到每秒數百 MB 的讀寫速度。這對我們的需求綽綽有餘,且成本結構也很有利。
此外,現代作業系統會非常積極地將磁碟資料快取到主記憶體中,甚至會樂於使用所有可用的閒置記憶體來快取磁碟資料。如同前述,WAL 也充分利用了作業系統大量的磁碟快取。
訊息資料結構#
訊息的資料結構是高吞吐量的關鍵。它定義了生產者、訊息佇列與消費者之間的契約。我們的設計透過消除訊息在從生產者傳到佇列再傳到消費者過程中不必要的資料複製來達成高效能。如果系統的任何部分對這個契約有歧見,訊息就需要被改寫,這會涉及昂貴的複製,可能嚴重損害系統效能。
以下是訊息資料結構的範例 schema:
| Field Name | Data Type |
|---|---|
| key | byte[] |
| value | byte[] |
| topic | string |
| partition | integer |
| offset | long |
| timestamp | long |
| size | integer |
| crc [5] | integer |
表 1 訊息的資料 schema
Message key#
訊息的 key 用於決定訊息所屬的 partition。如果未定義 key,則隨機選擇 partition。否則 partition 由 hash(key) % numPartitions 決定。如果需要更多彈性,生產者可以定義自己的對應演算法來選擇 partition。請注意 key 並不等同於 partition 編號。
Key 可以是字串或數字,通常攜帶一些業務資訊。Partition 編號是訊息佇列中的概念,不應顯式地暴露給 client。
有了適當的對應演算法,即使 partition 數量改變,訊息仍然可以平均地送到所有 partition。
Message value#
訊息的 value 是訊息的酬載(payload),可以是純文字或壓縮的二進位區塊。
提醒
訊息的 key 與 value 與 key-value(KV)儲存中的 key-value 對不同。在 KV store 中 key 是唯一的,可以透過 key 找到 value。在訊息中 key 不必唯一,有時甚至不是必填的,且我們也不需要透過 key 找到 value。
訊息的其他欄位#
- Topic:訊息所屬 topic 的名稱。
- Partition:訊息所屬 partition 的 ID。
- Offset:訊息在 partition 中的位置。我們可以透過 topic、partition、offset 三者的組合找到一則訊息。
- Timestamp:此訊息儲存時的時間戳。
- Size:此訊息的大小。
- CRC:循環冗餘校驗(Cyclic redundancy check, CRC)用於確保原始資料的完整性。
為了支援額外功能,可以依需求加入一些可選欄位。例如,如果可選欄位中包含 tag,則可以依 tag 過濾訊息。
批次處理(Batching)#
批次處理在這個設計中無所不在。我們在生產者、消費者與訊息佇列本身都做批次處理。批次處理對系統效能至關重要。在這一節中我們主要關注訊息佇列中的批次處理,生產者與消費者的批次處理稍後會更詳細地討論。
批次處理對提升效能至關重要,因為:
- 它允許作業系統將訊息合併到單一網路請求中,分攤昂貴的網路往返成本。
- Broker 以大區塊將訊息寫入 append log,這帶來更大塊的循序寫入與作業系統維護的更大連續磁碟快取區塊。兩者都帶來更高的循序磁碟存取吞吐量。
吞吐量與延遲之間有一個取捨。如果系統作為傳統訊息佇列部署,延遲可能更重要,可以調整為較小的批次大小。在這種情況下磁碟效能會略微下降。如果調整為高吞吐量,可能需要每個 topic 有更多的 partition,以彌補較慢的循序磁碟寫入吞吐量。
到目前為止,我們已經涵蓋了主要的磁碟儲存子系統與其磁碟資料結構。現在讓我們轉換話題,討論生產者與消費者的流程。然後我們會回頭完成訊息佇列其他部分的深入探討。
Producer flow#
如果生產者想要將訊息送到某個 partition,它應該連接到哪個 broker?第一個選項是引入一個 routing 層。所有送到 routing 層的訊息都會被路由到「正確」的 broker。如果 broker 有複本,「正確」的 broker 是 leader replica。我們稍後會討論複製。

如圖 11 所示,生產者試圖將訊息送到 topic A 的 partition 1。
- 生產者將訊息送到 routing 層。
- Routing 層從 metadata storage 讀取 replica distribution plan1並在本地快取。當訊息抵達時,它會將訊息路由到 partition 1 的 leader replica,該 replica 儲存在 broker 1。
- Leader replica 接收訊息,follower replica 從 leader 拉取資料。
- 當「足夠多」的 replica 已同步該訊息後,leader 提交資料(持久化到磁碟),代表資料可被消費,然後回應生產者。
你可能會想為什麼我們同時需要 leader 與 follower replica。原因是容錯。我們會在「In-sync replicas」一節深入探討這個過程。
這個方法可行,但有幾個缺點:
- 新的 routing 層代表額外的網路延遲,源於開銷與額外的網路跳躍。
- 請求批次處理是效率的主要驅動力之一,但這個設計沒有考慮到這點。
圖 12 顯示改良後的設計。

Routing 層被包進生產者中,並在生產者中加入了 buffer 元件。兩者都可以作為 producer client library 的一部分安裝在生產者端。這個改變帶來幾個好處:
- 較少的網路跳躍代表較低的延遲。
- 生產者可以擁有自己的邏輯來決定訊息應送到哪個 partition。
- Batching 將訊息緩衝在記憶體中,並以單一請求送出較大的批次,從而提高吞吐量。
批次大小的選擇是吞吐量與延遲之間的經典取捨(圖 13)。較大的批次大小會增加吞吐量,但因等待累積批次的時間較長,延遲較高。較小的批次大小會更快送出請求,因此延遲較低,但吞吐量較差。生產者可以根據使用情境調整批次大小。

Consumer flow#
消費者指定它在 partition 中的 offset,然後從該位置開始接收一批事件。圖 14 顯示了一個範例。

Push 與 pull#
一個重要的問題是 broker 應該將資料 push 給消費者,還是消費者應該從 broker pull 資料。
Push 模型
優點:
- 低延遲。Broker 在收到訊息後可以立即將其推送給消費者。
缺點:
- 如果消費速度低於生產速度,消費者可能會被淹沒。
- 難以處理處理能力差異很大的消費者,因為 broker 控制資料傳輸的速率。
Pull 模型
優點:
- 消費者控制消費速率。我們可以讓一組消費者即時處理訊息,另一組以批次模式處理訊息。
- 如果消費速度低於生產速度,我們可以擴展消費者,或讓它在能夠時自行追上。
- Pull 模型更適合批次處理。在 push 模型中,broker 不知道消費者是否能夠立即處理訊息。如果 broker 一次傳送一則訊息給消費者而消費者已經塞車,新訊息就會堆積在 buffer 中。Pull 模型則一次拉取消費者目前位置之後 log 中所有可用的訊息(或最大可設定大小),適合積極的資料批次處理。
缺點:
- 當 broker 中沒有訊息時,消費者可能仍會持續拉取資料,浪費資源。為了克服這個問題,許多訊息佇列支援 long polling 模式,讓拉取操作等待指定的時間以等待新訊息[6]。
基於這些考量,大多數訊息佇列選擇 pull 模型。
圖 15 顯示了消費者 pull 模型的工作流程。

- 一個新消費者想要加入 group 1 並訂閱 topic A。它透過對 group 名稱進行 hash 找到對應的 broker 節點。透過這種方式,同一群組中的所有消費者都連接到同一個 broker,這個 broker 也被稱為該 consumer group 的 coordinator。儘管命名相似,consumer group coordinator 與圖 8 中提到的 coordination service 是不同的。這個 coordinator 協調的是 consumer group,而前面提到的 coordination service 協調的是 broker 叢集。
- Coordinator 確認消費者已加入群組,並將 partition 2 指派給該消費者。Partition 指派策略有多種,包括 round-robin、range 等[7]。
- 消費者從上次消費的 offset 抓取訊息,這個 offset 由 state storage 管理。
- 消費者處理訊息並將 offset 提交給 broker。資料處理與 offset 提交的順序會影響訊息傳遞語意,稍後會討論。
Consumer rebalancing#
Consumer rebalancing 決定哪個消費者負責哪一組 partition 子集。這個過程可能在消費者加入、消費者離開、消費者崩潰或 partition 調整時發生。
當 consumer rebalancing 發生時,coordinator 扮演重要角色。讓我們先看 coordinator 是什麼。Coordinator 是其中一個 broker,負責與消費者通訊以達成 consumer rebalancing。Coordinator 接收消費者的 heartbeat 並管理它們在 partition 上的 offset。
讓我們以一個範例理解 coordinator 與消費者如何協同工作。

- 如圖 16 所示,每個消費者屬於一個群組。它透過對群組名稱 hash 來找到專屬的 coordinator。同一群組的所有消費者都連接到同一個 coordinator。
- Coordinator 維護一份已加入消費者的清單。當清單變化時,coordinator 會選出該群組的新 leader。
- 作為 consumer group 的新 leader,它會生成新的 partition dispatch plan 並回報給 coordinator。Coordinator 會將該計畫廣播給群組中的其他消費者。
在分散式系統中,消費者可能遇到各種問題,包括網路問題、崩潰、重啟等。從 coordinator 的角度看,它們將不再有 heartbeat。當這種情況發生時,coordinator 會觸發 rebalance 過程,重新分派 partition,如圖 17 所示。

讓我們模擬幾個 rebalance 情境。假設群組中有 2 個消費者,被訂閱的 topic 有 4 個 partition。圖 18 顯示新消費者 B 加入群組時的流程。

- 起初群組中只有消費者 A,它消費所有 partition 並與 coordinator 保持 heartbeat。
- 消費者 B 送出加入群組的請求。
- Coordinator 知道是時候 rebalance 了,因此它以被動方式通知群組中所有消費者。當 A 的 heartbeat 被 coordinator 收到時,它要求 A 重新加入群組。
- 一旦所有消費者都重新加入了群組,coordinator 從中選擇一個作為 leader,並通知所有消費者選舉結果。
- Leader 消費者生成 partition dispatch plan 並送給 coordinator。Follower 消費者向 coordinator 詢問 partition dispatch plan。
- 消費者開始從新分配到的 partition 消費訊息。
圖 19 顯示既有消費者 A 離開群組時的流程。

- 消費者 A 與 B 在同一個 consumer group 中。
- 消費者 A 需要關閉,因此它請求離開群組。
- Coordinator 知道是時候 rebalance 了。當 B 的 heartbeat 被 coordinator 收到時,它要求 B 重新加入群組。
- 後續步驟與圖 18 相同。
圖 20 顯示既有消費者 A 崩潰時的流程。

- 消費者 A 與 B 與 coordinator 維持 heartbeat。
- 消費者 A 崩潰,因此沒有 heartbeat 從消費者 A 送到 coordinator。由於 coordinator 在指定時間內沒有收到來自消費者 A 的任何 heartbeat 訊號,它將該消費者標記為死亡。
- Coordinator 觸發 rebalance 過程。
- 後續步驟與前一個情境相同。
現在我們完成了生產者與消費者流程的繞道,接著回頭完成訊息佇列 broker 其餘部分的深入探討。
State storage#
在訊息佇列 broker 中,state storage 儲存:
- Partition 與消費者之間的對應關係。
- 每個 partition 上 consumer group 最後消費的 offset。如圖 21 所示,consumer group 1 的最後消費 offset 是 6,consumer group 2 的 offset 是 13。

例如,如圖 21 所示,group 1 中的消費者按序從 partition 消費訊息,並提交 offset 6,這代表 offset 6 之前以及包含 offset 6 的所有訊息都已被消費。如果該消費者崩潰,同一群組中的另一個新消費者將從 state storage 讀取最後消費的 offset 來恢復消費。
消費者狀態的資料存取模式為:
- 頻繁的讀寫操作,但量不大。
- 資料更新頻繁,很少被刪除。
- 隨機的讀寫操作。
- 資料一致性很重要。
許多儲存方案都可以用來儲存消費者狀態資料。考量到資料一致性與快速讀寫的需求,像 Zookeeper 這類 KV store 是很好的選擇。Kafka 已經將 offset 儲存從 Zookeeper 移到 Kafka brokers 中,有興趣的讀者可以閱讀參考資料[8]了解更多。
Metadata storage#
Metadata storage 儲存 topic 的設定與屬性,包括 partition 的數量、保存期間以及複本的分佈。
Metadata 不常變動且資料量小,但對一致性的要求高。Zookeeper 是儲存 metadata 的好選擇。
ZooKeeper#
讀完前面幾節後,你大概已經感覺到 Zookeeper 對於設計分散式訊息佇列非常有幫助。如果你不熟悉它,Zookeeper 是分散式系統的基本服務,提供階層式 key-value store。它常被用於提供分散式設定服務、同步服務與命名註冊[2]。
Zookeeper 用來簡化我們的設計,如圖 22 所示。

讓我們簡單檢視這項變更:
- Metadata 與 state storage 被移到 Zookeeper。
- Broker 現在只需要維護訊息的 data storage。
- Zookeeper 協助 broker 叢集的 leader election。
複製(Replication)#
在分散式系統中,硬體問題很常見且不能被忽視。當磁碟損壞或永久故障時,資料會遺失。複製是達成高可用性的經典解決方案。
如圖 23 所示,每個 partition 有 3 個複本,分佈在不同的 broker 節點上。
對於每個 partition,標示出來的複本是 leader,其他則是 follower。生產者只將訊息送到 leader replica,follower replica 會持續從 leader 拉取新訊息。一旦訊息同步到足夠多的 replica,leader 就會回應 ACK 給生產者。我們會在下面的 In-sync Replicas 一節中詳細說明如何定義「足夠」。

每個 partition 的複本分佈稱為 replica distribution plan。例如,圖 23 中的 replica distribution plan 可以描述為:
- Topic A 的 partition 1:3 個複本,leader 在 broker 1,follower 在 broker 2 與 3。
- Topic A 的 partition 2:3 個複本,leader 在 broker 2,follower 在 broker 3 與 4。
- Topic B 的 partition 1:3 個複本,leader 在 broker 3,follower 在 broker 4 與 1。
誰來制定 replica distribution plan?運作方式如下:在 coordination service 的協助下,其中一個 broker 節點被選為 leader。它會生成 replica distribution plan 並將計畫持久化到 metadata storage 中。所有 broker 現在都可以根據此計畫運作。
如果你對複製有更多興趣,可以參閱《Designing Data-Intensive Applications》[9]一書的「Chapter 5. Replication」。
In-sync replicas#
我們提到訊息會被持久化到多個 partition,以避免單一節點故障,且每個 partition 有多個 replica。訊息只寫入 leader,follower 則從 leader 同步資料。我們需要解決的一個問題是讓它們保持同步。
In-sync replicas(ISR)指的是與 leader「同步」的複本。「同步」的定義取決於 topic 的設定。例如,如果 replica.lag.max.messages 的值為 4,代表只要 follower 落後 leader 不超過 3 則訊息,它就不會被從 ISR 中移除[10]。Leader 預設是 ISR。
讓我們以圖 24 為例說明 ISR 如何運作。
- Leader replica 中已提交的 offset 是 13。兩個新訊息被寫入 leader,但尚未被提交。已提交的 offset 代表所有 offset 之前以及包含該 offset 的訊息都已同步到 ISR 中所有的 replica。
- Replica-2 與 replica-3 已完全追上 leader,因此它們在 ISR 中且可以抓取新訊息。
- Replica-4 在設定的延遲時間內未完全追上 leader,因此它不在 ISR 中。當它再次追上時,可以被加回 ISR。

為什麼我們需要 ISR?原因是 ISR 反映了效能與耐久性之間的取捨。如果生產者不想遺失任何訊息,最安全的方法是確保所有複本在送出 ACK 之前都已同步。但慢的複本會讓整個 partition 變慢或無法使用。
既然我們討論了 ISR,接著看看 ACK 設定。生產者可以選擇等到 K 個 ISR 收到訊息後才接收 ACK,K 是可設定的。
ACK=all
圖 25 說明 ACK=all 的情況。在 ACK=all 下,生產者要等所有 ISR 都收到訊息後才能收到 ACK。這代表傳送訊息需要較長時間,因為要等最慢的 ISR,但提供最強的訊息耐久性。

ACK=1
在 ACK=1 下,生產者在 leader 持久化訊息後就會收到 ACK。延遲因為不用等待資料同步而改善。如果在訊息被 ACK 但尚未被 follower 節點複製之前 leader 立刻故障,那麼訊息就會遺失。這個設定適合可接受偶爾資料遺失的低延遲系統。

ACK=0
生產者持續送訊息給 leader 而不等待任何 ACK,且永不重試。這個方法以可能的訊息遺失為代價提供了最低的延遲。這個設定可能適合像收集 metric 或記錄 log 資料這類使用情境,因為資料量大且偶爾資料遺失是可以接受的。

可設定的 ACK 讓我們能夠用耐久性換取效能。
現在來看消費者端。最簡單的設定是讓消費者連接到 leader replica 來消費訊息。
你可能會想為什麼這個設計下 leader replica 不會被淹沒,為什麼訊息不從 ISR 讀取。原因是:
- 設計與運作上的簡單性。
- 由於一個 partition 內的訊息在同一 consumer group 中只會被分派給一個消費者,這限制了到 leader replica 的連線數。
- 只要 topic 不是超級熱門,到 leader replica 的連線數通常不會很大。
- 如果 topic 很熱門,我們可以透過擴展 partition 與消費者數量來擴充。
在某些情境下,從 leader replica 讀取可能不是最佳選擇。例如,如果消費者位於與 leader replica 不同的資料中心,讀取效能會下降。在這種情況下,讓消費者從最近的 ISR 讀取是值得的。有興趣的讀者可以查閱相關參考資料[11]。
ISR 非常重要。如何決定一個 replica 是否為 ISR 呢?通常每個 partition 的 leader 會透過計算每個 replica 與自身的落差來追蹤 ISR 列表。如果你對詳細演算法有興趣,可以在參考資料[12][13]中找到實作。
可擴展性#
到目前為止我們在分散式訊息佇列系統的設計上有了很大進展。下一步,讓我們評估各系統元件的可擴展性:
- Producers
- Consumers
- Brokers
- Partitions
Producer#
生產者在概念上比消費者簡單得多,因為它不需要群組協調。生產者的可擴展性可以透過新增或移除生產者實例輕鬆達成。
Consumer#
Consumer group 彼此隔離,因此新增或移除一個 consumer group 很容易。在 consumer group 內部,rebalancing 機制協助處理新增、移除或崩潰的情況。透過 consumer group 與 rebalance 機制,可以達成消費者的可擴展性與容錯。
Broker#
在討論 broker 端的可擴展性之前,我們先考慮 broker 的故障復原。

讓我們以圖 28 的範例來說明故障復原如何運作。
- 假設有 4 個 broker,partition(replica)分佈計畫如下:
- Topic A 的 partition 1:複本在 broker 1(leader)、2 與 3。
- Topic A 的 partition 2:複本在 broker 2(leader)、3 與 4。
- Topic B 的 partition 1:複本在 broker 3(leader)、4 與 1。
- Broker 3 崩潰,代表該節點上所有 partition 都遺失。Partition 分佈計畫變更為:
- Topic A 的 partition 1:複本在 broker 1(leader)與 2。
- Topic A 的 partition 2:複本在 broker 2(leader)與 4。
- Topic B 的 partition 1:複本在 broker 4 與 1。
- Broker controller 偵測到 broker 3 故障,並為其餘 broker 節點生成新的 partition 分佈計畫:
- Topic A 的 partition 1:複本在 broker 1(leader)、2 與 4(新)。
- Topic A 的 partition 2:複本在 broker 2(leader)、4 與 1(新)。
- Topic B 的 partition 1:複本在 broker 4(leader)、1 與 2(新)。
- 新複本作為 follower 工作並追上 leader。
要讓 broker 具備容錯,還有一些額外考量:
- 最小 ISR 數量規定生產者必須收到多少個複本後,訊息才被視為成功提交。數字越大越安全,但另一方面我們需要在延遲與安全之間取得平衡。
- 如果一個 partition 的所有複本都在同一 broker 節點,那麼我們無法容忍該節點故障。在同一節點上複製資料也是資源浪費。因此複本不應該在同一節點上。
- 如果一個 partition 的所有複本都崩潰,該 partition 的資料就永遠遺失。在選擇複本數量與位置時,需要在資料安全、資源成本與延遲之間取捨。將複本分佈在不同資料中心更安全,但會帶來更多延遲與成本以同步複本之間的資料。作為變通做法,data mirroring 可以幫助跨資料中心複製資料,但這超出本章範圍。參考資料[14]涵蓋了此主題。
現在讓我們回到討論 broker 的可擴展性。最簡單的解法是在 broker 節點被新增或移除時重新分佈複本。
不過還有更好的方法。Broker controller 可以暫時允許系統中的複本數量超過設定檔中的數量。當新加入的 broker 追上後,我們可以移除不再需要的複本。讓我們以圖 29 的範例來理解這個方法。

- 初始設定:3 個 broker、2 個 partition,每個 partition 有 3 個複本。
- 新 broker 4 被加入。假設 broker controller 將 partition 2 的複本分佈改為 broker(2、3、4)。Broker 4 上的新複本開始從 leader broker 2 複製資料。現在 partition 2 的複本數量暫時超過 3。
- 在 broker 4 上的複本追上後,broker 1 上的多餘 partition 被優雅地移除。
藉由這個流程,可以避免在新增 broker 時的資料遺失。類似的流程可以應用於安全地移除 broker。
Partition#
由於各種運作上的原因,例如擴展 topic、調整吞吐量、平衡可用性/吞吐量等,我們可能會改變 partition 的數量。當 partition 數量改變時,生產者在與任一 broker 通訊後會收到通知,消費者則會觸發 consumer rebalancing。因此對生產者與消費者來說都是安全的。
現在考慮當 partition 數量改變時的資料儲存層。如圖 30 所示,我們在 topic 上加入了一個 partition。

- 已持久化的訊息仍在舊的 partition 中,因此沒有資料遷移。
- 在新 partition(partition-3)加入後,新訊息會被持久化到 3 個 partition 上。
所以透過增加 partition 來擴展 topic 是直接了當的。
減少 partition 的數量
減少 partition 比較複雜,如圖 31 所示。

- Partition-3 被除役,因此新訊息只會被剩下的 partition(partition-1 與 partition-2)接收。
- 被除役的 partition(partition-3)無法立刻被移除,因為資料可能正在被消費者消費一段時間。只有在設定的保存期過後,資料才能被截斷且儲存空間才能被釋放。
減少 partition 並不是回收資料空間的捷徑。
- 在這個過渡期(partition-3 除役期間),生產者只將訊息送到剩下的 2 個 partition,但消費者仍然可以從全部 3 個 partition 消費。當被除役 partition 的保存期過期後,consumer group 需要 rebalancing。
資料傳遞語意#
既然我們已經理解分散式訊息佇列的不同元件,接著討論不同的傳遞語意:at-most once、at-least once、exactly once。
At-most once#
顧名思義,at-most once 代表訊息最多被傳遞一次。訊息可能會遺失但不會被重送。以下是 at-most once 傳遞在高層的運作方式。
- 生產者非同步地將訊息送到 topic 而不等待 ACK(ack=0)。如果訊息傳送失敗,沒有重試。
- 消費者抓取訊息並在資料被處理之前提交 offset。如果消費者剛好在提交 offset 後崩潰,訊息將不會被再次消費。

它適合像監控 metric 這類少量資料遺失可接受的使用情境。
At-least once#
在這個資料傳遞語意下,訊息可被傳遞多次是可接受的,但不應遺失任何訊息。以下是高層的運作方式:
- 生產者以同步或非同步附帶回應 callback 的方式傳送訊息,設定 ack=1 或 ack=all,以確保訊息送達 broker。如果訊息傳送失敗或逾時,生產者會持續重試。
- 消費者抓取訊息,並在資料成功處理後才提交 offset。如果消費者處理訊息失敗,它會重新消費該訊息,因此不會有資料遺失。另一方面,如果消費者處理了訊息但未能將 offset 提交給 broker,當消費者重啟後該訊息會被重新消費,導致重複。
- 訊息可能被多次傳遞到 broker 與消費者。

使用情境:在 at-least once 下,訊息不會遺失,但同一則訊息可能被多次傳遞。從使用者觀點來看雖然不理想,但對於資料重複不是大問題或可在消費者端去重的使用情境,at-least once 通常已經足夠好。例如,每則訊息有唯一 key,當寫入重複資料到資料庫時可以拒絕該訊息。
Exactly once#
Exactly once 是最難實作的傳遞語意。它對使用者友善,但對系統效能與複雜度的代價很高。

使用情境:金融相關的使用情境(支付、交易、會計等)。當重複是不可接受的,且下游服務或第三方不支援 idempotency 時,exactly once 特別重要。
進階功能#
在本節中,我們簡要討論一些進階功能,例如訊息過濾、延遲訊息與排程訊息。
訊息過濾#
Topic 是一個邏輯抽象,包含同一類型的訊息。然而某些 consumer group 可能只想消費某些子類型的訊息。例如,訂購系統將所有與訂單相關的活動送到一個 topic,但支付系統只關心與結帳和退款相關的訊息。
一個選項是為支付系統建立一個專屬 topic,再為訂購系統建立另一個專屬 topic。這個方法很簡單,但可能引發一些疑慮:
- 如果其他系統要求不同子類型的訊息怎麼辦?我們是否需要為每個消費者請求建立專屬 topic?
- 將相同的訊息儲存在不同 topic 上是資源浪費。
- 每次有新的消費者需求時生產者都需要改變,因為生產者與消費者現在緊密耦合。
因此,我們需要用不同的方法解決這個需求。所幸有訊息過濾來救援。
訊息過濾的一個簡單方案是消費者抓取完整的訊息集合,並在處理時過濾掉不需要的訊息。這個方法很有彈性,但會引入不必要的流量,影響系統效能。
更好的方案是在 broker 端過濾訊息,這樣消費者只會收到它們關心的訊息。實作這一點需要謹慎考量。如果資料過濾需要解密或反序列化資料,會降低 broker 的效能。
如果訊息含有敏感資料,它們不應該在訊息佇列中可讀。因此,broker 中的過濾邏輯不應提取訊息酬載。
最好把用於過濾的資料放到訊息的 metadata 中,讓 broker 可以高效讀取。例如,我們可以為每則訊息附加 tag。有了訊息 tag,broker 可以在該維度上過濾訊息。如果附加更多 tag,訊息可以在多個維度上被過濾。因此,一份 tag 列表可以支援大多數的過濾需求。要支援更複雜的邏輯如數學公式,broker 將需要文法解析器或腳本執行器,這對訊息佇列來說可能過重。
每則訊息附加 tag 後,消費者可以根據指定的 tag 訂閱訊息,如圖 35 所示。有興趣的讀者可以參閱參考資料[15]。

延遲訊息與排程訊息#
有時你想要將訊息傳遞給消費者的時間延遲一段指定的時間。例如,訂單若在建立後 30 分鐘內未付款應該被關閉。一則延遲驗證訊息(檢查付款是否完成)會立即被送出,但 30 分鐘後才會被傳遞給消費者。當消費者收到該訊息時,它檢查付款狀態。如果付款未完成,訂單將被關閉;否則該訊息將被忽略。
與傳送即時訊息不同,我們可以將延遲訊息送到 broker 端的暫存儲存,而不是立刻送到 topic,然後在時間到時才將它們送到 topic。高層設計如圖 36 所示。

系統的核心元件包含暫存儲存與計時函式:
- 暫存儲存可以是一個或多個特殊的訊息 topic。
- 計時函式超出本章範圍,但以下是 2 個受歡迎的解決方案:
- 具有預定義延遲級別的專用延遲佇列[16]。例如,RocketMQ 不支援任意時間精度的延遲訊息,但支援具有特定級別的延遲訊息。訊息延遲級別為 1s、5s、10s、30s、1m、2m、3m、4m、6m、8m、9m、10m、20m、30m、1h 與 2h。
- 階層式時間輪(hierarchical time wheel)[17]。
排程訊息代表訊息應在排定的時間被傳遞給消費者。整體設計與延遲訊息非常相似。
Step 4 - 收尾#
在本章中,我們呈現了具有資料串流平台中常見進階功能的分散式訊息佇列設計。如果面試結尾還有額外時間,以下是一些可以延伸討論的話題:
Protocol:它定義了不同節點之間如何交換資訊與傳輸資料的規則、語法與 API。在分散式訊息佇列中,protocol 應該能夠:
- 涵蓋所有活動,例如 production、consumption、heartbeat 等。
- 有效地傳輸大量資料。
- 驗證資料的完整性與正確性。
一些受歡迎的 protocol 包括 Advanced Message Queuing Protocol(AMQP)[18]與 Kafka protocol[19]。
重試消費。如果某些訊息無法成功被消費,我們需要重試這個操作。為了不阻塞傳入的訊息,我們如何在一段時間後重試?一個想法是將失敗的訊息送到專屬的重試 topic,讓它們稍後被消費。
歷史資料封存。假設有基於時間或容量的 log 保存機制,如果消費者需要回放某些已經被截斷的歷史訊息,我們該如何做?一個可能的解決方案是使用大容量儲存系統,例如 HDFS 或物件儲存,來儲存歷史資料。
恭喜你看到這裡!現在給自己拍拍背,做得好!
Chapter summary#