在本章中,我們會設計一個簡化版的 Google Maps。在開始系統設計前,先簡單了解一下 Google Maps。Google 在 2005 年啟動了 Google Maps 專案,並開發了一個網路地圖服務。它提供許多服務,例如衛星影像、街道地圖、即時交通狀況與路線規劃 [1]。
Google Maps 協助使用者尋找方向並導航到目的地。截至 2021 年 3 月,Google Maps 擁有 10 億日活躍使用者、99% 的世界覆蓋率,每日有 2,500 萬筆精確且即時的位置資訊更新 [2]。
鑑於 Google Maps 極為龐大複雜,必須先確定我們的版本要支援哪些功能。請注意本章使用的地圖磚(map tiles)來自 Stamen Design [3],資料來自 OpenStreetMap [4]。
Step 1 - Understand the Problem and Establish Design Scope#
面試官與應徵者之間的互動可能像這樣:
應徵者:我們預期有多少日活躍使用者?
面試官:10 億 DAU。
應徵者:我們應該聚焦在哪些功能?方向、導航與預估到達時間(ETA)?
面試官:讓我們聚焦在位置更新、導航、ETA 與地圖渲染。
應徵者:道路資料量有多大?我們可以假設能取得這些資料嗎?
面試官:好問題。可以,假設我們從不同來源取得了道路資料,是 TBs 等級的原始資料。
應徵者:我們的系統需要把交通狀況納入考量嗎?
面試官:要的,交通狀況對於精確的時間預估非常重要。
應徵者:那不同的交通方式呢?例如開車、走路、公車等?
面試官:我們應該要能支援不同交通方式。
應徵者:要支援多停靠點導航嗎?
面試官:能讓使用者定義多個停靠點是好事,但讓我們先不要聚焦在這個。
應徵者:商家地點與照片呢?我們預期會有多少照片?
面試官:很高興你問到並考慮了這些。我們不需要設計這部分。
本章的其餘部分將聚焦於三項主要功能。我們需要支援的主要裝置是手機。
- 使用者位置更新。
- 導航服務,包含 ETA 服務。
- 地圖渲染。
Non-functional requirements and constraints#
- 精確性:使用者不應被給予錯誤的方向。
- 流暢的導航:客戶端方面,使用者應有非常流暢的地圖渲染體驗。
- 資料與電池用量:客戶端應盡可能少用資料與電池。這對行動裝置非常重要。
- 一般可用性與可擴展性需求。
在開始設計之前,我們會簡單介紹一些有助於設計 Google Maps 的基本概念與術語。
Map 101#
Positioning system#
地球是一個繞著自轉軸轉動的球體。最頂端是北極,最底端是南極。
![圖 1 緯度與經度(來源:[5])](figure-1-latitude-and-longitude-3HRLJEPU.png)
- Lat(Latitude,緯度):表示我們在南北方向上的位置
- Long(Longitude,經度):表示我們在東西方向上的位置
Going from 3D to 2D#
把點從 3D 球體轉換到 2D 平面的過程稱為「地圖投影(Map Projection)」。
地圖投影有多種方法,每種都有其優勢與限制。幾乎所有方法都會扭曲實際的幾何形狀。下面是一些範例。
![圖 2 地圖投影(來源:Wikipedia [6] [7] [8] [9])](figure-2-map-projectionse-BEFJVLCR.png)
Google Maps 選擇了一種改良過的麥卡托投影(Mercator projection),稱為 Web Mercator。關於定位系統與投影的更多細節,請參考 [5]。
Geocoding#
Geocoding(地理編碼)是把地址轉換為地理座標的過程。例如「1600 Amphitheatre Parkway, Mountain View, CA」會被 geocode 為一組緯度/經度組合(latitude 37.423021, longitude -122.083739)。
反過來,把緯度/經度組合轉換為實際人類可讀的地址,稱為 reverse geocoding(反向地理編碼)。
geocoding 的一種方法是內插(interpolation) [10]。此方法利用來自不同來源的資料,例如地理資訊系統(GIS),把街道網路對應到地理座標空間。
Geohashing#
Geohashing 是一種編碼系統,把地理區域編碼成短字串(由字母與數字組成)。其核心概念是把地球視為一個攤平的平面,並遞迴地把網格切分為子網格(可為正方形或矩形)。我們以 0 到 3 之間的數字字串來表示每個網格,這些字串是遞迴產生的。
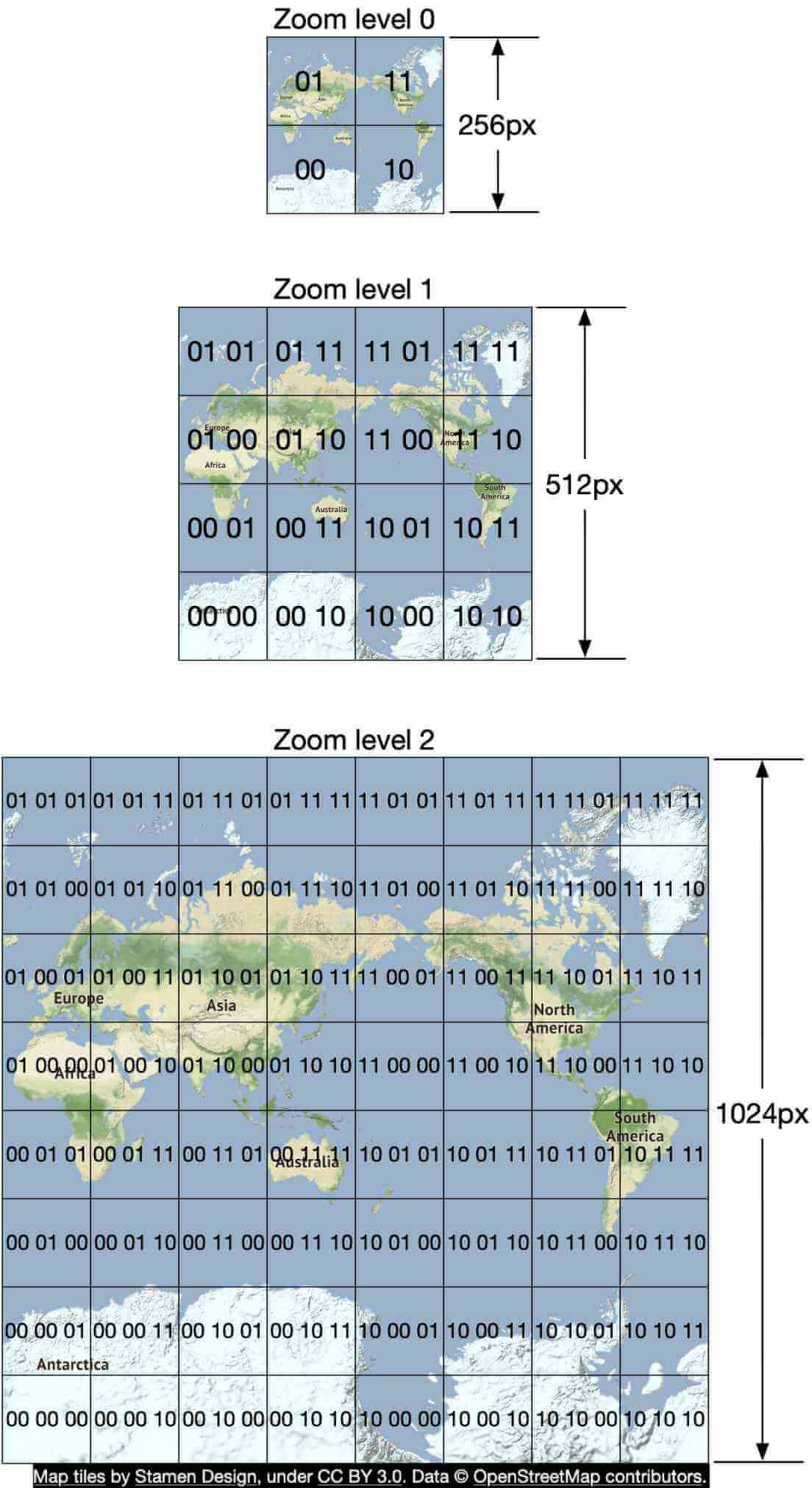
讓我們假設初始攤平的平面是 20,000 km _ 10,000 km 的大小。第一次切分後,我們會得到 4 個 10,000 km _ 5,000 km 的網格。如圖 3 所示,我們把它們表示為 00、01、10 與 11。我們再進一步把每個網格切分成 4 個網格,並使用相同的命名策略。每個子網格現在的大小為 5,000 km * 2,500 km。我們遞迴地切分網格,直到每個網格達到某個尺寸門檻。
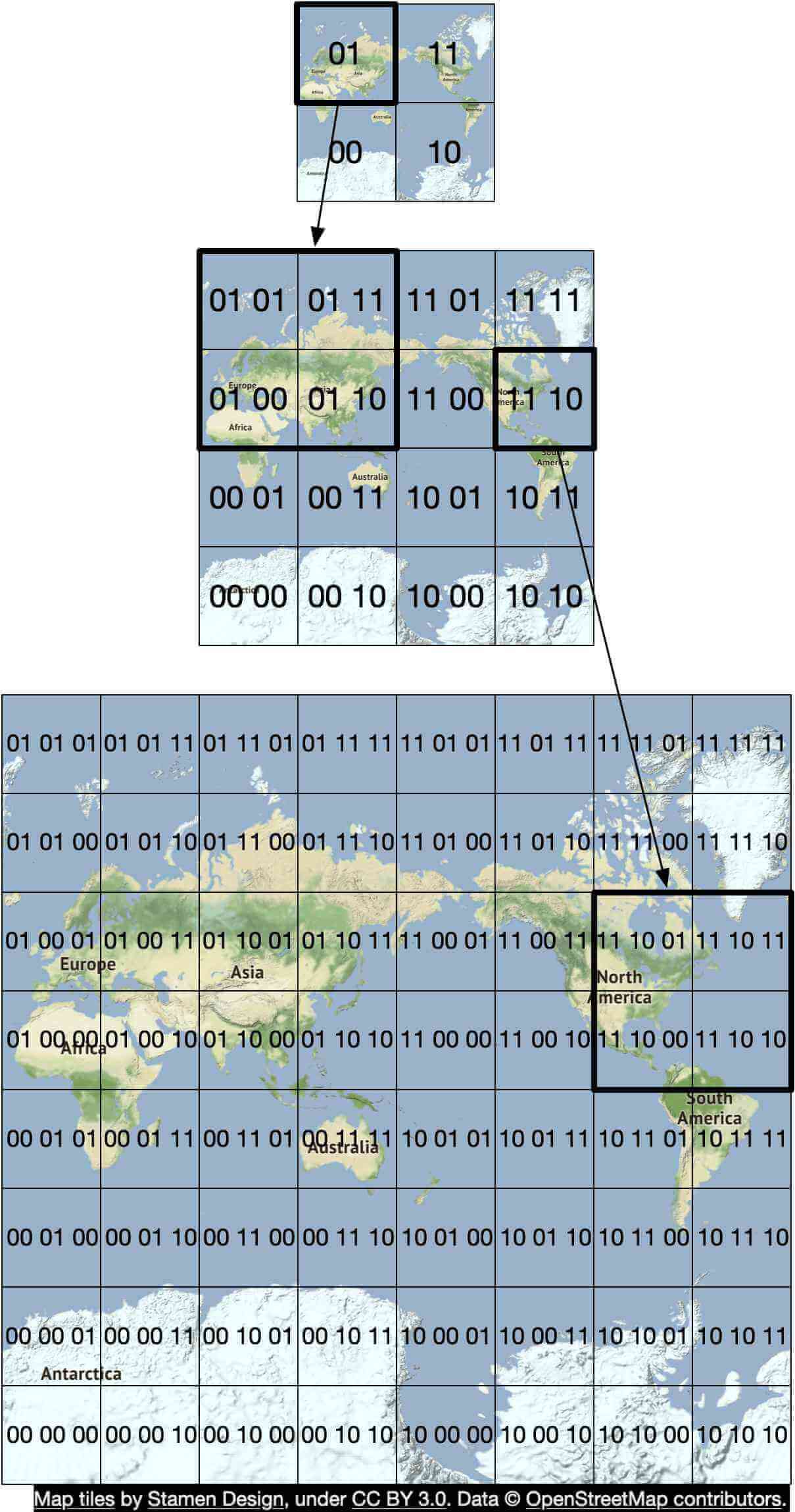
Geohashing 有許多用途。在我們的設計中,我們把 geohashing 用於地圖磚(map tiling)。關於 geohashing 與其優點的更多細節,請參考 [11]。
Map rendering#
我們不會在這裡詳述地圖渲染,但仍值得提一下基本概念。地圖渲染的一個基礎概念就是 tiling(拼磚)。世界並非以單張大型自訂影像呈現,而是被切分為許多較小的圖磚。客戶端只下載使用者所在區域相關的圖磚,並像馬賽克一樣將它們拼接起來顯示。
不同 zoom level(縮放等級)會有不同的圖磚集。客戶端會根據視窗的縮放等級選擇對應的圖磚集。這提供了適切的地圖細節,同時不會耗用過多頻寬。
舉個極端例子說明,當客戶端縮到最遠以顯示整個世界時,我們不會想要為非常高的縮放等級下載數十萬張圖磚。所有的細節都會被浪費掉。相反地,客戶端會在最低縮放等級下載一張圖磚,以一張 256x256 像素的影像來代表整個世界。
Road data processing for navigation algorithms#
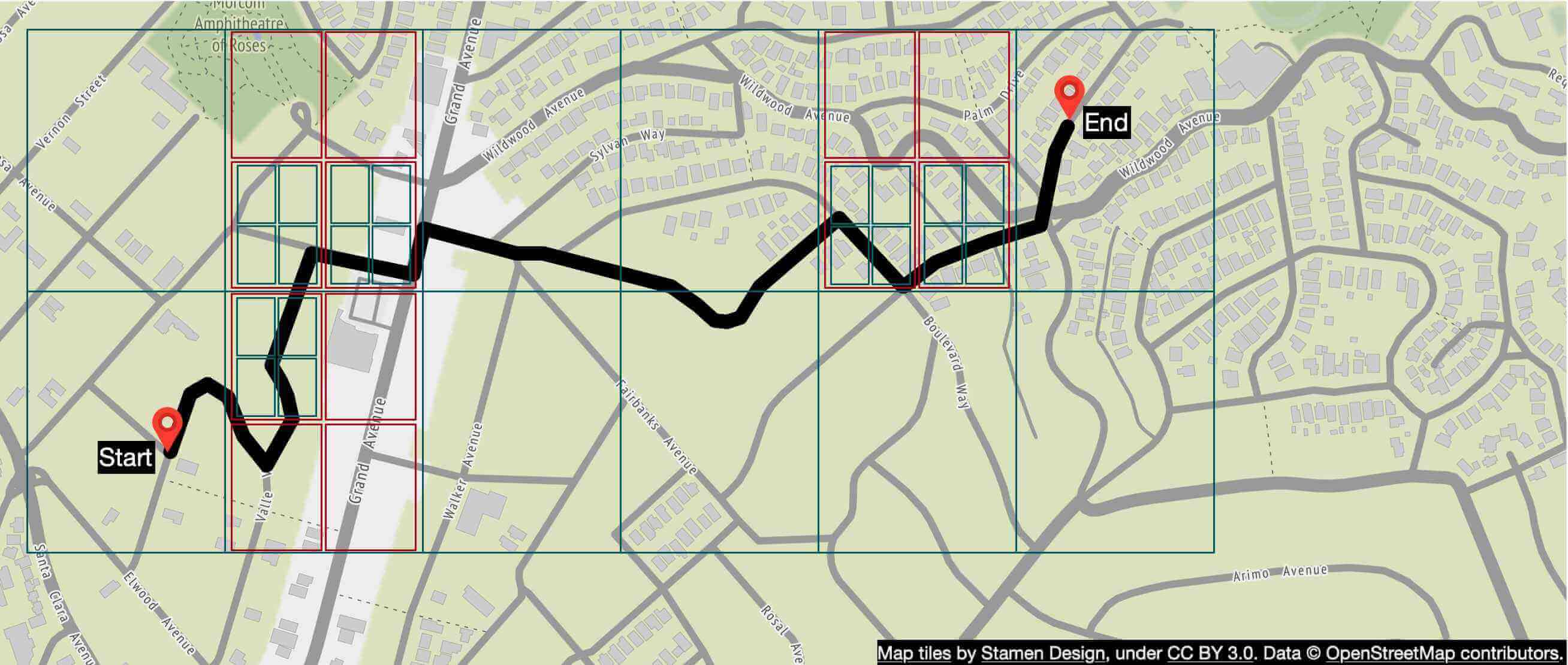
大多數的路徑規劃演算法都是 Dijkstra 或 A* 路徑搜尋演算法的變形。確切的演算法選擇是個複雜主題,本章不會深入探討。重要的是這些演算法都在圖(graph)資料結構上運作,其中交叉路口是節點(node),道路是邊(edge)。請見圖 4 範例:

對於這些演算法,路徑搜尋的效能對圖的大小極為敏感。如果把全世界的道路網路表示為單一圖,會耗用過多記憶體,而且對任何這些演算法來說都太大,難以高效執行。圖必須被切分為可管理的單位,這些演算法才能在我們的設計規模下運作。
切分全球道路網路的一種方式,與我們在地圖渲染中討論的拼磚概念非常類似。透過類似 geohashing 的細分技術,我們把世界切分為小網格。對於每個網格,我們把該網格內的道路轉換為一個小圖資料結構,包含該網格地理區域內的節點(交叉路口)與邊(道路)。我們稱這些網格為 routing tile(路由磚)。每個 routing tile 都保留其相連 tile 的參考。這正是路徑規劃演算法在這些相互連接的 routing tile 上巡訪、組合更大道路圖的方式。
藉由把道路網路切分為可隨選載入的 routing tile,路徑規劃演算法可以顯著降低記憶體耗用量,並透過一次只使用一小部分 routing tile(並且只在需要時載入額外 tile)來提升路徑搜尋效能。

在圖 5 中,我們把這些網格稱為 routing tile。Routing tile 與地圖磚相似的地方在於兩者都是覆蓋特定地理區域的網格。地圖磚是 PNG 影像,而 routing tile 是該磚所覆蓋區域之道路資料的二進位檔。
Hierarchical routing tiles
高效的導航路徑規劃也需要適當層級的詳細道路資料。例如對於跨國路徑規劃,若用詳細到街道層級的 routing tile 跑路徑規劃演算法,速度會很慢。把這些細節 routing tile 組合而成的圖很可能太大,會耗用過多記憶體。
通常會有三組不同詳細程度的 routing tile:
- 最詳細的層級:routing tile 較小,且只包含本地道路。
- 中間層級:tile 較大,只包含連接區域的主要幹道。
- 最低詳細層級:tile 涵蓋大範圍區域,且只包含連接城市與州的主要高速公路。
每個層級之間可能有邊連接到不同 zoom level 的 tile。例如從本地街道 A 進入高速公路 F 的匝道,會有一條由小 tile 中的節點(街道 A)連到大 tile 中節點(高速公路 F)的參考。圖 6 是不同尺寸 routing tile 的範例。
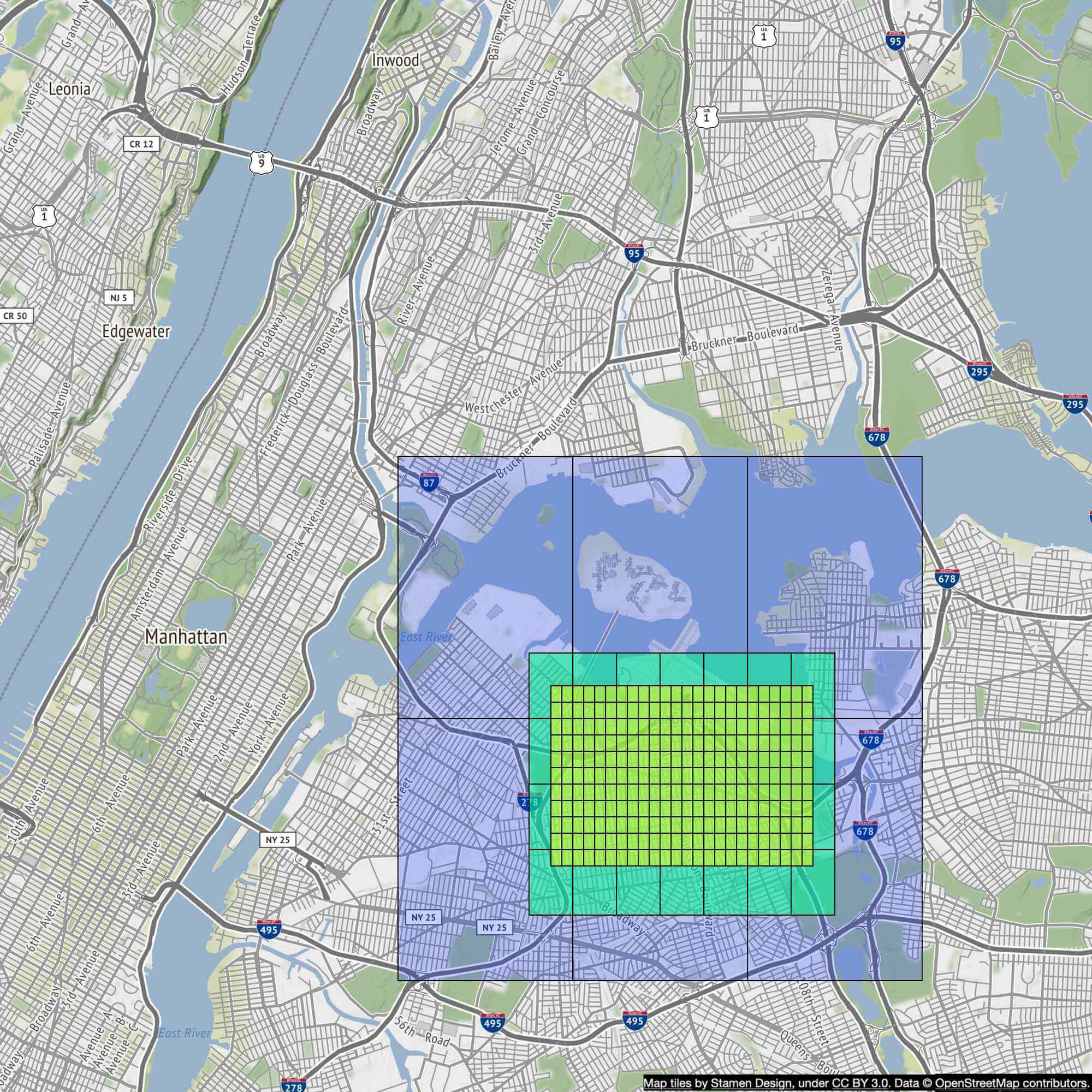
Back-of-the-envelope estimation#
了解了基礎之後,讓我們做粗略估算。由於設計聚焦在行動裝置,資料用量與電池消耗是兩個重要的考量因素。
在開始估算之前,這裡列出一些英制/公制換算供參考:
- 1 foot = 0.3048 meters
- 1 kilometer (km) = 0.6214 miles
- 1 km = 1,000 meters
Storage usage#
我們需要儲存三類資料:
- 世界地圖:詳細計算如下方所示。
- Metadata:每張地圖磚的 metadata 大小可以忽略不計,故我們在計算中略過。
- 道路資訊:面試官告訴我們從外部來源取得了 TBs 的道路資料。我們把這份資料集轉換為 routing tile,這也很可能是 TB 等級。
世界地圖
我們在 Map 101 一節中討論了地圖拼磚的概念。每個 zoom level 都有一組地圖磚。為了瞭解整個地圖磚集合的儲存需求,先估算最高 zoom level 中最大磚集的大小會很有幫助。在 zoom level 21,大約有 4.3 兆張圖磚(表 1)。讓我們假設每張圖磚是一張 256 _ 256 像素的壓縮 PNG 影像,影像大小約 100 KB。最高 zoom level 的整個磚集大約需要 4.4 兆 _ 100 KB = 440 PB。
表 1 顯示每個 zoom level 的圖磚數量遞增:
| Zoom | 圖磚數量 |
|---|---|
| 0 | 1 |
| 1 | 4 |
| 2 | 16 |
| 3 | 64 |
| 4 | 256 |
| 5 | 1 024 |
| 6 | 4 096 |
| 7 | 16 384 |
| 8 | 65 536 |
| 9 | 262 144 |
| 10 | 1 048 576 |
| 11 | 4 194 304 |
| 12 | 16 777 216 |
| 13 | 67 108 864 |
| 14 | 268 435 456 |
| 15 | 1 073 741 824 |
| 16 | 4 294 967 296 |
| 17 | 17 179 869 184 |
| 18 | 68 719 476 736 |
| 19 | 274 877 906 944 |
| 20 | 1 099 511 627 776 |
| 21 | 4 398 046 511 104 |
表 1 縮放等級
然而請記住,地球表面約 90% 是自然且大多無人居住的區域,例如海洋、沙漠、湖泊與山脈。由於這些區域的影像高度可壓縮,我們可以保守地把儲存估算減少 80-90%。這會把儲存大小降到 44 至 88 PB 之間。讓我們選一個簡單的整數:50 PB。
接下來,讓我們估算每個下一層(較低)zoom level 需要多少儲存空間。每降一個 zoom level,南北與東西方向的圖磚數量都各減半,整體圖磚數量減少 4 倍,因此該 zoom level 的儲存大小也減少 4 倍。每降一個 zoom level 大小減少 4 倍,總大小的計算便是個級數:50 + 50/4 + 50/16 + 50/64 + … = ~67 PB。這只是粗估,但已經足夠告訴我們大約需要 100 PB 來儲存所有不同詳細程度的地圖磚。
Server throughput#
為了估算伺服器吞吐量,讓我們檢視需要支援的請求類型。主要有兩種請求:
- 導航請求:由客戶端送出以啟動導航 session。
- 位置更新請求:由客戶端在使用者於導航 session 期間移動時送出。位置資料會被下游服務以許多不同方式使用,例如位置資料是即時交通資料的輸入之一。位置資料的使用情境會在設計深入探討部分介紹。
現在我們可以分析導航請求的伺服器吞吐量。假設我們有 10 億 DAU,每位使用者每週使用導航的總時間為 35 分鐘。換算為每週 350 億分鐘,或每天 50 億分鐘。
一個簡單的方式是每秒送出 GPS 座標,這會產生每天 3,000 億次(50 億分鐘 * 60)請求,或 300 萬 QPS(3,000 億請求 / 10^5 = 300 萬)。
但客戶端不需要每秒都送 GPS 更新。我們可以在客戶端做批次處理,並以較低的頻率(例如每 15 秒或 30 秒)送出,以降低寫入 QPS。實際頻率可以取決於使用者移動速度等因素。如果使用者塞在車陣中,客戶端可以放慢 GPS 更新。
在我們的設計中,我們假設 GPS 更新會被批次處理,並每 15 秒送到伺服器一次。透過此批次方式,QPS 降到 200,000(300 萬 / 15)。
假設尖峰 QPS 為平均的 5 倍。位置更新的尖峰 QPS = 200,000 * 5 = 100 萬。
Step 2 - Propose High-Level Design and Get Buy-In#
了解 Google Maps 之後,我們可以提出高階設計(圖 7)。
High-level design#

高階設計支援三項功能。讓我們逐一檢視:
- 位置服務(Location service)
- 導航服務(Navigation service)
- 地圖渲染(Map rendering)
Location service#
位置服務負責記錄使用者的位置更新。架構如圖 8 所示。

基本設計要求客戶端每 t 秒送出一次位置更新,t 是可設定的間隔。定期更新有幾個好處:
- 我們可以利用位置資料的串流隨時間改善系統。我們可以用這份資料來監控即時交通、偵測新增或關閉的道路、分析使用者行為以實現個人化等。
- 我們可以近即時地利用位置資料,提供更精準的 ETA 估算給使用者,並在必要時繞開交通。
但是我們真的需要把每筆位置更新立即送到伺服器嗎?答案大概是不需要。位置歷史可以在客戶端緩衝,再以較低的頻率批次送到伺服器。例如圖 9 所示,位置每秒記錄一次,但每 15 秒才以批次形式送到伺服器。這顯著地降低所有客戶端送出的總更新流量。

對於 Google Maps 這樣的系統,即使位置更新已批次處理,寫入量仍然非常大。我們需要一個專為高寫入量最佳化、且高度可擴展的資料庫,例如 Cassandra。我們可能也需要透過串流處理引擎(如 Kafka)記錄位置資料以便進一步處理。我們會在深入探討部分詳細討論這部分。
什麼樣的通訊協定適合呢?啟用 keep-alive 選項的 HTTP [12] 是不錯的選擇,因為它非常有效率。HTTP 請求看起來可能像這樣:
POST /v1/locations
Parameters
locs: JSON encoded array of (latitude, longitude, timestamp) tuples.Navigation service#
此元件負責找出從 A 點到 B 點的合理快速路線。我們可以容忍少許延遲。計算出來的路線不必是最快的,但精確性是關鍵。
如圖 8 所示,使用者透過負載平衡器把 HTTP 請求送到導航服務。請求包含起點與終點作為參數。API 看起來可能像這樣:
GET /v1/nav?origin=1355+market+street,SF&destination=Disneyland以下是導航結果可能的範例:
{
"distance": { "text": "0.2 mi", "value": 259 },
"duration": { "text": "1 min", "value": 83 },
"end_location": { "lat": 37.4038943, "Ing": -121.9410454 },
"html_instructions": "Head <b>northeast</b> on <b>Brandon St</b> toward <b>Lumin Way</b><div style=\"font-size:0.9em\">Restricted usage road</div>",
"polyline": { "points": "_fhcFjbhgVuAwDsCal" },
"start_location": { "lat": 37.4027165, "lng": -121.9435809 },
"geocoded_waypoints": [
{
"geocoder_status": "OK",
"partial_match": true,
"place_id": "ChIJwZNMti1fawwRO2aVVVX2yKg",
"types": ["locality", "political"]
},
{
"geocoder_status": "OK",
"partial_match": true,
"place_id": "ChIJ3aPgQGtXawwRLYeiBMUi7bM",
"types": ["locality", "political"]
}
],
"travel_mode": "DRIVING"
}關於 Google Maps 官方 API 的更多細節,請參考 [13]。
到目前為止,我們尚未把改路(reroute)與交通變化納入考量。這些問題會在深入探討部分由 Adaptive ETA 服務處理。
Map rendering#
如同我們在粗略估算中討論的,所有 zoom level 的地圖磚集合大小約為一百 PB。在客戶端保存整個資料集並不實際。地圖磚必須根據客戶端的位置與視窗縮放等級隨選從伺服器取回。
客戶端應該何時從伺服器取得新的地圖磚?以下是一些情境:
- 使用者在客戶端縮放與平移地圖視窗以探索周圍環境。
- 在導航期間,使用者從目前的地圖磚移動到鄰近的圖磚。
我們處理的資料量很大。讓我們看看如何高效地從伺服器提供這些地圖磚。
Option 1
伺服器根據客戶端位置與視窗縮放等級即時建立地圖磚。考量到位置與縮放等級的組合無限多,動態產生地圖磚有幾個嚴重缺點:
- 它對伺服器叢集造成龐大負擔來動態產生每張地圖磚。
- 由於地圖磚是動態產生的,難以利用快取。
Option 2
另一個選項是提供每個 zoom level 預先產生的地圖磚集。地圖磚是靜態的,每張圖磚以 geohashing 之類的細分機制涵蓋一個固定的矩形網格。每張圖磚因此可由其 geohash 表示。換句話說,每個網格都有一個唯一的 geohash。當客戶端需要某張地圖磚時,它會先根據自己的縮放等級決定要使用的地圖磚集合。它接著根據自己的位置計算出對應 zoom level 的 geohash,組合出地圖磚 URL。
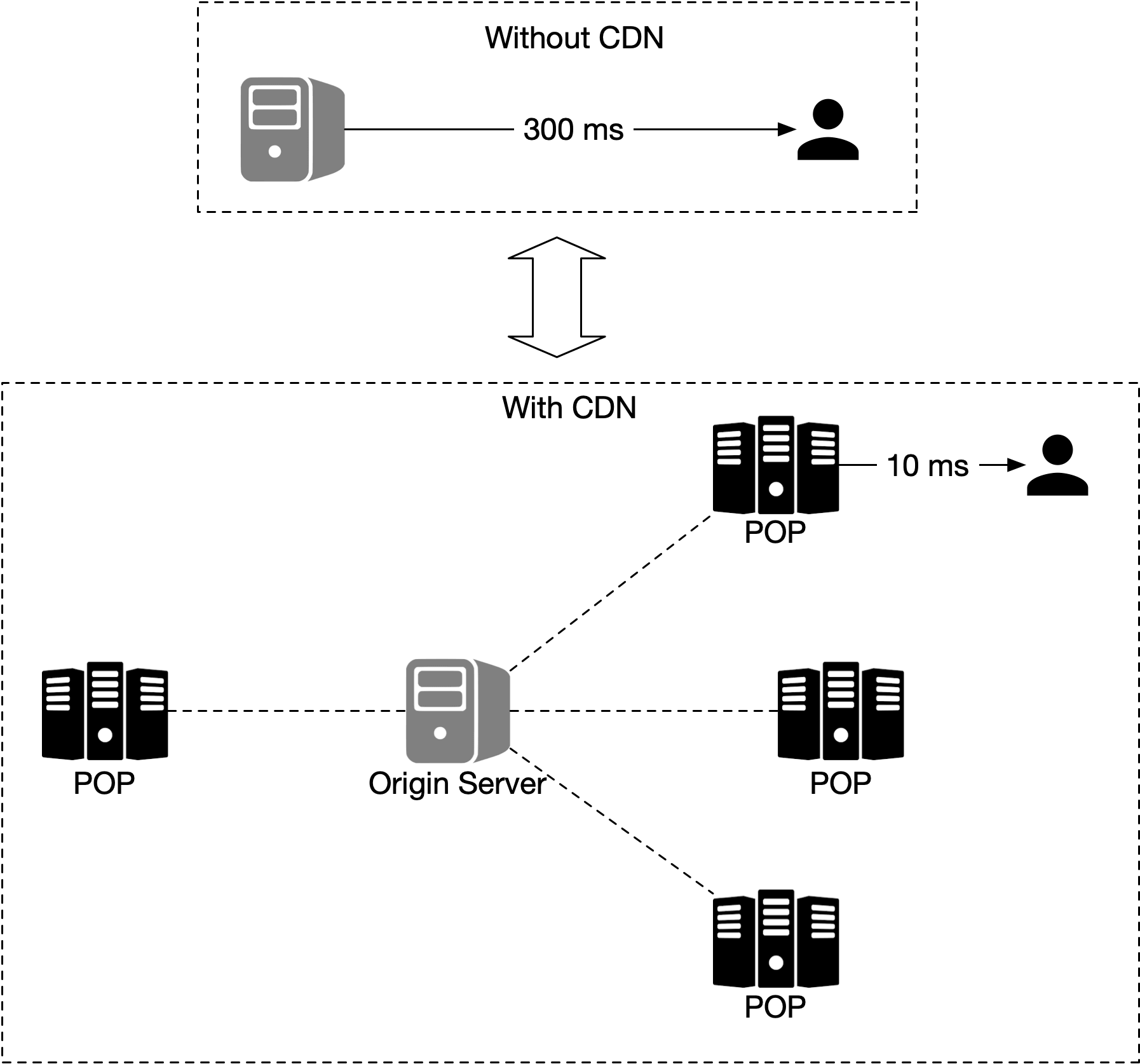
這些靜態、預先產生的影像由 CDN 提供,如圖 10 所示。

在上圖中,行動使用者向 CDN 發送 HTTP 請求以取得圖磚。如果 CDN 之前未曾提供過該特定圖磚,它會從來源伺服器取一份副本,並在本地快取後回傳給使用者。後續請求即使來自不同使用者,CDN 也會直接回傳快取副本,無需聯繫來源伺服器。
這種做法更具擴展性與效能,因為地圖磚從離客戶端最近的接入點(POP)提供,如圖 11 所示。地圖磚的靜態特性使其極為適合快取。
降低行動資料用量很重要。讓我們計算典型導航 session 期間客戶端需要載入的資料量。請注意以下計算未把客戶端快取納入考量。由於使用者每天走的路線可能類似,實際資料用量很可能因為客戶端快取而更低。
| 資料用量 |
|---|
| 假設使用者以每小時 30 公里移動,且在某 zoom level 下每張影像涵蓋 200m200m 的區塊(一個區塊以 256 像素 * 256 像素的影像表示,平均影像大小為 100 KB)。對於 1km1km 的區域,我們需要 25 張影像,即 2.5 MB(25 * 100KB)的資料。因此,若速度為每小時 30 公里,每小時需要 75 MB(30 * 2.5 MB)的資料,或每分鐘 1.25 MB。 |
表 2 資料用量
接下來估算 CDN 資料用量。在我們的規模下,成本是重要的考量因素。
| 透過 CDN 的流量 |
|---|
| 如先前所述,我們每天提供 50 億分鐘的導航。 換算為 50 億 * 1.25 MB = 每天 62.5 億 MB。因此, 我們每秒提供 62,500 MB(62.5 億 / 一天 10^5 秒)的地圖資料。 有了 CDN,這些地圖影像會從遍布世界各地的 POP 提供。 假設有 200 個 POP。每個 POP 每秒只需提供 數百 MB(62,500 / 200)。 |
表 3 透過 CDN 的流量
地圖渲染設計還有一個我們只簡單帶過的細節。客戶端如何知道從 CDN 取得地圖磚要用哪些 URL?請記住我們使用上述的 option 2。在這個方案中,地圖磚是靜態的,並依固定的網格組預先產生,每組代表一個離散的 zoom level。
由於我們以 geohash 編碼網格,每個網格都有一個唯一的 geohash,從客戶端的位置(緯度與經度)和縮放等級轉換為地圖磚的 geohash 在計算上非常有效率。這個計算可以在客戶端完成,我們就可以從 CDN 取得任何靜態圖磚。例如 Google 總部的圖磚 URL 看起來可能像這樣:
https://cdn.map-provider.com/tiles/9q9hvu.png
geohash 編碼的更詳細討論,請參考鄰近服務章節。
在客戶端計算 geohash 應該行得通。然而請記住,這個演算法是寫死在所有平台的客戶端中。把變更發布到行動應用是耗時且有點風險的過程。我們得確定 geohashing 是我們長期想用來編碼地圖磚集合的方法,並且不太可能改變。如果因為某些原因需要改用其他編碼方法,會花費大量心力且風險不低。
這裡還有一個值得考慮的選項。我們不寫死客戶端的演算法,而是引入一個服務作為中介,其工作就是根據相同輸入建構圖磚 URL。這是一個非常簡單的服務。額外得到的運維彈性可能值得。這是一個與面試官討論很有意思的取捨。替代的地圖渲染流程如圖 12 所示。
當使用者移動到新位置或新的縮放等級時,地圖磚服務會決定需要哪些圖磚,並把該資訊轉換為一組要取回的圖磚 URL。

- 行動使用者呼叫地圖磚服務以取得圖磚 URL。請求被送到負載平衡器。
- 負載平衡器把請求轉送到地圖磚服務。
- 地圖磚服務以客戶端位置與縮放等級作為輸入,回傳 9 個圖磚 URL 給客戶端。這些 tile 包括要渲染的圖磚與周圍 8 張圖磚。
- 行動客戶端從 CDN 下載圖磚。
我們會在設計深入探討部分對預先計算的地圖磚做更詳細的說明。
Step 3 - Design Deep Dive#
在本節中,我們會先討論資料模型,接著更詳細地討論位置服務、導航服務與地圖渲染。
Data model#
我們處理四種資料:
- Routing tile
- 使用者位置資料
- Geocoding 資料
- 預先計算的世界地圖磚
Routing tiles#
如先前所述,初始道路資料集從不同來源與機構取得,包含 TB 等級的資料。資料集會隨著應用程式持續從使用者身上收集位置資料而逐步改善。
該資料集包含大量道路與相關 metadata,例如名稱、郡名、經度與緯度。這些資料未組織為圖資料結構,無法被多數路徑規劃演算法使用。我們執行一個定期離線處理 pipeline,稱為 routing tile 處理服務(routing tile processing service),把這份資料集轉換為先前介紹的 routing tile。該服務定期執行,以擷取道路資料的新變更。
routing tile 處理服務的輸出就是 routing tile。如同 Map 101 一節所描述,這些 routing tile 有三組不同解析度。每張 tile 包含一份圖節點與邊的清單,代表該 tile 涵蓋區域內的交叉路口與道路。它也包含其道路所連接到的其他 tile 的參考。這些 tile 共同形成一個相互連接的道路網路,路徑規劃演算法可以漸進地使用。
routing tile 處理服務應該把這些 tile 儲存在哪裡?多數圖資料以記憶體中的鄰接串列(adjacency list) [14] 表示。tile 太多,無法把整組鄰接串列保存在記憶體中。我們可以把節點與邊以資料庫中的 row 儲存,但這只是把資料庫當成儲存來用,而且這種方式儲存零散資料相當昂貴。我們也不需要 routing tile 用到任何資料庫的功能。
更有效率的儲存方式是使用物件儲存(如 S3),並在使用這些 tile 的路徑規劃服務上積極做快取。有許多高效能的軟體套件可以把鄰接串列序列化為二進位檔。我們可以在物件儲存中以 geohash 來組織這些 tile,這提供了透過緯度/經度組合快速查找 tile 的機制。
我們稍後會討論最短路徑服務如何使用這些 routing tile。
User location data#
使用者位置資料很有價值。我們用它來更新道路資料與 routing tile,也用它來建立即時與歷史交通資料的資料庫。這份位置資料也會被多個資料串流處理服務消費,以更新地圖資料。
對於使用者位置資料,我們需要一個能良好處理寫入密集工作負載且可水平擴展的資料庫。Cassandra 會是不錯的選擇。
下面是單一 row 看起來可能的樣子:
| user_id | timestamp | user_mode | driving_mode | location |
|---|---|---|---|---|
| 101 | 1635740977 | active | driving | (20.0, 30.5) |
表 4 位置資料表
Geocoding database#
此資料庫儲存地點及其對應的緯度/經度組合。我們可以使用 key-value 資料庫(如 Redis)以提供快速讀取,因為我們有頻繁讀取與不頻繁寫入。我們用它把起點或終點轉換為緯度/經度組合,然後再傳給路線規畫服務。
Precomputed images of the world map#
當裝置請求某個區域的地圖時,我們需要取得附近道路並計算出代表該區域的影像,包含所有道路與相關細節。這些計算很重且重複,因此一次計算後快取影像很有幫助。我們在不同 zoom level 預先計算影像,並存放在 CDN 上,CDN 後端則由 Amazon S3 之類的雲端儲存支援。下方是這類影像的範例:

Services#
討論完資料模型後,讓我們仔細看看一些最重要的服務:位置服務、地圖渲染服務與導航服務。
Location service#
我們在高階設計中討論過位置服務的運作方式。在本節中,我們聚焦於此服務的資料庫設計,以及使用者位置如何被詳細運用。
在圖 14 中,key-value 儲存被用來儲存使用者位置資料。讓我們仔細看看。

由於我們每秒有 100 萬筆位置更新,我們需要一個支援快速寫入的資料庫。NoSQL key-value 資料庫或欄式(column-oriented)資料庫會是好選擇。
此外,使用者位置會持續變化,且新的更新一到,舊的就過時了。因此我們可以優先考慮可用性而非一致性。CAP 定理 [15] 指出我們在一致性、可用性與分區容錯性之中只能選兩個。考量我們的限制,我們會選擇可用性與分區容錯性。Cassandra 是合適的資料庫,能在我們的規模下提供強大的可用性保證。
key 是 (user_id, timestamp) 的組合,value 是緯度/經度組合。在這個設定中,user_id 是 primary key,timestamp 是 clustering key。把 user_id 當作 partition key 的優點是我們可以快速讀取特定使用者的最新位置。所有相同 partition key 的資料儲存在一起,依 timestamp 排序。在這種安排下,取得特定使用者在某時間範圍內的位置資料會非常有效率。
下面是表格可能的範例:
| key (user_id) | timestamp | lat | long | user_mode | navigation_mode |
|---|---|---|---|---|---|
| 51 | 132053000 | 21.9 | 89.8 | active | driving |
表 5 位置資料
我們如何使用使用者位置資料?
使用者位置資料是必要的。它支援許多使用情境:
- 我們用該資料來偵測新增與最近關閉的道路。
- 我們把它作為改善地圖精準度的輸入之一。
- 它也是即時交通資料的輸入。
為了支援這些使用情境,除了把使用者目前位置寫入資料庫外,我們也把這資訊記錄到訊息佇列(如 Kafka)。Kafka 是一個統一的低延遲、高吞吐量資料串流平台,專為即時資料 feed 設計。圖 15 展示在改良後的設計中如何使用 Kafka。

其他服務從 Kafka 消費位置資料串流以滿足各種使用情境。例如:
- 即時交通服務:消化輸出串流並更新即時交通資料庫。
- routing tile 處理服務:透過偵測新增或關閉的道路並更新物件儲存中受影響的 routing tile,藉此改善世界地圖。
- 其他服務也可以接入串流以滿足不同目的。
Rendering map#
在本節中,我們深入探討預先計算的地圖磚與地圖渲染最佳化。它們主要受到 Google Design [5] 工作的啟發。
Precomputed tiles#
如先前所述,有不同的 zoom level 預先計算地圖磚集,根據客戶端視窗大小與縮放等級提供適切層級的地圖細節給使用者。Google Maps 使用 21 個 zoom level(表 1),我們也採用此設計。
Level 0 是最縮小的層級,整個地圖以一張 256 * 256 像素的圖磚表示。
每增加一個 zoom level,地圖磚的數量在南北與東西方向都各加倍,每張圖磚仍維持 256 * 256 像素。如圖 16 所示:
- 在 zoom level 1 有 2 x 2 張圖磚,總組合解析度為 512 * 512 像素。
- 在 zoom level 2 有 4 x 4 張圖磚,總組合解析度為 1024 * 1024 像素。
每增加一級,整組圖磚的像素數量是上一級的 4 倍。增加的像素數量提供使用者更高的細節層級。這讓客戶端可以根據縮放等級以最佳細粒度渲染地圖,同時不消耗過多頻寬下載過於詳細的圖磚。
Optimization: use vectors#
隨著 WebGL 的發展與實作,一個潛在改進是把設計從透過網路傳送影像,改為傳送向量資訊(路徑與多邊形)。客戶端從向量資訊繪製路徑與多邊形。
向量圖磚的好處有:
- 頻寬節省:向量圖磚的一個明顯優點是向量資料的壓縮率比影像好很多,頻寬節省非常顯著。
- 平順的縮放體驗:一個比較不明顯的好處是向量圖磚提供更好的縮放體驗。對於點陣影像,當客戶端從一個 level 縮放到另一個 level 時,每個元素都會被拉伸並出現像素化。視覺效果相當突兀。對於向量化影像,客戶端可以適當地縮放每個元素,提供更平順的縮放體驗。
Navigation service#
接下來,讓我們深入探討導航服務。此服務負責尋找最快的路線。設計圖如圖 17 所示。

讓我們逐一檢視系統中的每個元件。
Geocoding service#
首先,我們需要一個服務把地址解析為緯度與經度組合的位置。地址可以是不同格式,例如可以是地點名稱或文字地址。
下面是 Google geocoding API 的請求與回應範例。
Request:
https://maps.googleapis.com/maps/api/geocode/json?address=1600+Amphitheatre+Parkway,+Mountain+View,+CAJSON response:
{
"results": [
{
"formatted_address": "1600 Amphitheatre Parkway, Mountain View, CA 94043, USA",
"geometry": {
"location": {
"lat": 37.4224764,
"lng": -122.0842499
},
"location_type": "ROOFTOP",
"viewport": {
"northeast": {
"lat": 37.4238253802915,
"lng": -122.0829009197085
},
"southwest": {
"lat": 37.4211274197085,
"lng": -122.0855988802915
}
}
},
"place_id": "ChIJ2eUgeAK6j4ARbn5u_wAGqWA",
"plus_code": {
"compound_code": "CWC8+W5 Mountain View, California, United States",
"global_code": "849VCWC8+W5"
},
"types": ["street_address"]
}
],
"status": "OK"
}導航服務在把緯度/經度組合送往下游尋找路線之前,會呼叫此服務對起點與終點進行 geocoding。
Route planner service#
此服務根據目前的交通與道路狀況,計算出針對行車時間最佳化的建議路線。它與多個服務互動,以下會接著討論。
Shortest-path service#
最短路徑服務接收緯度/經度組合的起點與終點,並回傳前 k 個最短路徑,不考慮交通或目前狀況。此計算只取決於道路結構。在這裡,快取路線會有好處,因為圖很少改變。
最短路徑服務針對物件儲存中的 routing tile 執行 A* 路徑搜尋演算法的變形。下面是概要:
- 演算法接收緯度/經度組合的起點與終點。緯度/經度組合會被轉換為 geohash,用來載入起點與終點 routing tile。
- 演算法從起點 routing tile 出發,巡訪圖結構,並在擴展搜尋區域時從物件儲存(或其本地快取,如果之前載入過)取得額外的鄰近 tile。值得一提的是,不同層級之間有連接同一區域的 tile。例如演算法可以「進入」只包含高速公路的較大 tile。演算法持續擴展搜尋,依需要取得更多鄰近 tile(或不同解析度的 tile),直到找到一組最佳路線。
圖 18 提供圖巡訪所用 tile 的概念性概覽。
ETA service#
一旦路線規劃服務收到一份可能的最短路徑清單,它會為每條可能的路線呼叫 ETA 服務,取得時間估算。為此,ETA 服務使用機器學習,根據目前交通與歷史資料來預測 ETA。
這裡的挑戰之一是我們不只需要即時交通資料,還要預測 10 或 20 分鐘後交通會是什麼樣子。這類挑戰需要在演算法層級解決,本節不討論。如果有興趣,請參考 [16] 與 [17]。
Ranker service
最後,當路線規劃服務取得 ETA 預測後,它會把此資訊傳給 ranker,套用使用者定義的可能 filter。範例 filter 包括避開收費道路或避開高速公路。Ranker 服務接著把可能的路線從最快到最慢排序,並回傳前 k 個結果給導航服務。
Updater services#
這些服務接入 Kafka 位置更新串流,並非同步地更新一些重要的資料庫使其保持最新。交通資料庫與 routing tile 是其中的例子。
- routing tile 處理服務:負責把帶有新發現道路與道路關閉的道路資料集,轉換為持續更新的 routing tile 集合。這有助於最短路徑服務更精確。
- 交通更新服務:從活躍使用者送出的位置更新串流中萃取交通狀況。這些洞察會被輸入到即時交通資料庫,這讓 ETA 服務能提供更精準的估算。
Improvement: adaptive ETA and rerouting#
目前的設計不支援 adaptive ETA 與 rerouting。為解決此問題,伺服器需要追蹤所有正在導航的活躍使用者,並在交通狀況改變時持續更新他們的 ETA。這裡我們需要回答幾個重要問題:
- 我們如何追蹤正在導航的活躍使用者?
- 我們如何儲存資料,使我們能在數百萬條導航路線中有效率地定位受交通變化影響的使用者?
讓我們從一個直觀的方案開始。在圖 19 中,user_1 的導航路線由 routing tile r_1、r_2、r_3、…、r_7 表示。

資料庫儲存正在導航的活躍使用者與路線資訊,看起來可能像這樣:
- user_1: r_1, r_2, r_3, …, r_k
- user_2: r_4, r_6, r_9, …, r_n
- user_3: r_2, r_8, r_9, …, r_m
- …
- user_n: r_2, r_10, r21, …, r_l
假設在 routing tile 2(r_2)發生交通事件。要找出受影響的使用者,我們會掃描每一個 row,並檢查 routing tile 2 是否在我們的 routing tile 清單中(請見下方範例)。
- user_1: r_1, r_2, r_3, …, r_k
- user_2: r_4, r_6, r_9, …, r_n
- user_3: r_2, r_8, r_9, …, r_m
- …
- user_n: r_2, r_10, r_21, …, r_l
假設表中的 row 數為 n,導航路線的平均長度為 m。找出所有受交通變化影響的使用者的時間複雜度為 O (n * m)。
我們可以加速這個過程嗎?讓我們探索另一種方式。對每一位正在導航的活躍使用者,我們保留目前的 routing tile、包含它的下一個解析度層級的 routing tile,並遞迴地找到下一個解析度層級的 routing tile,直到我們在 tile 中也找到使用者的目的地(圖 20)。透過這種方式,我們可以得到資料庫表中如下的 row:
user_1, r_1, super(r_1), super(super(r_1)), …

要查明使用者是否受交通變化影響,我們只需檢查某個 routing tile 是否在資料庫某個 row 的最後一個 routing tile 內。如果不是,該使用者不受影響;如果是,則該使用者受影響。透過這種方式,我們可以快速過濾掉許多使用者。
這種方法沒有指定當交通恢復時會發生什麼。例如如果 routing tile 2 解除壅塞,使用者可以回到原本路線,使用者要怎麼知道有可改路的選擇?一個想法是追蹤導航中使用者的所有可能路線,定期重新計算 ETA,並在發現有 ETA 更短的新路線時通知使用者。
Delivery protocols
實際上在導航期間,路線狀況可能改變,伺服器需要一個可靠的方式把資料推送給行動客戶端。對於從伺服器到客戶端的傳遞協定,我們的選項包括行動推播通知、long polling、WebSocket 與 Server-Sent Events(SSE)。
- 行動推播通知:不是好選擇,因為 payload 大小非常有限(iOS 為 4,096 bytes),而且它不支援網頁應用。
- WebSocket vs long polling:WebSocket 通常被認為是比 long polling 更好的選擇,因為它在伺服器上的足跡很小。
- WebSocket vs SSE:既然我們已排除行動推播通知與 long polling,選擇主要在 WebSocket 與 SSE 之間。雖然兩者都可行,我們偏向 WebSocket,因為它支援雙向通訊,而最終一哩交付(last-mile delivery)等功能可能需要雙向即時通訊。
關於 ETA 與 rerouting 的更多細節,請參考 [16]。
現在我們把每一塊設計都湊在一起了。請見圖 21 的更新後設計。

Step 4 - Wrap Up#
在本章中,我們設計了一個簡化版的 Google Maps 應用程式,包含位置更新、ETA、路線規畫與地圖渲染等關鍵功能。
如果你想擴充這個系統,一個潛在的改進方向是為企業客戶提供多停靠點導航能力。例如給定一組目的地,我們必須根據即時交通狀況找到造訪所有目的地的最佳順序,並提供適切導航。這對於 Door Dash、Uber、Lyft 等外送或叫車服務會很有幫助。
恭喜你看到這裡!現在請拍拍自己的肩膀。做得好!
Chapter Summary#