在本章中,我們要為一個名為「附近的朋友(Nearby Friends)」的新型行動應用功能,設計一個可擴展的後端系統。對於選擇開啟並授權存取位置的使用者,行動裝置端會顯示一份在地理位置上鄰近的朋友清單。如果你想看現實世界的範例,可以參考這篇文章 [1],內容介紹 Facebook 應用程式中類似的功能。
如果你讀過鄰近服務(Proximity Service)那一章,你可能會疑惑為什麼「附近的朋友」需要單獨成一章,因為它看起來和鄰近服務很相似。但若仔細思考,你會發現有重大差異:
- 在鄰近服務中,商家的地址是靜態的,因為它們的位置不會改變。
- 在附近的朋友中,資料更為動態,因為使用者位置會頻繁變動。
Step 1 - Understand the Problem and Establish Design Scope#
任何在 Facebook 規模下的後端系統都很複雜。在開始設計之前,我們需要先問一些釐清問題以縮小範圍。
應徵者:地理上多接近才算「附近」?
面試官:5 英里。這個數字應該是可設定的。
應徵者:我可以假設距離是兩位使用者之間的直線距離嗎?實際上,例如可能有條河擋在使用者之間,造成實際移動距離較長。
面試官:可以,這是合理的假設。
應徵者:應用程式有多少使用者?我可以假設有 10 億使用者,其中 10% 使用「附近的朋友」功能嗎?
面試官:可以,這是合理的假設。
應徵者:我們需要儲存位置歷史紀錄嗎?
面試官:要的,位置歷史對許多用途都很有價值,例如機器學習。
應徵者:我們可以假設如果朋友超過 10 分鐘沒有活動,該朋友就會從附近朋友清單中消失嗎?或者我們應該顯示其最後已知位置?
面試官:我們可以假設不活躍的朋友不再顯示。
應徵者:我們需要考慮隱私與資料法規例如 GDPR 或 CCPA 嗎?
面試官:好問題。為了簡化,目前先不用擔心這些。
Functional requirements#
- 使用者應該能在行動應用中看到附近的朋友。附近朋友清單中的每一筆都包含距離以及該距離最後更新的時間戳記。
- 附近朋友清單應該每幾秒更新一次。
Non-functional requirements#
- 低延遲:從朋友那裡接收位置更新時不應有過多延遲。
- 可靠性:整體系統需可靠,但偶爾遺失少量資料點是可接受的。
- 最終一致性(Eventual consistency):位置資料儲存不需要強一致性。不同副本之間有幾秒鐘的位置資料延遲是可接受的。
Back-of-the-envelope estimation#
讓我們做一個粗略估算(back-of-the-envelope estimation),來判斷系統可能面臨的規模與挑戰。下列是一些限制與假設:
- 附近的朋友定義為位置在 5 英里半徑內的朋友。
- 位置刷新間隔為 30 秒。原因是人類步行速度很慢(平均每小時 3-4 英里),30 秒內移動的距離對「附近的朋友」功能影響不大。
- 平均每天有 1 億使用者使用「附近的朋友」功能。
- 假設同時上線使用者數為 DAU 的 10%,即同時上線使用者數為 1,000 萬。
- 平均每位使用者有 400 位朋友。假設這些朋友全部都使用「附近的朋友」功能。
- 應用程式每頁顯示 20 位附近朋友,並可在使用者請求時載入更多。
| 計算 QPS |
|---|
| - 1 億 DAU
- 同時上線使用者:10% * 1 億 = 1,000 萬
- 使用者每 30 秒回報一次位置。
- 位置更新 QPS = 1,000 萬 / 30 = ~334,000 |
Step 2 - Propose High-Level Design and Get Buy-In#
在本節中,我們會討論以下內容:
- 高階設計
- API 設計
- 資料模型
在其他章節中,我們通常會在高階設計之前討論 API 設計與資料模型。但是在這個問題中,客戶端與伺服器之間的通訊協定可能不是直接的 HTTP 協定,因為我們需要把位置資料推送給所有朋友。在尚未理解高階設計的情況下,很難知道 API 該長什麼樣子。因此我們先討論高階設計。
High-level design#
從高階角度來看,這個問題需要一個能高效進行訊息傳遞的設計。概念上,使用者希望從每一位附近的活躍朋友接收位置更新。理論上這可以純粹用點對點(peer-to-peer)的方式完成,也就是讓使用者對附近所有的活躍朋友都維持一條持久連線(圖 2)。

這個方案對於連線時常不穩、且電力預算有限的行動裝置而言並不實用,但這個想法仍對整體設計方向有所啟發。
更實用的設計會有一個共用的後端,看起來像這樣:

圖 3 中後端的職責有哪些?
- 接收所有活躍使用者的位置更新。
- 對於每一筆位置更新,找出所有應該收到此更新的活躍朋友,並轉送給這些使用者的裝置。
- 如果兩位使用者之間的距離超過某個門檻,則不要轉送給接收方裝置。
聽起來相當簡單。問題在哪?問題在於要在這個規模下實現並不容易。我們有 1,000 萬活躍使用者,每位使用者每 30 秒更新一次位置,因此每秒會有 334K 次更新。如果每位使用者平均有 400 位朋友,並進一步假設大約 10% 的朋友在線且鄰近,後端每秒就要轉送 334K _ 400 _ 10% = 1,400 萬筆位置更新。這是相當龐大的轉送量。
Proposed design#
我們會先在較低的規模下提出後端的高階設計。稍後在深入探討的部分,再針對規模進行最佳化。
圖 4 展示了能滿足功能需求的基本設計。讓我們逐一檢視每個元件。

Load balancer#
負載平衡器位於 RESTful API 伺服器與具狀態的雙向 WebSocket 伺服器之前。它將流量分散到這些伺服器上以平均分配負載。
RESTful API servers#
這是一群無狀態的 HTTP 伺服器,負責處理一般的請求/回應流量。API 請求流程如圖 5 所示。這個 API 層處理一些輔助任務,例如新增/移除朋友、更新使用者個人檔案等。這些都很常見,我們不再詳細說明。

Websocket servers#
這是一群具狀態的伺服器,負責處理朋友位置的近即時更新。每個客戶端會與其中一台 WebSocket 伺服器維持一條持久的連線。當搜尋半徑內的朋友有位置更新時,更新會透過此連線發送給客戶端。
WebSocket 伺服器另一項主要職責是處理「附近的朋友」功能的客戶端初始化。它會把所有附近線上朋友的位置先送給行動客戶端。我們稍後會更詳細討論這部分。
請注意「WebSocket 連線」與「WebSocket 連線處理器(connection handler)」在本章中可互換使用。
Redis location cache#
Redis 用來儲存每位活躍使用者最近的位置資料。快取中的每一筆都設有 Time to Live(TTL)。當 TTL 過期,使用者就被視為不活躍,位置資料會從快取中移除。每次更新都會刷新 TTL。其他支援 TTL 的 KV 儲存也可以使用。
User database#
使用者資料庫儲存使用者資料與好友關係資料。可以使用關聯式資料庫或 NoSQL 資料庫。
Location history database#
此資料庫儲存使用者的歷史位置資料。它與「附近的朋友」功能沒有直接關係。
Redis pub/sub server#
Redis pub/sub [2] 是一種非常輕量的訊息匯流排。在 Redis pub/sub 中建立 channel 的成本非常低。一台具備數 GB 記憶體的現代 Redis 伺服器可以容納數百萬個 channel(也稱為 topic)。圖 6 展示了 Redis Pub/Sub 的運作方式。

在這個設計中,透過 WebSocket 伺服器收到的位置更新會被發佈到該使用者在 Redis pub/sub 伺服器上的 channel。每位活躍朋友的專屬 WebSocket 連線處理器都會訂閱此 channel。當有位置更新時,WebSocket 處理器函式會被觸發,並針對每位活躍朋友重新計算距離。如果新的距離在搜尋半徑內,新的位置與時間戳記會透過 WebSocket 連線傳送給該朋友的客戶端。其他具備輕量 channel 的訊息匯流排也可以使用。
了解每個元件的功能後,讓我們從系統的角度來看,當使用者位置變更時會發生什麼事。
Periodic location update#
行動客戶端會透過持久的 WebSocket 連線定期送出位置更新。流程如圖 7 所示。

- 行動客戶端把位置更新送到負載平衡器。
- 負載平衡器把位置更新轉送到該客戶端在 WebSocket 伺服器上的持久連線。
- WebSocket 伺服器把位置資料儲存到位置歷史資料庫。
- WebSocket 伺服器在位置快取中更新新位置。此更新會刷新 TTL。WebSocket 伺服器也會在使用者的 WebSocket 連線處理器中以變數方式儲存新位置,以便後續距離計算之用。
- WebSocket 伺服器把新位置發佈到使用者於 Redis pub/sub 伺服器上的 channel。步驟 3 至 5 可以平行執行。
- 當 Redis pub/sub 在某個 channel 上收到位置更新時,它會把更新廣播給所有訂閱者(WebSocket 連線處理器)。在這個例子中,訂閱者就是發送更新者的所有線上朋友。對於每個訂閱者(即該使用者的每位朋友),其 WebSocket 連線處理器都會收到該使用者的位置更新。
- 收到訊息後,連線處理器所在的 WebSocket 伺服器會計算發送新位置的使用者(位置資料在訊息中)與訂閱者(位置資料儲存於該訂閱者 WebSocket 連線處理器的變數中)之間的距離。
- 此步驟未繪製於圖中。如果距離未超過搜尋半徑,新位置與最後更新的時間戳記會被傳送到訂閱者的客戶端。否則更新會被丟棄。
由於理解此流程極為重要,讓我們再用一個具體例子來檢視,如圖 8 所示。在開始之前,先做幾個假設:
- 使用者 1 的朋友:使用者 2、使用者 3、使用者 4。
- 使用者 5 的朋友:使用者 4 與使用者 6。

- 當使用者 1 的位置變更時,他們的位置更新會被送到持有使用者 1 連線的 WebSocket 伺服器。
- 該位置會被發佈到 Redis pub/sub 伺服器上使用者 1 的 channel。
- Redis pub/sub 伺服器會把位置更新廣播給所有訂閱者。在這個例子中,訂閱者就是 WebSocket 連線處理器(使用者 1 的朋友們)。
- 如果發送位置的使用者(使用者 1)與訂閱者(使用者 2)之間的距離未超過搜尋半徑,新位置會被傳送到該客戶端(使用者 2)。
對於 channel 的每一個訂閱者都會重複進行上述計算。由於平均每人有 400 位朋友,且我們假設其中 10% 的朋友線上且鄰近,因此每筆使用者位置更新大約會轉送 40 筆位置更新。
API design#
我們已經建立了高階設計,現在來列出所需的 API。
WebSocket:使用者透過 WebSocket 協定發送與接收位置更新。最少我們需要以下 API:
1. Periodic location update
- 請求:客戶端發送 latitude、longitude 與 timestamp。
- 回應:無。
2. Client receives location updates
- 傳送資料:朋友的位置資料與時間戳記。
3. WebSocket initialization
- 請求:客戶端發送 latitude、longitude 與 timestamp。
- 回應:客戶端接收朋友的位置資料。
4. Subscribe to a new friend
- 請求:WebSocket 伺服器發送朋友 ID。
- 回應:朋友最新的 latitude、longitude 與 timestamp。
5. Unsubscribe a friend
- 請求:WebSocket 伺服器發送朋友 ID。
- 回應:無。
HTTP requests:API 伺服器處理諸如新增/移除朋友、更新使用者個人檔案等任務。這些都很常見,這裡不再詳細說明。
Data model#
另一個需要討論的重要元素是資料模型。我們已經在高階設計中討論過 User DB,所以這裡聚焦在位置快取與位置歷史資料庫。
Location cache#
位置快取儲存所有開啟附近朋友功能的活躍使用者最近的位置。我們使用 Redis 作為快取。快取的 key/value 如表 1 所示。
| key | value |
|---|---|
| user_id | {latitude, longitude, timestamp} |
表 1 位置快取
為什麼不使用資料庫來儲存位置資料?
「附近的朋友」功能只關心使用者的目前位置。因此我們每位使用者只需儲存一筆位置。Redis 是絕佳選擇,因為它提供超快速的讀寫操作。它支援 TTL,我們用來自動清除不再活躍的使用者。目前的位置不需要持久化儲存。
如果 Redis 實例當機,我們可以用一個空的新實例取代,並讓快取隨著新的位置更新流入而被填滿。在新快取暖機期間,活躍使用者可能會有一兩個更新週期收不到朋友的位置更新。這是可接受的權衡。在深入探討的章節中,我們會討論如何降低快取被取代時對使用者的影響。
Location history database#
位置歷史資料庫儲存使用者的歷史位置資料,schema 如下:
| user_id | latitude | longitude | timestamp |
|---|
我們需要一個能良好處理重度寫入工作負載並可水平擴展的資料庫。Cassandra 是好的選擇。我們也可以使用關聯式資料庫,但是用關聯式資料庫時,歷史資料無法塞進單一實例,因此需要分片(shard)。最基本的方法是依使用者 ID 進行分片。這種分片方式可以確保負載平均分散到所有分片,且操作上易於維護。
Step 3 - Design Deep Dive#
我們在前一節建立的高階設計在大多數情況下都可運作,但是在我們的規模下很可能會崩潰。在本節中,我們會一起在規模逐步擴大的過程中找出瓶頸,並逐步提出解決這些瓶頸的方案。
How well does each component scale?#
API servers#
擴展 RESTful API 層的方法早已廣為人知。它們是無狀態伺服器,可以根據 CPU 用量、負載或 I/O 等多種方式自動擴展。這裡不再贅述。
WebSocket servers#
對於 WebSocket 叢集,根據用量自動擴展並不困難。然而 WebSocket 伺服器是有狀態的,因此移除既有節點時必須小心。在節點被移除前,所有既有連線都應該被允許正常結束(drain)。為達成此目的,我們可以在負載平衡器將節點標記為「draining」,使新的 WebSocket 連線不再被導向該節點。當所有既有連線都關閉(或經過合理長的等待時間後),該伺服器才會被移除。
在 WebSocket 伺服器上發布新版本的應用程式軟體也需要同樣謹慎。
值得一提的是,有效自動擴展具狀態伺服器是優秀負載平衡器的工作。多數雲端負載平衡器都能很好地處理這項工作。
Client Initialization
行動客戶端在啟動時會與其中一台 WebSocket 伺服器實例建立持久 WebSocket 連線。每條連線都是長時間運作的。多數現代語言都能以相當小的記憶體佔用維持大量長連線。
當 WebSocket 連線初始化時,客戶端會送出使用者的初始位置,伺服器會在 WebSocket 連線處理器中執行下列任務:
- 它會在位置快取中更新該使用者的位置。
- 它會把位置儲存到連線處理器中的變數,供後續計算之用。
- 它會從使用者資料庫載入該使用者所有朋友。
- 它會對位置快取發送批次請求,取得所有朋友的位置。請注意,由於我們在位置快取中為每筆設定的 TTL 與不活躍逾時時間相同,如果某個朋友不活躍,他們的位置就不會在位置快取中。
- 對於快取回傳的每個位置,伺服器會計算使用者與該位置的朋友之間的距離。如果距離在搜尋半徑內,朋友的個人檔案、位置與最後更新時間戳記會透過 WebSocket 連線回傳給客戶端。
- 對於每個朋友,伺服器會訂閱該朋友在 Redis pub/sub 伺服器上的 channel。我們稍後會解釋為何使用 Redis pub/sub。由於建立新 channel 的成本很低,使用者會訂閱所有活躍與不活躍朋友的 channel。不活躍的朋友在 Redis pub/sub 伺服器上會佔用少量記憶體,但在他們上線之前不會消耗任何 CPU 或 I/O(因為他們不會發佈更新)。
- 它會把使用者目前的位置送到使用者在 Redis pub/sub 伺服器上的 channel。
User database#
使用者資料庫儲存兩組不同的資料:使用者個人檔案(user ID、username、profile URL 等)與好友關係。在我們設計的規模下,這些資料集很可能無法塞進單一關聯式資料庫實例。好消息是,這些資料可以透過依使用者 ID 分片來水平擴展。關聯式資料庫分片是非常常見的技術。
順帶一提,在我們設計的規模下,使用者與好友關係資料很可能由專責團隊管理,並透過內部 API 提供。在這種情況下,WebSocket 伺服器會使用內部 API 來取得使用者與好友相關資料,而不是直接查詢資料庫。無論是透過 API 還是直接查詢資料庫,在功能或效能上差異不大。
Location cache#
我們選擇 Redis 來快取所有活躍使用者最近的位置。如同先前所述,我們在每個 key 上都設定 TTL,每次位置更新都會更新 TTL。這為記憶體用量設定了上限。在尖峰時段有 1,000 萬活躍使用者,每筆位置不超過 100 bytes,一台具備數 GB 記憶體的現代 Redis 伺服器即可輕鬆容納所有使用者的位置資料。
然而,1,000 萬活躍使用者每 30 秒約更新一次,Redis 伺服器每秒需處理 334K 次更新。對於現代高階伺服器來說都可能稍嫌過高。幸運的是,這份快取資料很容易分片。每位使用者的位置資料是獨立的,我們可以依使用者 ID 對位置資料進行分片,把負載平均分散到多台 Redis 伺服器上。
為了提升可用性,我們可以把每個分片上的位置資料複製到備援節點。如果主節點當機,備援節點可以快速被提升為主節點,以最小化停機時間。
Redis pub/sub server#
pub/sub 伺服器作為路由層,用來把訊息(位置更新)從一位使用者導向所有線上朋友。如先前所述,我們選擇 Redis pub/sub 是因為建立新 channel 的成本非常輕量。當有人訂閱某個 channel 時,該 channel 才會被建立。如果訊息被發佈到沒有訂閱者的 channel,該訊息會被丟棄,對伺服器幾乎沒有負擔。當 channel 被建立時,Redis 會使用少量記憶體來維護一個 hash table 與 linked list [3] 以追蹤訂閱者。如果使用者離線時 channel 上沒有更新,channel 建立後不會耗用任何 CPU 週期。我們在設計中以下列方式利用此特性:
- 我們為每位使用「附近的朋友」功能的使用者分配一個唯一的 channel。使用者在應用初始化時會訂閱每位朋友的 channel,無論該朋友是否上線。這簡化了設計,因為後端不需要在朋友上線時處理訂閱、或在朋友離線時處理取消訂閱。
- 取捨是這個設計會使用較多記憶體。我們稍後會看到,記憶體用量不太可能成為瓶頸。在這個情況下,以較高的記憶體用量換取較簡單的架構是值得的。
我們需要多少台 Redis pub/sub 伺服器?
讓我們做點記憶體與 CPU 用量的計算。
記憶體用量
假設為每位使用「附近的朋友」功能的使用者都分配一個 channel,我們需要 1 億個 channel(10 億 _ 10%)。假設平均每位使用者有 100 位活躍朋友使用此功能(包括附近的或不附近的),且每個訂閱者在內部 hash table 與 linked list 中需要約 20 bytes 的指標來追蹤,那麼容納所有 channel 將需要約 200 GB(1 億 _ 20 bytes * 100 朋友 / 10^9 = 200 GB)。對於具備 100 GB 記憶體的現代伺服器,我們大約需要 2 台 Redis pub/sub 伺服器來容納所有 channel。
CPU 用量
如先前計算,pub/sub 伺服器每秒會推送約 1,400 萬筆更新給訂閱者。雖然在沒有實際 benchmark 的情況下,很難準確估計現代 Redis 伺服器每秒能推送多少訊息,但可以肯定的是單台 Redis 伺服器無法處理這個負載。我們選擇較保守的數字,假設一台配備 gigabit 網路的現代伺服器每秒能處理約 100,000 次訂閱者推送。考量我們的位置更新訊息很小,這個數字應該偏保守。使用此保守估計,我們需要把負載分散到 1,400 萬 / 100,000 = 140 台 Redis 伺服器上。再次強調,這個數字可能太保守,實際所需的伺服器數可能少很多。
從計算我們得出結論:
- Redis pub/sub 伺服器的瓶頸是 CPU 用量,而非記憶體用量。
- 為支援我們的規模,我們需要分散式的 Redis pub/sub 叢集。
Distributed Redis pub/sub server cluster#
我們要如何把 channel 分散到數百台 Redis 伺服器上呢?好消息是 channel 之間互相獨立。這使得依發佈者使用者 ID 進行分片,把 channel 分散到多台 pub/sub 伺服器上相對容易。但實際上,當 pub/sub 伺服器數達數百台時,我們應該更詳細討論作法,因為伺服器無可避免會時常當機,這樣在運維上才比較可管理。
這裡我們在設計中引入服務發現(service discovery)元件。可用的服務發現套件很多,最熱門的包括 etcd [4] 與 Zookeeper [5]。我們對服務發現元件的需求非常基本,僅需以下兩項功能:
能夠在服務發現元件中保存伺服器清單,並提供簡單的 UI 或 API 來更新它。從根本上來說,服務發現就是一個小型的 key-value 儲存,用來保存設定資料。以圖 9 為例,hash ring 的 key 與 value 看起來可能像這樣:
- Key:/config/pub_sub_ring
- Value:[ “p_1”, “p_2”, “p_3”, “p_4”]
能夠讓客戶端(在這個例子中是 WebSocket 伺服器)訂閱「Value」(Redis pub/sub 伺服器)的任何更新。
在第 1 點提到的「Key」之下,我們在服務發現元件中儲存所有活躍 Redis pub/sub 伺服器的 hash ring(請參考《System Design Interview》第一冊的一致性雜湊章節,或 [6] 來了解 hash ring 細節)。Redis pub/sub 伺服器的發佈者與訂閱者使用此 hash ring 來決定每個 channel 應該與哪一台 pub/sub 伺服器溝通。例如圖 9 中,channel 2 位於 Redis pub/sub server 1。
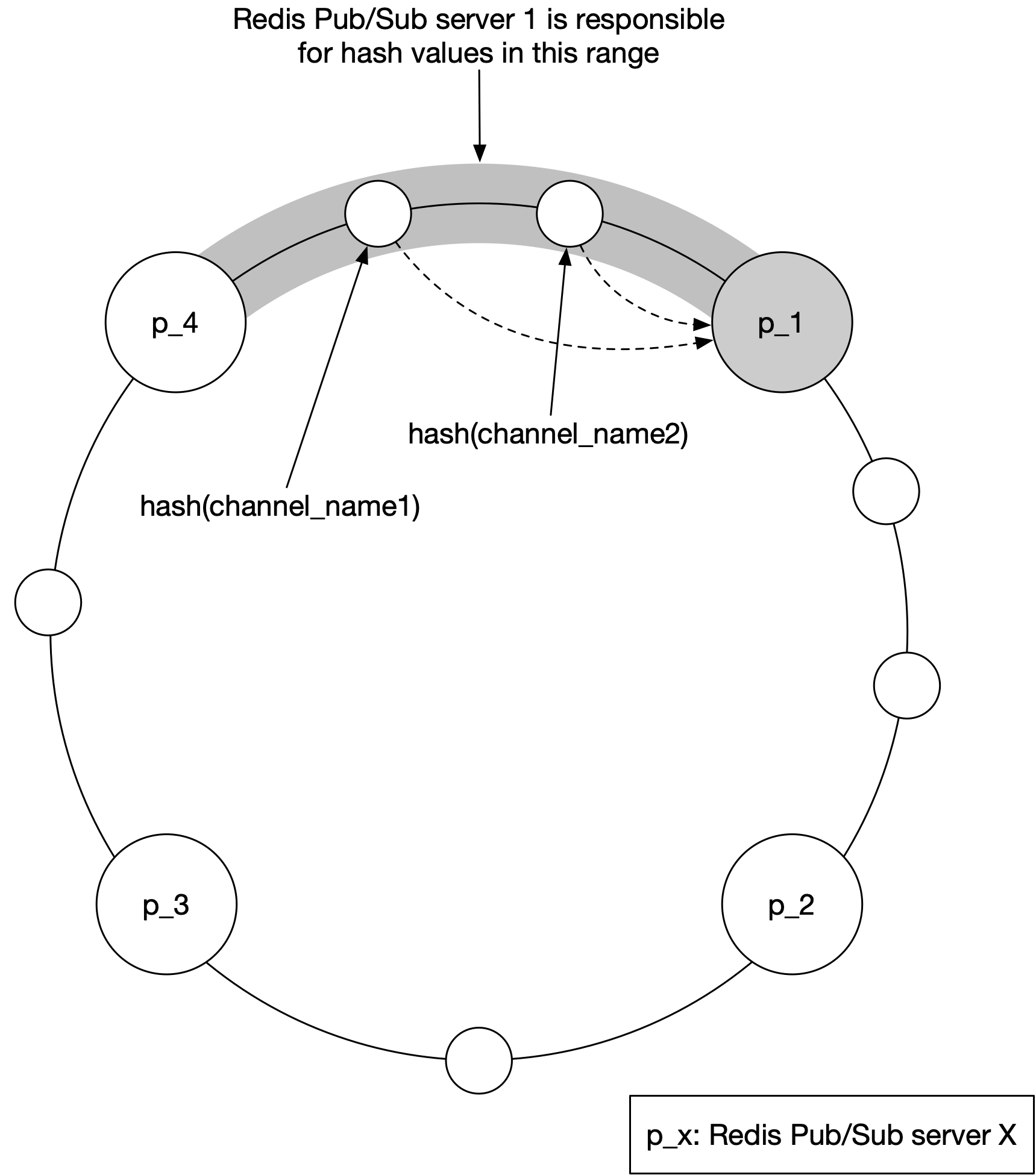
圖 10 展示當 WebSocket 伺服器把位置更新發佈到使用者 channel 時會發生什麼事。
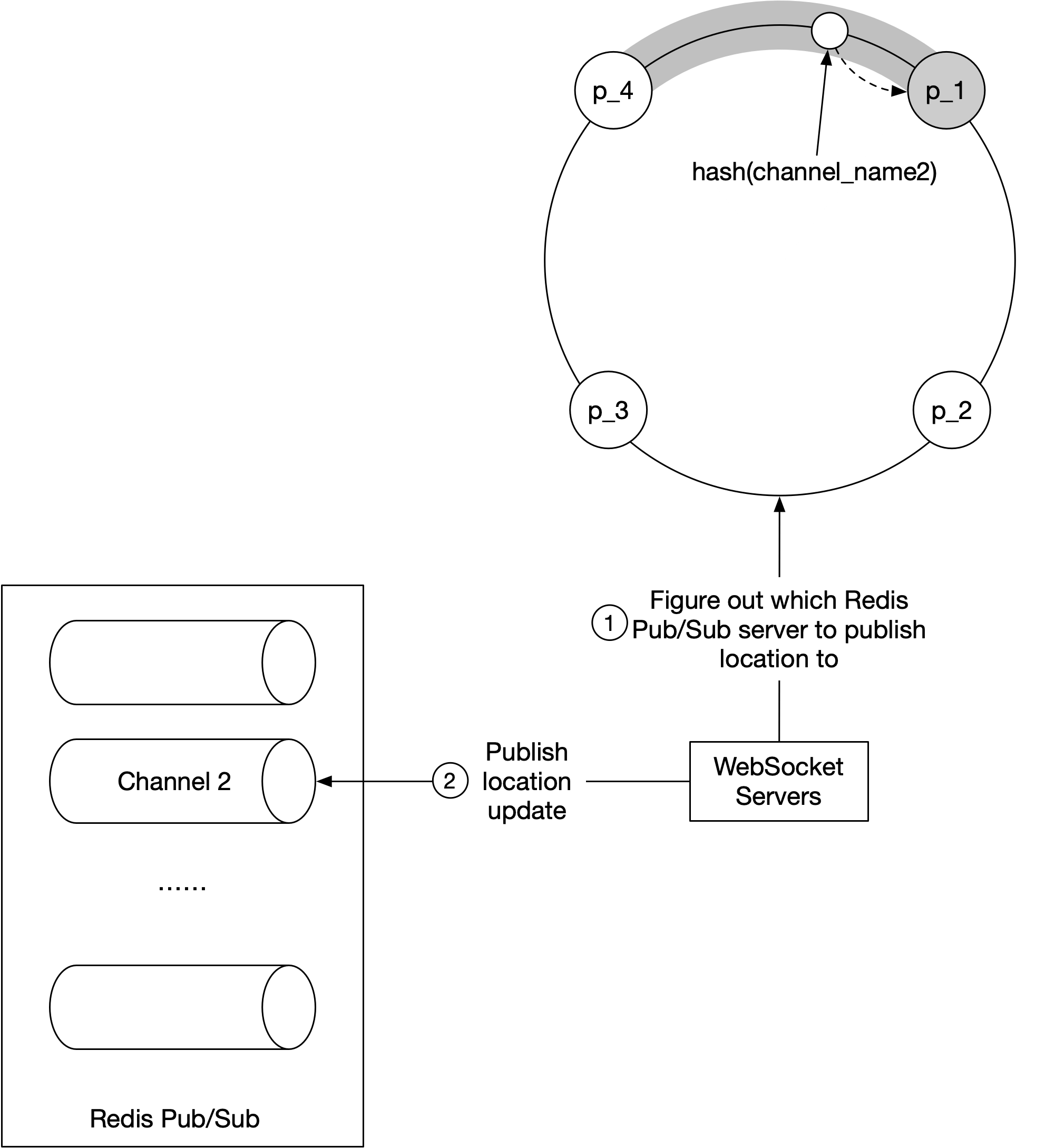
- WebSocket 伺服器查詢 hash ring 來決定要寫入的 Redis pub/sub 伺服器。真正的來源是儲存在服務發現中,但為了效率,每台 WebSocket 伺服器上都可以快取一份 hash ring。WebSocket 伺服器會訂閱 hash ring 的任何更新,以保持本地記憶體中的副本是最新的。
- WebSocket 伺服器把位置更新發佈到該 Redis pub/sub 伺服器上的使用者 channel。
訂閱 channel 取得位置更新也使用相同機制。
Scaling considerations for Redis pub/sub servers#
我們應該如何擴展 Redis pub/sub 伺服器叢集?是否應根據流量模式每天進行擴縮?對無狀態伺服器來說這是非常普遍的做法,因為風險低且能節省成本。為了回答這些問題,讓我們檢視一下 Redis pub/sub 伺服器叢集的一些特性:
- 在 pub/sub channel 上送出的訊息不會被持久化於記憶體或磁碟上。它們會被送給該 channel 的所有訂閱者後立即移除。如果沒有訂閱者,訊息會直接被丟棄。從這個意義上來說,通過 pub/sub channel 的資料是無狀態的。
- 但是 pub/sub 伺服器中確實儲存了 channel 的狀態。具體來說,每個 channel 的訂閱者清單是 pub/sub 伺服器追蹤的關鍵狀態。如果某個 channel 被搬移(例如該 channel 所在的 pub/sub 伺服器被替換、或在 hash ring 上新增/移除伺服器時),那麼該被搬移 channel 的每個訂閱者都必須得知此事,才能在舊伺服器上取消訂閱該 channel 並在新伺服器上重新訂閱替代 channel。從這個意義上來說,pub/sub 伺服器是有狀態的,必須協調所有訂閱者才能將服務中斷降到最低。
基於以上原因,我們應該把 Redis pub/sub 叢集視為類似具狀態的叢集,就像處理儲存叢集一樣。對於具狀態的叢集,擴縮會帶來一些運維開銷與風險,因此應該謹慎規畫。叢集通常會適度過度配置(over-provision),以確保能在白天的尖峰流量下保有充裕餘裕,避免不必要的叢集調整。
當不可避免地要擴縮時,請留意以下潛在問題:
- 當我們調整叢集大小時,許多 channel 會被搬移到 hash ring 上的不同伺服器。當服務發現元件通知所有 WebSocket 伺服器 hash ring 更新時,會出現大量的重新訂閱請求。
- 在這些大量重新訂閱事件期間,客戶端可能會錯過一些位置更新。雖然偶爾錯過對我們的設計來說是可接受的,但仍應盡量降低發生機率。
- 由於潛在的中斷,調整大小應該選在白天用量最低時進行。
實際上要怎麼調整大小呢?其實很簡單,依下列步驟進行:
- 決定新的 ring 大小,如果是擴大則準備足夠的新伺服器。
- 用新內容更新 hash ring 的 key。
- 監控 dashboard。WebSocket 叢集的 CPU 使用率應該會出現一些尖峰。
以圖 9 上方的 hash ring 為例,如果我們新增 2 個新節點(例如 p_5 與 p_6),hash ring 會如以下方式更新:
- 舊:[ “p_1”, “p_2”, “p_3”, “p_4”]
- 新:[ “p_1”, “p_2”, “p_3”, “p_4”, “p_5”, “p_6”]
Operational considerations for Redis pub/sub servers#
替換既有 Redis pub/sub 伺服器的運維風險低很多。它不會造成大量 channel 被搬移,只有被替換伺服器上的 channel 需要處理。這是好事,因為伺服器無可避免會時常當機需要被替換。
當 pub/sub 伺服器當機時,監控軟體應該要警告 on-call 人員。監控軟體如何監控 pub/sub 伺服器健康狀態的細節超出本章範圍,這裡不討論。On-call 人員會更新服務發現中的 hash ring key,把死掉的節點替換為新的備援節點。WebSocket 伺服器會收到此更新通知,每台則會通知它的連線處理器到新的 pub/sub 伺服器上重新訂閱 channel。每個 WebSocket 處理器會保留一份它已訂閱的所有 channel 清單,並在收到伺服器通知後,比對每個 channel 與 hash ring,判斷該 channel 是否需要在新伺服器上重新訂閱。
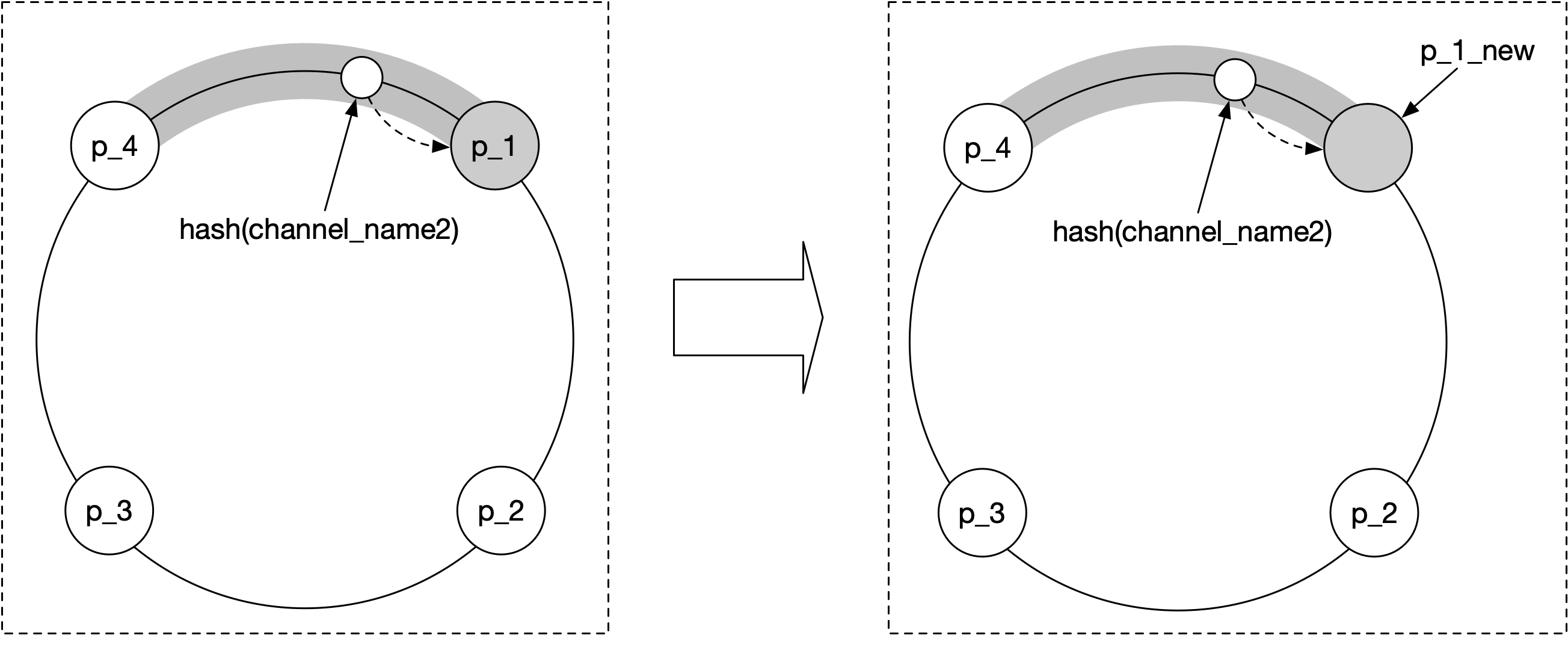
以圖 9 的 hash ring 為例,如果 p_1 當機,我們用 p1_new 替換它,hash ring 會如以下方式更新:
- 舊:[ “p_1”, “p_2”, “p_3”, “p_4”]
- 新:[ “p_1_new”, “p_2”, “p_3”, “p_4”]
Adding/removing friends#
當使用者新增或移除朋友時,客戶端應該做什麼?當新朋友被加入時,客戶端在伺服器上的 WebSocket 連線處理器需要被通知,以便訂閱新朋友的 pub/sub channel。
由於「附近的朋友」功能位於更大型應用的生態系內,我們可以假設「附近的朋友」功能可以在新增朋友時於行動客戶端註冊一個 callback。該 callback 被呼叫時,會送一則訊息給 WebSocket 伺服器以訂閱新朋友的 pub/sub channel。WebSocket 伺服器也會回傳一則包含新朋友最新位置與時間戳記的訊息(如果他們是活躍的)。
同樣地,客戶端可以在應用程式中註冊一個 callback,於朋友被移除時觸發。該 callback 會送一則訊息給 WebSocket 伺服器,以取消訂閱該朋友的 pub/sub channel。
這個訂閱/取消訂閱 callback 也可以用在朋友選擇加入或退出位置更新的時候。
Users with many friends#
有必要討論一下擁有很多朋友的使用者是否會在我們的設計中造成效能熱點。我們在這裡假設朋友數有硬性上限(例如 Facebook 的上限是 5,000 位朋友)。好友關係是雙向的。我們不是在討論名人可能擁有數百萬粉絲那種「追蹤者模型」。
在擁有數千位朋友的情境下,pub/sub 訂閱者會分散到叢集中的多台 WebSocket 伺服器上。更新負載也會分散其中,不太可能造成熱點。
該使用者會在其 channel 所在的 pub/sub 伺服器上造成稍多的負載。由於 pub/sub 伺服器超過 100 台,這些「鯨魚級」使用者會分散在不同的 pub/sub 伺服器上,額外的負載不應該壓垮任何單一伺服器。
Nearby random person#
你可以把這節稱為加分題,因為它不在原始的功能需求中。如果面試官想擴充設計,要顯示選擇分享位置的隨機路人呢?
利用我們現有設計的一種方法,是依 geohash 增加一組 pub/sub channel 池(geohash 細節請見鄰近服務章節)。如圖 12 所示,一個區域被分成四個 geohash 網格,並為每個網格建立一個 channel。
![圖 12 Redis pub/sub channel(地圖來源:[7])](figure-12-redis-pub-sub-channels-AHZA4ALB.svg)
網格內的任何人都訂閱相同的 channel。以網格 9q8znd 為例,如圖 13 所示。

- 在這裡,當使用者 2 更新位置時,WebSocket 連線處理器會計算該使用者的 geohash ID,並把位置送到該 geohash 對應的 channel。
- 任何附近訂閱該 channel 的人(除了發送者)都會收到位置更新訊息。
要處理位於 geohash 網格邊界附近的使用者,每個客戶端可以同時訂閱使用者所在的 geohash 與其周圍的八個 geohash 網格。圖 14 展示一個包含全部九個 geohash 網格的範例。
![圖 14 九個 geohash 網格(地圖來源:[7])](figure-14-nine-geohash-grids-IGQKWUYU.png)
Alternative to Redis pub/sub#
是否有什麼好的替代方案來取代 Redis pub/sub 作為路由層?答案是非常肯定的:有。Erlang [8] 是這個特定問題的絕佳方案。我們認為 Erlang 是比上述提出的 Redis pub/sub 更好的方案。
然而 Erlang 相當小眾,要找到優秀的 Erlang 工程師很困難。但如果你的團隊有 Erlang 專長,這會是個很好的選擇。
那麼為什麼是 Erlang?Erlang 是一種為高度分散與並行應用所打造的通用程式語言與執行環境。當我們在這裡說 Erlang 時,我們特別指的是 Erlang 生態系本身。這包括語言部分(Erlang 或 Elixir [9])以及執行環境與函式庫(稱為 BEAM [10] 的 Erlang 虛擬機,以及稱為 OTP [11] 的 Erlang 執行期函式庫)。
Erlang 的強大之處在於其輕量級的 process。Erlang process 是運行於 BEAM VM 上的實體。它的建立成本比 Linux process 便宜好幾個數量級。一個最基本的 Erlang process 大約佔用 300 bytes,一台現代伺服器上可以執行數百萬個。如果 Erlang process 沒有事情要做,它就在那裡完全不消耗任何 CPU 週期。換句話說,把我們設計中的 1,000 萬個活躍使用者各自塑模為一個 Erlang process,成本極低。
Erlang 也很容易在多台 Erlang 伺服器之間進行分散。運維開銷非常低,並且有絕佳的工具可以安全地除錯線上生產問題。部署工具也非常強大。
我們會如何在設計中使用 Erlang?我們會用 Erlang 實作 WebSocket 服務,並用一個分散式的 Erlang 應用程式取代整個 Redis pub/sub 叢集。在這個應用程式中,每位使用者都被塑模為一個 Erlang process。當使用者位置被客戶端更新時,使用者的 process 會從 WebSocket 伺服器接收更新。使用者的 process 也會訂閱其朋友的 Erlang process 的更新。訂閱機制是 Erlang/OTP 原生支援的,建立起來很容易。這會形成一張連線網狀結構,能高效地把位置更新從一位使用者送到許多位朋友。
Step 4 - Wrap Up#
在本章中,我們提出了一個支援附近朋友功能的設計。概念上,我們希望設計一個系統,能高效地把位置更新從一位使用者傳遞到他們的朋友。
部分核心元件包括:
- WebSocket:客戶端與伺服器之間的即時通訊。
- Redis:位置資料的快速讀寫。
- Redis pub/sub:路由層,把位置更新從一位使用者導向所有線上朋友。
我們先在較低規模下提出高階設計,再討論隨著規模增加而出現的挑戰。我們探討了如何擴展以下元件:
- Restful API 伺服器
- WebSocket 伺服器
- 資料層
- Redis pub/sub 伺服器
- Redis pub/sub 的替代方案
最後,我們討論了使用者擁有許多朋友時可能的瓶頸,也提出了「附近的隨機路人」功能的設計。
恭喜你看到這裡!現在請拍拍自己的肩膀。做得好!