在本章中,我們設計一個鄰近服務(proximity service)。鄰近服務用於探索附近的地點,例如餐廳、飯店、戲院、博物館等,是支援諸如 Yelp 上「找尋附近最佳餐廳」或 Google Maps 上「找尋最近的 k 個加油站」這類功能的核心組件。圖 1 展示了在 Yelp 上搜尋附近餐廳的使用者介面 [1]。請注意本章使用的地圖圖磚(map tiles)來自 Stamen Design [2],資料則來自 OpenStreetMap [3]。
![圖 1 在 Yelp 上的附近搜尋(來源:[1])](figure-1-neary-search-on-yelp-PIX55ZBV.png)
Step 1 - Understand the Problem and Establish Design Scope#
Yelp 支援許多功能,要在面試中設計全部是不可行的,因此透過提問來縮小範圍很重要。面試官與應徵者之間的互動可能像這樣:
應徵者:使用者可以指定搜尋半徑嗎?若指定半徑內沒有足夠的商家,系統會擴大搜尋嗎?
面試官:很棒的問題。我們先假設只關心指定半徑內的商家。如果時間允許,再討論當半徑內商家不足時要如何擴大搜尋。
應徵者:允許的最大半徑是多少?我可以假設是 20 km(12.5 mile)嗎?
面試官:這是一個合理的假設。
應徵者:使用者可以在 UI 上更改搜尋半徑嗎?
面試官:可以,我們提供以下選項:0.5km(0.31 mile)、1km(0.62 mile)、2km(1.24 mile)、5km(3.1 mile)以及 20km(12.42 mile)。
應徵者:商家資訊如何被新增、刪除或更新?這些操作需要即時反映嗎?
面試官:店家可以新增、刪除或更新商家。假設我們有一個事先的商業協議:新增/更新的商家會在隔天生效。
應徵者:使用者可能在使用 App/網站時移動,所以搜尋結果在一段時間後可能略有不同。我們需要刷新頁面以保持結果最新嗎?
面試官:假設使用者的移動速度緩慢,我們不需要持續刷新頁面。
Functional requirements#
基於這段對話,我們聚焦於 3 個關鍵功能:
- 根據使用者的位置(latitude 與 longitude 配對)與半徑回傳所有商家。
- 店家可以新增、刪除或更新商家,但這些資訊不需即時反映。
- 顧客可以檢視商家的詳細資訊。
Non-functional requirements#
從業務需求中,我們可以推導出一系列非功能性需求。你也應該與面試官確認這些需求。
- 低延遲。使用者應該能快速看到附近的商家。
- 資料隱私。位置資訊是敏感資料。當我們設計位置服務(location-based service,LBS)時,應該始終把使用者隱私納入考量。我們需要遵守資料隱私法律,例如 GDPR(General Data Protection Regulation)[4] 與 CCPA(California Consumer Privacy Act)[5] 等。
- 高可用性與擴展性需求。我們應該確保系統能處理人口稠密地區尖峰時段的流量激增。
Back-of-the-envelope estimation#
讓我們做一些粗略的估算,以了解我們的解決方案需要面對的潛在規模與挑戰。假設我們有 1 億日活躍使用者(DAU)以及 2 億家商家。
Step 2 - Propose High-Level Design and Get Buy-In#
在本節中,我們會討論以下內容:
- API 設計
- 高階設計
- 找出附近商家的演算法
- 資料模型
API Design#
我們以 RESTful API 慣例設計簡化版的 API。
GET /v1/search/nearby
此端點根據特定搜尋條件回傳商家。在實際應用中,搜尋結果通常會分頁。分頁(pagination)[6] 不是本章的重點,但在面試中值得一提。
請求參數:
| Field | Description | Type |
|---|---|---|
| latitude | 指定位置的 latitude | decimal |
| longitude | 指定位置的 longitude | decimal |
| radius | 選擇性。預設為 5000 公尺(約 3 mile) | int |
表 1 請求參數
回應主體
{
"total": 10,
"businesses":[{business object}]
}Business 物件包含渲染搜尋結果頁所需的所有內容,但要渲染商家詳細頁可能還需要額外屬性,例如圖片、評論、星等等。因此,當使用者點擊商家詳細頁時,通常會需要呼叫一個新的端點來取得商家的詳細資訊。
商家相關的 API
與 business 物件相關的 API 如下表所示。
| API | Detail |
|---|---|
| GET /v1/businesses/{:id} | 回傳一家商家的詳細資訊 |
| POST /v1/businesses | 新增一家商家 |
| PUT /v1/businesses/{:id} | 更新一家商家的詳細資料 |
| DELETE /v1/businesses/{:id} | 刪除一家商家 |
表 2 商家相關的 API
如果你對真實世界中地點/商家搜尋的 API 有興趣,兩個範例是 Google Places API [7] 與 Yelp Reservation API [8]。
Data model#
在本節中,我們討論讀寫比與 schema 設計。資料庫的擴展性會在 deep dive 中討論。
Read/write ratio#
讀取量很高,因為以下兩個功能非常常被使用:
- 搜尋附近的商家。
- 檢視商家的詳細資訊。
另一方面,寫入量較低,因為新增、移除、編輯商家資訊都是不頻繁的操作。
對於讀取繁重的系統,關聯式資料庫(例如 MySQL)會是合適的選擇。讓我們仔細看看 schema 設計。
Data schema#
主要的資料庫表格是 business 表格與 geospatial(geo)索引表格。
Business 表格
Business 表格包含商家的詳細資訊,如表 3 所示,主鍵為 business_id。

Geo 索引表格
Geo 索引表格用於有效率地處理空間操作。由於這個表格需要一些 geohash 知識,我們會在 deep dive 的「Scale the database」章節中討論。
High-level design#
高階設計圖如圖 2 所示。系統由兩部分組成:location-based service(LBS)以及商家相關服務(business-related service)。讓我們檢視系統的每個組件。

負載平衡器(Load balancer)
負載平衡器會自動將傳入流量分散到多個服務。一般而言,公司會提供單一 DNS 進入點,並依 URL 路徑將 API 呼叫內部路由到合適的服務。
Location-based service(LBS)
LBS 服務是系統的核心,負責在指定半徑與位置內找出附近的商家。LBS 具有以下特性:
- 它是讀取繁重的服務,沒有寫入請求。
- QPS 高,特別是在密集地區的尖峰時段。
- 此服務是無狀態的,因此容易水平擴展。
商家服務(Business service)
商家服務主要處理兩種請求:
- 店家建立、更新或刪除商家。這些請求主要是寫入操作,QPS 不高。
- 顧客檢視商家詳細資訊。在尖峰時段 QPS 很高。
資料庫叢集(Database cluster)
資料庫叢集可以使用主從(primary-secondary)設定。在這個設定中,主資料庫處理所有寫入操作,多個 replica 用於讀取操作。資料先寫入主資料庫,再複寫到 replica。由於複寫延遲,LBS 讀到的資料與寫入主資料庫的資料之間可能會有些差異。這種不一致通常不是問題,因為商家資訊不需要即時更新。
商家服務與 LBS 的擴展性
商家服務與 LBS 都是無狀態服務,因此能輕易自動新增更多伺服器以應付尖峰流量(例如用餐時段),並在離峰時段(例如睡眠時段)移除伺服器。如果系統運行於雲端,我們可以設定不同的 region 與 availability zone 以進一步提升可用性 [9]。我們會在 deep dive 中詳細討論。
Algorithms to fetch nearby businesses#
在實務中,公司可能會使用既有的地理空間資料庫,例如 Redis 中的 Geohash [10] 或具備 PostGIS 擴充的 Postgres [11]。
在面試中你不被期望了解這些地理空間資料庫的內部實作。比起單純丟出資料庫名稱,更好的方式是透過解釋地理空間索引如何運作來展現你的解題能力與技術知識。
下一步是探索擷取附近商家的不同選項。我們會列出幾個選項,逐一說明思考過程,並討論取捨。
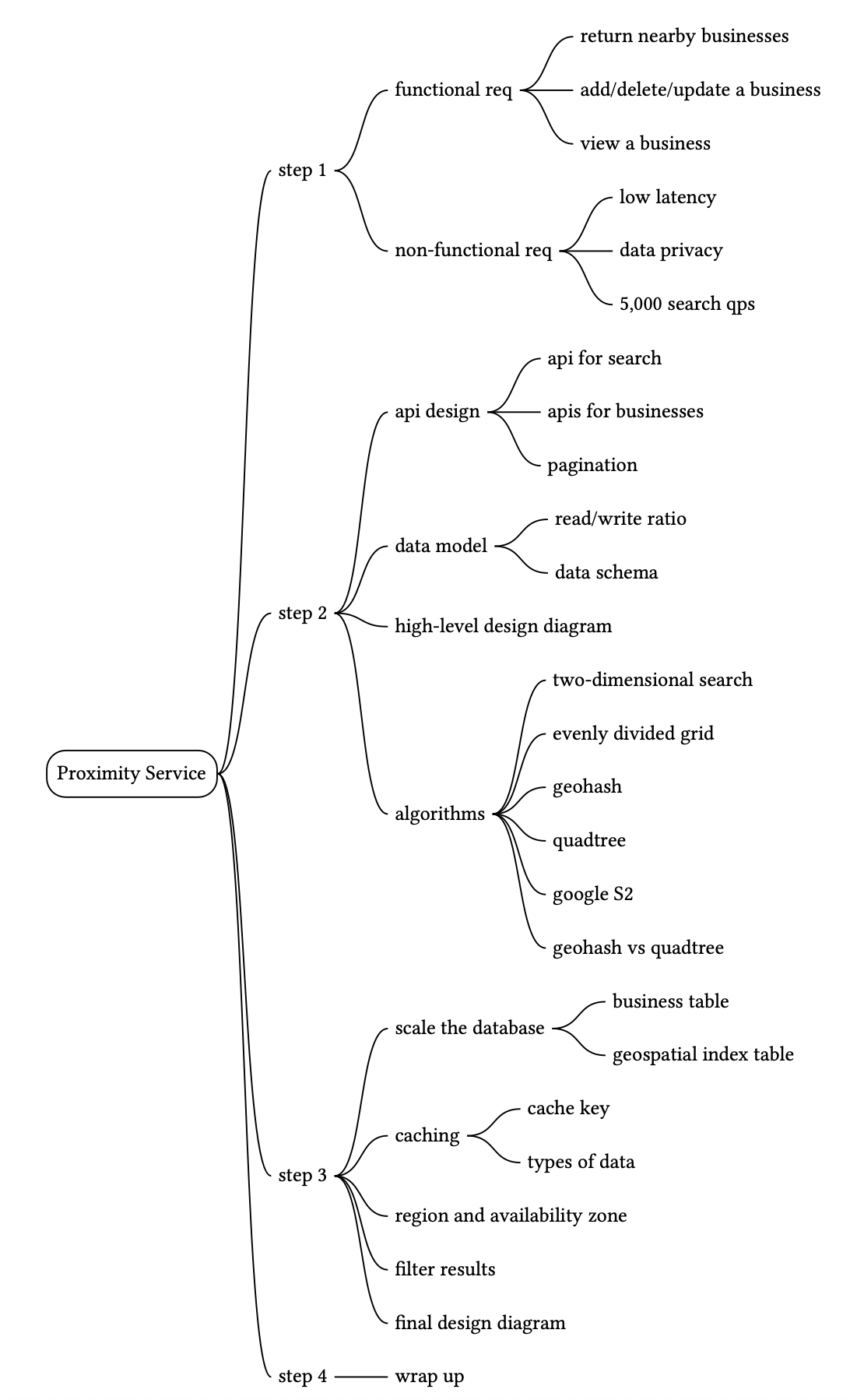
Option 1: Two-dimensional search#
最直觀但很粗糙的取得附近商家方式是用預定半徑畫一個圓,並找出圓內所有商家,如圖 3 所示。
這個過程可以轉換為以下偽 SQL 查詢:
SELECT business_id, latitude, longitude,
FROM business
WHERE (latitude BETWEEN {:my_lat} - radius AND {:my_lat} + radius) AND
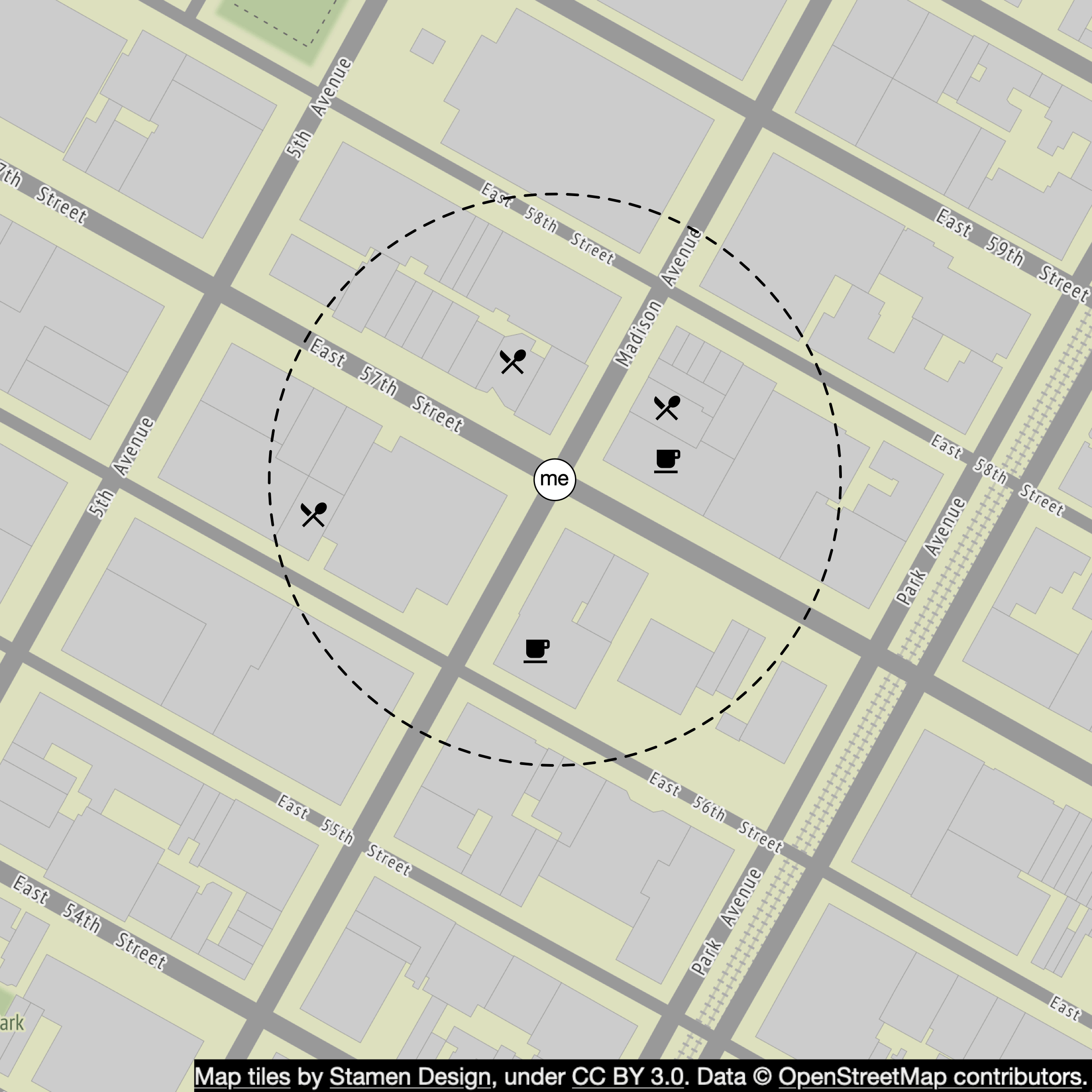
(longitude BETWEEN {:my_long} - radius AND {:my_long} + radius)這個查詢效率不彰,因為我們需要掃描整張表格。如果在 longitude 與 latitude 欄位上建索引呢?這會改善效率嗎?答案是改善有限。問題在於我們有二維資料,每個維度回傳的資料集仍可能很大。例如,如圖 4 所示,我們可以靠 longitude 與 latitude 欄位的索引快速擷取 dataset 1 與 dataset 2,但要取得半徑內的商家,我們需要對這兩個 dataset 進行 intersect 操作。這並不有效率,因為每個 dataset 包含大量資料。
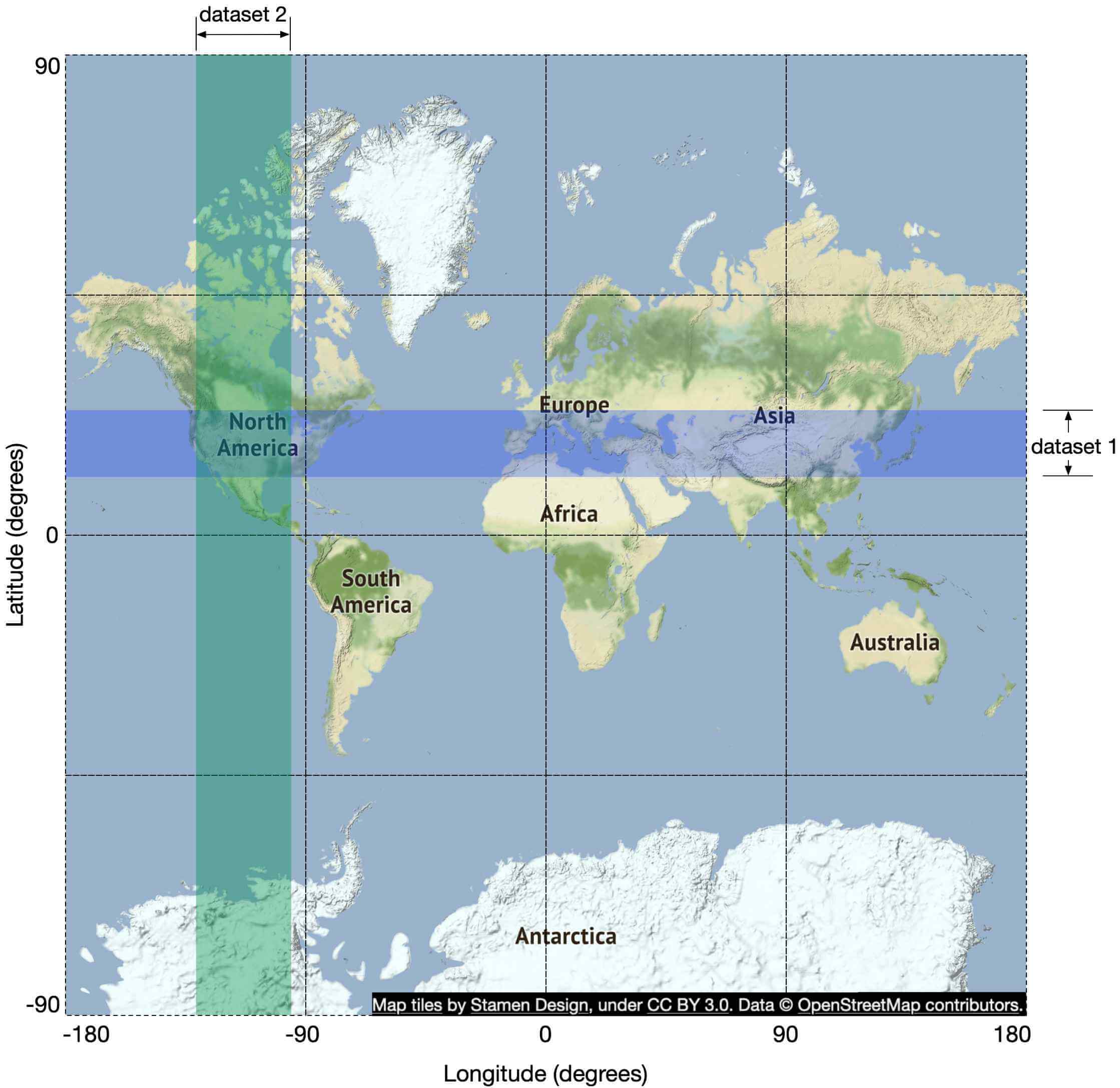
前一種方法的問題在於資料庫索引只能在一個維度上加速搜尋。因此自然的後續問題是:我們能將二維資料對應到一維嗎?答案是可以。
在深入解答之前,先看看不同類型的索引方法。從廣義來說,地理空間索引方法有兩大類,如圖 5 所示。標示出來的是我們會詳細討論的演算法,因為它們在業界廣為使用。
- Hash:even grid、geohash、cartesian tiers [12] 等。
- Tree:quadtree、Google S2、RTree [13] 等。

雖然這些方法的底層實作不同,但高階概念是一致的:將地圖切分為較小的區域並建立索引以加速搜尋。其中,geohash、quadtree 與 Google S2 在實際應用中最廣泛被使用。讓我們逐一檢視。
在實際面試中,你通常不需要解釋索引選項的實作細節。但了解地理空間索引的需求、其高階運作方式以及限制是重要的。
Option 2: Evenly divided grid#
一個簡單的方法是把世界平均切成小格(圖 6)。這樣每一格可能有多家商家,地圖上的每家商家都屬於某一格。
![圖 6 世界地圖(來源:[14])](figure-6-global-map-NWAMEPOX.png)
這個方法在某種程度上行得通,但有一個主要問題:商家分佈不均。紐約市區可能有大量商家,而沙漠或海洋上的某些格子根本沒有商家。透過將世界切成均勻方格,我們會得到非常不均勻的資料分佈。理想上我們希望在密集區使用較細的格子,在稀疏區使用較大的格子。另一個潛在挑戰是要找到固定格子的相鄰格子。
Option 3: Geohash#
Geohash 比均勻切格的選項更好。它的運作方式是把二維的 longitude 與 latitude 資料縮減為一維的字母與數字字串。Geohash 演算法透過遞迴地將世界切分成越來越小的格子,每次新增一個 bit。讓我們從高階層次了解 geohash 如何運作。
首先,沿著本初子午線(prime meridian)與赤道把地球分為四個象限。
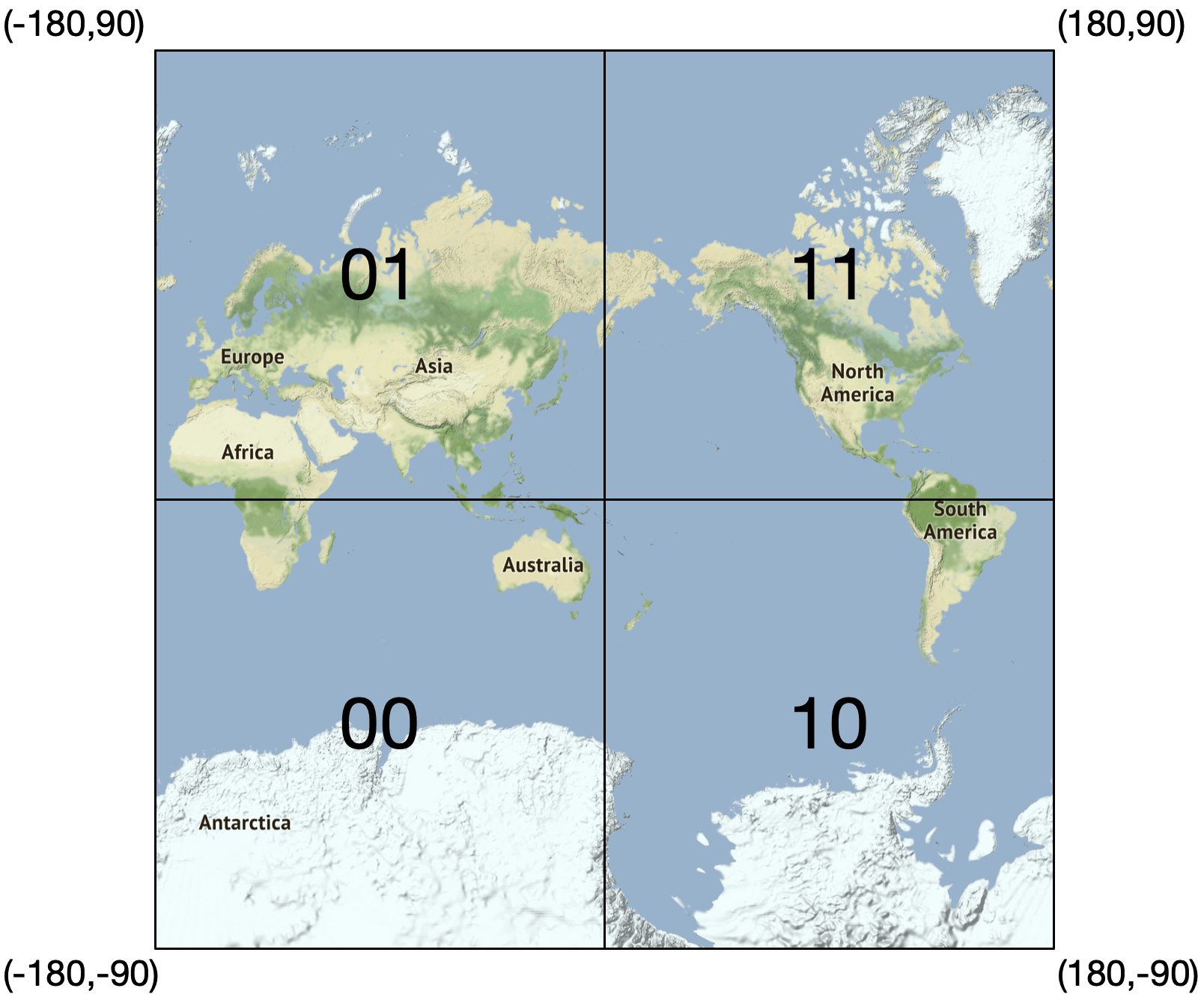
- Latitude 範圍 [-90, 0] 用 0 表示
- Latitude 範圍 [0, 90] 用 1 表示
- Longitude 範圍 [-180, 0] 用 0 表示
- Longitude 範圍 [0, 180] 用 1 表示
第二,將每一格再切成四個更小的格子。每一格可以由交替的 longitude bit 與 latitude bit 表示。
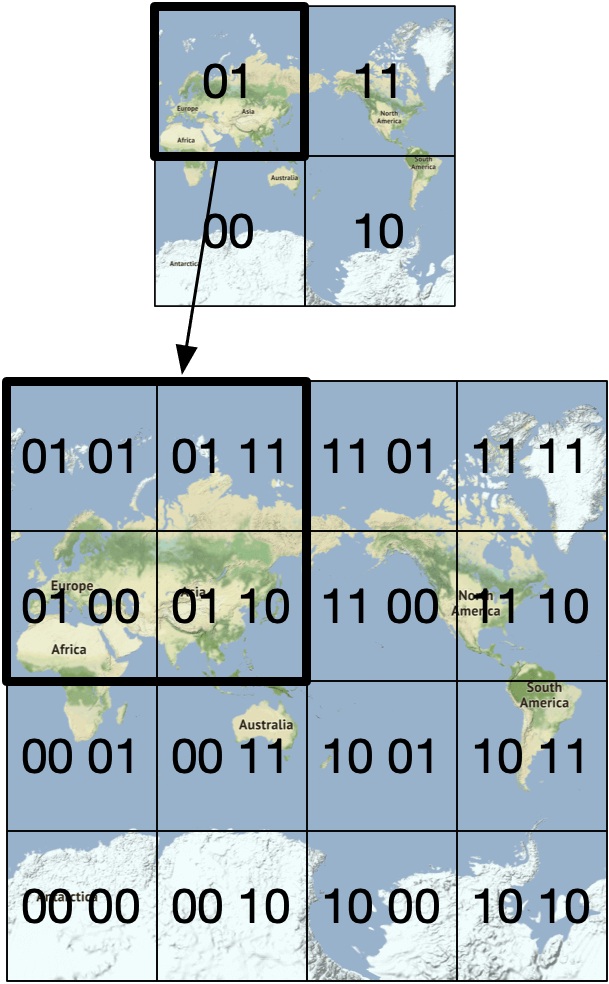
重複這個切分過程,直到格子大小符合所需精度。Geohash 通常使用 base32 表示法 [15]。讓我們看看兩個例子。
- Google 總部的 geohash(length = 6):
1001 10110 01001 10000 11011 11010 (base32 in binary) → 9q9hvu (base32)- Facebook 總部的 geohash(length = 6):
1001 10110 01001 10001 10000 10111 (base32 in binary) → 9q9jhr (base32)Geohash 有 12 個精度(也稱為 level),如表 4 所示。精度因子決定格子的大小。我們只關注長度介於 4 到 6 之間的 geohash。這是因為長度大於 6 時格子太小,而小於 4 時格子太大(見表 4)。
| Geohash 長度 | 格子寬 x 高 |
|---|---|
| 1 | 5,009.4km x 4,992.6km(地球大小) |
| 2 | 1,252.3km x 624.1km |
| 3 | 156.5km x 156km |
| 4 | 39.1km x 19.5km |
| 5 | 4.9km x 4.9km |
| 6 | 1.2km x 609.4m |
| 7 | 152.9m x 152.4m |
| 8 | 38.2m x 19m |
| 9 | 4.8m x 4.8m |
| 10 | 1.2m x 59.5cm |
| 11 | 14.9cm x 14.9cm |
| 12 | 3.7cm x 1.9cm |
表 4 Geohash 長度與格子大小對應(來源:[16])
我們如何選擇正確的精度?我們希望找到能涵蓋使用者指定半徑所形成的整個圓的最小 geohash 長度。半徑與 geohash 長度的對應關係如下表所示。
| 半徑(公里) | Geohash 長度 |
|---|---|
| 0.5 km(0.31 mile) | 6 |
| 1 km(0.62 mile) | 5 |
| 2 km(1.24 mile) | 5 |
| 5 km(3.1 mile) | 4 |
| 20 km(12.42 mile) | 4 |
表 5 半徑與 geohash 對應
這個方法大多數時候都很好用,但有一些 geohash 邊界處理上的邊界案例需要與面試官討論。
邊界問題
Geohash 保證兩個 geohash 之間共用前綴越長,它們就越接近。如圖 9 所示,所有的格子都共用前綴:9q8zn。
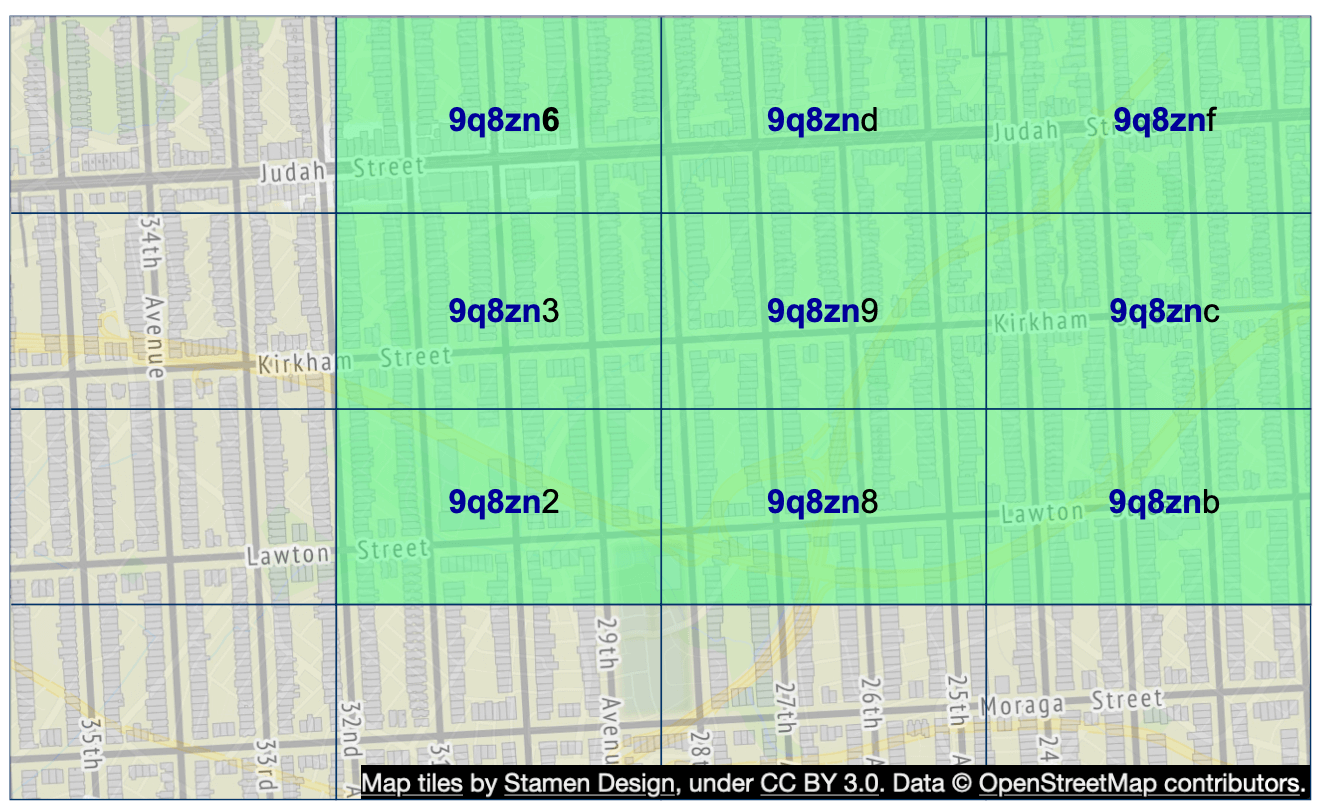
邊界問題 1
反向不成立:兩個位置可能非常接近卻完全沒有共用前綴。這是因為位於赤道或本初子午線兩側的兩個鄰近位置屬於世界的不同「半邊」。
例如在法國,La Roche-Chalais(geohash:u000)距離 Pomerol(geohash:ezzz)只有 30km,但它們的 geohash 完全沒有共用前綴 [17]。
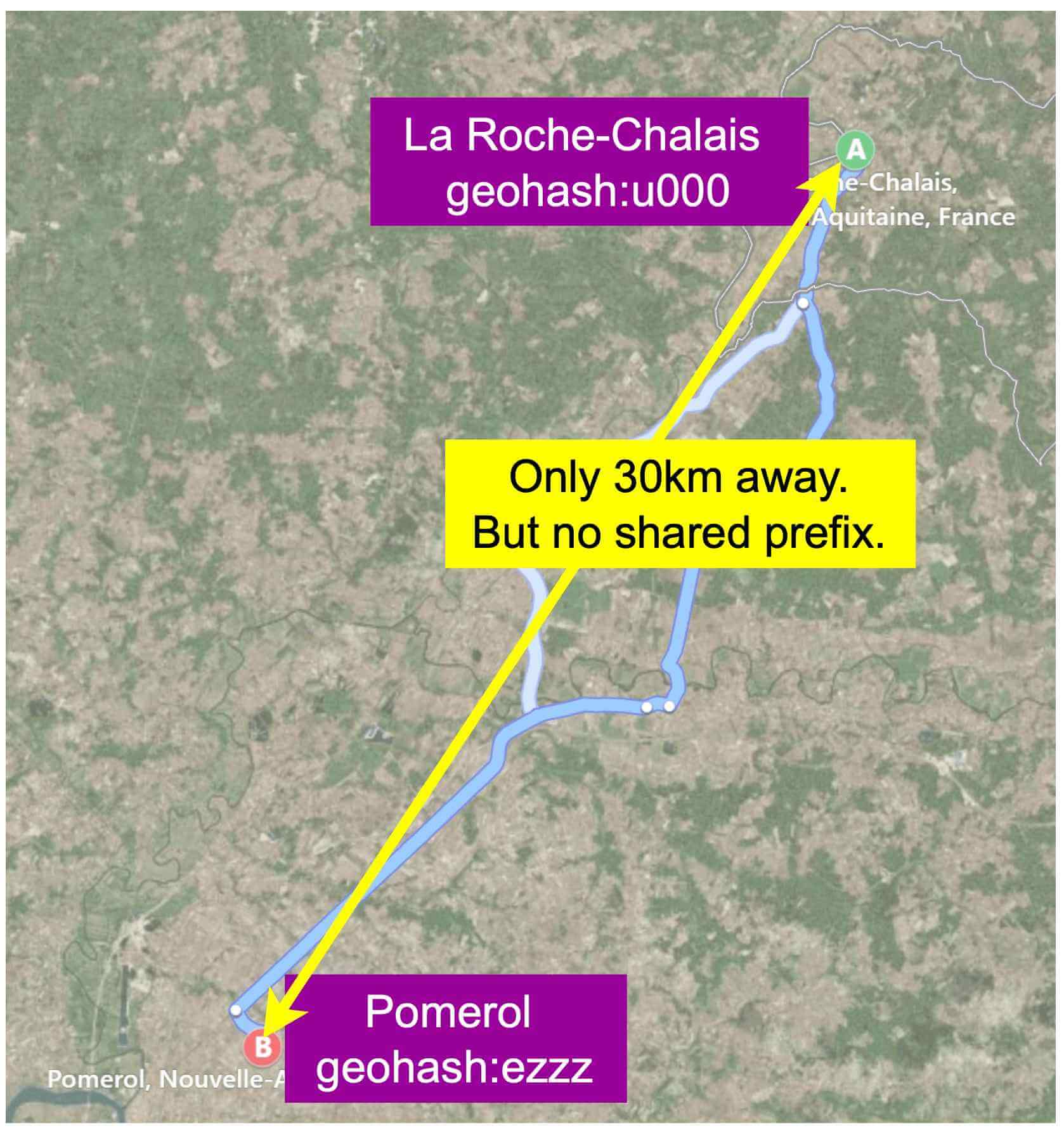
由於這個邊界問題,下面這個簡單的前綴 SQL 查詢無法擷取所有附近的商家。
SELECT * FROM geohash_index WHERE geohash LIKE `9q8zn%`邊界問題 2
另一個邊界問題是:兩個位置可能擁有很長的共用前綴,但卻屬於不同的 geohash,如圖 11 所示。
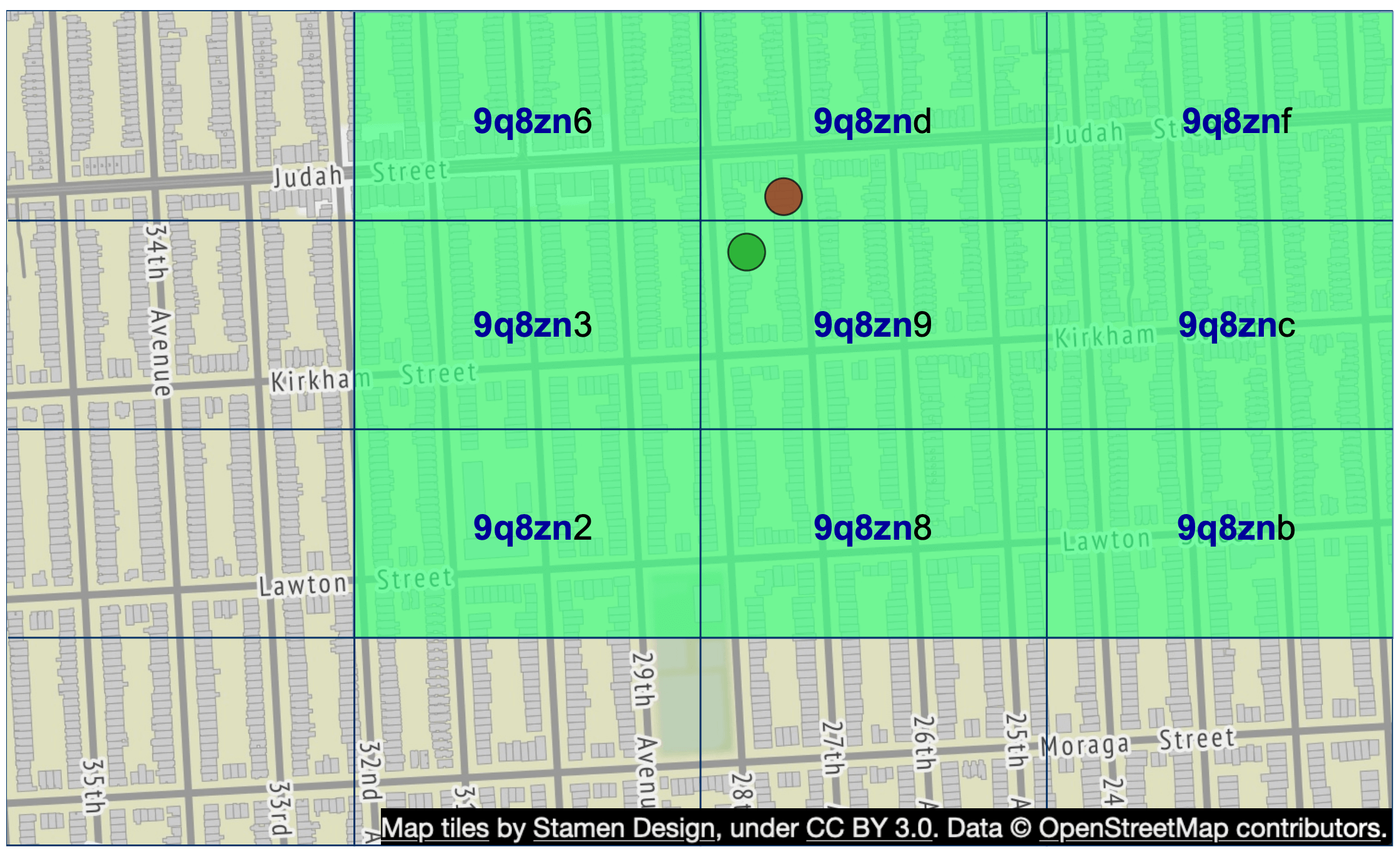
常見的解法是不只擷取目前格子內的商家,也擷取相鄰格子中的商家。相鄰格子的 geohash 可以在常數時間內計算出來,更多細節可以在這裡找到 [17]。
商家數量不夠
現在來處理加分題。如果目前格子與所有相鄰格子加總後,回傳的商家還是不夠該怎麼辦?
- 選項 1:只回傳半徑內的商家。這選項容易實作,但缺點明顯:它無法回傳足夠的結果以滿足使用者需求。
- 選項 2:擴大搜尋半徑。我們可以移除 geohash 的最後一個字元,並用新的 geohash 擷取附近商家。如果商家還不夠,繼續移除另一個字元。如此一來,格子大小會逐漸擴大,直到結果數超過所需。圖 12 顯示了擴大搜尋過程的概念圖。
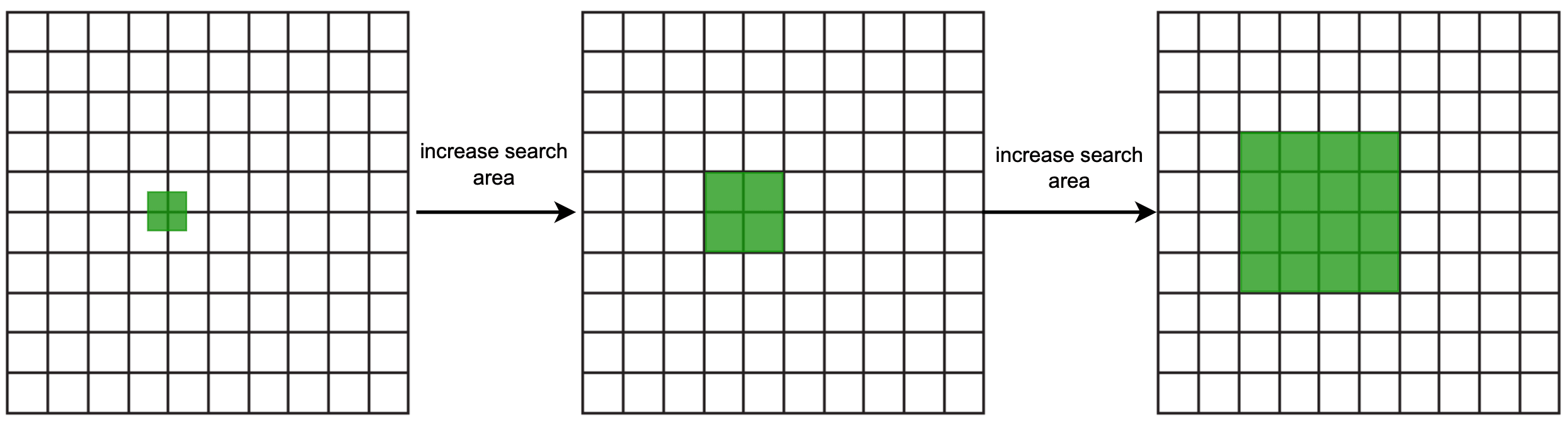
Option 4: Quadtree#
另一個熱門解法是 quadtree。Quadtree [18] 是一種資料結構,常用於將二維空間透過遞迴切分為四個象限(grid),直到格子內容符合某些條件為止。例如,條件可以是繼續切分直到格子內的商家數不超過 100。這個數字是任意的,實際數字可由業務需求決定。使用 quadtree 時,我們會在記憶體中建立樹狀結構來回應查詢。
Quadtree 是一個記憶體中的資料結構,而不是資料庫解決方案。它在每台 LBS 伺服器上運行,並在伺服器啟動時建立。
下圖視覺化了將世界切分為 quadtree 的概念過程。假設世界中有 200m(百萬)家商家。
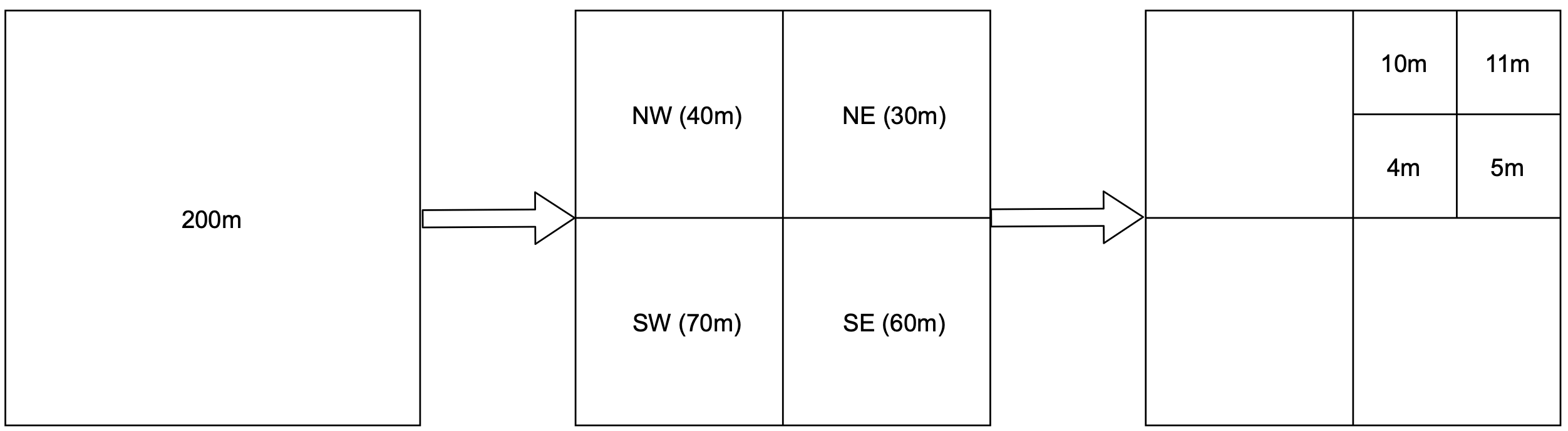
圖 14 詳細解釋 quadtree 的建構過程。根節點代表整個世界地圖。根節點被遞迴地切分為 4 個象限,直到沒有節點包含超過 100 家商家為止。

建構 quadtree 的偽程式碼如下:
public void buildQuadtree(TreeNode node) {
if (countNumberOfBusinessesInCurrentGrid(node) > 100) {
node.subdivide();
for (TreeNode child : node.getChildren()) {
buildQuadtree(child);
}
}
}要回答這個問題,我們需要知道儲存了什麼資料。
葉節點上的資料
| Name | Size |
|---|---|
| 用以識別格子的左上座標與右下座標 | 32 bytes(8 bytes * 4) |
| 格子內商家 ID 的清單 | 每個 ID 8 bytes * 100(單一格子允許的最大商家數) |
| 總計 | 832 bytes |
表 6 葉節點
內部節點上的資料
| Name | Size |
|---|---|
| 用以識別格子的左上座標與右下座標 | 32 bytes(8 bytes * 4) |
| 指向 4 個子節點的指標 | 32 bytes(8 bytes * 4) |
| 總計 | 64 bytes |
表 7 內部節點
雖然樹的建構過程取決於格子內的商家數,但這個數字不需要儲存在 quadtree 節點中,因為它可以從資料庫紀錄推斷出來。
知道每個節點的資料結構後,我們來看看記憶體使用量。
- 每格最多可儲存 100 家商家
- 葉節點數 = ~2 億 / 100 = ~200 萬
- 內部節點數 = 200 萬 * 1/3 = ~67 萬。如果你不知道為什麼內部節點數是葉節點數的三分之一,請參考參考資料 [19]。
- 總記憶體需求 = 200 萬 _ 832 bytes + 67 萬 _ 64 bytes = ~1.71 GB。即使加上一些建樹開銷,建樹的記憶體需求也相當小。
在實際面試中,我們不需要這麼詳細的計算。重點是 quadtree 索引不會占用太多記憶體,可以輕鬆裝進一台伺服器。這代表我們應該只用一台伺服器來儲存 quadtree 索引嗎?答案是否定的。視讀取量而定,單一 quadtree 伺服器可能沒有足夠的 CPU 或網路頻寬來服務所有讀取請求。若是這種情況,就需要將讀取負載分散到多台 quadtree 伺服器上。
建構整棵 quadtree 需要多久?
每個葉節點包含約 100 個商家 ID。建樹的時間複雜度為 (N/100) lg(N/100),其中 N 是商家總數。建構一棵包含 2 億家商家的 quadtree 可能需要幾分鐘。
如何用 quadtree 取得附近商家?
- 在記憶體中建立 quadtree。
- Quadtree 建立後,從根節點開始往下遍歷,直到找到包含搜尋起點的葉節點。如果該葉節點有 100 家商家,回傳該節點。否則,從相鄰節點補充商家,直到回傳足夠的商家為止。
Quadtree 的維運考量
如前所述,建構一棵包含 2 億商家的 quadtree 可能在伺服器啟動時需要幾分鐘。考慮這麼長的伺服器啟動時間所帶來的維運影響很重要。
在 quadtree 建構期間,伺服器無法服務流量。因此,我們應該將新版伺服器逐步部署到一小部分伺服器上。這可以避免一次將大批伺服器叢集下線而造成服務的「brownout」。也可以採用 Blue/green deployment [20],但讓整批新伺服器叢集同時從資料庫服務擷取 2 億商家,會對系統造成很大的壓力。雖然可行,但會讓設計變得複雜,你應該在面試中提到這一點。
另一個維運考量是:當商家隨時間被新增或移除時要如何更新 quadtree。最簡單的做法是逐步重建 quadtree,每次只重建一小部分伺服器,逐步遍及整個叢集。但這意味著某些伺服器在短時間內會回傳過時資料。然而,依據需求這通常是可接受的折衷。我們可以透過事先約定「新增/更新的商家在隔天才生效」的商業協議進一步緩解這個問題。這代表我們可以以每晚的工作來更新快取。這個方法的潛在問題是大量的 key 會在同一時間失效,對快取伺服器造成沉重負載。
也可以在商家被新增或移除時即時更新 quadtree。這當然會讓設計變複雜,特別是當 quadtree 資料結構可能被多執行緒存取時。這需要某種鎖定機制,會大幅讓 quadtree 的實作複雜化。
真實世界中的 quadtree 範例
Yext 提供了一張圖片(圖 15),展示了在丹佛(Denver)附近建立的 quadtree。我們希望密集區有更小、更細緻的格子,稀疏區則有較大的格子。
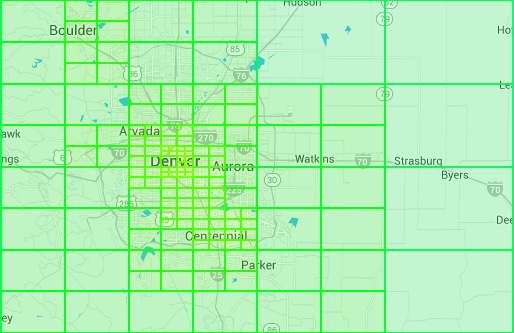
Option 5: Google S2#
Google S2 geometry library [22] 是這個領域另一個重量級玩家。與 quadtree 類似,它是一個記憶體中的解決方案。它基於 Hilbert curve(一種空間填充曲線)將球面對應到 1D 索引 [23]。Hilbert curve 有一個很重要的特性:在 Hilbert curve 上彼此接近的兩點,在 1D 空間中也接近(圖 16)。在 1D 空間上的搜尋比 2D 上的搜尋更有效率。有興趣的讀者可以使用 Hilbert curve 的線上工具 [24]。
![圖 16 Hilbert curve(來源:[24])](figure-16-hilbert-curve-A42ZBOV2.png)
S2 是一個複雜的函式庫,面試中你不被期望解釋其內部實作。但因為它在 Google、Tinder 等公司被廣泛使用,我們會簡要說明其優點。
S2 對 geofencing 非常合適,因為它能以不同層級涵蓋任意區域(圖 17)。根據維基百科:「Geofence 是真實世界地理區域的虛擬周界。Geo-fence 可以是動態產生的,例如以點位置為中心的半徑範圍,或可以是預先定義的一組邊界(例如校區或鄰里邊界)」[25]。
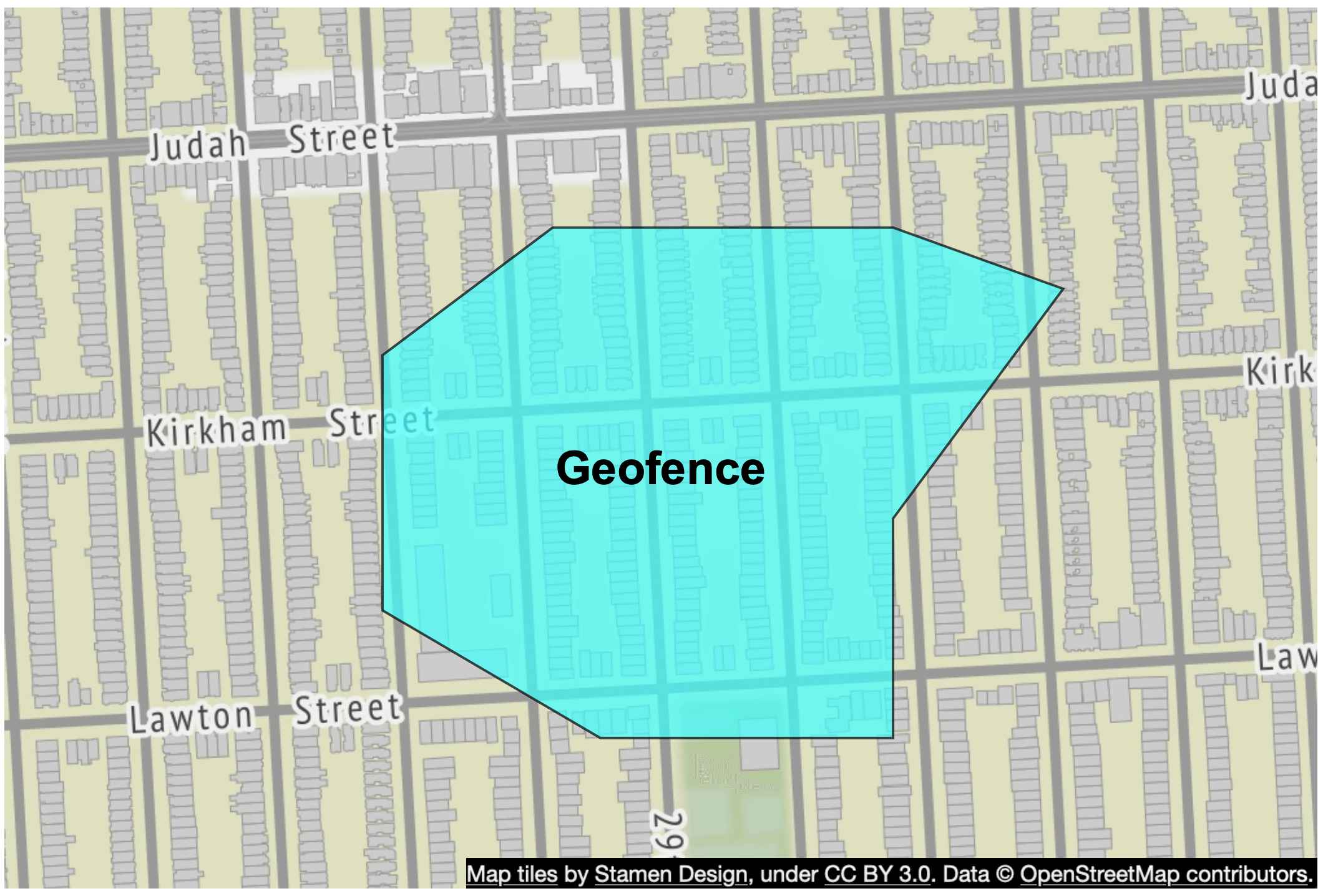
Geofencing 讓我們可以定義環繞感興趣區域的周界,並對離開該區域的使用者送出通知。這能提供比只回傳附近商家更豐富的功能。
S2 的另一個優勢是其 Region Cover 演算法 [26]。不像 geohash 有固定 level(精度),在 S2 中我們可以指定 min level、max level 與 max cells。S2 回傳的結果更細緻,因為 cell 大小有彈性。如果你想了解更多,可以參考 S2 工具 [26]。
Recommendation#
為了有效率地找出附近商家,我們討論了幾個選項:geohash、quadtree 與 S2。如表 8 所示,不同的公司或技術採用不同的選項。
| Geo Index | Companies |
|---|---|
| Geohash | Bing map [27]、Redis [10]、MongoDB [28]、Lyft [29] |
| Quadtree | Yext [21] |
| Geohash 與 Quadtree 同時使用 | Elasticsearch [30] |
| S2 | Google Maps、Tinder [31] |
表 8 不同類型的 geo 索引
在面試中,我們建議選擇 geohash 或 quadtree,因為 S2 在面試中較難清楚解釋。
Geohash vs quadtree#
在結束本節前,讓我們快速比較 geohash 與 quadtree。
Geohash
- 易於使用與實作。不需要建樹。
- 支援回傳指定半徑內的商家。
- 當 geohash 的精度(level)固定時,格子大小也固定。它無法依人口密度動態調整格子大小,需要更複雜的邏輯來支援這一點。
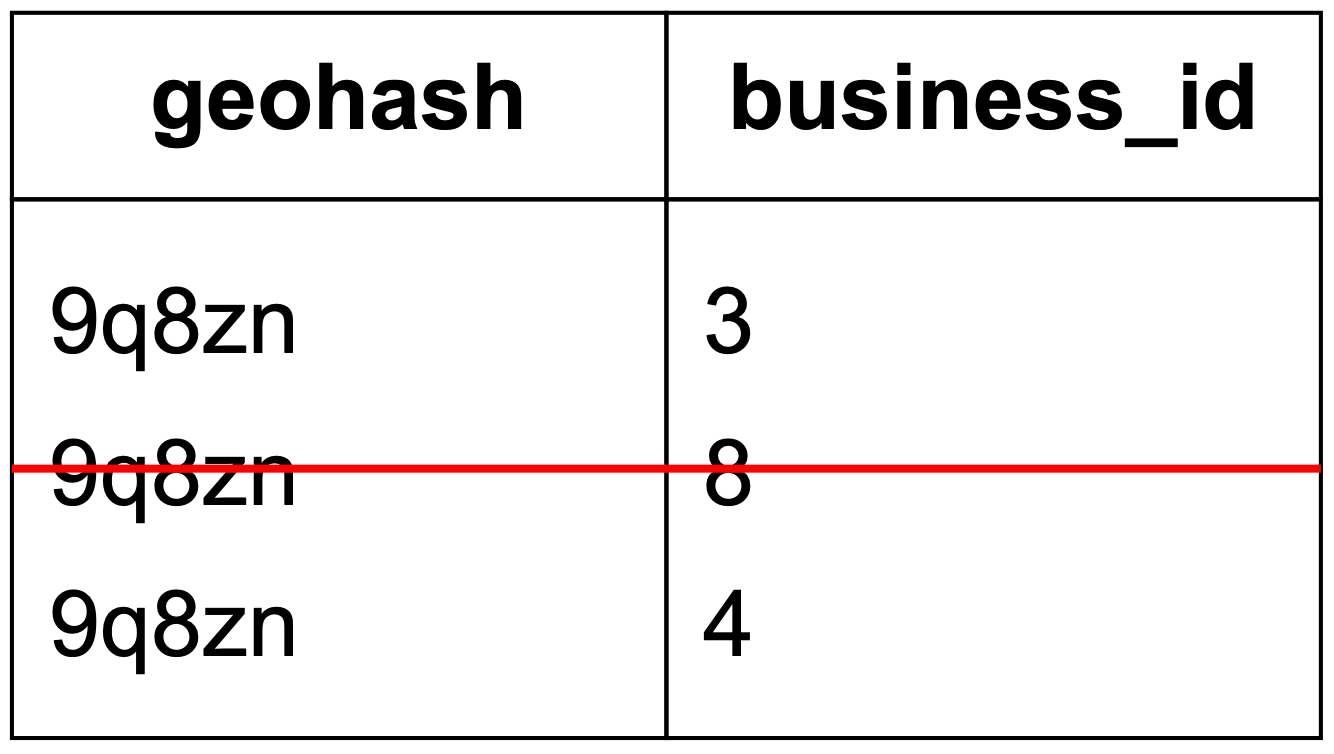
- 更新索引很容易。例如要從索引中移除一家商家,我們只需要從具有相同 geohash 與 business_id 的對應列中移除即可。具體範例見圖 18。
Quadtree
- 實作稍難,因為需要建樹。
- 支援擷取 k 個最近的商家。有時我們只想回傳 k 個最近的商家,而不在乎商家是否在指定半徑內。例如,當你旅行且車子快沒油時,你只想找最近的 k 個加油站。這些加油站可能不在你附近,但 App 需要回傳最近的 k 個結果。對於這類查詢,quadtree 是好的選擇,因為它的切分過程基於數量 k,可以自動調整查詢範圍直到回傳 k 個結果。
- 它能根據人口密度動態調整格子大小(見圖 15 的 Denver 範例)。
- 更新索引比 geohash 複雜。Quadtree 是樹結構,若要移除一家商家,我們需要從根節點遍歷到葉節點才能移除該商家。例如,要移除 ID = 2 的商家,我們必須一路從根節點遍歷到葉節點,如圖 19 所示。更新索引耗時 O(logn),但若資料結構由多執行緒程式存取,需要鎖定,實作會變複雜。此外,重新平衡樹也可能很複雜。當例如葉節點沒有空間容納新項目時就需要重新平衡。一個可能的解法是過度配置(over-allocate)範圍。

Step 3 - Design Deep Dive#
到這裡你應該對整個系統的樣貌有了不錯的了解。接下來讓我們深入幾個領域。
- 擴展資料庫
- 快取
- Region 與 availability zone
- 依時間或商家類型過濾結果
- 最終架構圖
Scale the database#
我們會討論如何擴展兩個最重要的表格:business 表格與 geospatial 索引表格。
Business table#
Business 表格的資料可能無法全部裝進一台伺服器,因此是 sharding 的好候選。最簡單的方法是依 business ID 進行 sharding。這個分片方案能確保負載在所有 shard 之間均勻分佈,且維運上易於維護。
Geospatial index table#
Geohash 與 quadtree 都被廣泛使用。由於 geohash 較簡單,我們以它為例。表格結構有兩種方式。
選項 1:對每個 geohash key,在單一列中儲存一個 business ID 的 JSON 陣列。這意味著一個 geohash 內所有的 business ID 都儲存於一列中。

選項 2:若同一個 geohash 中有多家商家,會有多列,每家商家一列。這意味著同一個 geohash 內不同的 business ID 儲存在不同列中。

以下是選項 2 的範例列。
| geohash | business_id |
|---|---|
| 32feac | 343 |
| 32feac | 347 |
| f3lcad | 112 |
| f3lcad | 113 |
表 11 geospatial 索引表格的範例列
建議:我們建議選項 2,原因如下:
對選項 1 而言,要更新一家商家,我們需要擷取 business_ids 陣列並掃描整個陣列以找到要更新的商家。當新增商家時,我們必須掃描整個陣列以確保沒有重複。我們也需要鎖定該列以避免並行更新。有許多邊界案例需要處理。
對選項 2 而言,如果使用 (geohash, business_id) 的複合主鍵這兩個欄位,新增與移除商家都非常簡單,不需要鎖定任何東西。
擴展 geospatial 索引
關於擴展 geospatial 索引常見的錯誤是直接跳到分片方案,而沒有先考慮資料表的實際大小。在我們的情況下,geospatial 索引表的完整資料集並不大(quadtree 索引只占用 1.71G 記憶體,geohash 索引的儲存需求類似)。
整個 geospatial 索引可以輕易裝進現代資料庫伺服器的工作集中。然而,視讀取量而定,單一資料庫伺服器可能沒有足夠的 CPU 或網路頻寬來處理所有讀取請求。若是這種情況,就需要將讀取負載分散到多台資料庫伺服器上。
對於關聯式資料庫,分散負載一般有兩種方式:新增 read replica,或對資料庫進行 sharding。
許多工程師喜歡在面試中談 sharding。然而,這對 geohash 表格可能不是好的選擇,因為 sharding 很複雜。例如,sharding 邏輯必須加入應用層。有時 sharding 是唯一選擇,但在這個情況下一切都能裝進資料庫伺服器的工作集中,沒有強烈的技術理由要把資料分到多台伺服器。
更好的做法是設置一系列 read replica 來協助分擔讀取負載。這個方法更易於開發與維護。基於這個理由,我們建議透過 replica 來擴展 geospatial 索引表格。
Caching#
在引入快取層之前,我們必須先問自己:我們真的需要快取層嗎?
並不一定可以直接看出快取就是穩贏的選擇:
- 工作負載是讀取繁重的,且資料集相對較小。資料可以裝進任何現代資料庫伺服器的工作集,因此查詢不是 I/O bound,速度幾乎與記憶體中的快取一樣快。
- 如果讀取效能成為瓶頸,我們可以新增資料庫 read replica 來提升讀取吞吐量。
與面試官討論快取時要謹慎,因為這需要仔細的 benchmarking 與成本分析。如果你判斷快取符合業務需求,那就可以接著討論快取策略。
Cache key#
最直接的快取鍵選擇是使用者的位置座標(latitude 與 longitude)。然而,這個選擇有幾個問題:
- 行動電話回傳的位置座標並不精確,它們只是最佳估計值 [32]。即使你不移動,每次在手機上取得座標可能略有不同。
- 使用者可能從一個位置移動到另一個位置,使位置座標略有變化。對大多數應用程式而言,這種變化沒有意義。
因此位置座標不是好的快取鍵。理想上,位置的小變動仍應對應到相同的快取鍵。前面提到的 geohash/quadtree 解法可以很好地處理這個問題,因為一個格子內所有商家都對應到相同的 geohash。
Types of data to cache#
如表 12 所示,有兩類資料可被快取以提升系統整體效能:
| Key | Value |
|---|---|
| geohash | 格子內 business ID 的清單 |
| business_id | Business 物件 |
表 12 快取中的鍵值對
格子內 business ID 的清單
由於商家資料相對穩定,我們會預先計算給定 geohash 的 business ID 清單,並將其儲存在像 Redis 這樣的鍵值儲存中。讓我們看一個啟用快取後取得附近商家的具體範例。
取得指定 geohash 的 business ID 清單。
SELECT business_id FROM geohash_index WHERE geohash LIKE `{:geohash}%`若 cache miss,將結果存到 Redis 快取中。
public List<String> getNearbyBusinessIds(String geohash) { String cacheKey = hash(geohash); List<string> listOfBusinessIds = Redis.get(cacheKey); if (listOfBusinessIDs == null) { listOfBusinessIds = Run the select SQL query above; Cache.set(cacheKey, listOfBusinessIds, "1d"); } return listOfBusinessIds; }
當有新商家被新增、編輯或刪除時,更新資料庫並讓快取失效。由於這些操作的數量相對少,且 geohash 方法不需要鎖定機制,更新操作很容易處理。
依需求,使用者可在用戶端選擇下列 4 個半徑:500m、1km、2km 以及 5km。這些半徑分別對應到 geohash 長度 4、5、5、6。為了能快速擷取不同半徑下的附近商家,我們在 Redis 中以三種精度(geohash_4、geohash_5 以及 geohash_6)快取資料。
如前所述,我們有 2 億家商家,每家商家在給定精度下只屬於 1 個格子。因此所需總記憶體為:
- Redis 值的儲存:8 bytes _ 2 億 _ 3 種精度 = ~5 GB
- Redis 鍵的儲存:可忽略
- 所需總記憶體:~5 GB
從記憶體使用量的觀點,一台現代 Redis 伺服器就足夠了,但為了確保高可用性並降低跨大陸延遲,我們在全球部署 Redis 叢集。鑑於估計的資料大小,我們可以在全球部署相同副本的快取資料。在最終架構圖(圖 21)中我們稱這個 Redis 快取為「Geohash」。
渲染用戶端頁面所需的商家資料
這類資料快取很直接。Key 是 business_id,value 是包含商家名稱、地址、圖片 URL 等的 business 物件。在最終架構圖(圖 21)中我們稱這個 Redis 快取為「Business info」。
Region and availability zones#
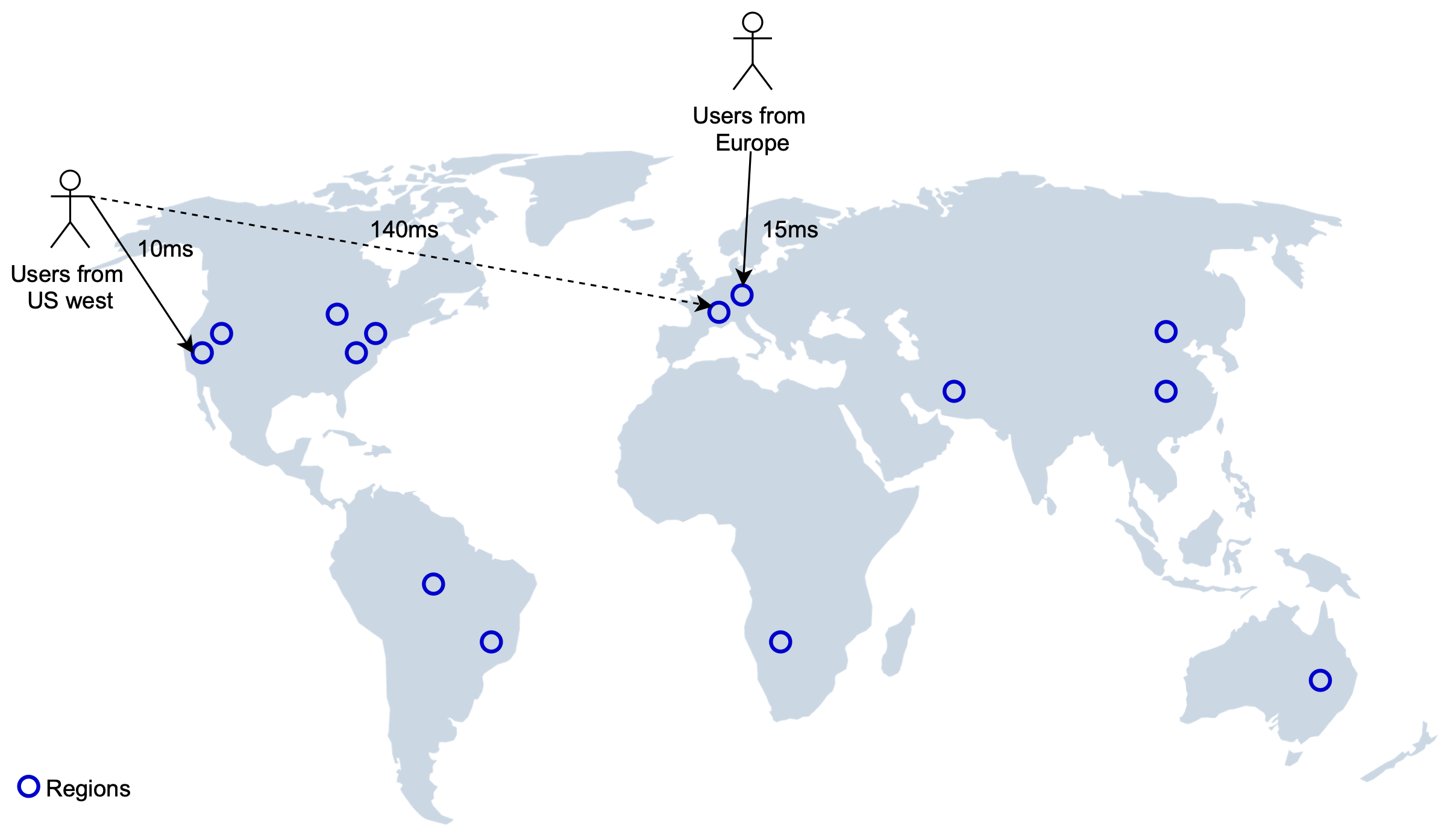
我們將 location-based service 部署到多個 region 與 availability zone,如圖 21 所示。這有幾個優點:
- 讓使用者在物理上「更靠近」系統。美西的使用者連到該區域的資料中心,歐洲的使用者連到歐洲的資料中心。
- 讓我們能將流量平均分散在人口之上。某些區域(例如日本與韓國)人口密度高。把它們放在不同 region,或甚至在多個 availability zone 中部署 LBS 來分散負載,可能是明智之舉。
- 隱私法律。某些國家可能要求使用者資料只能在當地使用與儲存。在這種情況下,我們可以在該國家設立一個 region,並使用 DNS routing 限制來自該國的所有請求只能進入該 region。
Follow-up question: filter results by time or business type#
面試官可能會問一個後續問題:如何只回傳目前營業中的商家,或只回傳餐廳類型的商家?
應徵者:當世界用 geohash 或 quadtree 切分為小格時,搜尋結果回傳的商家數量相對較少。因此可以接受先回傳 business ID,再 hydrate business 物件,並依營業時間或商家類型過濾。這個解法假設營業時間與商家類型儲存在 business 表格中。
Final design diagram#
把所有東西組合起來,我們得到下面的設計圖。
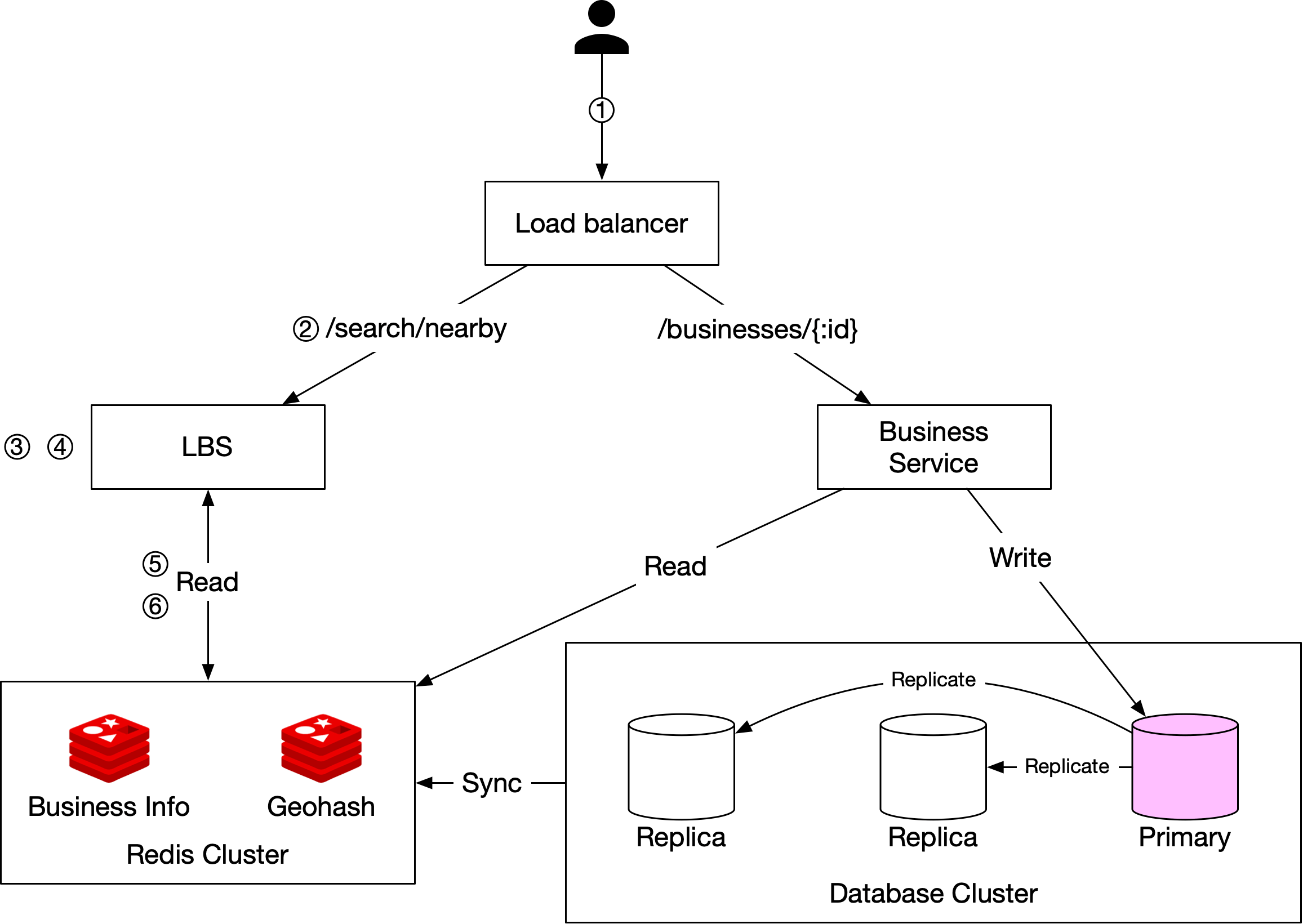
取得附近商家#
- 你嘗試在 Yelp 上尋找 500 公尺內的餐廳。用戶端將使用者位置(latitude = 37.776720、longitude = -122.416730)與半徑(500m)送到負載平衡器。
- 負載平衡器將請求轉發給 LBS。
- 根據使用者位置與半徑資訊,LBS 找到符合搜尋的 geohash 長度。對照表 5,500m 對應到 geohash 長度 = 6。
- LBS 計算相鄰 geohash 並加入清單。結果看起來像:list_of_geohashes = [my_geohash, neighbor1_geohash, neighbor2_geohash, …, neighbor8_geohash]。
- 對於 list_of_geohashes 中的每個 geohash,LBS 呼叫「Geohash」Redis 伺服器以擷取對應的 business ID。各個 geohash 的擷取呼叫可以平行進行以減少延遲。
- 根據回傳的 business ID 清單,LBS 從「Business info」Redis 伺服器擷取完整 hydrate 的商家資訊,然後計算使用者與商家之間的距離、排序,並將結果回傳給用戶端。
檢視、更新、新增或刪除商家#
所有商家相關的 API 都與 LBS 分離。要檢視商家的詳細資訊時,business service 會先檢查資料是否儲存在「Business info」Redis 快取中。如果有,快取的資料會回傳給用戶端。如果沒有,則從資料庫叢集擷取資料,再存到 Redis 快取,使後續請求可以直接從快取得到結果。
由於我們事先有商業協議:新增/更新的商家在隔天才生效,因此快取的商家資料會由每晚的工作來更新。
Step 4 - Wrap Up#
在本章中,我們呈現了鄰近服務的設計。這個系統是典型的 LBS,利用地理空間索引。我們討論了幾個索引選項:
- 二維搜尋
- 均勻切分格子
- Geohash
- Quadtree
- Google S2
Geohash、quadtree 與 S2 被不同科技公司廣泛使用。我們選 geohash 為例來展示地理空間索引如何運作。
在 deep dive 中,我們討論了為什麼快取對減少延遲有效、應該快取什麼,以及如何使用快取快速擷取附近商家。我們也討論了如何透過複寫與分片擴展資料庫。
接著我們檢視了把 LBS 部署到不同 region 與 availability zone 以提升可用性、讓使用者在物理上更靠近伺服器,並更好地遵循當地隱私法律。
恭喜你看到這裡!給自己一個鼓勵。做得好!
Chapter Summary#