近年來,雲端儲存服務(例如 Google Drive、Dropbox、Microsoft OneDrive 與 Apple iCloud)變得非常熱門。在本章中,你被要求設計一個 Google Drive。
在跳進設計之前,先花點時間了解 Google Drive。Google Drive 是一個檔案儲存與同步服務,能協助你將文件、相片、影片以及其他檔案儲存到雲端。你可以從任何電腦、智慧型手機與平板存取這些檔案,也可以輕鬆地與朋友、家人和同事分享 [1]。圖 1 與圖 15-2 分別展示了 Google Drive 在瀏覽器與行動應用程式上的樣貌。

Step 1 - Understand the problem and establish design scope#
設計一個 Google Drive 是相當大的專案,因此透過提問來縮小範圍非常重要。
應徵者:最重要的功能有哪些?
面試官:上傳與下載檔案、檔案同步以及通知。
應徵者:這是行動 App、Web App,還是兩者都要?
面試官:兩者都要。
應徵者:支援哪些檔案格式?
面試官:任何檔案類型。
應徵者:檔案需要加密嗎?
面試官:是的,儲存中的檔案必須加密。
應徵者:有檔案大小限制嗎?
面試官:有,檔案必須小於或等於 10 GB。
應徵者:產品有多少使用者?
面試官:1,000 萬 DAU。
在本章中,我們聚焦於以下功能:
- 新增檔案。最簡單的新增方式是把檔案拖放到 Google Drive。
- 下載檔案。
- 跨多裝置同步檔案。當在某一裝置新增檔案時,檔案會自動同步到其他裝置。
- 檢視檔案版本歷史。
- 與朋友、家人與同事分享檔案。
- 當檔案被編輯、刪除或被分享給你時送出通知。
本章不討論的功能包括:
- Google Doc 的編輯與協作。Google Doc 允許多人同時編輯同一份文件。這超出我們的設計範圍。
除了釐清需求之外,了解非功能性需求也很重要:
- 可靠性。對於儲存系統而言,可靠性極為重要。資料遺失是不可接受的。
- 快速同步速度。如果檔案同步耗時太久,使用者會失去耐心而放棄產品。
- 頻寬使用。如果產品占用太多不必要的網路頻寬,使用者會不滿,特別是當他們使用行動數據時。
- 可擴展性。系統應能處理大量流量。
- 高可用性。當部分伺服器離線、變慢或發生未預期的網路錯誤時,使用者仍應能使用系統。
Back of the envelope estimation#
- 假設應用程式有 5,000 萬註冊使用者與 1,000 萬 DAU。
- 使用者擁有 10 GB 免費空間。
- 假設使用者每天上傳 2 個檔案,平均檔案大小為 500 KB。
- 讀寫比為 1:1。
- 配置的總空間:5,000 萬 * 10 GB = 500 PB(Petabyte)
- 上傳 API 的 QPS:1,000 萬 * 2 次上傳 / 24 小時 / 3600 秒 ≈ 240
- 尖峰 QPS = QPS * 2 = 480
Step 2 - Propose high-level design and get buy-in#
我們不會一開始就直接展示高階設計圖,而是採用稍微不同的方式。我們會從簡單的東西開始:把所有東西都建在單一伺服器上。然後逐步擴充以支援數百萬使用者。透過這個練習,能複習課程中提到的一些重要主題。
讓我們從以下單伺服器設定開始:
- 一台 Web 伺服器負責上傳與下載檔案。
- 一個資料庫追蹤元資料(metadata),例如使用者資料、登入資訊、檔案資訊等等。
- 一個儲存系統用來儲存檔案。我們配置 1TB 的儲存空間來存放檔案。
我們花了幾小時架設一台 Apache Web 伺服器、一個 MySQL 資料庫,以及一個名為 drive/ 的目錄作為存放上傳檔案的根目錄。在 drive/ 目錄之下有一系列子目錄,稱為 namespace。每個 namespace 包含該使用者所有上傳的檔案。檔案在伺服器上的檔名與原始檔名一致。每個檔案或資料夾可以透過串接 namespace 與相對路徑唯一識別。
圖 3 左側顯示了 /drive 目錄的範例,右側則為其展開後的樣貌。

APIs#
API 長什麼樣子?我們主要需要 3 個 API:上傳檔案、下載檔案以及取得檔案版本。
1. 上傳檔案到 Google Drive
支援兩種上傳類型:
- 簡單上傳(Simple upload)。當檔案較小時使用此上傳類型。
- 可斷點續傳上傳(Resumable upload)。當檔案較大且網路中斷可能性較高時使用此上傳類型。
以下是一個 resumable upload API 的範例:
https://api.example.com/files/upload?uploadType=resumable
參數:
- uploadType=resumable
- data:要上傳的本地檔案。
可斷點續傳上傳透過以下 3 個步驟達成 [2]:
- 送出初始請求以取得 resumable URL。
- 上傳資料並監控上傳狀態。
- 若上傳被中斷,則恢復上傳。
2. 從 Google Drive 下載檔案
範例 API:https://api.example.com/files/download
參數:
- path:要下載的檔案路徑。
範例參數:
{
"path": "/recipes/soup/best_soup.txt"
}3. 取得檔案版本
範例 API:https://api.example.com/files/list_revisions
參數:
- path:你想取得版本歷史的檔案路徑。
- limit:要回傳的最大版本數量。
範例參數:
{
"path": "/recipes/soup/best_soup.txt",
"limit": 20
}所有 API 都需要使用者驗證並使用 HTTPS。SSL(Secure Sockets Layer)保護用戶端與後端伺服器之間的資料傳輸。
Move away from single server#
當越來越多檔案被上傳,最終你會看到如圖 4 所示的空間已滿警示。

只剩下 10 MB 儲存空間!這是一個緊急情況,因為使用者再也無法上傳檔案。第一個浮現腦中的解決方案是對資料進行 sharding,使資料分散在多台儲存伺服器上。圖 5 展示了基於 user_id 進行 sharding 的範例。

你熬夜架設好資料庫 sharding 並密切監控。一切又順利地運作。火是滅了,但你仍然擔心儲存伺服器發生故障時可能造成的資料遺失。你四處詢問,後端達人朋友 Frank 告訴你許多領先公司(例如 Netflix 與 Airbnb)都使用 Amazon S3 來儲存資料。「Amazon Simple Storage Service(Amazon S3)是一項物件儲存服務,提供業界領先的可擴展性、資料可用性、安全性與效能」[3]。你決定做些研究,看它是否合適。
讀了大量資料後,你對 S3 儲存系統有了不錯的理解,並決定把檔案存放在 S3。Amazon S3 同時支援同地區(same-region)與跨地區(cross-region)的複寫。一個區域(region)是一個地理區域,AWS(Amazon web services)在那裡有資料中心。如圖 6 所示,資料可以同地區複寫(左側)或跨地區複寫(右側)。冗餘的檔案儲存在多個區域,以防止資料遺失並確保可用性。Bucket 就像檔案系統中的資料夾。

把檔案放到 S3 之後,你終於可以一夜好眠,不再擔心資料遺失。為了避免類似問題再發生,你決定進一步研究可以改善的地方。你發現以下幾個方面:
- 負載平衡器(Load balancer):加上負載平衡器以分散網路流量。負載平衡器確保流量平均分配,且當某台 Web 伺服器故障時,它會把流量重新分配。
- Web 伺服器:加上負載平衡器後,可以根據流量負載輕易地新增/移除更多 Web 伺服器。
- 元資料資料庫:把資料庫從伺服器中移出,避免單點故障。同時設定資料複寫與 sharding 以滿足可用性與擴展性需求。
- 檔案儲存:使用 Amazon S3 來儲存檔案。為了確保可用性與耐久性,檔案會在兩個不同的地理區域進行複寫。
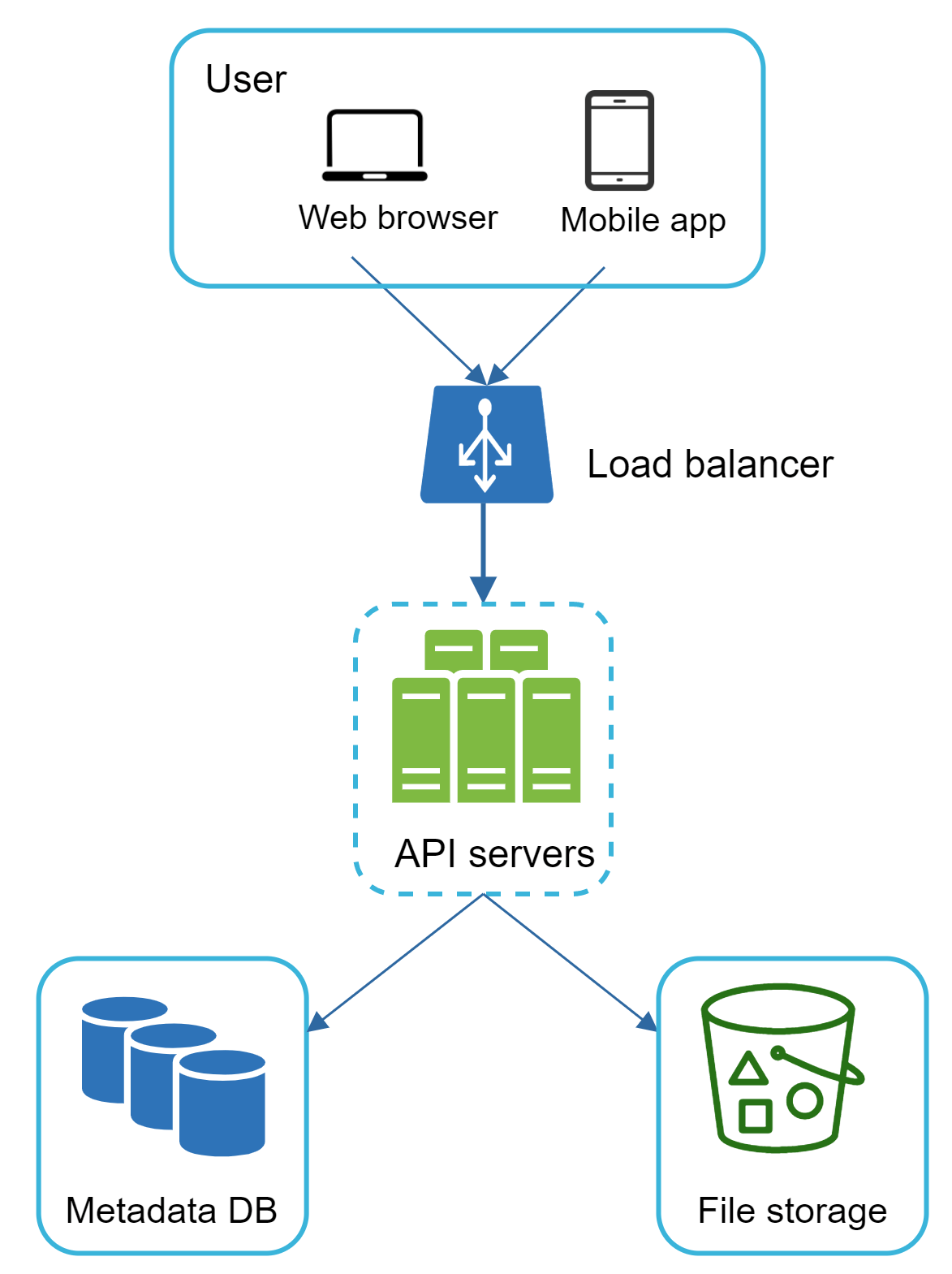
套用以上改善後,你成功將 Web 伺服器、元資料資料庫與檔案儲存從單一伺服器解耦。更新後的設計如圖 7 所示。
Sync conflicts#
對於像 Google Drive 這樣的大型儲存系統,同步衝突時不時會發生。當兩位使用者同時修改同一個檔案或資料夾時,就會發生衝突。我們該如何解決衝突?
衝突解決策略:先被處理的版本獲勝,後被處理的版本則收到衝突。
圖 8 顯示了同步衝突的範例。

在圖 8 中,user 1 與 user 2 試圖同時更新同一個檔案,但 user 1 的檔案先被我們的系統處理。User 1 的更新作業順利完成,但 user 2 收到了同步衝突。如何解決 user 2 的衝突?我們的系統會呈現該檔案的兩個副本:user 2 的本地副本與來自伺服器的最新版本(圖 9)。User 2 可以選擇合併兩個檔案,或以其中一個版本覆蓋另一個。

當多位使用者同時編輯相同文件時,要保持文件同步是相當有挑戰性的。有興趣的讀者可以參考參考資料 [4] [5]。
High-level design#
圖 10 展示了所提的高階設計。讓我們逐一檢視系統的各個組件。
- 使用者(User):使用者透過瀏覽器或行動 App 使用本應用程式。
- Block 伺服器(Block servers):Block 伺服器將區塊(block)上傳至雲端儲存。Block 儲存(也稱為 block-level storage)是一種在雲端環境儲存資料檔案的技術。一個檔案可以被切分為多個區塊,每個區塊都有唯一的雜湊值(hash value),儲存在我們的元資料資料庫中。每個區塊被視為獨立物件並存放於我們的儲存系統(S3)中。要重建一個檔案時,依特定順序將區塊接合即可。至於區塊大小,我們以 Dropbox 為參考:它將區塊的最大大小設定為 4MB [6]。
- 雲端儲存(Cloud storage):檔案被切成較小的區塊並存放在雲端儲存中。
- 冷儲存(Cold storage):冷儲存是專為儲存非活躍資料(即長期未被存取的檔案)所設計的電腦系統。
- 負載平衡器(Load balancer):負載平衡器將請求平均分配到 API 伺服器之間。
- API 伺服器(API servers):負責上傳流程之外幾乎所有的事情。API 伺服器用於使用者驗證、管理使用者個人檔案、更新檔案元資料等。
- 元資料資料庫(Metadata database):儲存使用者、檔案、區塊、版本等的元資料。請注意,檔案儲存在雲端,元資料資料庫只包含元資料。
- 元資料快取(Metadata cache):部分元資料會被快取以供快速擷取。
- 通知服務(Notification service):這是一個發布/訂閱(publisher/subscriber)系統,允許在某些事件發生時將資料從通知服務傳送至用戶端。在我們的情境中,當檔案在某處被新增/編輯/移除時,通知服務會通知相關用戶端,讓它們可以拉取最新變更。
- 離線備份佇列(Offline backup queue):若用戶端離線而無法拉取最新檔案變更,離線備份佇列會儲存相關資訊,待用戶端上線後再進行同步。
我們已從高階層次討論了 Google Drive 的設計。其中部分組件較為複雜值得仔細審視,我們將在 deep dive 中詳細討論。
Step 3 - Design deep dive#
在本節中,我們將仔細檢視以下內容:block 伺服器、元資料資料庫、上傳流程、下載流程、通知服務、節省儲存空間以及故障處理。
Block servers#
對於頻繁更新的大型檔案,每次更新都傳送整個檔案會耗用大量頻寬。我們提出兩項最佳化來最小化網路傳輸量:
- Delta sync。當檔案被修改時,只同步被修改的區塊,而非整個檔案,此處使用同步演算法 [7] [8]。
- 壓縮。對區塊套用壓縮可顯著減少資料大小。因此會根據檔案類型使用不同的壓縮演算法來壓縮區塊。例如,gzip 與 bzip2 用於壓縮文字檔;圖片與影片則需要不同的壓縮演算法。
在我們的系統中,block 伺服器負責檔案上傳的繁重工作。Block 伺服器處理用戶端傳入的檔案,將檔案切分為區塊、對每個區塊壓縮並加密。我們不會把整個檔案上傳到儲存系統,只會傳輸被修改的區塊。
圖 11 顯示了當新檔案被新增時 block 伺服器的工作方式。
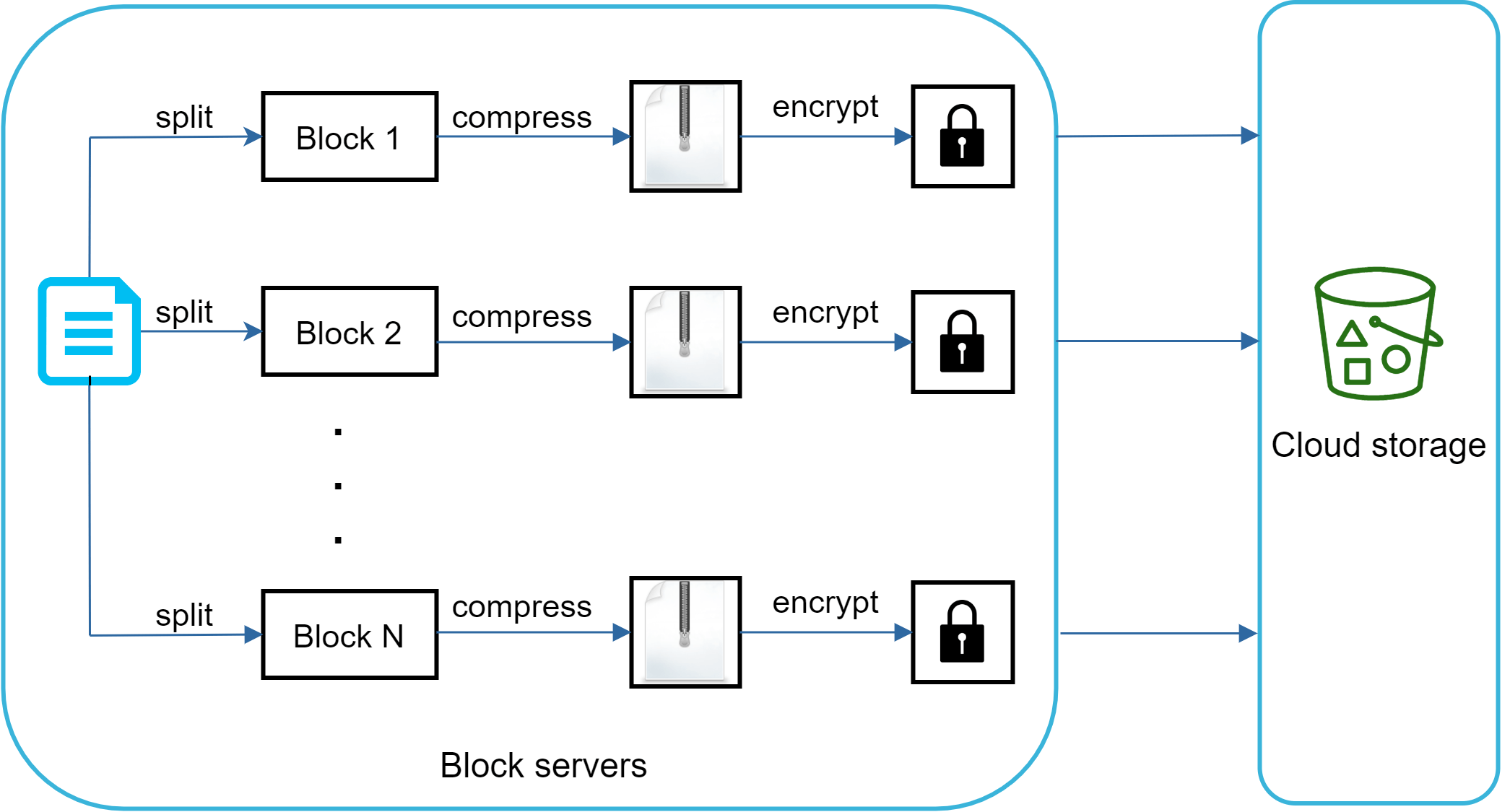
- 檔案被切分為較小的區塊。
- 每個區塊使用壓縮演算法壓縮。
- 為確保安全性,每個區塊在送往雲端儲存之前會被加密。
- 區塊被上傳至雲端儲存。
圖 12 描繪了 delta sync,意即只將被修改的區塊傳送至雲端儲存。標示出的「block 2」與「block 5」代表變更過的區塊。透過 delta sync,只有這兩個區塊會被上傳至雲端儲存。

Block 伺服器透過提供 delta sync 與壓縮,使我們能節省網路流量。
High consistency requirement#
我們的系統預設要求強一致性。同一時間不同用戶端看到同一檔案有不同內容是無法接受的。系統必須對元資料快取與資料庫層提供強一致性。
記憶體快取預設採用最終一致性模型,意即不同副本可能擁有不同資料。要達成強一致性,必須確保下列事項:
- 快取副本與主節點的資料一致。
- 在資料庫寫入時讓快取失效,以確保快取與資料庫保持相同的值。
在關聯式資料庫中達到強一致性很容易,因為它維持了 ACID(Atomicity、Consistency、Isolation、Durability)特性 [9]。然而 NoSQL 資料庫預設不支援 ACID 特性,需要在同步邏輯中以程式方式實作 ACID 特性。在我們的設計中,我們選擇關聯式資料庫,因為原生支援 ACID。
Metadata database#
圖 13 顯示了資料庫 schema 的設計。請注意這是高度簡化的版本,僅包含最重要的表格與值得關注的欄位。

- User:user 表格包含關於使用者的基本資訊,例如 username、email、profile photo 等。
- Device:device 表格儲存裝置資訊。Push_id 用於發送與接收行動推播通知。請注意一位使用者可以擁有多個裝置。
- Namespace:namespace 是使用者的根目錄。
- File:file 表格儲存與最新檔案相關的所有資訊。
- File_version:儲存檔案的版本歷史。既有的列為唯讀,以維持檔案版本歷史的完整性。
- Block:儲存與檔案區塊相關的所有資訊。任何版本的檔案皆可透過依正確順序合併所有區塊來重建。
Upload flow#
讓我們討論用戶端上傳檔案時會發生什麼事。為了更好地理解流程,我們繪製了如圖 14 所示的循序圖。

在圖 14 中,有兩個請求平行送出:新增檔案元資料以及將檔案上傳至雲端儲存。兩個請求都源自 client 1。
新增檔案元資料
- Client 1 送出請求以新增該新檔案的元資料。
- 將新檔案元資料儲存至元資料 DB,並將檔案上傳狀態變更為「pending」。
- 通知 notification service 有新檔案正在被新增。
- Notification service 通知相關用戶端(client 2)有檔案正在上傳。
將檔案上傳至雲端儲存
- Client 1 將檔案內容上傳至 block 伺服器。
- Block 伺服器將檔案切分為區塊、壓縮、加密區塊,並上傳至雲端儲存。
- 一旦檔案上傳完成,雲端儲存觸發上傳完成的 callback,請求被送至 API 伺服器。
- 在元資料 DB 中將檔案狀態變更為「uploaded」。
- 通知 notification service 檔案狀態已變更為「uploaded」。
- Notification service 通知相關用戶端(client 2)檔案已完整上傳。
當檔案被編輯時,流程類似,因此不再重複。
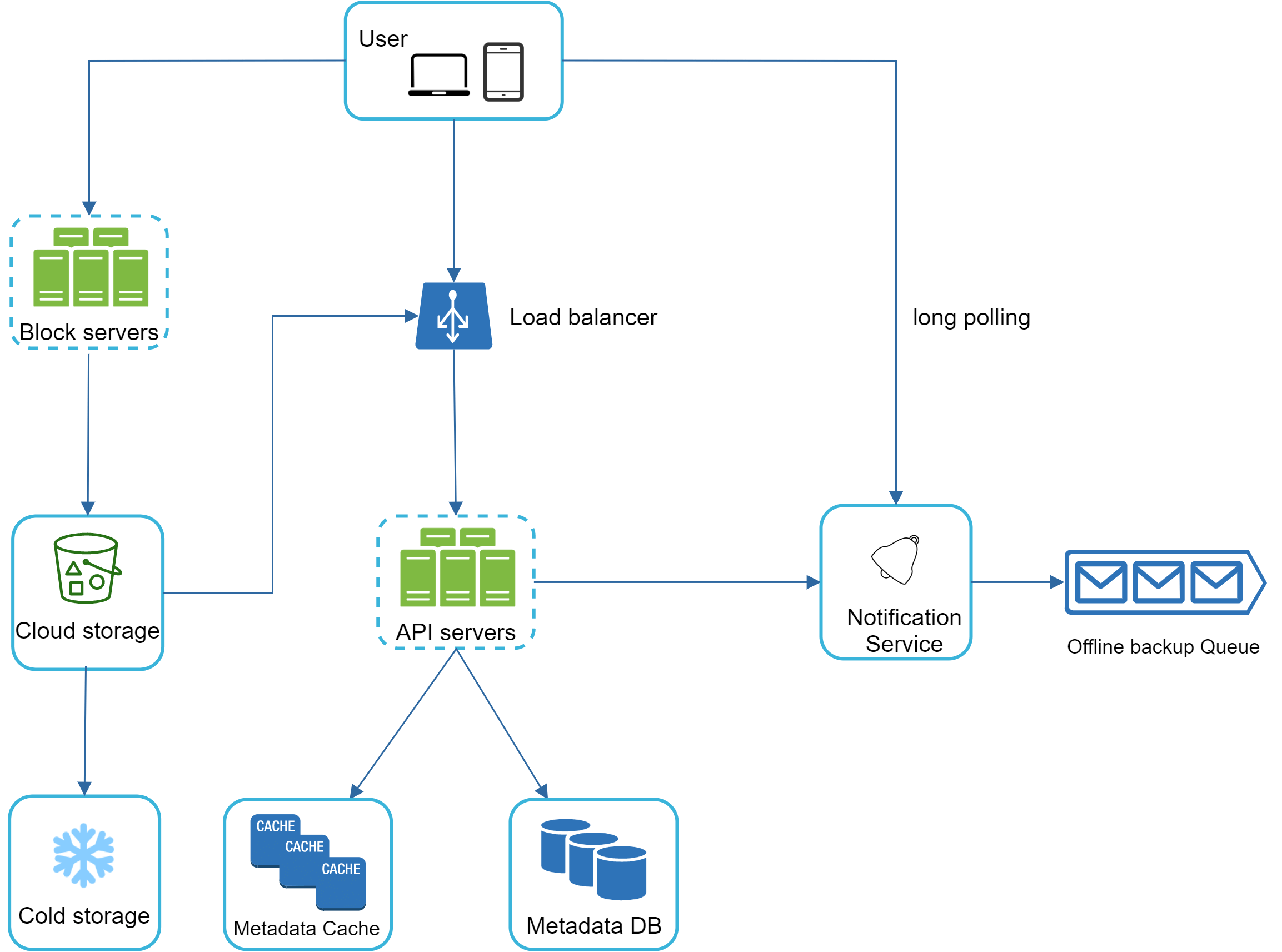
Download flow#
下載流程在檔案於他處被新增或編輯時被觸發。用戶端如何知道檔案被另一個用戶端新增或編輯?有兩種方式可讓用戶端得知:
- 若 client A 在檔案被另一個用戶端變更時是上線狀態,notification service 會通知 client A 在某處有變更,因此需要拉取最新資料。
- 若 client A 在檔案被另一個用戶端變更時是離線狀態,資料會被儲存到快取中。當離線的用戶端重新上線時,再拉取最新變更。
當用戶端知道檔案有變更後,它會先透過 API 伺服器請求元資料,然後下載區塊以重建檔案。圖 15 顯示了詳細流程。注意,由於空間限制,圖中只顯示最重要的組件。

- Notification service 通知 client 2 有檔案在他處被變更。
- 一旦 client 2 知道有新更新可用,它會送出請求以擷取元資料。
- API 伺服器呼叫元資料 DB 來擷取變更的元資料。
- 元資料回傳給 API 伺服器。
- Client 2 取得元資料。
- 一旦用戶端收到元資料,它會送出請求至 block 伺服器以下載區塊。
- Block 伺服器先從雲端儲存下載區塊。
- 雲端儲存將區塊回傳給 block 伺服器。
- Client 2 下載所有新區塊以重建檔案。
Notification service#
為了維持檔案一致性,本地對檔案的任何變動都需要通知其他用戶端以減少衝突。Notification service 即為此目的而建。在高階層次上,notification service 允許資料在事件發生時傳送至用戶端。以下是幾個選項:
- Long polling。Dropbox 使用 long polling [10]。
- WebSocket。WebSocket 提供用戶端與伺服器間的持久連線,通訊是雙向的。
雖然兩種選項都可行,我們選擇 long polling,原因有兩個:
- Notification service 的通訊不是雙向的。伺服器將檔案變更資訊送給用戶端,但反之則不需要。
- WebSocket 適合即時雙向通訊,例如聊天 App。對 Google Drive 而言,通知傳送頻率不高且沒有突發大量資料。
使用 long polling 時,每個用戶端與 notification service 建立一個 long poll 連線。當偵測到檔案變更時,用戶端會關閉該 long poll 連線。關閉連線意味著用戶端必須連線到元資料伺服器以下載最新變更。在收到回應或連線逾時後,用戶端會立即送出新的請求以保持連線開啟。
Save storage space#
為了支援檔案版本歷史並確保可靠性,相同檔案的多個版本會被儲存在多個資料中心。儲存空間可能因為頻繁備份所有檔案版本而被快速填滿。為了降低儲存成本,我們提出三項技巧:
- 對資料區塊進行去重(De-duplicate)。在帳戶層級消除重複的區塊是節省空間的簡單方法。若兩個區塊擁有相同的雜湊值即視為相同。
- 採用智慧型資料備份策略。可以套用兩種最佳化策略:
- 設定上限:我們可以設定要儲存的版本數上限。若達到上限,最舊的版本會被新版本取代。
- 只保留有價值的版本:某些檔案可能被頻繁編輯。例如,對一份被大量修改的文件儲存每個編輯版本,可能會在短時間內被儲存超過 1000 次。為避免不必要的副本,我們可以限制儲存的版本數,並對較近期的版本給予更高權重。實驗有助於找出最佳的版本保留數量。
- 將不常使用的資料移至冷儲存。冷資料是指數月或數年未活躍的資料。像 Amazon S3 Glacier [11] 這類冷儲存比 S3 便宜得多。
Failure Handling#
在大規模系統中故障會發生,我們必須採取設計策略來處理這些故障。面試官可能會有興趣聽你如何處理以下系統故障。
- 負載平衡器故障:若負載平衡器故障,次要的負載平衡器會啟用並接手流量。負載平衡器之間通常透過 heartbeat(定期傳送的訊號)互相監測。若一個負載平衡器一段時間未送出 heartbeat,則被視為故障。
- Block 伺服器故障:若 block 伺服器故障,其他伺服器會接手未完成或待處理的工作。
- 雲端儲存故障:S3 buckets 會在不同 region 中複寫多次。若檔案在某 region 不可用,可從其他 region 取得。
- API 伺服器故障:它是無狀態服務。若一台 API 伺服器故障,流量會被負載平衡器導向其他 API 伺服器。
- 元資料快取故障:元資料快取伺服器有多份複本。若一個節點故障,仍可從其他節點存取資料。我們會啟動一台新的快取伺服器來取代故障的伺服器。
- 元資料 DB 故障:
- Master 故障:若 master 故障,將其中一個 slave 提升為新的 master,並啟動一個新的 slave 節點。
- Slave 故障:若 slave 故障,可使用另一個 slave 進行讀取,並啟動另一台資料庫伺服器來取代故障的。
- Notification service 故障:每個上線使用者都與 notification 伺服器維持一個 long poll 連線。因此每台 notification 伺服器與許多使用者連線。根據 2012 年 Dropbox 的演講 [6],每台機器可開啟超過 100 萬條連線。若伺服器故障,所有 long poll 連線都會遺失,因此用戶端必須重新連到不同的伺服器。即使一台伺服器可以維持很多開啟的連線,也無法一次重連所有遺失的連線。重新連接所有失去的用戶端是一個相對緩慢的過程。
- 離線備份佇列故障:佇列被複寫多次。若一個佇列故障,佇列的消費者可能需要重新訂閱備份佇列。
Step 4 - Wrap up#
在本章中,我們提出了支援 Google Drive 的系統設計。強一致性、低網路頻寬與快速同步的組合,使這個設計顯得有趣。我們的設計包含兩個流程:管理檔案元資料與檔案同步。Notification service 是系統另一個重要組件,它透過 long polling 讓用戶端能掌握檔案的最新變更。
如同任何系統設計面試題,沒有完美的解答。每家公司都有獨特的限制,你必須設計符合那些限制的系統。了解你設計與技術選擇的取捨非常重要。如果還剩幾分鐘,可以談談不同的設計選項。
例如,我們可以從用戶端直接上傳檔案至雲端儲存,而不必經過 block 伺服器。這種做法的優點是讓檔案上傳更快,因為檔案只需要傳輸到雲端儲存一次。在我們的設計中,檔案會先被傳到 block 伺服器,再被傳到雲端儲存。然而新做法有幾個缺點:
- 第一,相同的切塊、壓縮與加密邏輯必須在不同平台(iOS、Android、Web)上實作,這容易出錯且需要大量工程努力。在我們的設計中,所有這些邏輯都實作在集中的地方:block 伺服器。
- 第二,由於用戶端容易遭駭或被操控,在用戶端實作加密邏輯並不理想。
系統另一個有趣的演進是把上線/離線邏輯移到一個獨立服務。我們稱之為 presence service。將 presence service 從 notification 伺服器中移出後,上線/離線功能就能輕易地被其他服務整合。
恭喜你看到這裡!給自己一個鼓勵。做得好!