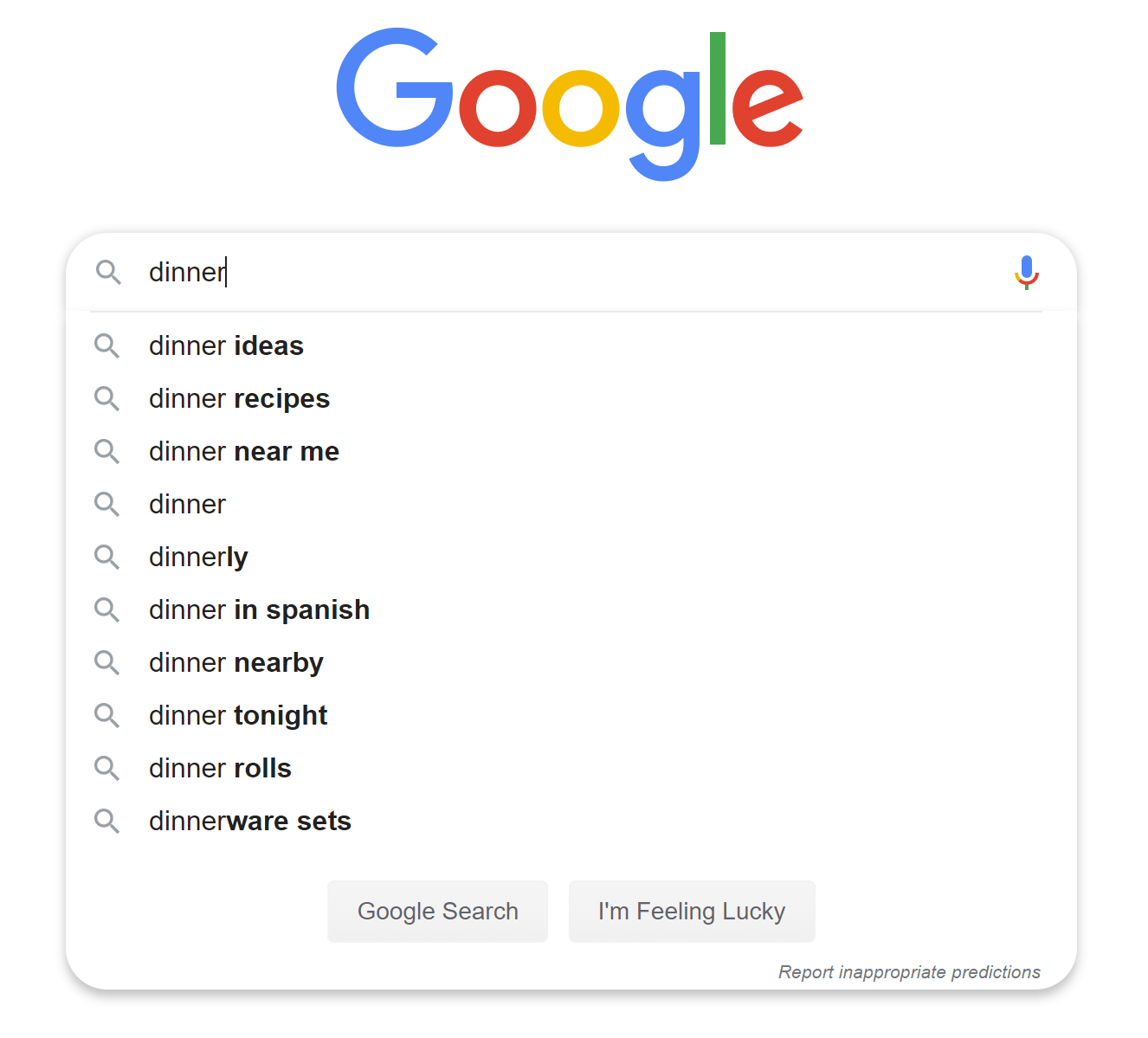
當你在 Google 搜尋或在 Amazon 購物時,當你在搜尋框中輸入文字時,會出現一個或多個與搜尋詞相符的結果。這個功能被稱為自動完成(autocomplete)、typeahead、search-as-you-type,或漸進式搜尋(incremental search)。圖 1 是 Google 搜尋的範例,當在搜尋框中輸入「dinner」時,會顯示一份自動完成結果清單。搜尋自動完成是許多產品的重要功能。這引出了我們的面試題目:設計一個搜尋自動完成系統,又稱「design top k」或「design top k most searched queries」。
Step 1 - Understand the problem and establish design scope#
處理任何系統設計面試題目的第一步,是問足夠多的問題來釐清需求。以下是應徵者與面試官互動的範例:
應徵者:是否只在搜尋查詢的開頭支援匹配,還是中間也支援?
面試官:只在搜尋查詢的開頭。
應徵者:系統應該回傳幾個自動完成建議?
面試官:5 個。
應徵者:系統如何知道要回傳哪 5 個建議?
面試官:根據熱門度決定,由歷史查詢頻率決定。
應徵者:系統支援拼字檢查嗎?
面試官:不支援拼字檢查或自動更正。
應徵者:搜尋查詢是英文嗎?
面試官:是的。如果最後時間允許,我們可以討論多語言支援。
應徵者:是否允許大寫與特殊字元?
面試官:不允許,我們假設所有搜尋查詢都是小寫英文字母。
應徵者:有多少使用者使用這個產品?
面試官:1,000 萬 DAU。
需求
以下是需求摘要:
- 快速回應時間:當使用者輸入搜尋查詢時,自動完成建議必須夠快地顯示。一篇關於 Facebook 自動完成系統的文章 [1] 顯示,系統需要在 100 毫秒內回傳結果,否則會造成卡頓。
- 相關性:自動完成建議應與搜尋詞相關。
- 排序:系統回傳的結果必須依熱門度或其他排名模型排序。
- 可擴展:系統能處理高流量。
- 高可用性:當系統部分離線、變慢或發生意外的網路錯誤時,系統應保持可用且可存取。
Back of the envelope estimation#
假設每日活躍使用者(DAU)為 1,000 萬。
一般人每天執行 10 次搜尋。
每筆查詢字串 20 bytes 資料:
- 假設我們使用 ASCII 字元編碼。1 字元 = 1 byte。
- 假設一個查詢包含 4 個單字,每個單字平均 5 個字元。
- 也就是每筆查詢 4 x 5 = 20 bytes。
對於輸入到搜尋框的每個字元,client 都會向後端發送一個自動完成建議的請求。平均而言,每筆搜尋查詢會發送 20 個請求。例如,當你輸入完「dinner」時,會發送以下 6 個請求到後端:
search?q=d search?q=di search?q=din search?q=dinn search?q=dinne search?q=dinner約 24,000 query per second(QPS)= 10,000,000 使用者 _ 10 查詢 / 天 _ 20 字元 / 24 小時 / 3600 秒。
尖峰 QPS = QPS * 2 = 約 48,000。
假設每日查詢中有 20% 是新的。1,000 萬 _ 10 查詢 / 天 _ 20 byte / 查詢 * 20% = 0.4 GB。這代表每天有 0.4 GB 的新資料加到儲存中。
Step 2 - Propose high-level design and get buy-in#
在高階層次上,系統被分為兩部分:
- 資料蒐集服務(Data gathering service):它蒐集使用者輸入的查詢並即時彙總。即時處理對大型資料集而言並不實用,但這是個不錯的起點。我們會在 deep dive 中探索更實際的解決方案。
- 查詢服務(Query service):給定搜尋查詢或 prefix,回傳搜尋次數最多的 5 個詞。
Data gathering service#
讓我們用一個簡化的例子來看看資料蒐集服務如何運作。假設我們有一個如圖 2 所示的頻率表,儲存查詢字串及其頻率。一開始頻率表是空的。後來使用者依序輸入查詢「twitch」、「twitter」、「twitter」與「twillo」。圖 2 顯示了頻率表是如何更新的。

Query service#
假設我們有一個如表 1 所示的頻率表。它有兩個欄位:
- Query:儲存查詢字串。
- Frequency:表示某個查詢被搜尋的次數。
| Query | Frequency |
|---|---|
| 35 | |
| twitch | 29 |
| twilight | 25 |
| twin peak | 21 |
| twitch prime | 18 |
| twitter search | 14 |
| twillo | 10 |
| twin peak sf | 8 |
表 1
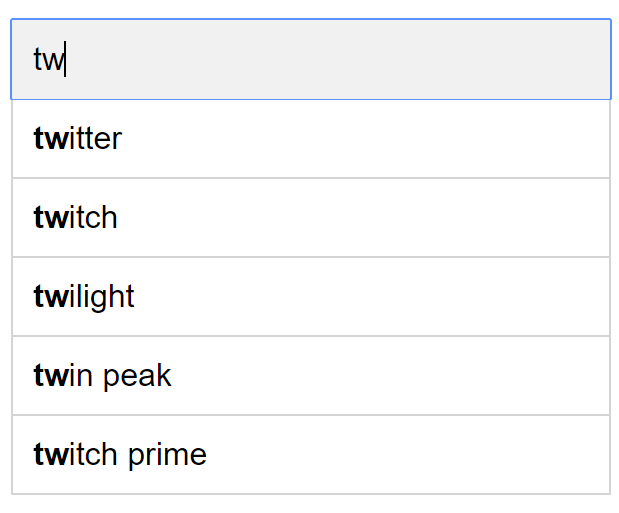
當使用者在搜尋框輸入「tw」時,會顯示以下熱門 5 個搜尋查詢(圖 3),假設頻率表基於表 1。
要取得熱門 5 個常被搜尋的查詢,執行下列 SQL 查詢:

當資料集很小時,這是一個可接受的解決方案。當資料集很大時,存取資料庫會成為瓶頸。我們會在 deep dive 中探索最佳化方法。
Step 3 - Design deep dive#
在高階設計中,我們討論了資料蒐集服務與查詢服務。高階設計並非最佳,但它是個不錯的起點。在本節中,我們會深入幾個元件並探索最佳化,內容如下:
- Trie 資料結構
- 資料蒐集服務
- 查詢服務
- 儲存擴展
- Trie 操作
Trie data structure#
在高階設計中,我們使用關聯式資料庫作為儲存。然而,從關聯式資料庫抓取熱門 5 筆搜尋查詢是沒效率的。我們使用 trie(prefix tree,又稱前綴樹)這個資料結構來克服這個問題。由於 trie 資料結構對系統至關重要,我們會花相當多的時間設計一個客製化的 trie。請注意,部分想法來自於文章 [2] 與 [3]。
理解基本的 trie 資料結構對這個面試題目至關重要。然而,這比較像是資料結構問題而不是系統設計問題。此外,網路上有許多教材說明這個概念。在本章中,我們只會討論 trie 資料結構的概觀,並專注於如何最佳化基本 trie 以改善回應時間。
Trie(讀作「try」)是一種樹狀資料結構,可以緊湊地儲存字串。其名稱來自單字 retrieval,這表示它是為字串檢索操作而設計。Trie 的主要概念包括:
- Trie 是一種樹狀資料結構。
- Root 代表空字串。
- 每個節點儲存一個字元並有 26 個子節點,每個可能的字元對應一個。為了節省空間,我們不畫空連結。
- 每個樹節點代表一個單字或一個 prefix 字串。
圖 5 顯示了一個有搜尋查詢「tree」、「try」、「true」、「toy」、「wish」、「win」的 trie。搜尋查詢以較粗的邊框標示。

基本 trie 資料結構在節點中儲存字元。為了支援依頻率排序,需要在節點中包含頻率資訊。假設我們有以下頻率表。
| Query | Frequency |
|---|---|
| tree | 10 |
| try | 29 |
| true | 35 |
| toy | 14 |
| wish | 25 |
| win | 50 |
表 2
加入頻率資訊到節點後,更新後的 trie 資料結構如圖 6 所示。

自動完成如何用 trie 運作?在深入演算法之前,讓我們先定義幾個名詞:
- p:prefix 的長度
- n:trie 中總節點數
- c:給定節點的子節點數
取得熱門 k 個被搜尋查詢的步驟如下:
- 找到 prefix。時間複雜度:O(p)。
- 從 prefix 節點走訪子樹以取得所有有效的子節點。如果子節點能形成有效的查詢字串,就算是有效的。時間複雜度:O(c)。
- 對子節點排序並取得前 k 個。時間複雜度:O(clogc)。
讓我們用圖 7 的例子來解釋演算法。假設 k 等於 2,使用者在搜尋框輸入「tr」。演算法運作如下:
- 步驟 1:找到 prefix 節點「tr」。
- 步驟 2:走訪子樹以取得所有有效的子節點。在這個例子中,節點 [tree: 10]、[true: 35]、[try: 29] 都是有效的。
- 步驟 3:對子節點排序並取得前 2 個。[true: 35] 與 [try: 29] 是 prefix 為「tr」的前 2 個查詢。

這個演算法的時間複雜度是上述每個步驟所花時間的總和:O(p) + O(c) + O(clogc)。
上述演算法很直接,但它太慢了,因為在最壞情況下我們需要走訪整個 trie 才能取得前 k 個結果。以下是兩個最佳化:
- 限制 prefix 的最大長度
- 在每個節點快取熱門搜尋查詢
讓我們逐一檢視這些最佳化。
Limit the max length of a prefix#
使用者很少在搜尋框輸入很長的搜尋查詢,因此可以說 p 是個小整數,例如 50。如果我們限制 prefix 的長度,「找到 prefix」的時間複雜度可以從 O(p) 降為 O(small constant),亦即 O(1)。
Cache top search queries at each node#
為了避免走訪整個 trie,我們在每個節點儲存熱門 k 個最常使用的查詢。由於 5 到 10 個自動完成建議對使用者來說已足夠,k 是個相對較小的數字。在我們的特定情境中,只快取熱門 5 個搜尋查詢。
藉由在每個節點快取熱門搜尋查詢,我們大幅降低了取得熱門 5 個查詢的時間複雜度。然而,這個設計需要大量空間在每個節點儲存熱門查詢。用空間換取時間是非常值得的,因為快速的回應時間非常重要。
圖 8 顯示了更新後的 trie 資料結構。每個節點都儲存熱門 5 個查詢。例如,prefix 為「be」的節點儲存以下內容:[best: 35, bet: 29, bee: 20, be: 15, beer: 10]。

讓我們重新檢視套用這兩項最佳化後的演算法時間複雜度:
- 找到 prefix 節點。時間複雜度:O(1)。
- 回傳熱門 k 個。由於熱門 k 個查詢已被快取,這個步驟的時間複雜度是 O(1)。
由於每個步驟的時間複雜度都降為 O(1),我們的演算法只需 O(1) 就能抓取熱門 k 個查詢。
Data gathering service#
在我們先前的設計中,每當使用者輸入搜尋查詢時,資料就會即時更新。這種做法不實際,原因有以下兩點:
- 使用者每天可能輸入數十億筆查詢。每次查詢都更新 trie 會大幅拖慢查詢服務。
- 一旦 trie 建好,熱門建議可能變化不大,因此沒有必要頻繁更新 trie。
要設計可擴展的資料蒐集服務,我們會檢視資料來自哪裡以及如何被使用。像 Twitter 這類即時應用程式需要最新的自動完成建議。然而,許多 Google 關鍵字的自動完成建議在每日基礎上可能變化不大。
儘管使用案例各有不同,資料蒐集服務的底層基礎大致相同,因為用來建構 trie 的資料通常來自分析或日誌服務。
圖 9 顯示了重新設計後的資料蒐集服務。每個元件會被逐一檢視。

Analytics Logs。 它儲存有關搜尋查詢的原始資料。Logs 是 append-only 的且未建立索引。表 3 顯示了 log 檔案的範例。
| query | time |
|---|---|
| tree | 2019-10-01 22:01:01 |
| try | 2019-10-01 22:01:05 |
| tree | 2019-10-01 22:01:30 |
| toy | 2019-10-01 22:02:22 |
| tree | 2019-10-02 22:02:42 |
| try | 2019-10-03 22:03:03 |
表 3
Aggregators。 Analytics logs 的大小通常非常大,且資料格式不對。我們需要彙總資料,以便我們的系統可以輕鬆處理。
依使用案例不同,我們可能會以不同方式彙總資料。對於像 Twitter 這類即時應用程式,我們會以較短的時間間隔彙總資料,因為即時結果很重要。另一方面,較少彙總資料(例如每週一次)對許多使用案例可能就夠了。
在面試過程中,要確認即時結果是否重要。我們假設 trie 每週重建一次。
Aggregated Data#
表 4 顯示了每週彙總資料的範例。「time」欄位代表一週的開始時間。「frequency」欄位是該週對應查詢出現次數的總和。
| query | time | frequency |
|---|---|---|
| tree | 2019-10-01 | 12000 |
| tree | 2019-10-08 | 15000 |
| tree | 2019-10-15 | 9000 |
| toy | 2019-10-01 | 8500 |
| toy | 2019-10-08 | 6256 |
| toy | 2019-10-15 | 8866 |
表 4
Workers。 Workers 是一組伺服器,定期執行非同步工作。它們建構 trie 資料結構並儲存到 Trie DB 中。
Trie Cache。 Trie Cache 是一個分散式快取系統,將 trie 保存在記憶體中以便快速讀取。它每週對 DB 拍一次快照(snapshot)。
Trie DB。 Trie DB 是持久性儲存。有兩種儲存資料的選項:
- Document store:由於 trie 每週都會重建,我們可以定期對它拍快照、序列化,並將序列化後的資料儲存在資料庫中。像 MongoDB [4] 這樣的 document store 很適合儲存序列化資料。
- Key-value store:透過套用以下邏輯,trie 可以表示為 hash table 形式 [4]:
- Trie 中的每個 prefix 對應到 hash table 中的一個 key。
- 每個 trie 節點上的資料對應到 hash table 中的一個 value。
圖 10 顯示了 trie 與 hash table 之間的對應關係。

在圖 10 中,左邊每個 trie 節點對應到右邊的 <key, value> 對。如果你不清楚 key-value store 如何運作,請參考「Design a key-value store」章節。
Query service#
在高階設計中,查詢服務直接呼叫資料庫以抓取熱門 5 筆結果。圖 11 顯示了改良後的設計,因為先前的設計效率不彰。
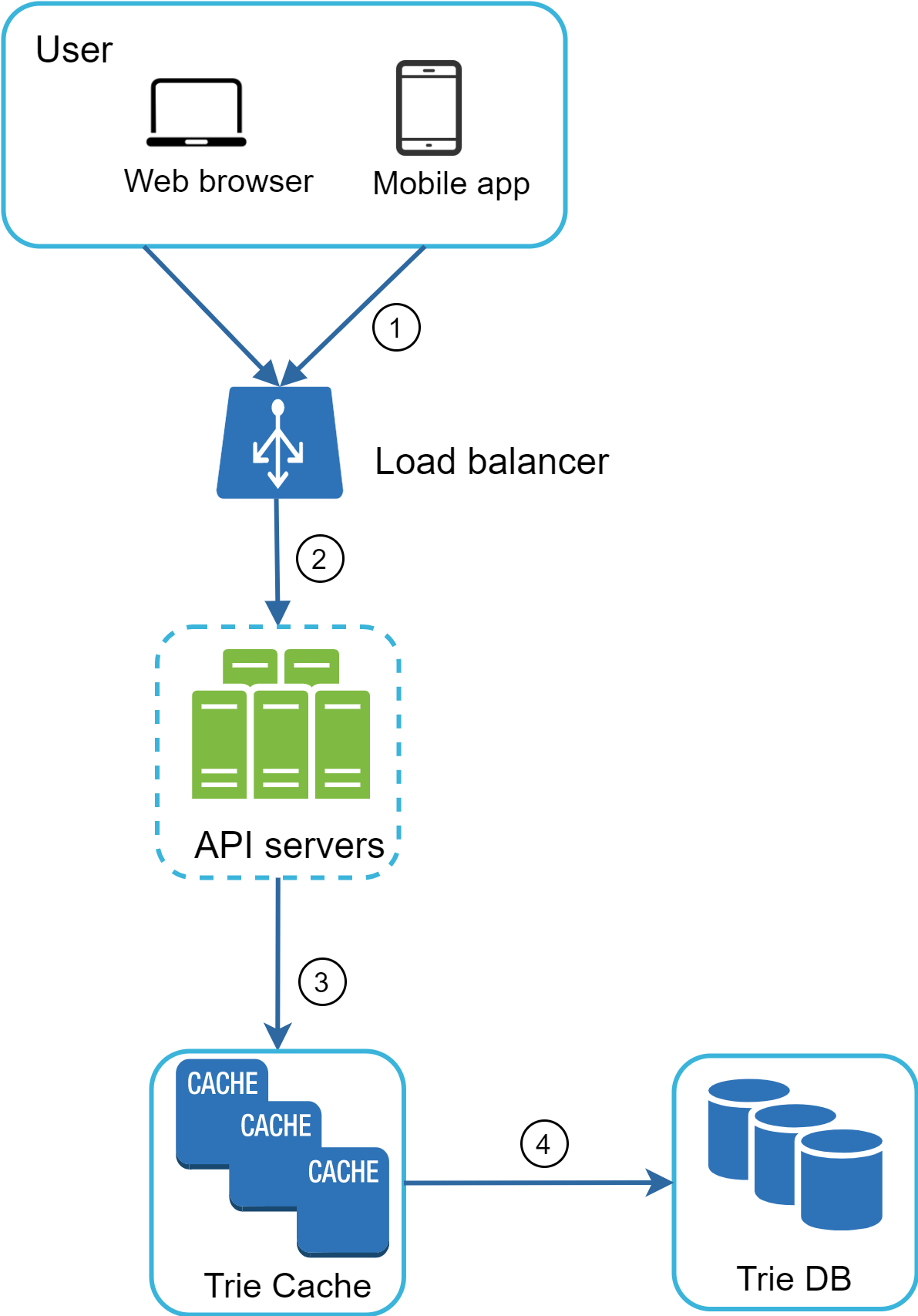
- 搜尋查詢被送到 load balancer。
- Load balancer 將請求路由到 API 伺服器。
- API 伺服器從 Trie Cache 取得 trie 資料,並為 client 建構自動完成建議。
- 若資料不在 Trie Cache 中,我們會把資料補回快取。這樣後續對相同 prefix 的請求都會從快取回傳。當快取伺服器記憶體不足或離線時,可能會發生 cache miss。
查詢服務需要極快的速度。我們提出以下最佳化:
AJAX 請求:對於 web 應用程式,瀏覽器通常會發送 AJAX 請求來抓取自動完成結果。AJAX 的主要好處是發送/接收 request/response 不會重新整理整個網頁。
瀏覽器快取:對於許多應用程式,自動完成搜尋建議在短時間內可能變化不大。因此,自動完成建議可以儲存在瀏覽器快取中,讓後續請求可以直接從快取取得結果。Google 搜尋引擎使用相同的快取機制。圖 12 顯示了當你在 Google 搜尋引擎輸入「system design interview」時的回應 header。如你所見,Google 在瀏覽器中將結果快取 1 小時。
cache-control 中的「private」表示結果是針對單一使用者的,不能被共用快取所快取。「max-age=3600」表示快取有效期為 3600 秒,亦即一小時。

- 資料抽樣:對於大規模系統,記錄每筆搜尋查詢需要大量處理能力與儲存空間。資料抽樣很重要。例如,系統每 N 個請求只記錄 1 個。
Trie operations#
Trie 是自動完成系統的核心元件。讓我們看看 trie 操作(建立、更新與刪除)是如何運作的。
Create#
Trie 由 workers 使用彙總資料建立。資料來源是 Analytics Log/DB。
Update#
有兩種方式可以更新 trie:
- 選項 1:每週更新 trie。一旦建立新的 trie,新的 trie 就會取代舊的。
- 選項 2:直接更新個別 trie 節點。我們盡量避免這個操作,因為它很慢。但如果 trie 的大小很小,這是個可接受的解決方案。當我們更新一個 trie 節點時,從它一路上溯到 root 的所有祖先節點都必須更新,因為祖先節點儲存了子節點的熱門查詢。圖 13 顯示了更新操作如何運作的例子。在左側,搜尋查詢「beer」原本的值是 10。在右側,它被更新為 30。如你所見,該節點與其祖先節點的「beer」值都被更新為 30。

Delete#
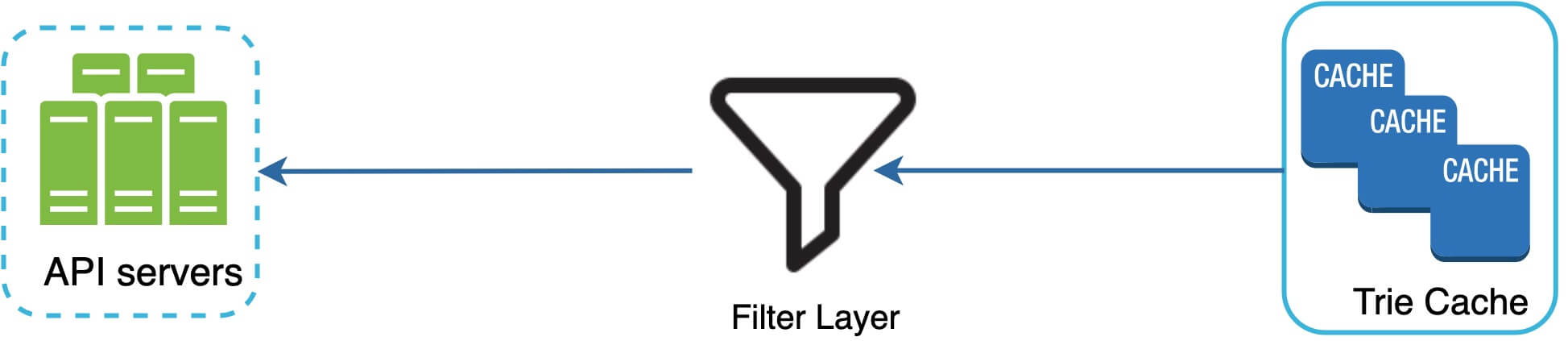
我們必須移除仇恨、暴力、性露骨或危險的自動完成建議。
我們在 Trie Cache 前面加上一個過濾層(圖 14)來過濾掉不想要的建議。擁有過濾層讓我們有彈性根據不同的過濾規則移除結果。不想要的建議會以非同步方式從資料庫實際移除,這樣下次更新週期就會使用正確的資料集來建構 trie。
Scale the storage#
既然我們已經發展出一個系統來向使用者提供自動完成查詢,現在該解決當 trie 變得太大而無法放進一台伺服器時的可擴展性問題。
由於只支援英文,一個天真的 sharding 方法是依照第一個字元。以下是一些範例:
- 如果我們需要兩台伺服器來儲存,可以將以「a」到「m」開頭的查詢儲存在第一台伺服器,「n」到「z」儲存在第二台。
- 如果我們需要三台伺服器,可以將查詢分為「a」到「i」、「j」到「r」與「s」到「z」。
依此邏輯,我們最多可以將查詢分成 26 台伺服器,因為英文有 26 個字母。讓我們將依第一個字元 sharding 定義為第一層 sharding。要儲存超過 26 台伺服器的資料,我們可以在第二層或甚至第三層 sharding。例如,以「a」開頭的查詢資料可以分到 4 台伺服器:「aa-ag」、「ah-an」、「ao-au」與「av-az」。
乍看之下這個方法似乎合理,直到你意識到「c」開頭的單字遠多於「x」開頭的單字,這會造成不平均的分布。
為了減輕資料失衡問題,我們會分析歷史資料分布模式,並套用更聰明的 sharding 邏輯,如圖 15 所示。Shard map manager 維護一個查找資料庫,用來識別資料列應該存到哪裡。例如,如果「s」與「u」、「v」、「w」、「x」、「y」與「z」合起來的歷史查詢數量相近,我們可以維護兩個 shard:一個給「s」,另一個給「u」到「z」。

Step 4 - Wrap up#
在你完成 deep dive 後,面試官可能會問你一些後續問題。
面試官:你會如何擴展你的設計以支援多語言?
要支援其他非英文查詢,我們在 trie 節點中儲存 Unicode 字元。如果你不熟悉 Unicode,這裡是它的定義:「一種編碼標準,涵蓋世界上所有書寫系統的所有字元,包括現代與古代」[5]。
面試官:如果某個國家的熱門搜尋查詢與其他國家不同呢?
在這種情況下,我們可能會為不同國家建立不同的 trie。為了改善回應時間,我們可以將 trie 儲存在 CDN 中。
面試官:我們要如何支援趨勢(即時)搜尋查詢?
假設一則新聞事件爆發,某個搜尋查詢突然變得熱門。我們原本的設計無法運作,因為:
- 離線 workers 還沒被排程更新 trie,因為它是按週排程執行。
- 即使有排程,建構 trie 也需要太長的時間。
建構即時搜尋自動完成很複雜,超出本課程的範圍,所以我們只給幾個想法:
- 透過 sharding 縮小工作資料集。
- 變更排名模型,給最近的搜尋查詢更多權重。
- 資料可能以串流(stream)形式進來,所以我們無法一次取得所有資料。串流資料表示資料持續產生。串流處理需要不同的系統:Apache Hadoop MapReduce [6]、Apache Spark Streaming [7]、Apache Storm [8]、Apache Kafka [9] 等。由於這些主題都需要特定領域知識,我們在這裡不深入細節。
恭喜你走到這裡!現在給自己一個鼓勵。做得好!