在網路系統中,速率限制器(rate limiter)用來控制由用戶端或服務所送出流量的速率。在 HTTP 的世界裡,速率限制器會限制用戶端在指定時間內可送出的請求數量。如果 API 請求數超過速率限制器所定義的閾值,所有超出的呼叫都會被阻擋。
以下是幾個範例:
- 一位使用者每秒最多只能發布 2 篇貼文。
- 從同一 IP 位址每天最多只能建立 10 個帳號。
- 從同一裝置每週最多只能領取 5 次獎勵。
在本章中,你的任務是設計一個速率限制器。在開始設計之前,我們先看看使用 API 速率限制器有哪些好處:
- 防止由阻斷服務(Denial of Service,DoS)攻擊造成的資源耗盡 [1]。幾乎所有大型科技公司發布的 API 都會強制執行某種形式的速率限制。例如,Twitter 將推文限制為每 3 小時 300 則 [2]。Google docs API 預設限制為:每位使用者每 60 秒最多 300 次讀取請求 [3]。速率限制器透過阻擋過量的呼叫,可防止有意或無意的 DoS 攻擊。
- 降低成本。限制過量請求意味著需要較少的伺服器,並可將更多資源分配給高優先順序的 API。對於使用付費第三方 API 的公司而言,速率限制極為重要。例如以下外部 API 都是按呼叫次數計費:信用查詢、付款處理、健康紀錄取得等。限制呼叫次數對於降低成本至關重要。
- 防止伺服器過載。為了降低伺服器負載,速率限制器可用來過濾由機器人或使用者不當行為造成的過量請求。
Step 1 - Understand the problem and establish design scope#
速率限制可以使用不同的演算法來實作,每種演算法各有優缺點。面試官與應徵者之間的互動有助於釐清我們要打造的速率限制器類型。
應徵者:我們要設計哪一種速率限制器?是用戶端速率限制器,還是伺服器端的 API 速率限制器?
面試官:好問題。我們聚焦在伺服器端的 API 速率限制器。
應徵者:速率限制器是基於 IP、使用者 ID 還是其他屬性來節流(throttle)API 請求?
面試官:速率限制器應該足夠彈性,能支援不同的節流規則組合。
應徵者:系統規模如何?是為新創公司打造,還是擁有龐大使用者基礎的大公司?
面試官:系統必須能處理大量請求。
應徵者:系統會在分散式環境中運作嗎?
面試官:是的。
應徵者:速率限制器是獨立服務,還是應該實作在應用程式碼中?
面試官:這是設計決定,由你決定。
應徵者:我們需要通知被節流的使用者嗎?
面試官:是的。
需求#
以下是系統需求的摘要:
- 準確地限制過量請求。
- 低延遲。速率限制器不應拖慢 HTTP 回應時間。
- 盡量使用最少的記憶體。
- 分散式速率限制。速率限制器可在多台伺服器或行程之間共享。
- 例外處理。當使用者的請求被節流時,向其顯示清楚的例外。
- 高容錯性。如果速率限制器發生任何問題(例如某台快取伺服器離線),不應影響整個系統。
Step 2 - Propose high-level design and get buy-in#
讓我們保持簡單,使用基本的用戶端與伺服器模型來進行通訊。
速率限制器要放在哪裡#
直覺上,你可以將速率限制器實作在用戶端或伺服器端。
- 用戶端實作。一般而言,用戶端是不可靠的位置,不適合執行速率限制,因為用戶端請求很容易被惡意行為者偽造。此外,我們可能無法控制用戶端的實作。
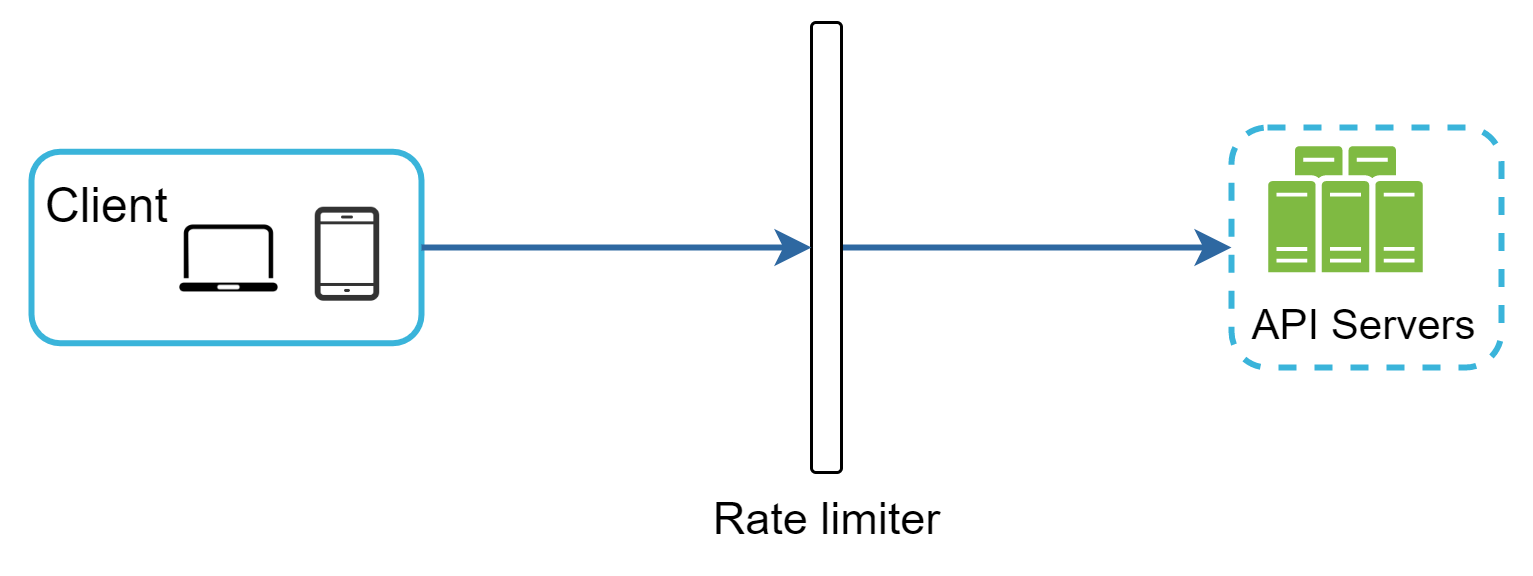
- 伺服器端實作。圖 1 顯示了一個放在伺服器端的速率限制器。

除了用戶端與伺服器端的實作之外,還有另一種方式。我們不將速率限制器放在 API 伺服器上,而是建立一個速率限制器中介層(middleware),用來節流送往 API 的請求,如圖 2 所示。
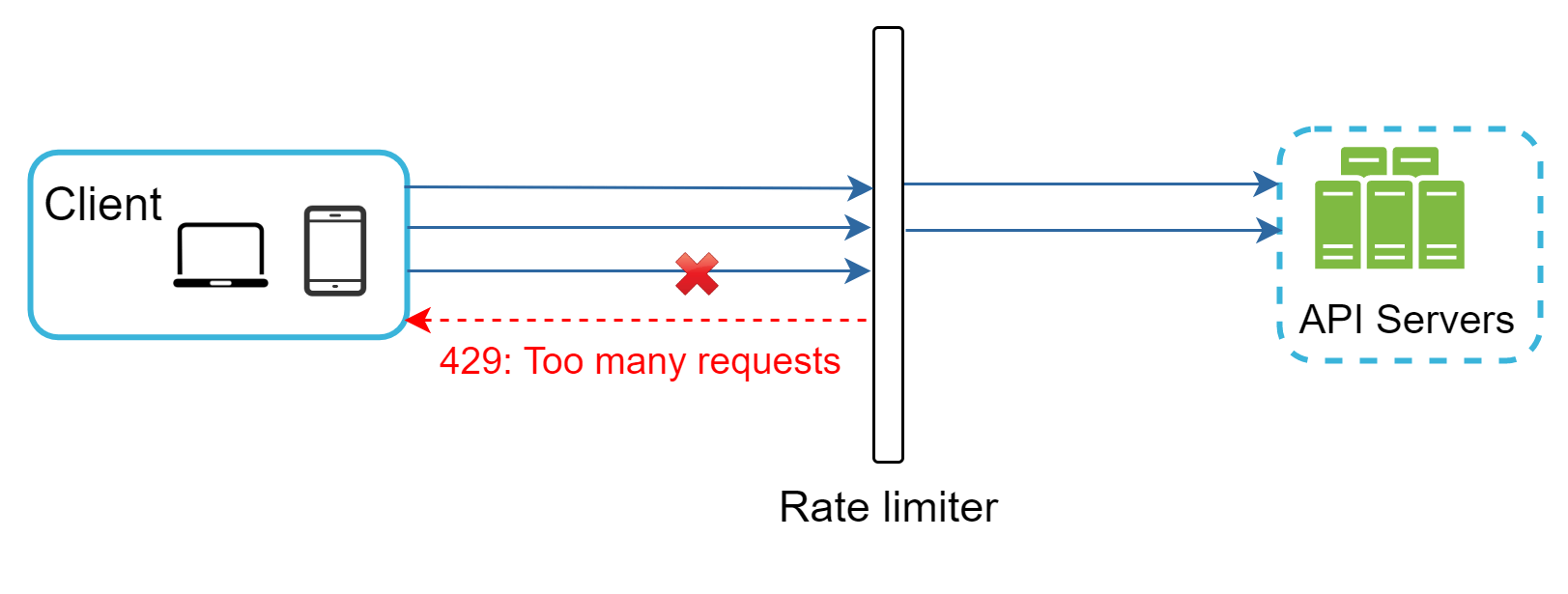
讓我們以圖 3 的範例說明此設計中速率限制如何運作。假設我們的 API 允許每秒 2 個請求,而某用戶端在一秒內向伺服器送出 3 個請求。前兩個請求會被路由到 API 伺服器,但速率限制器中介層會節流第三個請求並回傳 HTTP 狀態碼 429。HTTP 429 回應狀態碼表示使用者送出了過多請求。
雲端微服務(cloud microservices)[4] 已普遍流行,速率限制通常實作在稱為 API gateway 的元件中。API gateway 是一種完全託管的服務,支援速率限制、SSL 終止、認證、IP 白名單、提供靜態內容等。目前我們只需要知道 API gateway 是一個支援速率限制的中介層。
在設計速率限制器時,一個重要的問題是:速率限制器應該實作在伺服器端還是 gateway?沒有絕對的答案,這取決於你公司目前的技術堆疊、工程資源、優先順序、目標等。
以下是一些一般性的指引:
- 評估你目前的技術堆疊,例如程式語言、快取服務等。確保你目前的程式語言能有效率地在伺服器端實作速率限制。
- 找出符合你業務需求的速率限制演算法。當你在伺服器端實作所有東西時,你對演算法擁有完全的控制權。然而,如果你使用第三方 gateway,選擇可能會受到限制。
- 如果你已採用微服務架構,並在設計中加入了 API gateway 來執行認證、IP 白名單等功能,那麼你可以將速率限制器加到 API gateway 中。
- 自行打造速率限制服務需要時間。如果你沒有足夠的工程資源來實作速率限制器,使用商業 API gateway 是更好的選擇。
速率限制的演算法#
速率限制可以使用不同的演算法來實作,每種演算法都有其獨特的優缺點。雖然本章不聚焦於演算法,但在高層次理解這些演算法有助於選擇正確的演算法或組合來符合我們的使用情境。以下是常見演算法的清單:
- Token bucket
- Leaking bucket
- Fixed window counter
- Sliding window log
- Sliding window counter
Token bucket 演算法#
Token bucket 演算法被廣泛用於速率限制。它簡單、易於理解,並普遍被網路公司採用。Amazon [5] 與 Stripe [6] 都使用此演算法來節流其 API 請求。
Token bucket 演算法的運作方式如下:
- token bucket 是一個具有預先定義容量的容器。token 會以預設速率定期放入桶中。一旦桶滿,就不再加入更多 token。如圖 4 所示,token bucket 容量為 4,補充器每秒將 2 個 token 放入桶中。一旦桶滿,多餘的 token 將溢出。

- 每個請求消耗一個 token。當請求到達時,我們會檢查桶中是否有足夠的 token。圖 5 說明其運作方式。
- 如果有足夠的 token,我們為每個請求取出一個 token,請求得以通過。
- 如果沒有足夠的 token,請求會被丟棄。

圖 6 說明 token 消耗、補充與速率限制邏輯如何運作。在這個範例中,token bucket 大小為 4,補充速率為每分鐘 4 個。

Token bucket 演算法有兩個參數:
- Bucket size:桶中允許的最大 token 數。
- Refill rate:每秒放入桶中的 token 數。
我們需要多少個桶?這取決於速率限制規則,以下是幾個範例。
- 通常需要為不同的 API 端點設置不同的桶。例如,如果允許使用者每秒發布 1 篇貼文、每天加 150 位好友、每秒按讚 5 篇貼文,那麼每位使用者就需要 3 個桶。
- 如果我們需要根據 IP 位址來節流請求,每個 IP 位址都需要一個桶。
- 如果系統允許每秒最多 10,000 個請求,那麼設置一個由所有請求共享的全域桶就很合理。
優點:
- 演算法易於實作。
- 記憶體使用率高。
- Token bucket 允許短時間的突發流量。只要還有 token 剩下,請求就能通過。
缺點:
- 演算法中的兩個參數是 bucket size 與 token 補充速率,但要正確調整這兩個參數可能具有挑戰性。
Leaking bucket 演算法#
Leaking bucket 演算法類似於 token bucket,差別在於請求是以固定速率被處理的。它通常使用先進先出(first-in-first-out,FIFO)佇列來實作。演算法運作方式如下:
- 當請求到達時,系統會檢查佇列是否已滿。如果未滿,請求就會被加入佇列。
- 否則,請求會被丟棄。
- 請求會以固定間隔從佇列中取出並處理。
圖 7 說明此演算法如何運作。

Leaking bucket 演算法有以下兩個參數:
- Bucket size:等於佇列大小。佇列保存將以固定速率處理的請求。
- Outflow rate:定義每單位時間(通常以秒為單位)可以以固定速率處理的請求數量。
電子商務公司 Shopify 使用 leaky bucket 來進行速率限制 [7]。
優點:
- 由於佇列大小有限,記憶體使用率高。
- 請求以固定速率被處理,因此適合需要穩定流出速率的使用情境。
缺點:
- 突發流量會以舊請求填滿佇列,如果這些請求未及時處理,新近的請求就會被速率限制。
- 演算法中有兩個參數,要正確調整可能不容易。
Fixed window counter 演算法#
Fixed window counter 演算法的運作方式如下:
- 演算法將時間軸劃分為固定大小的時間視窗,並為每個視窗指派一個計數器。
- 每個請求使計數器加 1。
- 一旦計數器達到預先定義的閾值,新的請求就會被丟棄,直到新的時間視窗開始。
讓我們用一個具體的例子來看看它如何運作。在圖 8 中,時間單位為 1 秒,系統允許每秒最多 3 個請求。在每個 1 秒視窗中,如果接收到超過 3 個請求,多餘的請求就會被丟棄,如圖 8 所示。

此演算法的主要問題是,在時間視窗邊緣的突發流量可能會導致超過配額的請求通過。
考慮以下情況:

在圖 9 中,系統允許每分鐘最多 5 個請求,可用配額會在整分時重設。如圖所示,2:00:00 與 2:01:00 之間有五個請求,2:01:00 與 2:02:00 之間又有五個請求。對於 2:00:30 到 2:01:30 之間的一分鐘視窗,總共有 10 個請求通過,是允許請求數的兩倍。
優點:
- 記憶體使用率高。
- 易於理解。
- 在單位時間視窗結束時重設可用配額,符合某些使用情境。
缺點:
- 視窗邊緣的流量尖峰可能會導致超過配額的請求通過。
Sliding window log 演算法#
如先前所討論,fixed window counter 演算法有一個主要問題:它允許在視窗邊緣有更多請求通過。Sliding window log 演算法解決了這個問題。它的運作方式如下:
- 演算法會追蹤請求的時間戳記。時間戳記資料通常保存在快取中,例如 Redis 的 sorted set [8]。
- 當新請求進來時,移除所有過期的時間戳記。過期時間戳記定義為早於目前時間視窗起點的時間戳記。
- 將新請求的時間戳記加入記錄。
- 如果記錄大小等於或低於允許數量,則接受請求;否則拒絕請求。
我們以圖 10 中的範例來說明演算法。

在這個範例中,速率限制器允許每分鐘 2 個請求。通常記錄中儲存的是 Linux 時間戳記,但我們的範例為了可讀性使用人類可讀的時間表示。
- 當新請求在 1:00:01 到達時,記錄是空的,因此請求被允許。
- 新請求在 1:00:30 到達,時間戳記 1:00:30 被插入記錄。插入後記錄大小為 2,未超過允許數量,因此請求被允許。
- 新請求在 1:00:50 到達,時間戳記被插入記錄。插入後記錄大小為 3,大於允許大小 2,因此此請求被拒絕,雖然時間戳記仍保留在記錄中。
- 新請求在 1:01:40 到達。位於 [1:00:40, 1:01:40) 範圍的請求屬於最新時間區間,但 1:00:40 之前送出的請求已過期。兩個過期時間戳記 1:00:01 與 1:00:30 從記錄中被移除。移除操作後記錄大小變為 2,因此請求被接受。
優點:
- 由此演算法實作的速率限制非常準確。在任何滑動視窗中,請求都不會超過速率限制。
缺點:
- 演算法消耗大量記憶體,因為即使請求被拒絕,其時間戳記仍可能保留在記憶體中。
Sliding window counter 演算法#
Sliding window counter 演算法是一種混合方法,結合了 fixed window counter 與 sliding window log。此演算法可以用兩種不同的方式實作。我們將在本節說明其中一種實作,並在本節結尾提供另一種實作的參考。圖 11 說明此演算法如何運作。

假設速率限制器允許每分鐘最多 7 個請求,前一分鐘有 5 個請求,目前一分鐘有 3 個請求。對於到達目前分鐘 30% 位置的新請求,滑動視窗中的請求數量使用以下公式計算:
- 目前視窗中的請求數 + 前一視窗中的請求數 * 滑動視窗與前一視窗的重疊百分比
- 使用此公式,我們得到 3 + 5 * 0.7% = 6.5 個請求。根據使用情境,這個數字可以向上或向下取整。在我們的範例中,向下取整為 6。
由於速率限制器允許每分鐘最多 7 個請求,因此目前的請求可以通過。然而,再收到一個請求後就會達到上限。
由於篇幅限制,我們不在此討論另一種實作。有興趣的讀者請參考參考資料 [9]。此演算法並不完美,它有其優缺點。
優點
- 它平滑了流量尖峰,因為速率是基於前一視窗的平均速率。
- 記憶體使用率高。
缺點
- 它只適用於不太嚴格的回看視窗。它是實際速率的近似值,因為它假設前一視窗中的請求是均勻分布的。然而,這個問題可能沒有看起來那麼糟。根據 Cloudflare [10] 所做的實驗,在 4 億個請求中,只有 0.003% 的請求被錯誤地允許或被速率限制。
高階架構#
速率限制演算法的基本概念很簡單。在高層次上,我們需要一個計數器來追蹤從同一位使用者、IP 位址等送出多少個請求。如果計數器大於上限,就拒絕請求。
我們應該將計數器存放在哪裡?由於磁碟存取速度慢,使用資料庫不是好主意。記憶體快取被選為儲存位置,因為它速度快且支援基於時間的過期策略。
例如,Redis [11] 是實作速率限制的熱門選項。它是一個記憶體儲存系統,提供兩個指令:INCR 與 EXPIRE。
- INCR:將儲存的計數器加 1。
- EXPIRE:為計數器設定逾時。如果逾時到期,計數器會被自動刪除。
圖 12 顯示速率限制的高階架構,其運作方式如下:
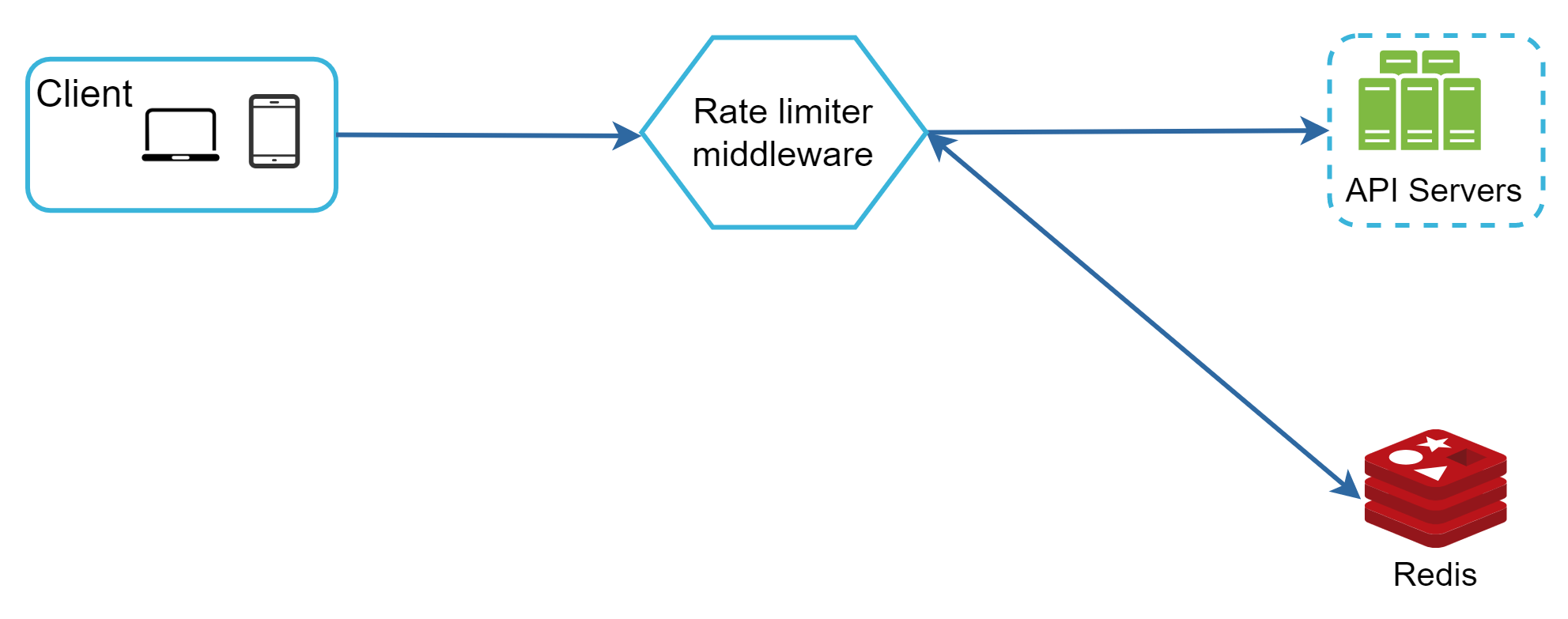
- 用戶端送出請求至速率限制中介層。
- 速率限制中介層從 Redis 中對應的桶取得計數器,並檢查是否已達上限。
- 如果已達上限,請求被拒絕。
- 如果未達上限,請求被送至 API 伺服器。同時,系統將計數器加 1 並存回 Redis。
Step 3 - Design deep dive#
圖 12 的高階設計並未回答以下問題:
- 速率限制規則如何建立?規則存放在哪裡?
- 如何處理被速率限制的請求?
在本節中,我們將先回答關於速率限制規則的問題,再討論處理被速率限制請求的策略。最後,我們會討論分散式環境中的速率限制、詳細設計、效能最佳化與監控。
速率限制規則#
Lyft 開源了他們的速率限制元件 [12]。我們將窺探該元件並查看一些速率限制規則的範例:
domain: messaging
descriptors:
- key: message_type
value: marketing
rate_limit:
unit: day
requests_per_unit: 5在以上範例中,系統被設定為每天最多允許 5 則行銷訊息。以下是另一個範例:
domain: auth
descriptors:
- key: auth_type
value: login
rate_limit:
unit: minute
requests_per_unit: 5此規則顯示用戶端每分鐘登入不能超過 5 次。規則通常寫在組態檔中並儲存於磁碟上。
超過速率上限#
當請求被速率限制時,API 會回傳 HTTP 回應碼 429(too many requests)給用戶端。視情況而定,我們可能會將被速率限制的請求加入佇列,稍後再處理。例如,如果某些訂單因系統過載而被速率限制,我們可以保留這些訂單稍後再處理。
速率限制器標頭#
用戶端如何知道自己是否被節流?以及用戶端如何知道在被節流之前還剩下多少個允許的請求?答案在於 HTTP 回應標頭。速率限制器會回傳以下 HTTP 標頭給用戶端:
X-Ratelimit-Remaining: The remaining number of allowed requests within the window.
X-Ratelimit-Limit: It indicates how many calls the client can make per time window.
X-Ratelimit-Retry-After: The number of seconds to wait until you can make a request again without being throttled.當使用者送出過多請求時,會回傳 429 too many requests 錯誤與 X-Ratelimit-Retry-After 標頭給用戶端。
詳細設計#
圖 13 呈現系統的詳細設計。
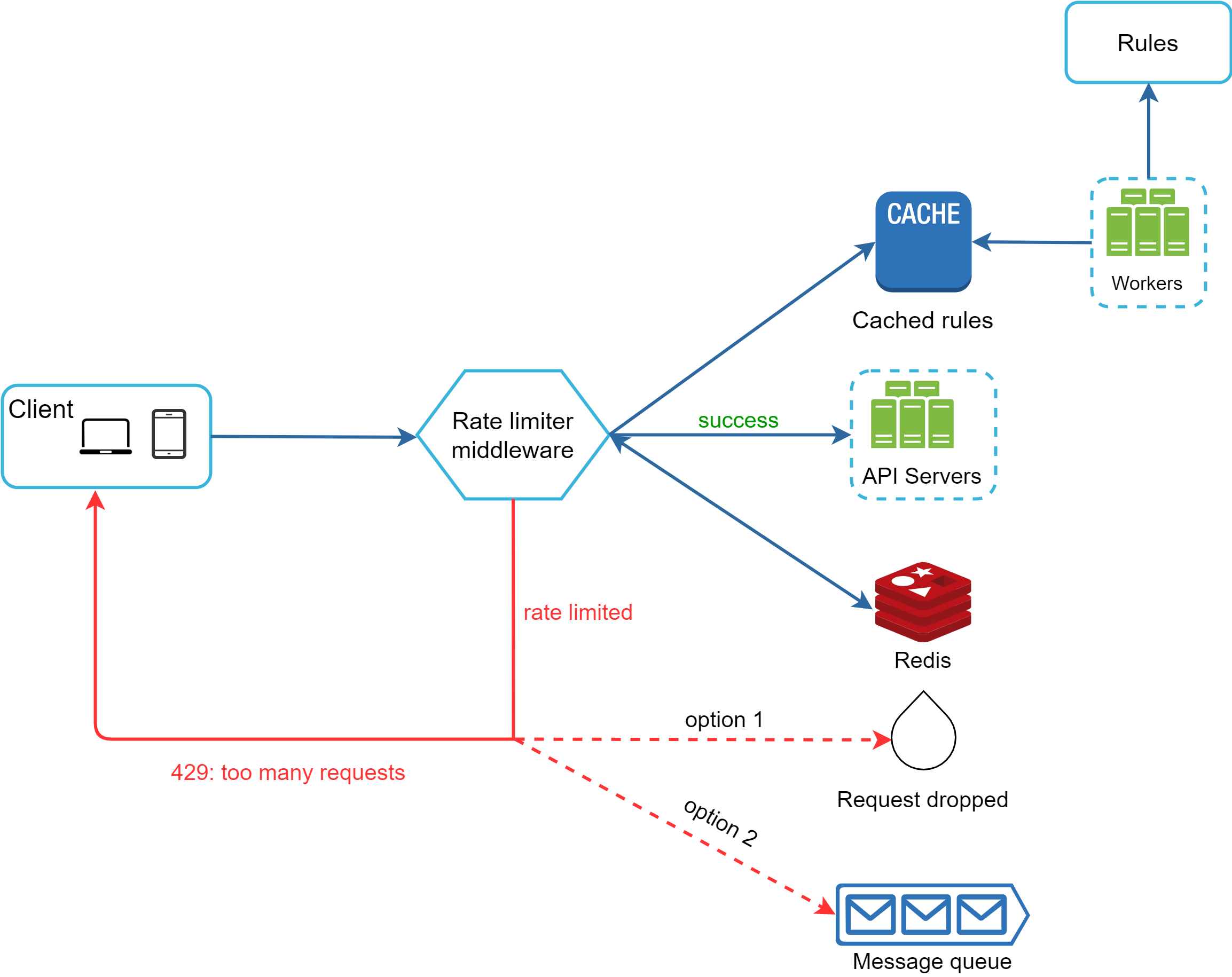
- 規則儲存在磁碟上。Worker 會頻繁地從磁碟拉取規則並儲存到快取中。
- 當用戶端送出請求至伺服器時,請求會先被送到速率限制器中介層。
- 速率限制器中介層從快取載入規則,並從 Redis 快取取得計數器與最近一次請求的時間戳記。根據回應,速率限制器決定:
- 如果請求未被速率限制,就轉發到 API 伺服器。
- 如果請求被速率限制,速率限制器會回傳 429 too many requests 錯誤給用戶端。同時,請求會被丟棄或轉發到佇列。
分散式環境中的速率限制器#
在單一伺服器環境中建立速率限制器並不困難,但要將系統擴展為支援多台伺服器與並行執行緒卻是另一回事。有兩個挑戰:
- 競爭條件(race condition)
- 同步問題
競爭條件#
如先前所討論,速率限制器在高層次上的運作方式如下:
- 從 Redis 讀取 counter 值。
- 檢查 (counter + 1) 是否超過閾值。
- 如果未超過,將 Redis 中的 counter 值加 1。
在高度並行的環境中可能發生競爭條件,如圖 14 所示。

假設 Redis 中的 counter 值為 3。如果兩個請求並行讀取 counter 值之後再回寫值,每個都會將 counter 加 1 並寫回,沒有檢查另一個執行緒。兩個請求(執行緒)都認為自己取得了正確的 counter 值 4。然而,正確的 counter 值應為 5。
鎖(Lock)是解決競爭條件最直接的方式。然而,鎖會大幅拖慢系統速度。常用兩種策略來解決此問題:Lua script [13] 與 Redis 的 sorted set 資料結構 [8]。對這些策略有興趣的讀者,請參考對應的參考資料 [8] [13]。
同步問題#
同步是分散式環境中另一個重要的考量因素。為了支援數百萬使用者,單一速率限制器伺服器可能無法處理流量。當使用多台速率限制器伺服器時,就需要同步。
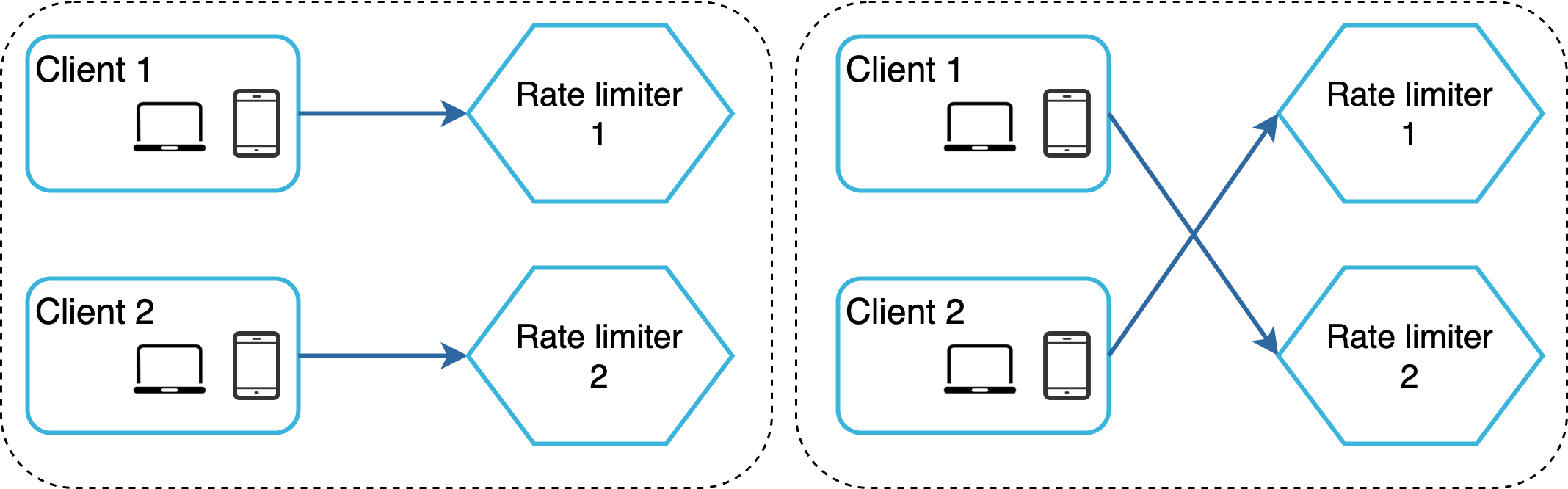
例如,在圖 15 左側,client 1 將請求送到 rate limiter 1,client 2 將請求送到 rate limiter 2。由於 web 層是無狀態的,用戶端可能將請求送到不同的速率限制器,如圖 15 右側所示。如果沒有同步發生,rate limiter 1 不會包含任何 client 2 的資料,因此速率限制器無法正常運作。
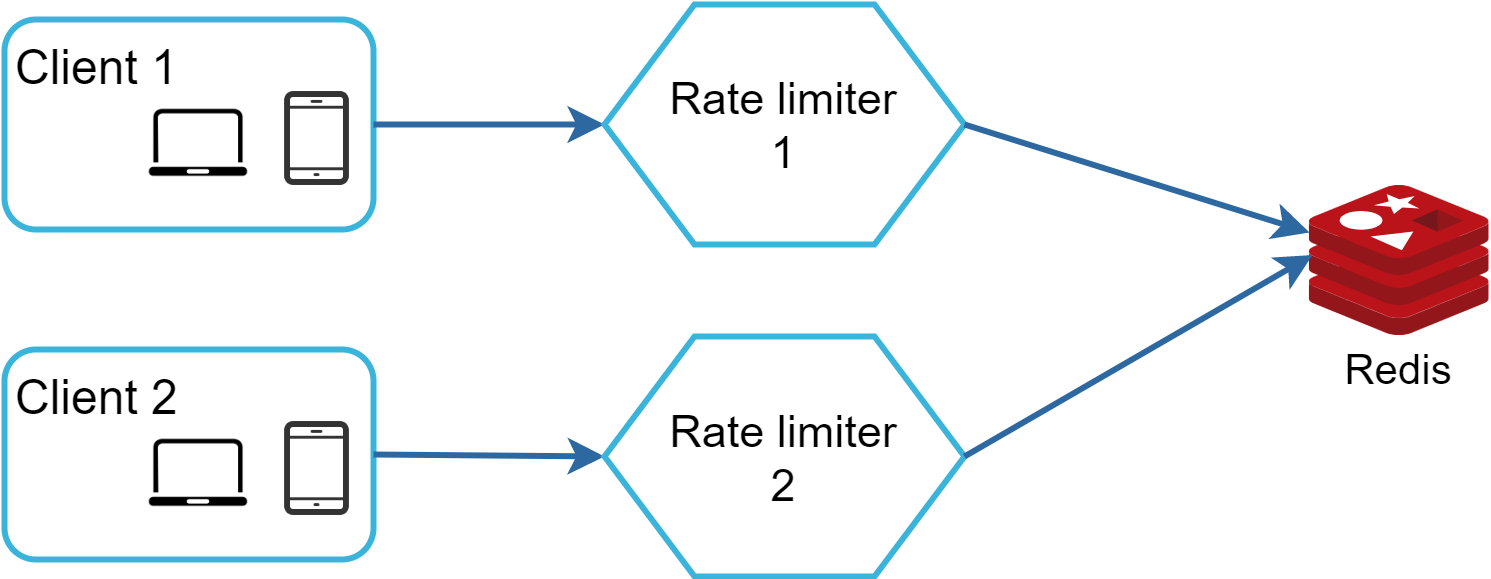
一個可能的解決方案是使用 sticky session,允許用戶端將流量送到同一個速率限制器。但這個解決方案不可取,因為它既不可擴展也不靈活。較好的方法是使用集中式資料儲存如 Redis。設計如圖 16 所示。
效能最佳化#
效能最佳化是系統設計面試中常見的主題。我們將涵蓋兩個改進的領域。
首先,多資料中心設定對速率限制器至關重要,因為對於遠離資料中心的使用者而言,延遲很高。大多數雲服務供應商在世界各地建立了許多邊緣伺服器位置。例如,截至 2020 年 5 月 20 日,Cloudflare 擁有 194 個地理分散的邊緣伺服器 [14]。流量會自動路由到最近的邊緣伺服器以降低延遲。
![Figure 17 (Source: [10])](figure-4-17-AWRJL2OI.png)
其次,使用**最終一致性(eventual consistency)**模型來同步資料。如果你不熟悉最終一致性模型,請參考「Design a Key-value Store」章節中的「Consistency」一節。
監控#
速率限制器上線後,收集分析資料以檢查速率限制器是否有效非常重要。我們主要要確保:
- 速率限制演算法有效。
- 速率限制規則有效。
例如,如果速率限制規則太嚴格,許多有效請求會被丟棄。在這種情況下,我們會想稍微放寬規則。在另一個範例中,我們注意到當有像快閃特賣那樣的突發流量時,速率限制器會變得無效。在這種情況下,我們可能會替換演算法以支援突發流量。Token bucket 在這裡很適合。
Step 4 - Wrap up#
在本章中,我們討論了速率限制的不同演算法及其優缺點。討論的演算法包括:
- Token bucket
- Leaking bucket
- Fixed window
- Sliding window log
- Sliding window counter
接著,我們討論了系統架構、分散式環境中的速率限制器、效能最佳化與監控。與任何系統設計面試問題一樣,如果時間允許,還有一些額外的討論點:
- 硬性 vs 軟性速率限制。
- 硬性:請求數不能超過閾值。
- 軟性:請求可以在短時間內超過閾值。
- 不同層級的速率限制。在本章中,我們只討論了應用層的速率限制(HTTP:第 7 層)。也可以在其他層套用速率限制。例如,你可以使用 Iptables [15] 根據 IP 位址套用速率限制(IP:第 3 層)。註:開放系統互連模型(Open Systems Interconnection model,OSI model)有 7 層 [16]:第 1 層:實體層、第 2 層:資料連結層、第 3 層:網路層、第 4 層:傳輸層、第 5 層:會議層、第 6 層:表現層、第 7 層:應用層。
- 避免被速率限制。設計用戶端時遵循以下最佳實務:
- 使用用戶端快取以避免頻繁地呼叫 API。
- 了解上限,不要在短時間內送出過多請求。
- 包含程式碼來捕捉例外或錯誤,讓你的用戶端可以從例外中優雅地復原。
- 在重試邏輯中加入足夠的退避時間。
恭喜你看到這裡!現在給自己拍拍背,做得好!