設計一個能支援數百萬使用者的系統極具挑戰性,是一段需要不斷打磨、永無止境的旅程。在本章中,我們會從一個只服務單一使用者的系統開始,逐步把它擴展到能服務數百萬使用者。讀完本章後,你將掌握一系列有助於攻克系統設計面試題的技巧。
單一伺服器架構#
千里之行始於足下,建構複雜系統也是同樣道理。為了從簡單的東西開始,所有元件都跑在同一台伺服器上。圖 1 顯示了單一伺服器架構,所有東西——Web App、資料庫、快取等——都在同一台機器上執行。
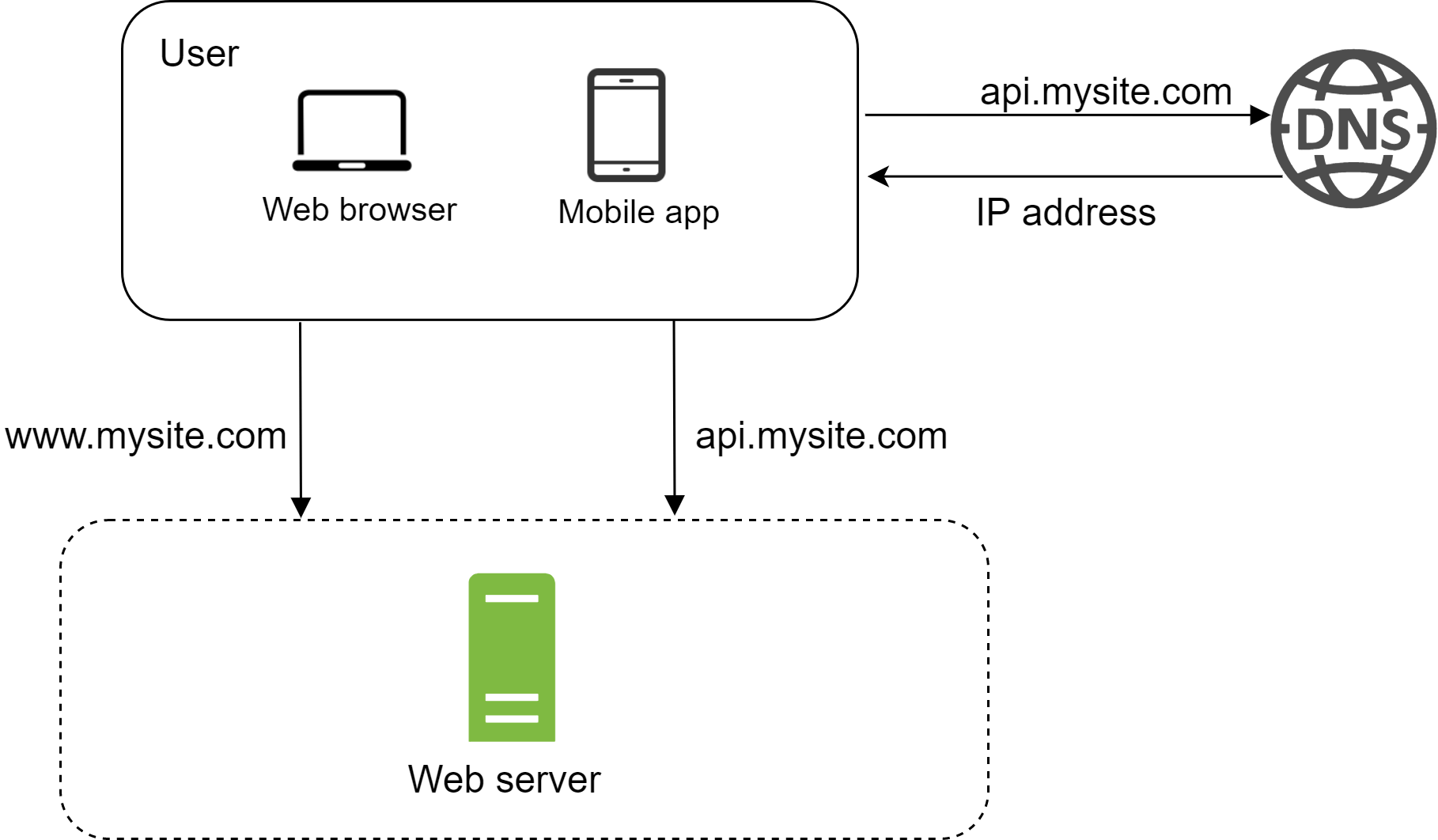
要理解這個架構,從請求流程與流量來源切入會很有幫助。我們先看請求流程(圖 2)。
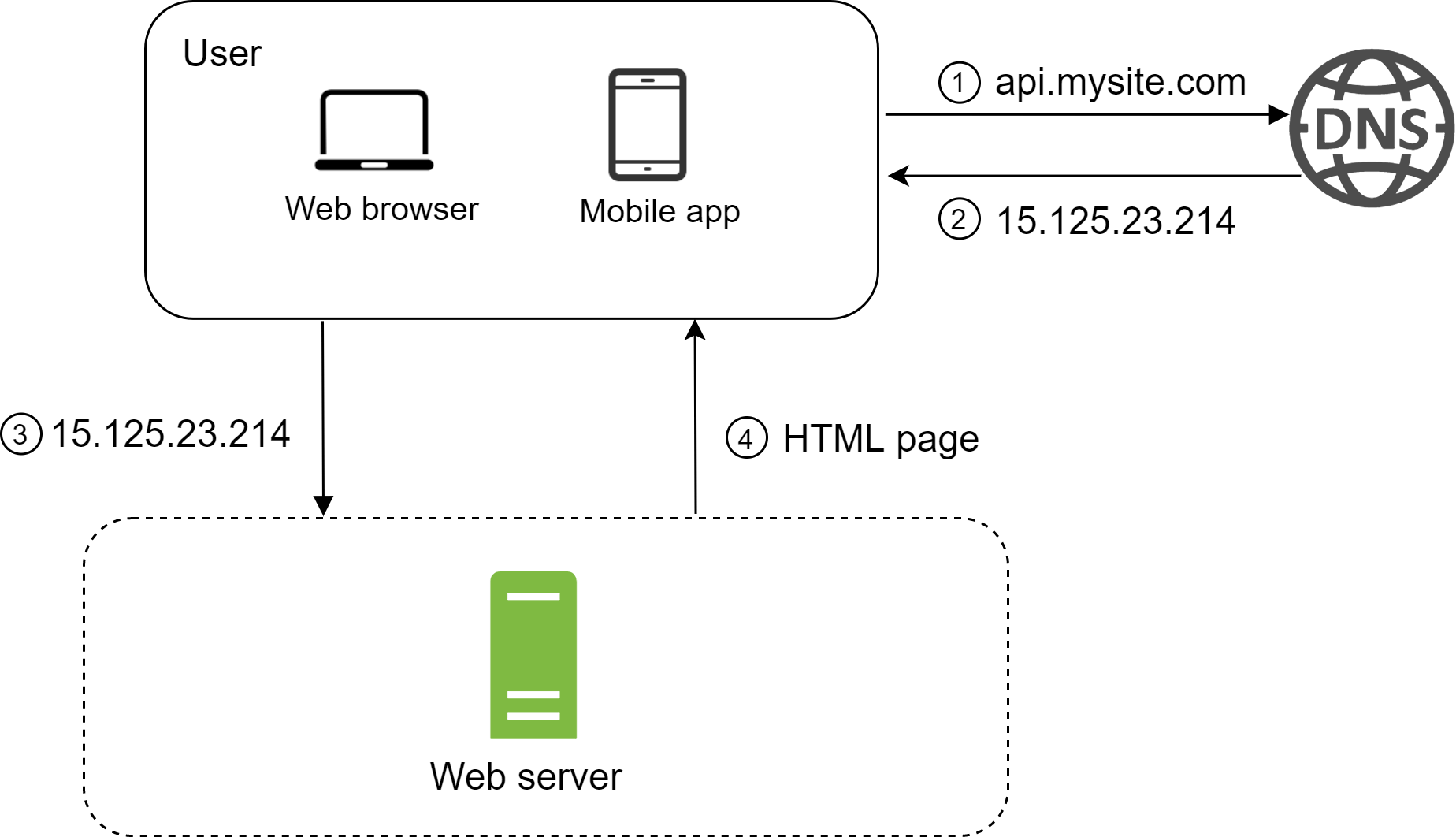
- 使用者透過網域名稱(例如 api.mysite.com)連上網站。網域名稱系統(Domain Name System, DNS)通常是由第三方提供的付費服務,並非由我們自己的伺服器代管。
- 瀏覽器或行動應用程式會收到 IP(Internet Protocol)位址。在這個範例中,回傳的 IP 位址是 15.125.23.214。
- 取得 IP 位址後,HTTP(Hypertext Transfer Protocol)[1] 請求會直接送到 Web 伺服器。
- Web 伺服器回傳 HTML 頁面或 JSON 回應供前端渲染。
接著我們來看流量來源。Web 伺服器的流量主要來自兩類:Web 應用與行動應用。
- Web 應用:使用伺服器端語言(Java、Python 等)處理商業邏輯與儲存,並使用前端語言(HTML 與 JavaScript)負責畫面呈現。
- 行動應用:HTTP 是行動 App 與 Web 伺服器之間的通訊協定。由於 JSON(JavaScript Object Notation)格式簡潔,常被用來作為 API 回應的資料格式。以下是 JSON 格式的 API 回應範例:
GET /users/12 — 取得 id = 12 的使用者物件
{
"id": 12,
"firstName": "John",
"lastName": "Smith",
"address": {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": 10021
},
"phoneNumbers": ["212 555-1234", "646 555-4567"]
}資料庫#
隨著使用者數成長,一台伺服器已不敷使用,我們需要多台機器:一台處理 Web/Mobile 流量,另一台跑資料庫(圖 3)。把 Web/Mobile 流量伺服器(Web 層)與資料庫(資料層)分離,可以讓兩者各自獨立擴展。
該選哪種資料庫?#
你可以選擇傳統的關聯式資料庫,或是非關聯式資料庫。我們來比較它們的差異。
關聯式資料庫又稱為關聯式資料庫管理系統(Relational Database Management System, RDBMS)或 SQL 資料庫。最熱門的有 MySQL、Oracle、PostgreSQL 等。關聯式資料庫以資料表(table)與資料列(row)來表示與儲存資料,你可以透過 SQL 在不同資料表之間執行 join 操作。
非關聯式資料庫又稱為 NoSQL 資料庫。常見的有 CouchDB、Neo4j、Cassandra、HBase、Amazon DynamoDB 等 [2]。它們大致分為四類:
- 鍵值儲存(key-value store)
- 圖形儲存(graph store)
- 欄式儲存(column store)
- 文件儲存(document store)
NoSQL 通常不支援 join 操作。
對大多數開發者而言,關聯式資料庫是首選,因為它已經發展了超過 40 年,歷來表現都很穩定。然而,如果關聯式資料庫不適合你的特定場景,那就有必要往外探索。在以下情境下,NoSQL 可能更合適:
- 應用要求極低的延遲。
- 資料是非結構化的,或不存在關聯。
- 你只需要序列化與反序列化資料(JSON、XML、YAML 等)。
- 你需要儲存海量資料。
垂直擴展與水平擴展#
垂直擴展(Vertical scaling),又稱為「scale up」,是指為伺服器增加更多資源(CPU、RAM 等)。水平擴展(Horizontal scaling),又稱為「scale-out」,則是透過增加伺服器數量來擴展系統。
當流量還小時,垂直擴展是個不錯的選擇,主要優點是簡單。但它也有嚴重的限制:
- 垂直擴展有硬性上限。一台伺服器無法無限制地增加 CPU 與記憶體。
- 垂直擴展沒有故障轉移(failover)與備援。一旦那台伺服器掛了,整個網站/App 就跟著掛掉。
由於垂直擴展的限制,水平擴展對大規模應用更為理想。
在前面的設計裡,使用者直接連到 Web 伺服器。一旦 Web 伺服器離線,使用者就無法存取網站;另一種情境是,當大量使用者同時連線而超出 Web 伺服器負載上限時,使用者通常會體驗到回應變慢甚至無法連線。要解決這些問題,最佳手段是引入負載平衡器(Load Balancer)。
負載平衡器#
負載平衡器會把進來的流量平均分配到一組事先定義好的 Web 伺服器之間。圖 4 顯示了負載平衡器的工作方式。
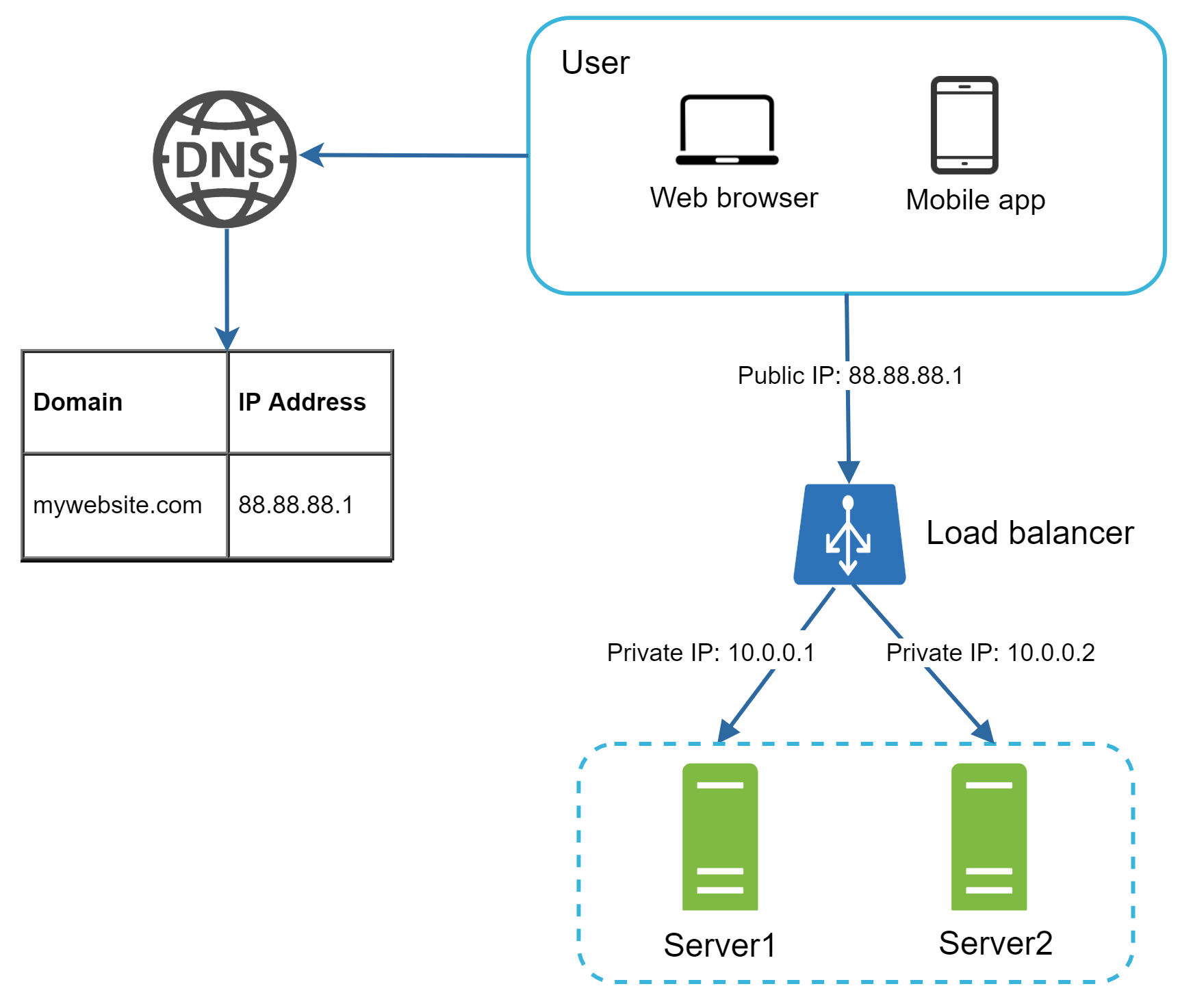
如圖 4 所示,使用者會直接連到 Load Balancer 的公開 IP,這樣一來客戶端就無法直接存取後端 Web 伺服器了。為了強化安全,伺服器之間使用私有 IP(private IP) 通訊。私有 IP 只能在同一個網路內的伺服器之間互相連線,而無法從公網存取。Load Balancer 透過私有 IP 與 Web 伺服器溝通。
在圖 4 中,加入 Load Balancer 與第二台 Web 伺服器後,我們成功解決了「沒有故障轉移」的問題,也提升了 Web 層的可用性。細節如下:
- 如果伺服器 1 離線,所有流量會被導向伺服器 2,網站不會跟著掛掉。我們也會把一台新的健康伺服器加入伺服器池,以分擔負載。
- 如果流量爆增、兩台伺服器不夠用,Load Balancer 也能優雅地處理這個情況。你只需要把更多伺服器加進池子,Load Balancer 會自動開始把請求送過去。
現在 Web 層看起來不錯了,那資料層呢?目前的設計只有一台資料庫,無法做故障轉移與備援。資料庫複寫(Database Replication) 是處理這個問題的常見手法,我們來看看。
資料庫複寫#
引述維基百科:「資料庫複寫可被應用在許多資料庫管理系統中,通常以主從(master/slave)關係建立在原資料庫(master)與其副本(slave)之間」[3]。
主資料庫一般只負責寫入操作;從資料庫則接收主資料庫的資料副本,只負責讀取。所有會修改資料的指令(如 insert、delete、update)都必須送到主資料庫。大多數應用的讀取量遠高於寫入量,因此系統中從資料庫的數量通常比主資料庫多。圖 5 顯示了一個主資料庫帶多個從資料庫的架構。

資料庫複寫的優點:
- 效能更佳:在主從模型中,所有寫入與更新都發生在 master,而讀取則分散到各個 slave。這種模型可以平行處理更多查詢,因此效能更好。
- 可靠性:若其中一台資料庫伺服器毀於天災(颱風、地震等),資料仍然會被保留下來。由於資料已被複寫到多個地點,你不用擔心資料遺失。
- 高可用性:透過跨地點複寫資料,即使某台資料庫離線,你的網站仍然可以從其他資料庫伺服器存取資料而不中斷。
前面我們討論了 Load Balancer 如何提升系統可用性。同樣的問題也可以問:要是有一台資料庫離線怎麼辦?圖 5 中討論的架構可以處理這個情況:
- 如果只有一台 slave 而它剛好離線,讀取會暫時被導向 master;一旦發現問題,新的 slave 就會頂上去。如果有多台 slave,讀取會被導向其他健康的 slave,新的伺服器會替換掉故障的那台。
- 如果 master 離線,會由一台 slave 被升為新的 master,所有資料庫操作會暫時在新 master 上執行;同時會立刻安排一台新的 slave 來接續資料複寫。在實際生產環境中,把一台 slave 升為 master 比較複雜,因為 slave 上的資料未必是最新的,缺失的資料需要靠資料修復腳本補回來。雖然像 multi-master 與 circular replication 這類複寫方式也能幫忙,但它們的設定更為複雜,超出本書討論範圍。有興趣的讀者可參考延伸閱讀資料 [4] [5]。
圖 6 展示了加入 Load Balancer 與資料庫複寫後的系統設計。
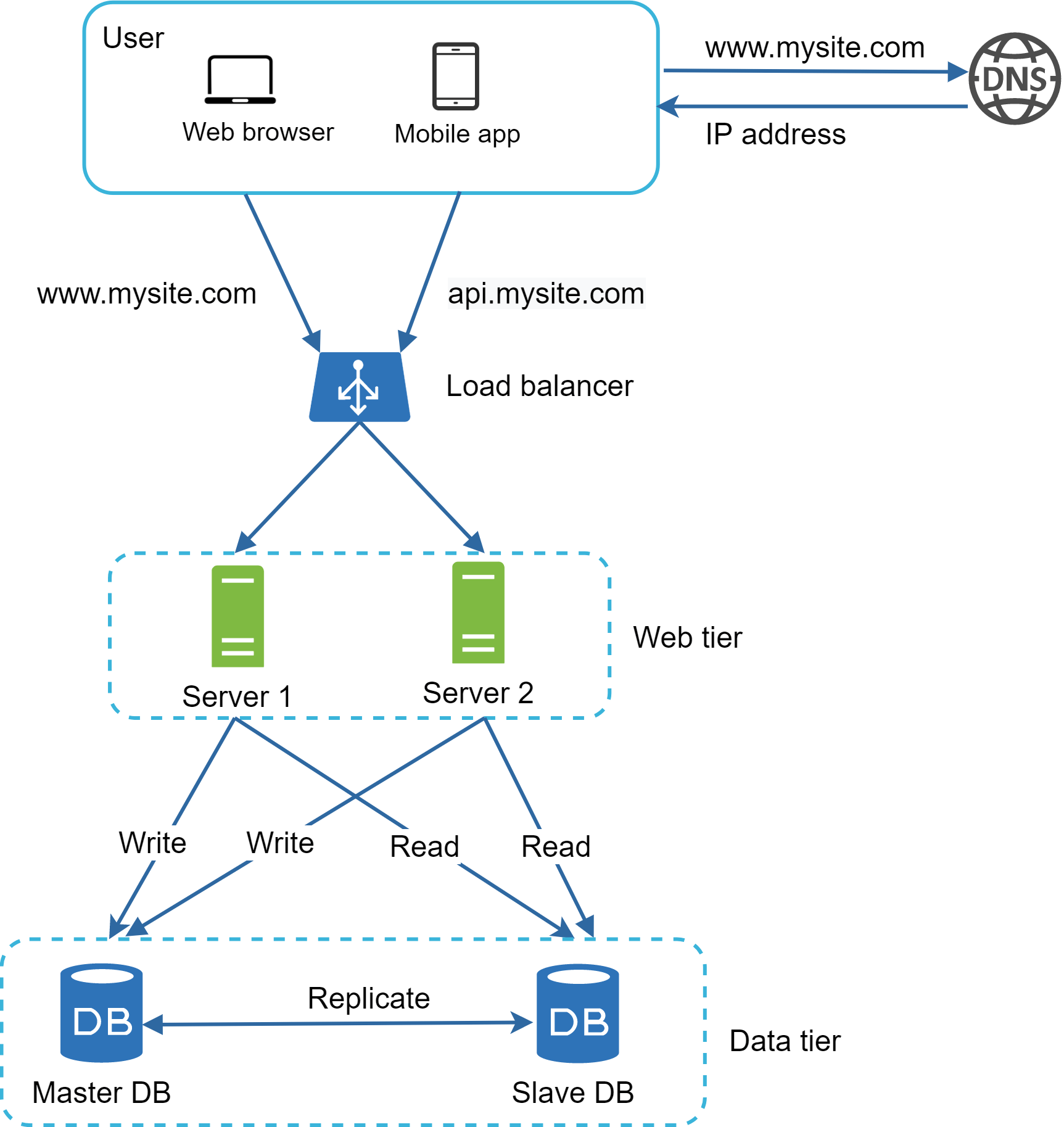
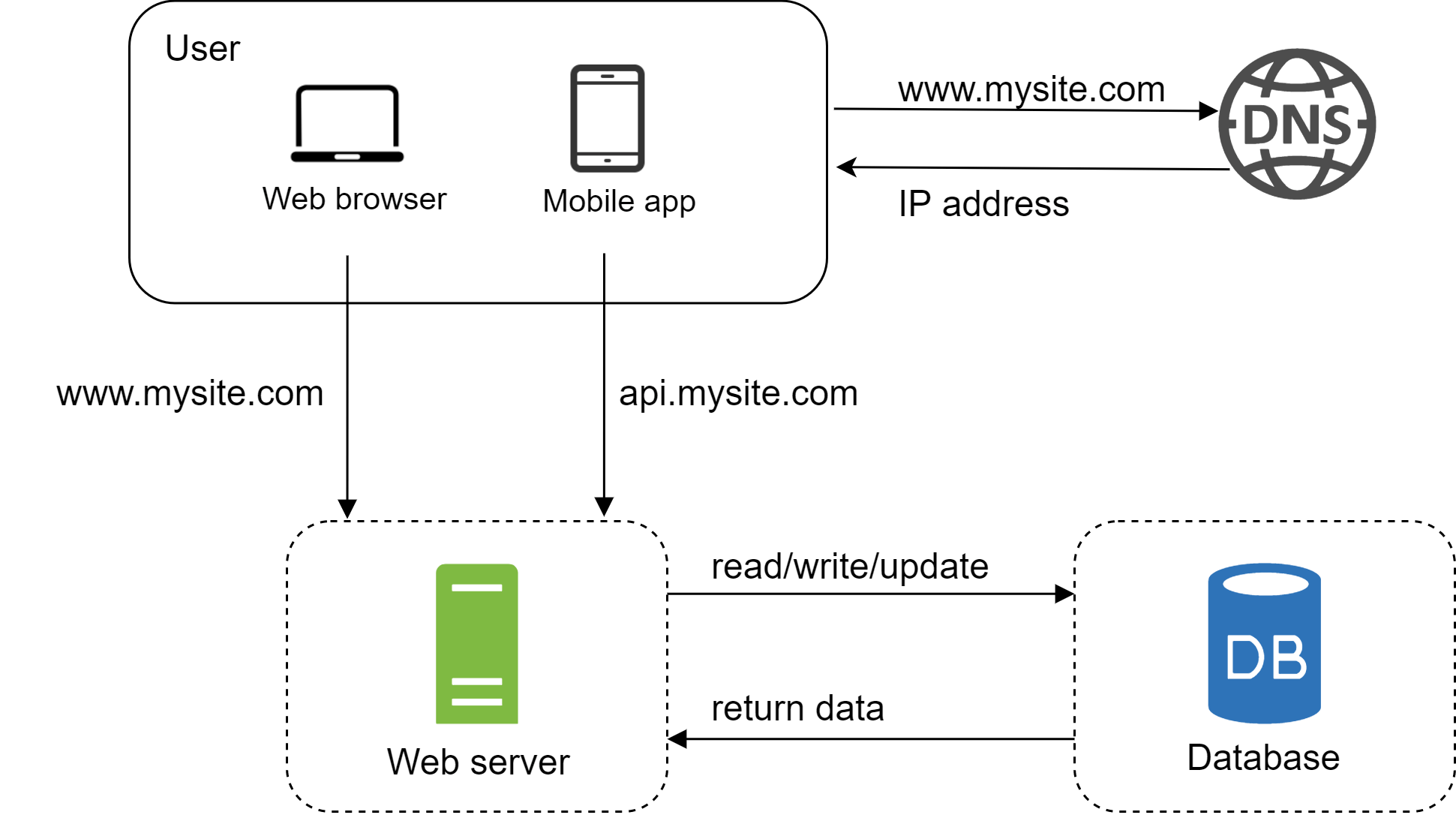
我們來看一下這個設計:
- 使用者透過 DNS 取得 Load Balancer 的 IP。
- 使用者用這個 IP 連上 Load Balancer。
- HTTP 請求被路由到 Server 1 或 Server 2。
- Web 伺服器從 slave 資料庫讀取使用者資料。
- Web 伺服器把任何會修改資料的操作(包括寫入、更新、刪除)導向 master 資料庫。
現在你對 Web 層與資料層都有了紮實的理解,是時候改善載入/回應時間了。我們可以加上一層快取,並把靜態內容(JavaScript、CSS、圖片、影片檔)搬到內容遞送網路(Content Delivery Network, CDN)。
快取#
快取(Cache) 是一個暫存區域,用來把昂貴運算的結果或經常被存取的資料放在記憶體中,讓後續請求能更快地被服務。如圖 6 所示,每次載入新頁面時,都會執行一次或多次資料庫查詢來抓資料;反覆呼叫資料庫對應用效能影響極大,而 Cache 正可以緩解這個問題。
快取層#
快取層是一個暫時性的資料儲存層,速度遠快於資料庫。把快取獨立成一層的好處包括:
- 更佳的系統效能
- 降低資料庫負載
- 可以獨立擴展快取層
圖 7 是一個可能的快取伺服器配置:

收到請求後,Web 伺服器會先檢查快取裡是否已有對應結果。如果有,就直接把資料回給客戶端;如果沒有,就去查資料庫,把結果寫入快取,再回給客戶端。這種快取策略稱為 read-through cache。針對不同的資料型態、大小與存取模式,還有其他快取策略可供選擇。先前的研究說明了不同快取策略的運作方式 [6]。
與快取伺服器互動很簡單,因為大多數快取伺服器都為常見程式語言提供了 API。下方是典型的 Memcached API:
SECONDS = 1
cache.set('myKey, 'hi there', 3600 * SECONDS)
cache.get('myKey')使用快取的注意事項#
使用快取系統時,有幾點需要考慮:
- 何時使用快取:當資料讀取頻繁、但很少被修改時,適合使用快取。由於快取資料存放在揮發性記憶體中,快取伺服器並不適合用來持久化資料。例如,快取伺服器一旦重啟,記憶體中的資料全部會消失,因此重要資料應該保存在持久性儲存中。
- 過期策略(Expiration policy):實作合理的過期策略是好習慣。一旦快取資料過期就會被清除。若沒有過期策略,資料就會永遠留在記憶體裡。過期時間不宜太短,否則系統會頻繁地從資料庫重新載入資料;但也不該太長,否則資料會變得過時。
- 一致性(Consistency):確保資料儲存與快取保持同步。由於修改資料儲存與快取的操作不在同一個交易中,因此可能會出現不一致。當系統跨多個地區擴展時,要維持資料儲存與快取的一致性更具挑戰。詳細內容可參考 Facebook 發表的論文「Scaling Memcache at Facebook」[7]。
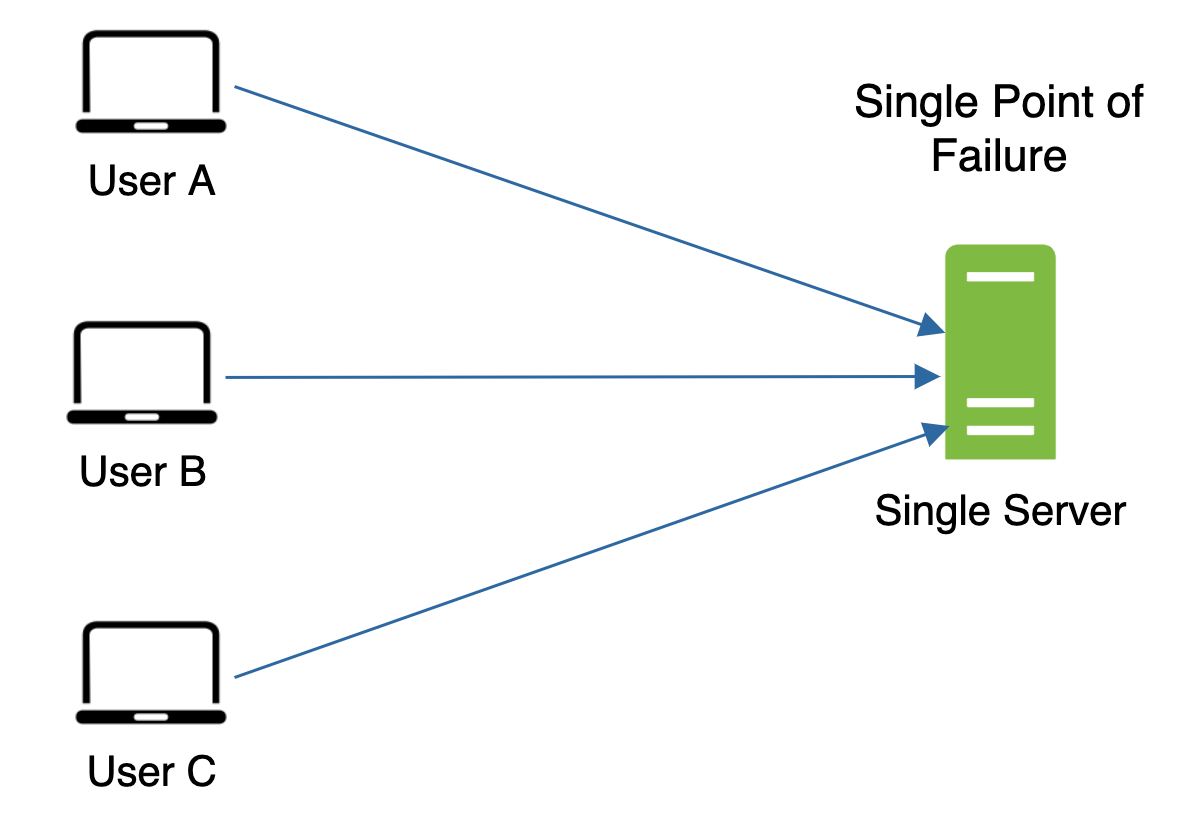
- 緩解故障:單一快取伺服器代表一個潛在的單點故障(Single Point of Failure, SPOF),維基百科對 SPOF 的定義為:「單點故障是指系統中某一部分一旦失效,整個系統就會停止運作」[8]。因此建議在多個資料中心部署多台快取伺服器以避免 SPOF。另一個建議做法是預先多配置一定百分比的記憶體,當記憶體用量上升時就會有緩衝空間。
- 淘汰策略(Eviction Policy):當快取被填滿後,任何要新增項目的請求都可能導致現有項目被移除,這稱為快取淘汰。最常用的淘汰策略是最近最少使用(Least Recently Used, LRU)。其他像最少被使用(Least Frequently Used, LFU)或先進先出(First In First Out, FIFO)等策略,則可以依不同情境採用。
內容遞送網路(CDN)#
CDN 是由地理上分散部署的伺服器組成的網路,用來遞送靜態內容。CDN 伺服器會快取像圖片、影片、CSS、JavaScript 這類靜態資源。
動態內容快取是一個相對較新的概念,超出本書討論範圍。它能根據請求路徑、查詢字串、cookie 與請求標頭來快取 HTML 頁面,更多細節可參閱延伸資料 [9]。本書聚焦在如何用 CDN 來快取靜態內容。
CDN 的高層運作如下:當使用者造訪網站時,最靠近他的 CDN 伺服器會把靜態內容傳給他。直覺上,使用者離 CDN 伺服器愈遠,網站載入速度愈慢。例如 CDN 伺服器若在舊金山,洛杉磯的使用者會比歐洲的使用者更快拿到內容。圖 9 是一個展示 CDN 如何提升載入速度的好例子。

圖 10 展示了 CDN 的工作流程。
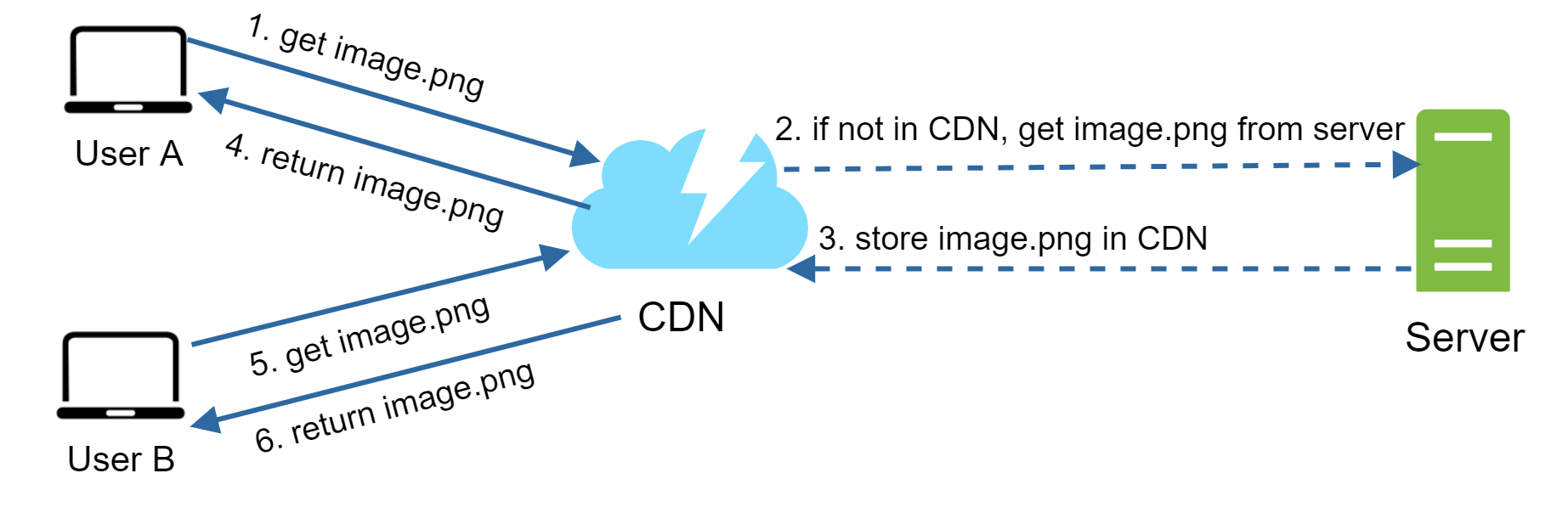
使用者 A 透過某個圖片 URL 嘗試取得 image.png,這個 URL 的網域是 CDN 廠商提供的。下面兩個 URL 範例分別示範 Amazon 與 Akamai CDN 的圖片 URL 樣貌:
https://mysite.cloudfront.net/logo.jpghttps://mysite.akamai.com/image-manager/img/logo.jpg
如果 CDN 伺服器的快取裡沒有 image.png,它會向來源(origin)請求檔案,來源可能是 Web 伺服器或像 Amazon S3 這樣的雲端儲存。
來源把 image.png 回傳給 CDN 伺服器,並可選擇性地附上 HTTP 標頭 Time-to-Live(TTL),用來描述該圖片應快取多久。
CDN 把圖片快取下來並回傳給使用者 A。圖片會一直留在 CDN 中,直到 TTL 過期。
使用者 B 對同一張圖片發出請求。
只要 TTL 還沒過期,圖片就會直接從快取回傳。
使用 CDN 的注意事項#
- 成本:CDN 由第三方廠商營運,傳入與傳出 CDN 的資料都會被計費。對於很少被存取的資源,快取下來幫助有限,因此可以考慮把它們從 CDN 移除。
- 設定合適的快取過期時間:對於時效性內容,設定快取過期時間很重要。時間不宜過長也不宜過短:太長內容會不夠新鮮,太短則會頻繁從來源伺服器重新拉取內容到 CDN。
- CDN 故障備援:你應該思考當 CDN 出問題時,網站/應用該如何因應。若 CDN 暫時掛掉,客戶端應能偵測到問題並改向來源請求資源。
- 失效檔案:你可以在檔案過期前先把它從 CDN 移除,做法包括:
- 透過 CDN 廠商提供的 API 讓該物件失效。
- 使用物件版本控制來提供不同版本的物件。要為物件加上版本,可以在 URL 後面附加參數(例如版本號)。例如把版本號 2 加到查詢字串:image.png?v=2。
圖 11 展示了加入 CDN 與快取後的設計。
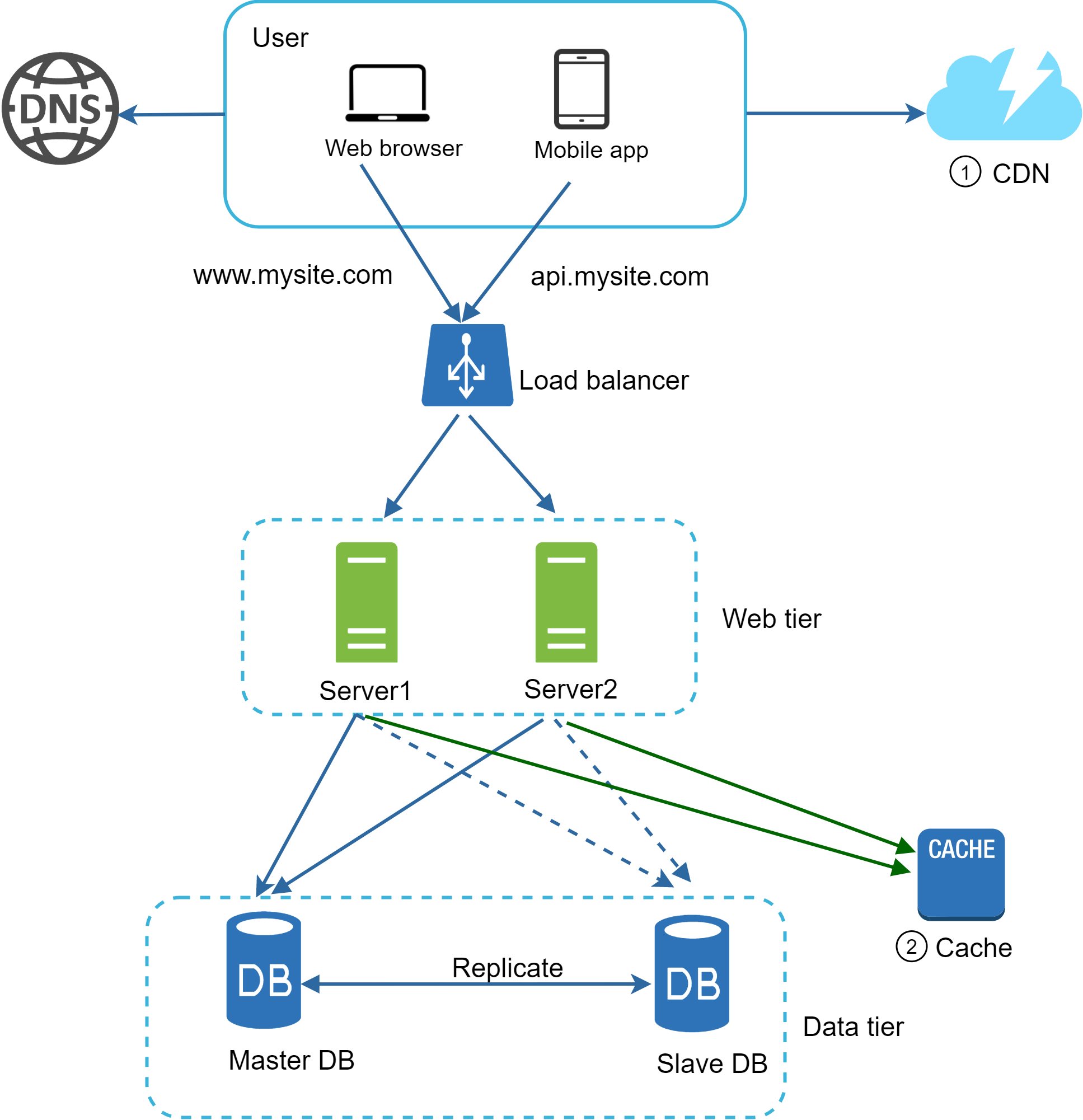
- 靜態資源(JS、CSS、圖片等)不再由 Web 伺服器提供,而是改由 CDN 取得,以獲得更佳效能。
- 透過快取資料,資料庫負載得以減輕。
無狀態 Web 層#
現在該來考慮如何水平擴展 Web 層了。為此,我們需要把狀態(例如使用者 session 資料)從 Web 層搬出去。好的做法是把 session 資料存到持久性儲存裡,例如關聯式資料庫或 NoSQL。叢集中每一台 Web 伺服器都可以從資料庫存取狀態資料,這就是所謂的無狀態(stateless)Web 層。
有狀態架構#
有狀態(stateful)伺服器與無狀態(stateless)伺服器有幾個關鍵差異。Stateful 伺服器會在多次請求之間記住客戶端的狀態,而 stateless 伺服器則完全不保留狀態資訊。
圖 12 展示了一個有狀態架構的例子。
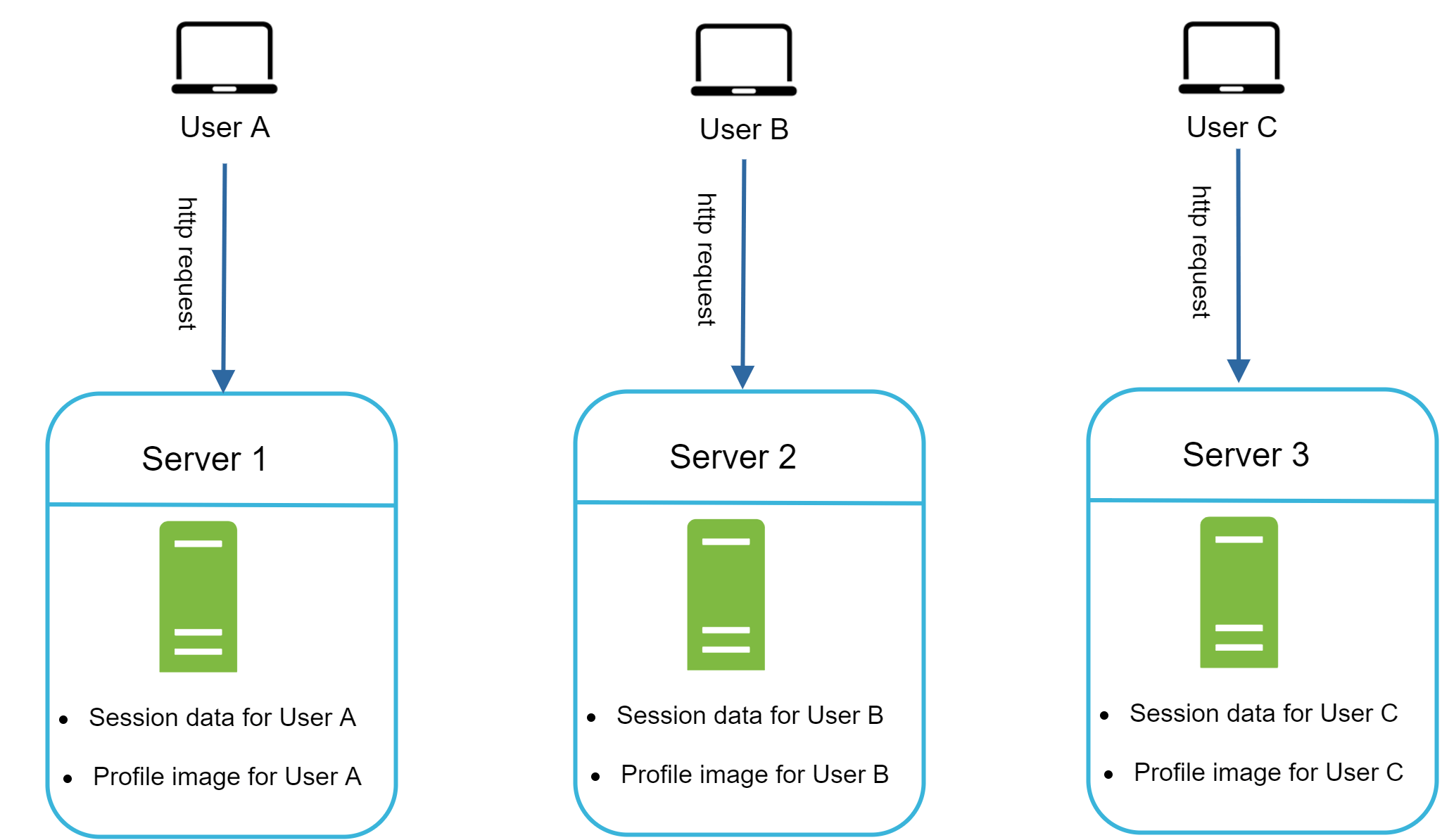
在圖 12 中,使用者 A 的 session 資料與大頭照都存放在 Server 1。要驗證使用者 A,HTTP 請求就必須被導向 Server 1;如果請求被送到別的伺服器(例如 Server 2),驗證就會失敗,因為 Server 2 上沒有使用者 A 的 session 資料。同樣地,使用者 B 的所有請求都必須被導向 Server 2,使用者 C 則必須被送到 Server 3。
問題在於:來自同一客戶端的每個請求都必須被導向同一台伺服器。大多數 Load Balancer 都能透過 sticky session 來達成這件事 [10],但這會帶來額外的開銷。在這種架構下,新增或移除伺服器都更加困難,處理伺服器故障也更具挑戰。
無狀態架構#
圖 13 展示了無狀態架構。
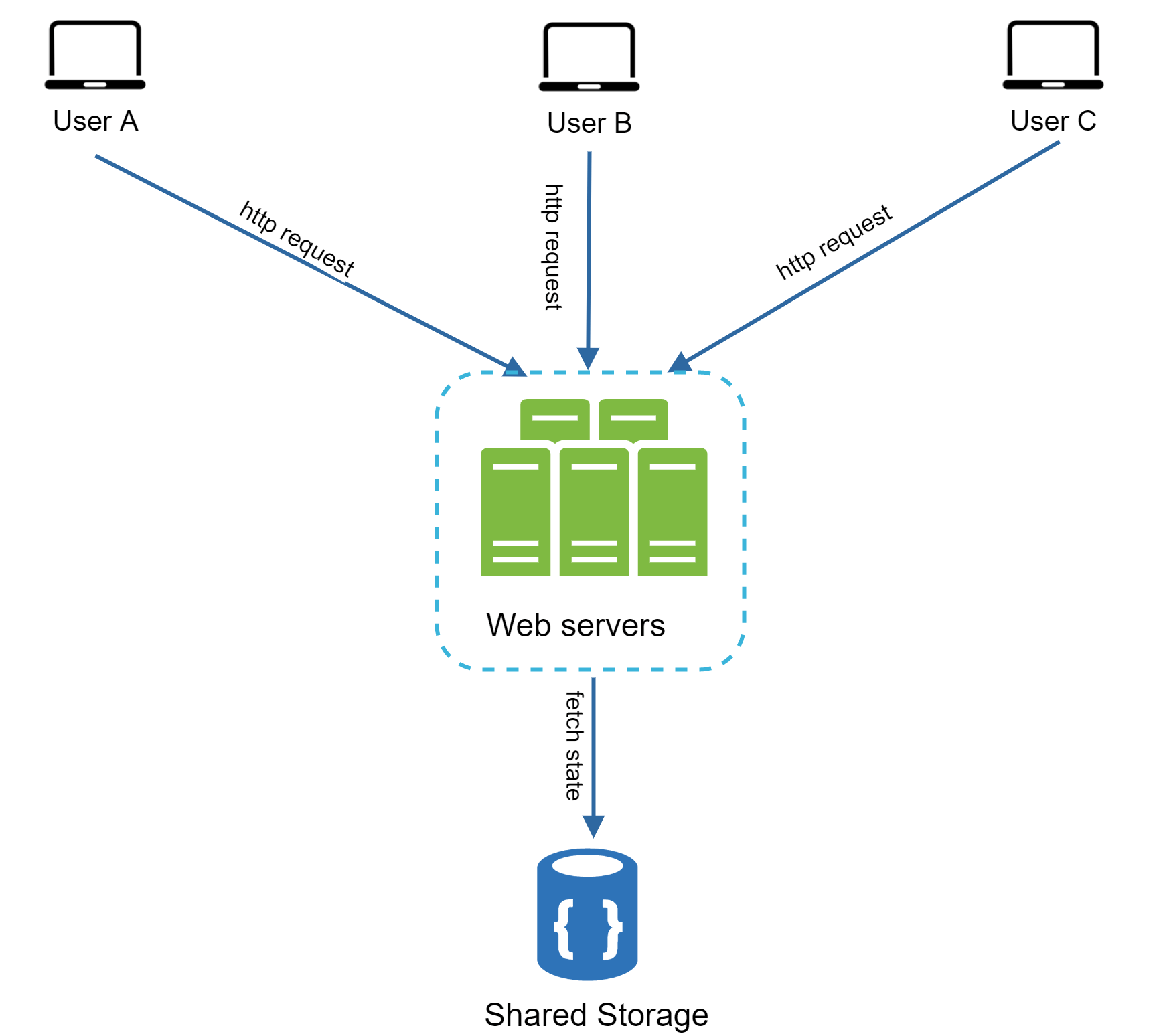
在這個無狀態架構中,使用者的 HTTP 請求可以送到任何一台 Web 伺服器,由它從共用的資料儲存中抓取狀態資料。狀態資料只放在共用的資料儲存裡,不再存在於 Web 伺服器中。無狀態系統更簡單、更穩固、也更容易擴展。
圖 14 展示了採用無狀態 Web 層後的更新後設計。
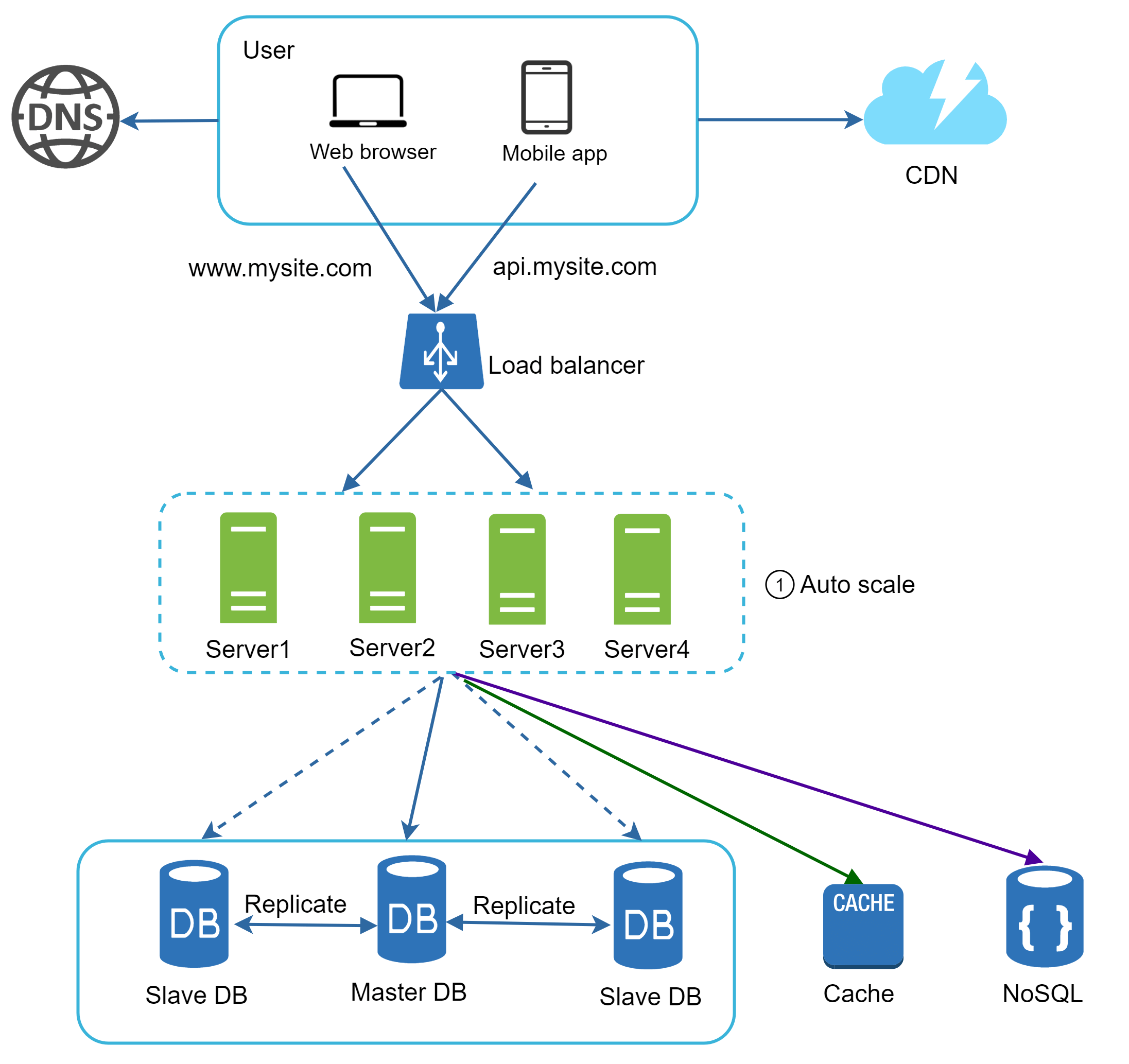
在圖 14 中,我們把 session 資料從 Web 層搬出,放到持久性資料儲存中。這個共用儲存可以是關聯式資料庫、Memcached/Redis、NoSQL 等。我們選擇 NoSQL 是因為它易於擴展。所謂自動擴展(auto-scaling) 是指根據流量負載自動新增或移除 Web 伺服器;當狀態資料從 Web 伺服器中移出後,依流量自動增減伺服器就變得輕而易舉。
你的網站持續快速成長,吸引到大量國際使用者。為了提升可用性、並在更廣闊的地理區域提供更佳的使用者體驗,支援多個資料中心便成為必要。
資料中心#
圖 15 展示了一個包含兩個資料中心的範例。在正常運作下,使用者會被 geoDNS(也稱為 geo-routed)導向最近的資料中心,流量切分為 x% 在 US-East、(100 – x)% 在 US-West。geoDNS 是一種 DNS 服務,可以根據使用者所在位置把網域名稱解析到不同的 IP 位址。
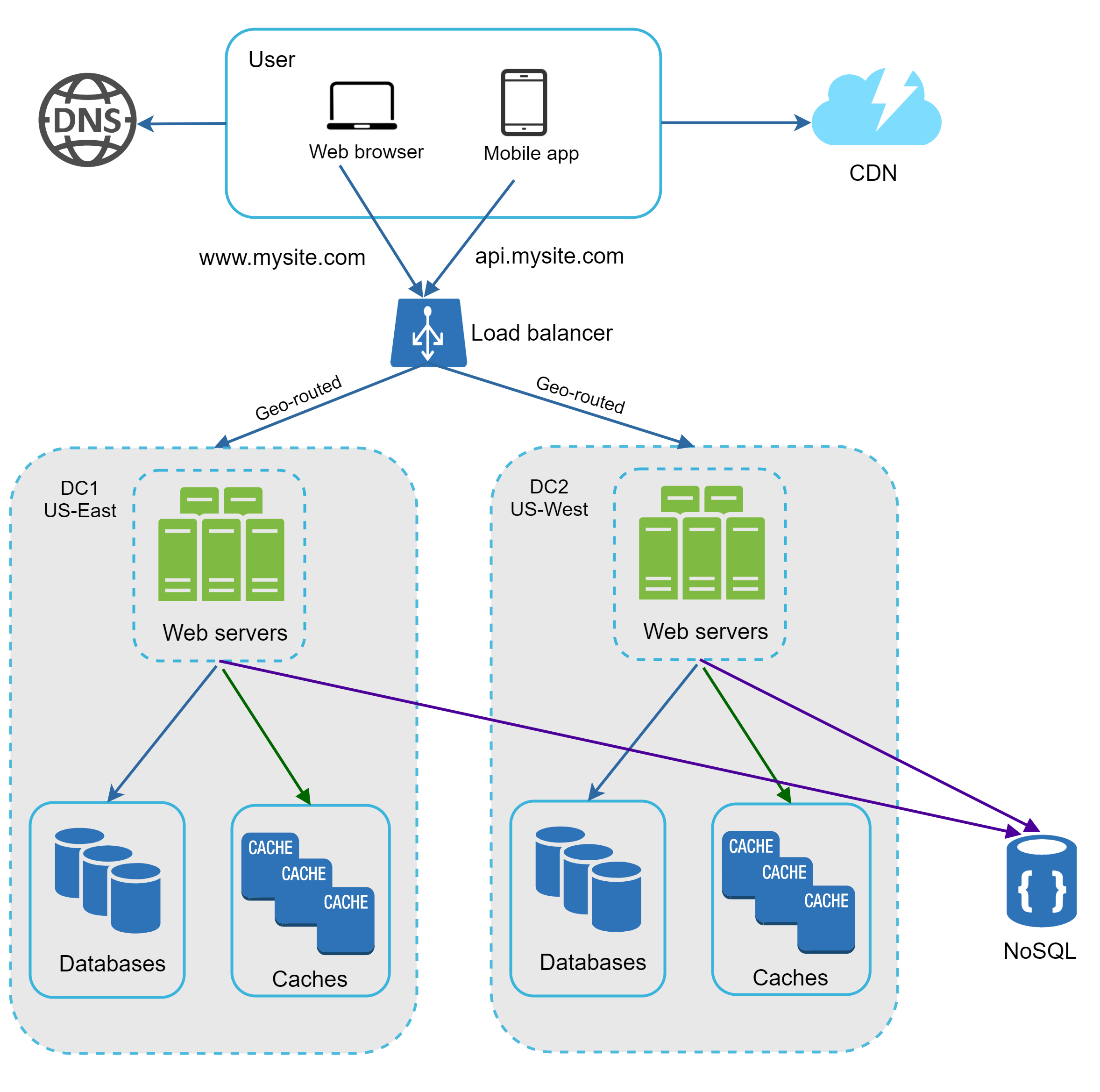
當某個資料中心發生重大故障時,我們會把所有流量導向健康的資料中心。在圖 16 中,資料中心 2(US-West)離線,100% 的流量都被導向資料中心 1(US-East)。
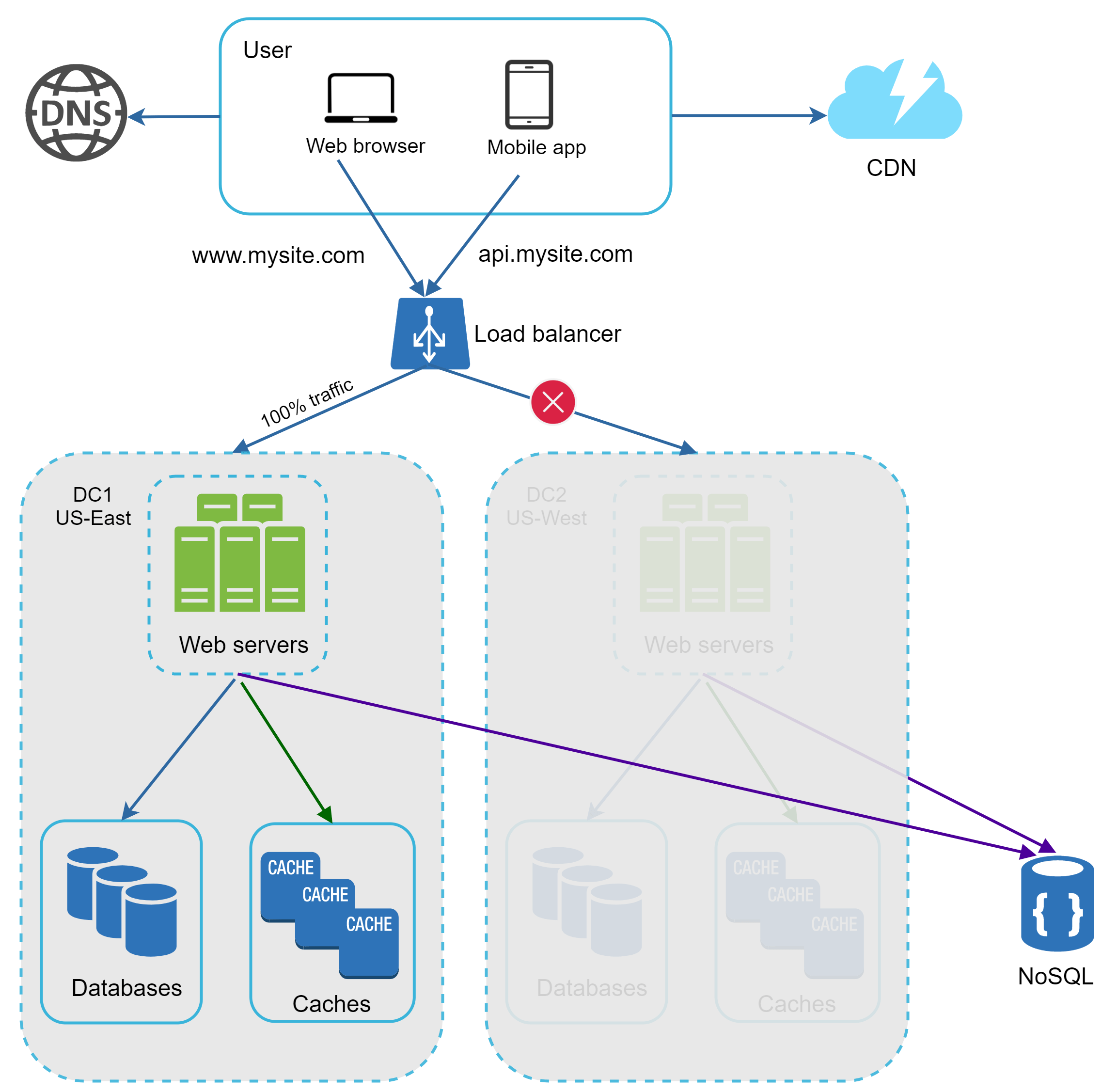
要實現多資料中心架構,必須解決幾個技術挑戰:
- 流量導向:需要有效的工具把流量導向正確的資料中心。GeoDNS 可以根據使用者所在位置把流量導向最近的資料中心。
- 資料同步:來自不同地區的使用者可能使用不同的本地資料庫或快取。在故障轉移時,流量可能被導向一個資料尚未同步的資料中心。常見的策略是跨多個資料中心複寫資料。先前一份研究展示了 Netflix 如何實作非同步多資料中心複寫 [11]。
- 測試與部署:在多資料中心架構下,重要的是要在不同地點測試你的網站/應用。自動化部署工具對於保持各資料中心服務一致至關重要 [11]。
要進一步擴展我們的系統,需要把不同元件解耦,使它們能各自獨立擴展。訊息佇列(Message Queue) 是許多現實世界分散式系統用來解決這個問題的關鍵手法。
訊息佇列#
訊息佇列是一種持久性元件,存於記憶體中,支援非同步通訊。它扮演緩衝區的角色,並分派非同步請求。訊息佇列的基本架構很簡單:
- 稱為生產者(producer/publisher) 的輸入服務建立訊息並發佈到佇列
- 稱為消費者(consumer/subscriber) 的其他服務或伺服器則連到佇列、讀取並執行訊息所定義的動作
模型如圖 17 所示。

解耦使訊息佇列成為構建可擴展、可靠應用的首選架構。透過訊息佇列,當消費者無法處理時,生產者仍可把訊息送進佇列;當生產者不在線時,消費者也仍可從佇列讀取訊息。
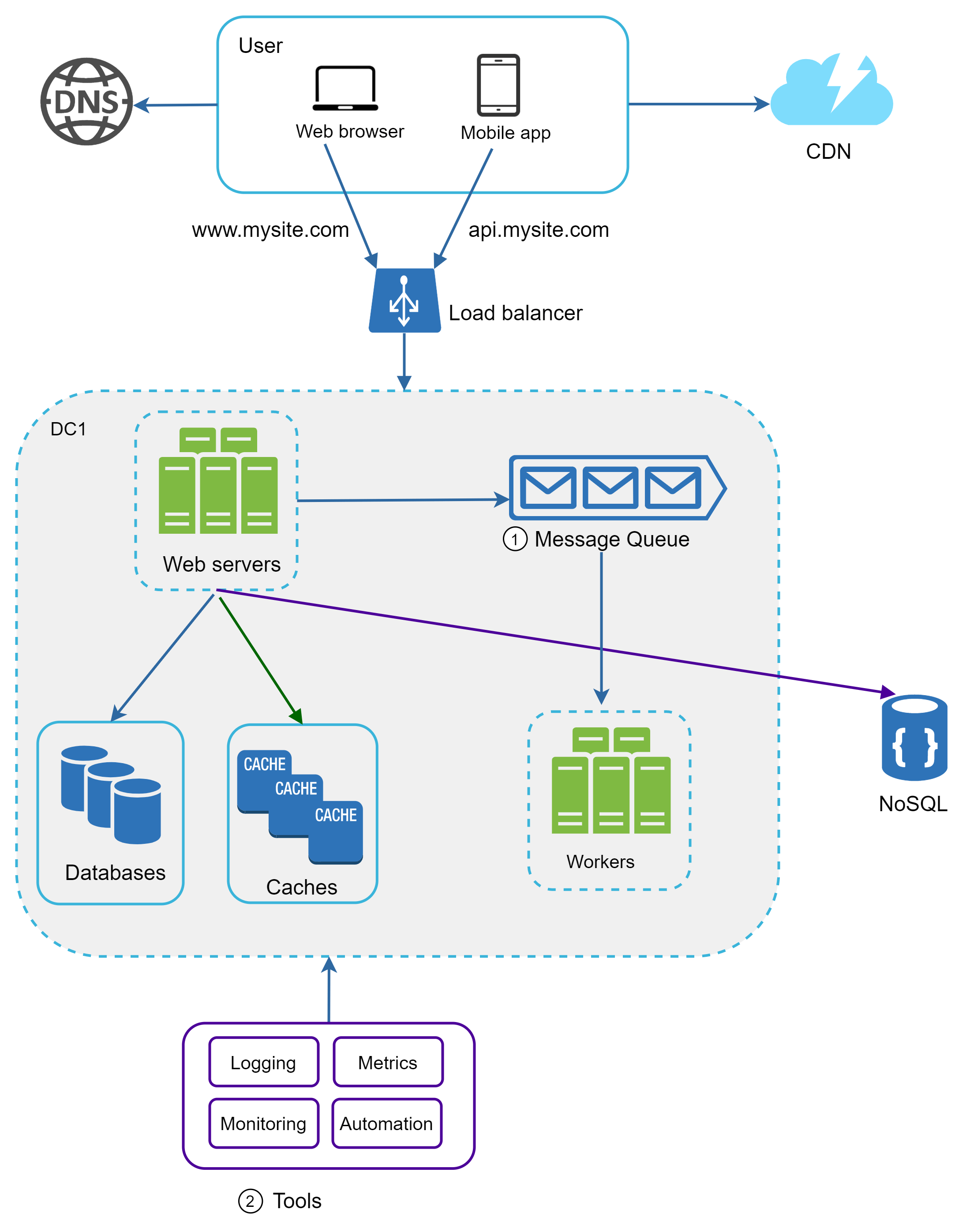
考慮以下場景:你的應用支援照片自訂功能,包括裁切、銳化、模糊等。這些自訂任務需要時間才能完成。在圖 18 中,Web 伺服器把照片處理工作發佈到訊息佇列,照片處理工作者(worker)從訊息佇列取出工作並非同步執行照片自訂任務。生產者與消費者可以各自獨立擴展:當佇列變大時,可以增加更多 worker 縮短處理時間;反之,當佇列大多時候都是空的時候,就可以減少 worker 數量。

日誌、指標、自動化#
當你還在經營一個只跑在幾台伺服器上的小網站時,日誌、指標與自動化雖然是好習慣,但並非必要。然而當你的網站成長為服務龐大業務時,投資這些工具就變得至關重要。
日誌(Logging):監控錯誤日誌很重要,因為它能幫助你發現系統中的錯誤與問題。你可以在每台伺服器上單獨監看錯誤日誌,或使用工具把它們集中到一個服務中以便搜尋與檢視。
指標(Metrics):收集不同類型的指標可以幫助我們獲得業務洞察並了解系統健康狀況。以下是一些有用的指標:
- 主機層級指標:CPU、記憶體、disk I/O 等。
- 彙整層級指標:例如整個資料庫層、快取層的效能等。
- 關鍵業務指標:日活躍使用者數(DAU)、留存率、營收等。
自動化(Automation):當系統變得龐大且複雜,我們需要自行打造或借助自動化工具來提升生產力。持續整合(Continuous Integration, CI)是一種好做法——每次程式碼簽入都會經過自動化驗證,讓團隊能及早發現問題。此外,自動化建置、測試、部署流程等也能大幅提升開發效率。
加入訊息佇列與各種工具#
圖 19 展示了更新後的設計。受限於空間,圖中只畫出一個資料中心。
- 設計中加入了訊息佇列,讓系統更鬆耦合、更具故障韌性。
- 加入了日誌、監控、指標與自動化工具。
隨著資料每天不斷成長,你的資料庫負載愈來愈重。是時候擴展資料層了。
資料庫擴展#
資料庫擴展大致有兩種方法:垂直擴展與水平擴展。
垂直擴展#
垂直擴展,又稱 scaling up,是指為現有機器增加更多資源(CPU、RAM、DISK 等)。市面上有一些非常強大的資料庫伺服器,根據 Amazon Relational Database Service(RDS)[12],你可以取得一台擁有 24 TB 記憶體的資料庫伺服器,這種等級的伺服器可以儲存與處理大量資料。例如 stackoverflow.com 在 2013 年每月有超過 1,000 萬不重複訪客,但它只用一台主資料庫 [13]。然而垂直擴展也有一些嚴重的缺點:
- 你可以為資料庫伺服器加更多 CPU、RAM 等,但硬體有上限。當你的使用者數很大時,單一伺服器就不夠用。
- 單點故障的風險更高。
- 垂直擴展的整體成本很高,強大的伺服器都非常昂貴。
水平擴展#
水平擴展又稱為分片(sharding),是指增加更多伺服器的做法。圖 20 比較了垂直擴展與水平擴展。

Sharding 把大型資料庫切分成更小、更易管理的片段(shard)。每個 shard 共享相同的 schema,但實際資料則各自獨立。
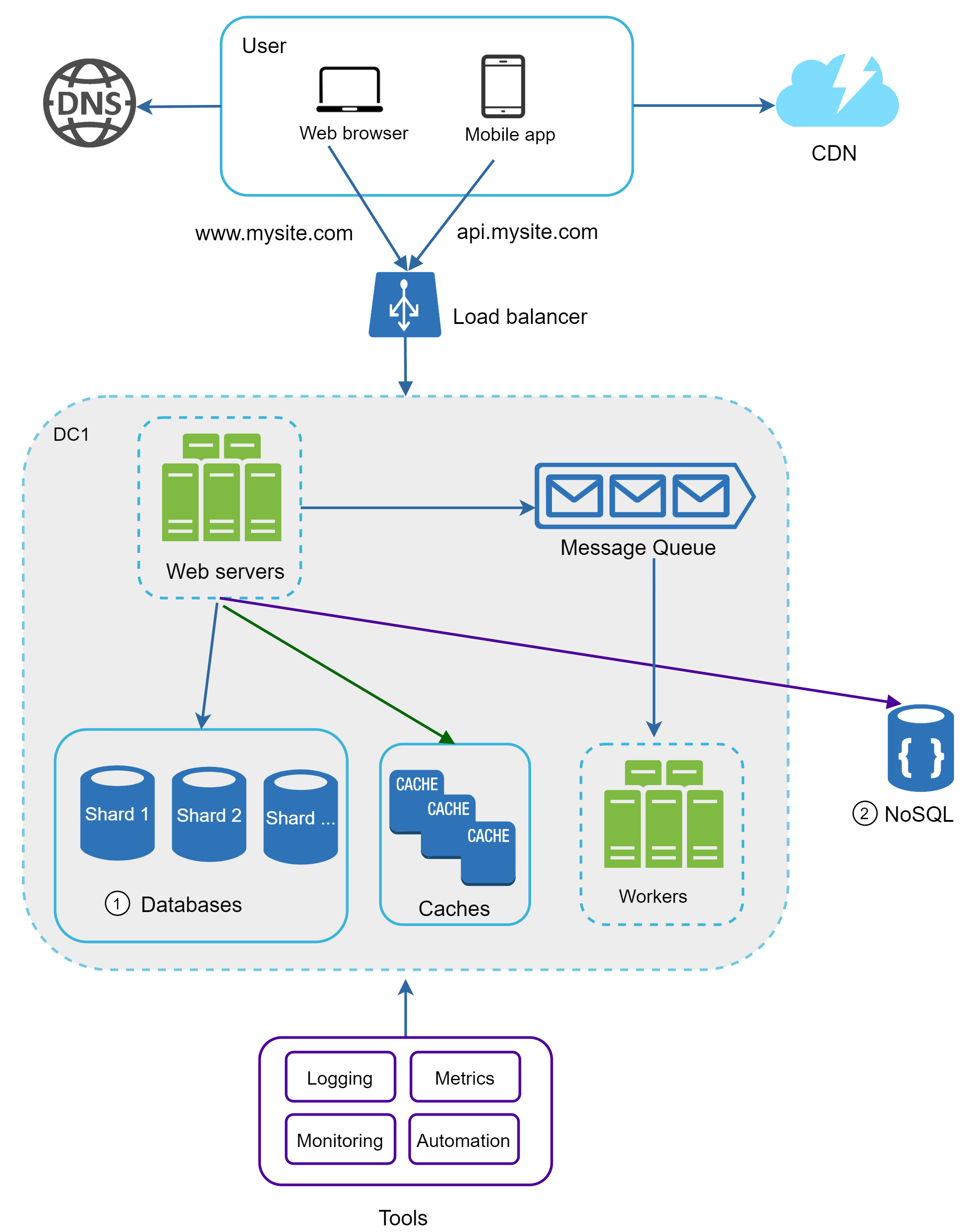
圖 21 展示了一個 sharded 資料庫的例子。使用者資料根據 user ID 被分配到不同的資料庫伺服器。每次存取資料時,都會用一個 hash 函式來找到對應的 shard。在這個例子中,hash 函式是 user_id % 4:結果為 0 就用 shard 0 來存取資料,結果為 1 就用 shard 1,其他依此類推。

圖 22 展示了 sharded 資料庫中的 user table。

實作 sharding 策略時最重要的考量是 sharding key 的選擇。Sharding key(又稱 partition key)由一個或多個欄位組成,決定資料如何被分配。如圖 22 所示,“user_id” 就是 sharding key。Sharding key 透過把資料庫查詢路由到正確的資料庫,讓你能高效地存取與修改資料。選擇 sharding key 時,最重要的標準之一就是要選一個能讓資料分布平均的 key。
Sharding 是擴展資料庫的好技術,但遠非完美的解方。它為系統引入了複雜性與新挑戰。
以下是 sharding 帶來的主要挑戰:
- Resharding(重新分片):在以下情境需要 resharding:1) 由於資料快速成長,單一 shard 無法再承載更多資料;2) 由於資料分布不均,某些 shard 比其他 shard 更快達到容量上限。當 shard 用盡時,必須更新 sharding 函式並搬移資料。一致性雜湊(Consistent Hashing)是常用來解決此問題的技術。
- 名人問題(Celebrity problem):又稱為 hotspot key 問題。對特定 shard 的過度存取可能造成伺服器超載。想像一下 Katy Perry、Justin Bieber 與 Lady Gaga 的資料全都落在同一個 shard 上:對社交應用而言,這個 shard 將會被大量讀取操作淹沒。要解決此問題,可能需要為每位名人各自分配一個 shard,每個 shard 甚至可能需要再細分。
- Join 與反正規化(de-normalization):一旦資料庫被分片到多台伺服器,跨 shard 執行 join 操作就變得困難。常見的權變做法是反正規化資料庫,讓查詢能在單一資料表內完成。
在圖 23 中,我們對資料庫分片以支援快速增長的資料量。同時,部分非關聯式的功能被移到 NoSQL 資料儲存中以減輕資料庫負載。下面這篇文章涵蓋了 NoSQL 的許多應用場景 [14]。
數百萬使用者,乃至更遠#
擴展系統是一個迭代的過程。把本章學到的內容反覆套用,已經能帶我們走得很遠。要支援超過數百萬的使用者,還需要更多的微調與新策略,例如你可能需要對系統進行優化,並把系統解耦成更細的服務。本章學到的所有技巧都能為迎接新挑戰打下良好基礎。
在本章結尾,我們來總結一下如何擴展系統以支援數百萬使用者:
- 保持 Web 層無狀態
- 在每一層都建立備援
- 盡可能快取資料
- 支援多個資料中心
- 將靜態資源放到 CDN
- 透過 sharding 擴展資料層
- 將各層拆分為獨立服務
- 監控系統並使用自動化工具
恭喜你讀到這裡!給自己拍拍背,做得好!