為什麼利弊分析不夠用#
決策之所以困難,是因為你必須在資訊不完整的情況下做選擇。當你考慮職涯轉換時,選項可能無窮無盡——換一份相似但條件更好的工作、在原公司往上爬、跳到別家公司更高的職位、甚至重新進修轉換跑道。你無法在做決定前完整體驗每一個選項,這就是人生。
大多數人遇到這類情境會直接拿出利弊分析(pros and cons list):把好處列一邊、壞處列一邊,然後比一比。它在簡單情境裡確實有用,但有四個明顯缺陷:
- 預設只有兩個選項,但現實裡通常更多
- 把所有條目都當作等重的,忽略了它們之間的差異
- 把每一項當成獨立事件處理,忽略彼此的關聯
- 好處通常比壞處更顯眼,會讓你陷入「鄰家草地比較綠」的偏誤
作者 Gabriel 早年曾考慮從創業者轉職做創投。利弊清單上一片好處(與創辦人共事、高報酬、無創業風險),幾乎沒有壞處——但他忽略了高度社交、不停拒絕別人、難以入行、長時間陪伴掙扎中的公司等隱藏成本。經驗有限時,利弊清單注定不完整。
這呼應了馬斯洛的錘子(Maslow’s hammer):「如果你只有一把錘子,所有東西看起來都像釘子。」利弊清單就是決策模型裡的那把錘子——好用,但絕不是萬用工具。你需要更多的決策模型,才能對不同情境挑出最合適的那一把。
衡量成本與效益#
最簡單的升級,是替每一條利弊加上分數(例如 −10 到 10),再把同一個選項的分數加總起來互相比較。這就是**成本效益分析(cost-benefit analysis)**最初級的形式:透過量化讓條目不再等重,也能輕鬆橫向比較多個選項。
進入更嚴謹的版本後,分數會被換成具體的金額:
- 把成本與效益逐項列出,並標上 −$100、+$5,000 等實際金額
- 對於無形的成本與效益(例如不必面對房東的安心感),也要硬著頭皮給一個概估值
- 把所有條目排進時間軸——每一年都是一欄,方便你看出長期影響
為什麼要把現金流排進時間軸?因為今天拿到的好處,比未來同樣金額的好處更值錢。原因有三:今天就能拿去再投資(資本機會成本)、通膨會吃掉購買力、未來本身充滿不確定性。
要把未來金額換算回今天的價值,必須使用折現率(discount rate)。例如:投資 $50,000 的債券,十年後拿回 $100,000,用 6% 折現率折回現值約 $55,839,淨收益是 $5,839——值得考慮。
但折現率本身就是個敏感參數,這時要做敏感度分析(sensitivity analysis):
- 把折現率從 0% 一路調到 16%,計算每個情境下的淨收益
- 你會發現 4% 時淨收益是 $17,556,8% 時卻變成 −$3,680
- 對所有不確定的輸入參數都該做敏感度分析,找出真正的關鍵驅動因子
折現率沒有「標準答案」:政府通常用接近利率的數字、大公司會用更高的內部資本成本、新創公司則因為高風險而需要 50% 以上的折現率。氣候變遷這類影響跨世代的議題尤其麻煩——折現率會讓遙遠未來的代價被壓縮到接近零,有人認為這在道德上並不公平。
最後要小心:成本效益分析的結果取決於你輸入的數字。電腦科學裡有句話叫垃圾進、垃圾出(garbage in, garbage out)——估算粗糙、時間軸對不齊、折現率亂選,結論自然不可信。但只要謹慎輸入並搭配敏感度分析,它就是利弊清單的最佳替代品。
馴服複雜性#
當選項與成本不再清晰、結果充滿不確定性時,你需要更強的工具。
決策樹與期望值#
想像你要找承包商修泳池。老牌廠商開價 $2,500 一週搞定;新人開價 $2,000,但只有 50% 機率準時,另外有 25%、20%、5% 的機率分別超支 $250、$500、$1,000。
這時可以畫出決策樹(decision tree):方框是決策點、圓圈是機率分支、葉子是各種可能結果。把每個分支的「機率 × 成本」加總,就得到該選項的期望值(expected value)。新承包商的期望值是 $2,212.50,反而比老廠商的 $2,500 還低。
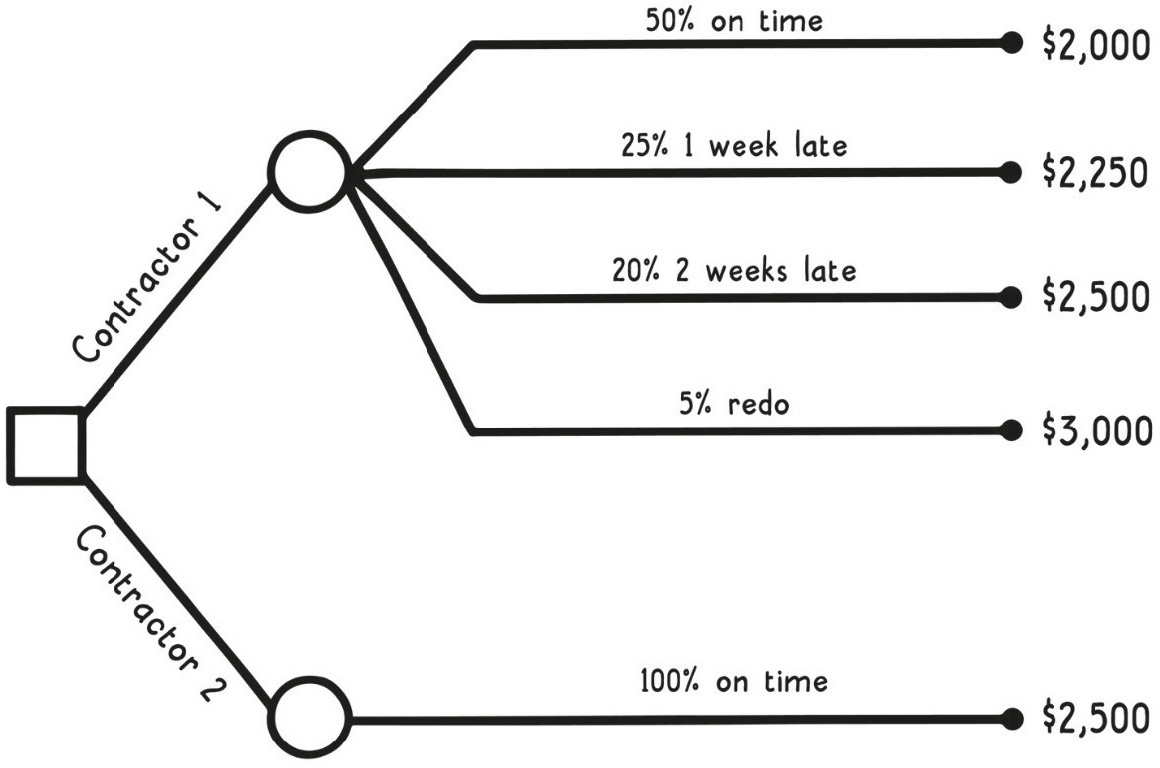
Decision Tree(決策樹)
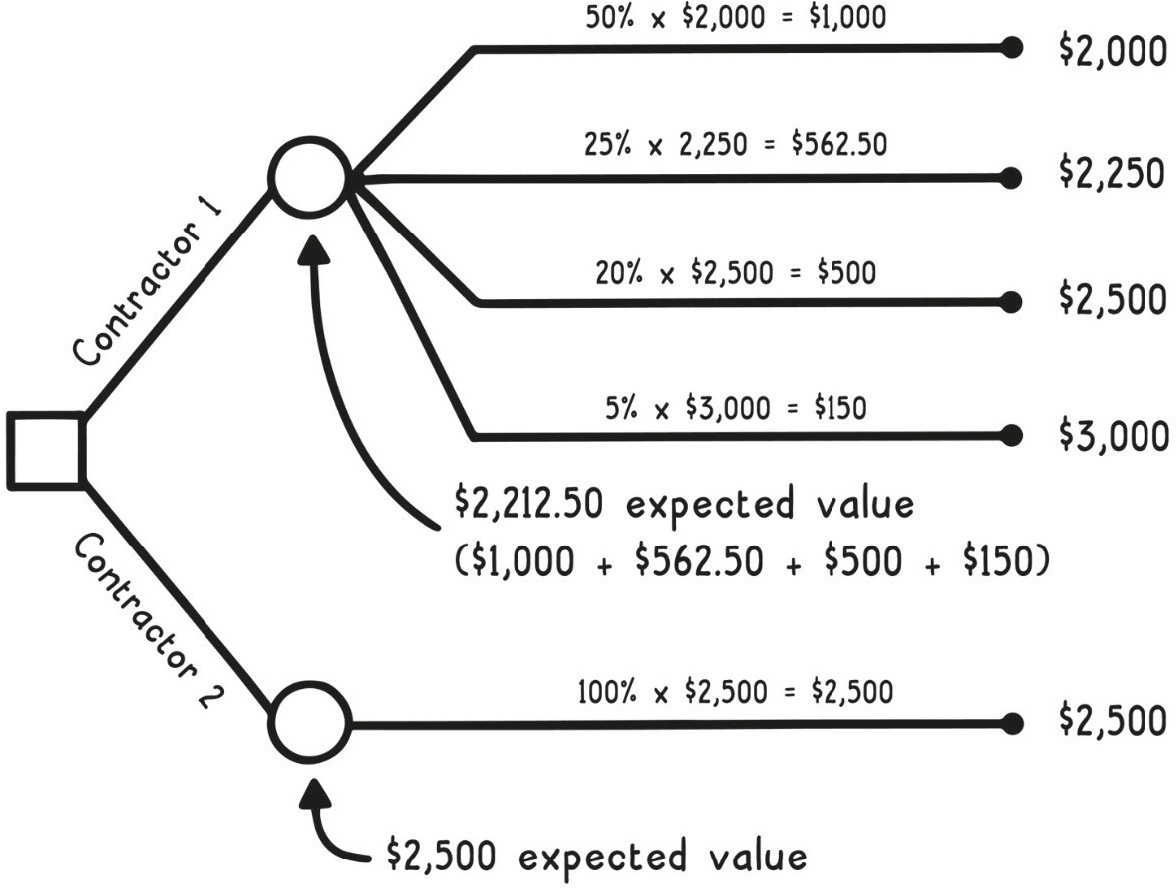
Expected Value(期望值)
期望值不是「實際會付的金額」,而是無數次重複後的平均值。就像 2015 年美國媽媽平均生 2.4 個小孩——沒有任何人剛好生 2.4 個,但所有人加總平均下來就是這個數字。
效用值與功利主義#
純看金額還不夠。如果你已經訂好泳池派對,承包商遲到帶來的焦慮、調度替代方案的成本,都該被「定價」進去。把這些加進葉子節點後,你得到的就是效用值(utility values)——反映你對所有結果的真實偏好。
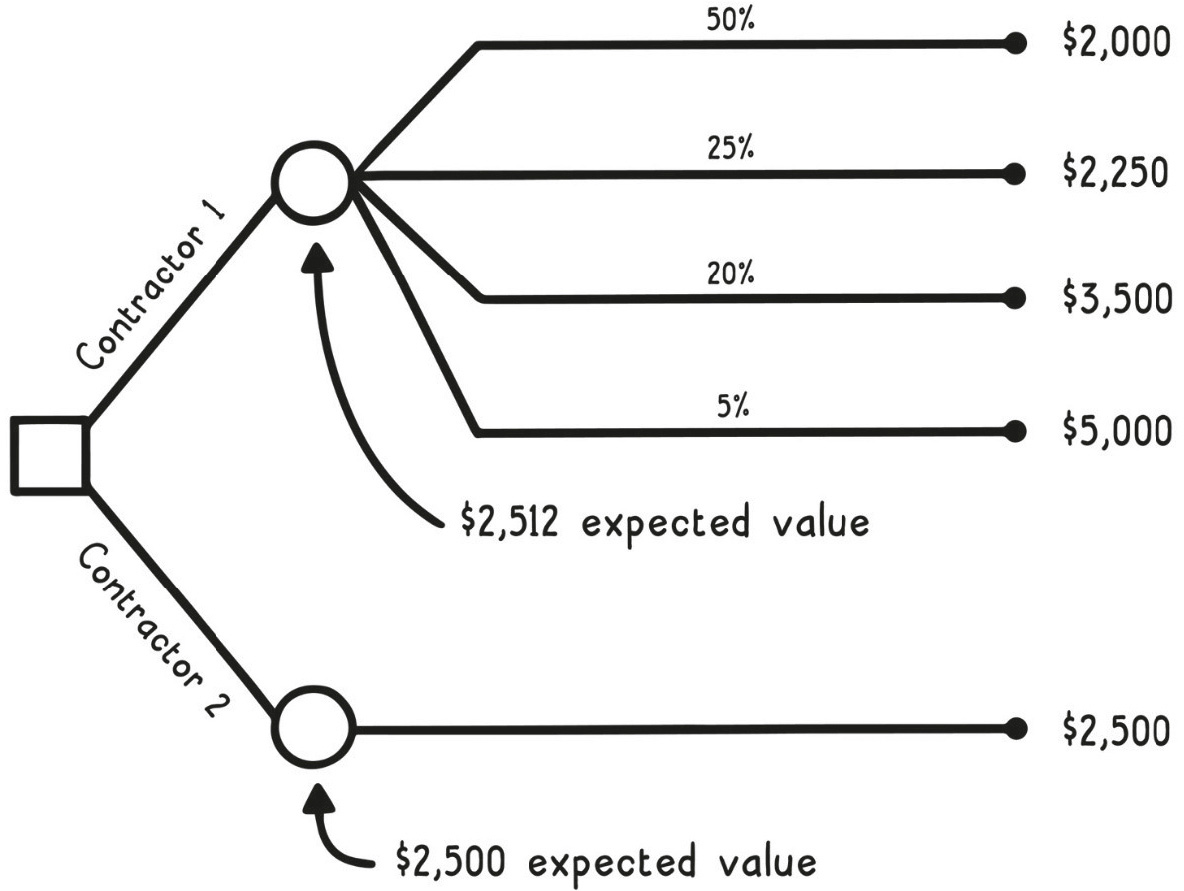
Utility Values(效用值)
放大來看,**功利主義(utilitarianism)**正是把這種思路推到極致的哲學:最道德的決策,是讓所有人總效用最大的那個。但功利主義也有缺陷:總效用增加時可能極度不均(例如所得不平等),而且效用本身難以估計。
黑天鵝與肥尾分布#
決策樹特別適合處理「機率低、衝擊大」的情境,例如健保高自負額方案在大病時的破產風險。針對這類事件,你必須警惕黑天鵝事件(black swan event)——名稱來自歐洲人長年以為黑天鵝不存在,後來才發現澳洲滿地都是。
低機率高衝擊事件容易被低估,原因有三:
- 人們以為事件落在常態分布上,但實際是肥尾分布(fat-tailed distribution),極端值出現的機率遠高於鐘形曲線預期
- 把多個分布混淆成單一分布(例如忽略了基因病變導致的極端身高)
- 低估了**串聯失敗(cascading failures)**的可能性,例如 2007–2008 年的房貸證券一路拖垮銀行與保險業
休士頓在過去三年發生了三次「五百年一遇」的洪水。氣候變遷正在改寫機率本身——當系統條件改變,原本的機率估算就需要重做。
系統思考與模擬#
要看懂這類複雜情境,得先退一步使用系統思考(systems thinking):把整個系統當成一個整體去理解組件間的互動,避免決策產生意外後果。
當系統太大難以全部裝進腦中時,可以畫圖:
- 因果環圖(causal loop diagram):呈現系統中的回饋迴路
- 存量流量圖(stock and flow diagram):顯示事物如何累積與流動
- 進一步可以用軟體做模擬(simulation),設好初始條件後讓系統自己跑下去
模擬會展現兩個常見的系統現象:**勒沙特列原理(Le Chatelier’s principle)**指出系統在條件改變時會自我調整以部分抵銷外力(與生物學的恆定性 homeostasis 同源);**遲滯(hysteresis)**則描述系統當前狀態會受過去歷史影響,是一種特殊的路徑依賴。
**蒙地卡羅模擬(Monte Carlo simulation)**是一種特別有用的模擬:用隨機初始條件跑大量次模擬,看不同結果出現的頻率。它在曼哈頓計畫期間因物理學家 Stanislaw Ulam 玩接龍時的靈感而誕生,現在從科學研究到創投基金都在使用。
最後,系統思考能幫你看見全貌,避免陷入局部最佳解(local optimum)——一個還不錯但不是最好的解。你真正想找的是全域最佳解(global optimum),但前提是你得先知道那座更高的山存在。
留意未知的未知#
1955 年心理學家 Joseph Luft 與 Harrington Ingham 提出了**未知的未知(unknown unknowns)**這個概念,後來被前美國國防部長 Rumsfeld 在 2002 年的一場記者會上講紅。把它畫成 2×2 矩陣,就能系統性地拆解你對情境的掌握程度:
- 已知的已知(known knowns):你已經知道怎麼處理的風險
- 已知的未知(known unknowns):你知道存在但結果不明的風險,可透過去風險(de-risking)轉成已知的已知
- 未知的已知(unknown knowns):你沒注意到但別人有清楚解法的風險,找有經驗的顧問就能浮現出來
- 未知的未知(unknown unknowns):最不顯眼、需要刻意挖掘的風險
整個練習的目的,就是把所有四象限裡的條目逐步搬進「已知的已知」這格。這跟系統思考一樣,都是在追求對情境的完整理解。
情境分析與思想實驗#
要挖出未知的未知,可以使用情境分析(scenario analysis):刻意構想出多個合理但相異的未來,深入分析每一種的可能性與後果。它困難在於人會被第一個想法錨定,慣性地把當下軌跡延伸下去。
破解方法包括:
- 列出可能發生的重大事件(股災、新法規、產業合併),再回推到自己的處境
- 進行思想實驗(thought experiment)——在腦中而非現實中跑實驗。最有名的是薛丁格的貓
- 使用「如果……會怎樣」式的問句去探索未來
Schrödinger's Cat Thought Experiment(薛丁格的貓思想實驗)
- 把同樣問句倒過來用在過去,叫做反事實思考(counterfactual thinking):如果我當年接了那份工作?如果我念了另一所學校?
這些技巧屬於橫向思考(lateral thinking)——讓想法從一個點跳到另一個點,而非像**批判性思考(critical thinking)**那樣直接評斷眼前的想法。橫向思考就是「跳出框架思考」。
群體迷思與發散思考#
情境分析很難一個人完成,但找一群人腦力激盪也未必更好——因為**群體迷思(groupthink)**會讓成員為了和諧而趨向共識,迴避衝突與替代方案。**從眾效應(bandwagon effect)**則描述觀點隨著支持者增加而迅速擴散,形成風潮。
對抗群體迷思的工具:
- 建立質疑假設、批判評估的文化
- 設置魔鬼代言人(Devil’s advocate)的角色
- 主動找意見不同的人加入
- 降低領導者對小組討論的影響
- 把大組拆成獨立的小組
最後一條尤其關鍵,它正是發散思考(divergent thinking)的基礎:先讓所有人各自想出多種解法,最後再進行收斂思考(convergent thinking),把候選方案收斂到少數幾個。實務做法是:先開一次只說明目標的會議,散會後讓大家獨立思考,再聚回來統合。
群眾外包與超級預測者#
要走得更遠,可以跳出組織做群眾外包(crowdsourcing)——向任何想參與的人徵求想法。Netflix 在 2009 年舉辦的演算法競賽就是經典例子,群眾跑出的推薦系統打敗了 Netflix 自家的版本。
James Surowiecki 在《群眾的智慧》裡指出,群眾外包要產生效果需要三個條件:
- 意見多樣性(diversity of opinion):每個人都帶著自己的私有資訊與經驗
- 獨立性(independence):人們能不受他人影響地表達意見
- 可彙整性(aggregation):能把多元意見彙整成集體決策
1906 年的一場郡集會上,近八百人各自猜測一頭牛的重量,平均值剛好等於牛真實重量的 1,197 磅。屠夫看到的、農夫看到的、獸醫看到的都不一樣,這些資訊在集體平均後互相補位。
把群眾外包應用到情境分析上,最直接的形式是預測市場(prediction market)——像股市一樣,每股價格在 $0 到 $1 之間,代表事件發生的機率。如果你覺得真實機率高過市場價,就買進「會發生」的股票。PredictIt 這類公開市場成功預測過不少選舉,但 2016 年同時錯失了 Trump 當選與英國脫歐——事後檢討發現意見不夠多元,且參與者被初期的賠率所影響。
另一個值得認識的計畫叫做 Good Judgment Project,研究者 Philip E. Tetlock 從上千名參與者中辨認出超級預測者(superforecasters):他們的預測準確度甚至超越握有機密情報的情報機構。他歸納出他們共有的特質:
- 智力與快速進入新領域的能力
- 領域知識的深度
- 反覆練習這項技能
- 善於團隊合作但避免群體迷思
- 開放心態,願意挑戰自己的信念
- 訓練自己參考過往機率,避開基準率謬誤
- 願意花時間思考
- 持續根據新資訊修正預測(避免確認偏誤)
把推理寫成商業案例#
走完整套決策模型後,最後一步是把它整理成商業案例(business case)——一份說明決策邏輯的文件。這是**從第一性原理推論(arguing from first principles)**的具體實踐:清楚列出前提,並推演到結論。
商業案例可短可長,從幾段說明到完整報告都行。它的價值在於:
- 強迫你檢查推理過程中的漏洞
- 提供與同事討論決策的共同基礎
- 在最終形式裡用來說服他人,甚至說服自己
回到本章開頭的職涯轉換問題:你可以先用情境分析想像不同職涯軌跡,再對最有希望的選項做成本效益分析或決策樹,最後把整套推理寫成一份簡潔的商業案例。
本章重點:
- 想用利弊清單時,考慮升級為成本效益分析或決策樹
- 任何量化評估都要做敏感度分析,特別注意折現率
- 留意黑天鵝與未知的未知,用系統思考與情境分析主動發掘
- 系統夠複雜時,用模擬輔助評估
- 提防群體迷思的盲區,刻意引入發散與橫向思考
- 努力理解全域最佳解,並朝它移動