用機率與統計穿越不確定性#
組織與個人都越來越仰賴資料做決策:小孩何時該上床、哪種飲食最有效、那台車比較安全。然而對於同一個議題,幾乎都能找到雙方陣營各自端出「數字」支持自己的立場,難怪有人會說「謊言、該死的謊言、還有統計數字」。
- 資料可以被刻意操弄,也可能被無意誤讀
- 但放棄所有統計、改用直覺與意見決策更糟
- 真正的解法是用心智模型理解研究的內部結構,判斷哪些資訊值得相信
法國數學家拉普拉斯(Pierre-Simon Laplace)在 1812 年寫道:「人生中最重要的問題,多半其實只是機率問題。」
該不該相信?從軼事到實驗#
人類天生會用過往經驗推斷未來,但軼事證據(anecdotal evidence)——個人聽聞或目睹的零散故事——常常導出錯誤結論:
- 「今年下了大雪,所以根本沒有全球暖化」
- 「我爺爺一輩子每天一包菸活到八十幾,所以菸不會致癌」
- 「我打完流感疫苗就感冒了,是疫苗害的」
軼事的問題在於樣本不具代表性,人們特別愛分享極端故事。即使有人抽菸沒得肺癌,也只證明「抽菸不必然得肺癌」,無從推論一般抽菸者的罹癌機率。
「相關不蘊含因果(correlation does not imply causation)」是統計學最常被忽略的警語。兩件事先後發生或同時變化,並不代表前者導致後者。
當看似的因果關係出現時,要警覺背後可能有:
- 混淆因子(confounding factor):影響「假定原因」與「觀察結果」的第三變項。例如打疫苗後感冒,真正原因往往是疫苗與感冒高峰期同時出現
- 偽相關(spurious correlation):純粹由隨機巧合產生的相關。網站 Spurious Correlations 蒐集了大量此類「乳酪消費量與床單纏繞死亡人數高度相關」之類的笑話

Correlation Does Not Imply Causation(相關不蘊含因果)
要產生可信的證據,得從定義假設(hypothesis)開始,避免德州神槍手謬誤(Texas sharpshooter fallacy)——先射擊再畫靶——以及在看到結果後才偷偷修改目標的「移動標靶」。實驗設計的黃金標準是:
- 隨機對照實驗(randomized controlled experiment):將參與者隨機分派到實驗組與對照組,每次只變動一個因子
- A/B 測試:產品開發領域的對照實驗版本
- 盲測(blinding):受試者甚至研究者都不知誰屬哪組,避免偏好影響結果
- 安慰劑(placebo)與安慰劑效應(placebo effect):對照組得到外觀相同但無效的處置;單純的「期待」就會帶來真實的生理改變,反向則稱為反安慰劑效應(nocebo effect)
當研究主題不易直接量測時,常會使用代理指標(proxy endpoint)——例如以 BMI 衡量肥胖、以 IQ 衡量智力。代理指標方便但容易失真:抗心律不整藥能減少心律不整,卻反而提高心臟病後的猝死率,因此「減少心律不整」並非「降低死亡率」的好代理。
隱藏的偏誤#
即使是設計周全的實驗,也常被各種偏誤滲透:
- 選擇偏誤(selection bias):分組無法真正隨機。例如研究孕婦抽菸的影響時,繼續抽菸的孕婦本身可能也做出其他高風險選擇
- 無回應偏誤(nonresponse bias):被選中卻未參與的人若與主題相關,例如員工敬業度調查中冷感員工不填問卷,結果會嚴重失真
- 回應偏誤(response bias):受試者的回答因問題措辭、順序、記憶誤差或自我形象維護而偏離真實
- 倖存者偏誤(survivorship bias):只看到「活下來」的樣本
二戰時,研究人員想根據返航戰機的彈孔位置加裝裝甲。統計學家 Abraham Wald 指出:被擊落的飛機才是真正的樣本——彈孔多的位置代表那裡中彈仍能返航;應該補強的,是返航飛機沒有彈孔的部位。
倖存者偏誤無所不在:只看 Bill Gates、Mark Zuckerberg 就以為輟學創業是好主意,會忽略所有失敗的輟學者;老建築看起來比現代建築美,因為醜陋的早就被拆光了。
評估或設計研究時,要習慣性追問:誰沒有出現在樣本裡?這個樣本相對於底層母體為何不隨機?
小數法則的陷阱#
人類傾向高估小樣本的代表性,這個謬誤被稱為小數法則(law of small numbers),相對於真正的統計定律:
- 大數法則(law of large numbers):樣本越大,平均結果越接近真實期望值
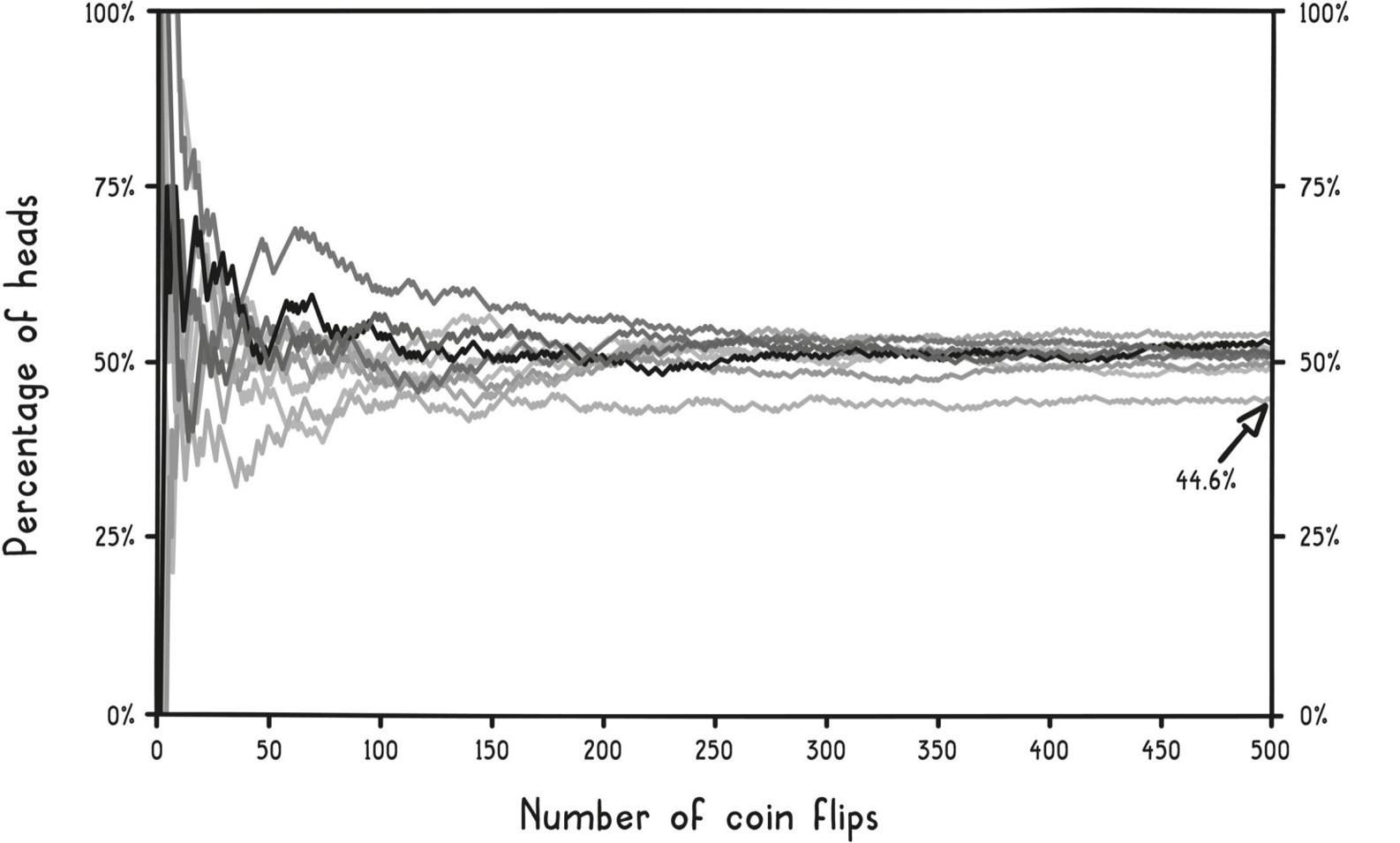
Law of Large Numbers(大數法則)
樣本太小會引發多種錯誤思考:
- 賭徒謬誤(gambler’s fallacy):以為連開十次黑後,下一次出現紅的機率變高。1913 年 Monte Carlo 賭場確實出現過連續 26 次黑(機率 1.37 億分之一),但任何特定 26 次序列的機率同樣低,只是不一樣令人印象深刻
- 集群錯覺(clustering illusion):隨機資料天然會出現連續或群聚。每 20 次擲幣序列中,出現連續 4 次同面的機率高達 50%,看起來「太規律」反而才不像隨機
- 向均值回歸(regression to the mean):極端結果之後通常跟著較典型的結果。樂團首張專輯爆紅、第二張就「江郎才盡」,多半不是心理因素,而是純粹數學
不可能與低機率不同。一百萬分之一的事件,在七十億人的星球上每天都在發生。美國公衛官員每年要調查超過一千件可疑癌症集群,絕大多數其實只是隨機。
不要假設小樣本的結果具代表性;要區分真正的訊號與雜訊,唯一的方法是收集更多資料。
鐘形曲線:分布、變異與中央極限定理#
當資料量大時,會用圖表與**摘要統計(summary statistics)**來壓縮資訊:
- 集中趨勢:平均數(mean)、中位數(median)、眾數(mode)
- 離散程度:全距(range)、四分位距(interquartile range)、變異數(variance)、標準差(standard deviation)
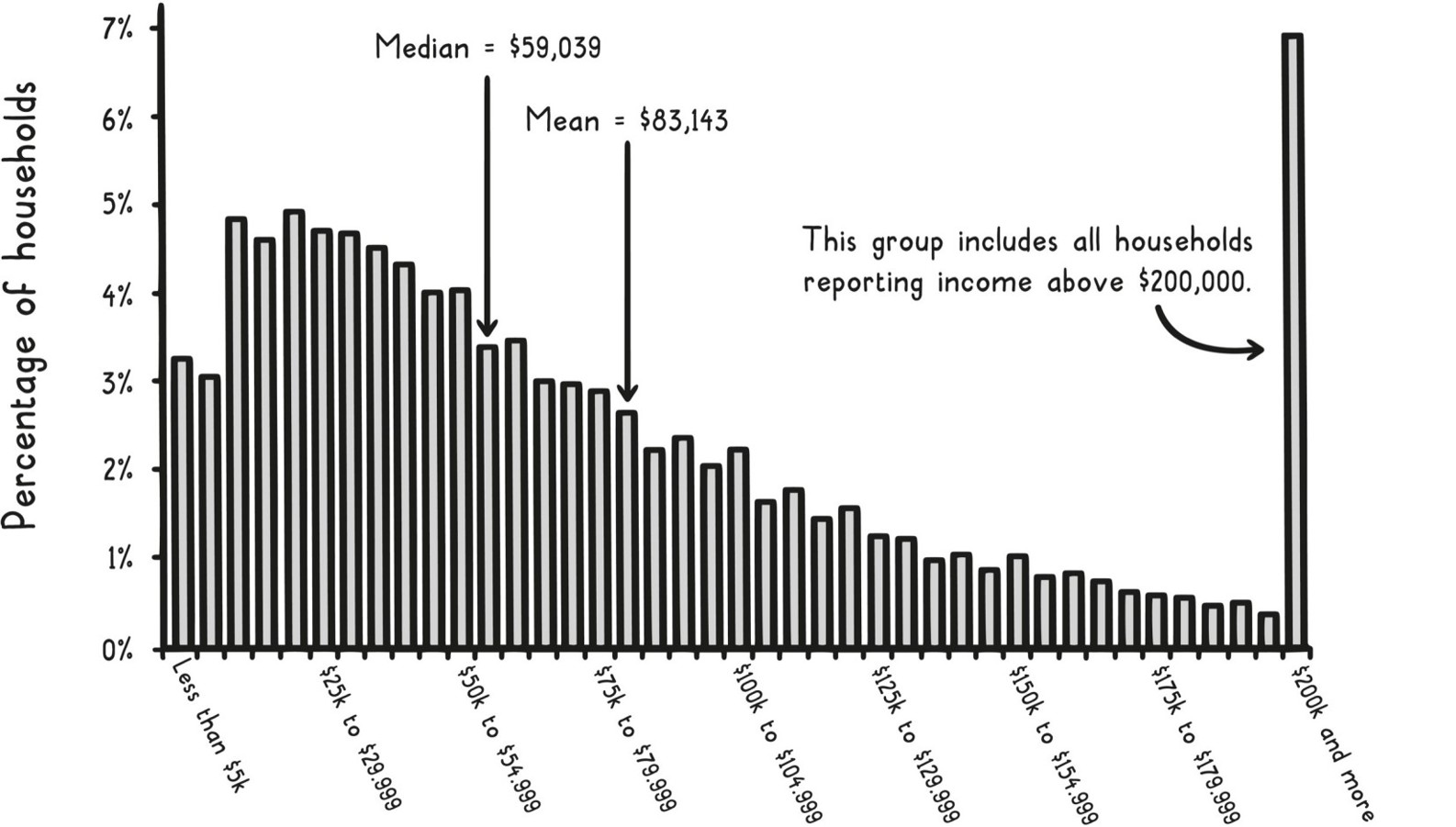
當資料偏斜時(例如美國家庭所得,中位數 5.9 萬美元 vs. 平均 8.3 萬美元),平均數會被極端值拉走,這時中位數比平均數更有代表性。
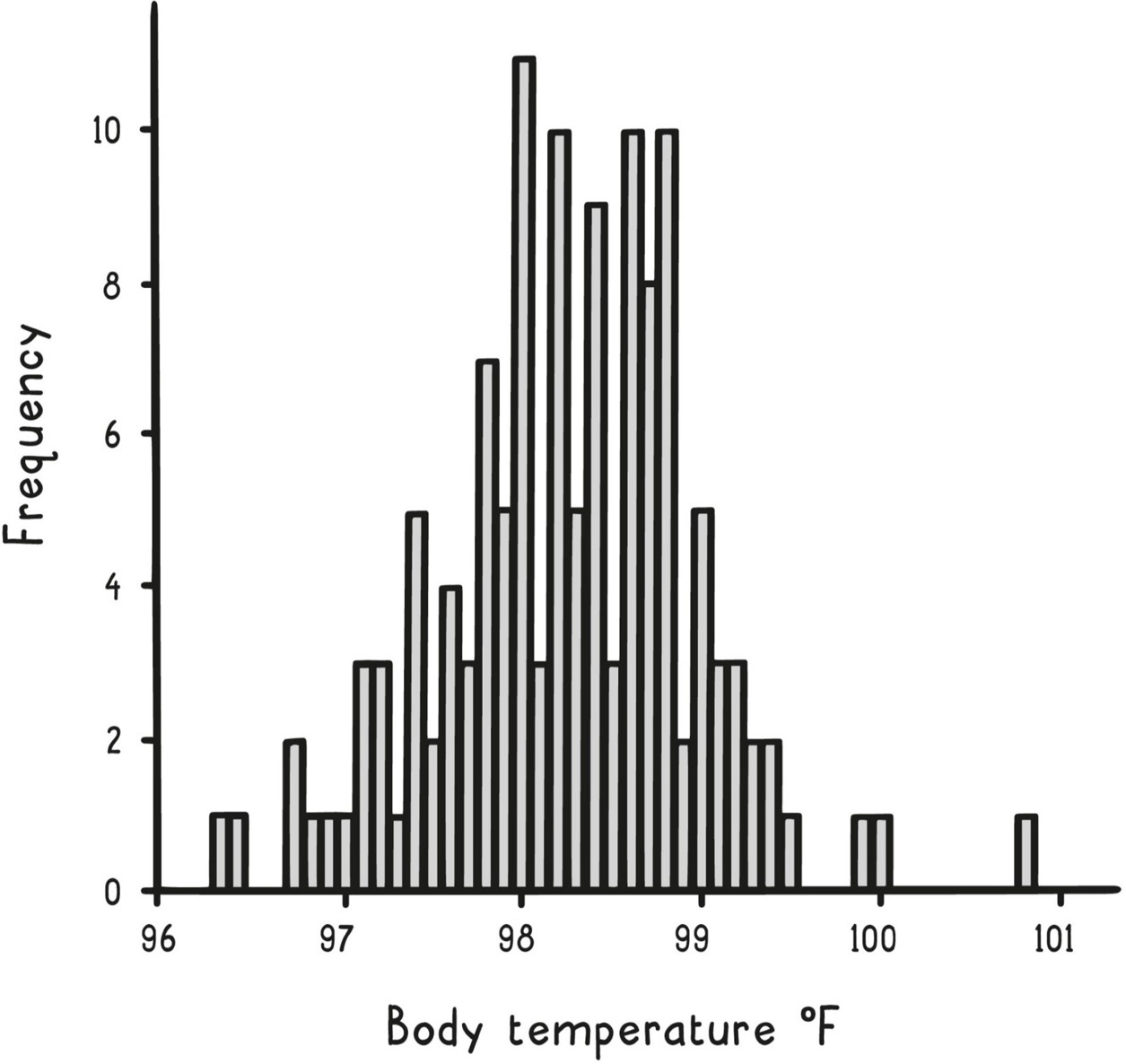
Histogram(直方圖)
很多自然現象——身高、血壓、體溫——的分佈呈現鐘形對稱,被稱為常態分布(normal distribution)。在常態分布下,有個非常實用的記憶法則:
- 約 68% 的值落在平均數 ±1 個標準差內
- 約 95% 落在 ±2 個標準差內
- 約 99.7% 落在 ±3 個標準差內
Variance & Standard Deviation(變異數與標準差)
世界上不只有常態分布,還有許多重要的機率分布(probability distribution):
- 對數常態分布(log-normal distribution):適用於符合冪律的現象,如財富、城市規模、保險損失
- 卜瓦松分布(Poisson distribution):時間或空間區間內的獨立隨機事件,如雷擊次數、城市命案數
- 指數分布(exponential distribution):事件發生的時間間隔,如人或產品壽命、放射性粒子衰變
- 伯努利分布(Bernoulli distribution):單次「是非題」的二元結果,廣告是否成交、A/B 測試是否點擊
常態分布之所以特別好用,是因為中央極限定理(central limit theorem):不管原始資料來自什麼分布,從中抽取樣本並計算平均,這些「樣本平均」近似常態分布。樣本越大,樣本分布越窄、越集中於真實平均。

Central Limit Theorem(中央極限定理)
投票民調的「±3% 誤差」其實是一種信賴區間(confidence interval),搭配信賴水準(confidence level)(通常為 95%)。意思是:如果重複做這個民調很多次,其中約 95% 的區間會包含真實值。
中央極限定理告訴我們:要把民調誤差減半,樣本數需要變成四倍。是非題民調若要 ±10% 誤差只需 96 人;±3% 需要 1,067 人;±2% 則需要 2,401 人。
在媒體看到一個沒有誤差線(error bar)的數字時要警覺——你完全不知道該數字的不確定性有多大。永遠在自己的報告中放上誤差線。
條件機率與貝氏思考#
如果在街上遇到一個陌生人,平均身高的最佳猜測是男女中間。一旦得知對方是女性,最佳猜測就變成 162 公分。這就是條件機率(conditional probability)——在某事件已發生條件下,另一事件的機率。
很多人會犯反向謬誤(inverse fallacy):把 P(A|B) 與 P(B|A) 混為一談。
「九十歲前罹乳癌 | 帶有 BRCA 突變」的機率高達 80%;但「帶有 BRCA 突變 | 九十歲前罹乳癌」只有 5–10%。兩者完全不同。
更系統性的錯誤是基率謬誤(base rate fallacy)——忽略事件本身的底層發生率。經典例子:警察隨機臨檢,酒測儀器有 5% 誤判率,假設酒駕者只佔千分之一,那麼酒測呈陽性的人實際上「真的酒駕」的機率竟然只有約 2%,而非直覺以為的 95%。
連結兩個方向的條件機率的工具,就是貝氏定理(Bayes’ theorem)。它也分隔出統計學的兩大陣營:
- 頻率學派(Frequentist):機率必須建立在大量觀察之上,沒觀察就沒機率
- 貝氏學派(Bayesian):可以引入既有知識作為「先驗(prior)」,再依新資料逐步更新信念
貝氏方法產生的是可信區間(credible interval),可以直觀地說「真值有 95% 的機率在此區間內」——這正是大多數人誤以為信賴區間在說的話。實務上,當資料夠多,兩派結論會收斂到一起。
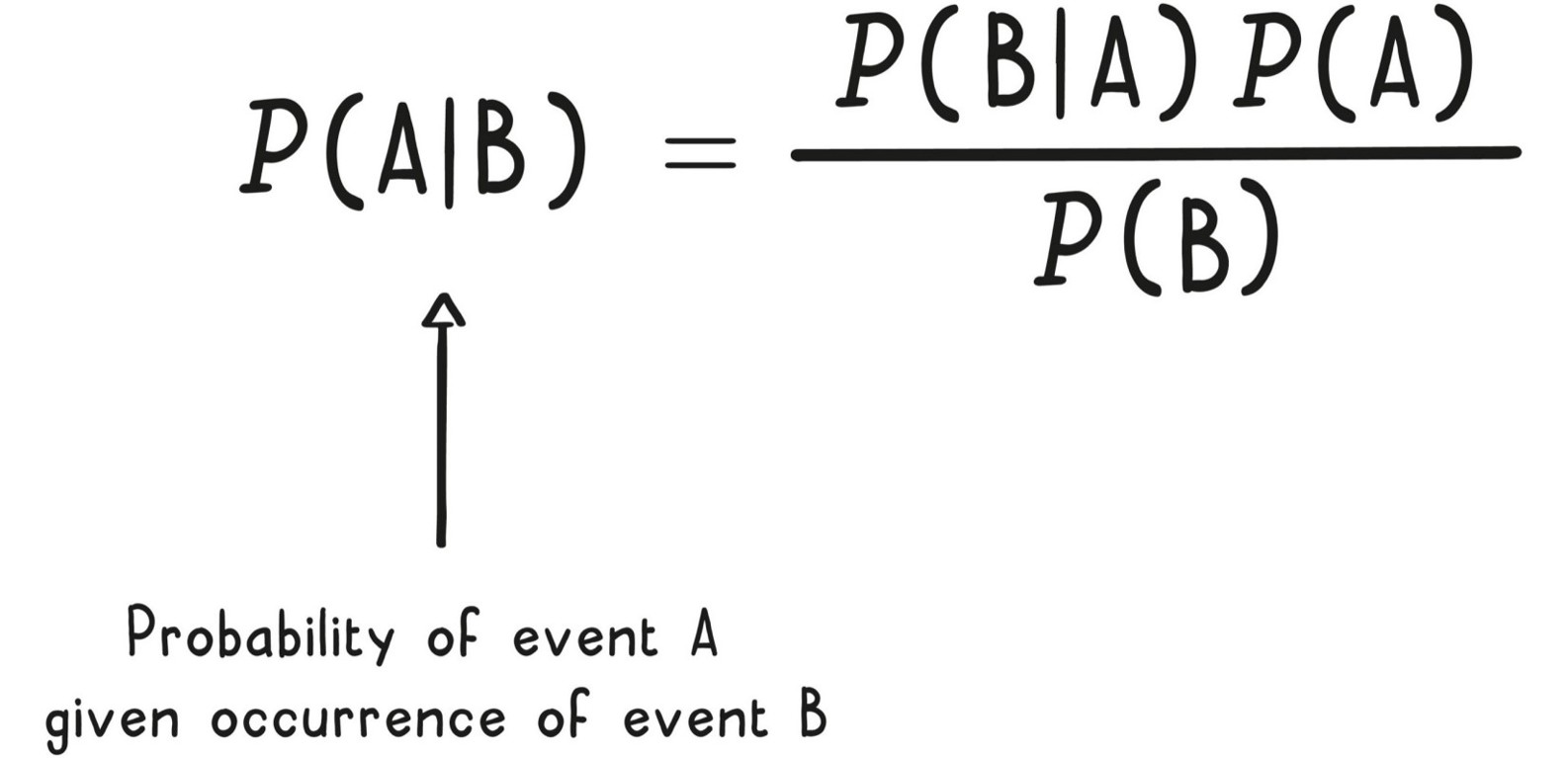
Bayes' Theorem(貝氏定理)
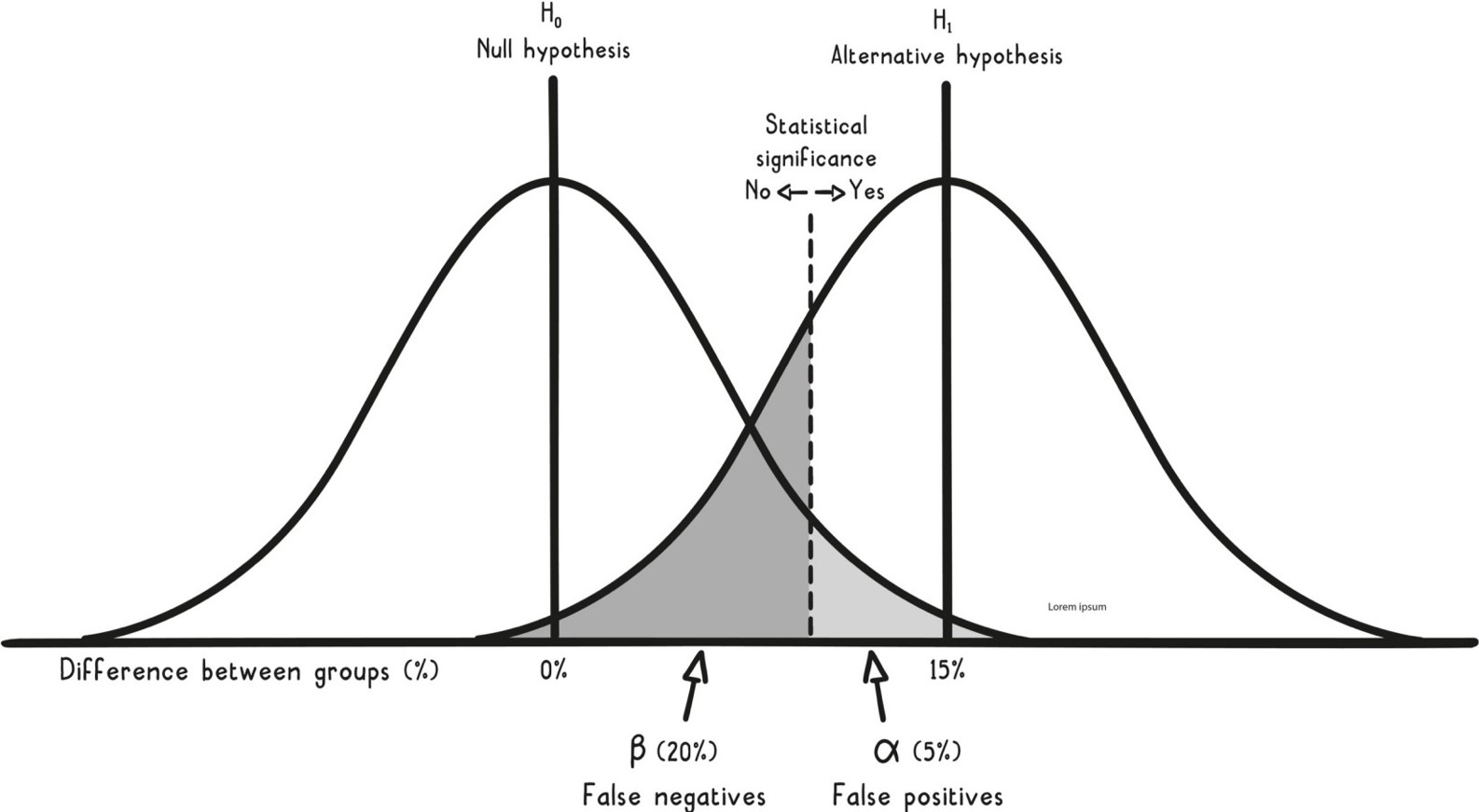
對或錯?型一誤差、型二誤差與檢定力#
任何判斷系統都有四種可能結果:
- 真陽性(true positive)、真陰性(true negative):判斷正確
- 偽陽性(false positive):說有但其實沒有,又稱型一誤差(type I error),發生率以 α 表示
- 偽陰性(false negative):說沒有但其實有,又稱型二誤差(type II error),發生率以 β 表示
設計實驗時要決定容忍多少錯誤率。常見選擇:
- α = 5%(對應信賴水準 95%)
- 1 − β = 80%–90%,稱為實驗的檢定力(power)
美國刑事審判要求「超越合理懷疑」,這是有意識的權衡:寧可放走犯人(偽陰性)也不願冤枉好人(偽陽性)。
實驗的標準框架是先設定虛無假設(null hypothesis)——兩組沒有差異——以及描述「最小有意義差異」的對立假設(alternative hypothesis)。蒐集到足夠證據才能拒絕虛無假設。要偵測的差異越小,所需**樣本數(sample size)**越大。
最常用來宣告結果是否**統計顯著(statistically significant)**的指標是 p 值(p-value):在虛無假設為真的前提下,得到目前或更極端結果的機率。p 值小於選定的 α,就稱為統計顯著。
Statistical Significance(統計顯著性)
美國統計學會在 2016 年明確聲明:「科學結論與商業或政策決策,不應只看 p 值是否跨過某個門檻。」過度聚焦 p 值會把豐富資訊壓縮成單一數字,並掩蓋研究設計上的瑕疵與偏誤。
幾個常被忽略的細節:
- 「沒找到顯著結果」不等於「確認沒有效果」——「證據缺席」不是「缺席的證據」
- 統計顯著 ≠ 實質顯著:樣本夠大時,連 1% 的差異都能達到統計顯著,但對使用者毫無意義
- 與其只看 p 值,不如同時看「效果大小 + 信賴區間」
再現性危機#
在心理學等領域,當研究人員嘗試重新驗證已發表的「正面結果」時,能成功再現的不到 50%——這就是再現性危機(replication crisis)。
如果偽陽性平均只能再現 5%、真陽性可再現 80%,要讓再現率落在 50%,意味著原始研究中約有 40% 是偽陽性。這比理論上的 5% 高出許多,原因包括:
- 資料浚渫(data dredging)/ p-hacking:對同一份資料反覆測試直到找到顯著結果。著名的 XKCD 漫畫描繪研究者測試 21 種顏色軟糖直到「綠色軟糖致痘」p 值夠小
- 發表偏誤(publication bias):期刊偏好顯著結果,負面結果常常未被發表,導致不同團隊重複嘗試同樣失敗的假設
- 隱性偏誤滲入:選擇偏誤、倖存者偏誤等
- 向均值回歸:原始研究碰巧捕捉到極端效果,再現研究的真實效果其實小很多
要提升研究可信度,可以:
- 採用更嚴格的 p 值門檻來校正多重檢定
- 使用更大的樣本以偵測較小的真實效果
- 在實驗開始前就預先註冊(pre-register)要做的統計檢定,避免事後 p-hacking
評估任何單一研究時要保持懷疑。理想狀況下,應該尋找已經完成的系統性回顧(systematic review)或統合分析(meta-analysis)——這類研究有計畫地整合既有所有研究,是醫療指南與政策制定的依據。
統合分析能提高估計的精確度,但也有侷限:研究設計差異過大時不宜合併、原始研究的偏誤會被一起繼承、發表偏誤無法消除。
本章核心要點#
- 別陷入賭徒謬誤與基率謬誤
- 軼事與相關只能用來「產生假設」;要建立可信結論仍須仰賴設計良好的實驗
- 偏好已被驗證的設計:隨機對照實驗或 A/B 測試,並注意統計顯著性
- 常態分布在實驗分析中特別有用,靠的是中央極限定理;記住 68% 落在 ±1σ、95% 落在 ±2σ
- 任何單一實驗都可能產生偽陽性或偽陰性,並可能受選擇偏誤、回應偏誤、倖存者偏誤等影響
- 再現能提高結論的可信度——研究新領域時,先找系統性回顧或統合分析
- 處理不確定性時,所有報告數字本身也都帶有不確定性;永遠尋找並標示誤差線
統計學不是治癒不確定性的魔法,但它讓你能更誠實地描述自己對各種結果的信心。如統計學家 Andrew Gelman 所言:我們必須「更願意接受不確定性,並擁抱變異」。