專案開始時最大的問題是:我們到底在蓋什麼?我們大概知道系統的輪廓,但總有未知的角落和尚未定案的設計細節。傳統的瀑布式流程試圖透過冗長的前期需求蒐集來消除這些不確定性,但 Scrum 團隊採取截然不同的做法——以 just-in-time 的方式處理需求。
Product backlog(產品待辦清單)是一份列出所有尚未實現功能的清單,由 product owner 維護並按優先順序排列,因此有時也被稱為 prioritized feature list。它與傳統需求文件的最大不同在於,它是高度動態的——每個 sprint 都會新增、移除和重新排序項目。
本章探討三個關鍵轉變:從撰寫文件轉向對話討論、漸進式細化需求,以及以範例說明取代傳統規格書。
從文件轉向對話(Shift from Documents to Discussions)#
關於需求有一個重大迷思:只要把需求寫下來,使用者就會得到他們想要的東西。事實並非如此。書面文字具有誤導性——它們看起來比實際上更精確。
作者舉了一個經典案例:他寄信請助理預訂丹佛的凱悅酒店,助理回信說「酒店已 booked」。一週後才發現「booked」的意思是「已客滿」而非「已預訂」。如果當時是對話而非電子郵件,語調早就暴露了誤解。
為什麼對話優於文件#
- 書面文件會讓你暫停判斷:當某件事被寫下來,特別是經過精美排版後,它看起來很正式、很完整。人們傾向於不去質疑它
- 書面文件缺乏意義的迭代確認:在對話中,我們會自然地透過「所以你的意思是…」、「如果我理解正確…」等方式反覆確認理解。這種迭代在文件中是缺失的
- 書面文件削弱全團隊責任感:文件創造了順序式的交接——一個人定義產品,另一群人建造它。這種主僕關係不利於團隊投入感。對話則相反:全團隊討論帶來更高的認同感
不要把嬰兒和洗澡水一起倒掉#
這些書面溝通的弱點並不意味著我們應該完全拋棄文件。Agile Manifesto 說的是「重視可運作的軟體勝過詳盡的文件」,而非「不要寫文件」。目標是找到文件與對話之間的正確平衡。
程式碼和自動化測試本身就是一種文件形式。經驗豐富的 Scrum 團隊會善用這些產出物,僅在法規、合約或法律要求時才補充書面需求文件。Tom Poppendieck 說得好:「當文件主要是為了實現交接,它們是有害的;當它們記錄了最好不要被遺忘的對話,它們是有價值的。」
使用 User Stories 來管理 Product Backlog#
User stories 是將焦點從撰寫功能轉向討論功能的最佳方式。一個 user story 是從使用者或客戶的角度出發的簡短功能描述,通常遵循以下模板:
As a <type of user>, I want <some goal> so that <some reason>.
User stories 通常寫在索引卡或便條紙上。重要的是,卡片上的文字不是完整的功能描述,而是開發團隊與 product owner 之間的雙向承諾:
- 團隊承諾在開始工作前會與 product owner 討論
- Product owner 承諾在團隊準備好討論時會到場
使用索引卡這種輕量級媒介正是刻意為之——它時刻提醒著團隊,卡片不需要包含所有細節,細節會在對話中浮現。
雖然 user story 格式中的 user 聽起來很侷限,但它適用於各種領域。例如:“As the loan authorization system, I want to receive all data as valid, well-formed XML so that I don’t have to worry about syntax checking.” 也是完全合理的 user story。
跨職能團隊降低文件需求#
常見的反對意見是:沒有規格文件,QA 團隊怎麼知道要測試什麼?在 Scrum 之前的組織中這確實是問題——程式設計師自行決策,然後透過規格文件將決定傳達給測試人員。但在 Scrum 團隊中,程式設計師和測試人員是同一個跨職能團隊的成員,測試人員應該參與到討論中,而不是等待文件被交付。
作者在前敏捷時代的經驗啟發了一個實用做法:讓從文件受益的人來撰寫和維護文件。因為測試人員是詳細規格的主要受益者,所以由測試人員來撰寫。這不僅解決了文件過期的問題,還促使程式設計師和測試人員更早、更頻繁地交流。
漸進式細化需求(Progressively Refine Requirements)#
無論在專案初期多努力地識別所有需求,我們永遠不可能成功。總有一些東西是使用者和開發者在看到系統逐漸成形之前無法想到的。
浮現式需求(Emergent Requirements)#
那些我們無法預先識別的功能被稱為 emergent requirements(浮現式需求)。它們存在於每個非平凡的專案中,使得完美預測時程成為不可能的任務。
在傳統瀑布式流程中,浮現式需求被視為計畫的失敗。但在 Scrum 中,團隊接受需求必然會浮現,並將其視為規劃過早或過於詳細的結果,而非計畫的失敗。
處理浮現式需求的第一步是承認我們無法想到所有事情。一旦接受這個前提,就更容易接受我們不需要一份完美的前期需求文件。相反,我們應該根據功能被開發的時間點,以不同的精確度來描述它們。
Product Backlog 冰山#
Product backlog 天然地呈現冰山形狀:
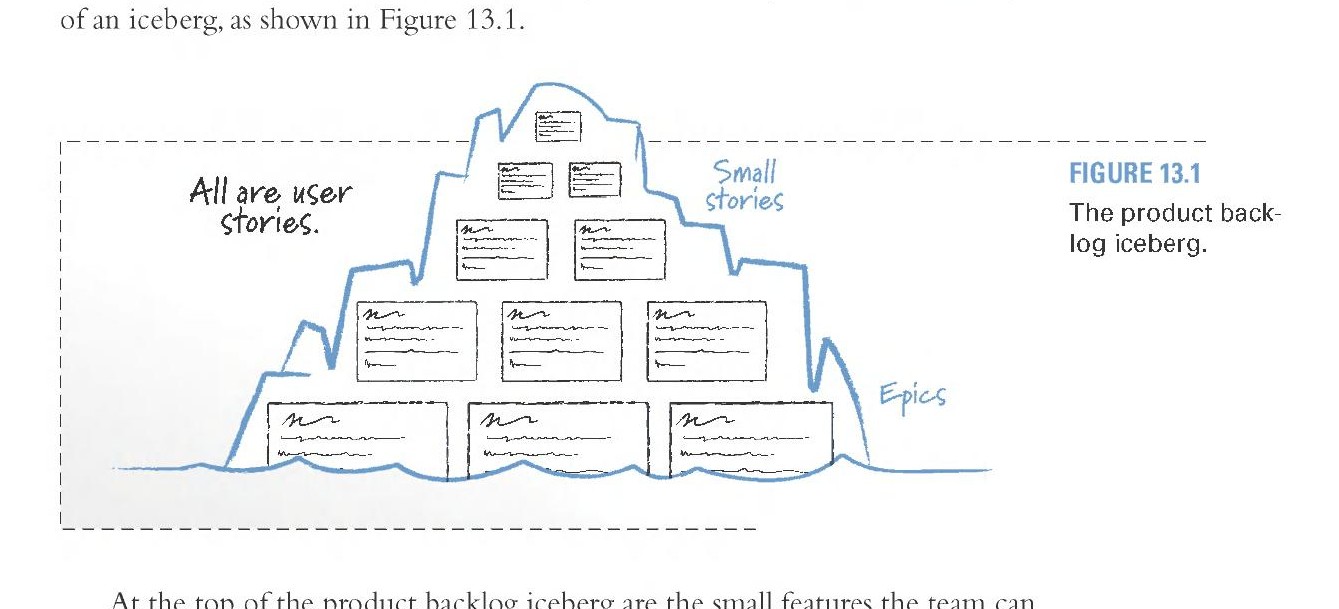
Figure 13.1: The product backlog iceberg
- 冰山頂端:即將開發的小型 user stories,細節充足,可在單一 sprint 內完成
- 冰山中段:較大且細節較少的 stories
- 水面以下:巨大的 epic stories,僅有粗略的估算和優先順序
- 水線之下不可見處:連討論都還沒發生的功能
梳理 Product Backlog(Grooming)#
隨著冰山頂端的項目被開發和移除,冰山頂部會變平。為了維持冰山形狀,團隊需要定期花時間 grooming(梳理)product backlog——將大的 stories 拆分為小的、為即將到來的項目補充細節、重新估算和排序。
經驗法則是每個 sprint 大約花 10% 的時間來梳理 backlog,為未來的 sprint 做準備。
團隊的目標不是在每個 sprint 開始時就完美理解所有要開發的項目。相反,我們追求的是 just-in-time、just-enough 的方式——功能只需在 sprint 開始時被「充分理解」(sufficiently understood),而非「完全理解」(fully understood)。大的功能在往冰山頂端移動時才被拆分和補充細節。
為什麼要漸進式細化需求#
漸進式細化有三個核心原因:
- 事情會改變:專案進行過程中優先順序會轉移,原本重要的功能可能變得不再重要。最可能改變的是那些離開發最遠的功能,因此只需高層級描述即可
- 沒有必要:軟體開發如同在霧中夜間行車——你只能看到車頭燈照到的距離,但你仍然可以這樣完成整趟旅程。冰山形狀的 backlog 提供了足夠的能見度
- 時間是稀缺的:將所有需求同等對待是浪費。我們應該保護最寶貴的資源——時間
User Stories 的漸進式細化#
敏捷需求流程必須支持在 product backlog 冰山的各個層級創建需求。團隊需要能夠輕鬆地在冰山底部建立大型的佔位需求,之後將它們拆解為中型項目,最終拆成小到可以在單一 sprint 完成的工作。
Epic(史詩故事)是一個需要超過一到兩個 sprint 才能完成的大型 user story。例如:
As a user, I am required to log into the system so that my information can only be accessed by me.
看似簡單,但如果 product owner 澄清這涵蓋了所有與登入相關的功能(新增密碼、變更密碼等),它可能需要兩到三個 sprint。因此在開發前,需要被拆分為更小的 stories:
- 以使用者名稱和密碼登入
- 建立新帳號
- 變更密碼
- 密碼過於簡單時發出警告
- 忘記密碼時請求新密碼
- 登入失敗時不顯示是帳號還是密碼錯誤
- 連續三次登入失敗時發出通知
有些 epic 非常龐大,拆分時會先分成中型的 stories(可能本身也是 epic),再進一步拆成小 stories。拆分應該以 just-in-time 的方式進行——在團隊即將開發前才拆分。
添加滿足條件(Conditions of Satisfaction)#
當 stories 小到無法再拆分時,透過添加 conditions of satisfaction 來繼續細化。滿足條件是 user story 完成後必須為真的高層級驗收測試。例如:
As a vice president of marketing, I want to select a holiday season to be used when reviewing the performance of past advertising campaigns so that I can identify profitable ones.
其滿足條件可能包括:
- 支援主要零售節日:聖誕節、復活節、總統日、母親節等
- 支援跨兩個日曆年的節日(不跨三個)
- 節日季節可以從一個節日設定到下一個節日
- 節日季節可以設定為節日前若干天
這些條件告訴團隊 product owner 對功能的期望——包括會包含什麼和不會包含什麼。
學會在沒有規格書的情況下開始(Learn to Start Without a Specification)#
Scrum 團隊將焦點從撰寫需求轉向討論需求,並在專案過程中漸進式地細化需求,因此團隊必須學會在沒有傳統規格書的情況下舒適地開始工作。
適當使用規格文件#
目標不是丟棄有用的文件,而是適當地使用它們。規格文件的主要適當用途是傳達最適合以書面形式表達的資訊——例如科學和數學應用中的複雜計算。
規格文件的一個危險是它們很少被保持更新。在撰寫文件之前,問問自己是否願意承諾持續更新它。如果不願意,考慮在文件上加一個「有效期限」,就像牛奶盒上的保存期限一樣。
以範例說明(Specification by Example)#
Specification by example 是一種強大的替代方案。範例是溝通系統期望行為的絕佳方式,特別是搭配對話和少量解釋文字時效果更好。
例如,假設我們要建造一個自動批准休假申請的系統。Product owner 寫了一個 user story:“As an employee, I want a request for up to my earned vacation time to be automatically approved so that I don’t need to wait for someone to approve it manually.” 然後透過範例來細化:
| days_accrued | days_requested | approved? |
|---|---|---|
| 6 | 5 | Yes |
| 5 | 6 | No |
| 5 | 5 | Yes |
隨著需求變得更複雜(例如加入年資超過一年的員工可多請五天的規則),範例表格也會擴展,增加更多欄位(如 employed_over_1_year)和測試案例。當場景越來越複雜時,specification by example 的威力就越明顯——透過對話和範例的結合,product owner 所要求的與開發者所建造的更可能一致。
Specification by example 的終極威力在於:這些範例可以直接轉化為自動化測試。當規格過期時,我們可以立即透過執行測試來發現——如果測試通過,說明應用程式符合規格;如果不通過,說明規格或程式需要更新。測試變成了自我驗證的規格。
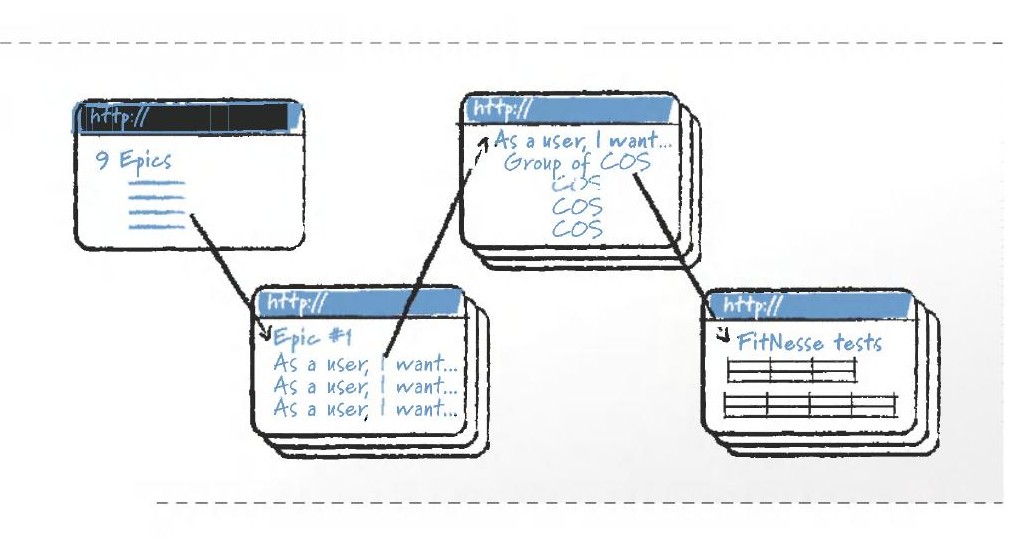
Figure 13.2: A series of FitNesse wiki pages for acceptance tests
挪威的敏捷專案經理 Trond Wingard 的團隊大量使用 FitNesse wiki 來建立可執行的測試和規格。他們的政策是:所有需求和測試都必須在 FitNesse 中,沒有例外。首頁包含九個 epic 的連結,每個 epic 頁面列出其 user stories,每個 story 頁面描述 story 內容並列出 conditions of satisfaction 群組,每個群組都有對應的 FitNesse 測試。
讓 Product Backlog 保持 DEEP#
作者與 Roman Pichler 共同提出 DEEP 這個縮寫來描述好的 product backlog 的關鍵屬性:
- Detailed Appropriately(適當的細節度):即將開發的 user stories 需要足夠詳細以便在 sprint 中完成;較遠期的 stories 則以較少細節描述即可
- Estimated(已估算):Product backlog 不僅是工作清單,也是規劃工具。越往下的項目估算越不精確,這是正常且預期的
- Emergent(浮現的):Product backlog 不是靜態的,它會隨著學習的增加而持續變化——新增、移除或重新排序 user stories
- Prioritized(已排序):最有價值的項目排在最上面。團隊始終按優先順序工作,從而最大化產品的價值
別忘了對話(Don’t Forget to Talk)#
雖然專案的 product backlog 會被寫在某處——索引卡上或軟體工具中——但它不是傳統需求文件或 use case model 的一對一替代品。與 backlog 上的文字同等重要的是圍繞它的對話。這些對話發生在團隊和 product owner 共同腦力激盪初始 backlog 項目時,也發生在 sprint 期間團隊漸進地細化對功能的理解時。
在改善團隊對 product backlog 的使用時,不要忘記這些對話的重要性。