SQL Server 2022 的分析整合是 Synapse Link,但客戶並不喜歡必須搭配 Synapse Dedicated Pool。他們真正想要的是「從 SQL Server 到 data lake 的近即時分析」——這就是 Fabric Mirroring 的起點。
命名小故事:SQL Server 早期的 Database Mirroring 是 Always On Availability Groups 的前身。雖然名字會撞車,最後 Fabric 團隊仍選用 Mirroring 一詞。
本章帶你認識 Microsoft Fabric 與 SQL Server 2025 的整合方式:透過 Fabric Mirroring 把 SQL Server 資料近即時同步進 Fabric 的 OneLake,並進一步用 Lakehouse、Power BI、Data Agent 編織出統一的資料故事。
Microsoft Fabric 介紹#
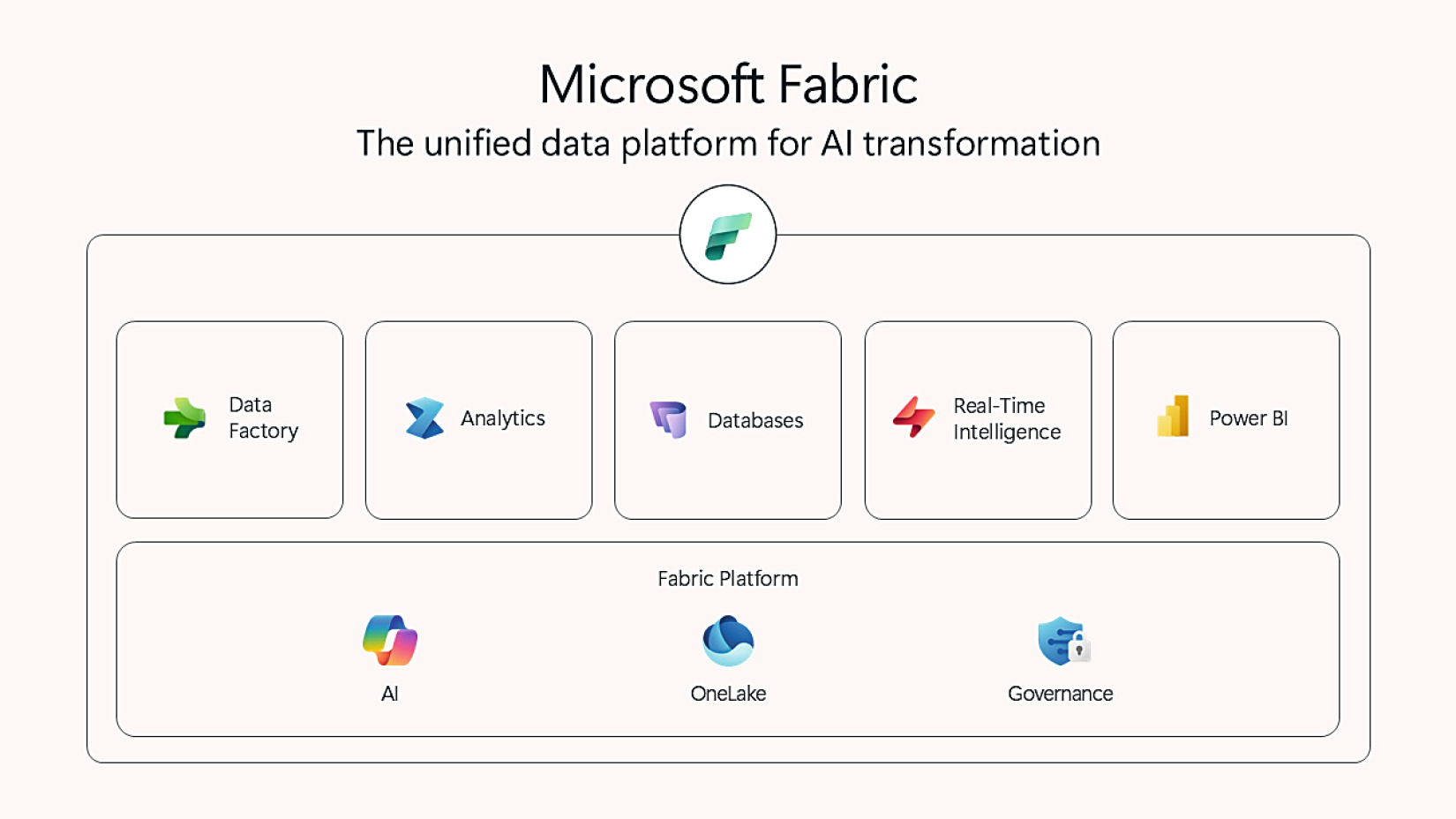
Figure 8-1: Microsoft Fabric
Fabric 從「unified analytics platform」進化為「unified data platform」,因為它納入了資料庫服務(如 SQL Database、Cosmos DB)。
服務與解決方案#
| 元件 | 說明 |
|---|---|
| Data Factory | 資料移動、轉換 |
| Analytics | 倉儲、機器學習、Notebook、Spark |
| Databases | SQL Database 與 Cosmos DB 都可在 Fabric 中部署 |
| Real-Time Intelligence(RTI) | 串流資料的事件驅動分析 |
| Power BI | 自服務報表平台 |
横跨所有服務的關鍵能力#
AI#
AI 是 Fabric 各服務的中樞——Copilot、AI Services、AI Functions,以及 SQL Database in Fabric 內建的向量搜尋(與第 4 章相同的 SQL AI 能力)。
OneLake#
Amir Netz 形容 OneLake 為「OneDrive for your data」。
- 真正的企業資料 lake
- 跨 Fabric 體驗統一
- 推薦以 Delta Parquet 格式存放——這正是 Fabric Mirroring 的目的端
- Lakehouse 是 OneLake 上的核心抽象
Governance#
- 與 Microsoft Entra 整合
- Microsoft Purview 提供 Data Catalog、Information Protection、Data Loss Prevention(DLP)、Audit
其他特色#
- 服務之間互通:PySpark Notebook、AI Functions、User Data Functions、pipelines、taskflow、ALM
- 統一 UI:Fabric portal;以 Workspaces 組織資源(類似 Azure resource group)
- Capacity Model:以 Fabric Capacity Units(CUs) 計費,整體共享
全產品 roadmap:
https://aka.ms/fabricroadmap
SQL Mirroring 全景#
「Fabric Mirroring 是一個低成本、低延遲的方案,把不同系統的資料匯聚到單一分析平台。」
— Microsoft 官方定義
為何需要 Mirroring#
許多客戶想要的並非另建 replication subscriber 或 AG secondary,而是:
- 把讀取工作 offload 到 OneLake
- 在 Fabric 中與其他資料整合,享有統一的分析、AI、報表體驗
Mirroring 的覆蓋範圍#
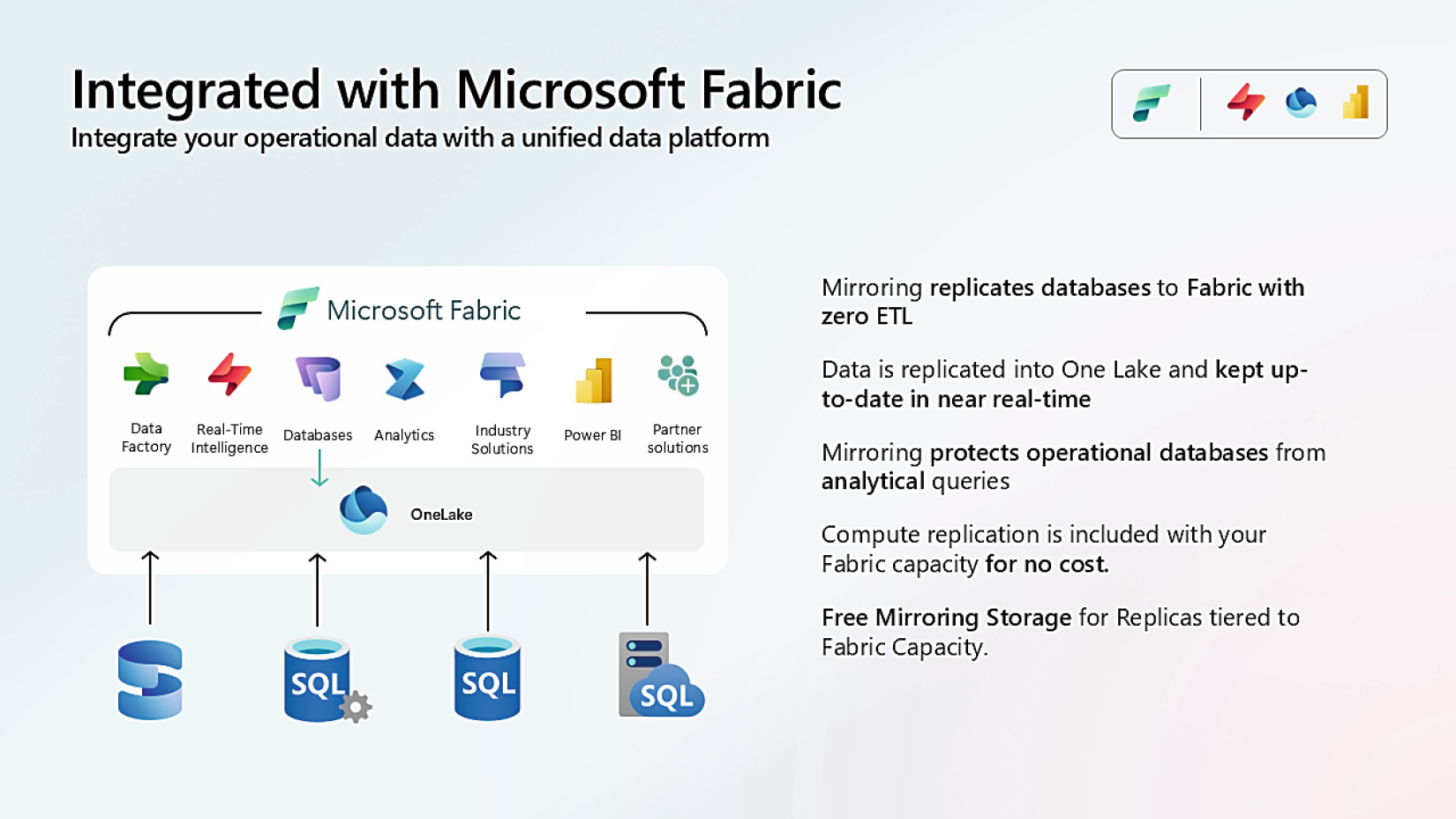
Figure 8-2: SQL 全面覆蓋的 Mirroring
SQL Server 2025 公開預覽釋出時的支援狀態:
來源 狀態 機制 Azure SQL Database GA 強化版 Synapse Link change feed Azure SQL Managed Instance Public Preview 同上 SQL Server 2025 Public Preview 同上 SQL Server 2016–2022 Public Preview 透過 Change Data Capture(CDC) SQL Database in Fabric 自動 mirror 進 OneLake
計費#
Mirror 後在 OneLake 的儲存空間免費——每單位 CU 享 1TB(例:F32 capacity = 32TB 免費)。但實際查詢 mirrored data 時,會依 Fabric Capacity Units 共享計費。
計價:
https://azure.microsoft.com/pricing/details/microsoft-fabric/#pricing
SQL Server 2025 Fabric Mirroring 架構#
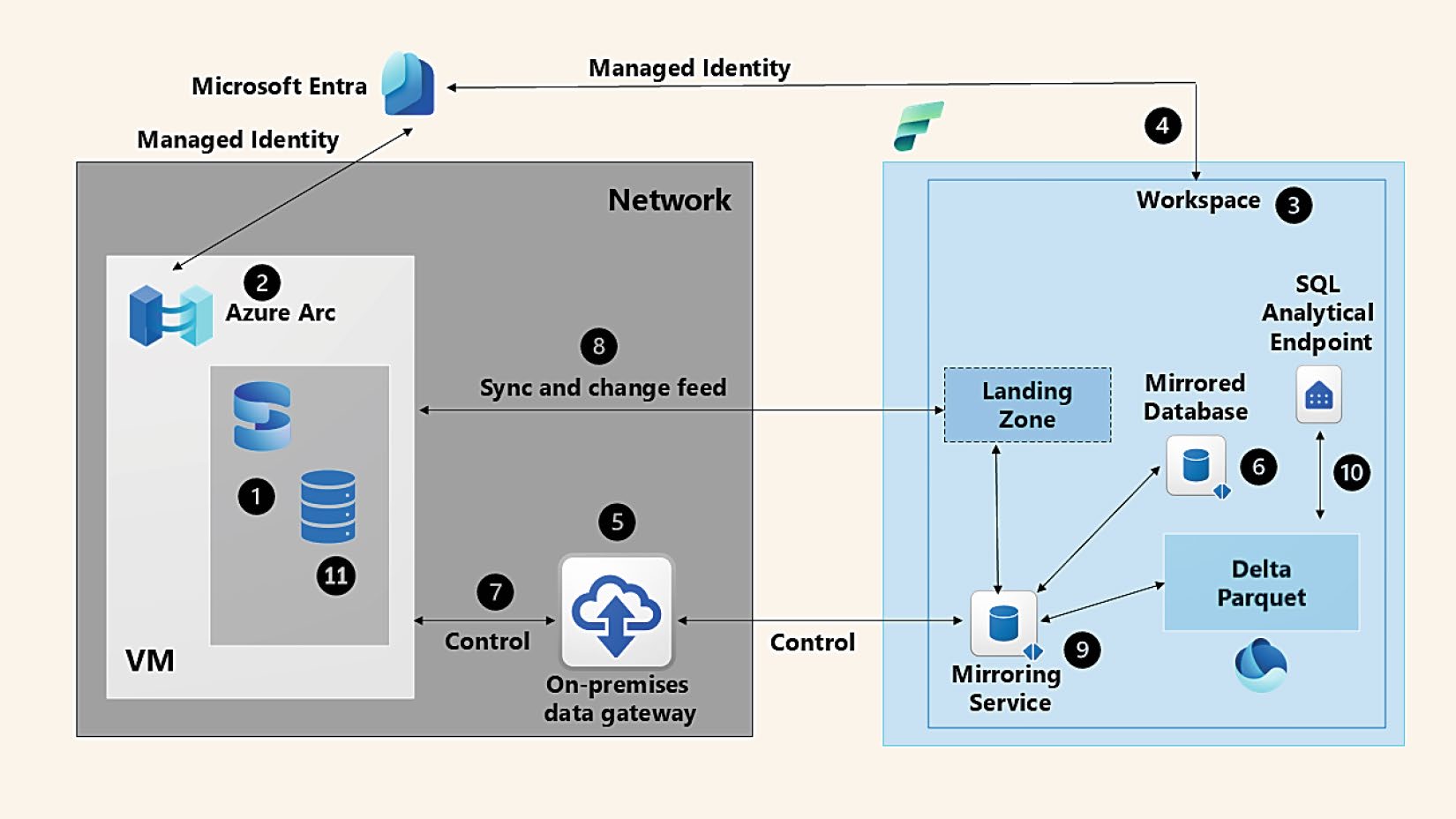
Figure 8-3: SQL Server 2025 的 Fabric Mirroring 架構
flowchart LR
A["1\. SQL Server 2025"] --> B["2\. Azure Arc + Managed Identity"]
B --> C["8\. SQL Server 背景執行緒同步資料"]
C --> D["Landing Zone"]
D --> E["9\. Mirroring 服務轉成 Delta Parquet"]
E --> F["10\. OneLake 中的 Mirrored Database"]
F --> G["SQL Analytics Endpoint(讀)"]
H["3\. Fabric workspace"] --> F
I["4\. 把 Managed Identity 指派給 workspace"] --> H
J["5\. On-premises Data Gateway(OPDG)"] -- "7\. 控制平面(系統 SP)" --> A
H -- "6\. 建立 Mirrored Database 並啟動" --> J11 個流程步驟(節錄要點)#
- SQL Server 2025:以資料庫為單位選擇要 mirror 的 table
- Azure Arc + Managed Identity:給 SQL Server 寫入 Landing Zone 的權限
- 建立 Fabric workspace
- 指派 Managed Identity 權限到 workspace(AG secondary 場景才需要)
- 部署 OPDG(On-premises Data Gateway)作為控制平面
- 建立 Mirrored Database 並選表
- OPDG 透過系統 SP 在 SQL Server 啟用 mirror
- 背景執行緒同步選定資料表至 Landing Zone
- Mirroring service 把 Landing Zone 內的資料轉成 Delta Parquet 寫入 OneLake
- SQL Analytics Endpoint 提供唯讀的 TDS 相容查詢端點
- 任何後續變更 由 transaction log 背景擷取送進 Landing Zone,自動更新 Delta Parquet
SQL Server 2016–2022 的差別:OPDG 同時兼任控制平面與資料平面——透過 CDC 訊息把資料拉到 Fabric。
Delta Parquet(實際是 Fabric 採用的 Delta verti-parquet)能對 Parquet 檔做交易式更新——這是 Fabric Mirroring 能做到「近即時」的關鍵。
注意事項與限制#
公開預覽期間的限制(GA 後可能變更,請追蹤
https://learn.microsoft.com/fabric/database/mirrored-database/sql-server-limitations):
- 只有 AG primary 支援 mirror
- 不能與 CDC、Change Event Streaming(CES)、Replication 並存
- 一個資料庫最多 mirror 500 張資料表(資料庫大小不限)
- 來源端的 RLS、Object-Level Permissions、DDM 不會 propagate 到 OneLake;OneLake 自有權限系統
- 不支援的 DDL:partition operations、修改 primary key
- 只能 mirror 資料表(不可 mirror view、stored procedure、function)
- 可建立 Resource Governor resource pool 管理 mirroring 使用的資源
Mirror 只送 committed transaction;交易不會被卡住,但 transaction log truncation 可能因延遲而延後。
範例:把 AdventureWorksLT mirror 到 Fabric#
前置條件#
- SQL Server 2025(Developer / Enterprise)
- 還原 AdventureWorksLT(注意 UDT 不支援 mirror,需先用
alteradwltsql2025.sql把 UDT 換成原生型別) - Azure Arc + Microsoft Entra + system-assigned Managed Identity
- Fabric Capacity(無付費可用
https://aka.ms/fabrictrial) - 建立 Fabric workspace(範例命名:
adwspace) - 把 system-assigned Managed Identity 指派給 workspace(僅 AG secondary 必要)
- 部署 On-premises Data Gateway:與 Fabric 同帳號登入
Figure 8-4: On-premises Data Gateway 安裝完成
在 Fabric 建立 Mirrored Database#
- workspace ➜ + New Item ➜ Mirror SQL Server
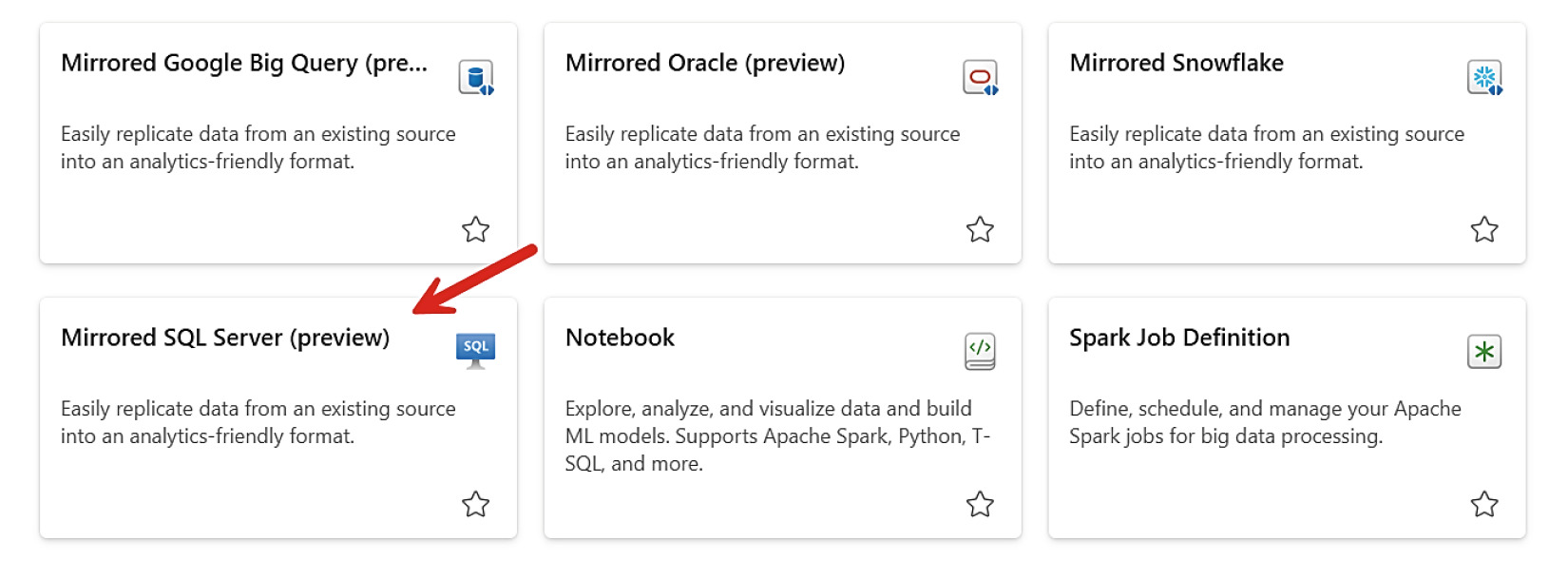
Figure 8-5: 在 Fabric Portal 新增 Mirror SQL Server 項目
- 連線設定:
- Server:本機填
. - Database:
AdventureWorksLT - Data gateway:選擇剛安裝的 OPDG
- Authentication kind:可用 Windows、SQL、Microsoft Entra(範例使用還原資料庫的 Windows 帳號)
- Privacy Level:
None - 取消勾選 Use encrypted connection(若使用 SQL Server 自簽憑證)
- Server:本機填
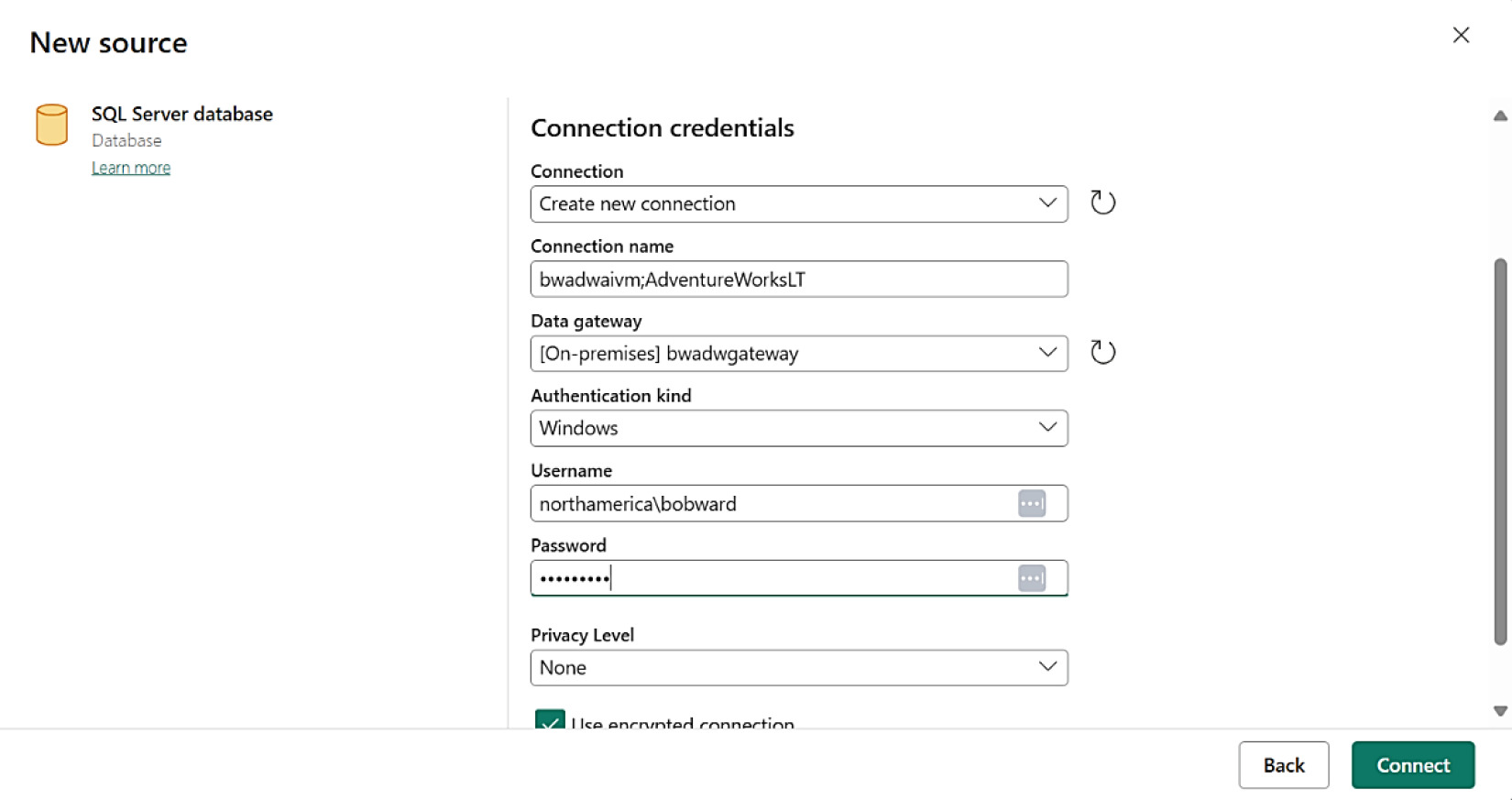
Figure 8-6: 為 Mirroring 建立新的連線
- 選 mirror 的 table:
Customer、CustomerAddress、Address
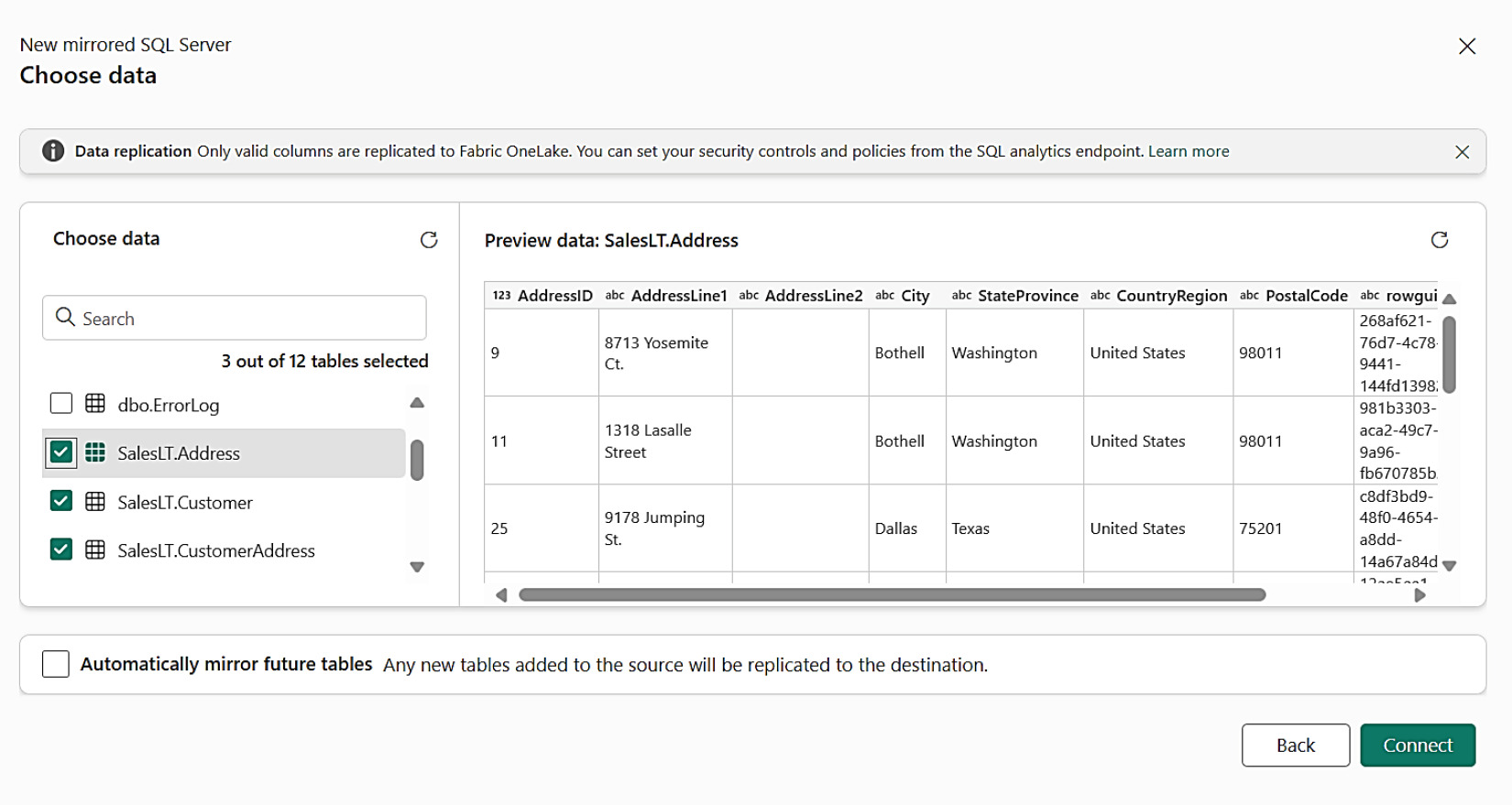
Figure 8-7: 選擇要 Mirror 的資料表
- 命名 destination:例如
AdventureWorksCustomers,建立後啟動 mirror - 等待初始同步完成
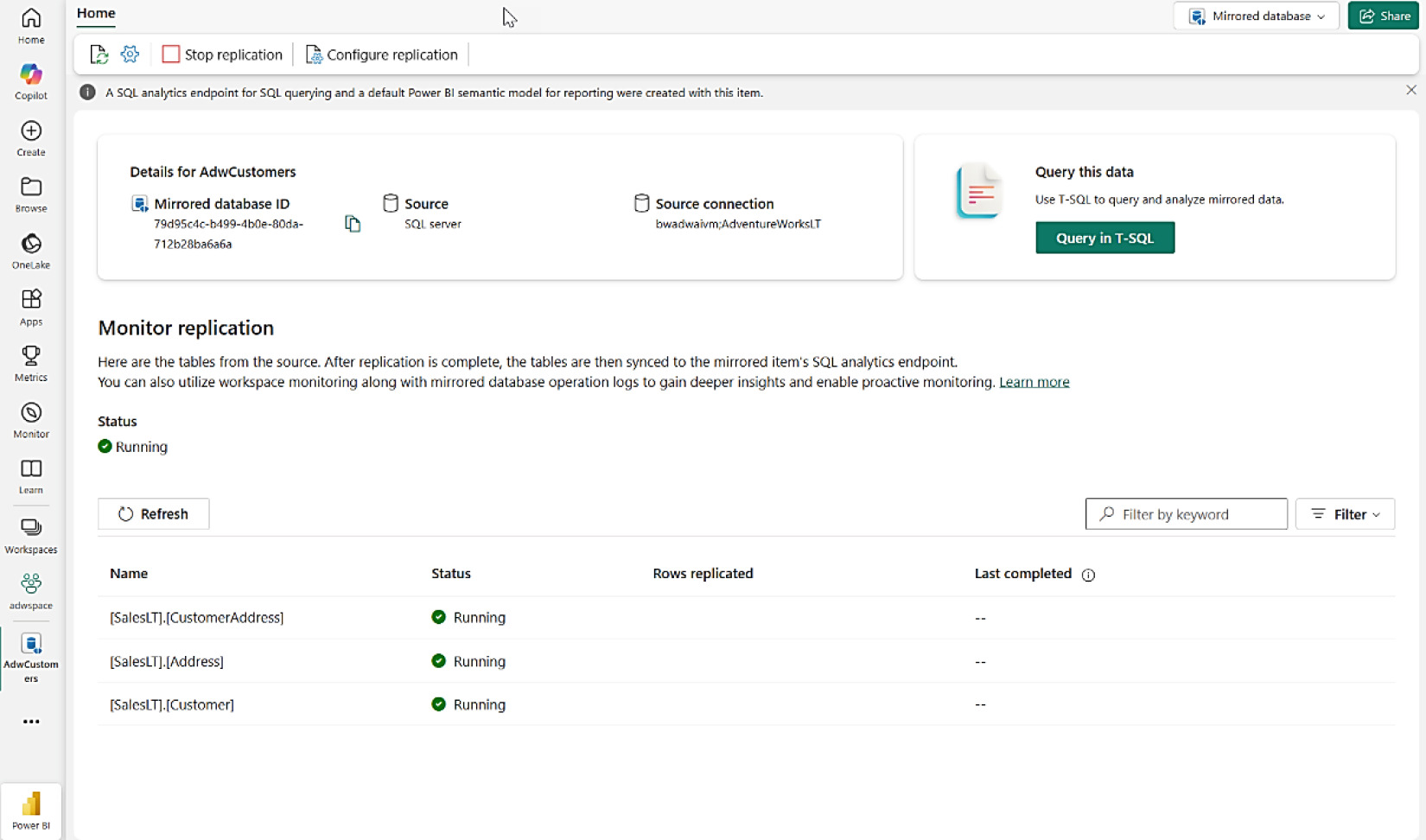
Figure 8-8: 監控 SQL Server 2025 的 Fabric Mirroring 狀態
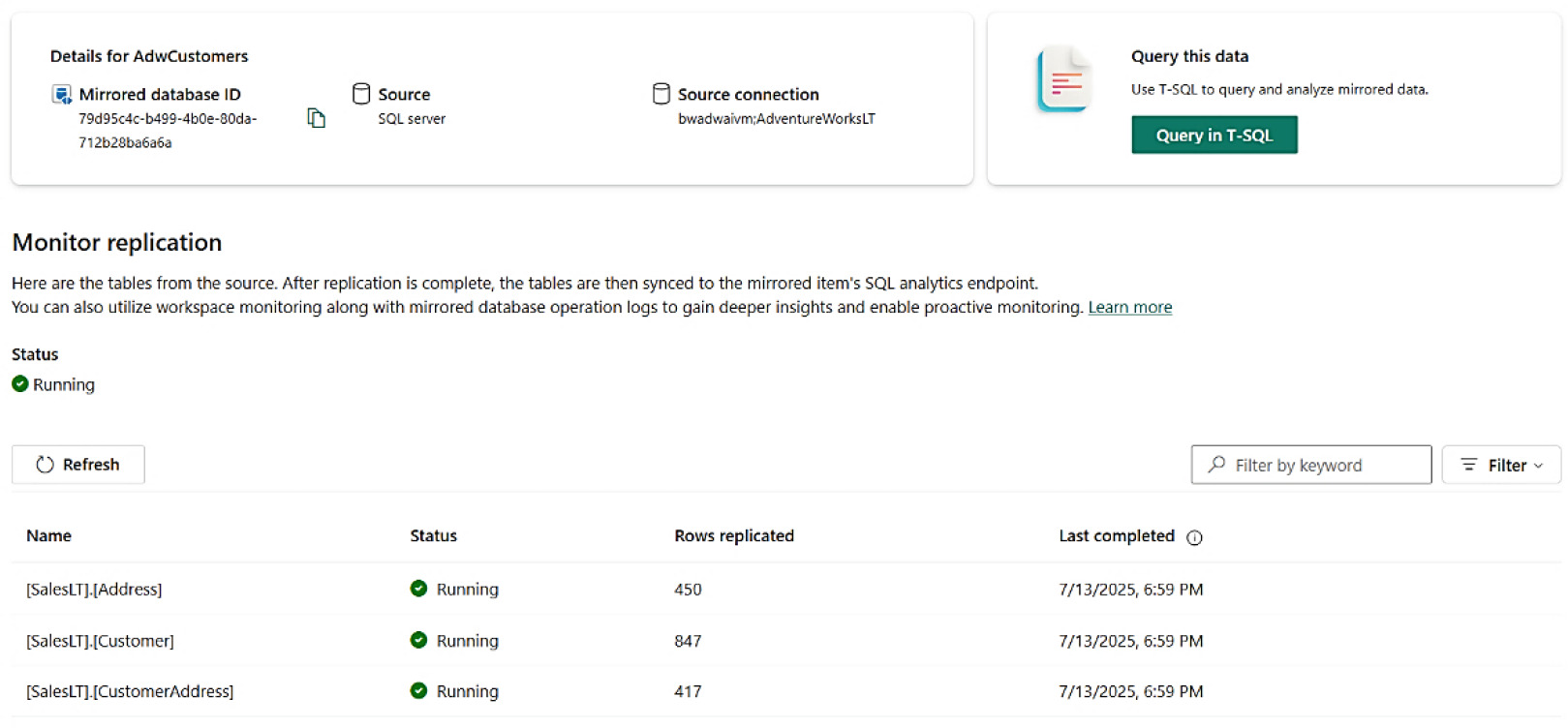
Figure 8-9: Fabric Mirror 完成初始同步
同步速度取決於:
- 資料表大小
- SQL Server 與 Fabric 之間的網路延遲
- SQL Server 上的 CPU / I/O 負載
從 SQL Server 端檢查 mirror 狀態#
USE AdventureWorksLT;
EXEC sp_help_change_feed;
SELECT * FROM sys.dm_change_feed_log_scan_sessions;
SELECT * FROM sys.dm_change_feed_errors;用 SQL Analytics Endpoint 查詢 mirror#
進到 workspace ➜ 選 SQL Analytics Endpoint,可看到 mirror 的 table(保留來源 schema,例如 SalesLT)。
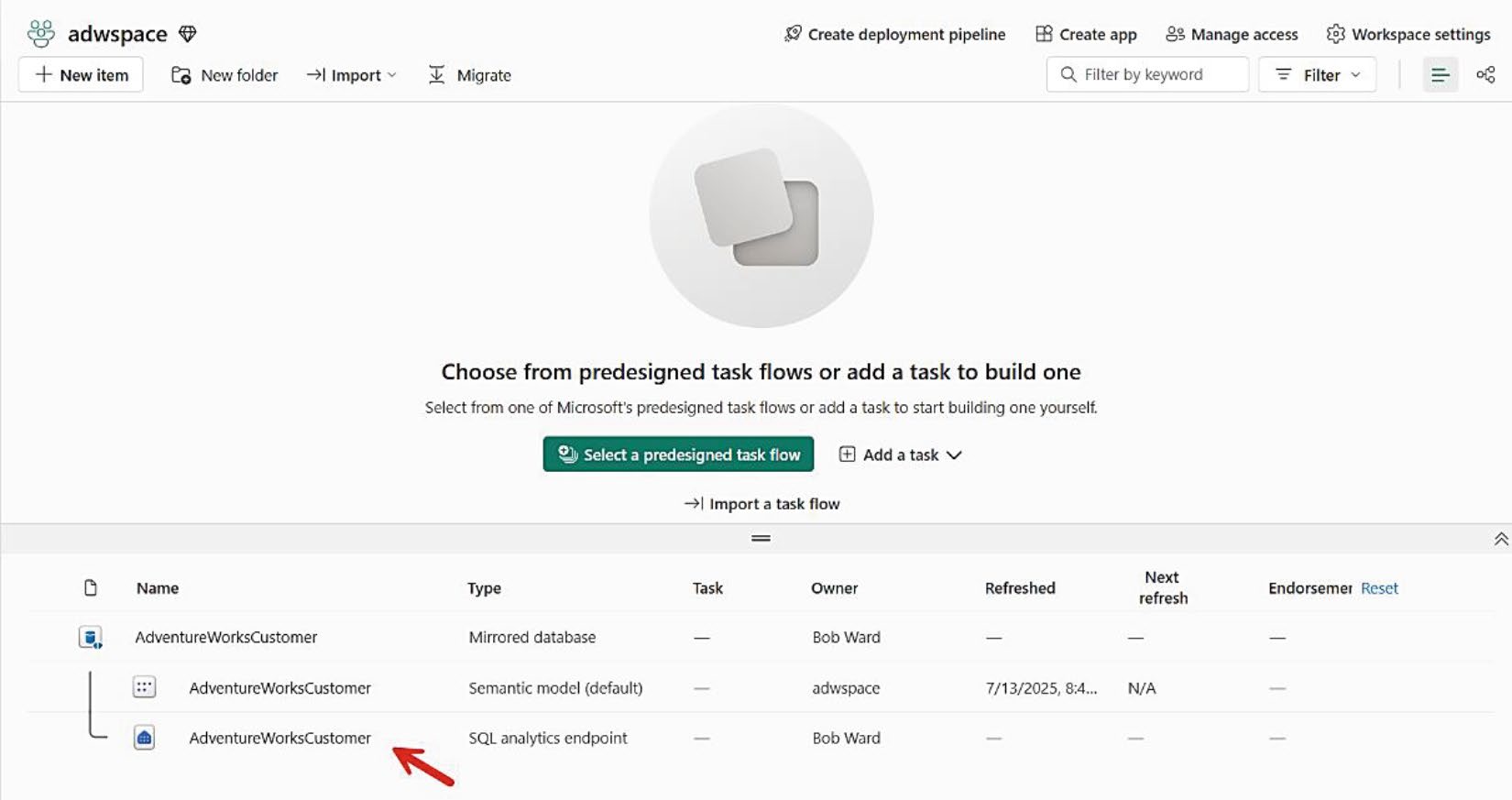
Figure 8-10: 找到 Mirrored 資料的 SQL Analytics Endpoint
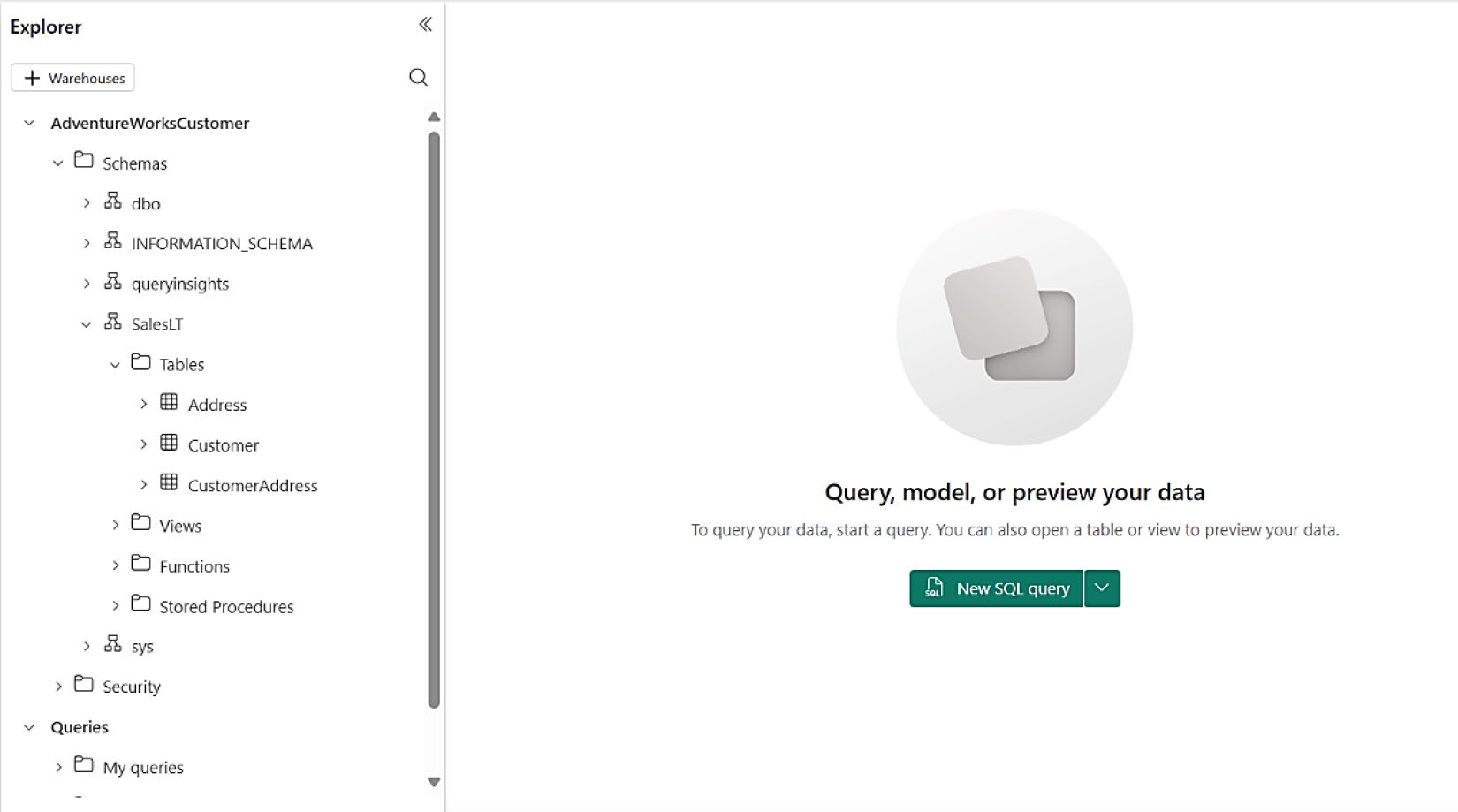
Figure 8-11: SQL Analytics Endpoint 體驗
可用 Copilot 直接以 prompt 產生查詢——Copilot 知道 schema。
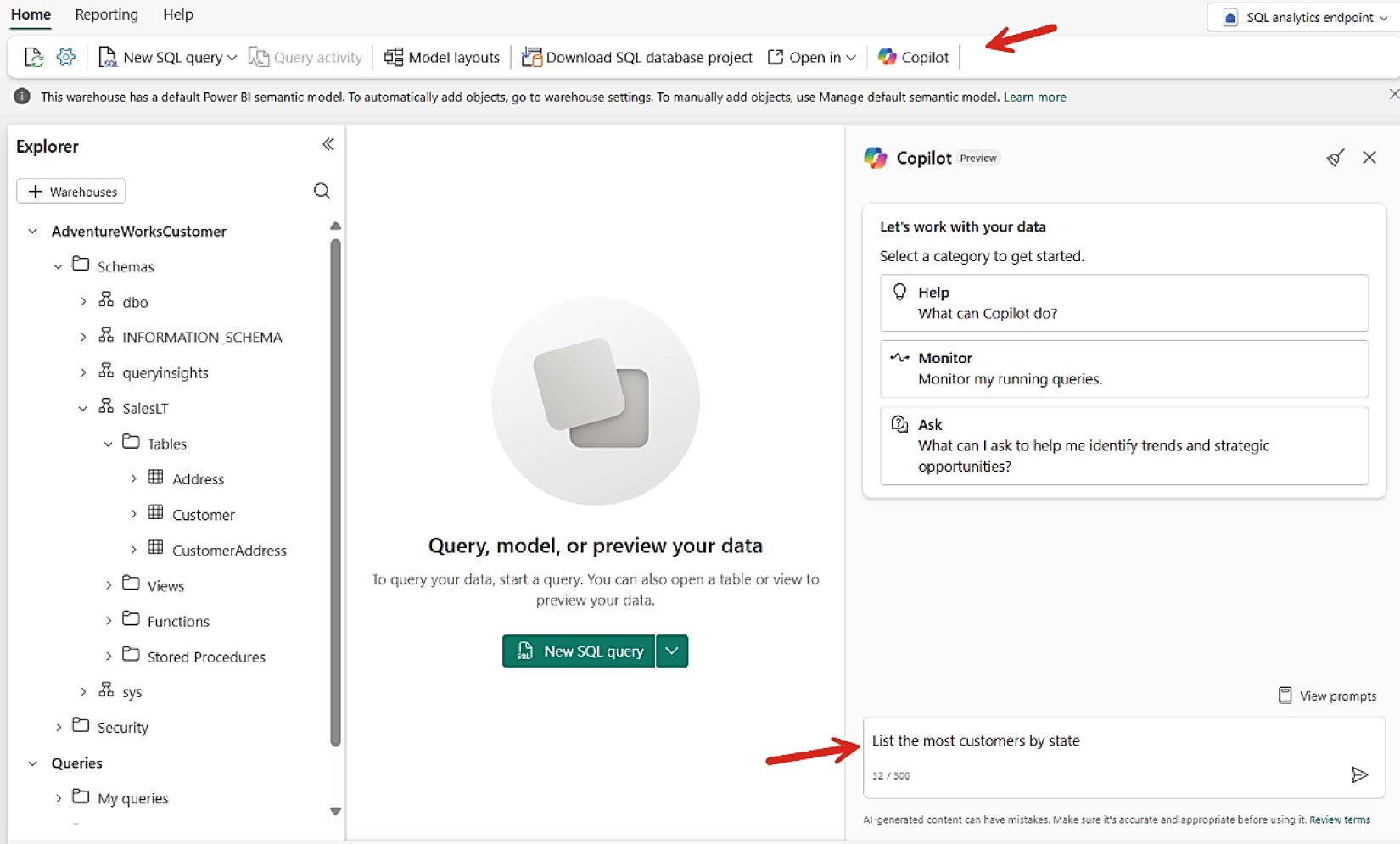
Figure 8-12: 透過 Copilot prompt 產生 SQL 查詢
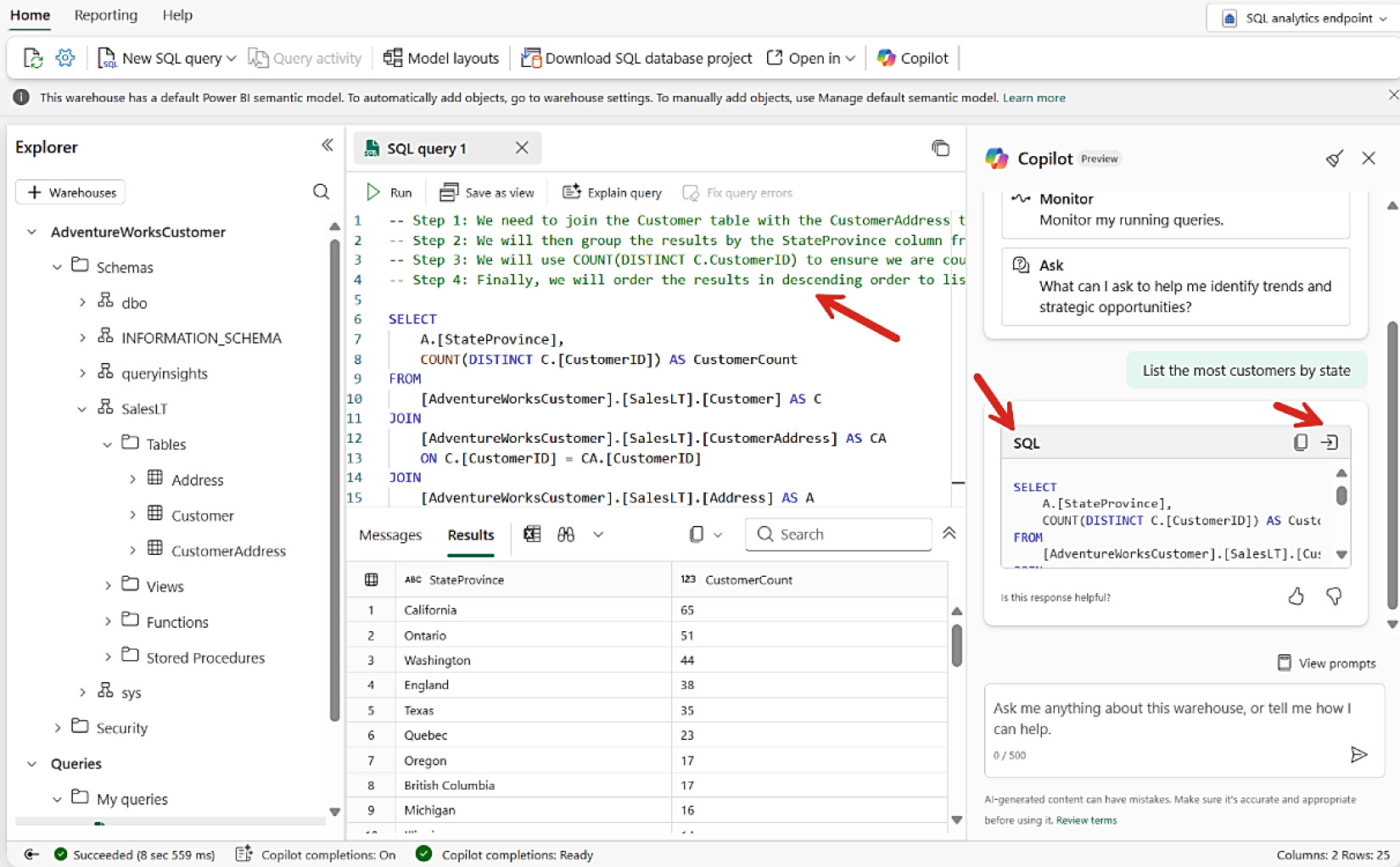
Figure 8-13: Copilot 為 Mirrored 資料庫產生的查詢
SQL Analytics Endpoint 為 TDS 相容,可直接用 SSMS 連線,連線字串可在 Fabric portal 取得。
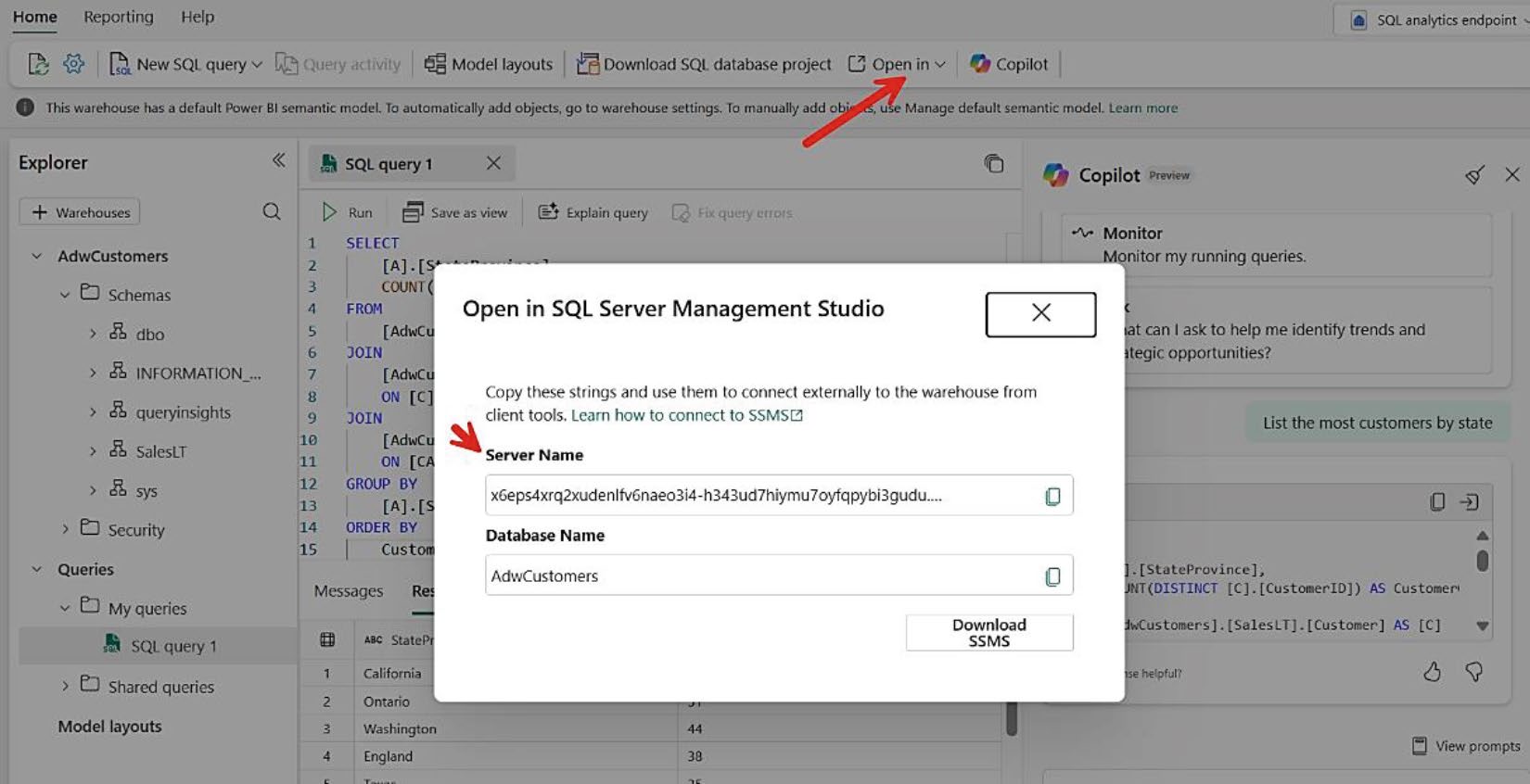
Figure 8-14: 取得 SQL Analytics Endpoint 在 SSMS 的連線字串
驗證即時同步#
來源端做變更:
USE AdventureWorksLT;
INSERT INTO SalesLT.Address (
AddressLine1, AddressLine2, City, StateProvince, CountryRegion, PostalCode
)
VALUES (
'129 W 81st St, Apt 5A',
'Newman!',
'New York',
'NY',
'US',
'10024'
);回到 Fabric 即可在 SQL Analytics Endpoint 中看到新列出現。
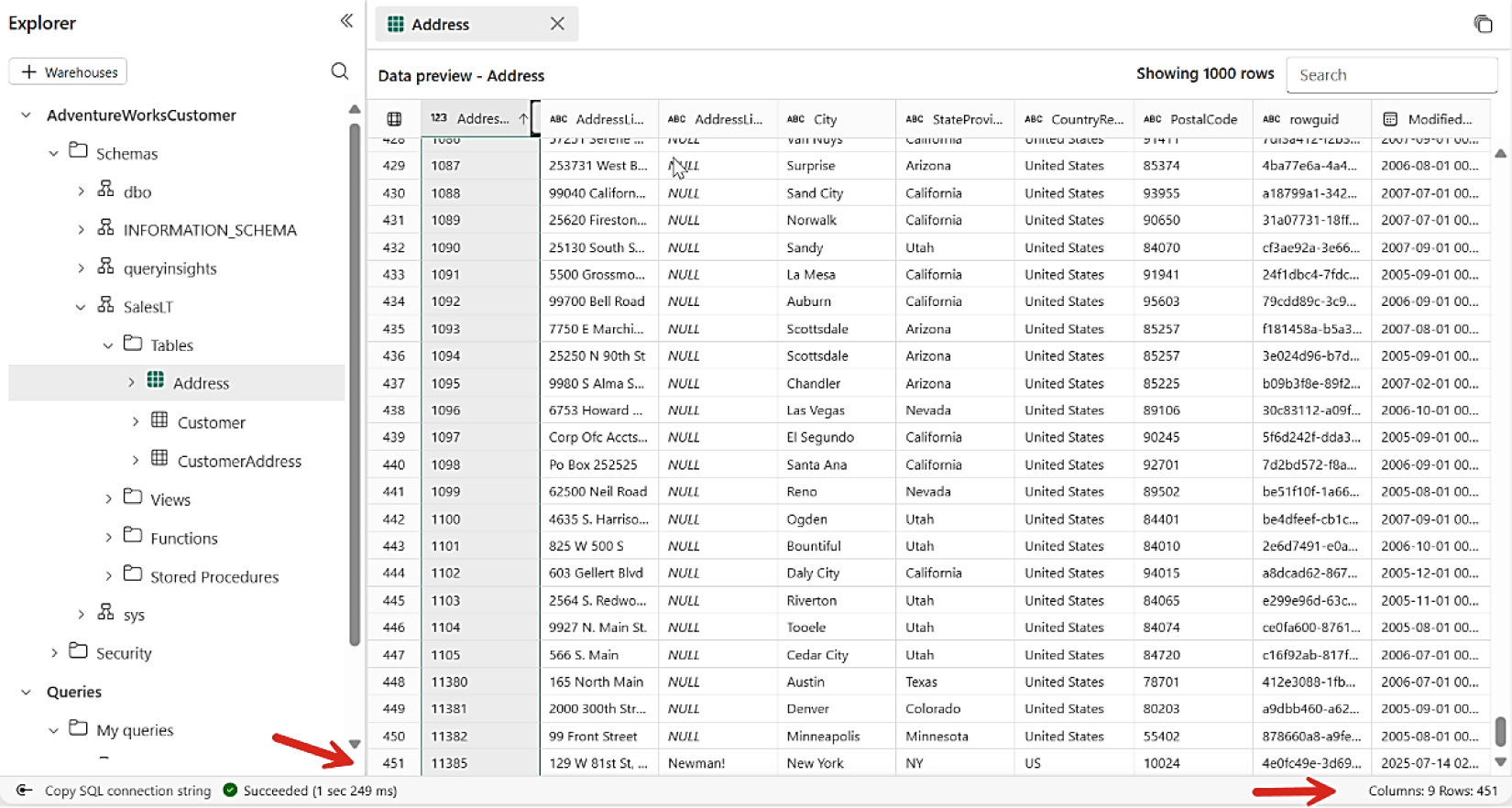
Figure 8-15: 看到從 SQL Server 2025 同步而來的新資料列
走得更遠:統一資料平台#
延續範例,再加上其他來源:
- Azure SQL Database:mirror 來源 AdventureWorksLT 中的 product 系列 table(
alteradwltazureqsl.sql處理 UDT),命名AdventureWorksProducts - SQL Database in Fabric:在 Fabric 內部署一個 SQL Database,自動 mirror 進 OneLake,命名
AdventureWorksSales,再以alteradwltsqldbfabric.sql移除非銷售相關資料表
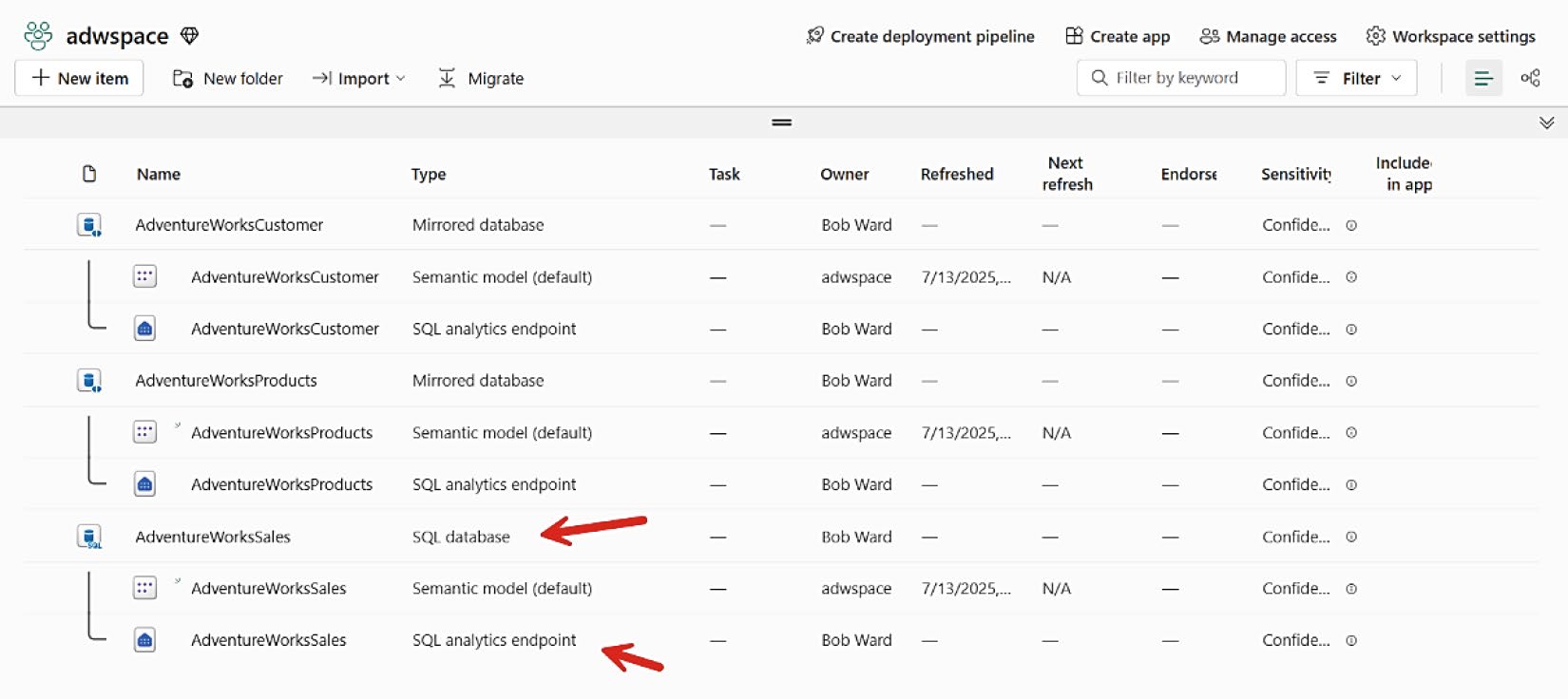
Figure 8-16: workspace 中目前所有的資料庫
Figure 8-17: 在 SQL Analytics Endpoint 視圖中加入 Warehouse
Figure 8-18: 在 SQL Analytics Endpoint 中檢視所有資料庫
為三個來源建立 Lakehouse#
Lakehouse 是 OneLake 上的邏輯檢視,可透過 shortcut(捷徑)連到其他來源資料,不需複製。
- workspace ➜ + New Item ➜ Lakehouse(命名
AdventureWorks) - Add data ➜ Shortcut ➜ OneLake
Figure 8-19: 透過 Shortcut 把資料加入 Lakehouse
- 從同一 workspace 中選擇 mirrored databases 的資料表加入 shortcut
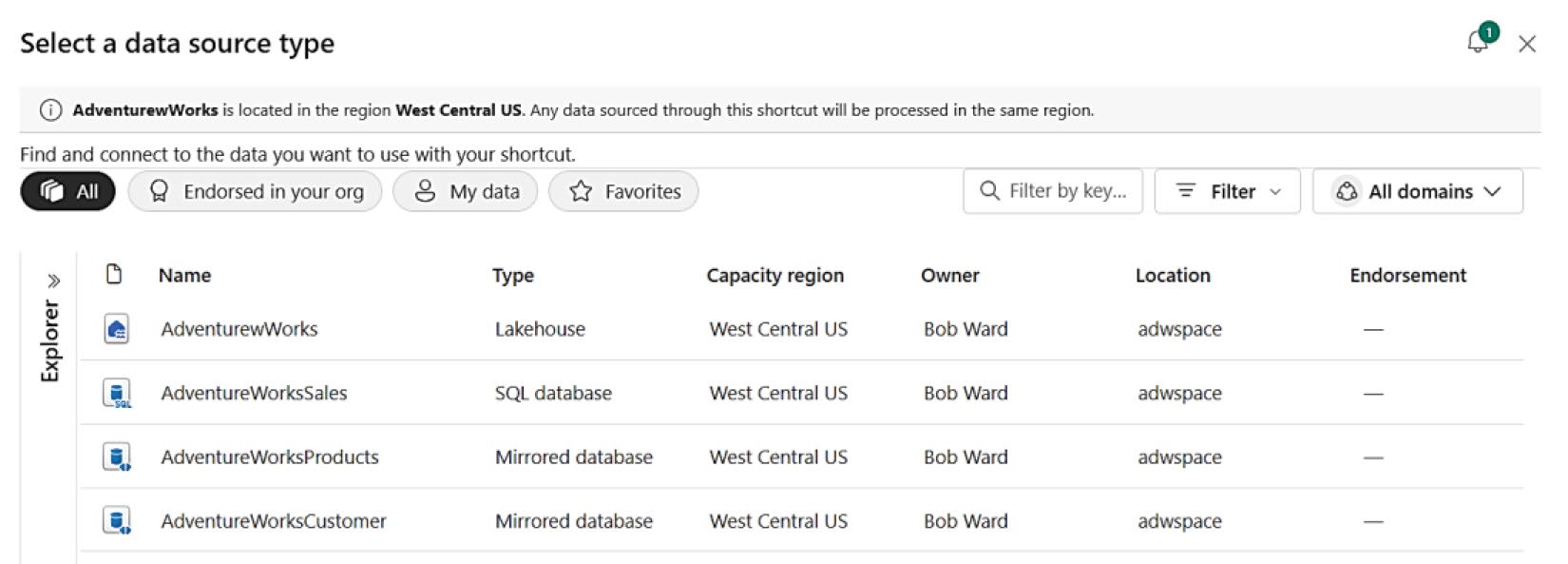
Figure 8-20: 從 workspace 的資料庫中挑選 Shortcut 來源
- 完成後 Lakehouse 列表會顯示捷徑圖示——任何來源端變更都會即時反映
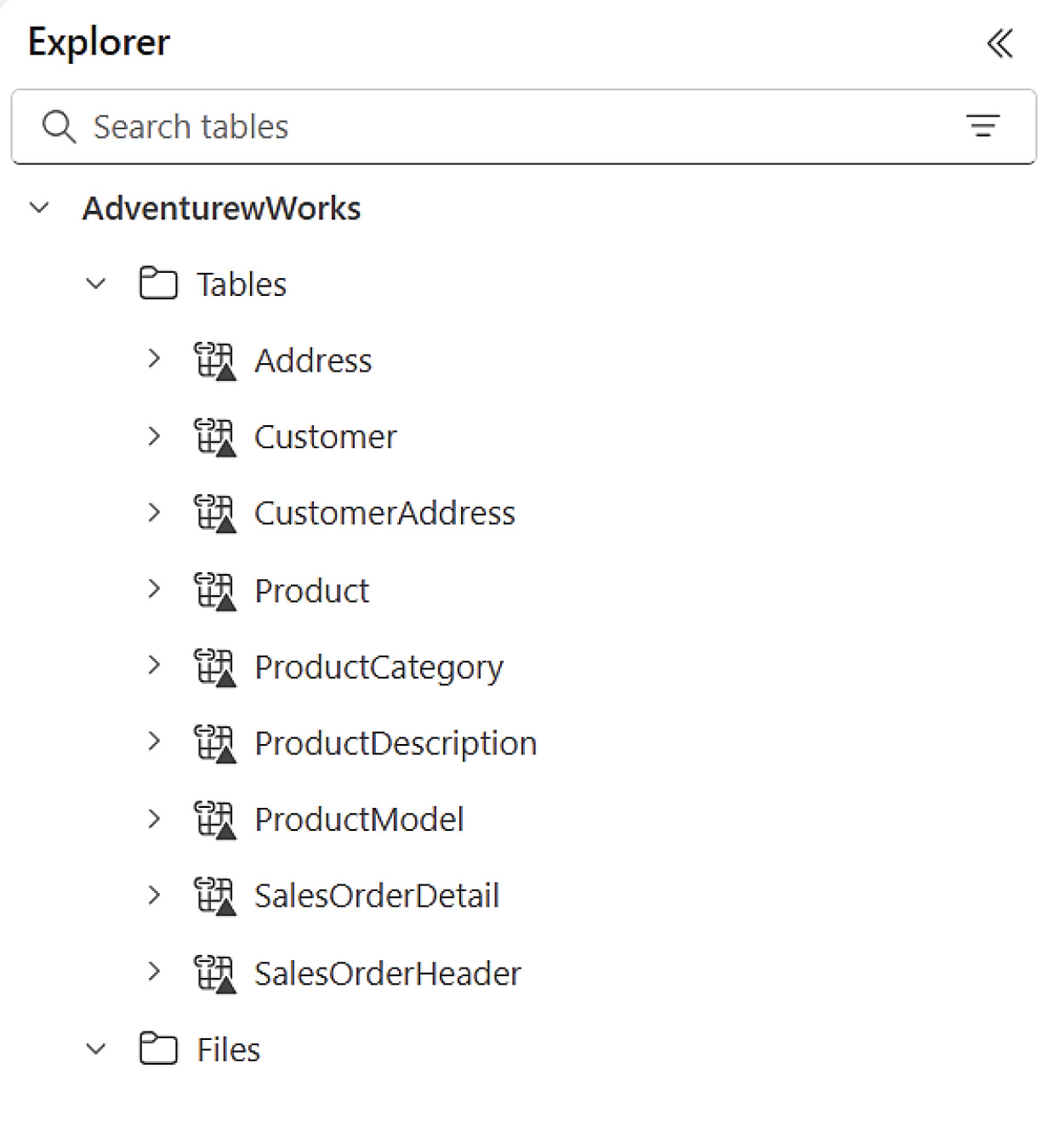
Figure 8-21: 在 Lakehouse 中統一檢視資料
Lakehouse 的 SQL Analytics Endpoint#
Lakehouse 也提供 SQL Analytics Endpoint。再用 Copilot 跨表 join 三個來源——使用者完全不需要知道資料分散在哪。
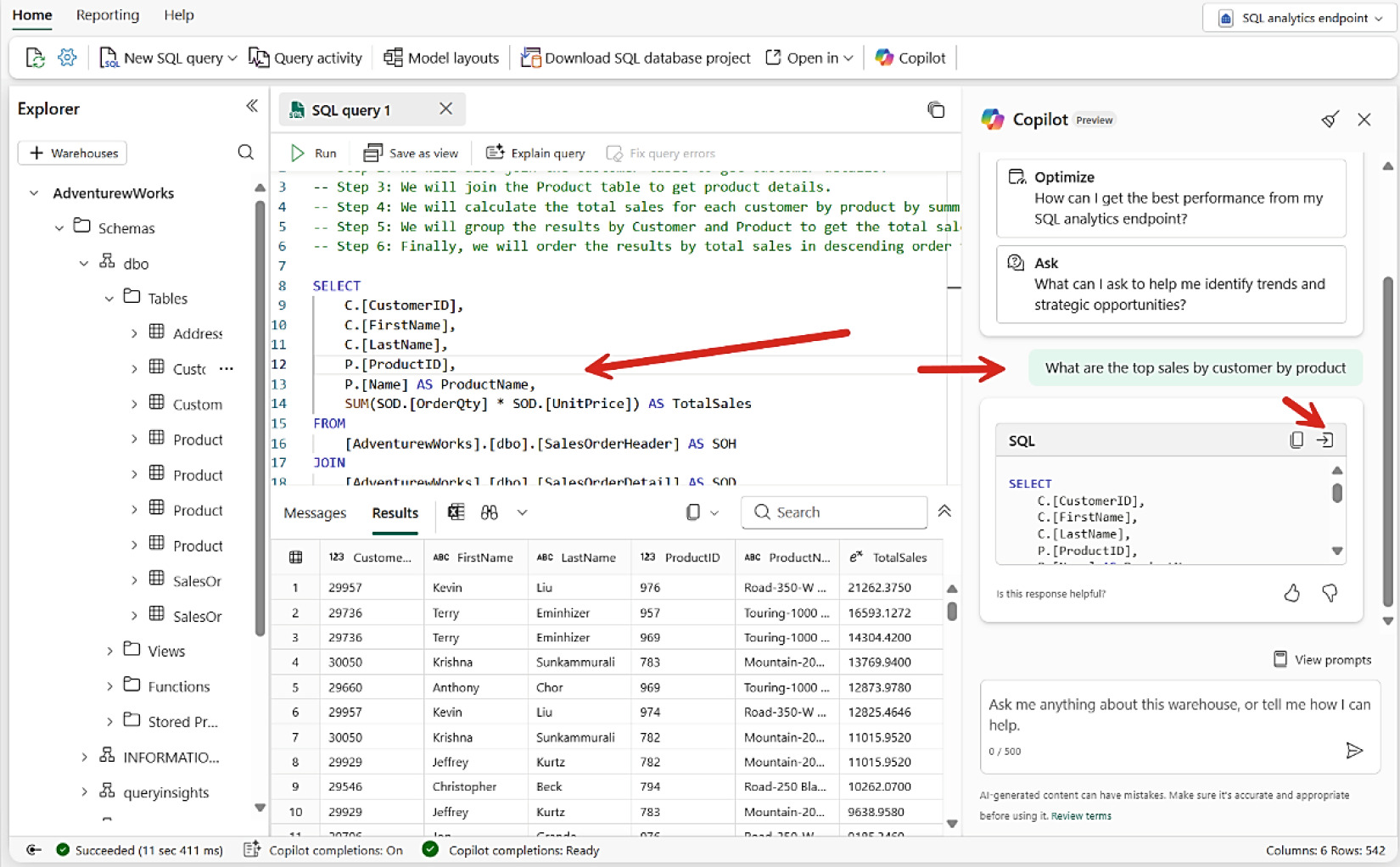
Figure 8-22: 用 Copilot 在 Lakehouse 中跨表 Join
Power BI、Data Agents 與 SSMS#
Power BI 報表#
- 在 Lakehouse 建立 DirectLake Semantic Model(DirectLake 在 Power BI 上有顯著效能優勢)
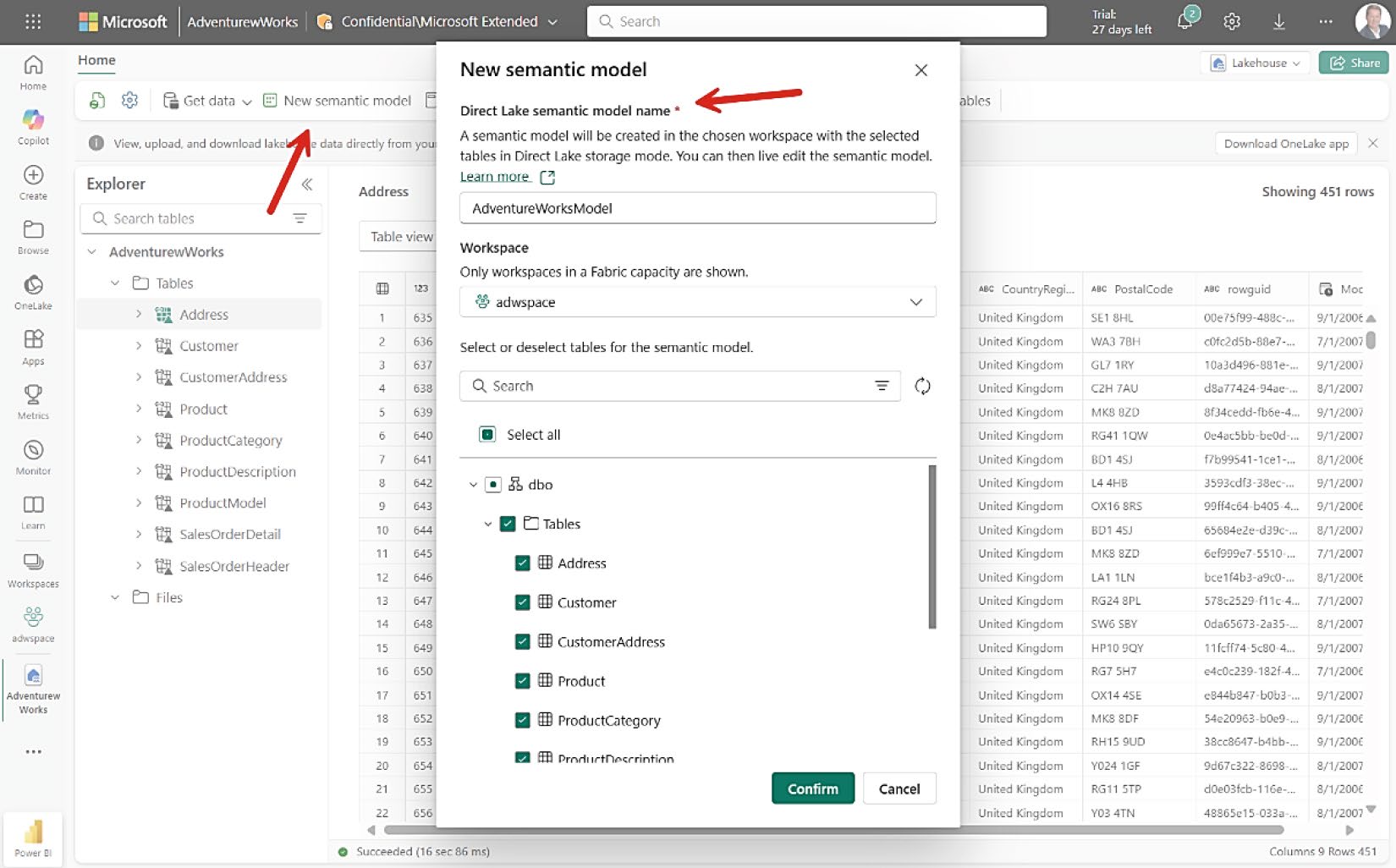
Figure 8-23: 建立新的 DirectLake Semantic Model
- 從 Semantic Model 建立空白報表
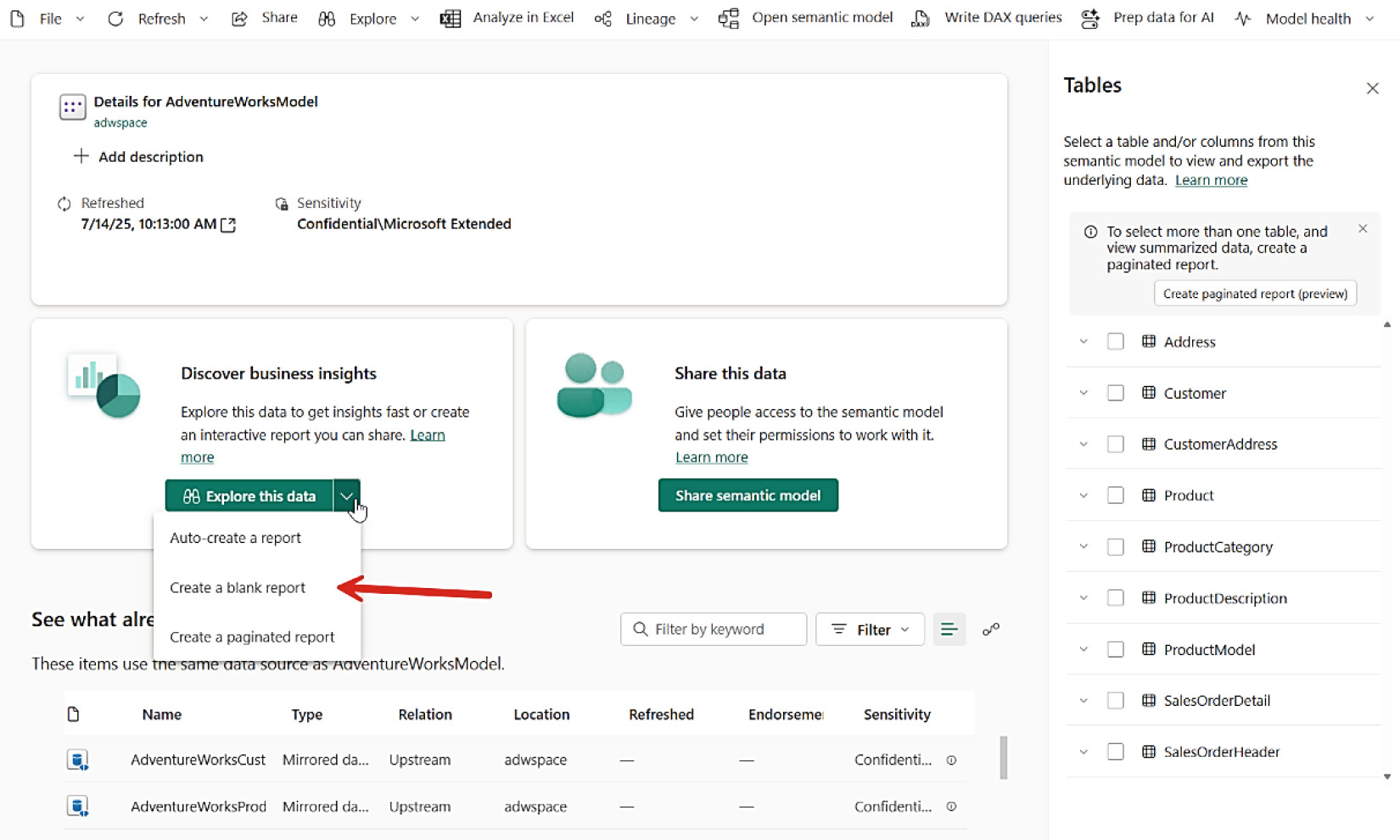
Figure 8-24: 從 Semantic Model 建立空白報表
- 用 Copilot in Power BI 自動產生視覺化內容
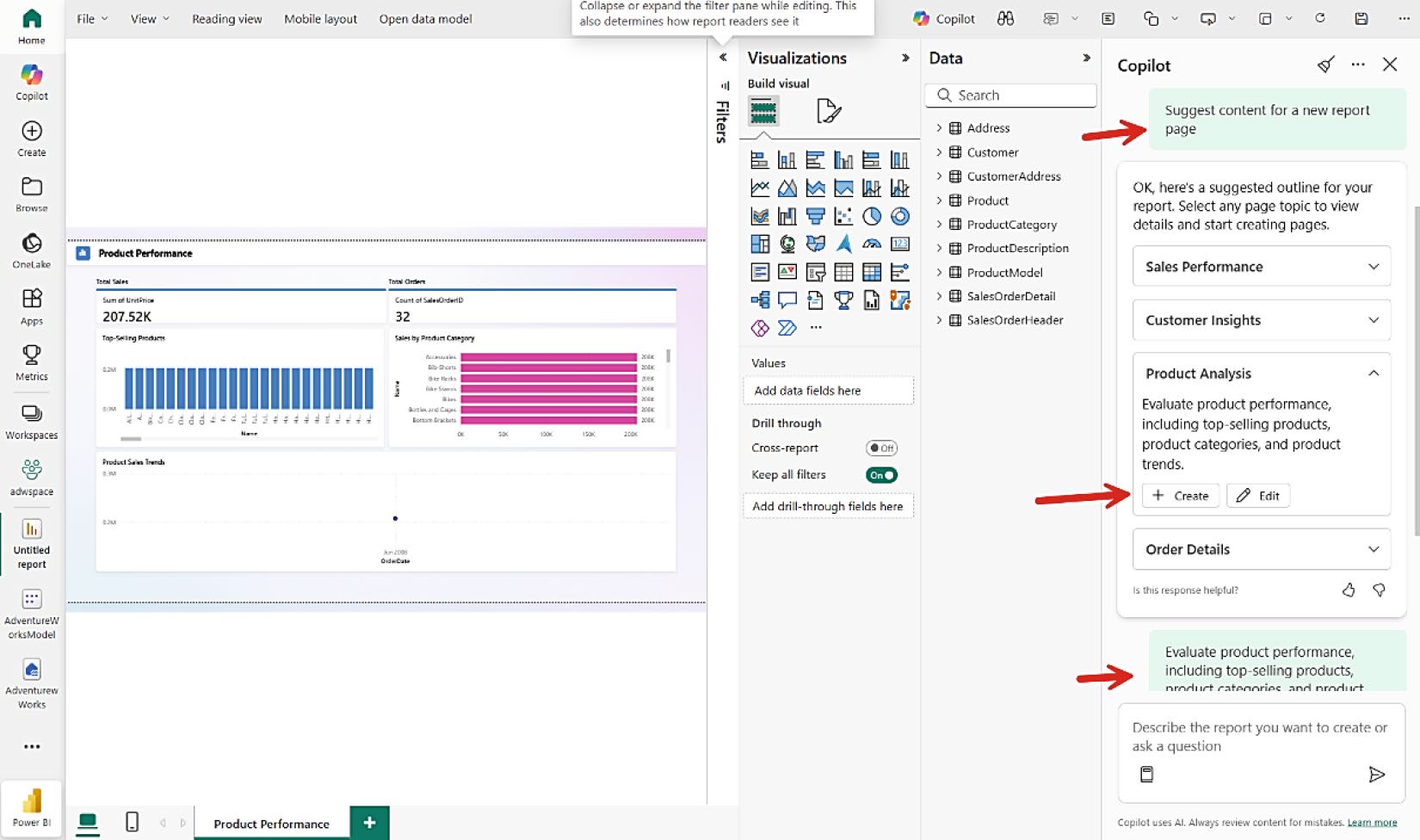
Figure 8-25: 用 Copilot 建立 Power BI 報表
可在報表中插入 Power BI narrative visual 內嵌 Copilot:
https://learn.microsoft.com/power-bi/create-reports/copilot-create-narrative
Fabric Data Agents#
Fabric Data Agents 可基於 Lakehouse 等資料源建立 AI Agent,把整個資料集變成「可對話」的應用,並可發佈為 AI app。
文件:
https://learn.microsoft.com/fabric/data-science/how-to-create-data-agent
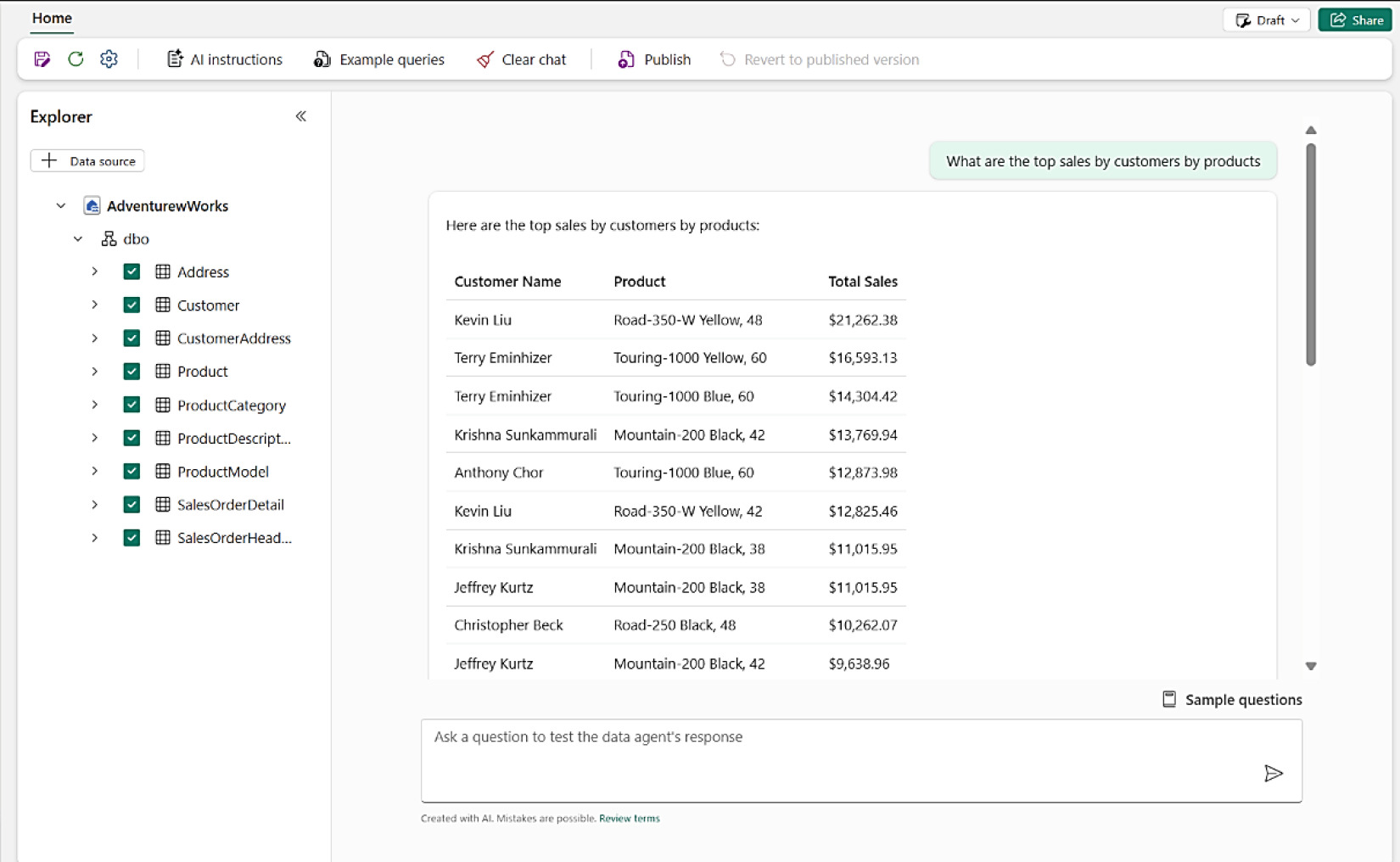
Figure 8-26: 透過 Fabric Data Agents 與 Lakehouse 對話
SSMS 連 Lakehouse#
由於 SQL Analytics Endpoint 是 TDS 相容,使用 Microsoft Entra 帳戶(具備 Lakehouse 權限)即可從 SSMS 連線。連線後可同時查詢 workspace 中所有 SQL Analytics Endpoint。
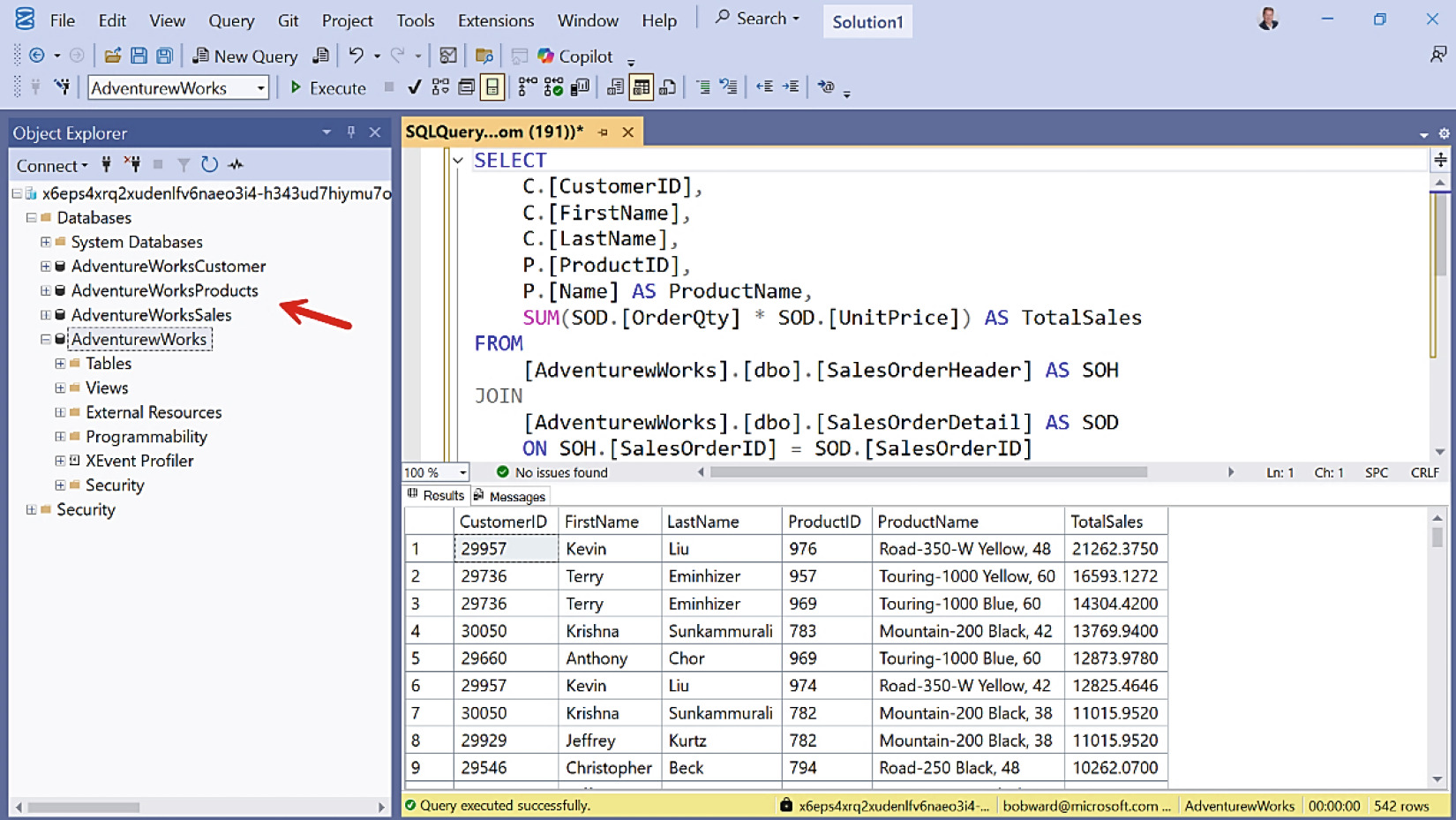
Figure 8-27: 用 SSMS 對 Lakehouse 執行查詢
SQL 一直是資料故事的一部分#
「在 AI 驅動的世界,分析平台必須近即時。Fabric Mirroring 提供了一條把 SQL 交易資料持續匯入 OneLake 的現代化道路,作為報表、進階分析、AI、資料科學的堅實基礎。我們在 2024 年把 Azure SQL Mirroring 帶進 Fabric 後,客戶就一直追問 SQL Server 何時跟進——SQL Server 2025 是把同一套技術帶到地端 SQL Server 的最佳時機。沒有複雜設定、沒有 ETL,只要從 Fabric portal 提供連線資訊與選表即可上路。」
— Ajay Jagannathan,Fabric Mirroring for SQL 產品負責人
下一章——也是本書的尾聲——將把 SQL Server 2025 放進「Microsoft SQL ground to cloud to fabric」的全景中。