SQL Server 團隊早在 AI 成為當紅議題之前,就開始思考「AI 內建」(AI Built-In)的方向。SQL Server 2016 引入 R Services(內部代號 SPEES,即 sp_execute_external_script),允許在 SQL Server 旁以隔離方式執行 R 程式並整合資料庫資料。後續演化為 2017 年的 Machine Learning Services(新增 Python、Linux 支援)、2019 年的 Java Language Extensions,並引入 PREDICT 函式以載入並執行預先訓練好的 ONNX 與 R 模型。
這些早期投資雖未如預期普及,但讓團隊熟悉 AI 概念,並為 SQL Server 2025 重用「擴充框架(extensibility framework)」奠定基礎。
本章將說明 SQL Server 2025 如何在企業級安全與規模下提供向量內建支援,並用實例帶你從地端到雲端使用 AI 模型。
我們在解什麼問題#
更聰明的搜尋#
SQL Server 既有的 LIKE、T-SQL 函式與全文搜尋(Full-Text Search, FTS)以關鍵字為主。向量搜尋則能用「語意」找出資料中沒出現過的字詞所代表的概念,讓既有資料庫的搜尋體驗更豐富。
集中化向量搜尋#
許多客戶開始把現有 PDF、Word 等文件「集中」到 SQL Server,因為它們:
- 信任 SQL Server 的安全模型
- 喜愛 T-SQL 語言
Davide Mauri 提供的範例 pipeline:
https://github.com/Azure/document-vector-pipeline/tree/main/AzureSQL/csharp
提供建構積木而非託管 AI 模型#
SQL Server 2025 從一開始就決定不託管 AI 模型。
- 讓客戶自由選擇地端或雲端 AI 模型
- 提供 T-SQL 與引擎能力作為 building blocks
- 與 LangChain、Semantic Kernel、Entity Framework Core、MCP Server 等現代框架相容
推進安全與規模#
幾乎所有客戶都把「安全」列為使用 AI 的最大障礙。把能力建在資料庫引擎裡,等同於把 AI 包進 SQL Server 既有的安全與規模保護傘下。
克服複雜度#
T-SQL 是熟悉的語言,並能在引擎中為 AI 能力提供安全防護。
什麼是「AI-Ready」#
對 SQL Server 2025 而言,AI-Ready 代表:
- 能存取地端或雲端的 AI 模型
- 提供新的 vector 資料型別
- 在 SQL Server 引擎的安全保護下執行向量搜尋
完整 AI 功能列表:
https://learn.microsoft.com/sql/sql-server/what-s-new-in-sql-server-2025#ai
GA 後預期狀態:
- GA 全面支援:vector 資料型別、model definitions、
VECTOR_DISTANCE- 需要
PREVIEW_FEATURES:vector index、VECTOR_SEARCH、text chunking、ONNX 模型,預計後續累積更新(CU)正式 GA
Vector 資料型別#
新增 vector(n) 型別:
n為維度(dimensions),目前最大支援 1,998- 內部以最佳化的二進位存放,每個元素為 4-byte 單精度浮點
- 經
SELECT查詢時以 JSON 陣列呈現 - SQL Server 2025 因此正式成為 vector store
你必須讓
vector(n)的n與 embedding 模型的維度完全一致。否則使用AI_GENERATE_EMBEDDINGS時會出現:Msg 42204, Level 16, State 2, Line 5 The vector dimensions 500 and 1024 do not match.
雖然主要用途是儲存模型生成的 embedding,但任何符合維度的浮點陣列都可以放進來——資料科學家也可儲存傳統的 feature vector。
Driver 支援#
- 更新 TDS 協定與驅動程式以二進位格式傳輸 vector,減少 payload 並保留浮點精度
- 已更新的驅動:
Microsoft.Data.SqlClient、Microsoft JDBC Driver - 未更新的舊驅動 「just work」,但會把 vector 視為
nvarchar(max)
Model Definitions#
為什麼引入 CREATE EXTERNAL MODEL#
雖然 sp_invoke_external_rest_endpoint 也能呼叫 embedding 模型 API,但每筆資料都要逐列呼叫,且必須處理 URL 細節。
「我們堅守一個原則:絕對不把 AI 模型載入資料庫引擎。」
因此團隊設計了新的 T-SQL
CREATE EXTERNAL MODEL陳述式(database scoped),把模型 metadata 與存取方式集中管理。
語法#
CREATE EXTERNAL MODEL external_model_object_name
[ AUTHORIZATION owner_name ]
WITH
( LOCATION = '<prefix>://<path>[:<port>]'
, API_FORMAT = '<OpenAI, Azure OpenAI, etc>'
, MODEL_TYPE = EMBEDDINGS
, MODEL = 'text-embedding-model-name'
[ , CREDENTIAL = <credential_name> ]
[ , PARAMETERS = '{"valid":"JSON"}' ]
[ , LOCAL_RUNTIME_PATH = 'path to the ONNX runtime files' ]
);| 參數 | 說明 |
|---|---|
external_model_object_name | 物件識別子,用於 AI_GENERATE_EMBEDDINGS 等陳述式 |
AUTHORIZATION | 指定擁有者(user 或 role),決定誰能用此模型 |
LOCATION | REST endpoint URL(必須是 HTTPS),或 ONNX 模型檔案路徑 |
API_FORMAT | Azure OpenAI、OpenAI、Ollama、本地 ONNX |
MODEL_TYPE | 目前只支援 EMBEDDINGS,預留未來擴充 |
MODEL | 模型名稱 |
CREDENTIAL | 對應 DATABASE SCOPED CREDENTIAL(API key 或 Azure Managed Identity) |
PARAMETERS | 模型參數(如 {"dimensions": 1536} 在某些模型中可調整輸出維度) |
LOCAL_RUNTIME_PATH | ONNX runtime 路徑(使用 ONNX 模型時必填) |
安全層面要點:
- 必須先啟用伺服器設定
external rest endpoint enabled- 必須使用 HTTPS——若服務本身不支援,需要 caddy / nginx 等 proxy
CREATE EXTERNAL MODEL預設只有sysadmin有權;其他使用者(即使是db_owner)也需要明確授權ALTER EXTERNAL MODEL可改定義,但若改了模型,記得重新生成所有 embeddings
為什麼把 OpenAI 與 Azure OpenAI 區分#
- Azure OpenAI 在 Azure AI Foundry 中有特殊的安全、低延遲需求,與直接的 OpenAI 不同
- Azure AI Foundry 中非 Azure OpenAI 的模型(如 NVIDIA、Llama 等),則使用
API_FORMAT = 'OpenAI' - 許多其他服務(地端與雲端)也支援 OpenAI 標準,因此最後從「model provider」改為「
API_FORMAT」
系統檢視#
SELECT * FROM sys.external_models;產生 embeddings:AI_GENERATE_EMBEDDINGS#
SELECT AI_GENERATE_EMBEDDINGS(@text USE MODEL MyEmbeddingModel)- 接受
nvarchar、varchar、nchar、char文字輸入或表達式 - 必須以
USE model_identifier指定模型——固定名稱,不可使用變數 - 支援
SELECT、INSERT...SELECT、UPDATE,再也不需要 cursor - 內部仍是逐列同步處理,目前沒有批次概念
- 結果為 JSON 陣列;插入到 vector 欄位時自動轉成二進位格式
- 診斷可使用 XEvent
ai_generate_embeddings_summary
Text Chunking:AI_GENERATE_CHUNKS#
Embedding 模型有 token 上限——例如
text-embedding-ada-002為 8,192 tokens(約 12–16K 字元)。超過上限時:
- Azure OpenAI:回傳明確錯誤
- Ollama:靜默截斷文字(必須警惕)
AI_GENERATE_CHUNKS 把長文字切成可送入模型的片段。目前是「固定」切法,需 PREVIEW_FEATURES。未來可能支援以全文搜尋的「段落」概念切分。
文件:https://learn.microsoft.com/sql/t-sql/functions/ai-generate-chunks-transact-sql
VECTOR_DISTANCE 與精確搜尋#
DECLARE @v AS VECTOR(1536);
SELECT @v = title_vector
FROM [dbo].[wikipedia_articles]
WHERE title = 'Alan Turing';
SELECT id, title, VECTOR_DISTANCE('cosine', @v, title_vector) AS distance
FROM [dbo].[wikipedia_articles]
WHERE VECTOR_DISTANCE('cosine', @v, title_vector) < 0.3
ORDER BY distance;距離選項:
選項 適用情境 cosineCosine distance(最常用) euclideanEuclidean distance dotNegative dot product 多數現代 AI 模型回傳的是已 normalized 的 embeddings,此時
cosine通常表現最佳。
想知道你的向量是否 normalized:
VECTOR_NORM:回傳向量大小VECTOR_NORMALIZE:回傳 normalized 版本實務建議:選一個輸出 normalized vector 的模型,搭配
cosine。
VECTOR_DISTANCE 是 scan 操作,可能引發 spool(吃 tempdb)。資料量大時要改用 vector index。
Vector Index:DiskANN#
ANN 與 HNSW#
Approximate Nearest Neighbor(ANN)是大規模向量索引的主流,犧牲少許準確度換取速度。HNSW(Hierarchical Navigable Small World) 為其中知名實作,但通常需要全部存於記憶體。
DiskANN#
2019 年由 Microsoft Research 與學界提出 DiskANN,2021 年開源(
https://github.com/microsoft/DiskANN)。它利用快速 SSD,避免向量索引必須完全駐留記憶體,已成為微軟產品的常用標準。
SQL Server 2025 透過下列陳述式建立 DiskANN 索引:
CREATE VECTOR INDEX product_vector_index
ON Production.ProductDescriptionEmbeddings (Embedding)
WITH (METRIC = 'cosine', TYPE = 'diskann', MAXDOP = 8);搭配 VECTOR_SEARCH T-SQL 函式做近似搜尋。
目前限制#
公開預覽期間(需
PREVIEW_FEATURES)的限制:
- 一旦建立 vector index,該表變為唯讀(read-only)
- 必須有單欄整數的 primary key clustered index
- 不會複寫到 subscriber
VECTOR_SEARCH為 post-filter only——先做向量搜尋,再套用其他 predicateVECTOR_SEARCH不能用在 view 中上述限制將隨後續 CU 逐步解除。團隊也針對開源 benchmark
https://github.com/MageChiu/VectorDBBench做效能改善。
SQL Vector 架構與七步驟#
完整流程:
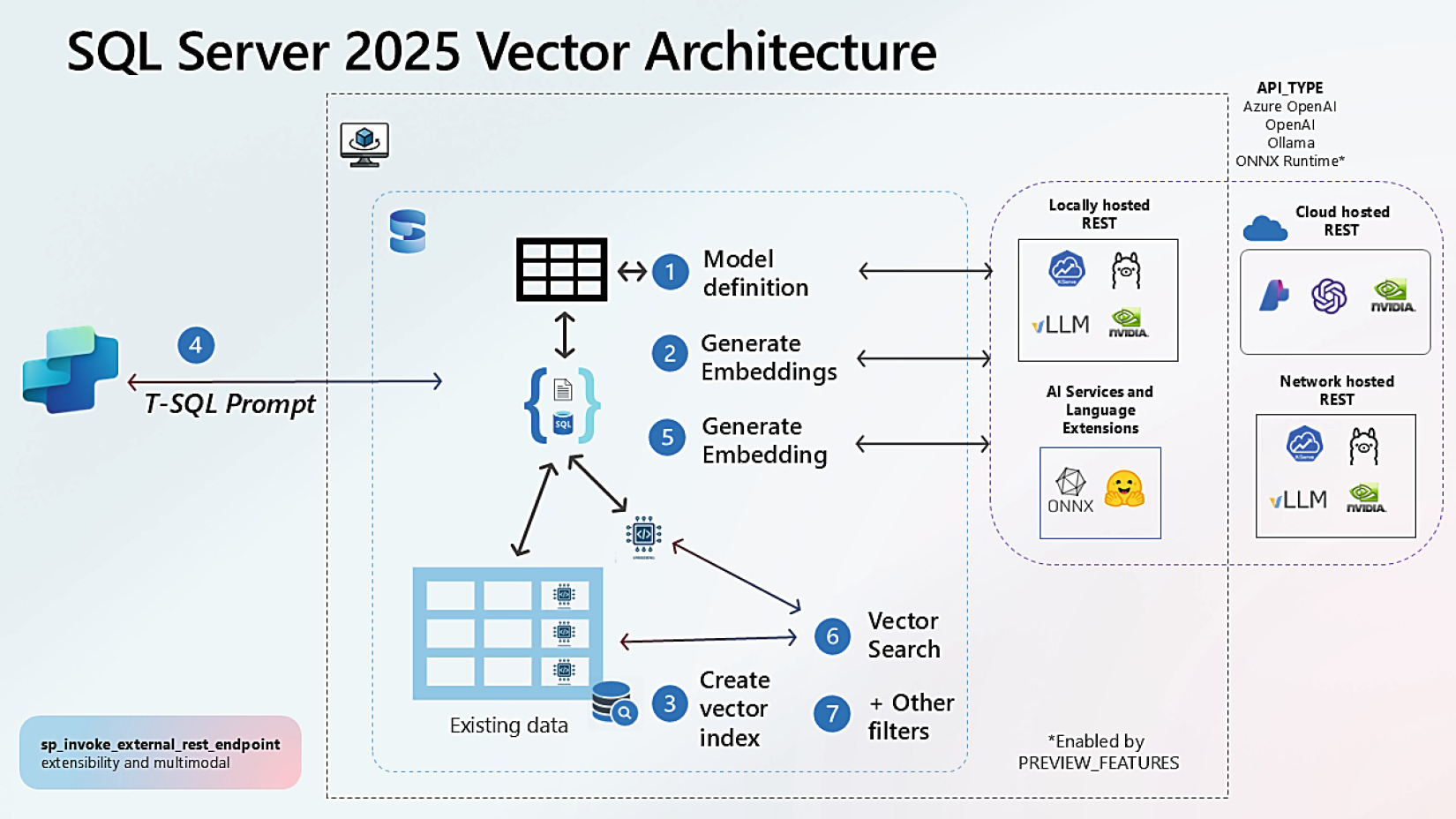
Figure 4-1: SQL Server 向量架構
flowchart LR
A["1\. 建立 Model Definition"] --> B["2\. 用 AI_GENERATE_EMBEDDINGS 生成並存入 vector 欄位"]
B --> C["3\. 建立 Vector Index(可選)"]
C --> D["4\. T-SQL 接收 prompt"]
D --> E["5\. 用同一模型把 prompt 轉 embedding"]
E --> F["6\. VECTOR_DISTANCE 或 VECTOR_SEARCH"]
F --> G["7\. 套用其他 WHERE 條件 / 重排"]步驟 7 的 Re-ranking 結合 SQL Server 全文搜尋(CONTAINSTABLE / FREETEXTTABLE 提供 BM25 評分)與向量搜尋的 top-K,再以 Reciprocal Rank Fusion(RRF) 整合,達到 lexical + semantic 雙贏。
範例:
https://devblogs.microsoft.com/azure-sql/enhancing-search-capabilities-in-sql-server-and-azure-sql-with-hybrid-search-and-rrf-re-ranking
若
CREATE EXTERNAL MODEL的 API_FORMAT 不符需求,仍可用sp_invoke_external_rest_endpoint直接呼叫任何 REST embedding 端點。
為何稱為「企業級」#
你完全掌握存取權#
- 必須先開啟
external rest endpoint enabled(REST)或external AI runtimes enabled(ONNX) - 必須有
CREATE EXTERNAL MODEL權限 - 全部能力以 T-SQL 暴露,自然納入企業級 SQL 安全模型
你選擇 AI 模型#
地端、區網、雲端任你決定,主流提供方都支援:
- Azure OpenAI
- OpenAI / OpenAI-compatible
- Ollama
- ONNX runtime
模型隔離於 SQL Server 引擎之外#
無論地端或雲端,模型都不會載入引擎。
善用 SQL 安全功能#
| 功能 | 用途 |
|---|---|
| Row-Level Security (RLS) | 列級存取控管 |
| Transparent Data Encryption (TDE) | 透明加密 |
| Dynamic Data Masking (DDM) | 動態資料遮罩 |
| SQL Server Auditing | 追蹤所有 AI、向量、模型存取 |
| SQL Server Ledger | 對話歷史與意見回饋的不可竄改記錄(https://aka.ms/sqlledger) |
完整範例:以 AdventureWorks 做產品向量搜尋#
問題情境:在 Production.ProductDescription 上做 RAG 搜尋,prompt 為「Show me stuff for extreme outdoor sports」。注意「stuff」「extreme」並不出現在任何描述中——傳統搜尋很難命中。
前置條件#
- 已安裝 Ollama 與 caddy(本機 HTTPS proxy)
- caddy 的自簽憑證需匯入 SQL Server 服務帳號可信任的憑證庫(Windows:
certlm.msc➜ Trusted Root Certification Authorities ➜ Import%APPDATA%\Caddy\pki\authorities\local\root.crt➜ 重啟 SQL Server 服務) - SQL Server 2025 Developer / Enterprise Edition,安裝時勾選 Full-Text Search
- 還原 AdventureWorks2022 資料庫
- 啟用 REST API:
enablerestapi.sql - 建立全文索引:
createft.sql - 啟用
PREVIEW_FEATURES:enable_preview_features.sql
對照:傳統搜尋幾乎找不到#
USE AdventureWorks;
SELECT * FROM Production.ProductDescription
WHERE Description LIKE '%Show me stuff for extreme outdoor sports%';
SELECT * FROM Production.ProductDescription
WHERE CONTAINS(Description, '"Show me stuff for extreme outdoor sports"');
SELECT * FROM Production.ProductDescription
WHERE FREETEXT(Description, 'Show me stuff for extreme outdoor sports');前兩個查詢回傳 0 列;FREETEXT 回兩列,但結果不夠理想。
步驟 1:建立 Model Definition#
USE [AdventureWorks];
IF EXISTS (SELECT * FROM sys.external_models WHERE name = 'MyOllamaEmbeddingModel')
DROP EXTERNAL MODEL MyOllamaEmbeddingModel;
CREATE EXTERNAL MODEL MyOllamaEmbeddingModel
WITH (
LOCATION = 'https://localhost/api/embed',
API_FORMAT = 'Ollama',
MODEL_TYPE = embeddings,
MODEL = 'mxbai-embed-large');
SELECT * FROM sys.external_models;Ollama 單筆 embedding 的 endpoint 是
/api/embeddings,但 SQL Server 用的是「批次」端點/api/embed。此處只是 metadata,沒有把 AI 模型載入資料庫。
步驟 2:建立 vector 表並產生 embeddings#
USE AdventureWorks;
DROP TABLE IF EXISTS Production.ProductDescriptionEmbeddings;
CREATE TABLE Production.ProductDescriptionEmbeddings
(
ProductDescEmbeddingID INT IDENTITY NOT NULL PRIMARY KEY CLUSTERED,
ProductID INT NOT NULL,
ProductDescriptionID INT NOT NULL,
ProductModelID INT NOT NULL,
CultureID nchar(6) NOT NULL,
Embedding vector(1024)
);這張「join 表」與原始描述表分離,便於管理:
- 必要的 single-column integer clustered primary key(vector index 前提)
vector(1024)對應mxbai-embed-large模型的最大維度
產生 embeddings:
INSERT INTO Production.ProductDescriptionEmbeddings
SELECT p.ProductID, pmpdc.ProductDescriptionID, pmpdc.ProductModelID, pmpdc.CultureID,
AI_GENERATE_EMBEDDINGS(pd.Description USE MODEL MyOllamaEmbeddingModel)
FROM Production.ProductModelProductDescriptionCulture pmpdc
JOIN Production.Product p
ON pmpdc.ProductModelID = p.ProductModelID
JOIN Production.ProductDescription pd
ON pd.ProductDescriptionID = pmpdc.ProductDescriptionID
ORDER BY p.ProductID;作者測試:有 GPU 的筆電 1 分鐘可生成 1,764 列 embedding;無 GPU 顯著變慢。
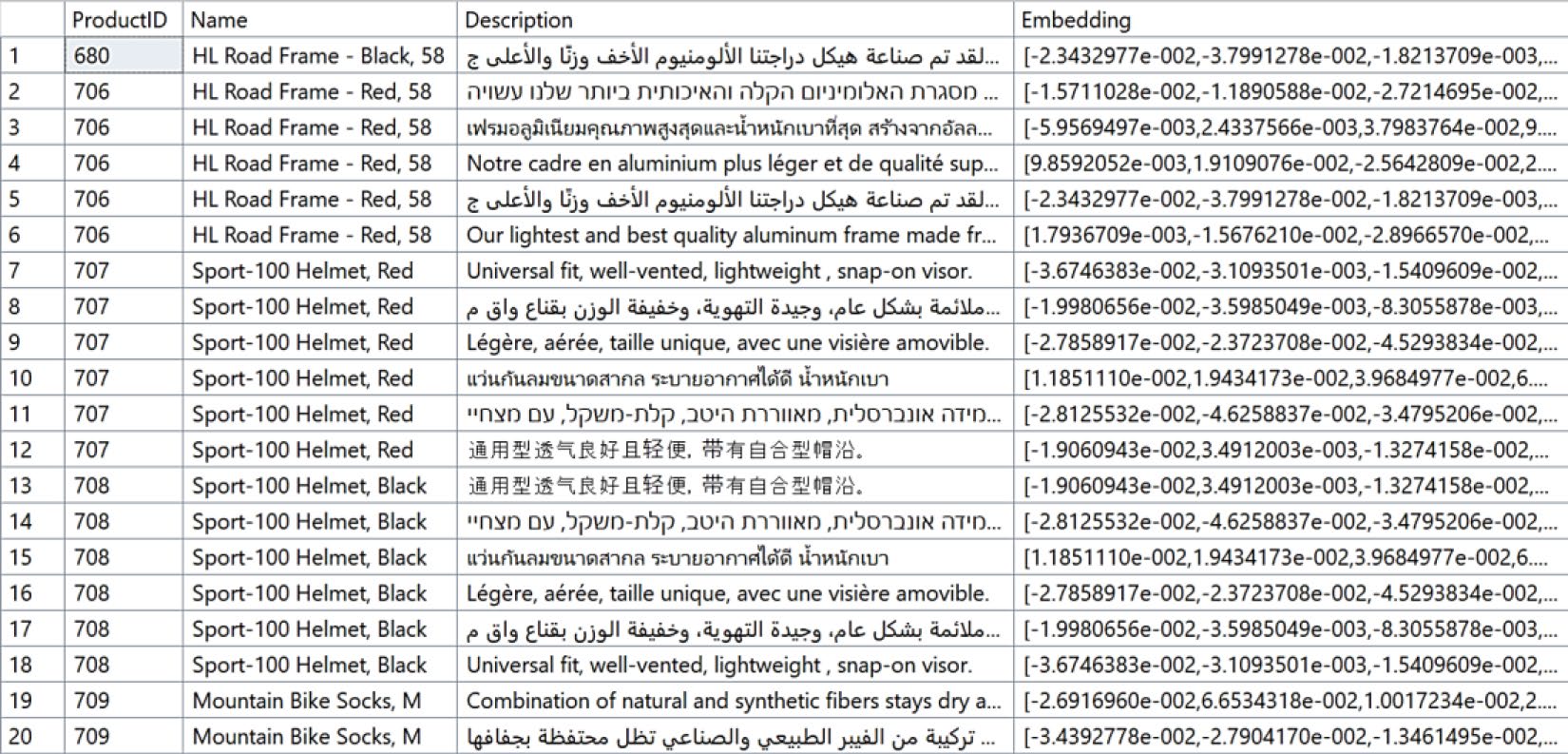
Figure 4-2: 在 SQL Server 2025 中探索 embeddings
步驟 3:建立 vector index#
USE [AdventureWorks];
CREATE VECTOR INDEX product_vector_index
ON Production.ProductDescriptionEmbeddings (Embedding)
WITH (METRIC = 'cosine', TYPE = 'diskann', MAXDOP = 8);步驟 4–7:以 prompt 做向量搜尋#
預存程序:
USE [AdventureWorks];
CREATE OR ALTER PROCEDURE find_relevant_products_vector_search
@prompt nvarchar(max),
@stock smallint = 500,
@top int = 10,
@min_similarity decimal(19,16) = 0.3
AS
IF (@prompt IS NULL) RETURN;
DECLARE @retval int, @vector vector(1024);
SELECT @vector = AI_GENERATE_EMBEDDINGS(@prompt USE MODEL MyOllamaEmbeddingModel);
SELECT p.Name AS ProductName,
pd.Description AS ProductDescription,
p.SafetyStockLevel AS StockLevel
FROM vector_search(
table = Production.ProductDescriptionEmbeddings AS t,
column = Embedding,
similar_to = @vector,
metric = 'cosine',
top_n = @top
) AS s
JOIN Production.ProductDescriptionEmbeddings pe
ON t.ProductDescEmbeddingID = pe.ProductDescEmbeddingID
JOIN Production.Product p
ON pe.ProductID = p.ProductID
JOIN Production.ProductDescription pd
ON pd.ProductDescriptionID = pe.ProductDescriptionID
WHERE (1 - s.distance) > @min_similarity
AND p.SafetyStockLevel >= @stock
ORDER BY s.distance;呼叫:
EXEC find_relevant_products_vector_search
@prompt = N'Show me stuff for extreme outdoor sports',
@stock = 100,
@top = 20;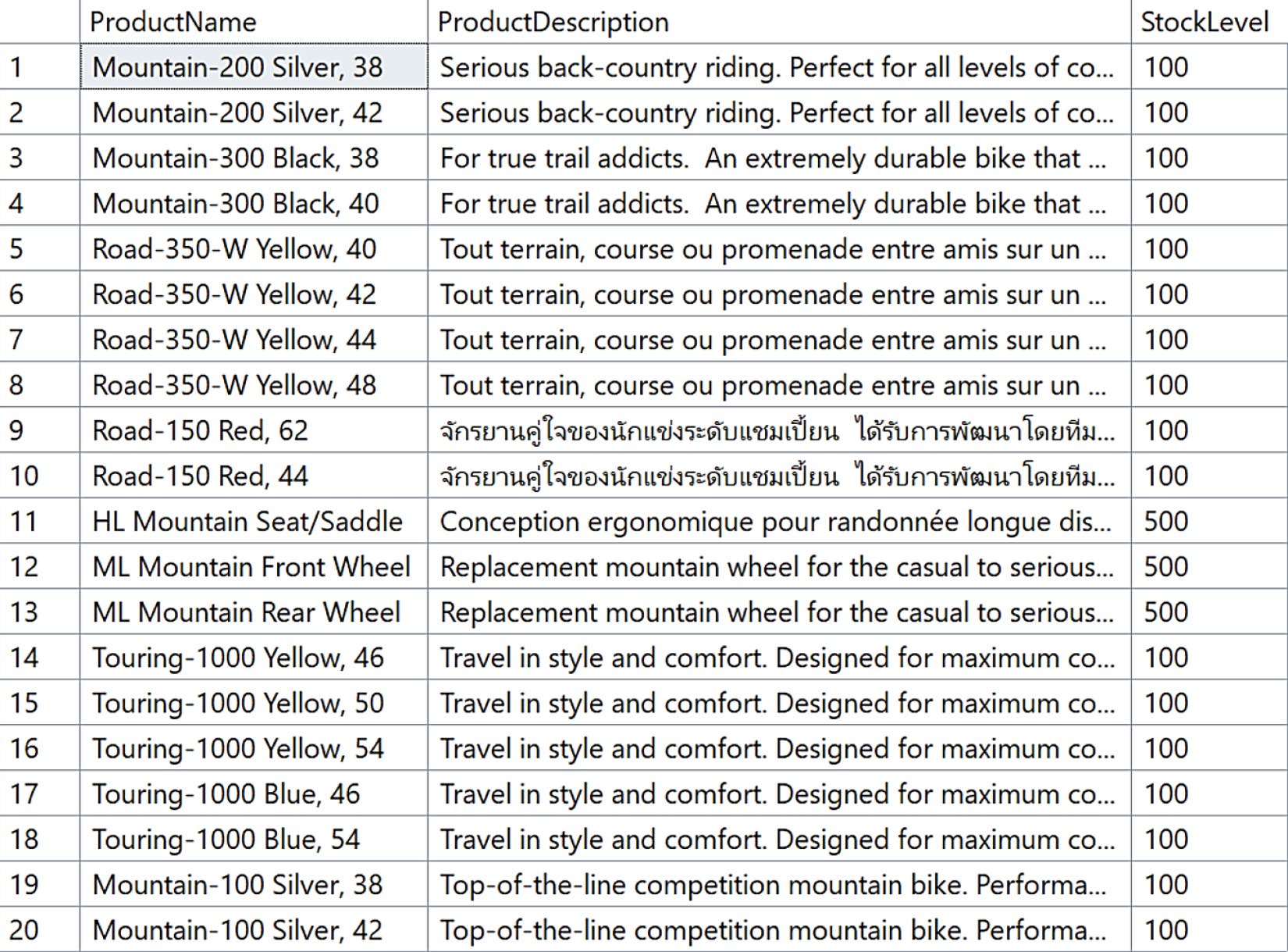
Figure 4-3: 使用 Ollama 進行向量搜尋的結果
VECTOR_SEARCH回傳的結果集包含原表所有欄位再加上distance:
distance越小代表越相似cosine索引必須以cosine搜尋
用 mxbai-embed-large 跑出來的結果有些不是英文——因為這個模型不擅長多語意處理。下一節改用 Azure AI Foundry 解決。
切換到 Azure AI Foundry#
OpenAI 的 text-embedding-ada-002 對多語言友善。改動很小:
1. 部署模型並取得 endpoint 與 API key#
部署文件:https://learn.microsoft.com/azure/ai-foundry/openai/how-to/create-resource
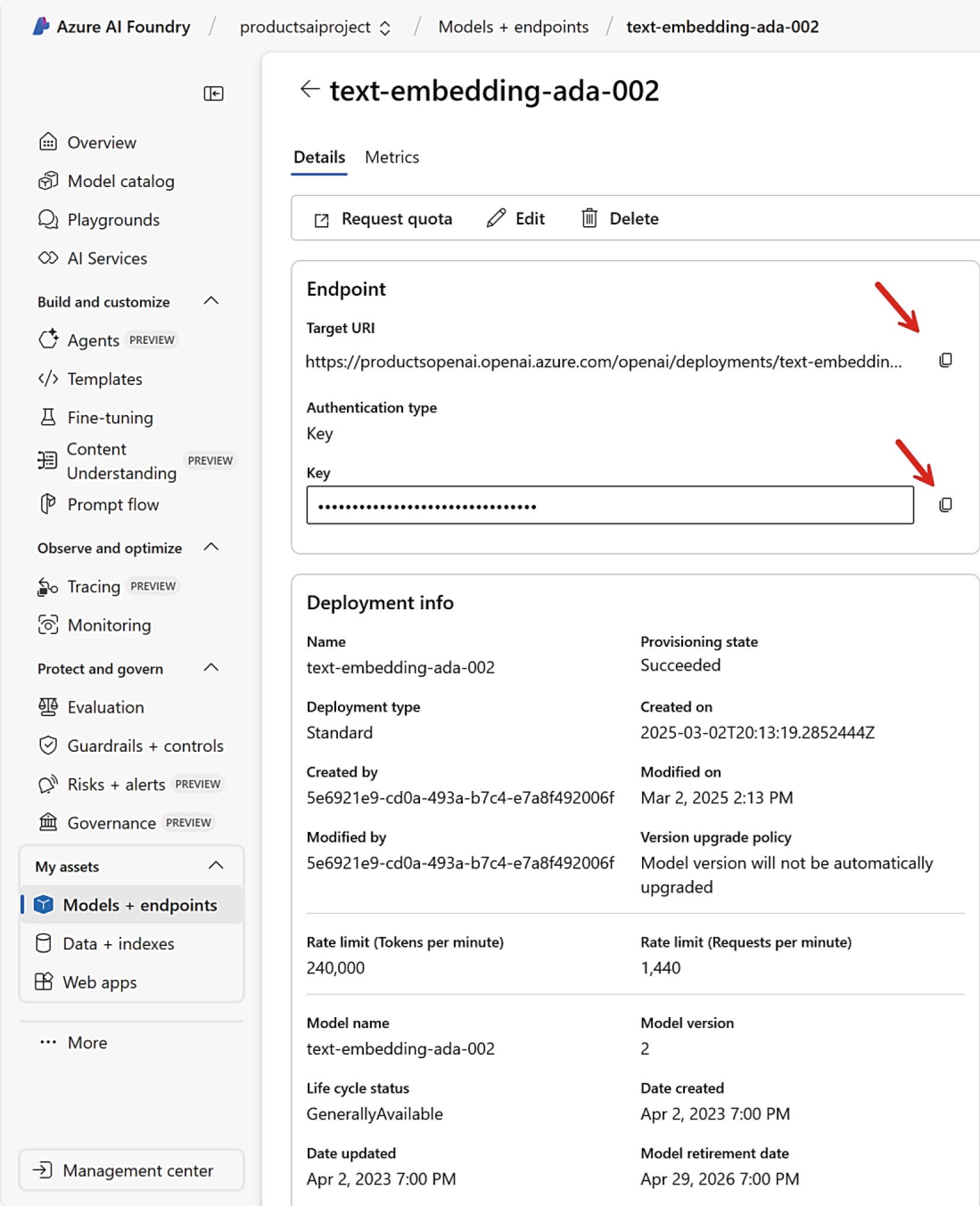
Figure 4-4: 來自 Azure AI Foundry 的 embedding 模型 endpoint 與 API key
2. 建立 master key 與 database scoped credential#
USE [AdventureWorks];
IF NOT EXISTS(SELECT * FROM sys.symmetric_keys WHERE name = '##MS_DatabaseMasterKey##')
BEGIN
CREATE MASTER KEY ENCRYPTION BY PASSWORD = N'<strongpassword>';
END;
IF EXISTS(SELECT * FROM sys.database_scoped_credentials WHERE NAME = 'https://<azureai>.openai.azure.com')
BEGIN
DROP DATABASE SCOPED CREDENTIAL [https://<azureai>.openai.azure.com];
END;
CREATE DATABASE SCOPED CREDENTIAL [https://<azureai>.openai.azure.com]
WITH IDENTITY = 'HTTPEndpointHeaders',
SECRET = '{"api-key": "<api_key>"}';3. 建立 Azure OpenAI external model#
CREATE EXTERNAL MODEL MyAzureOpenAIEmbeddingModel
WITH (
LOCATION = 'https://<azureai>.openai.azure.com/openai/deployments/text-embedding-ada-002/embeddings?api-version=2023-05-15',
API_FORMAT = 'Azure OpenAI',
MODEL_TYPE = EMBEDDINGS,
MODEL = 'text-embedding-ada-002',
CREDENTIAL = [https://<azureai>.openai.azure.com]
);重新生成 embeddings、重建索引、把預存程序改用 MyAzureOpenAIEmbeddingModel。
多語言驗證#
EXEC find_relevant_products_vector_search
@prompt = N'Show me stuff for extreme outdoor sports',
@stock = 100,
@top = 20;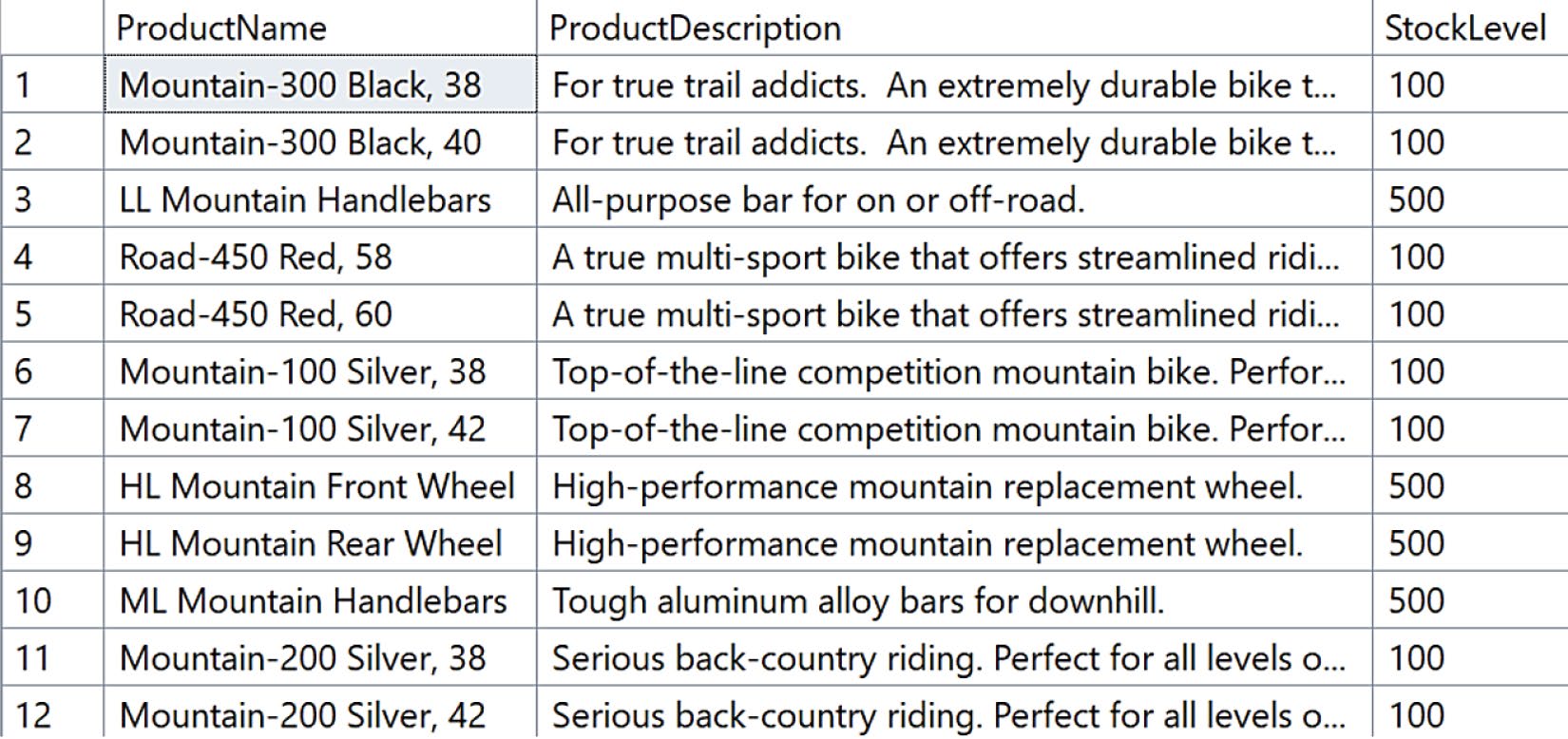
Figure 4-5: 使用 Azure AI Foundry 進行向量搜尋
EXEC find_relevant_products_vector_search
@prompt = N'请向我展示极限户外运动的装备',
@stock = 100,
@top = 20;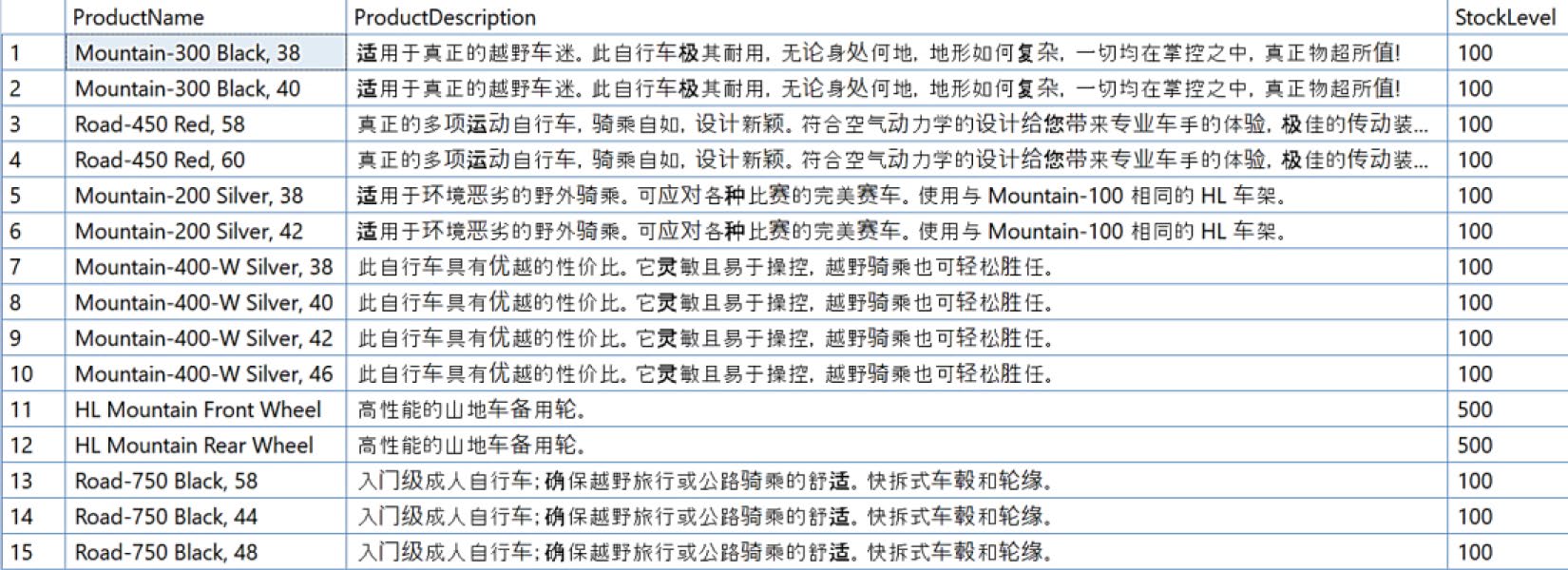
Figure 4-6: 使用 Azure AI Foundry 以另一語言進行向量搜尋
兩種語言都能命中相關產品——只是換了模型,應用就支援了多語言。
第 6 章會展示如何改用 Azure Managed Identity 取代 API key,達到更安全的驗證。
其他模型選項#
OpenAI 與 OpenAI-compatible#
設定 API_FORMAT = 'OpenAI',可用於:
- OpenAI 原生服務
- NVIDIA NIM(NVIDIA Inference Microservices):使用 NVIDIA Triton,支援 OpenAI REST 協定。範例:
nvidia/nv-embedqa-e5-v5-query - vLLM:常用於 Linux,模型多來自 Hugging Face
- KServe:Kubernetes 開源服務
CREATE EXTERNAL MODEL MyOpenAICompatEmbeddingModel
WITH (
LOCATION = 'https://bwsqlnvidia.centralus.cloudapp.azure.com/v1/embeddings',
API_FORMAT = 'OpenAI',
MODEL_TYPE = EMBEDDINGS,
MODEL = 'nvidia/nv-embedqa-e5-v5-query',
CREDENTIAL = [https://bwsqlnvidia.centralus.cloudapp.azure.com]
);NIM 不直接支援 HTTPS,需 proxy。
本地 ONNX 支援#
ONNX 模式不走 REST,但仍不在 SQL Server 引擎中載入模型:
- 借用原 SQL Server 2016 Machine Learning Services 的擴充框架
- 因此把 Machine Learning Services 改名為 AI Services and Language Extensions(必須安裝此功能)
- 需要
PREVIEW_FEATURES,且設定步驟相對繁瑣- 模型可從 Hugging Face 下載 ONNX 格式或自行轉換
設定步驟詳見:https://learn.microsoft.com/sql/t-sql/statements/create-external-model-transact-sql#example-with-a-local-onnx-runtime
SQL Server 2025 AI 的未來#
「我們的計畫是讓 vector 能力與 query optimizer 完全整合,可同時最佳化向量搜尋、向量索引與既有 filter。我們也計畫加入最新的 vector quantization 演算法以降低記憶體使用、提升效能;支援半精度浮點、稀疏向量等。」
— Davide Mauri,Microsoft
需要 PREVIEW_FEATURES 的功能(vector index、vector search、text chunking、ONNX)將透過後續 CU 達到 GA 品質。
安全與規模兼具的 AI#
「Vectors 正在改變我們與資料互動的方式——透過 embeddings 帶來自然、直覺的體驗。在 SQL Server 內部直接管理向量,借用世界級 query optimizer,不需外部工具,讓向量搜尋應用更易建構、更安全、效能也更高。每當資料離開資料庫,開發者就要付『整合稅』——複雜度、延遲、風險。把 vectors 留在資料庫裡,就完全省下這些成本。」
— Davide Mauri,SQL 端到端 vector 能力負責人
下一章將繼續開發者主題,看看為何 SQL Server 2025 是過去十年中對開發者最重要的版本。