本章為第 4 章 SQL Server 2025 的「AI 內建」(AI Built-In)能力打下基礎。即使你已掌握 AI 模型類型、向量、嵌入、向量搜尋、Retrieval Augmented Generation(RAG,檢索增強生成)、AI Tools、Model Context Protocol(MCP)等概念,仍建議先讀本章再進入第 4 章。
本章不含 SQL 程式碼,但會以 Ollama(
https://ollama.com,可在筆電本機安裝)做為 REST 範例的 AI 模型主機。
AI 應用之路(The Path)#
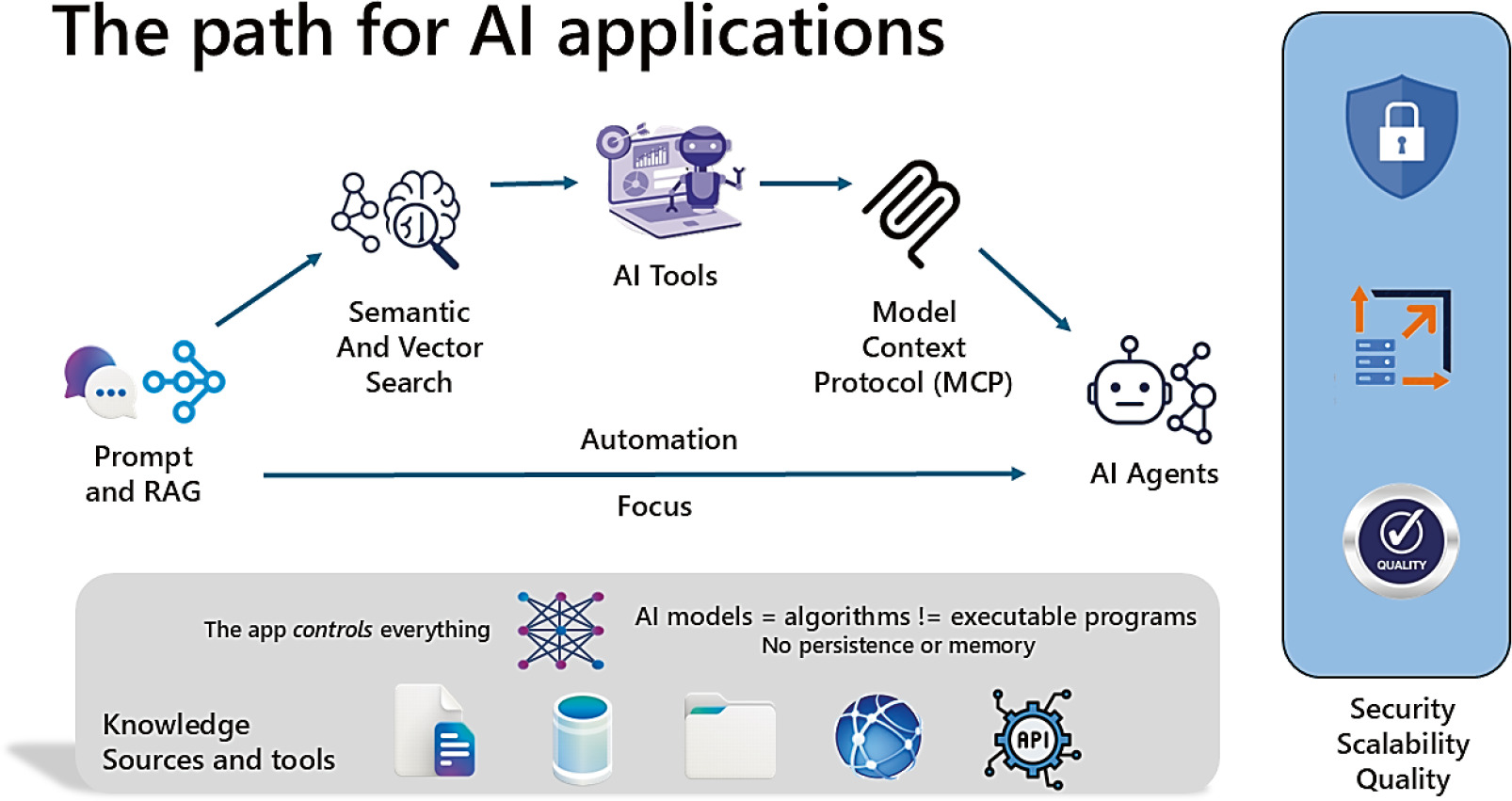
Figure 3-1: AI 應用之路
從左到右逐步堆疊#
微軟團隊發現許多客戶(甚至 SQL 專家)的 AI 知識落後於內部討論的速度,因此提出一條從左到右、逐步堆疊的路徑:
- Prompts:純粹用提示詞與 AI 模型互動
- RAG / Vector Search:以資料檢索豐富提示
- AI Tools:讓模型協助選擇與使用工具
- MCP(Model Context Protocol):標準化工具的探索與使用
- AI Agents:把任務交給能自主行動的代理
在這條路徑上越往右,越要重視三件事:
- Security(安全性)
- Scalability(規模化)
- Quality(品質)
你掌握 AI(You Control AI)#
某次演講後有聽眾問:「我要怎麼把 AI 關掉?」這個問題的根源,是把 AI 模型誤以為是會自己跑程式的軟體。事實上:
- AI 模型不是可執行程式,而是被應用程式載入使用的演算法檔案
- AI 模型沒有狀態(state),不會自己保留記憶
- AI 模型不能執行程式碼,只能「建議」應用程式去執行
- AI 模型無法搜尋網路或讀取你的資料;那是應用程式做的
ChatGPT 像是有對話記憶,其實是應用程式每次把整段對話歷程送進模型;token 上限會限制這個歷程能塞多長。
開發者對 AI 行為的掌控,遠超過直觀印象。
知識才是關鍵#
模型訓練資料只到某個時間點。要善用模型,常需以「你的知識」加以擴充——可能是檔案、資料庫、網路搜尋結果,甚至是 API 呼叫的輸出。
安全、規模、品質#
「如果你必須在安全與其他優先順序之間取捨,答案很清楚:選安全。」
— Satya Nadella,Microsoft CEO
SQL Server 2025 的「新」AI 能力主要落在路徑的前兩段:RAG 與 向量搜尋。Tools、MCP、AI Agents 仍可使用 SQL Server 2025(含向量搜尋),但這些主題本身不是 SQL Server 2025 的新功能。
Prompts 與 RAG#
兩種提示#
當應用程式呼叫語言模型(Language Model)的 API 時,通常包含兩種 prompt:
- System message:界定模型的角色與回應方式(例:「你是一位購物小幫手」)
- User prompt:使用者的查詢或指令(例:「幫我找滑雪用的最佳服飾」)
模型回傳的是 生成式(generative) 回應——不僅理解語言,也以接近人類的方式回覆。
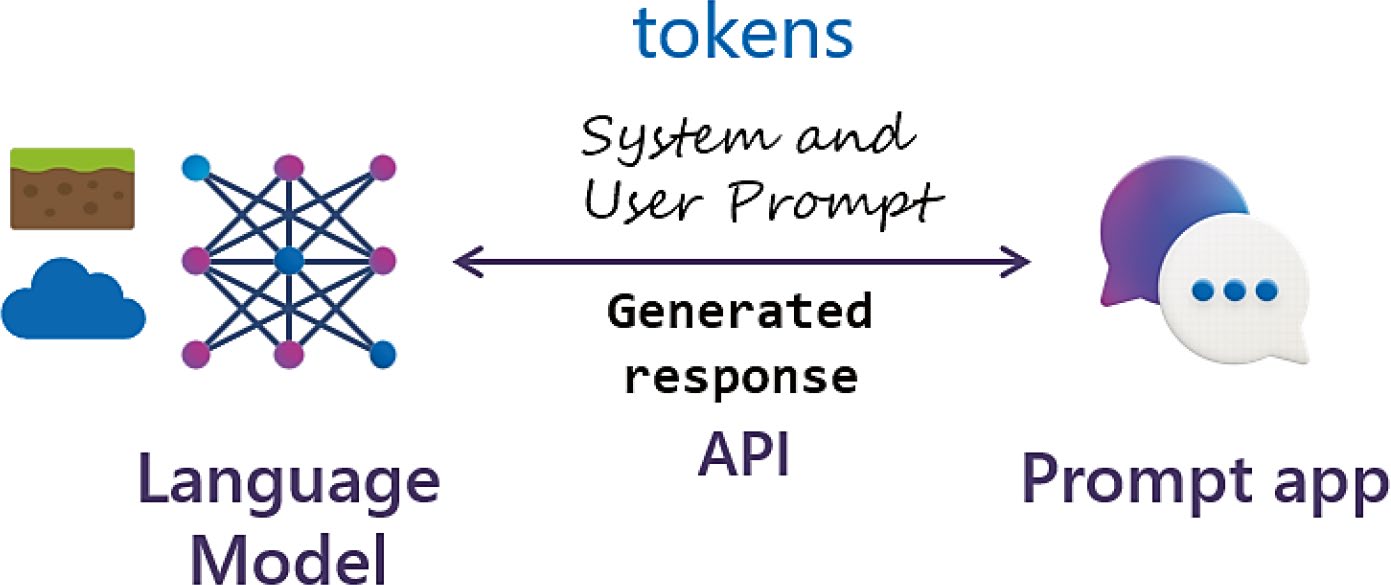
Figure 3-2: 提示與 AI 模型
推論引擎與 Token#
API 背後是 推論引擎(inference engine),負責載入模型、接收輸入並產生回應。常見實作:
- ONNX Runtime
- TensorRT
- vLLM
開發者通常透過 Ollama、OpenAI、Azure AI Foundry 等代管服務經由 REST 存取,毋須直接面對推論引擎。
模型互動以 token 計算。粗略換算:英文 100 字 ≈ 75 tokens。Token 上限同時涵蓋 system message、user prompt 與回應。
OpenAI 的 GPT-5 支援 128,000 tokens,相當於約 192 頁的文字。
Retrieval Augmented Generation(RAG)#
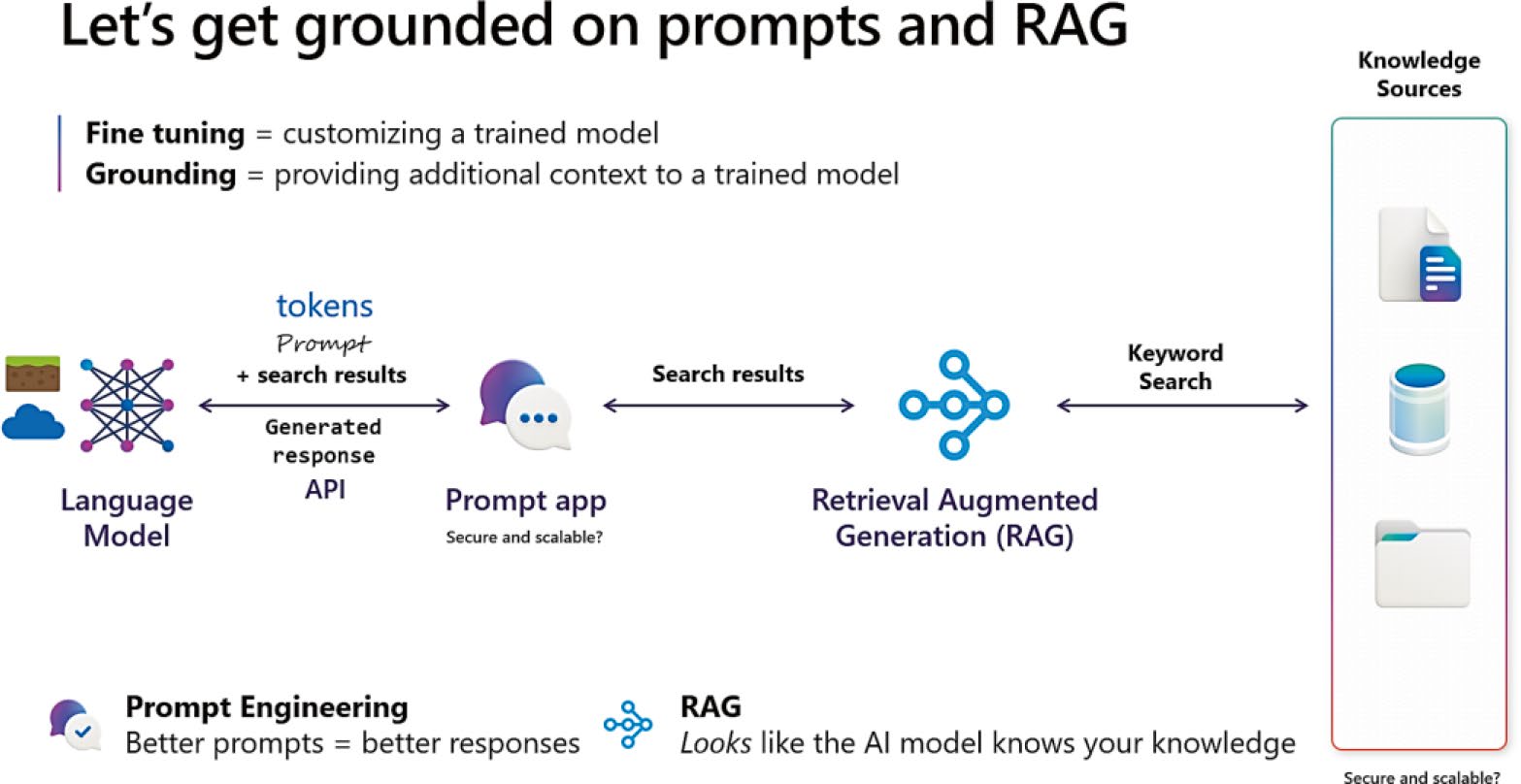
Figure 3-3: 提示與 RAG
RAG 是 prompt engineering 的一種形式:
- 應用程式先用搜尋(最簡單是關鍵字搜尋)取得相關資料
- 把搜尋結果加進 prompt 一併送給模型
- 模型基於更豐富的脈絡產生回應
RAG 又稱 grounding(接地),但要分清楚兩件事:
- Grounding ≠ Tuning:tuning 是真的改變模型權重;grounding 只是把資料塞進 prompt
- 模型不會記住 你給的資料;保留資料的是應用程式
AI 模型#
模型類型#
Chat Completion(聊天完成)#
- 最常見的語言模型類型
- 代表作:OpenAI 的 GPT(Generative Pre-trained Transformer)
- 支援 assistant prompt(前一輪回應)+ user prompt 形成多輪對話
- 模型本身仍無記憶——每一輪由應用程式重送整段歷程
Google 的 BERT(Bidirectional Encoder Representations from Transformers) 與 GPT 同期推出,能力相似但取向不同。
Deep Reasoning(深度推理)#
- 擁有 chat completion 的全部能力,加上更複雜的「思考」
- 常與 tools 概念深度結合
- 代表作:GPT-5
- 通常處理時間更長,但回應品質更高
Embeddings(嵌入)#
- 將文字、影像、音訊、影片轉成有語意的數字陣列
- 這些向量稱為 embeddings,由模型生成且只有模型知道意義
- 兩組向量可用 cosine distance(餘弦距離) 比較相似度——距離越近越相似
- 知名範例:OpenAI 的
text-embedding-ada-002
資料科學家過去使用的 feature vectors(特徵向量)是人類設計、可讀的。而 embedding 是模型生成、人類不可讀但可比較相似度。
其他類型#
- 語音辨識、影像生成(如 DALL-E)、文字轉語音、語音轉文字、語言翻譯等
- 模型來源:Azure AI Foundry、Hugging Face、GitHub repos
模型大小#
| 名稱 | 中文 | 特點 |
|---|---|---|
| LLM | Large Language Model | 數百億級參數、需 GPU |
| MLM | Medium Language Model | 中型 |
| SLM | Small Language Model | 小型 |
| Mini | (如 GPT-4.1 Mini、Phi-4 Mini) | 極小型 |
從 mini 到 large 能力遞增,成本與資源也遞增。許多應用一律使用 LLM 其實並無必要。
要不要用 GPU?
- Fine-tuning 模型 → 強烈建議
- Chat completion 或 deep reasoning → 顯著更快
- 輕量 embedding → 不一定需要
- 大量 embedding 批次處理 → 顯著加速
取得與存取 AI 模型#
Azure AI Foundry#
- Microsoft 的企業級 AI 雲端 PaaS
- 模型來源涵蓋 OpenAI、NVIDIA、Hugging Face、Mistral、Llama、Cohere、Grok、DeepSeek 等
- 透過 REST 存取,需 Azure 訂閱
- 微軟對上架模型有品質、安全、公平性審核流程
OpenAI#
- GPT 系列、
text-embedding-ada-002、text-embedding-3-small、text-embedding-3-large等 - OpenAI 制定的 REST 協定成為業界標準(許多服務支援 OpenAI-compatible endpoint)
- 寫作期間 OpenAI 也釋出開源模型
Hugging Face#
- 全球開源 AI 模型最大平台,估計超過 100 萬個模型
- 多數模型可下載免費使用,部分有授權限制
- 也提供 HUGS(Hugging Face Generative AI Services)付費代管
NVIDIA#
- 不只是 GPU 廠商;提供 NVIDIA AI Enterprise Platform 軟體平台
- 透過 REST 提供模型,或以 NIM(NVIDIA Inference Microservices) 容器交付
- NIM 內建 Triton 主機服務,可獨立部署於 Linux 或 Kubernetes
ONNX Runtime#
- ONNX(Open Neural Network Exchange)是 Microsoft 與 Facebook 於 2017 年合作的開源中性模型格式
- ONNX Runtime 可被任何應用內嵌,以 API 形式呼叫
- 在 SQL Server 2025(第 4 章)提供透過擴充框架使用 ONNX 模型的能力
Foundry Local#
- 2025 年 Build 大會發表,將 Azure AI Foundry 體驗帶到 Windows 與 macOS
- 內含模型目錄(含開源與付費);針對 CPU、GPU、NPU 自動最佳化
- 背後使用 ONNX Runtime;自帶模型必須是 ONNX 格式
- 支援 OpenAI-compatible REST endpoint
Ollama#
- 目前最受歡迎的地端 AI 模型代管軟體
- 跨 Windows、Linux、容器;以 REST 提供服務
- 支援 GGUF(GPT-Generated Unified Format)格式自帶模型;也有付費 Turbo 服務
REST 與 AI 實作#
REST(Representational State Transfer)是與 AI 模型互動最常見的方式。Windows 預設就附帶 curl,是極佳的測試工具。
Ollama + Caddy 的 HTTPS 設定#
為什麼需要 caddy?
- Azure OpenAI、OpenAI 原生支援 HTTPS
- Ollama、NVIDIA Triton 不支援 HTTPS
- 需要反向代理(reverse proxy)把 HTTPS 流量轉到本機服務
- caddy 自動安裝自簽憑證,比 nginx 更方便本機測試
範例 Caddyfile(簡化重點):
{
admin localhost:2019
}
localhost, 127.0.0.1 {
tls internal
@ollama path /api/* /v1/*
reverse_proxy 127.0.0.1:11434 {
flush_interval -1
}
}啟動:
.\caddy_windows_amd64.exe run --config Caddyfile
.\caddy_windows_amd64.exe trust用 curl 呼叫 Ollama#
下載模型後,用 curl 呼叫:
ollama pull llama3
curl -H "Content-Type: application/json" -d "{
\"model\":\"llama3\",
\"messages\":[
{\"role\":\"system\",\"content\":\"You are a helpful assistant that explains database concepts clearly.\"},
{\"role\":\"user\",\"content\":\"Explain the difference between clustered and nonclustered indexes in SQL Server.\"}
],
\"stream\":false
}" http://localhost:11434/api/chat不同 endpoint 的協定路徑:
- Ollama:
/api/chat- OpenAI / Azure OpenAI / OpenAI-compatible:
/v1/chat/completions
換成 HTTPS#
設定好 caddy 後,網址改成 https://localhost/api/chat,連 port 都不用寫(caddy 監聽 443):
curl --ssl-no-revoke -H "Content-Type: application/json" -d "{...}" https://localhost/api/chat
--ssl-no-revoke是 Windows 內建curl.exe的特殊需求;用 T-SQL 透過 caddy 時不需要。
第 5 章將以 T-SQL 預存程序
sp_invoke_external_rest_endpoint把這個概念整合進 SQL Server。
加入向量搜尋#
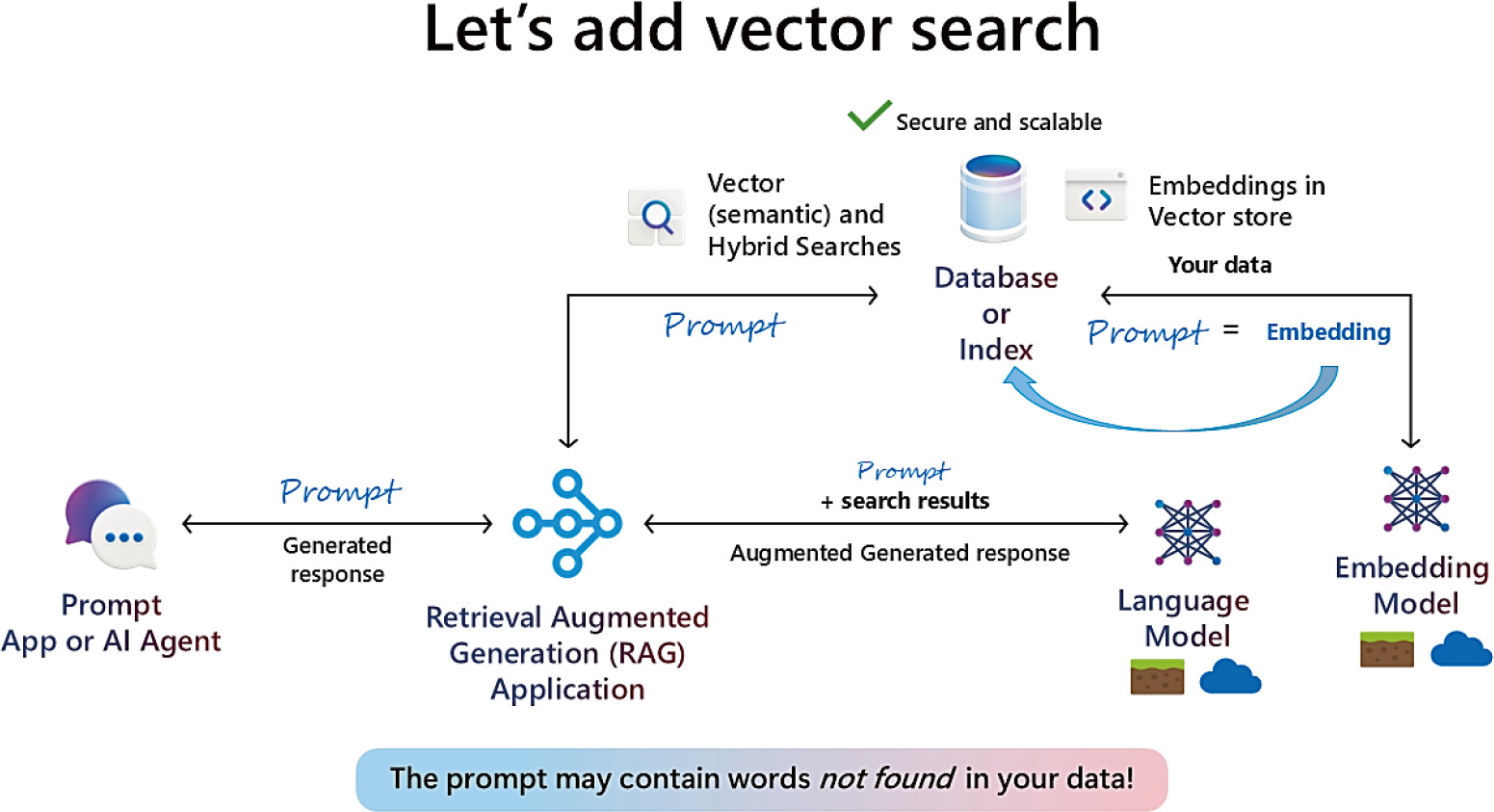
Figure 3-4: 以你的資料進行向量搜尋
概念#
向量搜尋(vector search,又稱 semantic search,語意搜尋)流程:
- 用 embedding 模型把資料轉成向量並存進資料庫或索引
- 查詢時把 prompt 也轉成向量
- 在資料庫/索引中找最相近的向量(常用 cosine distance)
向量搜尋的關鍵價值:prompt 中的字詞不必出現在資料中。模型理解語意,所以「tight」與「fitted」等同義詞能被找到。
結合 RAG,模式進一步強化:先做向量搜尋(或結合關鍵字搜尋的 hybrid search),再把結果交給聊天模型生成最終回應。
不依賴 SQL Server 的快速原型#
- Azure AI Search 內建 SQL Database / Managed Instance / Azure VM 上 SQL Server 的 indexer
- Azure AI Foundry 可上傳 Excel 後自動建向量索引,再到 chat playground 試問
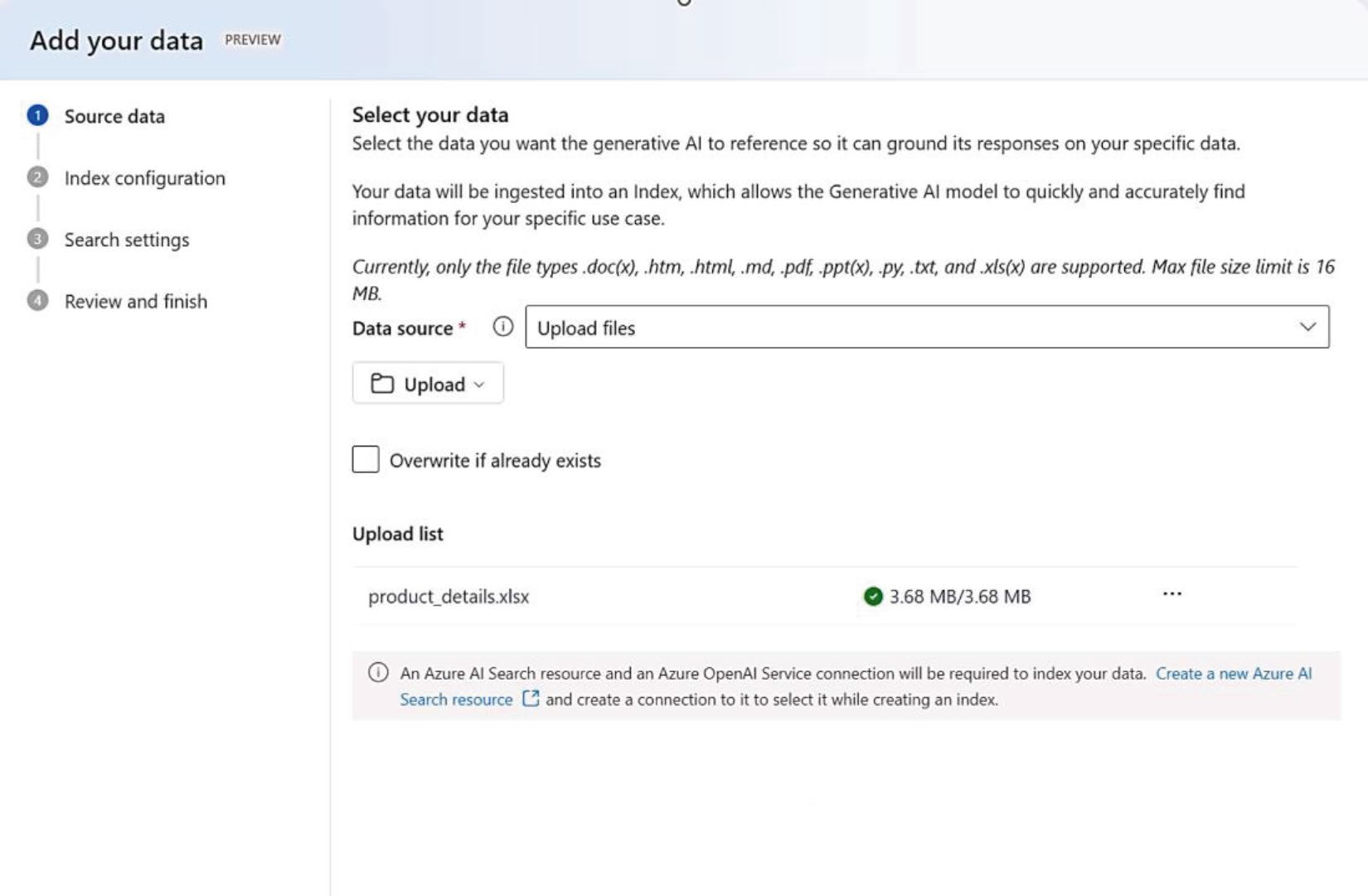
Figure 3-5: 在 Azure AI Foundry 為試算表建立向量索引
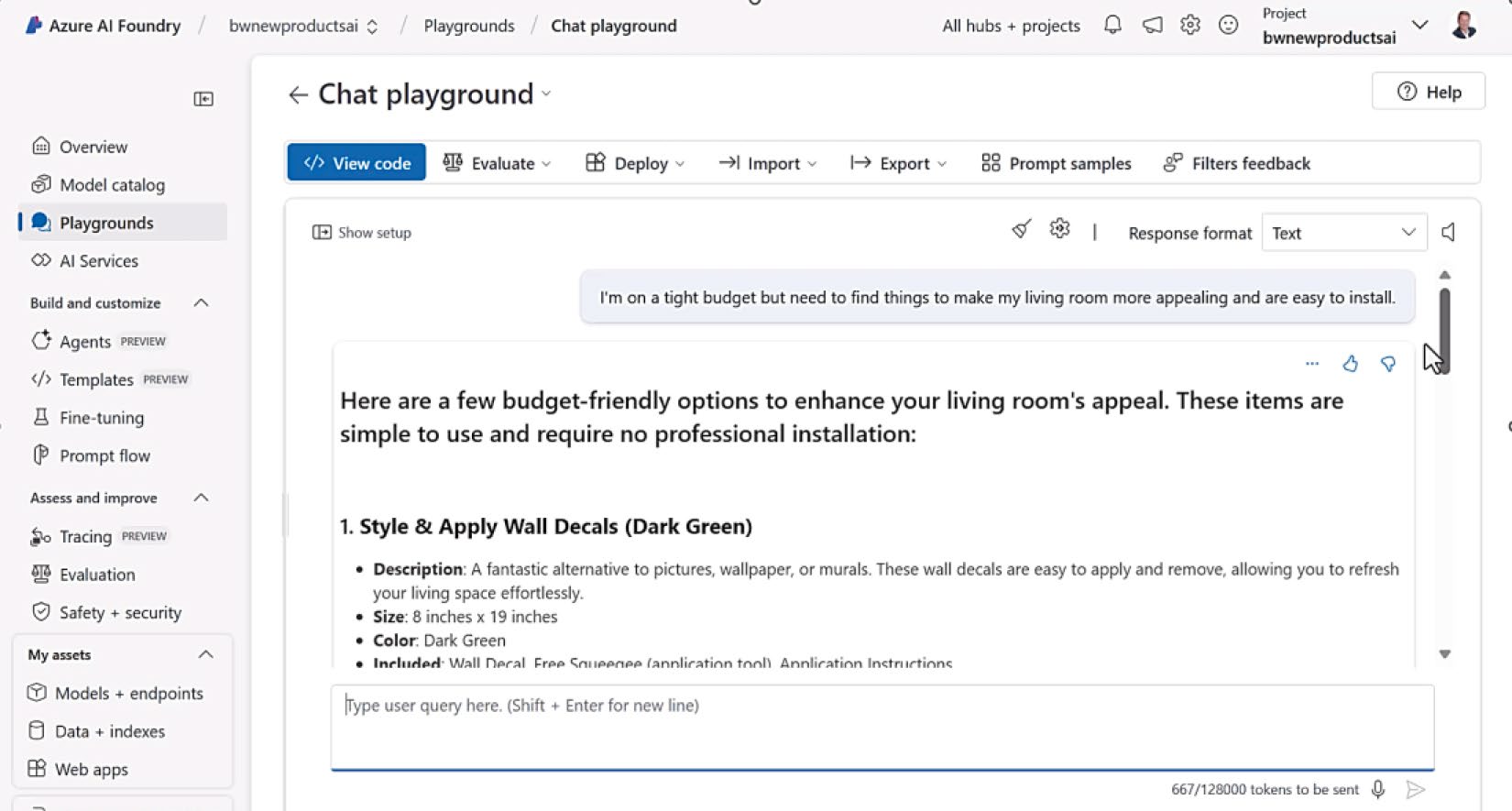
Figure 3-6: 使用 chat playground 對試算表進行向量搜尋
用 Ollama 產生 embeddings#
ollama pull mxbai-embed-large
curl --ssl-no-revoke -X POST https://localhost/api/embeddings \
-H "Content-Type: application/json" \
-d "{\"model\": \"mxbai-embed-large\", \"prompt\": \"The Dallas Cowboys are the best team in the NFL\"}"回傳的 JSON 包含 embedding 欄位,內含浮點數陣列——即輸入文字的語意向量。第 4 章會看到 SQL Server 2025 如何把這些數字轉成新的二進位 vector 資料型別。
AI Tools 與 MCP#
AI Tools#
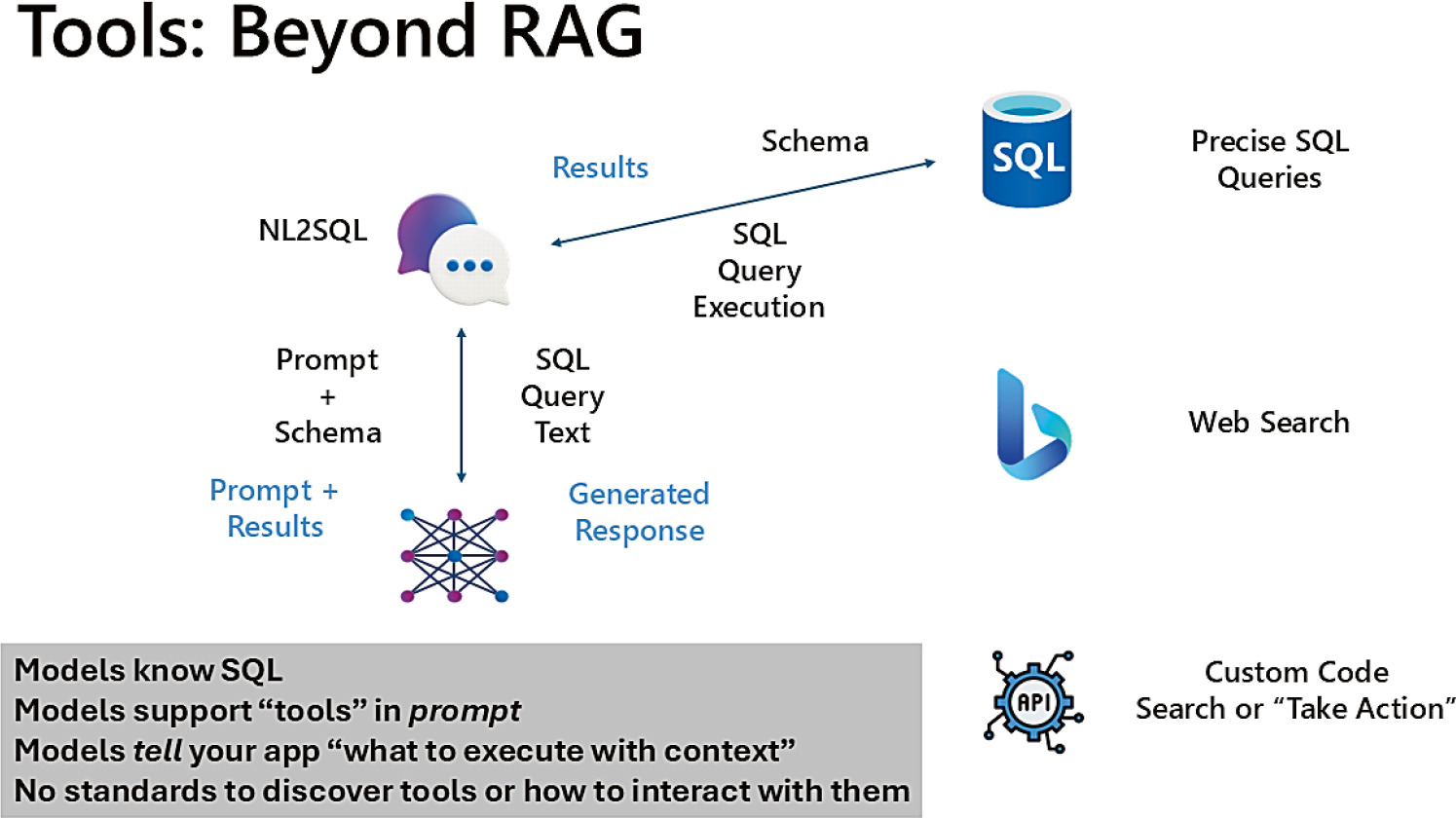
Figure 3-7: SQL Server 作為 AI 工具
當應用需要的不只是「搜尋」而是「精確查詢」時,可以把 SQL Server 當成 工具(tool):
- 應用程式取得資料表 schema → 以 system message 提供給 AI 模型
- AI 模型「建議」一段 T-SQL(不會自己執行)
- 應用程式選擇是否執行該 T-SQL
- 可選:用查詢結果再做 RAG,回傳給模型作最終回應
責任歸屬:執行 T-SQL 的是應用程式,不是 AI 模型——這是基本安全準則。模型只是「提議」(propose)。
範例 payload 結構(簡化版):
{
"model": "llama3.1",
"stream": false,
"tools": [{
"type": "function",
"function": {
"name": "propose_sql",
"description": "Propose a read-only, parameterized T-SQL SELECT...",
"parameters": { "...JSON Schema..." }
}
}],
"messages": [
{ "role": "system", "content": "T-SQL policy: read-only, parameterize all values..." },
{ "role": "system", "content": "Schema subset: Sales.SalesOrderHeader..." },
{ "role": "user", "content": "Show the top 10 products by total revenue in the last 30 days." }
]
}模型回傳 tool_calls 結構,包含 sql、bindings、tables_used 等欄位,由應用程式解析後執行參數化查詢。
Model Context Protocol(MCP)#
Tools 雖然普及,但缺乏標準的探索與通訊協定。MCP(https://modelcontextprotocol.io)由 Anthropic 於 2024 年 11 月推出,被稱為「AI 的 USB-C」。
| 元件 | 角色 |
|---|---|
| MCP Server | 實作各種工具,提供給 hosts 呼叫 |
| MCP Client | 處理 host 與 server 之間的協定通訊 |
| MCP Host | 託管 client 的 AI 應用程式 |
- 通訊協定:JSON+RPC over stdio(本機)或 HTTPS(遠端)
- Microsoft 已釋出 SQL Server 的 MCP Server preview:
https://github.com/Azure-Samples/SQL-AI-samples/tree/main/MssqlMcp,提供 List Tables、Read Data 等工具 - 可搭配 VSCode + GitHub Copilot 或 Claude Desktop 等 host 試用
MCP Server 由 server 自己執行 T-SQL,多了一層安全與最佳實踐邊界。但 MCP 仍屬新興技術,且多為開源實作,企業採用節奏可能較慢。
AI Agents#
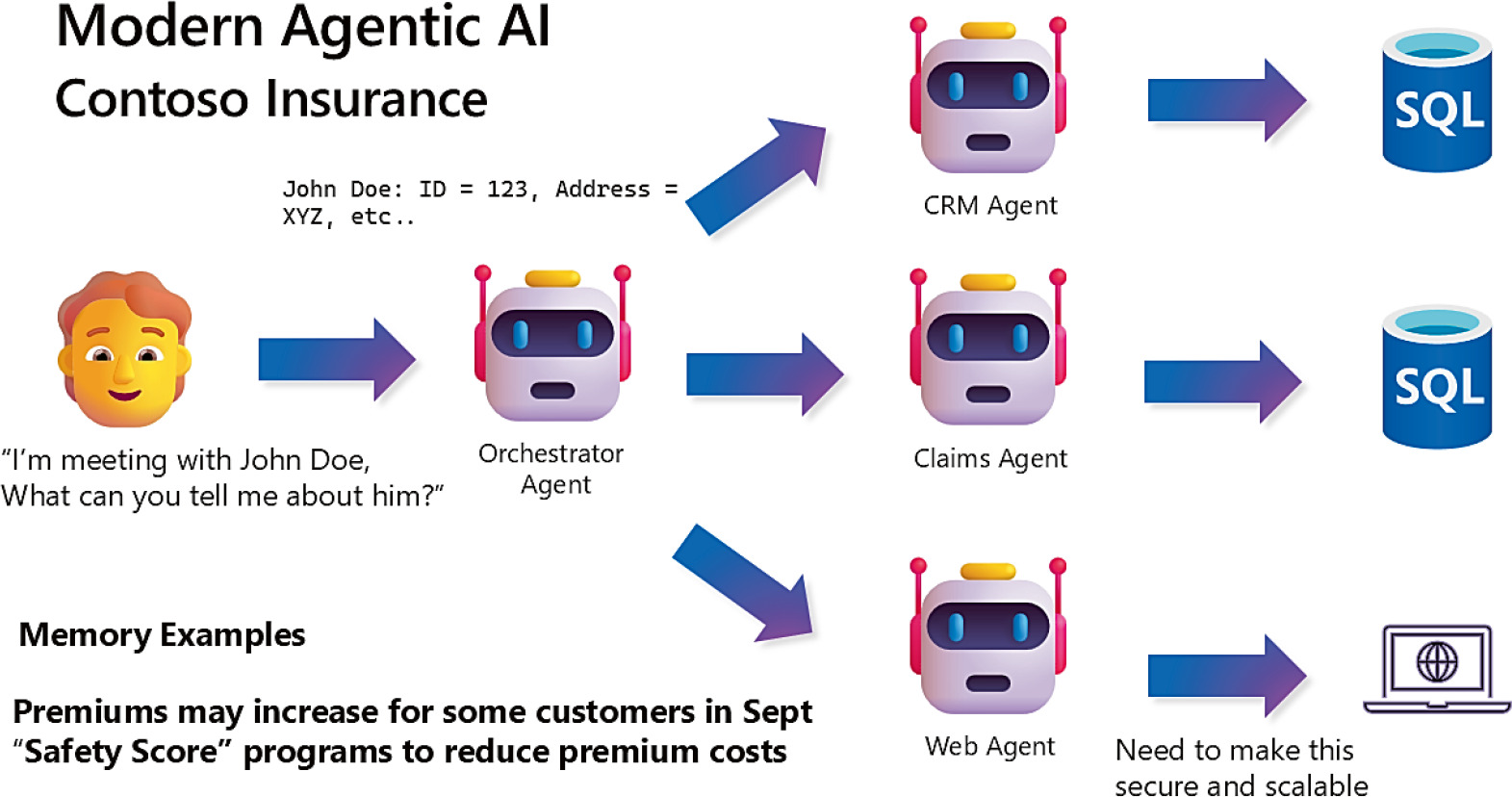
Figure 3-8: AI Agents
「Agent 就是人類可以委派任務的東西。」
— Kevin Scott,Microsoft CTO
差異:
- Chat 模式:你貼上會議筆記 → 我幫你摘要 + 草擬 email
- Agent 模式:我自己到 Teams 找筆記 → 摘要 → 草擬 email →(可能)幫你寄出
AI Agent 不只是回答問題,而是完成任務,有時是自主完成。但仍記得:執行任務的是應用程式(agent),AI 模型只是它的助手。
這是為什麼路徑越右側、越要強化 security、scalability、quality。
模組化設計#
- 把問題拆成多個 agent 比單一 monolithic 更佳
- Davide Mauri 的保險範例:Orchestrator agent 協調 CRM、claims、web search 等子 agent
- 每個 agent 都可以背後接一個 MCP Server
- 通常會加入「memory」概念
範例專案:https://github.com/Azure-Samples/azure-sql-db-chat-sk/tree/insurance-chatbot-demo
品質怎麼把關#
- 看模型 benchmark:
https://llm-stats.com、Azure AI Foundry 的模型比較 - 你選擇模型:知道不同模型的特性,按需使用
- 研究訓練資料:例如
https://cdn.openai.com/gpt-5-system-card.pdf - 用 temperature 等參數調校:
- 範圍 0–2.0,預設 1.0
- 數值越低,多次相同 prompt 的回應越一致
- 數值越高,回應越有創意但可能不一致或產生幻覺(hallucination)
- 應用、資料、工具的品質掌握在你手上:別因為加了 AI 就降低原本對品質的要求
經驗教訓#
- 建立 Responsible AI 政策:Microsoft 的版本可參考
https://www.microsoft.com/ai/responsible-ai - 像對待軟體一樣對待 AI 模型:列入企業軟體採購流程
- 設計時加上護欄(guardrails):先弄清楚商業問題,再用 path 從小做起,避免「只是想用 AI」的失敗專案
- 選對模型類型:別用 chat completion 模型去產生 embeddings,反之亦然
- 檢視資料品質與安全:AI 結果好壞取決於資料的好壞
啟航 SQL Server 2025 AI Built-In#
「AI 時代已經來臨。SQL 從業者必須超越傳統的查詢調校與 schema 設計。理解 AI 基礎已不再是選項,而是必備。SQL Server 2025 把 AI 深度整合進引擎,讓開發者與 DBA 能夠建構智慧應用、自動化洞察、釋放分析的新維度。學習 AI 讓你能駕馭這些能力,並使你的職涯具備未來保證。」
— Muazma Zahid,Microsoft
下一章將進入 SQL Server 2025 的 AI Built-In 能力,特別是向量搜尋與安全存取 AI 模型的方式。