為什麼有這一章#
整本書到這裡,已涵蓋從優化器、計畫、索引、統計到鎖、死結、in-memory、IQP 的所有主題。本章把所有原則整理成 可實踐的檢核表——當你拿到一個慢查詢時,照這張單子掃過去就能命中大多數常見問題。
這一章不是新內容,是 整本書的回顧 + 經驗法則彙編。Fritchey 開頭就說:「query tuning is hard」——這份方法論是降低那個難度的最後一道扶手。
四大主題:
- 資料庫設計(Database Design)
- 設定(Configuration Settings)
- 維運(Database Administration)
- 查詢設計(Query Design)
資料庫設計檢核表#
使用 Entity Integrity(唯一性約束)#
- 每張表都要有明確 PK / unique constraint
- artificial key(IDENTITY、GUID)vs. natural key 各有取捨:
- Artificial:型別窄、與業務解耦、GDPR 友善;但仍要為 natural key 加 unique 約束
- Natural:可讀性高;但通常較寬、會被業務變更影響、GDPR 較難處理
Unique index 不只是資料完整性——優化器需要它。書中實測:移除
UNIQUE後SELECT DISTINCT必須走 Stream Aggregate;加回UNIQUE後優化器知道資料天然不重複,計畫直接砍掉聚合運算。
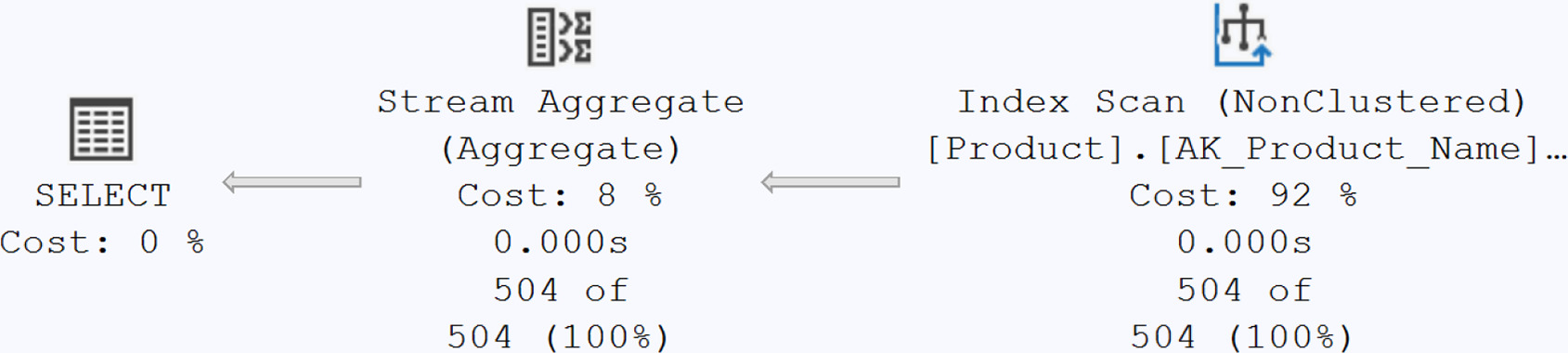
Figure 23-1: An aggregation operation with an execution plan

Figure 23-2: A UNIQUE constraint removes the need for aggregation
維護 Domain 與 Referential Integrity#
把 constraint 留在資料庫——它們不只是資料保護,更是 優化器的決策素材:
- 資料型別:把日期存成
date,不是varchar FOREIGN KEY:讓優化器在 simplification 階段刪除不需要的 joinCHECK:書中實測WHERE C2 = 30在CHECK (C2 BETWEEN 10 AND 20)的表上 → 優化器直接回空集,完全不讀表DEFAULT、NOT NULL
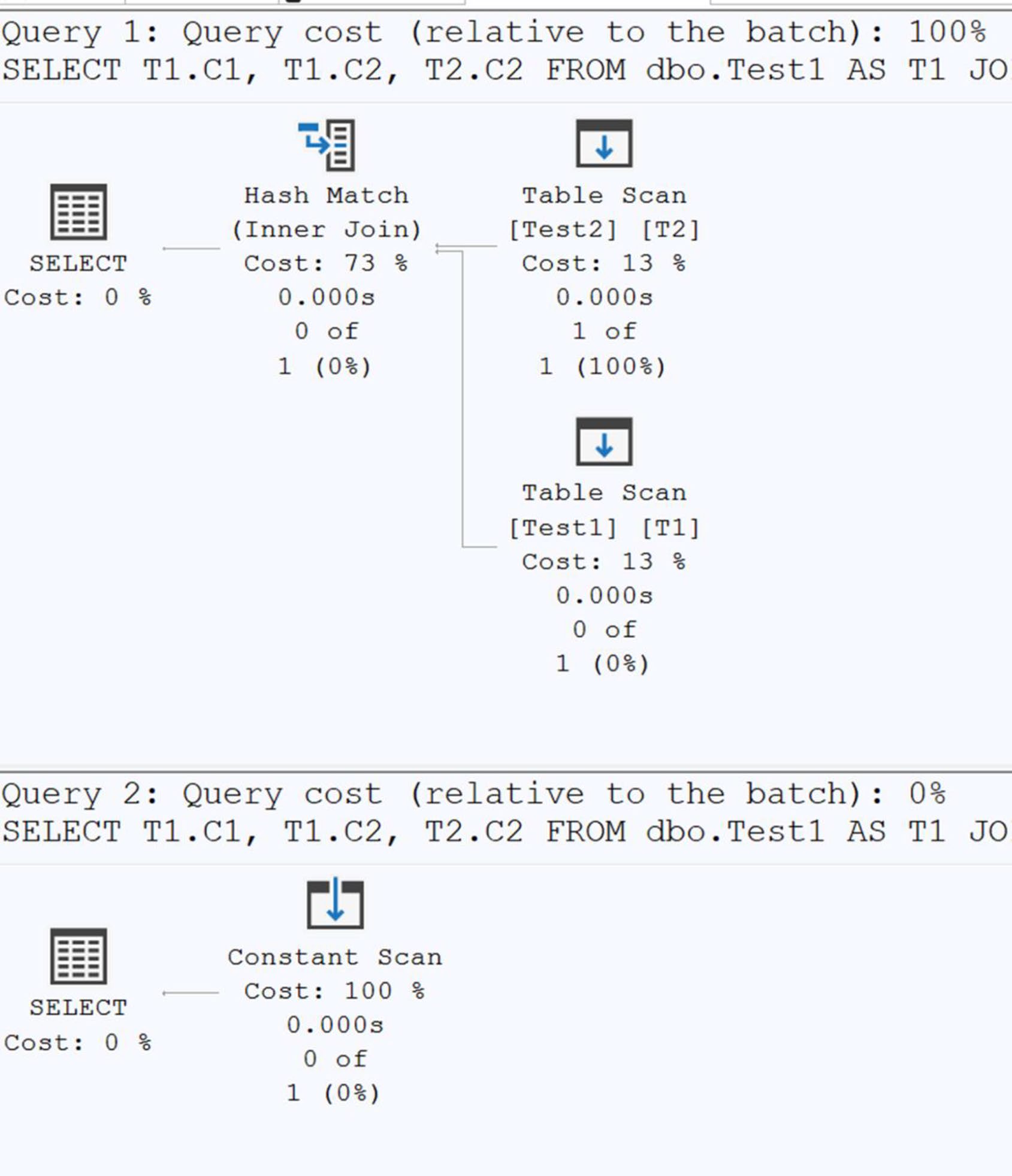
Figure 23-3: Plans where the predicate is within and outside a CHECK constraint
Constraint 必須是 TRUSTED(用
WITH CHECK建立)。批次匯入後務必:ALTER TABLE ... WITH CHECK CHECK CONSTRAINT ALL;
索引設計最佳實務#
- 鍵盡量窄
- 選擇性高的欄位優先
- 偏好 INT 類型,避免 VARCHAR
- 多欄位 index:選擇性高的放前面
- 用
INCLUDE做 covering index(不要塞 key) - 索引服務 WHERE / JOIN / HAVING
Clustered index 額外考量:
- key 越窄越好(會被每個 nonclustered index 攜帶)
- 先建 clustered,再建 nonclustered
- 重建時用
WITH (DROP_EXISTING = ON)避免 nonclustered 被重建兩次 - 不要把頻繁更新的欄位設為 clustered key
用
sys.dm_db_index_usage_stats找出「從未被使用」的索引——這些索引是純粹開銷。但記得這 DMV 會隨重啟重置,下手前再驗證。
Missing Index 的提示與
sys.dm_db_missing_index_*是 建議而非命令。這些 DMV 也無法和具體 query 對應,當作參考即可。
其他設計建議#
- 不要用
sp_開頭命名 stored procedure——會先去 master 找 - 少用 trigger——隱形成本,難以追蹤、容易變成 deadlock 根因
- 適當運用 in-memory tables(特別是 OLTP 高併發)
- 適當運用 columnstore(分析型)
- 適當運用 graph storage(多對多 / 階層關係)
- 使用適當的資料型別——避免隱式轉換
設定檢核表#
Memory#
- 設
max server memory,避免和 OS / 其他應用搶記憶體 - 必要時設
min server memory與 index creation memory
Cost Threshold for Parallelism#
預設 5 對絕大多數系統都太低。
不要把 MAXDOP 設為 1 來避免 parallelism 問題——應該調 cost threshold。
兩種設法:
- 科學派:撈出 plan cache 或 Query Store 中所有計畫的成本,計算平均 + 標準差,把 threshold 設為
平均 + 2 × 標準差或更高 - 經驗派:直接從 35 開始,監測後調整
Max Degree of Parallelism (MAXDOP)#
- 多 CPU 系統可限制單一查詢的並行度
- 避免 1(會完全停用 parallelism)
- OLTP 通常不需要禁用 parallelism——先調 cost threshold
Optimize for Ad Hoc Workloads#
對 ad hoc 為主的工作量幾乎是 無風險開啟——大幅減少 plan cache 的「只跑一次的計畫」。
Blocked Process Threshold#
EXEC sp_configure 'blocked process threshold', 5; -- 秒
RECONFIGURE;設定門檻 + 用 Extended Events 抓 blocked_process_report → production blocking 觀察的標準作法。
Database Compression#
- 2008 起 Enterprise / Developer Edition 提供
- 通常 節省的 I/O > 多花的 CPU
- 評估後啟用,特別是大表
維運檢核表#
統計資訊#
- 預設啟用 AUTO_CREATE_STATISTICS 與 AUTO_UPDATE_STATISTICS
- 必要時排程手動更新(大表、變動劇烈表)
- 非同步更新(async)對某些系統有幫助
- 若同時排程 index rebuild 與 statistics update,先做 statistics——index rebuild 會自動更新統計,反過來會白做
索引碎片#
Fritchey 在這版書中明確調整觀點:「設好 fill factor 比反覆 rebuild 更值得」。
多數系統不需要 nightly REBUILD job——測量過再修。
- Off-hours 進行
- 用
sys.dm_db_index_physical_stats取數據再決策 - 小表沒辦法 defragment
- Azure 上的 rebuild 會吃 I/O 額度(throttle 風險)
避免有害的自動行為#
AUTO_CLOSE = OFF:開啟會在最後連線關閉時清空 cache,下次重啟成本巨大AUTO_SHRINK = OFF:縮小檔案 → block 其他 process + OS 級別 fragmentation;應手動規劃容量
查詢設計檢核表#
最重要的一節——多數效能問題在這裡。
基本#
SET NOCOUNT ON:每個 procedure 第一行- 明確指定 schema:
dbo.MyTable而非MyTable - 避免 non-sargable 條件(
!=、NOT EXISTS、LIKE '%x') - 避免大量
IN清單(> 100 → 警惕、> 1000 → 必出問題) - 避免大量
OR子句(> 12 → 重構)
SQL Server 2022 起的
query_antipatternExtended Event 自動偵測這類模式,是排查反模式的好工具。
不要對欄位施加運算#
-- 壞
WHERE LEFT(SalesOrderNumber, 3) = 'SO5'
-- 好
WHERE SalesOrderNumber LIKE 'SO5%'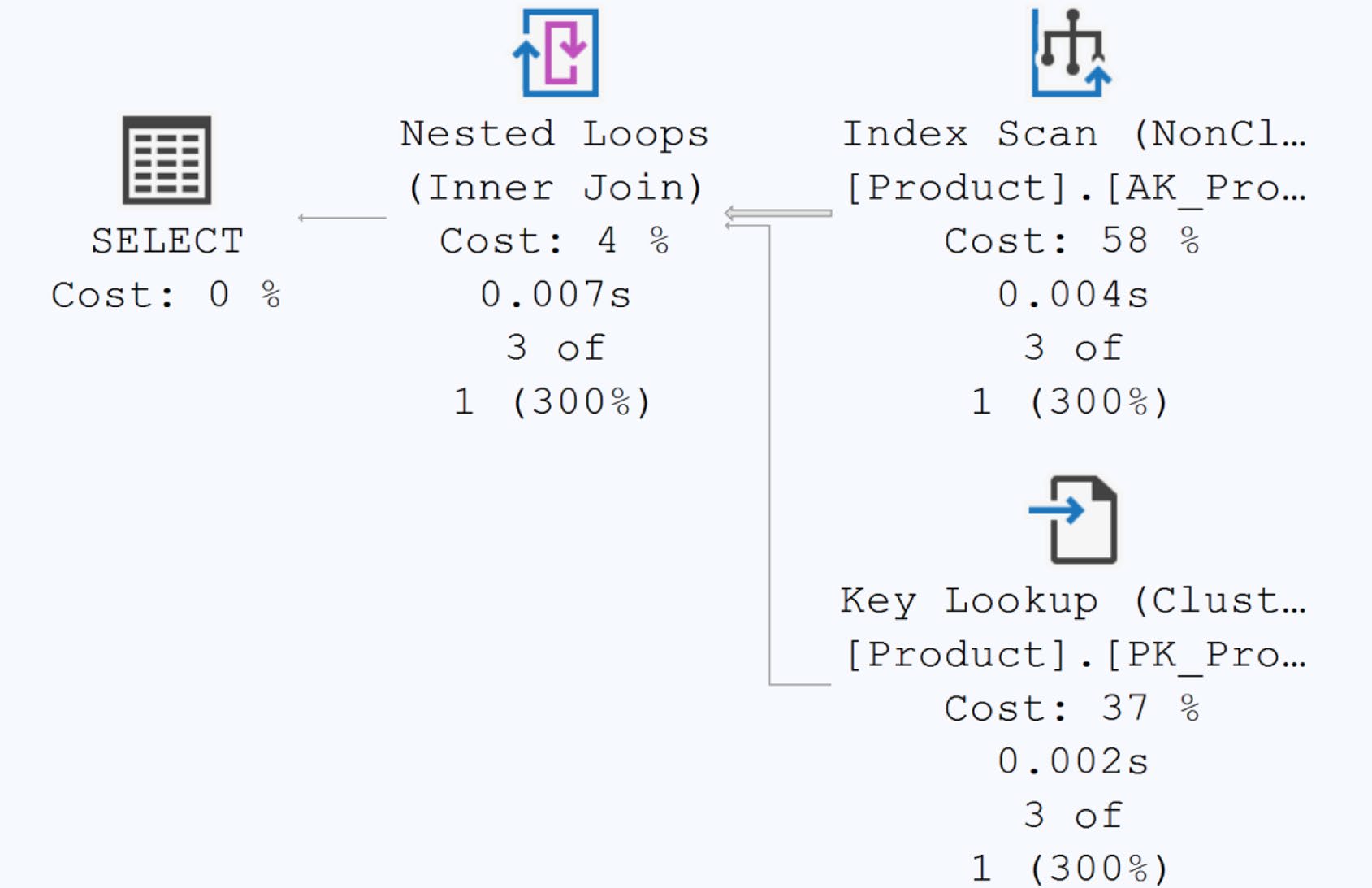
Figure 23-4: Execution plan with poor performance
第一個走 index scan、第二個能 seek。
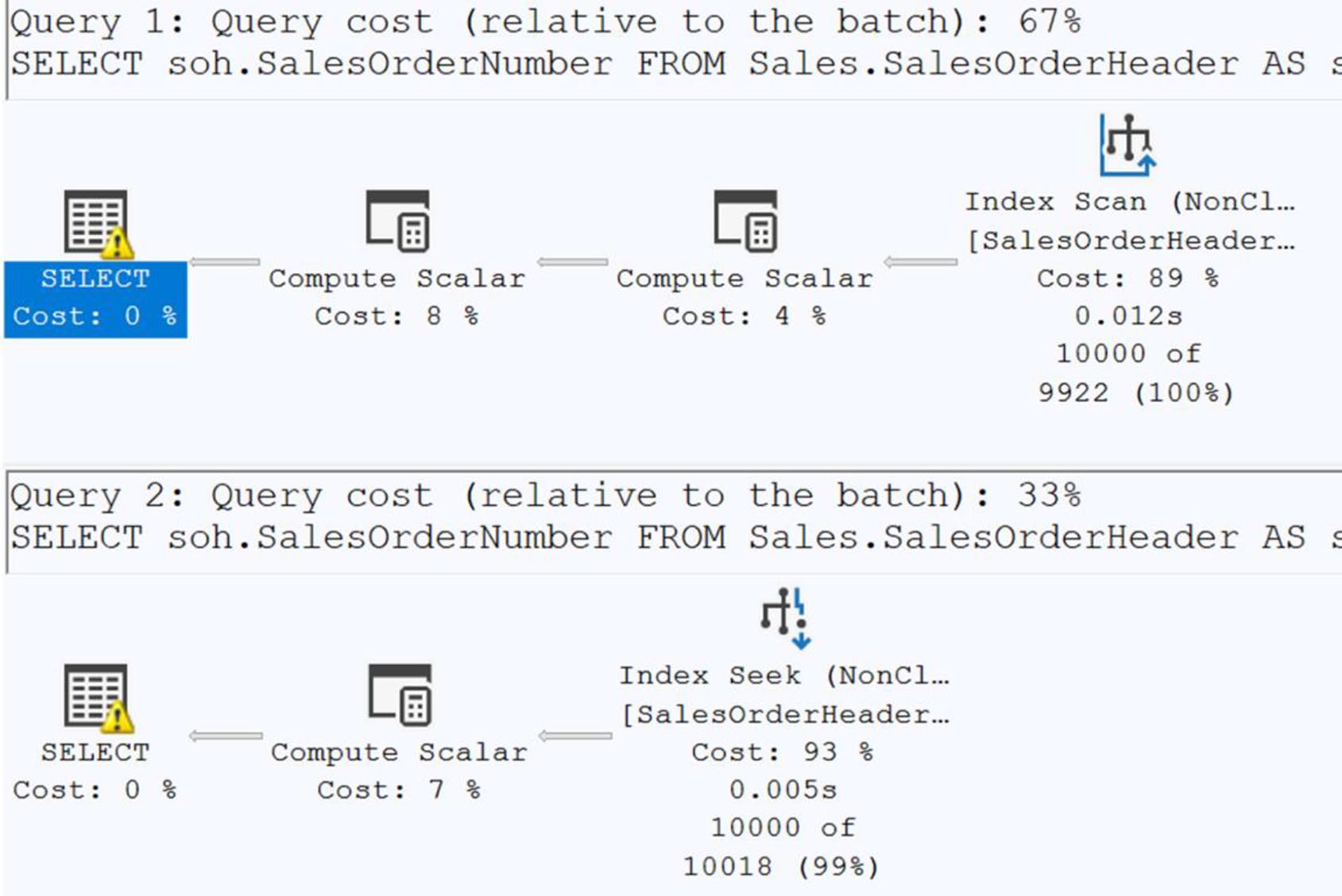
Figure 23-5: One query not using an index
避免 hint#
OPTIMIZE FOR ... UNKNOWN等少數場景合理- 多數 hint 是「拿走優化器的選擇權」——常常 短期解、長期傷
不要 nest views / UDF#
- View 對優化器是 subquery 不是 table
- 巢狀 view → 簡化階段超時 → 計畫失控
防止隱式轉換#
- 變數、參數型別 永遠 對齊欄位
- Join 時兩邊鍵值型別要一致
- 執行計畫上看到 type conversion 警告 → 認真檢查
計畫重用#
- 用 stored procedure /
sp_executesql取代字串拼接 - 用 two-part name 提升重用率
- 開 Optimize for Ad Hoc Workloads
Transaction#
- 越短越好
- 不要把外部 API、user input 包進去
- 一致存取順序(避免 deadlock)
- 適當的 isolation level(多數情境 RCSI 最佳)
Cursor#
- 能改 set-based 就改
- 必須用 cursor →
FAST_FORWARD READ_ONLY
進階武器#
- 適當情境用 natively compiled stored procedure
- 分析型查詢用 columnstore index
- 啟用 Query Store——所有後續調校的基礎設施
完整流程:從識別到修正#
flowchart TD
A[使用者反映慢 / 監測告警] --> B[找出哪一條 query]
B --> C[Query Store + DMV 觀察計畫與指標]
C --> D{看哪個面向?}
D -->|多計畫變動| E[Parameter sensitive?<br/>Plan forcing / PSP]
D -->|單一計畫慢| F[計畫分析: 七大路標]
F --> G{瓶頸類型}
G -->|Scan太多| H[索引設計]
G -->|估算偏離| I[統計 / cardinality]
G -->|逐列處理| J[改 set-based]
G -->|大量等待| K[Blocking / 死結 / wait stats]
H --> L[改動後驗證]
I --> L
J --> L
K --> L
L --> M{有改善?}
M -->|否| N[回到 C 重新分析]
M -->|是| O[文件化、入監控]本章定調#
- 整套方法論建立在前 22 章的單元上:量測 → 改 → 驗證
- 沒有銀彈——但有一套 保證能命中多數常見問題的檢核表
- 自動化與 IQP 處理機械化任務;人類專注設計與決策
- Query Store 是貫穿一切的觀察工具,啟用它
結語#
Fritchey 開頭與結尾都用同一句話:「Query tuning is hard」。但難不代表沒有方法。
把書中的工具、概念、檢核表內化,加上 每次只改一件事 → 量測 → 驗證 的紀律,你就能在不同系統、不同版本、不同工作負載下持續改善 SQL Server 效能。
接下來的查詢調校之路,讀者就是主角。