為什麼有 Graph Database#
從 SQL Server 2017 起,你可以在 SQL Server 內建立 graph database——以 節點(node) 與 邊(edge) 為核心結構,原生支援多對多、層級式關係。
Graph 不取代 OLTP(rowstore)也不取代分析(columnstore)。它解決的問題是 多對多 + 多層次關係查詢——例如「誰呼叫過誰呼叫過的人」、「兩個節點之間的最短路徑」、「朋友的朋友的朋友」。
這類查詢用傳統關聯模型寫出來會充滿遞迴 JOIN,效能與可讀性都糟。
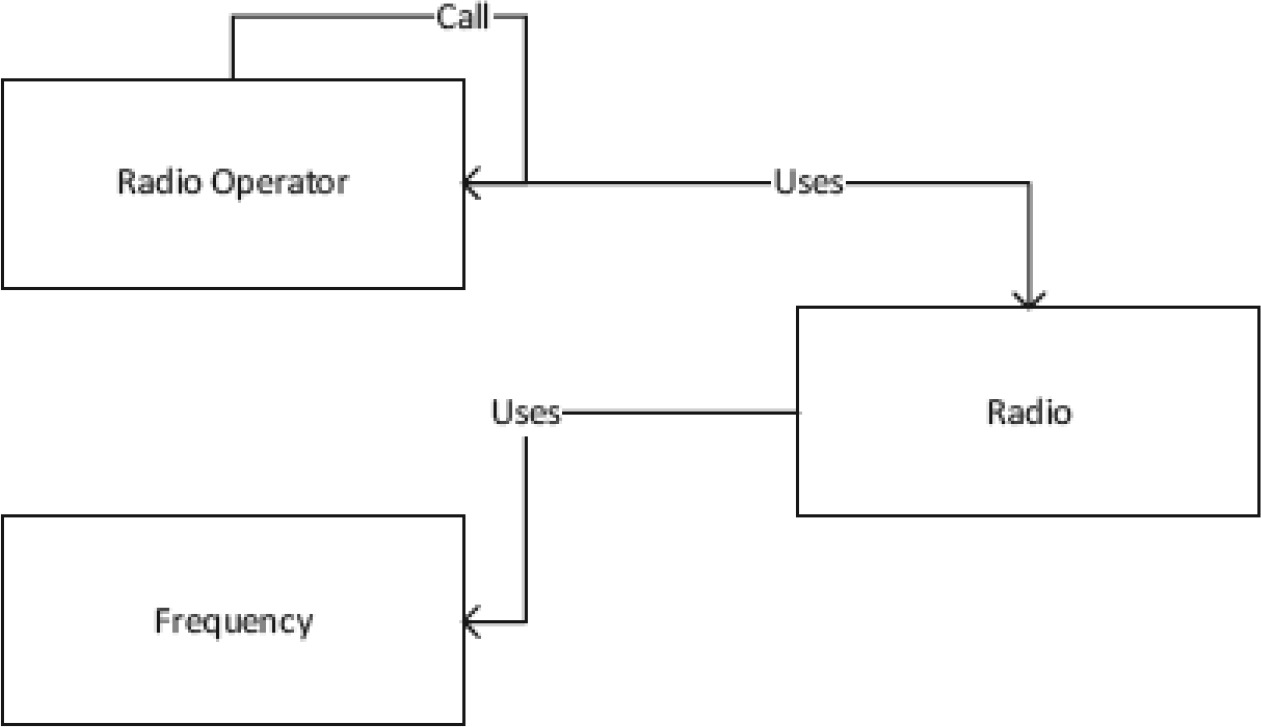
Figure 20-1: A graph relationship with nodes and edges
基本結構#
每個資料庫只能有 一個 graph,由兩種表組成:
- Node table:描述某種物件(例如 RadioOperator、Frequency、Radio)
- Edge table:描述物件之間的關係(例如 Calls、Uses)
範例:
flowchart LR
O1[Operator: Grant] -->|Calls| O2[Operator: Bob]
O1 -->|Uses| R1[Radio: Yaesu FT-3]
R1 -->|Uses| F1[Frequency: 145.520 MHz]建立 Node 與 Edge#
-- Node
CREATE TABLE grph.RadioOperator
(
RadioOperatorID int IDENTITY NOT NULL,
OperatorName varchar(50) NOT NULL,
CallSign varchar(9) NOT NULL
) AS NODE;
-- Edge
CREATE TABLE grph.Calls AS EDGE;特性:
AS NODE/AS EDGE是核心關鍵字- Edge table 不需自定欄位——SQL Server 自動建立
$edge_id、$from_id、$to_id - Node table 自動多出
$node_id
建立 graph 不需要特殊資料庫設定,就是普通 table——只是有特殊欄位與語法支援。
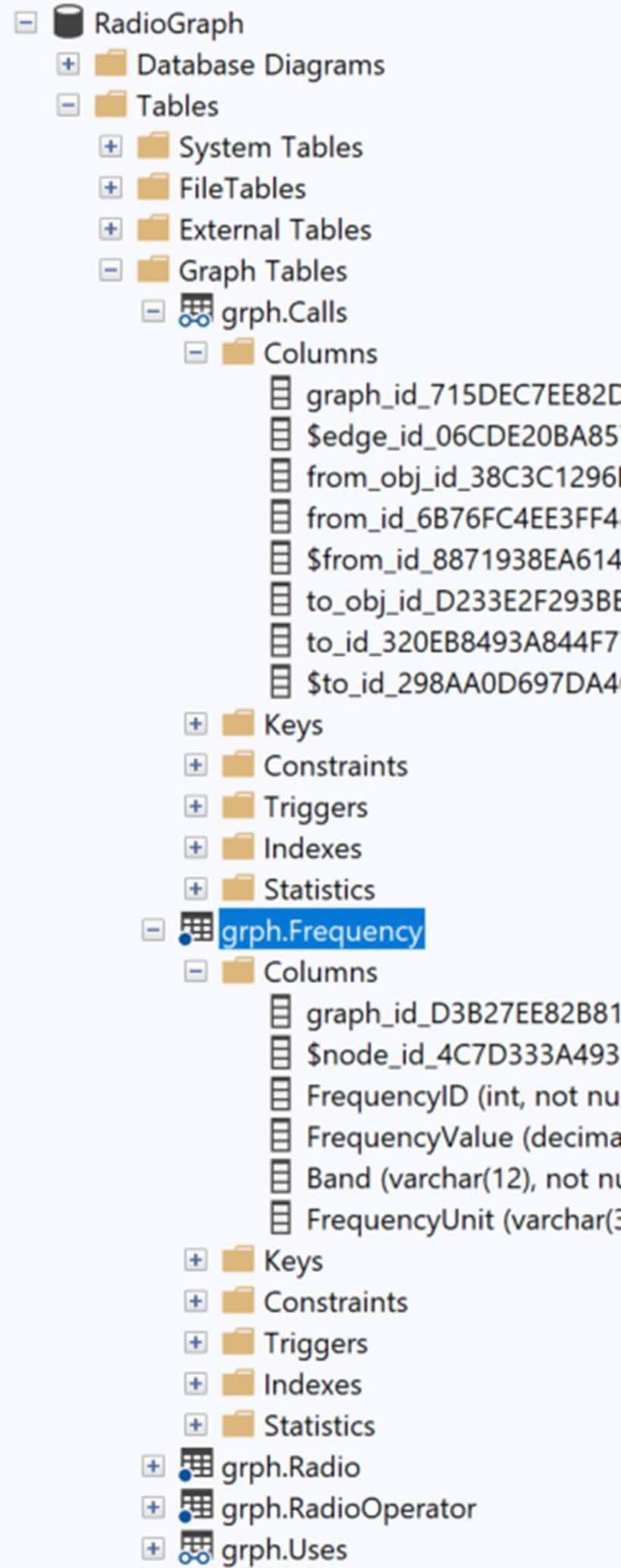
Figure 20-2: Tables inside of a graph database
載入資料#
Node 直接 INSERT#
INSERT INTO grph.RadioOperator (OperatorName, CallSign)
VALUES ('Grant Fritchey', 'KC1KCE'), ('Bob McCall', 'QQ5QQQ');$node_id 自動產生,類似 IDENTITY。
Edge 用 $from_id 與 $to_id#
INSERT INTO grph.Calls ($from_id, $to_id)
VALUES
(
(SELECT $node_id FROM grph.RadioOperator WHERE RadioOperatorID = 1),
(SELECT $node_id FROM grph.RadioOperator WHERE RadioOperatorID = 4)
);方向必須一致。
$from_id與$to_id的意義由你在 application 中定義,但所有 INSERT 必須遵守同一規則——否則「a 呼叫 b」與「b 呼叫 a」就會混淆。
查詢:MATCH 語法#
graph 查詢用 MATCH 取代 JOIN,並用 ASCII-art 表示方向:
SELECT Calling.OperatorName, Calling.CallSign,
Called.OperatorName, Called.CallSign
FROM grph.RadioOperator AS Calling,
grph.Calls AS C,
grph.RadioOperator AS Called
WHERE MATCH(Calling-(C)->Called);Calling-(C)->Called 表示:「Calling 透過 edge C 指向 Called」。也可以寫成 Called<-(C)-Calling,意義相同。
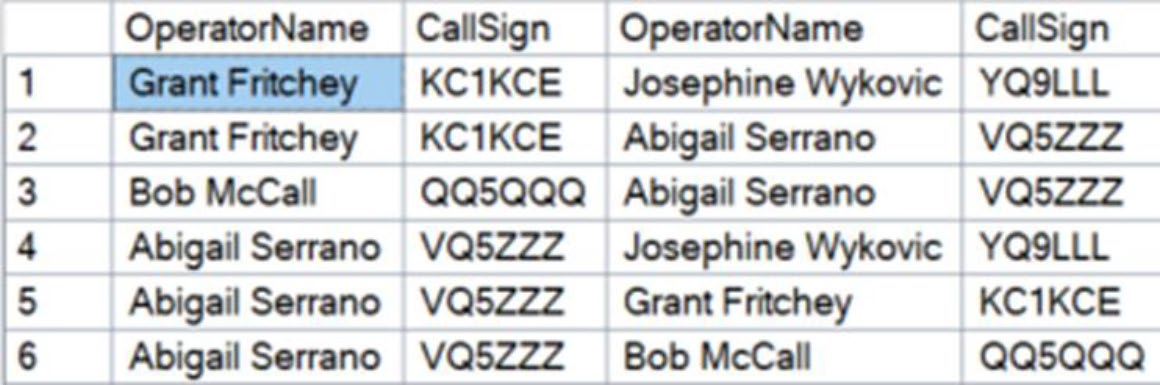
Figure 20-3: Which radio operators have called out to which other operators
ASCII art 風格:
A-(E)->B:A 透過 E 連到 B(有向)A<-(E)-B:B 透過 E 連到 AA-(E1)->B-(E2)->C:兩段串接
與關聯模型的效能差異#
書中對比相同邏輯:
Graph (MATCH) | Relational JOIN | |
|---|---|---|
| 執行時間 | 247 μs | 1.1 ms |
5 倍差距——而且資料量很小。實際多層次關係(friends-of-friends)下差距會更大。
多層關係 + 過濾#
SELECT Calling.OperatorName, Calling.CallSign,
Called.OperatorName, Called.CallSign,
TheyCalled.OperatorName, TheyCalled.CallSign
FROM grph.RadioOperator AS Calling,
grph.Calls AS C,
grph.RadioOperator AS Called,
grph.Calls AS C2,
grph.RadioOperator AS TheyCalled
WHERE MATCH(Calling-(C)->Called-(C2)->TheyCalled)
AND Calling.RadioOperatorID = 1;用同一個 edge table 取兩次 alias,串成 2-hop 路徑。可以無限延伸:3-hop、4-hop、加上更多過濾條件。

Figure 20-4: The people called by the people I called
共同被呼叫者:方向交叉#
WHERE MATCH(WeCalled-(C)->AllCalled<-(C2)-TheyCalled)意思是:「WeCalled 呼叫 AllCalled,TheyCalled 也呼叫 AllCalled」——找出共同呼叫對象。這在傳統 SQL 要寫得很長。
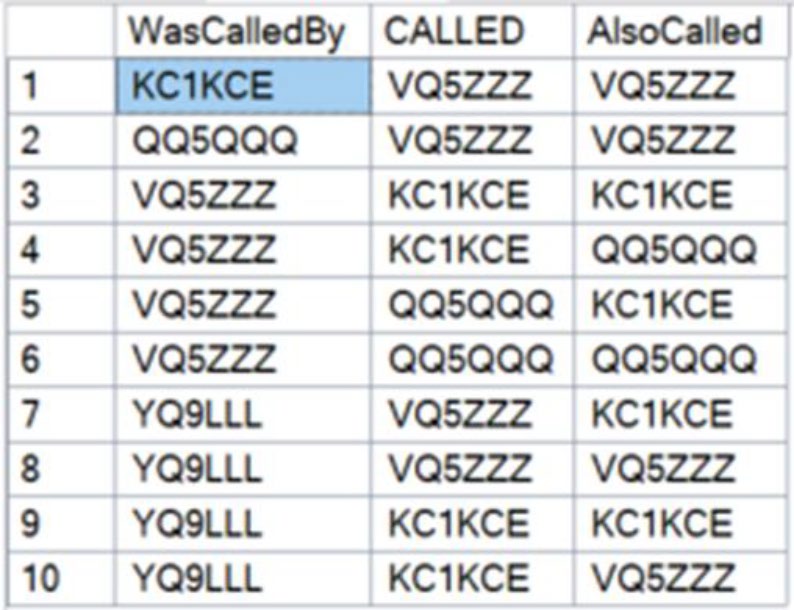
Figure 20-5: Relationships can be expressed in multiple ways
SHORTEST_PATH#
SQL Server 2019+ 加入的功能,能找:
- 兩節點間最短路徑
- 一個節點到多個節點的最短路徑
SELECT
Person1.OperatorName,
STRING_AGG(Person2.OperatorName, '->') WITHIN GROUP (GRAPH PATH) AS PathToTarget,
LAST_VALUE(Person2.OperatorName) WITHIN GROUP (GRAPH PATH) AS Target
FROM grph.RadioOperator AS Person1,
grph.Calls FOR PATH AS Calls,
grph.RadioOperator FOR PATH AS Person2
WHERE MATCH(SHORTEST_PATH(Person1(-(Calls)->Person2)+))
AND Person1.RadioOperatorID = 1;關鍵語法:
FOR PATH標記:在 SHORTEST_PATH 內參與路徑的別名SHORTEST_PATH(... +):+表示 1 至多個跳數STRING_AGG(... WITHIN GROUP (GRAPH PATH))把路徑串成可讀字串LAST_VALUE(... WITHIN GROUP (GRAPH PATH))拿到路徑終點
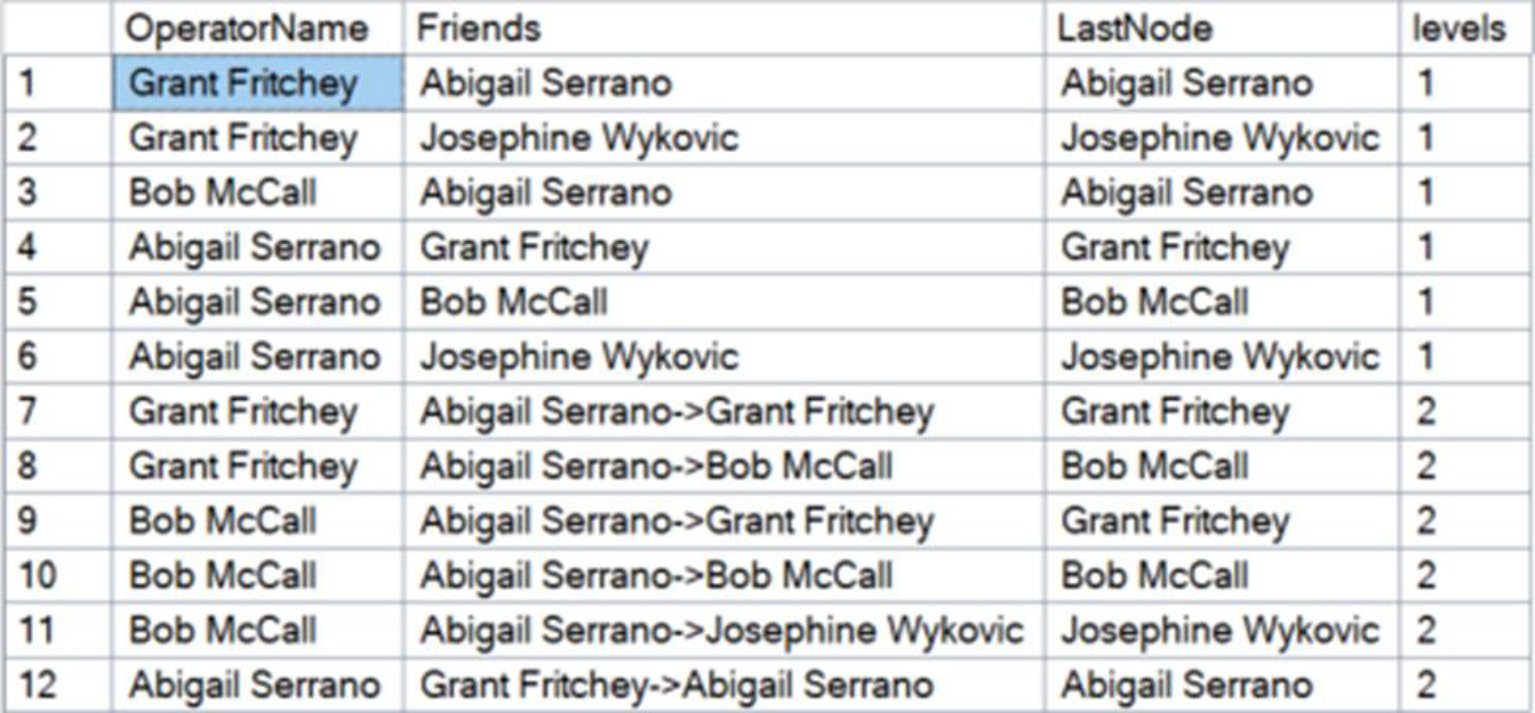
Figure 20-6: The paths and levels showing which operators have called who

Figure 20-7: The beginning of the results of an AI search
效能與索引#
Graph 表本質仍是 SQL Server 的關聯式表,所有索引調校原則仍適用:
$node_id、$from_id、$to_id預設有 nonclustered index——不要刪除- 對 node table 的 business key(如
RadioOperatorID)建索引能加速 MATCH 中的篩選 - 對 edge table 加 nonclustered index 涵蓋常見過濾條件
- Graph 也支援 columnstore index 與 memory-optimized table
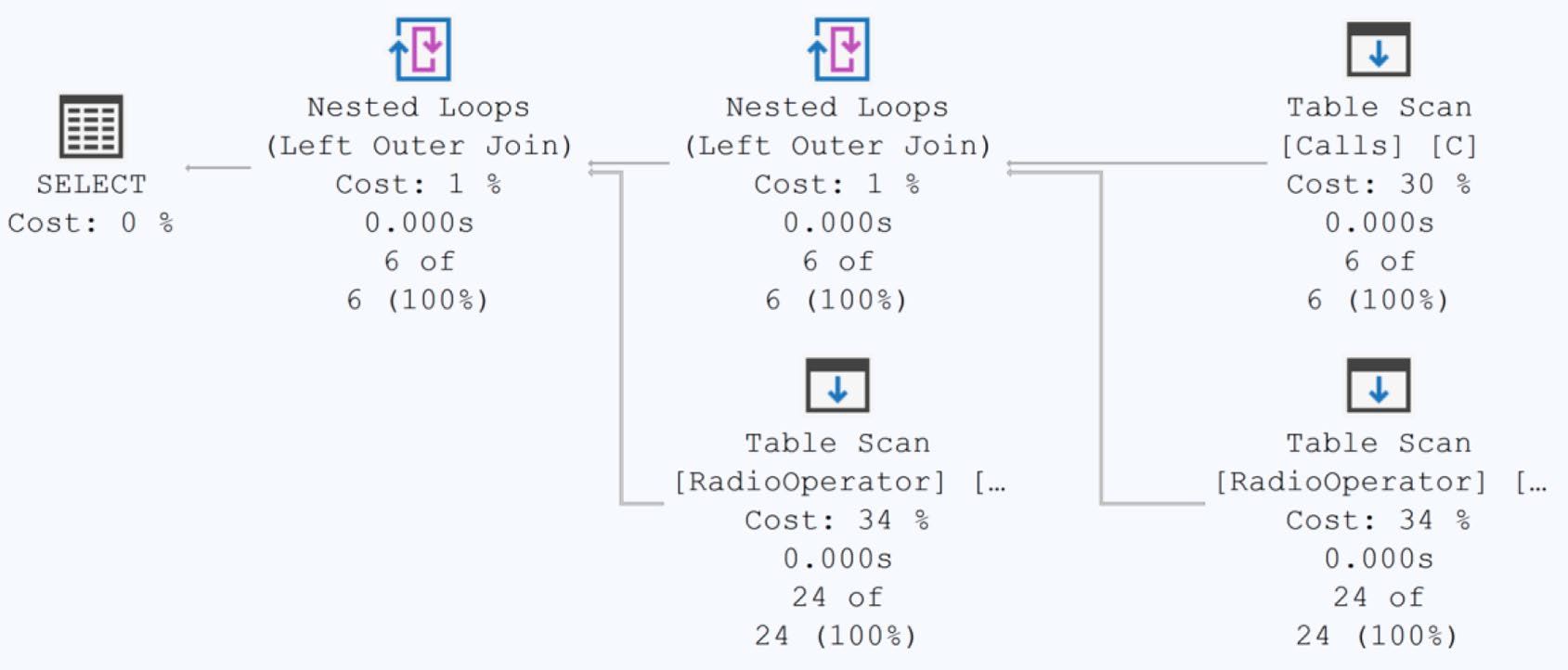
Figure 20-8: A fairly normal execution plan from a graph query
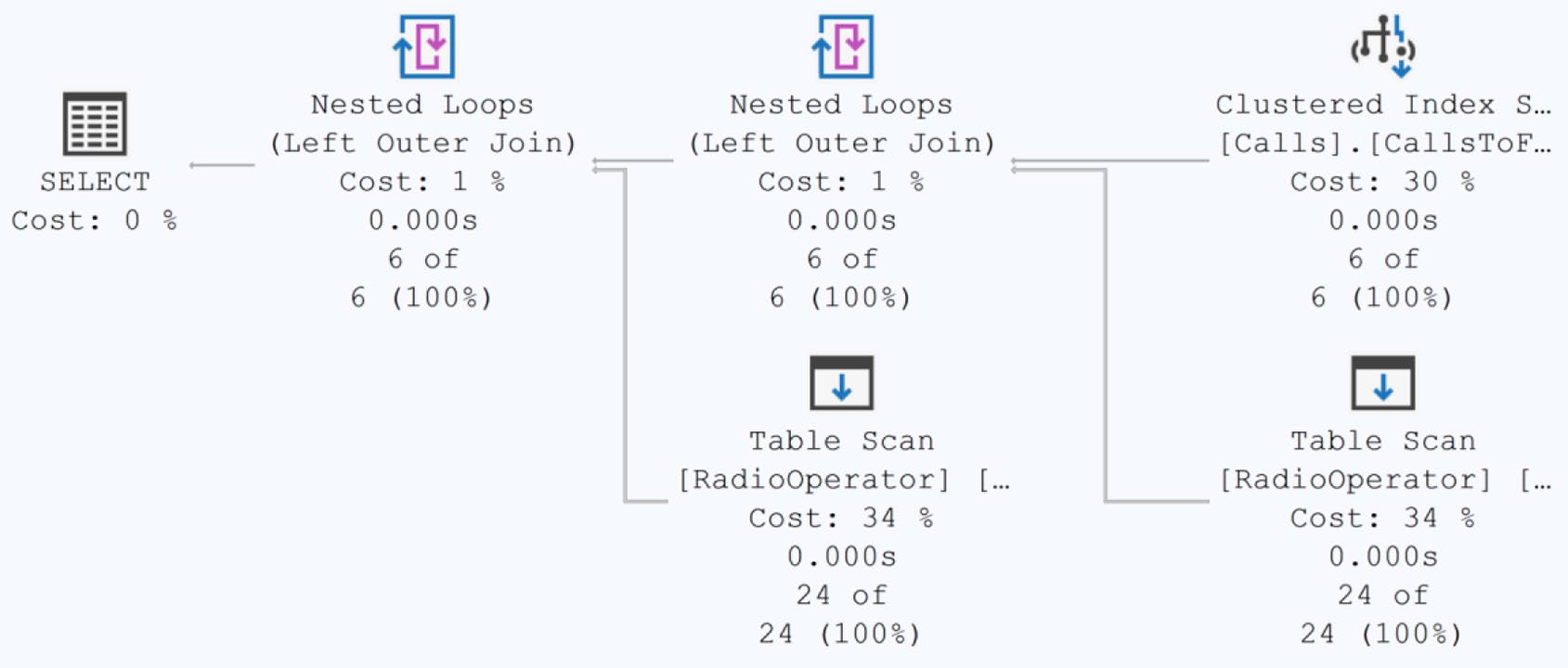
Figure 20-9: Table scan has been replaced
Graph 沒有自動的 referential integrity。建立 edge 時不會檢查
$from_id/$to_id是否真的指向某個 node。資料一致性要由應用層或 trigger 保證。SQL Server 2019 起新增
EDGE CONSTRAINT——可在 edge table 上強制要求「from 必須來自 node table A、to 必須來自 node table B」。
何時該用 Graph#
適合:
- 社交網路、組織圖、依賴關係圖
- 推薦引擎、影響力分析
- 路徑查詢(運輸、網路)
- 詐欺偵測(追蹤帳戶之間的關聯)
不適合:
- 主要是「拿一筆資料」的查詢——傳統 OLTP 更直接
- 大量 aggregation——columnstore 更好
- 稀疏關係(node 多、edge 少)——overhead 大過效益
與 Cypher / Gremlin 的差異#
SQL Server 的 graph 不是 Neo4j 那種「graph-only」資料庫。它把 graph 嵌入關聯式環境,好處 是能在同一資料庫中混用 OLTP / 分析 / graph;侷限 是專業 graph DB 的進階演算法(PageRank、社群偵測等)不在內建。
本章定調#
- Graph database 解決「多層關係」這類傳統 SQL 寫起來很痛的問題
- Node / Edge 表 + MATCH ASCII-art 語法是核心
- SHORTEST_PATH 是高層次關係查詢的利器
- 仍是 SQL Server 表,索引、統計、執行計畫工具全部適用
- 不是 Neo4j 殺手,但對「混合環境」中的關係查詢非常有用
下一章將進入 智慧查詢處理(Intelligent Query Processing)——SQL Server 自動最佳化的一系列功能,含 batch mode on rowstore、scalar UDF inlining、memory grant feedback 等。