為什麼有 In-Memory OLTP#
OLTP 系統追求極致 throughput——當磁碟 I/O 與傳統鎖機制成為瓶頸時,SQL Server 提供了 memory-optimized(in-memory) 表與 natively compiled stored procedure。它們:
- 把資料放進記憶體
- 用 optimistic concurrency(無鎖)取代傳統鎖
- 把 stored procedure 編譯成 DLL(native code)
- 寫 log 採非同步
In-memory 是 特殊化工具,不是 OLTP 的萬能解。它有大量限制與系統需求;用對地方有極大效能提升,用錯地方反而麻煩。
記憶體 vs. 磁碟的折衷#
MEMORY_OPTIMIZED table 提供三種 durability:
| 模式 | 寫到磁碟? | 速度 | 風險 |
|---|---|---|---|
SCHEMA_AND_DATA | 是(同步交易,非同步 log) | 快 | 與一般 table 相當的安全 |
| Delayed Durability | 是(延遲寫入) | 更快 | 故障時可能丟最近交易 |
SCHEMA_ONLY | 否,僅在記憶體 | 最快 | 重啟後資料消失 |
Session state、cache、隊列等「丟了也沒關係」的資料 →
SCHEMA_ONLY最划算。真實業務資料 →
SCHEMA_AND_DATA。
系統需求#
- 64-bit modern CPU
- 磁碟空間至少是資料的 2 倍(要存兩份檔案:data + delta)
- 大量記憶體——除了原本系統需要的,還要額外加給 in-memory tables
啟動時 SQL Server 必須把 in-memory tables 全部載入記憶體。記憶體不夠 → 啟動失敗或表不可用。容量規劃要保守。
啟用步驟#
ALTER DATABASE AdventureWorks
ADD FILEGROUP InMemoryData CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE AdventureWorks
ADD FILE (NAME = 'InMemoryFile',
FILENAME = '/var/opt/mssql/data/inmemoryfile.ndf')
TO FILEGROUP InMemoryData;SQL Server 2025 之前:加上 memory-optimized filegroup 後 無法移除。不要在 production 上輕率測試。
SQL Server 2025 起可以移除(前提是先刪掉所有 memory-optimized table 與 procedure)。
啟用後的限制#
DBCC CHECKDB跳過 in-memory tablesAUTO_CLOSE不建議啟用- Database Snapshot 不支援
ATTACH_REBUILD_LOG不支援- Database Mirroring 不支援;但 Availability Groups OK
建立 Memory-Optimized Table#
CREATE TABLE dbo.Address
(
AddressID INT IDENTITY(1,1) NOT NULL
PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 50000),
AddressLine1 NVARCHAR(60) NOT NULL,
City NVARCHAR(30) NOT NULL,
StateProvinceID INT NOT NULL,
PostalCode NVARCHAR(15) NOT NULL,
ModifiedDate DATETIME NOT NULL DEFAULT (GETDATE())
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);關鍵:
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = ...)- 必須有至少一個索引(hash 或 nonclustered)——資料無 page 概念,需索引才能定位
BUCKET_COUNT是 hash index 的桶數
不支援的資料型別#
geography/geometryxmldatetimeoffset(部分版本)rowversionhierarchyidsql_variant- 使用者定義型別
SQL Server 2016 起開始支援 FK、CHECK、UNIQUE constraint。off-row 欄位也支援,單列可超過 8060 bytes。
跨資料庫限制#
memory-optimized table 不能直接參與跨資料庫 transaction / 查詢。要跨資料庫,可改用 memory-optimized table variable(非交易性)。
In-Memory Table Variable#
需要先 CREATE TYPE:
CREATE TYPE dbo.PostalCodeType AS TABLE
(
ID INT NOT NULL PRIMARY KEY NONCLUSTERED,
City NVARCHAR(30) NOT NULL,
PostalCode NVARCHAR(15) NOT NULL,
INDEX CityIndex HASH (City) WITH (BUCKET_COUNT = 100)
)
WITH (MEMORY_OPTIMIZED = ON);之後即可如普通 table variable 使用。
書中實測對比:
| 載入 19,000 列 | 單列 SELECT | |
|---|---|---|
| 傳統 table variable | 25.8 ms | 339 μs |
| In-memory table variable | 15.1 ms | 118 μs |

Figure 19-1: Execution plan showing a mix of table types
對於 任何 大量使用
@TableVar的場景,改成 in-memory 版本通常 無痛獲得 2x–3x 效能——尤其是寫入密集的 ETL / 中介結果。
In-Memory Index#
memory-optimized table 沒有 page,索引也不會 fragment。UPDATE 是邏輯 DELETE + INSERT,後續 garbage collection 會清理。
每張表 必須至少一個索引(決定資料如何被定位)。SQL Server 2017 起每表上限 999 個索引(但實際應遠少於此)。
兩種索引:
Hash Index#
對 key 算 hash → 落入某個 bucket。
PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 50000)
Figure 19-2: Hash values in buckets with a shallow and deep distribution
Bucket count 是關鍵參數:
- 太小 → 多個 key 擠同一個桶 → chain 變長 → 查詢變慢
- 太大 → 浪費記憶體 + 掃描時讀過很多空桶
建議:鍵值唯一數量的 1–2 倍;若不會成長則設等於唯一數即可。
觀察 hash index 健康#
SELECT i.name,
hs.total_bucket_count,
hs.empty_bucket_count,
hs.avg_chain_length,
hs.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats AS hs
JOIN sys.indexes AS i
ON hs.object_id = i.object_id AND hs.index_id = i.index_id
WHERE OBJECT_NAME(hs.object_id) = 'Address';avg_chain_length 太大 → 桶不夠;empty_bucket_count 太大 → 桶過多。

Figure 19-3: Results from sys.dm_db_xtp_hash_index_stats
Hash index 對 點查詢(point lookup) 極快,但對 範圍查詢(range scan) 沒幫助——它的鍵值是 hash 後的,順序毫無意義。範圍查詢請用 nonclustered index。
Memory-Optimized Nonclustered Index#
像 B-Tree 但叫 Bw-Tree(無鎖、optimistic 設計)。支援範圍查詢與排序。
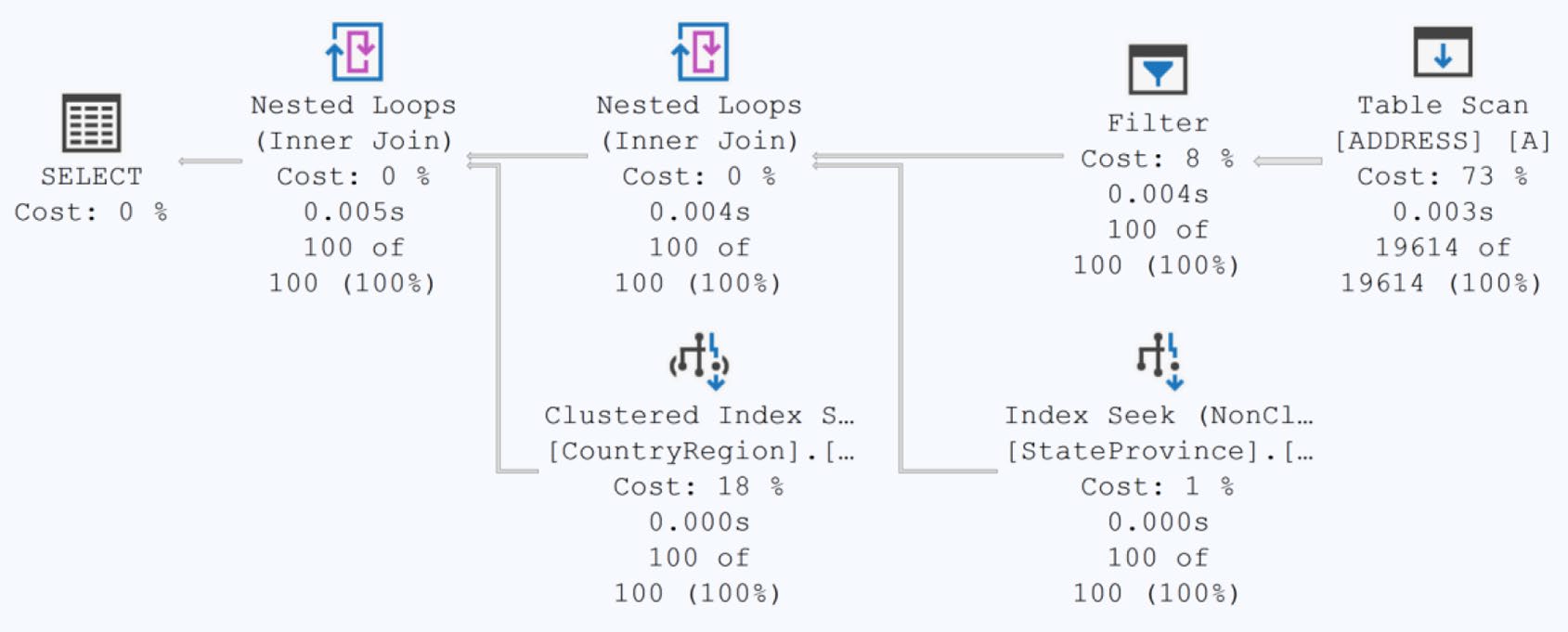
Figure 19-4: A scan of an in-memory table
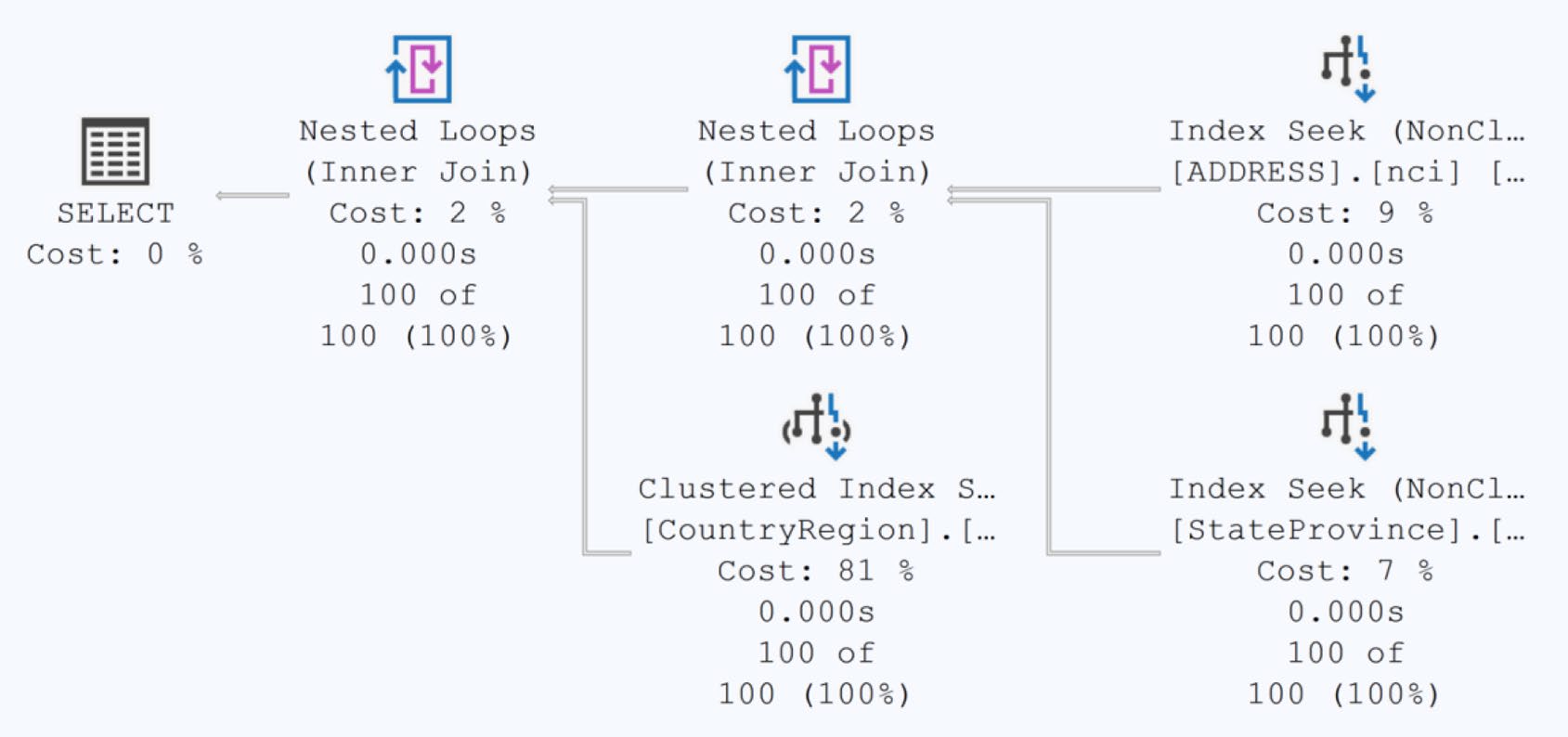
Figure 19-5: Scan replaced with a seek

Figure 19-6: Statistics on the memory-optimized table

Figure 19-7: Histogram of the hash index
點查詢用 hash、範圍 /
ORDER BY用 nonclustered。多數實際工作負載會 同時建兩種 來覆蓋不同存取路徑。
Native Compiled Stored Procedure#
T-SQL 寫的 procedure 被編譯成 C 程式碼 → DLL,啟動時載入 SQL Server OS。
CREATE PROCEDURE dbo.GetAddress
@AddressID INT
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
SELECT AddressLine1, City, PostalCode
FROM dbo.Address
WHERE AddressID = @AddressID;
END;特性:
- 必須
NATIVE_COMPILATION+SCHEMABINDING - 必須
BEGIN ATOMIC(一個 atomic block) - 必須指定 isolation level 與 language
- 編譯成本高,但 執行極快——最適合「短小、高頻、純 in-memory」的工作

Figure 19-8: Execution plan for a natively compiled procedure
Figure 19-9: SELECT operator properties
限制#
- T-SQL 子集,許多功能不支援(CTE、cross-database query、
*、MERGE部分語法…) - 只能存取 memory-optimized table
- 不支援 RECOMPILE hint
- 沒有 plan cache 行為——每次都用編譯時的 plan
何時該用 In-Memory OLTP#
不要把所有表都改成 in-memory。特性鮮明:
適合:
- 高頻寫入(IoT 流入、頻繁更新的計數器、session state)
- 高併發 OLTP 短交易
- 暫時資料(cache、queue、staging)
- tempdb contention 嚴重的中介結果(用 memory-optimized table variable)
不適合:
- Range scan 為主的查詢
- 大量資料的分析查詢(用 columnstore)
- 需要跨資料庫 transaction
- 不可預測的 query plan(無法 native compile)
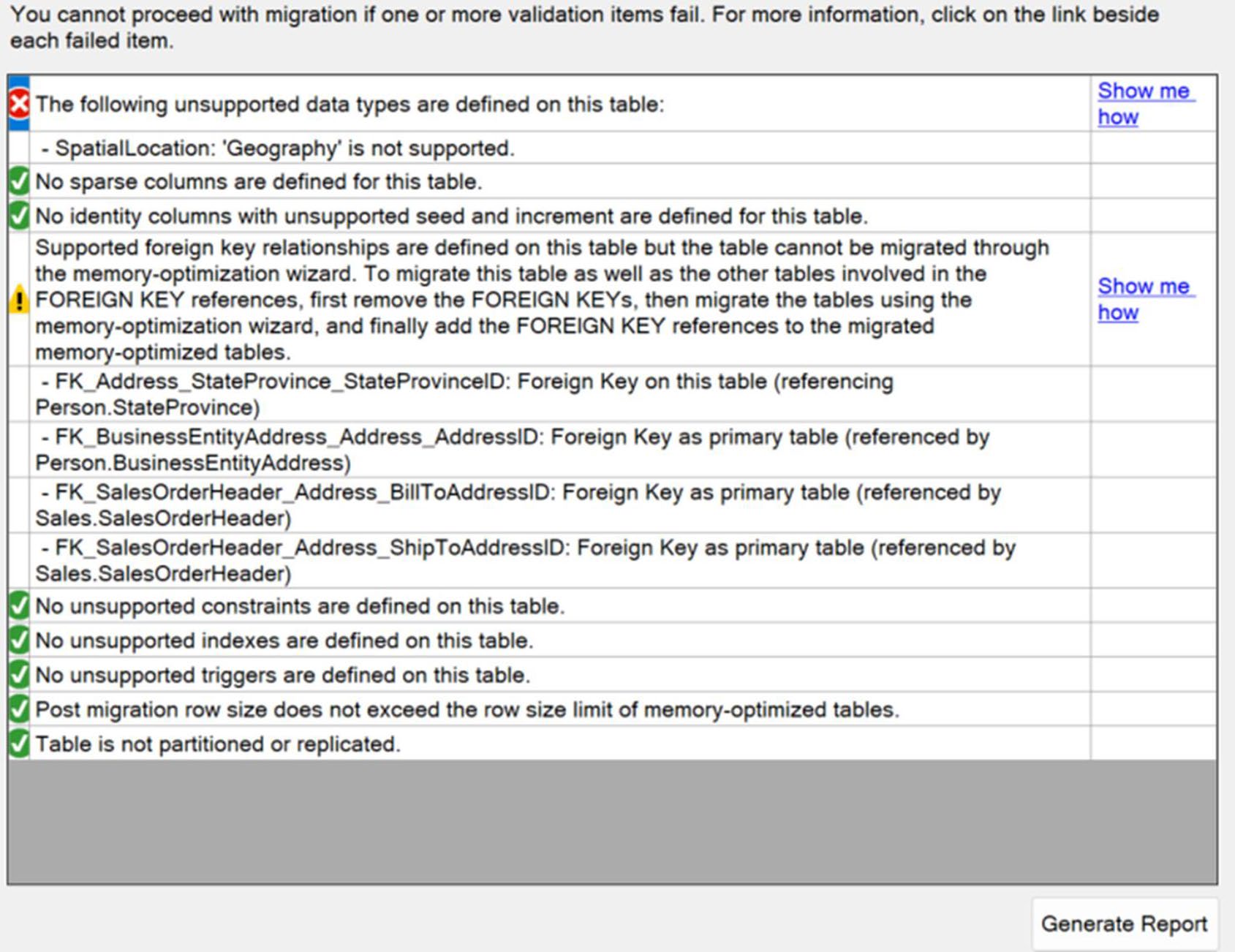
Figure 19-10: Results of the Memory Optimization Advisor

Figure 19-11: All checks are passed
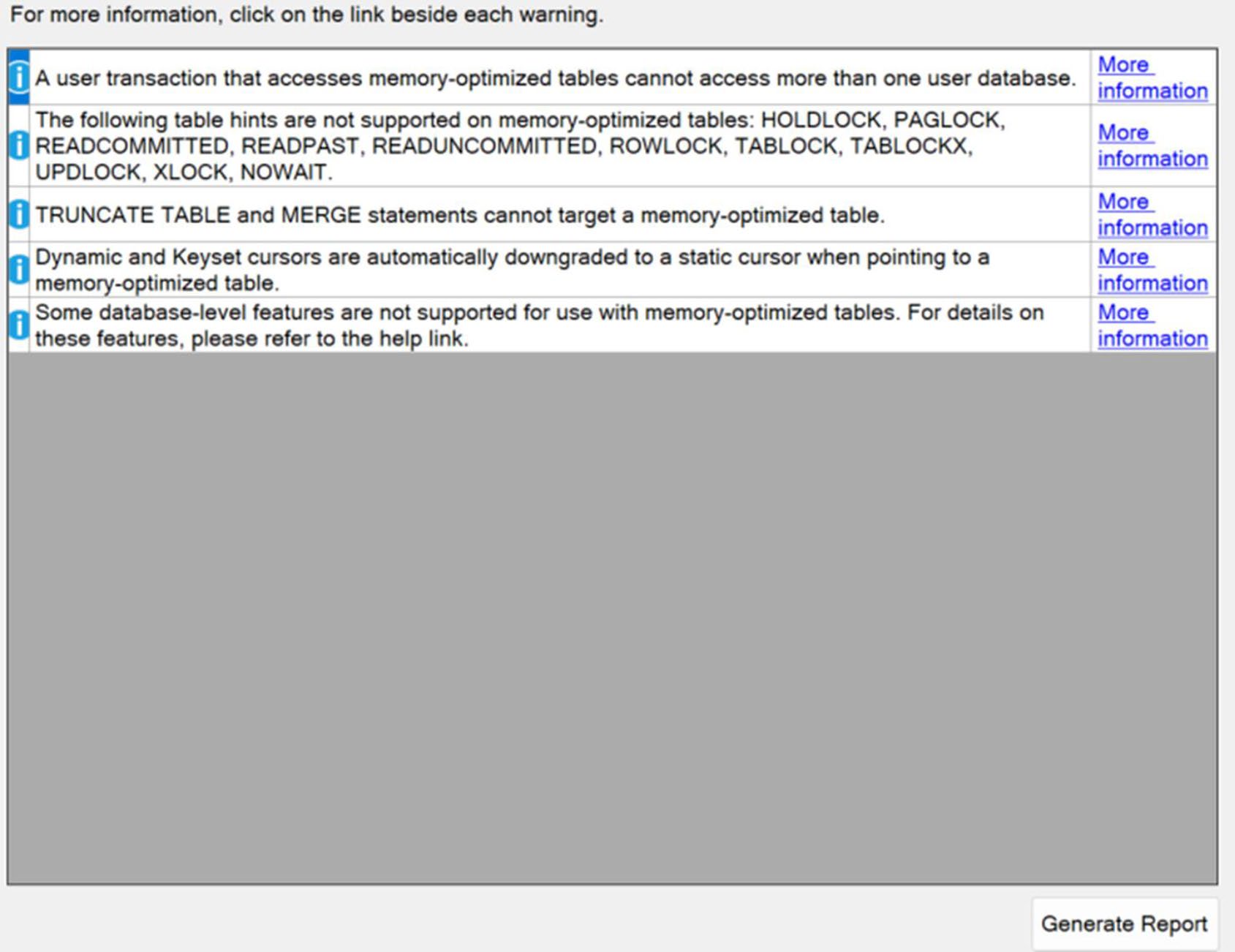
Figure 19-12: Warnings about migrating a table to in-memory storage
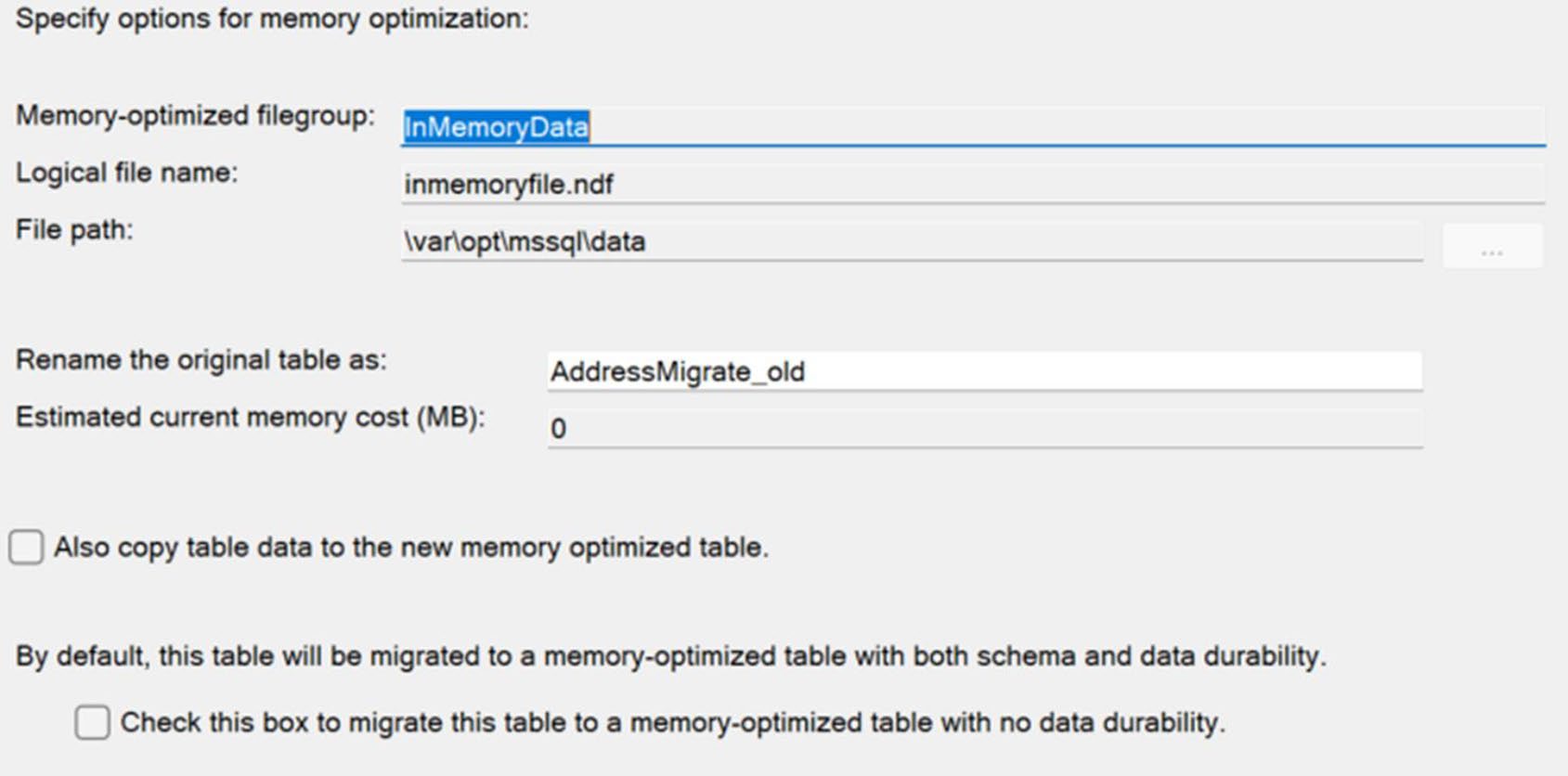
Figure 19-13: Naming the table and migrating data
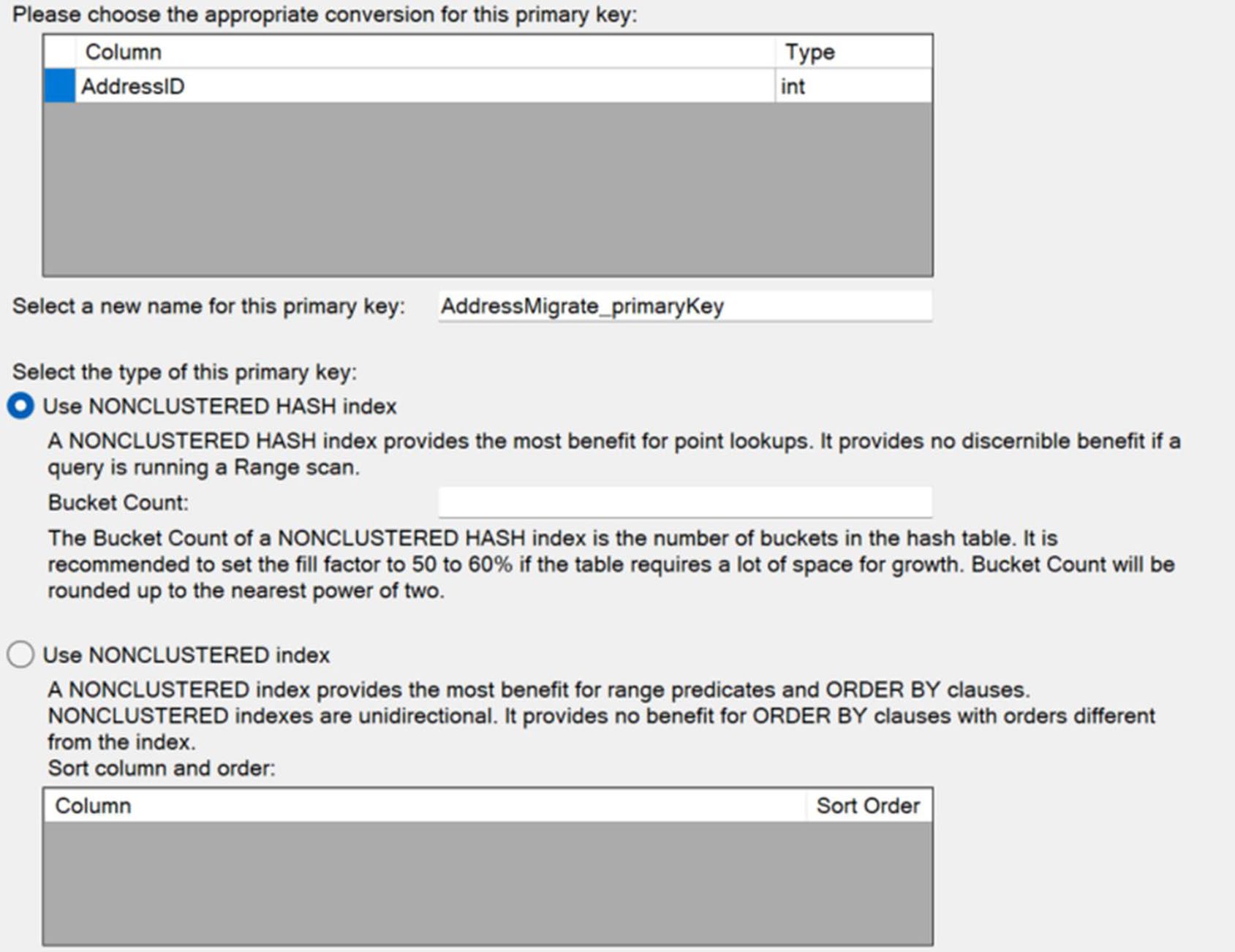
Figure 19-14: Selecting an index for the in-memory table

Figure 19-15: After migrating the table to in-memory storage

Figure 19-16: Native Compilation Advisor failed this procedure

Figure 19-17: Explanation for the failure from the Native Compiled Advisor
本章定調#
- In-memory OLTP = memory-optimized table + native compiled procedure,雙劍合璧才能發揮極致
- 三種 durability 對應不同資料安全 / 速度需求
- Hash index 點查詢無敵;範圍查詢仍需 nonclustered
- Native compiled procedure 是「短、頻、純」場景的最強加速器
- 系統需求高(記憶體、磁碟、CPU),啟用前先測試與評估
下一章將進入 圖形資料庫(graph database)——SQL Server 用 NODE / EDGE 表處理多對多關係的方式。