三個容易被混淆的詞#
Locking、Blocking、Deadlocking 是相關但不同的三件事:
- Locking:SQL Server 為了協調多個 session 對資料的存取,所放上的鎖。每次有讀寫都會發生。
- Blocking:當 session A 持有鎖、session B 想要相同資源時,B 必須 等待 A 釋放——B 被「封鎖」了。
- Deadlocking(死結):兩個 session 各自持有對方需要的鎖,誰都不能繼續——形成 deadly embrace。第 17 章詳述。
把三個詞分清楚,討論問題、求救別人時才能精準。
為什麼會有 Blocking#
任何寫入查詢都需要鎖以保護資料正確性。當:
- 索引設計糟糕 → 鎖的範圍變大
- 程式碼寫不好 → 持鎖時間變長
- Transaction 設計不當 → 同上
- 系統負載增加 → 等待者越來越多
結果就是大量 blocking,效能像連鎖反應一樣崩潰。
Memory-optimized table(記憶體最佳化資料表)走完全不同的鎖機制——第 19 章詳述。
交易與 ACID#
每條 query 都在某個 transaction 裡——不論是 auto-commit、BEGIN TRAN ... COMMIT、ROLLBACK。
SQL Server 用 ACID 四個性質保證資料正確:
- Atomicity(原子性):整個 transaction 全部成功或全部回滾
- Consistency(一致性):transaction 結束時資料庫處於合法狀態
- Isolation(隔離性):transaction 不會被其他 transaction 即時看到中間狀態
- Durability(持久性):commit 後資料已落盤,即使停電也不丟
Isolation 是 blocking 的主因——為了讓不同 transaction 不互相干擾,必須拿鎖、必須等待。降低 blocking 的核心策略就是 挑對 isolation level(下節)。
Atomicity 的兩個關鍵設定#
SET XACT_ABORT ON#
預設 OFF——transaction 中某條語句失敗時,只回滾那一條,其他成功的會留下。 打開 ON 後 → 任何錯誤都會把整個 transaction 回滾,符合「all-or-nothing」直覺。
TRY ... CATCH + ROLLBACK#
BEGIN TRY
BEGIN TRAN;
-- ...
COMMIT;
END TRY
BEGIN CATCH
ROLLBACK;
PRINT 'An error occurred';
RETURN;
END CATCH;明確掌控錯誤行為,並且 能更早結束 transaction——縮短 lock 持有時間。
鎖的種類與粒度#
從最細到最粗:
- RID:heap 表的單列
- KEY:clustered / nonclustered index 的單列
- PAGE:8 KB page
- EXTENT:8 個 page = 64 KB
- HoBT:Heap or B-Tree(partition)
- Rowgroup:columnstore 的 row group
- TAB:整張表
- FIL、APP、MDT、AU
- XACT:transaction(SQL Server 2025 Optimized Locking)
- DB:整個資料庫
沒有「最佳」的鎖粒度——SQL Server 視情境決定。單列改用 RID/KEY、大量改用 PAGE/EXTENT、極大量改用 TAB。
觀察鎖的 DMV#
SELECT request_session_id, resource_database_id,
resource_associated_entity_id, resource_type,
resource_description, request_mode, request_status
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID;關鍵欄位:
resource_type:被鎖的資源類型(RID / KEY / PAGE / OBJECT…)resource_description:例如1:2480:0=FileID:PageID:Slotrequest_mode:鎖模式(S / X / U / IS / IX / SIX…)request_status:GRANT(已取得)/WAIT(被封鎖)

Figure 16-1: A row-level lock for the DELETE statement

Figure 16-2: A KEY lock to DELETE data from a clustered index
鎖模式#
- S(Shared):讀鎖,多個 S 互相不阻擋
- X(Exclusive):寫鎖,與其他鎖互斥
- U(Update):準備改寫,先 U 鎖避免 S → X 升級時的 deadlock 機會
- IS / IX / SIX:意圖鎖(intent),出現在較高層級,告訴其他 session「下層有 S/X」
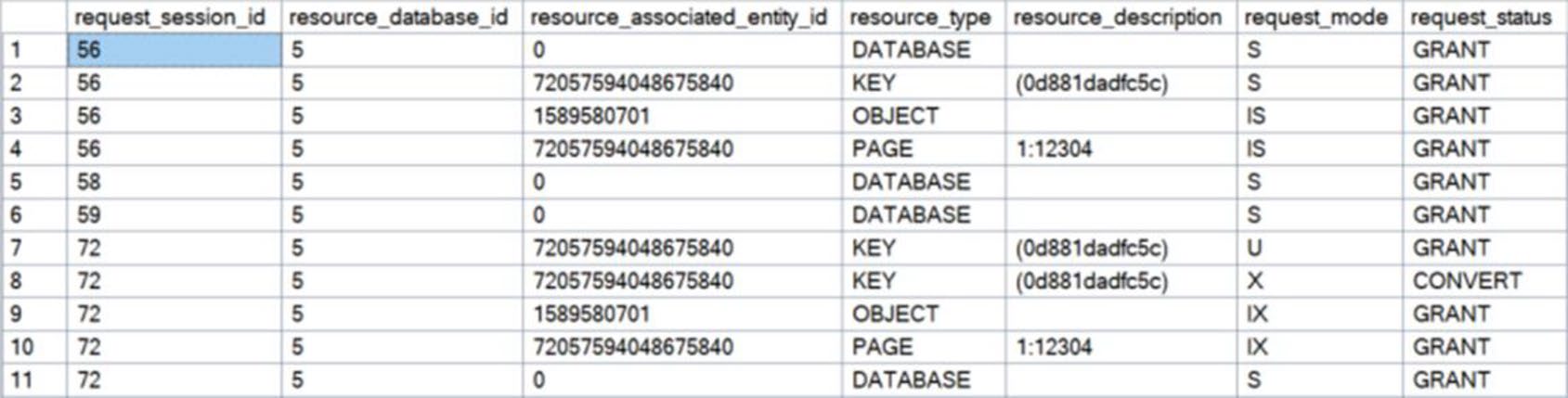
Figure 16-3: Locks held by initial UPDATE statements
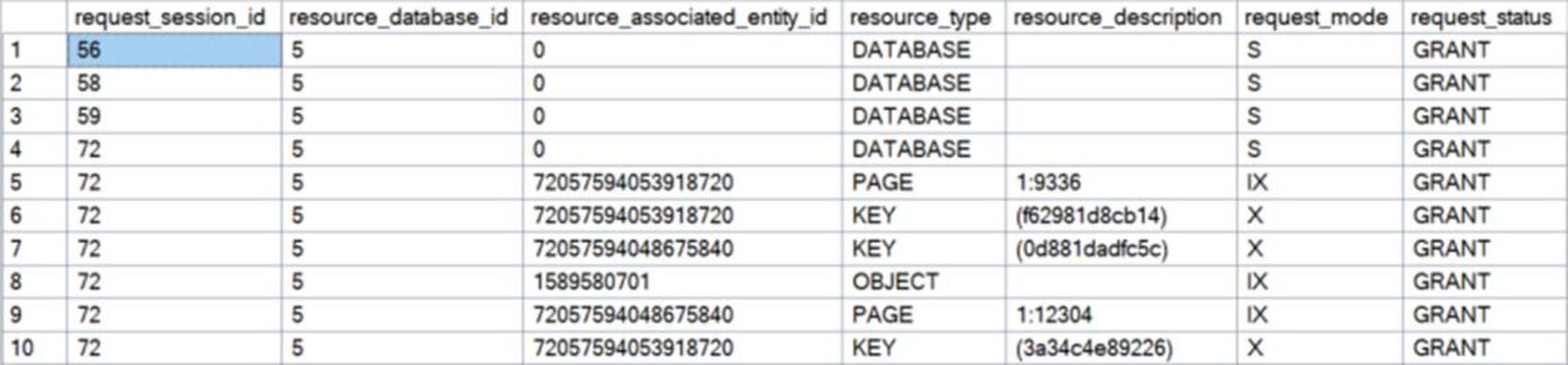
Figure 16-4: Locks held only by the second UPDATE statement
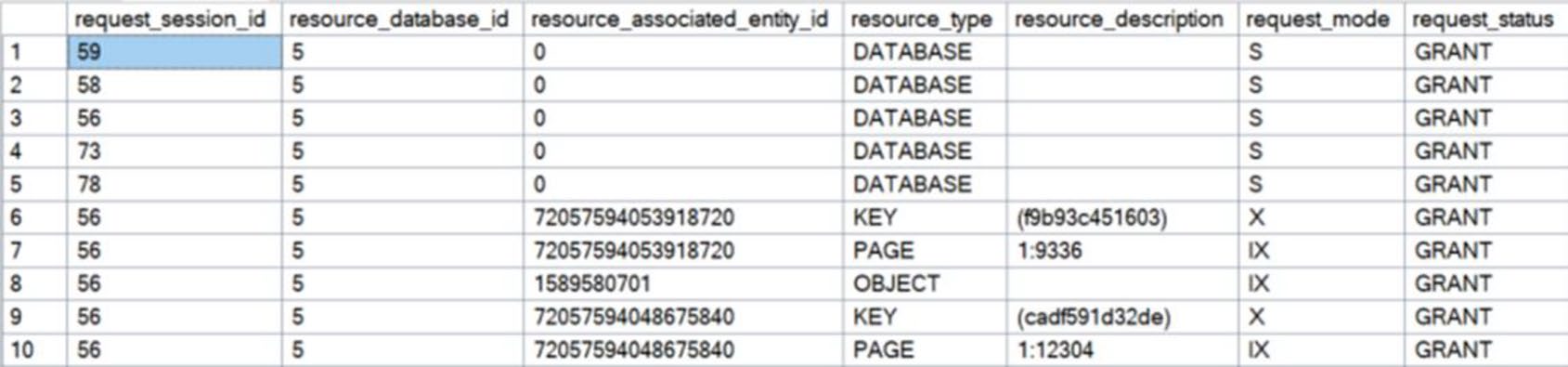
Figure 16-5: Locks taken out for a DELETE include Intent locks
Lock Escalation#
太多細粒度鎖(每列一個 RID/KEY)→ 記憶體爆炸。SQL Server 會 escalate:把幾千把細鎖換成一把表級 TAB 鎖。
- 觸發門檻:通常單一語句鎖到約 5,000 列 / 單一資料庫鎖佔用量達某個閾值
- 升到 TABLE 或 HoBT(partition table 才有 HoBT 選項)
Escalation 對 OLTP 是災難——一張表突然變成獨佔,所有讀寫卡住。
緩解:
- 拆 batch、單次 < 5,000 列
- 對 partition table 設
LOCK_ESCALATION = AUTO- 設計索引讓鎖能落在 KEY 而非 PAGE / TABLE
Isolation Levels#
SQL Server 預設 Read Committed。可選:
- Read Uncommitted:可讀未 commit 的 dirty data(同
WITH (NOLOCK)) - Read Committed:只讀已 commit 的資料;讀完即釋放 S 鎖
- Repeatable Read:transaction 內讀過的列保持鎖直到 commit
- Serializable:最嚴格,避免 phantom read,鎖整個範圍
- Snapshot:透過版本控制提供「讀寫不互相阻塞」
- Read Committed Snapshot Isolation(RCSI):Read Committed 的 row-versioning 變體
多數 OLTP 系統開 RCSI 是最佳折衷——讀者不阻擋寫者,寫者不阻擋讀者,且仍維持 read committed 語意。
啟用:
ALTER DATABASE MyDB SET READ_COMMITTED_SNAPSHOT ON;
Snapshot 與 RCSI 的代價:tempdb 需要儲存 row version,寫入加重 tempdb 壓力。極高寫入量系統需要規劃 tempdb 容量。
不要用
WITH (NOLOCK)換取「快」——會讀到 dirty data、可能 漏列、重複讀同列、讀到不一致快照。RCSI 才是正解。
Optimized Locking(SQL Server 2025)#
SQL Server 2025 新功能。在啟用 Accelerated Database Recovery(ADR)或 row-versioning 隔離的資料庫上:
- 每列都有
xactid(transaction ID) - 鎖以 transaction ID 為粒度(XACT lock),取代部分 row / page lock
- 更省記憶體
- 更不易觸發 escalation
對寫入頻繁的 OLTP,啟用 ADR + Optimized Locking 能顯著降低 lock 衝突——但要在 production 之前測試影響面。

Figure 16-6: XACT locks for Optimized Locking
索引對 Blocking 的影響#
沒有合適索引的查詢會 scan 整張表——掃過的所有列都要拿 S 鎖。即使最後只回 1 列,也可能 鎖掉 100 萬列幾秒,blocking 範圍極大。
設計索引時除了考慮速度,也要想:
- 這個索引能讓查詢精準鎖到該鎖的範圍嗎?
- 是否能避免 lock escalation?

Figure 16-7: Locking in a nonclustered index

Figure 16-8: Effects of a clustered index on locking behavior
分析 Blocking 的工具#
sys.dm_exec_requests#
即時看誰被誰擋:
SELECT session_id, blocking_session_id, wait_type,
wait_time, last_wait_type, status, command,
sql_handle, plan_handle
FROM sys.dm_exec_requests
WHERE blocking_session_id <> 0;
Figure 16-9: Information about the blocked and blocking processes
Activity Monitor / SSMS Reports#
SSMS 內建 Activity Monitor 可看 lock waits 與 head blocker。
Extended Events#
blocked_process_report 事件——當阻塞超過設定門檻(sp_configure 'blocked process threshold')就會產出 XML 報告,供事後分析。
設定
blocked process threshold為 5–10 秒,搭配 XE event file target,是 production 環境最低成本的長期觀察方式。
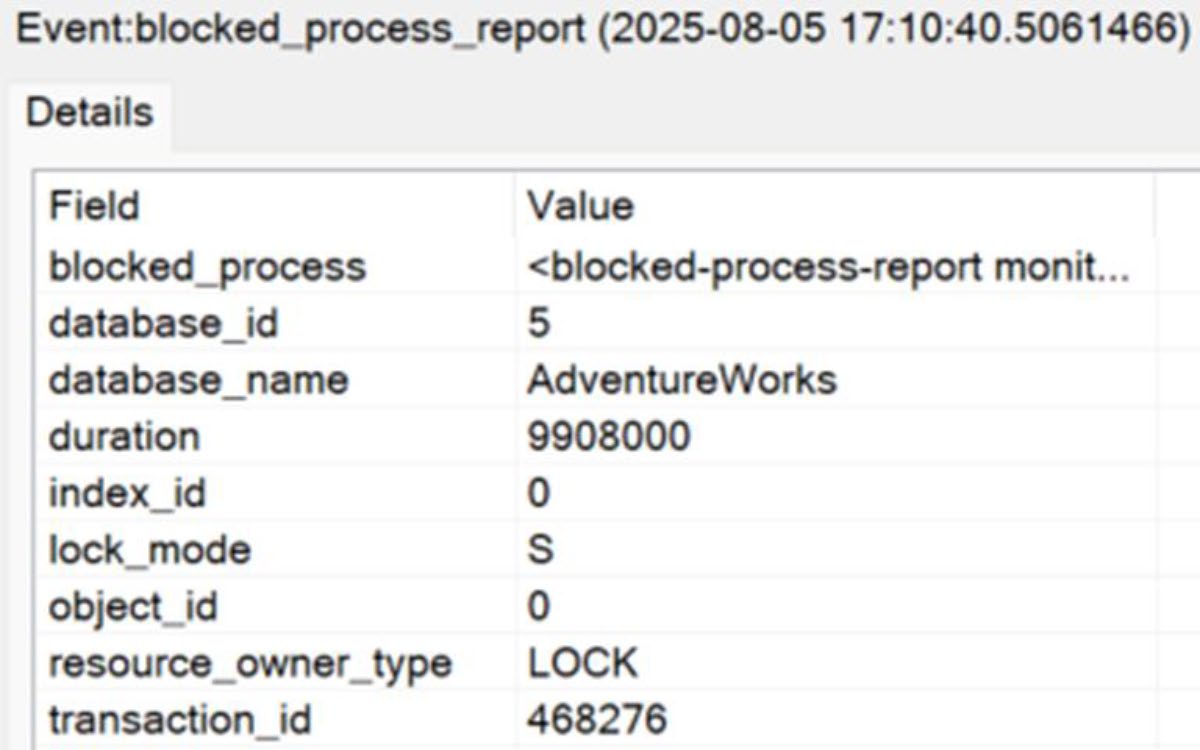
Figure 16-10: Data from the blocked_process_report Extended Event
降低 Blocking 的實務建議#
- Transaction 越短越好:別把外部 API 呼叫、使用者輸入包進去
- 以一致的順序存取資源:避免 deadlock
- 適當的索引:避免 scan,鎖落在 KEY/RID 而非 PAGE/TAB
- 適當的 isolation level:多數場景 RCSI 最好
- 批次操作分塊執行:每批 < 5,000 列以避 escalation
- 避免 long-running transaction:鎖越久 → 等候越多
- 少用 cursor:逐列鎖定 + 慢
- 善用
READPAST:對 queue 表處理特別有用——跳過已被鎖住的列
本章定調#
- Locking ≠ Blocking ≠ Deadlocking——是三件事
- ACID 是 blocking 的根源,特別是 Isolation
- 鎖有粒度層級,escalation 是 OLTP 殺手
- 預設 Read Committed 對寫入頻繁的系統不夠,RCSI 通常是正確選擇
- 不要用
WITH (NOLOCK)解 blocking——這是把問題變成 dirty data - SQL Server 2025 的 Optimized Locking 是寫入密集型系統的新利器
下一章將進入 死結(deadlock)——blocking 的極端版本:兩邊都動不了。