從「會跑」到「省資源」#
第 14 章談的是 query 是否能用上索引、結構是否合理;本章專注於 同樣功能下省 CPU、I/O、記憶體 的技巧。
四大主題:
- 避免吃資源的查詢設計
- 強化 plan cache 的利用
- 減少網路開銷
- 降低 transaction 成本
避免高成本查詢#
1. 用對的資料型別#
優化器會自動做 隱式轉換(implicit conversion)——讓你的程式跑得起來,但代價可能是 整個索引廢掉。
-- VARCHAR 欄位上比對 NVARCHAR
SELECT t.MyValue FROM dbo.Test1 AS t
WHERE t.MyKey = N'UniqueKey333'; -- 注意 N 前綴書中實測:
| 寫法 | 計畫 | reads | 時間 |
|---|---|---|---|
WHERE MyKey = 'UniqueKey333' | Index Seek | 4 | 266μs |
WHERE MyKey = N'UniqueKey333' | Index Scan(NVARCHAR vs VARCHAR) | 38 | 4,185μs |
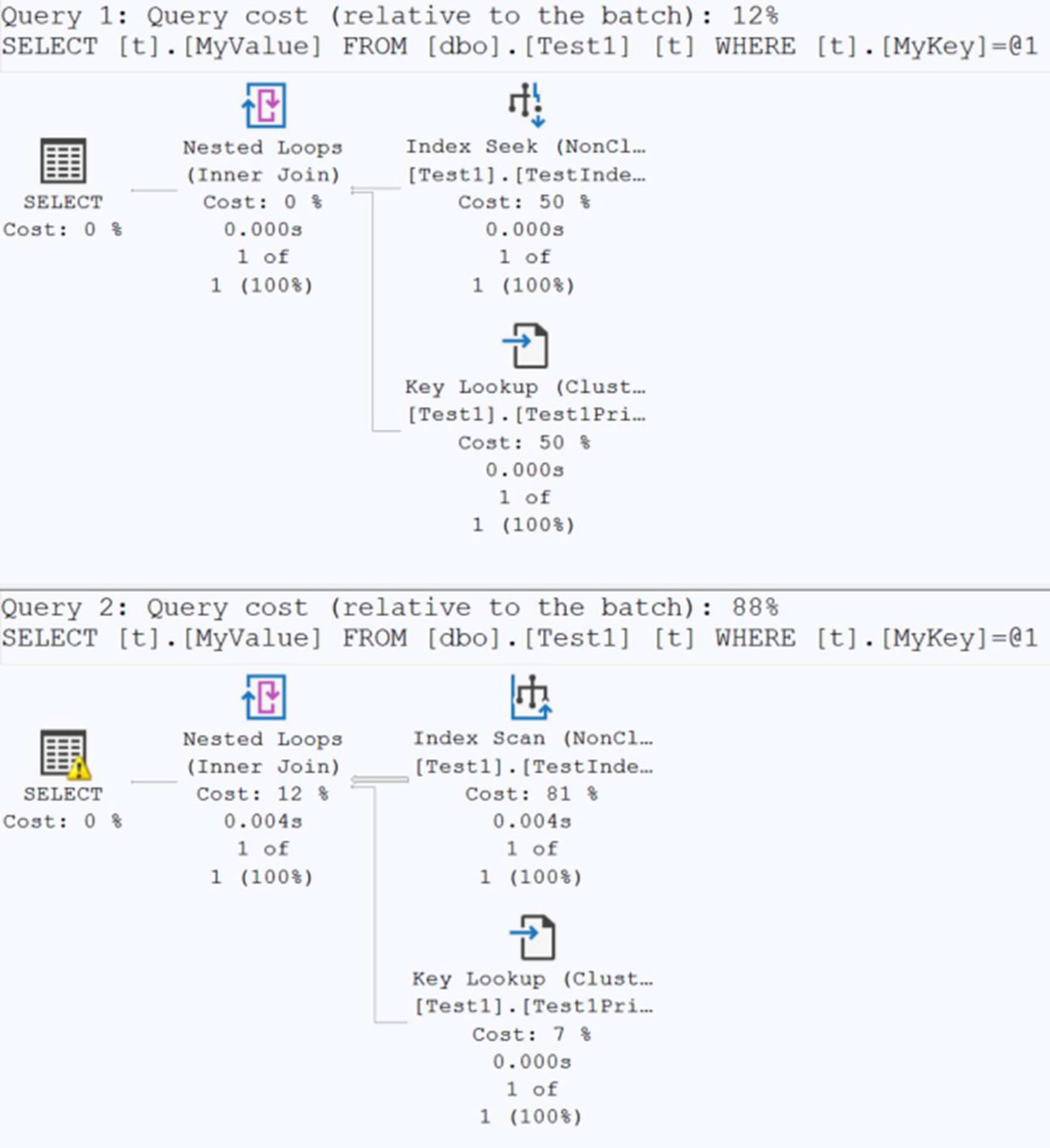
Figure 15-1: Two execution plans showing implicit conversion at work
轉換永遠套在比對值,而不是欄位值上——但若型別不一致,整個欄位仍要執行
CONVERT_IMPLICIT()→ 索引失效。永遠把 參數、變數、常數的型別與欄位對齊。執行計畫上的型別轉換警告務必檢查。
2. 用 EXISTS 取代 COUNT(*) 檢查存在#
-- 壞:必須掃完所有符合列才能得到 count
DECLARE @n INT;
SELECT @n = COUNT(*) FROM Sales.SalesOrderDetail WHERE OrderQty = 1;
IF @n > 0 PRINT 'Record Exists';
-- 好:找到第一筆就返回
IF EXISTS (SELECT 1 FROM Sales.SalesOrderDetail WHERE OrderQty = 1)
PRINT 'Record Exists';書中實測:
| reads | 時間 | |
|---|---|---|
| COUNT | 1,248 | 9.7 ms |
| EXISTS | 29 | 1.66 ms |
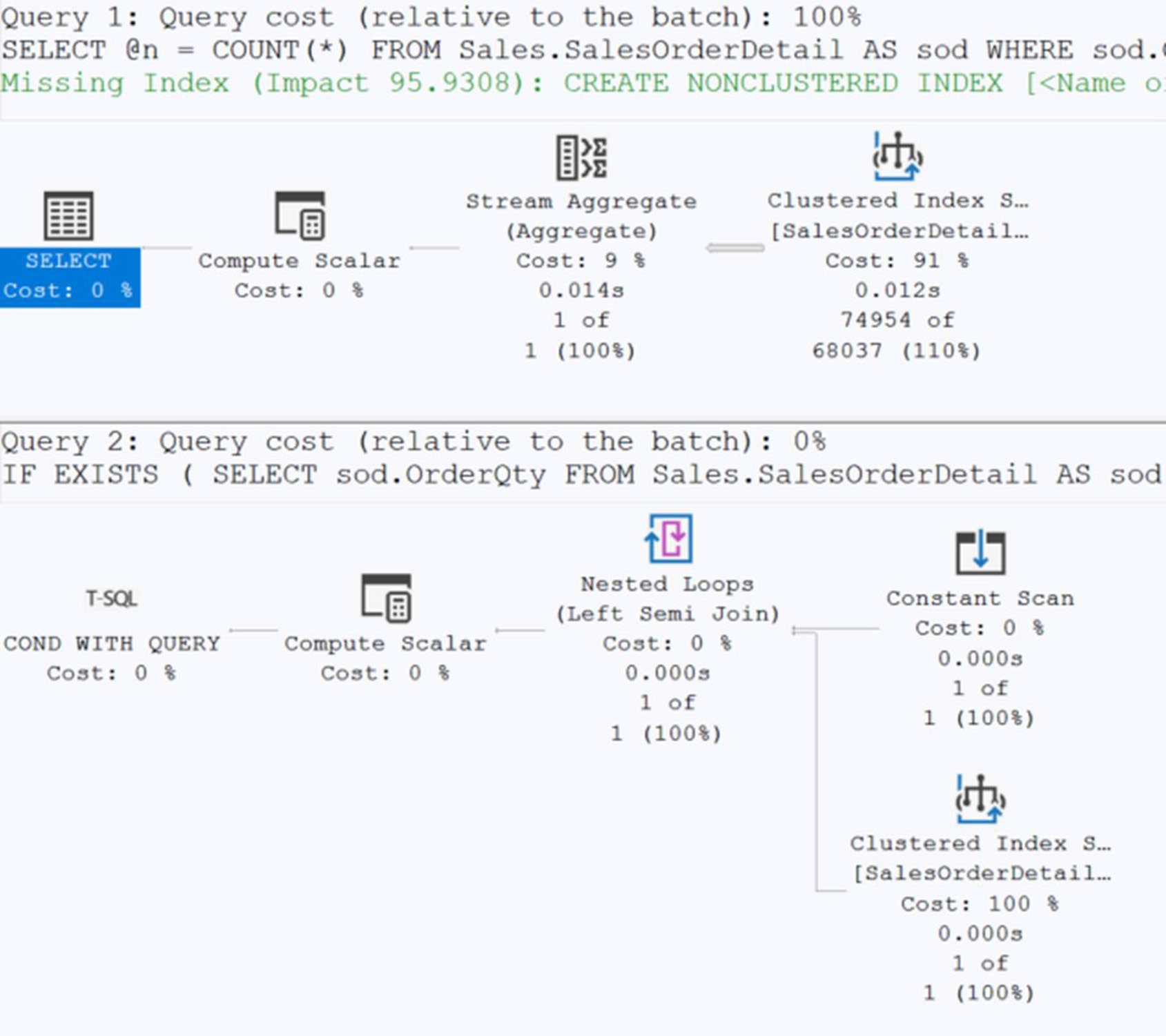
Figure 15-2: Different execution plans between COUNT and EXISTS
注意例外:當查詢的條件 不會命中任何資料時,兩者都需要全 scan,差異消失。要驗證資料 是否存在 用
EXISTS;要實際計數才用COUNT。
3. UNION ALL vs. UNION#
UNION 會去重——這意味必須做隱含的 sort 或 hash aggregate。UNION ALL 直接拼接。
書中對三段不重複的 query:
| 計畫 | 時間 | |
|---|---|---|
| UNION | Index Seek × 3 + Stream Aggregate × 3 + Merge Join × 2 | 2.4 ms |
| UNION ALL | Index Seek × 3 + Concatenation | 1.56 ms |
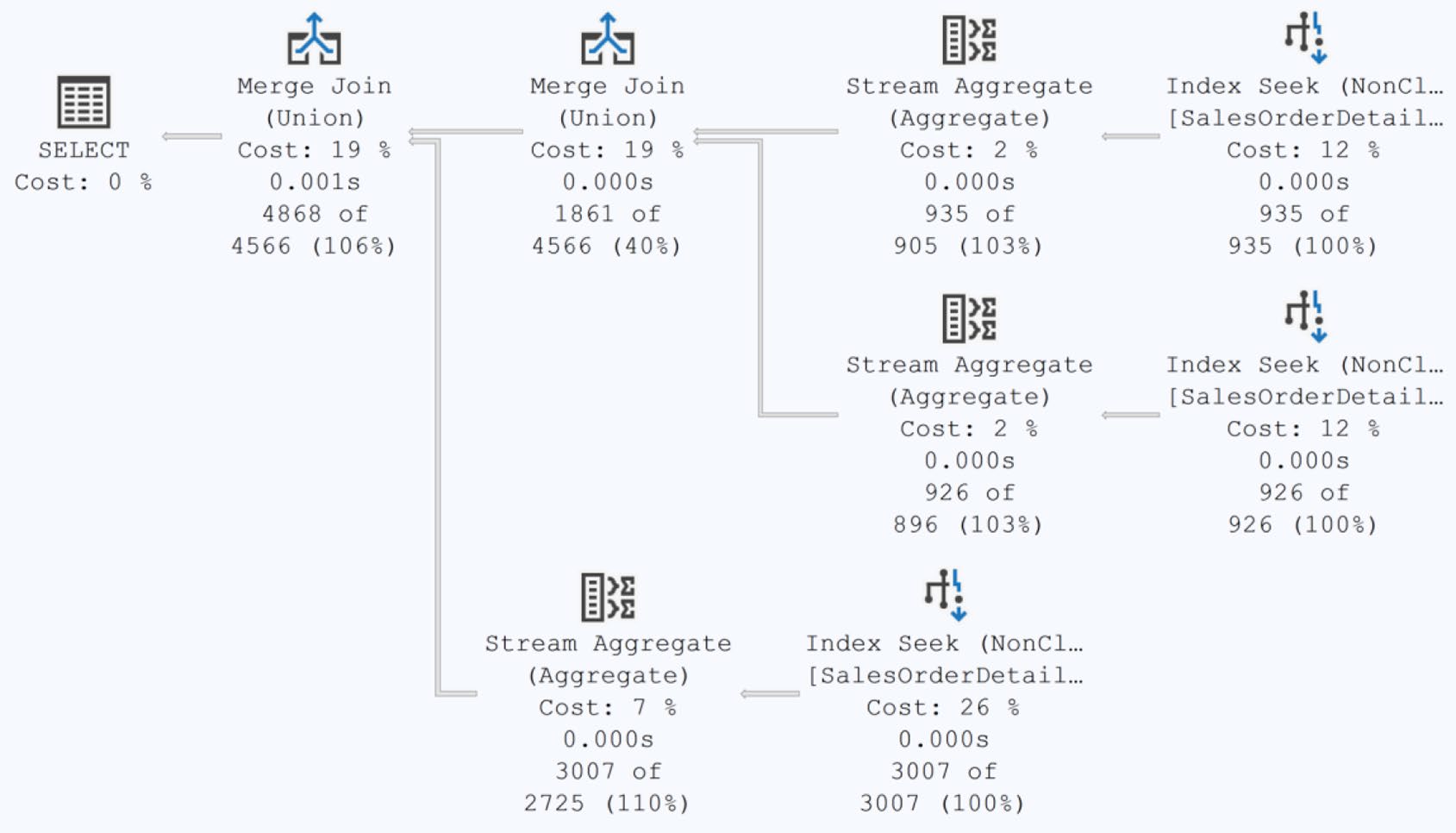
Figure 15-3: Execution plan from a UNION query
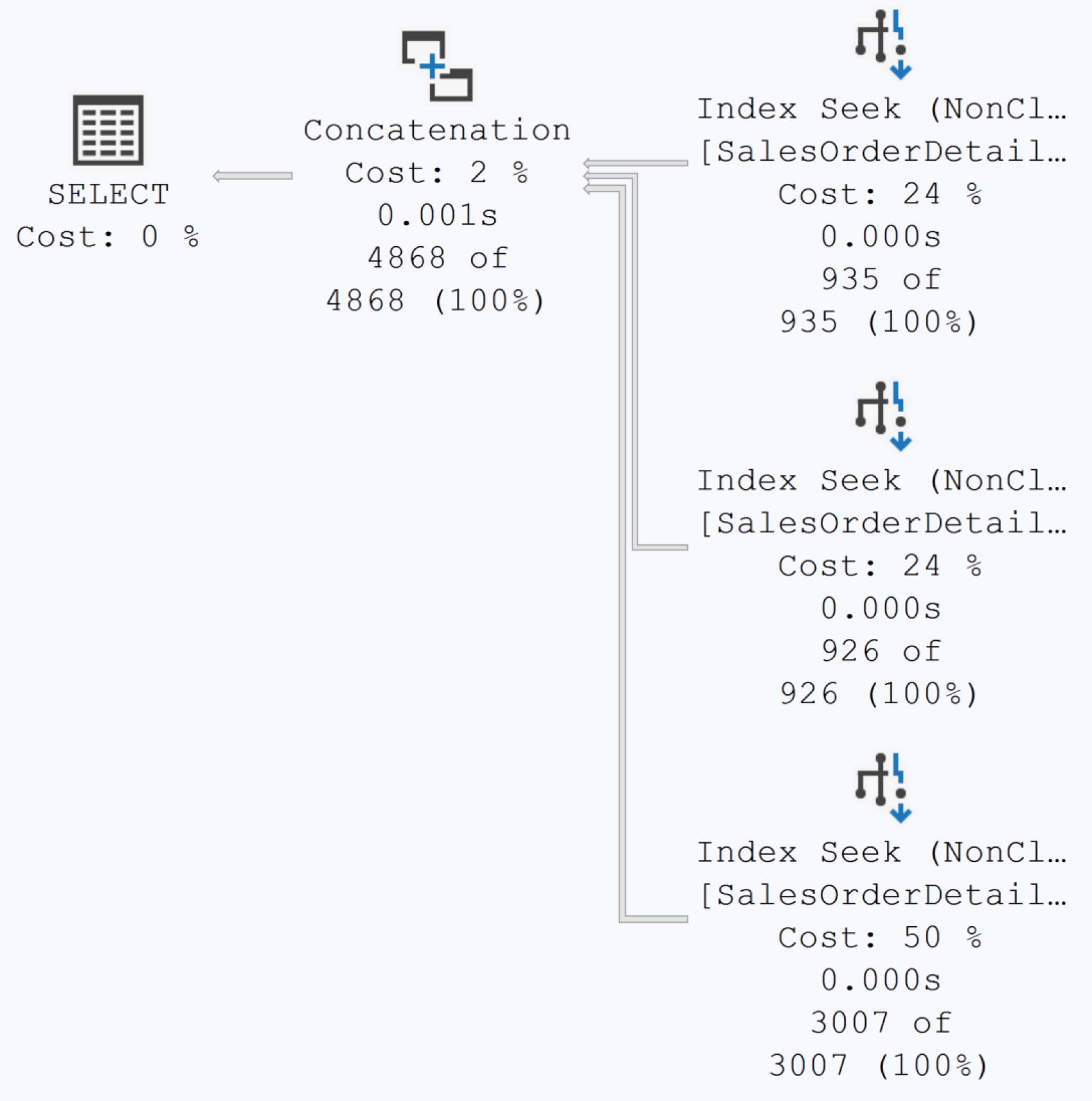
Figure 15-4: An execution plan for UNION ALL
預設先想 UNION ALL,只有真的需要去重才用 UNION。reads 可能一樣,但 CPU / 記憶體會明顯減少。
4. 索引支援 aggregation 與 sort#
MIN、MAX、ORDER BY 等運算 若有對應索引 就能直接取頂端 / 底端,毋須掃全表。
SELECT MIN(UnitPrice) FROM Sales.SalesOrderDetail;| 計畫 | reads | 時間 | |
|---|---|---|---|
| 沒有 UnitPrice 索引 | Clustered Index Scan + Stream Aggregate | 1,248 | 15.2 ms |
加 IX(UnitPrice ASC) | Index Scan + Top + Stream Aggregate | 3 | 389μs |

Figure 15-5: No supporting index for the aggregate query

Figure 15-6: An index supports the query
對分析型查詢,columnstore index 仍是首選;但對 OLTP 風格的「拿一個極值」,rowstore index 也能極快地解。
5. 慎用 batch 中的 local variable#
local variable 編譯時值未知 → 優化器只能用 density 平均估算(同第 13 章)。對非均勻分佈的欄位可能誤判。
書中實測,同一查詢用 local variable vs. 硬寫值,兩者最終回傳一樣的 48 列:
| 寫法 | 估算列數 | reads | 時間 |
|---|---|---|---|
| local variable | 3(density 估算) | 242 | 333μs |
| 硬寫值 | 48(histogram 精確) | 170 | 723μs |

Figure 15-7: Execution plan with a local variable
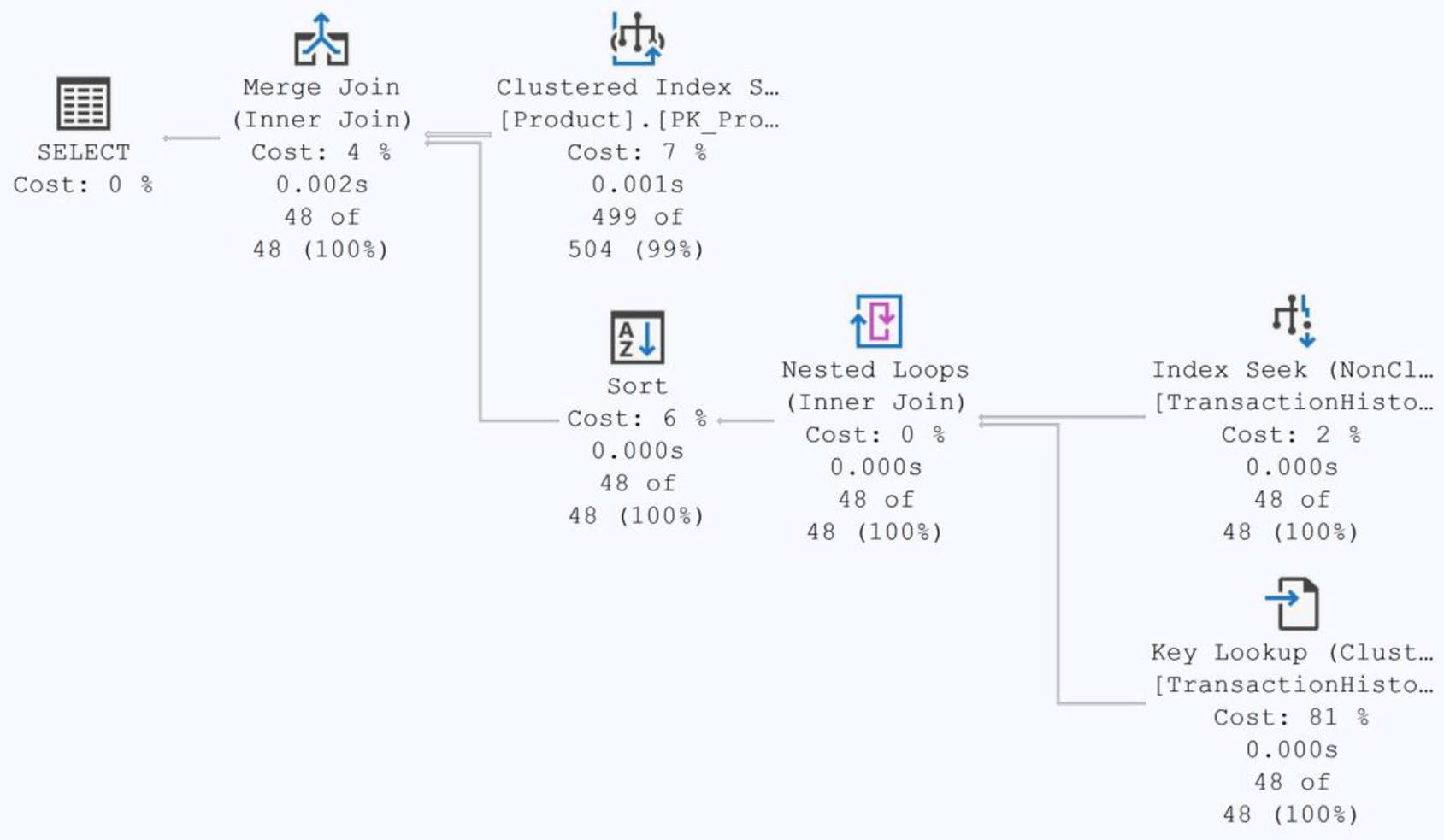
Figure 15-8: The execution plan changes with a hard-coded value
兩者各有勝負——局部變數版較快、硬寫值版讀數較少。沒有單一最佳解。
結論:能用 parameter 就用 parameter(讓 sniffing 工作),不得已才用 variable。寫硬值雖然能精確估算,但會犧牲程式碼可維護性。
6. Stored procedure 名稱很重要#
不要用 sp_ 開頭——這是 system stored procedure 的保留前綴。SQL Server 解析時會:
- 先到
master找 - 找不到再找當前資料庫的限定名稱
- 最後才找
dboschema
額外的 lookup 雖小但是真實成本。命名建議:usp_(user stored procedure)或直接用業務名。
若你建了一個與系統 procedure 同名的
sp_xxx,會直接撞車——execution 可能呼叫到系統那一個,或因參數不同直接報錯。
減少網路開銷#
把多個查詢打包成一批#
每次 round-trip 都有網路 latency。能在 server 端用一個 batch 或 procedure 完成的工作,就別拆成多次 round-trip。
客戶端要能處理多個結果集,或接收 JSON / 結構化結果。這對 ORM 預設行為(每次操作都單獨呼叫)需要刻意設計。
SET NOCOUNT ON#
預設每條語句執行後會傳一段 (N row(s) affected) 訊息——對長批次累積成可觀的網路訊息。
SET NOCOUNT ON;
-- ...your queries...不會觸發 recompile、不會造成行為改變,單純省訊息。所有 stored procedure 與 batch 預設都應加上。
降低 Transaction 成本#
每個 DML 都自動是一個 transaction(atomic)。多個 DML 不包在一個 transaction 裡 → 每個都各自寫 log。
Logging 的差異#
書中對 10,000 列的迴圈 INSERT:
-- 沒包 transaction
WHILE @Count <= 10000
BEGIN
INSERT INTO dbo.Test1 (C1) VALUES (@Count % 256);
SET @Count = @Count + 1;
END;時間 39 秒、log 從 7.9 MB / 5% 漲到 72 MB / 24%。
包進一個 transaction 後#
BEGIN TRAN;
WHILE @Count <= 10000
BEGIN
INSERT INTO dbo.Test1 (C1) VALUES (@Count % 256);
SET @Count = @Count + 1;
END;
COMMIT;效能與 log 用量都大幅改善——所有 INSERT 共用同一筆 commit。
但 transaction 太大也有問題:
- 持有的 lock 越多越久 → 阻塞其他人
- 失敗回滾代價高
- log truncation 被延後
折衷:用合理大小的 batch(例如每 1,000 列 commit 一次)。
減少 Lock 開銷#
幾個原則:
- 降低 transaction 範圍:不要把外部 API 呼叫、使用者輸入等慢操作包進 transaction
- 改用 row-level lock:避免不必要的 escalation 到 page / table lock
- 改用較低的 isolation level(在可接受的前提下)——例如 RCSI(Read Committed Snapshot Isolation)讓讀取不阻塞寫入
- 避免 cursor:逐列鎖定 + 慢吞吞,幾乎都能改寫成 set-based 操作
不要為了「省鎖」而把所有查詢加上
WITH (NOLOCK)。它跳過 shared lock,會 讀到 dirty data、可能漏讀或重複讀同一列。處理鎖爭用的正確姿勢是 RCSI。
本章定調#
- 用對型別、用對運算子,能讓索引發揮 100% 效能
EXISTS/UNION ALL/SET NOCOUNT是低風險高回報的小改動- Transaction 大小要拿捏——太細過於頻繁,過粗封鎖太久
- Local variable 對 cardinality 估算不友善;parameter / 硬寫值各有取捨
下一章將進入 Blocking 與被封鎖行程——當多個 session 競爭資源時的診斷與解法。