T-SQL 寫法決定一切#
硬體、雲端服務層級、伺服器設定、索引——它們都重要。但當 T-SQL 寫得糟,前面所有努力都救不回來。
寫得不好的查詢有專有名詞——code smell。其中最致命的是 RBAR(Row By Agonizing Row)——強迫 SQL Server 以逐列模式處理,違反集合式(set-based)設計初衷。
本章四大主題:
- 縮小結果集(result set)
- 讓索引能被有效運用
- 謹慎使用 optimizer hint
- 維護 referential integrity
把結果集縮到最小#
老格言:「Move only the data you need, and only when you need to move it.」
兩條具體原則:
- 只 SELECT 你需要的欄位
- 用 WHERE 過濾你需要的列
業務說「報表要 100,000 列」時,先別急著寫 query——人不會看 100,000 列。問清楚他們要的是 aggregation 還是某個子集。
限制 SELECT 欄位#
SELECT * 不是世界末日,但它會 打斷覆蓋索引(covering index)。書中實測對 Sales.SalesTerritory:
-- 只取 Name, TerritoryID(覆蓋索引可用)
SELECT Name, TerritoryID FROM ... WHERE ... -- 2 reads / 127μs
-- SELECT *
SELECT * FROM ... WHERE ... -- 4 reads / 331μs
Figure 14-1: An execution plan showing a covering index in action
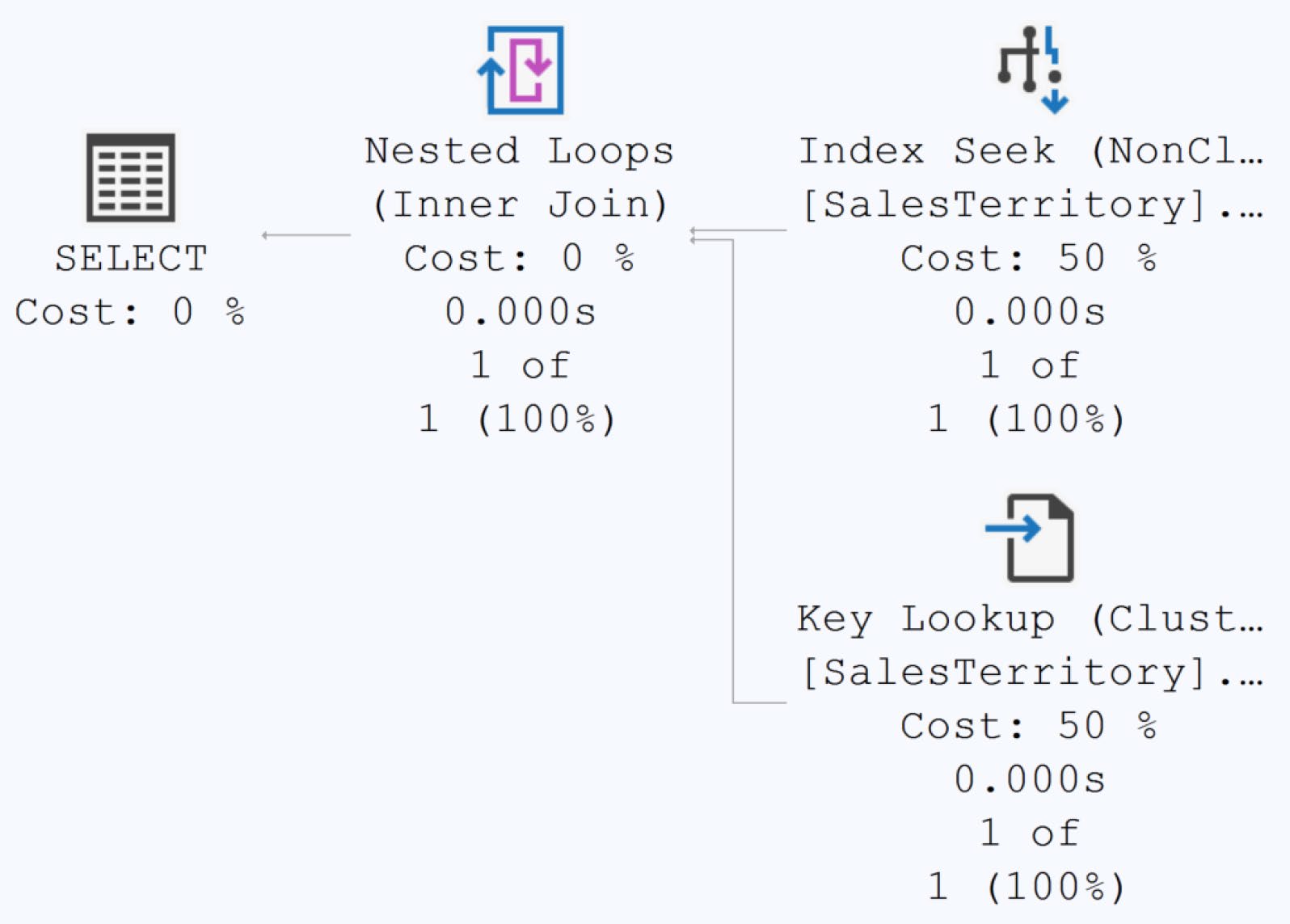
Figure 14-2: The query no longer has a covering index
reads 加倍、時間加倍——僅僅因為多取了不需要的欄位。
用 WHERE 過濾#
WHERE 對應了索引使用、選擇性、cardinality——基本上 所有索引行為的入口。
SELECT、UPDATE、DELETE 都依賴 WHERE 找到目標列;INSERT 也會在做 referential integrity 檢查時用到。
讓索引能被有效使用#
三條關鍵:
- 用 sargable 的 search condition
- 不要對欄位本身做運算
- 謹慎使用 scalar UDF
Sargable vs. Non-Sargable#
Sargable(Search ARGument ABLE):能讓優化器走 index seek 的條件。 Non-sargable:通常逼迫 index scan / table scan。
| 類型 | 條件 |
|---|---|
| Sargable | =、>、>=、<、<=、BETWEEN、LIKE 'x%' |
| Non-sargable | <>、!=、!>、!<、NOT EXISTS、NOT IN、NOT LIKE、LIKE '%x'、LIKE '%x%' |
用 inclusion 取代 exclusion:把「不是 A」改成「是 B 或 C」常常能換得 seek。多重排除條件有時可改寫成
EXCEPT也比NOT IN友善。
IN / OR / BETWEEN#
三者邏輯等價但物理表現不同。書中實測:
WHERE id IN (51825, 51826, 51827, 51828) -- 18 reads / 193μs(4 個獨立 seek)
WHERE id = 51825 OR id = 51826 OR ... -- 18 reads / 165μs
WHERE id BETWEEN 51825 AND 51828 -- 6 reads / 172μs(單一範圍 seek)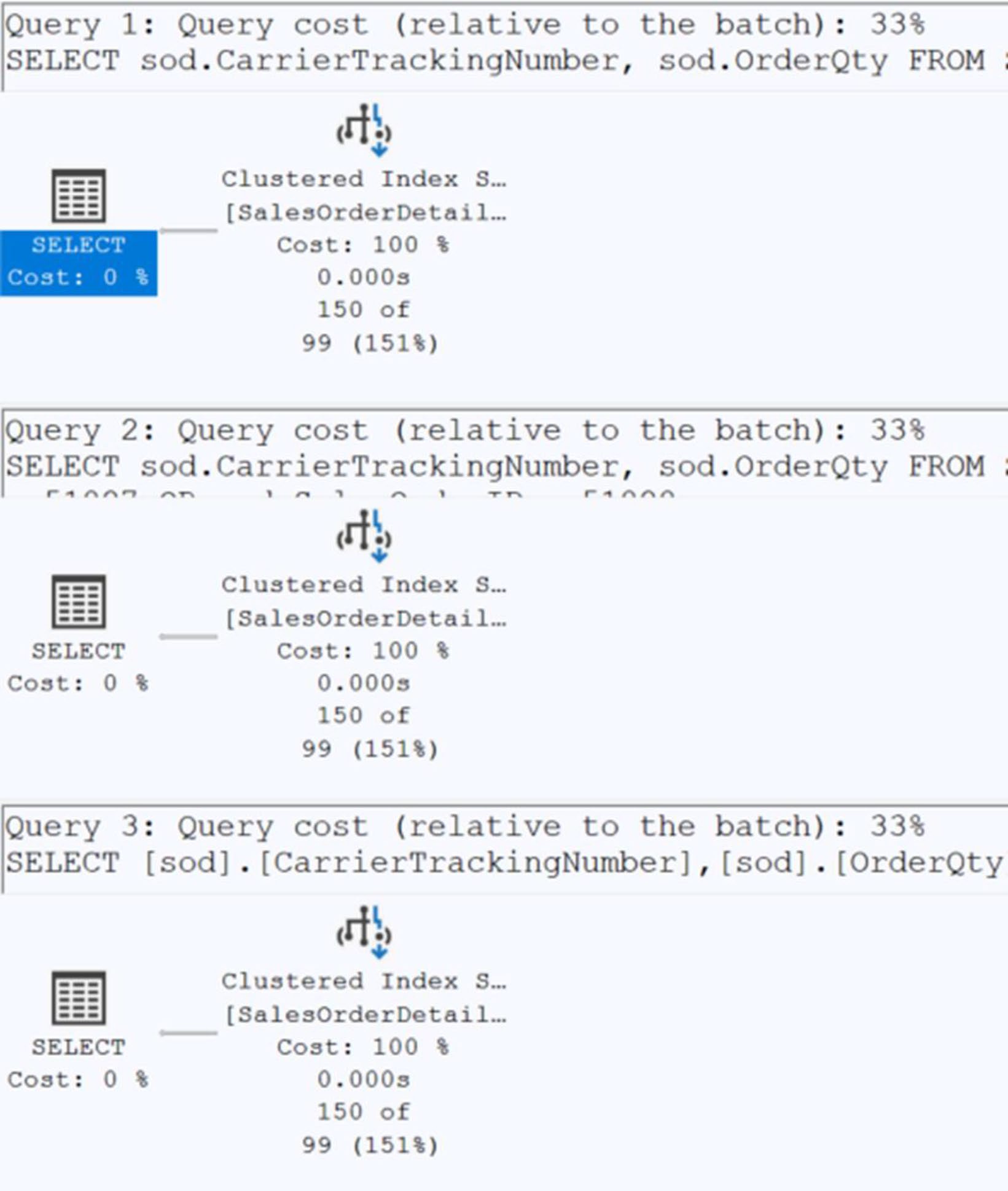
Figure 14-3: Three visually identical execution plans
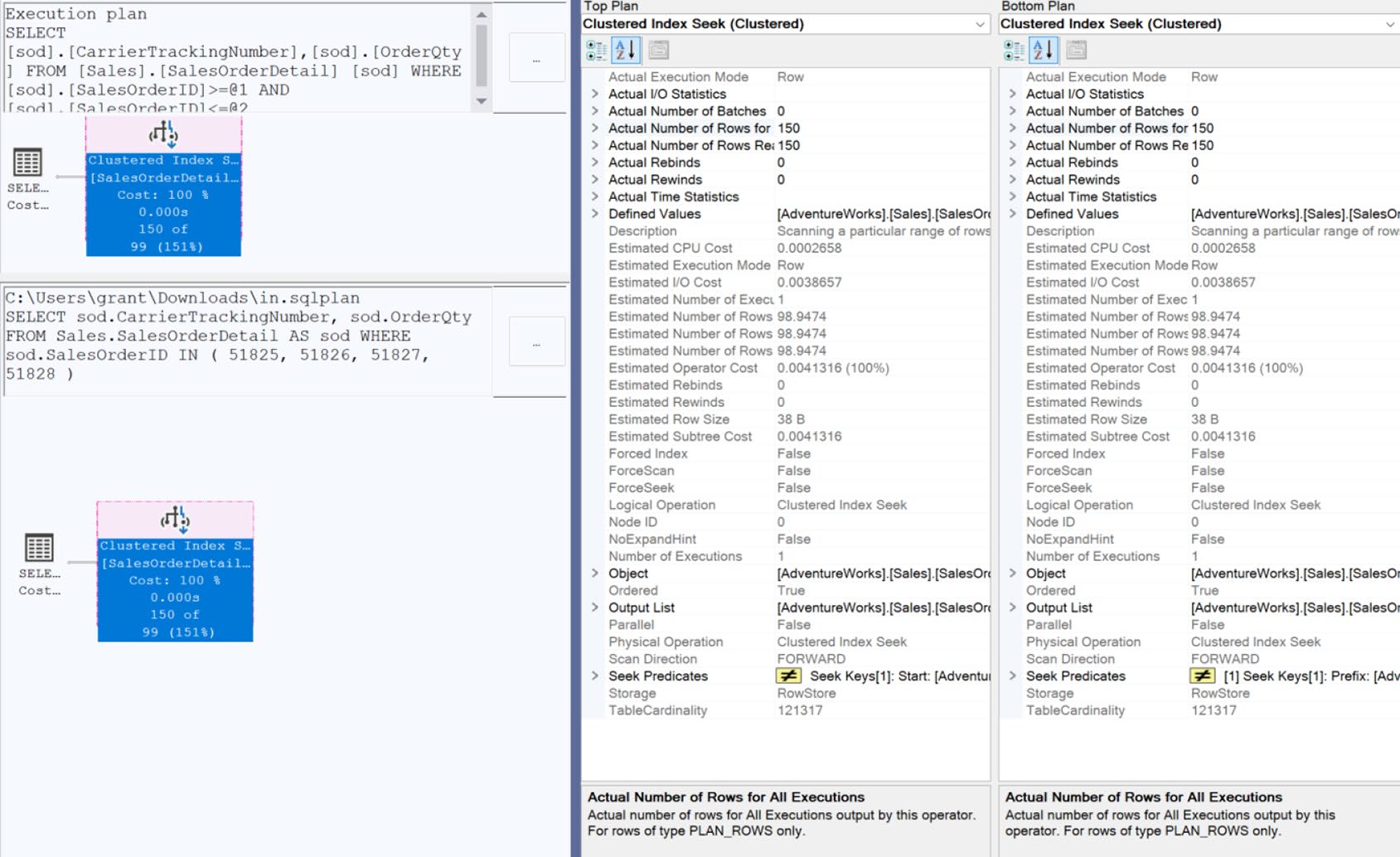
Figure 14-4: Differences between two execution plans
執行計畫看起來一樣,但 BETWEEN 用一次 seek 涵蓋整個範圍,reads 是 1/3。
連續的整數值範圍 → 用
BETWEEN;不連續的值 → 用IN,比OR簡潔且優化器更易處理。
LIKE#
LIKE 'Ice%':sargable,可走 index seek(內部會被改寫成>= 'Ice' AND < 'Icf')LIKE '%Ice'、LIKE '%Ice%':non-sargable,必走 scan
文字後段比對需求很常見,但放在 leading edge 的
%直接讓索引廢掉。考慮 Full-Text Index 或重新設計欄位儲存方式(例如反向字串)。
!< vs. >=#
兩者邏輯等價。優化器會 自動把 !< 改寫成 >= 並重用同一個計畫。但別依賴這個——直接寫 >= 對讀程式碼的人也清楚。
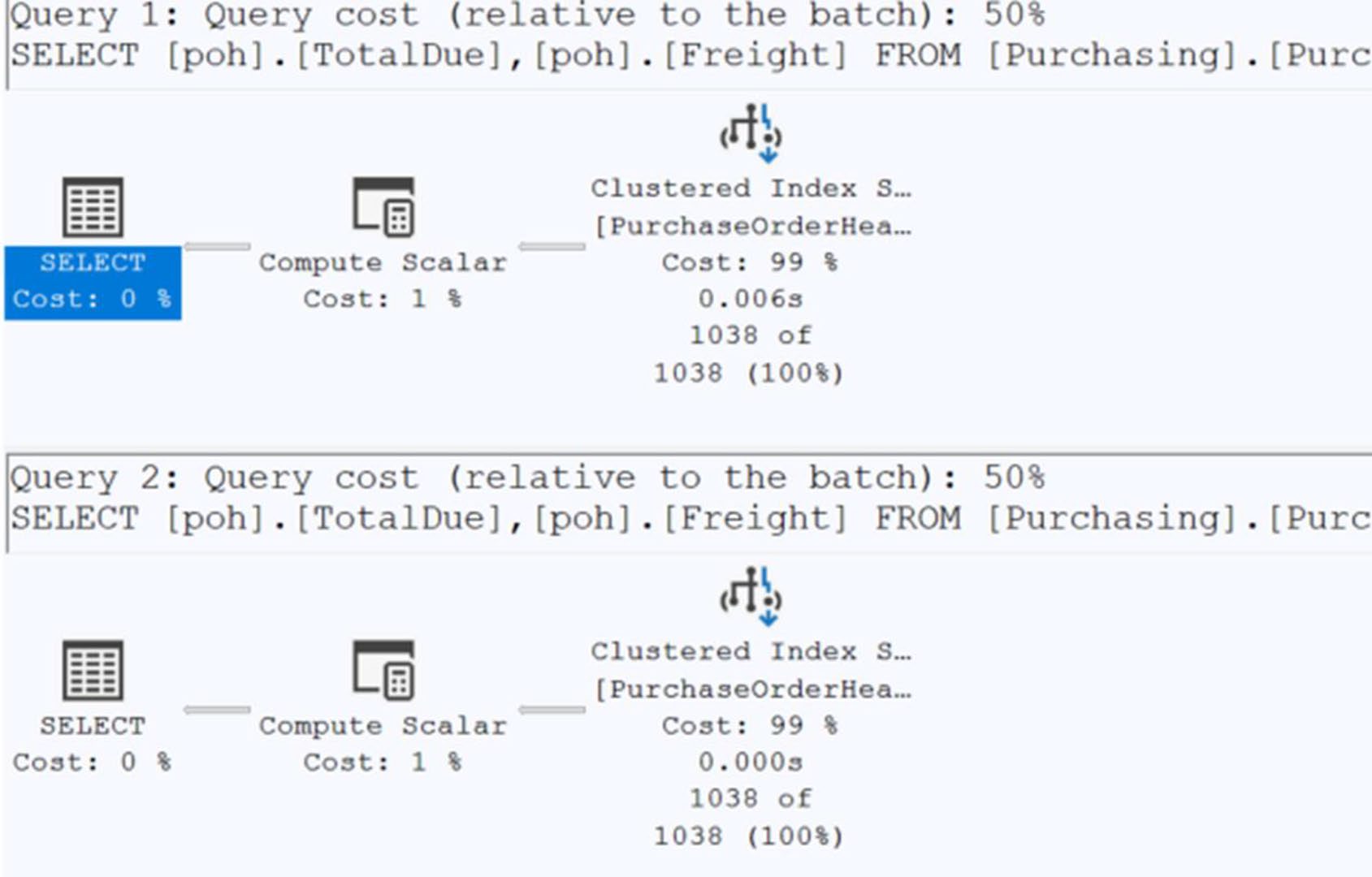
Figure 14-5: Identical execution plans
不要對欄位做運算#
任何包在欄位外面的運算都會讓索引失效。書中實測:
-- 對欄位做運算(壞)
WHERE poh.PurchaseOrderID * 2 = 3400 -- index scan,11 reads / 2.15ms
-- 把運算移到字面值(好)
WHERE poh.PurchaseOrderID = 3400 / 2 -- index seek,2 reads / 177μs
Figure 14-6: An index scan caused by a calculation

Figure 14-7: A seek with the calculation removed

Figure 14-8: Perplexity AI explaining how to troubleshoot this query
函數套在欄位上#
DATEPART、CONVERT、UPPER、ISNULL 等等,套在欄位上時 同樣讓索引失效。
-- 壞
WHERE DATEPART(yy, OrderDate) = 2008
AND DATEPART(mm, OrderDate) = 4
-- 73 reads / 2.48ms
-- 好(同樣結果)
WHERE OrderDate >= '2008-04-01'
AND OrderDate < '2008-05-01'
-- 2 reads / 239μs
Figure 14-9: An index scan caused by the DATEPART function

Figure 14-10: A seek occurs when dates are treated appropriately
經典反模式:把日期 / 時間存成
VARCHAR/CHAR為了「方便顯示」。所有日期運算都得做型別轉換 → 索引全部失效。請用date/datetime2/datetimeoffset。
Scalar UDF 的陷阱#
Scalar UDF(純量自訂函數)看似有效的程式碼重用工具,但對 每一列 呼叫一次:
- 強迫逐列處理
- 計畫上看起來只是 Compute Scalar,實際成本被嚴重低估
- 阻擋並行執行
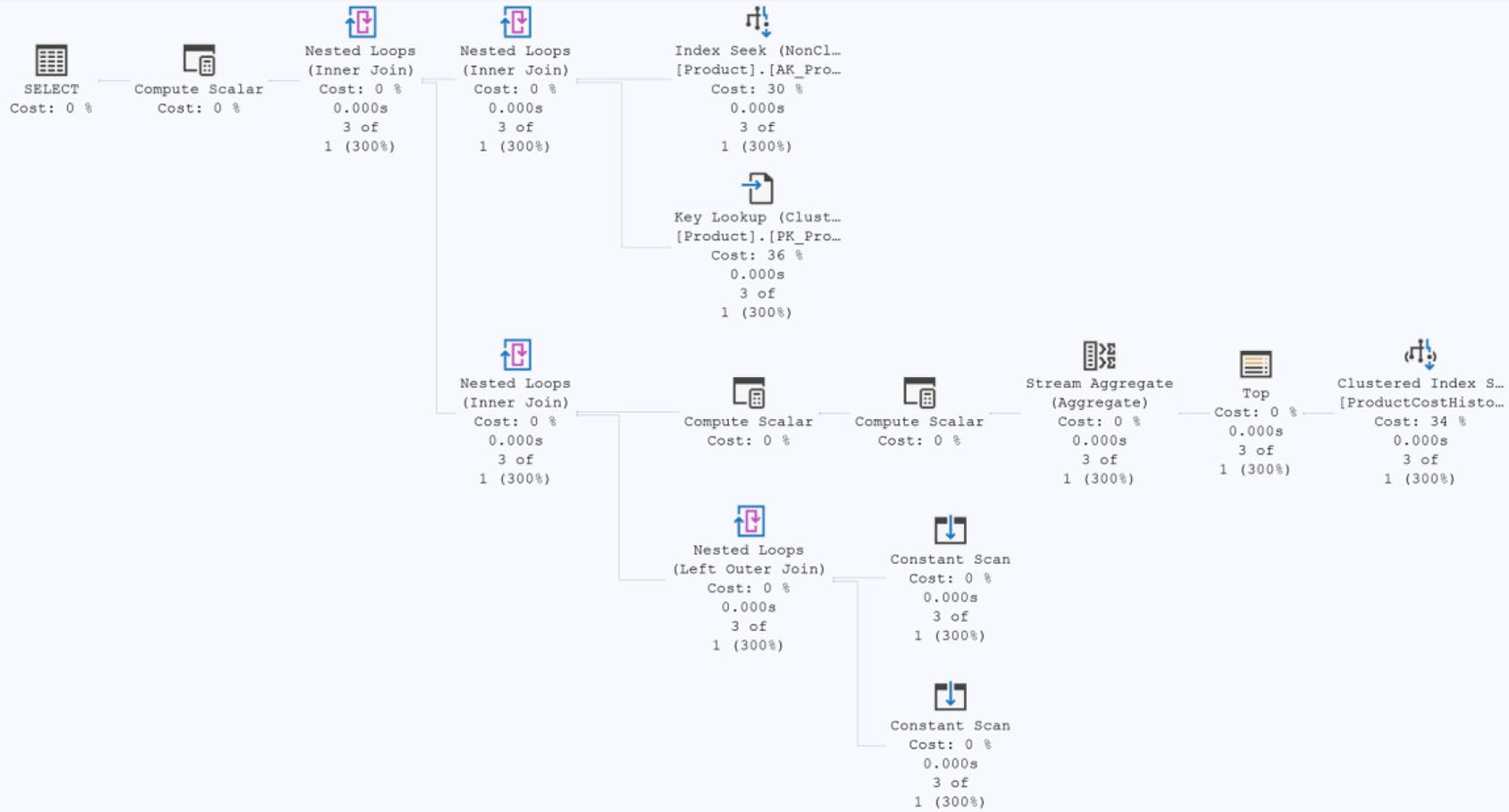
Figure 14-11: Execution plan with a scalar function

Figure 14-12: Data retrieval inside the scalar function

Figure 14-13: IF statement within the execution plan

Figure 14-14: Satisfying the rest of the query
SQL Server 2019 起的 Scalar UDF inlining 部分緩解此問題(第 21 章詳述)。但仍有許多場景不適用 inlining——用 inline TVF 或直接內嵌邏輯通常更快。
-- 改成 inline TVF(多列 join)
CREATE FUNCTION dbo.fn_GetCost (@ProductID INT)
RETURNS TABLE
AS RETURN (
SELECT StandardCost FROM Production.Product WHERE ProductID = @ProductID
);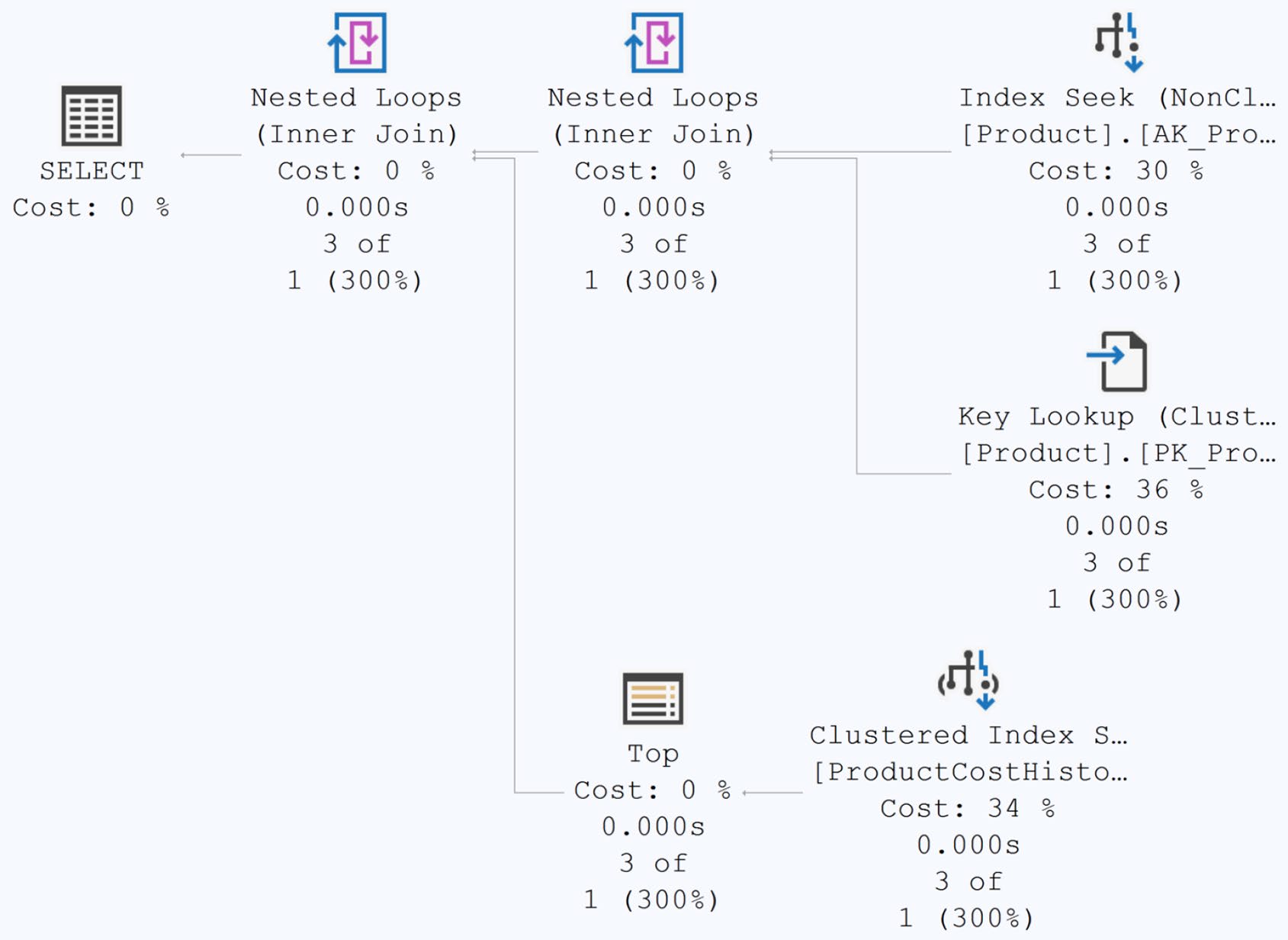
Figure 14-15: Simplified execution plan after eliminating the scalar function
謹慎使用 Optimizer Hint#
Hint 不是建議,是命令。它剝奪優化器的選擇權,並把當下決策固化下來。資料變動 → 環境變動 → 原本的 hint 可能變成枷鎖。

Figure 14-16: Execution for a query without any hints
常見 hint#
(NOLOCK)/READUNCOMMITTED:跳過 shared lock,讀到髒資料 / 同列讀兩次 / 漏讀 的風險都真實存在。不要為了快而用——應該用 RCSI(Read Committed Snapshot Isolation)取代。(INDEX(...)):強制走某索引。優化器以後若有更好選擇也用不上。OPTION (MAXDOP n):限制平行度。OPTION (RECOMPILE):每次重新編譯(第 13 章)。OPTION (OPTIMIZE FOR ...):固定參數值編譯(第 13 章)。
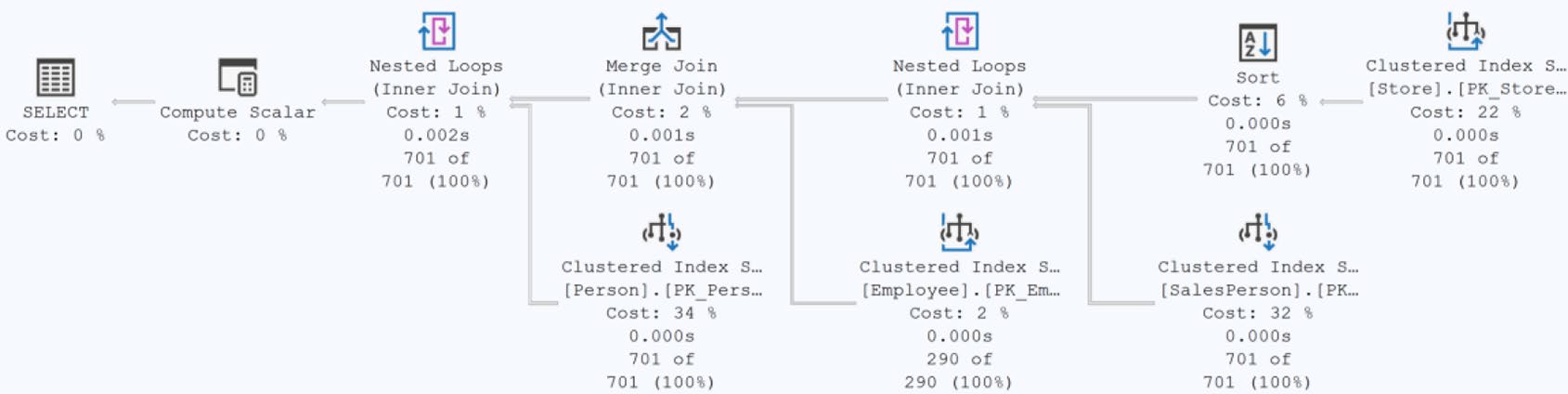
Figure 14-18: Forcing a single join to change may have consequences

Figure 14-19: A scan from an index hint
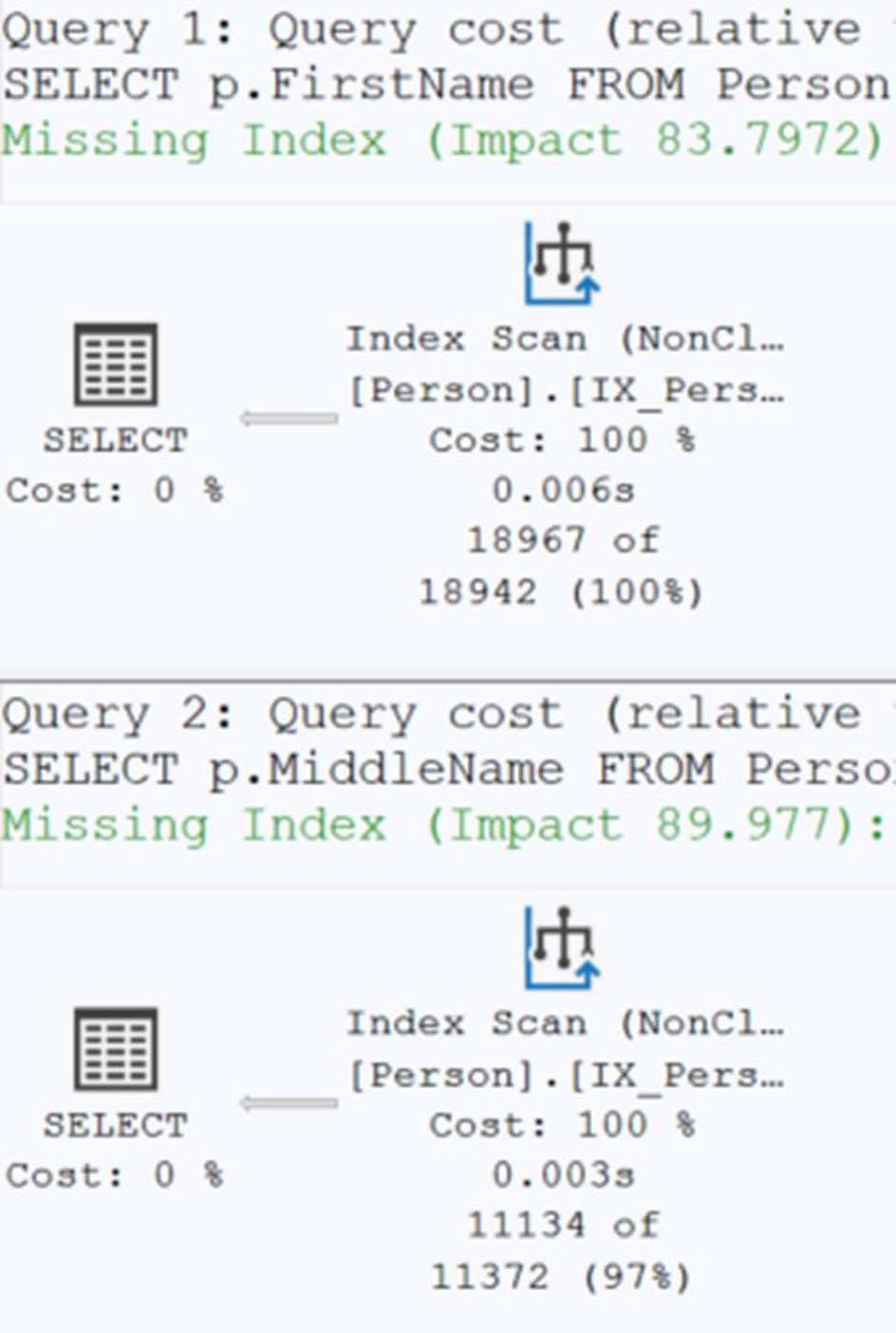
Figure 14-20: Two visually identical execution plans
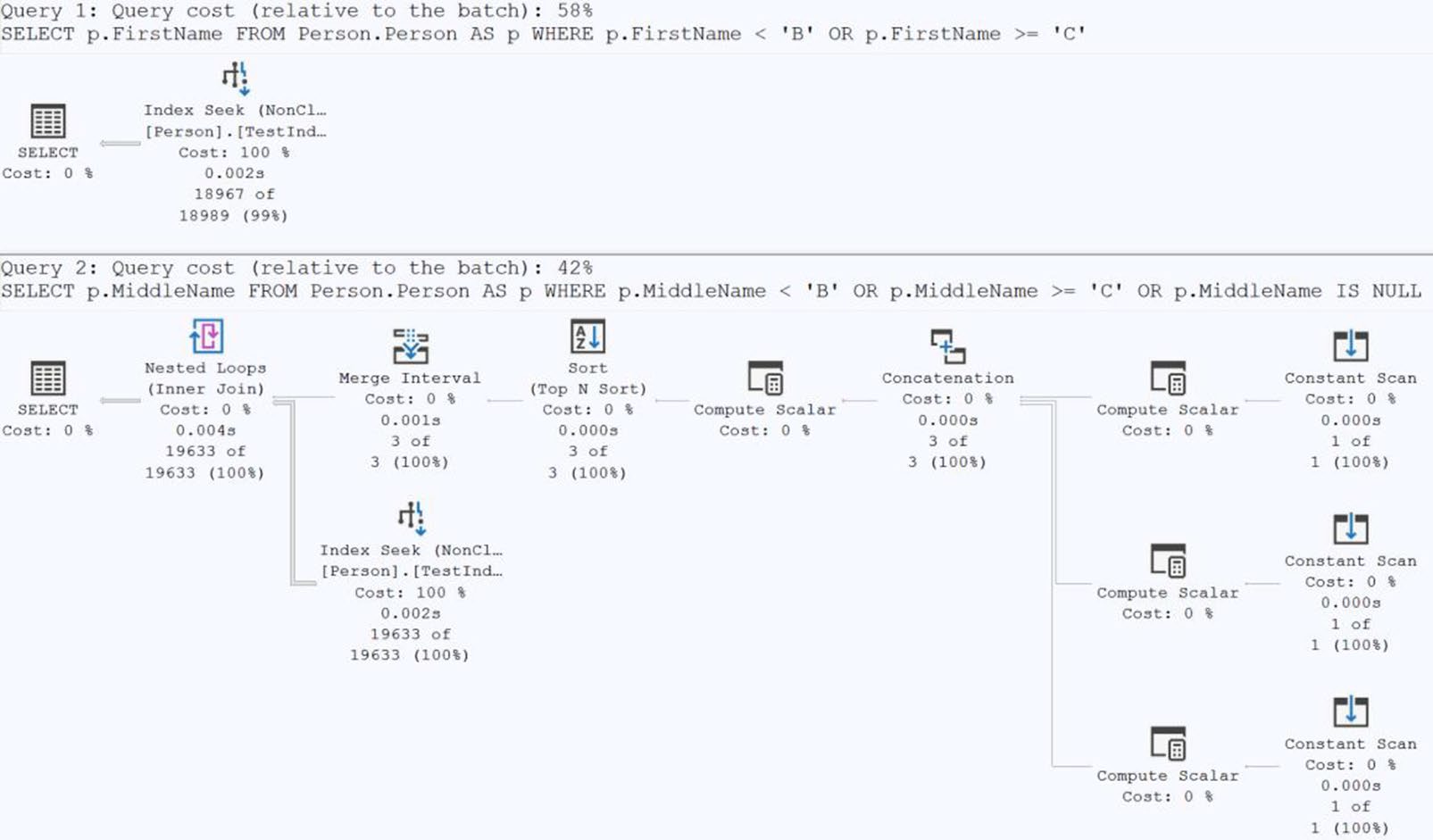
Figure 14-21: Indexes and IS NULL changed the execution plans
動 hint 之前先問:真正的根因是什麼? 通常是統計不準、索引設計不佳、或查詢寫法問題。處理根因比硬塞 hint 更可持續。
Query Store / Plan Guide 提供「不改程式碼也能上 hint」#
第 6 章與第 8 章提過:透過 Query Store 的 sp_query_store_set_hints 或 plan guide,不必動程式碼 就能套 hint——對遺留系統極為有用。
維護 Referential Integrity#
外鍵(FK)、唯一約束(UQ)、檢查約束(CK)不只是資料完整性的保證——它們是優化器的重要決策素材:
- FK 讓優化器在 join 簡化時可剔除不需要的表
- 唯一性讓優化器知道「最多一列」→ 改變 join 策略
- Check constraint 讓優化器在 query 包含明顯不可能的條件時直接短路

Figure 14-22: An execution plan with no data access at all
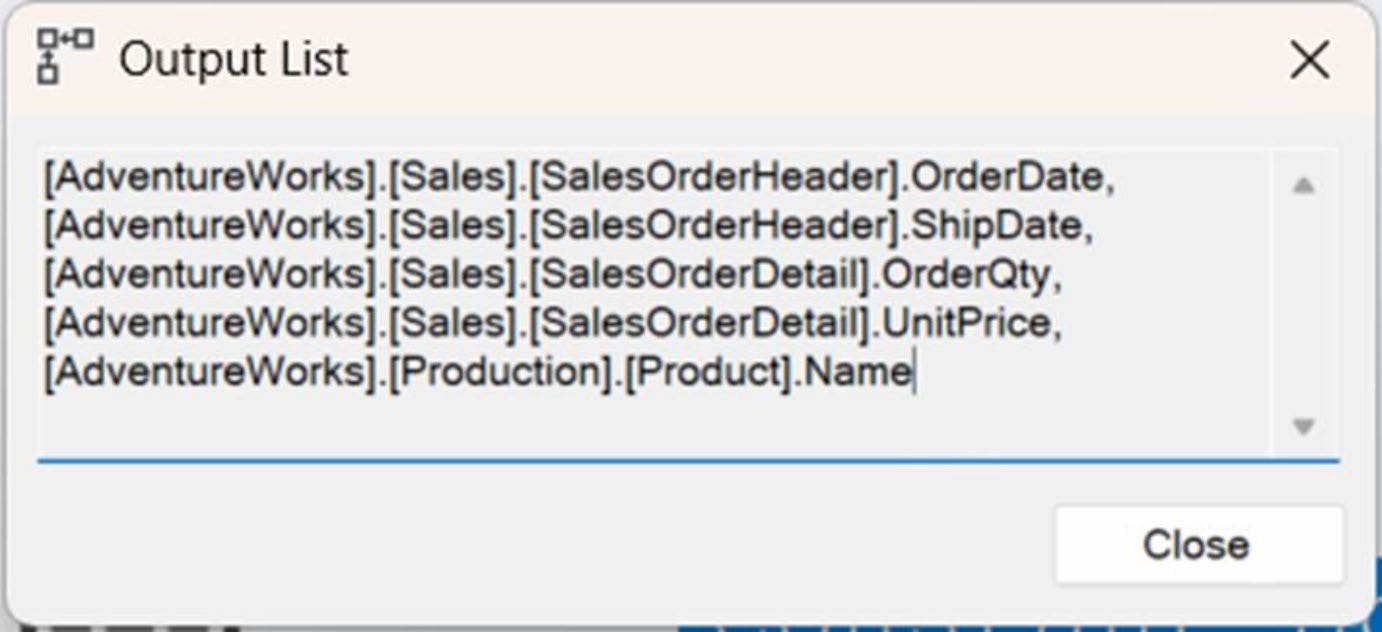
Figure 14-23: The Output List to produce an empty result set
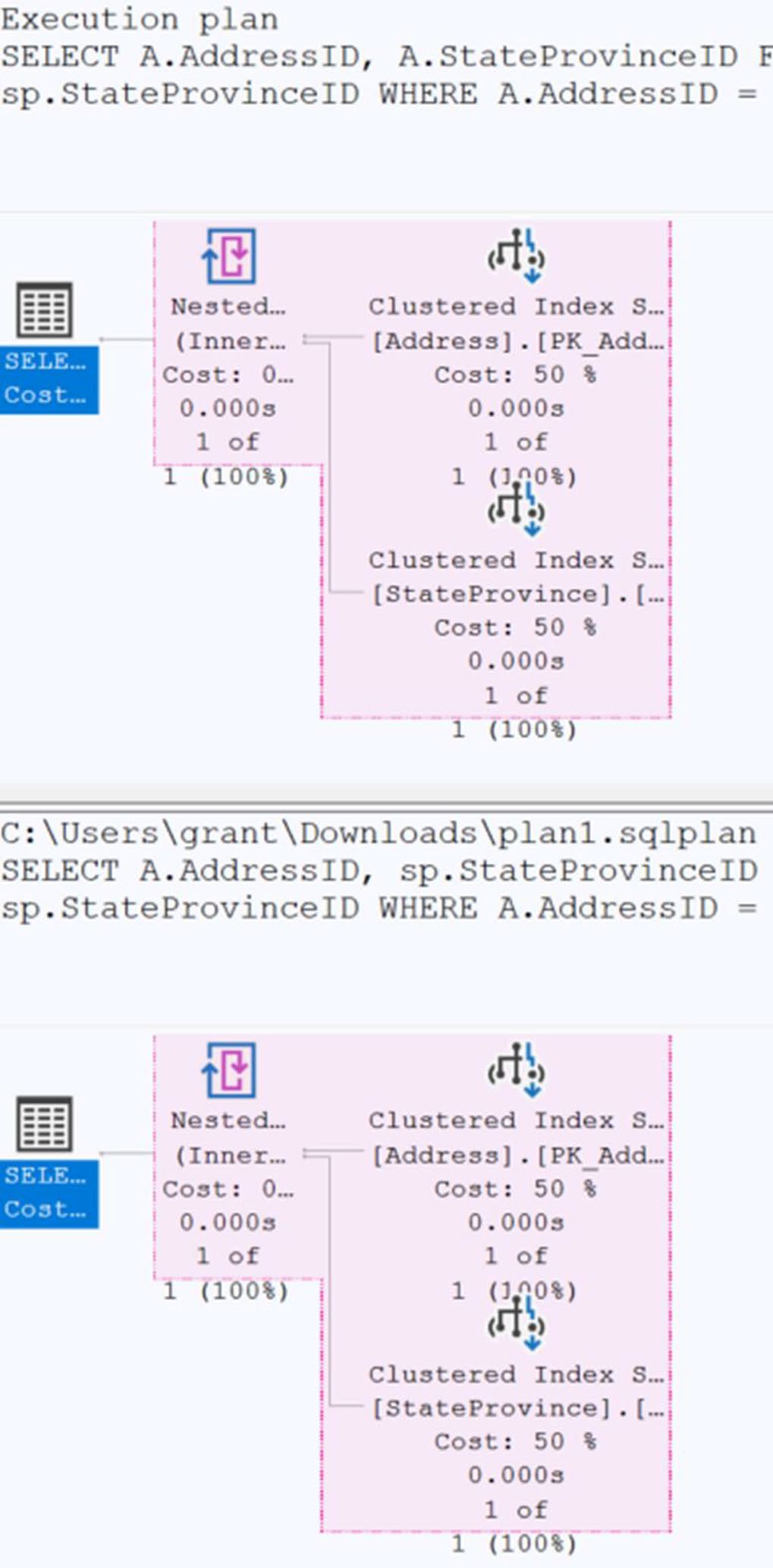
Figure 14-24: Two identical execution plans
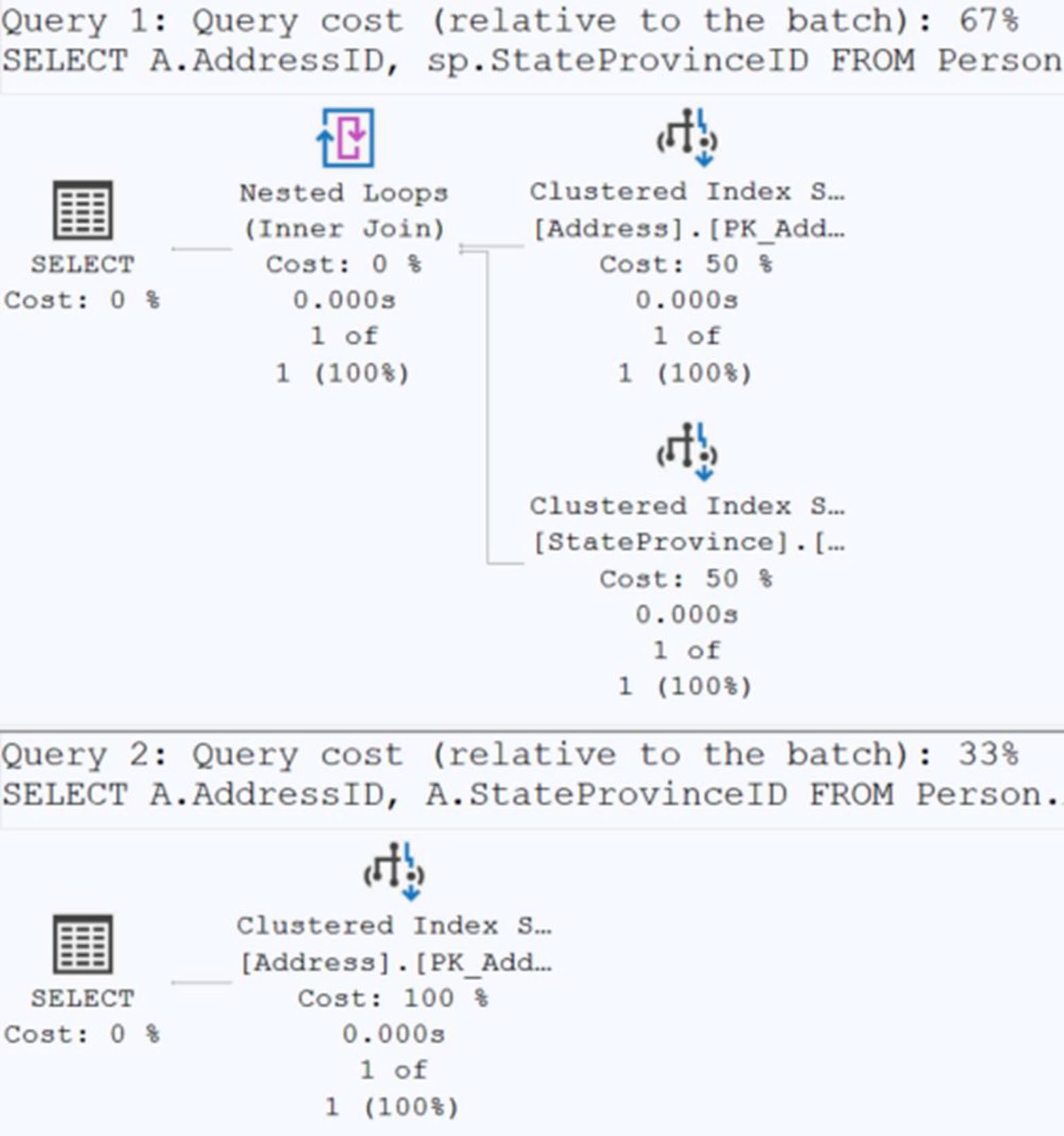
Figure 14-25: The execution plans are now different because of the foreign key
把 constraint 設成 TRUSTED(即
WITH CHECK而非WITH NOCHECK)才能讓優化器使用。批次匯入後請記得:ALTER TABLE ... WITH CHECK CHECK CONSTRAINT ALL;否則 constraint 雖然存在,但
is_not_trusted = 1,優化器無法依賴它做決策。
本章定調#
- 寫對的 T-SQL 比加索引、買硬體都重要
- 先把欄位、列縮小;再確保 sargable、無欄位運算
- Scalar UDF 是隱形殺手;改 inline TVF / 內嵌
- Hint 是最後手段,先處理根因
- Constraint 不只是資料完整性——維持 trusted 才能輔助優化
下一章將進入 降低查詢資源使用——看如何在不犧牲功能的前提下省 CPU、I/O、記憶體。