為什麼這章「有點爭議」#
碎片化(fragmentation)是經典話題,傳統觀點是「碎片一定要修」。Fritchey 在這章直接質疑這個觀點:
- 修碎片本身有成本(時間、I/O、blocking)
- 修完後資料一變動 → 又得重來
- 現代 SSD / NVMe 上「page 跳來跳去」的代價已大幅降低
不要無腦排程 nightly REBUILD。先量測碎片真的影響你的查詢嗎?影響大多少?再決定是否處理、用哪種策略。
Rowstore 碎片如何發生#
SQL Server 把所有資料放在 8 KB page,page 又以 8 個為一組組成 extent(64 KB)。
Page Split#
當一個 page 滿了,再來的 INSERT / UPDATE 把它撐破:
- 一半留在原 page,另一半搬到 新 allocate 的 page
- 新 page 的位置不見得在原 page 旁邊
- 邏輯順序仍然正確(雙向鏈結串列),但 實體順序錯位 了

Figure 12-1: Leaf pages in order
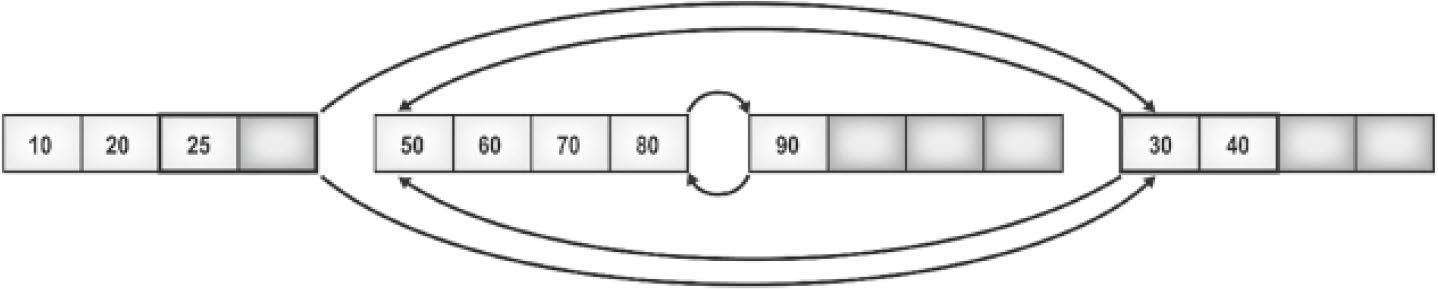
Figure 12-2: Leaf pages out of order
兩種碎片#
- External fragmentation:page 在不同 extent 間跳來跳去
- Internal fragmentation:page 內部空洞——page 沒滿
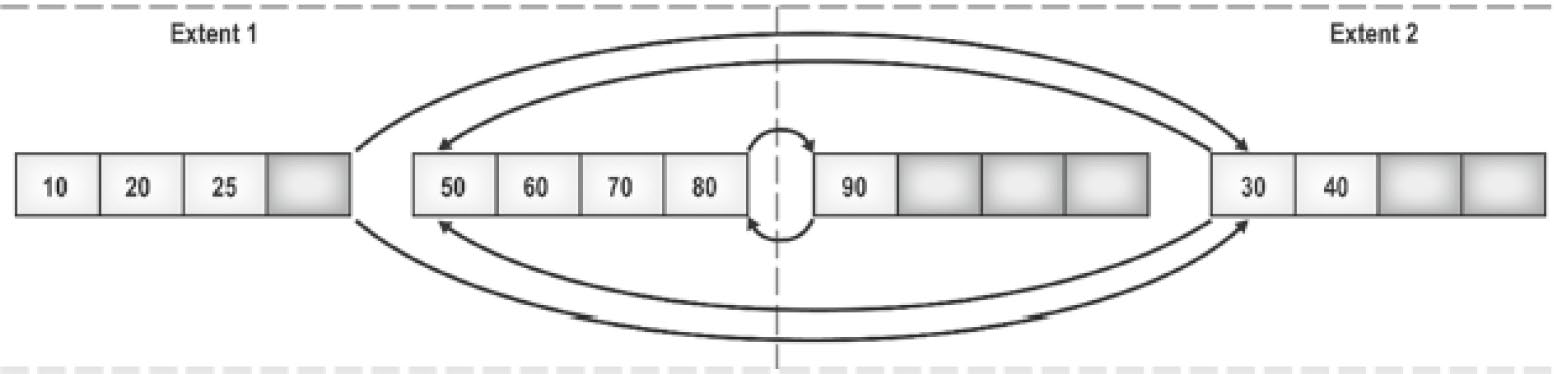
Figure 12-3: Pages distributed across extents
Internal fragmentation 不一定壞。空間能讓後續 INSERT / UPDATE 不必再 split,反而對寫入有利。
範例:UPDATE 觸發 split#
書中建一個固定 ROW size 的表,全部 8 列剛好擠滿一個 page。然後:
UPDATE dbo.SplitTest SET C3 = 'Add data' WHERE C1 = 200;C3 變長 → page 容不下 → split。sys.dm_db_index_physical_stats 顯示 page count 從 1 變 2,碎片率從 0% 跳到 50%。

Figure 12-4: Physical attributes of the index iClustered

Figure 12-5: Fragmentation in the index iClustered
範例:INSERT 中段觸發 split#
INSERT INTO dbo.SplitTest VALUES (110, 'C2', '');110 要排在 100 與 200 中間 → page 滿 → split。

Figure 12-6: Fragmentation from an INSERT in iClustered
反之,INSERT 在尾端(例如新增
C1 = 900)只會 allocate 新 page,不會 split。這也是 sequential key(如IDENTITY)對 OLTP 比 random key(如 random GUID)友善的核心原因。
Heap 的特殊情況#
heap 表也會碎片化。但若用 ALTER TABLE ... REBUILD 修整,所有 nonclustered index 必須重建——因為它們透過 RID(physical 位置)指向資料,而資料剛被搬家。
修 heap 的碎片代價遠比修 clustered index 高。這也是 heap 不該作為主流 OLTP 設計的原因之一。
Columnstore 的「碎片」#
columnstore 沒有 page split,但有自己的「碎片」:
- 修改 / 刪除不是真的改 column segment
- 而是 邏輯標記為已刪除 / 已更新,留在另一個 B-Tree 的 deltastore
- 累積的「邏輯刪除」就是 columnstore 的碎片
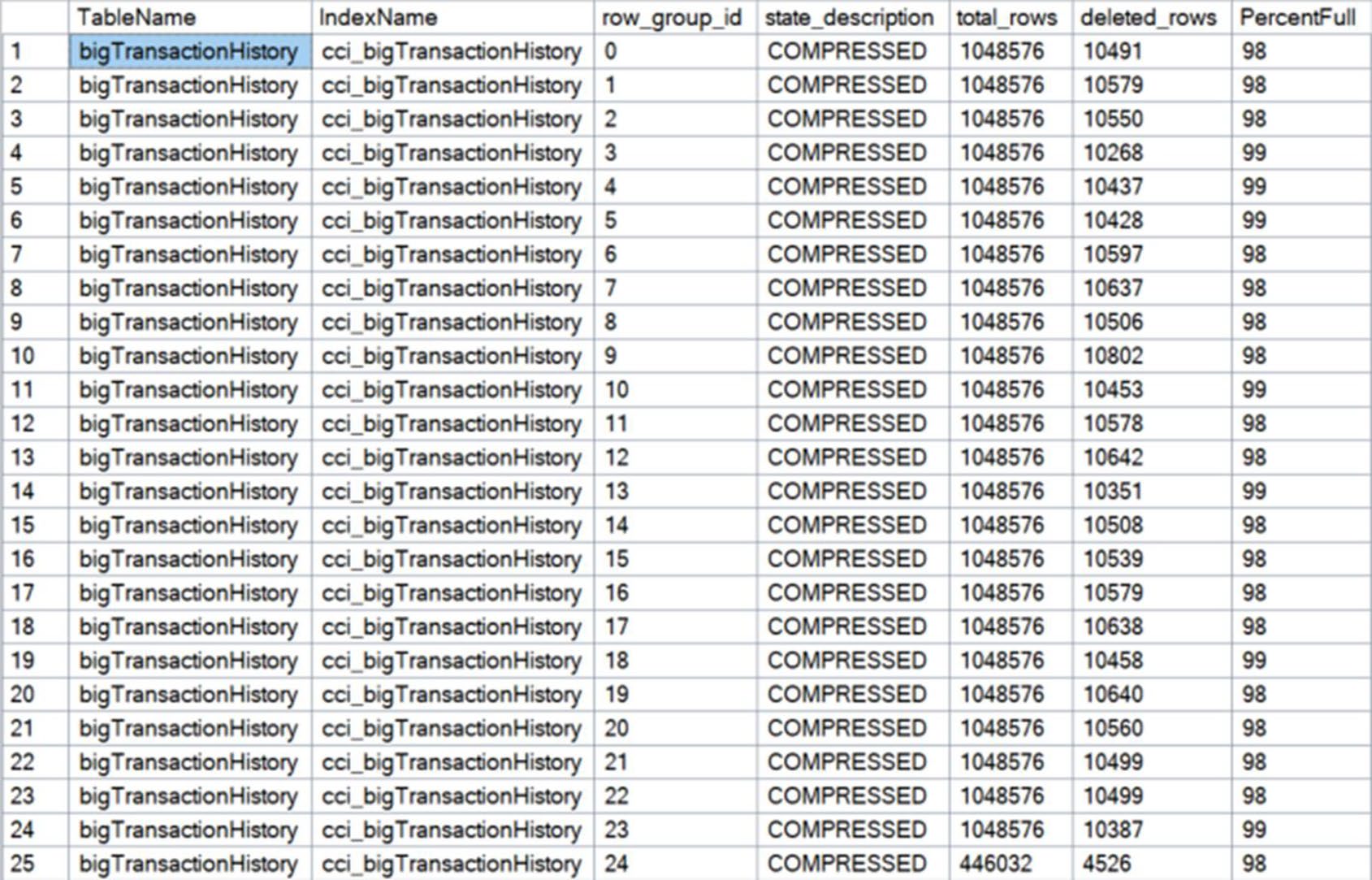
Figure 12-7: Fragmentation within a clustered columnstore index
觀察:sys.column_store_row_groups#
SELECT OBJECT_NAME(i.object_id) AS TableName,
i.name AS IndexName,
csrg.row_group_id,
csrg.state_description,
csrg.total_rows,
csrg.deleted_rows,
100 * (total_rows - ISNULL(deleted_rows, 0)) / total_rows AS PercentFull
FROM sys.indexes AS i
JOIN sys.column_store_row_groups AS csrg
ON i.object_id = csrg.object_id
AND i.index_id = csrg.index_id
WHERE name = 'cci_bigTransactionHistory';PercentFull 顯示每個 row group 多少列是「實際存活」。書中對 bigTransactionHistory 跑一個跨 row group 的 DELETE 後,每個 group 的 PercentFull 都掉下來。
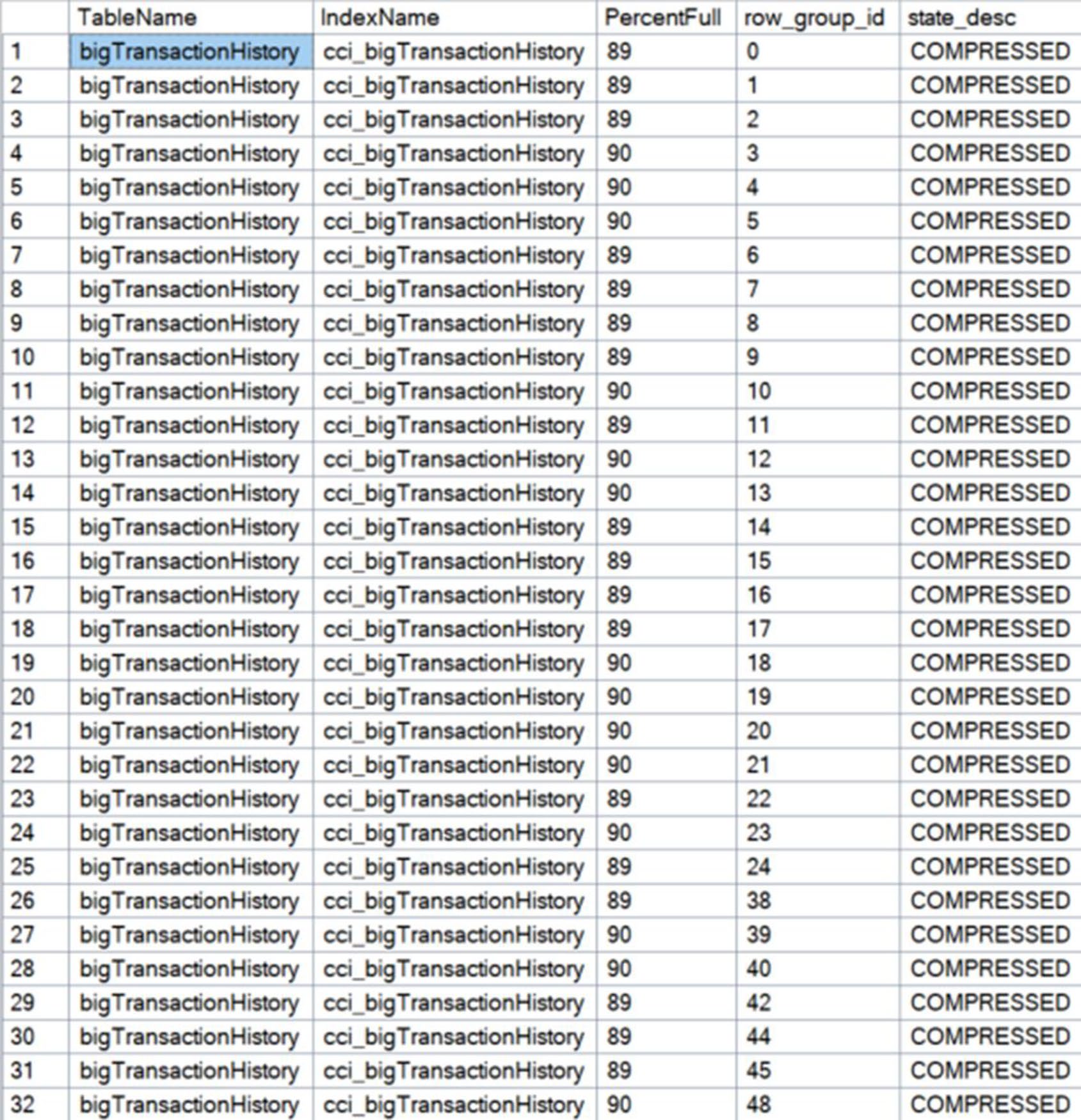
Figure 12-11: Several rowgroups are missing 10%
碎片到底傷多大#
Rowstore 實測#
對 20,000 列的表跑兩個查詢:
| 查詢 | 修整前 | 修整後 |
|---|---|---|
| 6 列範圍掃 | 8 reads / 886μs | 6 reads / 401μs |
| 10,000 列大範圍掃 | 10,034 reads / 461 ms | 6,695 reads / 303 ms |
小範圍查詢從碎片影響不大——只讀單頁時誰跟誰相鄰幾乎不重要。
大範圍 scan 受碎片影響最深——sequential I/O 變 random I/O、no read-ahead。
Columnstore 實測#
對同一個 aggregation 查詢:
| 狀態 | reads | duration |
|---|---|---|
| 沒有 deleted | 154,494 | 104 ms |
| DELETE 一段範圍後 | 154,238 | 212 ms |
reads 幾乎沒變但時間翻倍——多出來的時間花在「join 另一個追蹤已刪列的內部 B-Tree」上。
Columnstore 的這個額外 join 不會出現在執行計畫——只能透過效能退步察覺。
量測碎片的工具#
sys.dm_db_index_physical_stats#
最重要的 DMV,三種模式:
- Limited(預設):最快但最粗
- Sampled:抽 1% 的 page,準確度 / 速度平衡
- Detailed:掃所有 page,最準但最重
不要不指定
OBJECT_ID而把模式設成Detailed——會對整個資料庫所有索引做完整掃描,極可能讓 production 進入維護等級的 I/O 衝擊。
索引若不到 10,000 page,即使你選 Sampled,SQL Server 也會自動升級為 Detailed。
關鍵欄位:
avg_fragmentation_in_percent:邏輯碎片百分比fragment_count、page_count、avg_page_space_used_in_percentrecord_count、avg_record_size_in_bytes
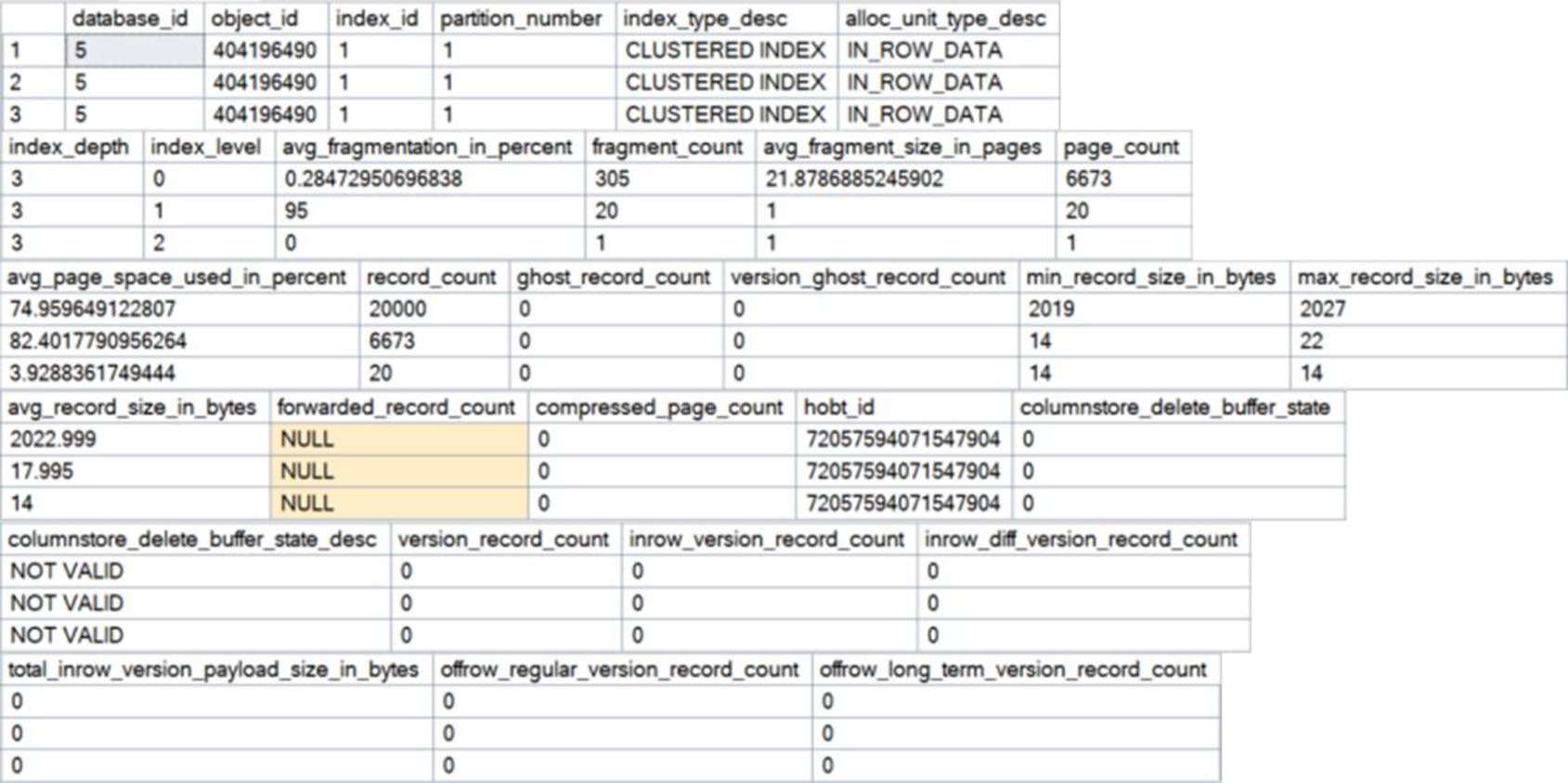
Figure 12-8: Complete results from sys.dm_db_index_physical_stats

Figure 12-9: Fragmentation of the dbo.FragTest table
sys.column_store_row_groups#
如上節的查詢——觀察每個 row group 的 total_rows / deleted_rows。
修整碎片的工具#
REBUILD vs. REORGANIZE#
ALTER INDEX iClustered ON dbo.FragTest REBUILD;
ALTER INDEX iClustered ON dbo.FragTest REORGANIZE;
Figure 12-10: dbo.FragTest after running REORGANIZE
| REBUILD | REORGANIZE | |
|---|---|---|
| 動作 | 重建整個索引(drop + create) | 把 leaf level page 內整理 |
| 鎖 | 預設 schema-mod 鎖;可加 ONLINE | online、可中斷恢復 |
| 統計資訊 | 重新建立(含 fullscan) | 不更新統計 |
| 適用 | 高度碎片(> 30%) | 中度碎片(5-30%) |
| 成本 | 高 | 低 |
經典 Microsoft 規則:
- 0–5%:別動
- 5–30%:REORGANIZE
- > 30%:REBUILD
但這只是粗略指引。重點還是看查詢效能是否實際受影響。
Columnstore 的修整#
ALTER INDEX ... REORGANIZE 對 columnstore 是合併小 row group、實體刪除已標記的列。REBUILD 則完全重建整個 columnstore——成本高、收益顯著。
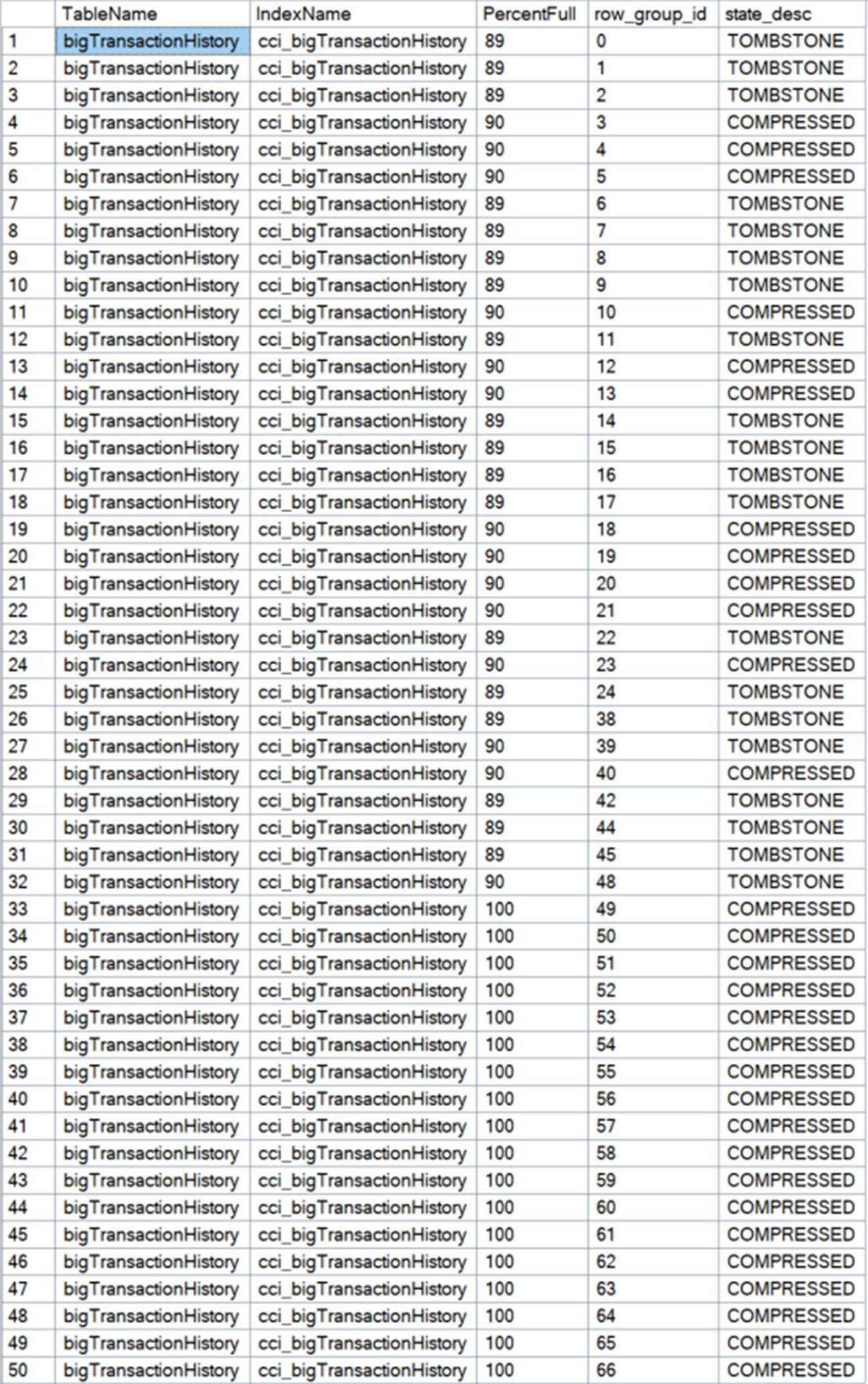
Figure 12-12: Results of REORGANIZE on dbo.bigTransactionHistory
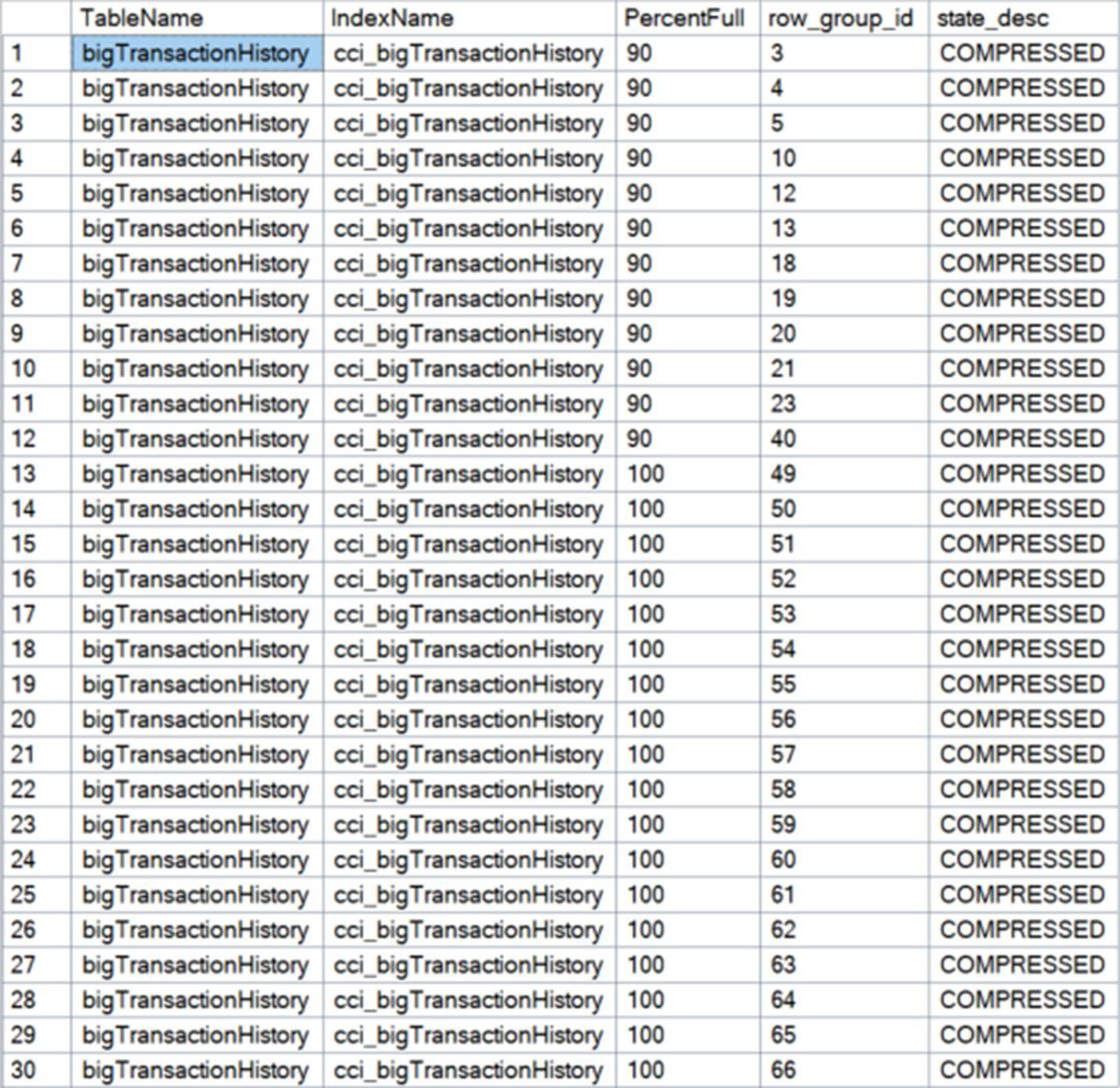
Figure 12-13: More defragmentation of the columnstore index
Fill Factor#
建索引時可指定 FILLFACTOR,留空間給未來的 INSERT / UPDATE,降低 page split 機率。
CREATE INDEX IX_Test ON dbo.MyTable (Col1) WITH (FILLFACTOR = 80);意義:每個 leaf page 只填 80%,留 20% 空間。

Figure 12-14: Fill factor set to the default value of 0

Figure 12-15: Fill factor set to 75

Figure 12-16: Fragmentation after new records

Figure 12-17: The number of pages goes up
Fill factor 是 空間換 split 成本 的取捨:
- 太小 → page 多 → 大範圍 scan I/O 增加
- 太大(接近 100)→ split 機率高
對 sequential key(如 IDENTITY)幾乎不需要 fill factor;對 random key(如 random GUID)才有意義。
自動化處理#
幾種典型方案:
- Ola Hallengren 的 Maintenance Solution:社群最常用,依碎片率分級處理
- SQL Server Agent Job + 自寫腳本:依
sys.dm_db_index_physical_stats結果決定 REBUILD / REORGANIZE - Azure SQL Database 的 Auto Tuning:自動處理建議
不論用哪一種,先量出哪幾條索引真的需要維護,再排頻率——對 99% 的索引可以「永遠不修」也沒影響。
本章定調#
- 碎片不是天敵:對小範圍查詢幾乎無感;大範圍 scan 才是受害者
- 修碎片的代價有時比放著不管更高
- Rowstore 用 page split / extent;columnstore 用 deltastore + logical delete
- 量測工具:
sys.dm_db_index_physical_stats/sys.column_store_row_groups - 處理工具:REBUILD / REORGANIZE,搭配適當 fill factor
- 以查詢實測為準,不要依賴老舊規則
下一章將進入 參數敏感查詢(Parameter Sensitive Queries)——同一條查詢、同一個計畫、不同參數值卻天差地別效能的問題。