本章主題#
延續第 9 章的索引基礎,本章深入更進階的行為與特殊類型:
- 覆蓋索引(covering index)
- 索引交集(index intersection)與索引連接(index join)
- 過濾索引(filtered index)
- 索引化檢視表(indexed view / materialized view)
- 索引特性(unique、ascending/descending、INCLUDE…)
- 特殊索引類型(spatial、XML、full-text、vector…)
覆蓋索引(Covering Index)#
涵蓋查詢所需所有欄位的 nonclustered index——優化器毋須回查 clustered index / heap 取資料。
Key vs. INCLUDE#
CREATE NONCLUSTERED INDEX IX_Address_StateProvinceID
ON Person.Address (StateProvinceID ASC)
INCLUDE (PostalCode)
WITH (DROP_EXISTING = ON);- 加入 key:欄位會排序、影響 B-Tree 結構,可用於
WHERE/JOIN/HAVING與ORDER BY - 加入 INCLUDE:只儲存在 leaf page,不能 用於過濾條件,但讓索引「覆蓋」更多欄位而不撐大 B-Tree
書中實測:對 Person.Address 加上 INCLUDE 後,SELECT PostalCode WHERE StateProvinceID = 42 從 19 reads / 316μs 降到 2 reads / 167μs。
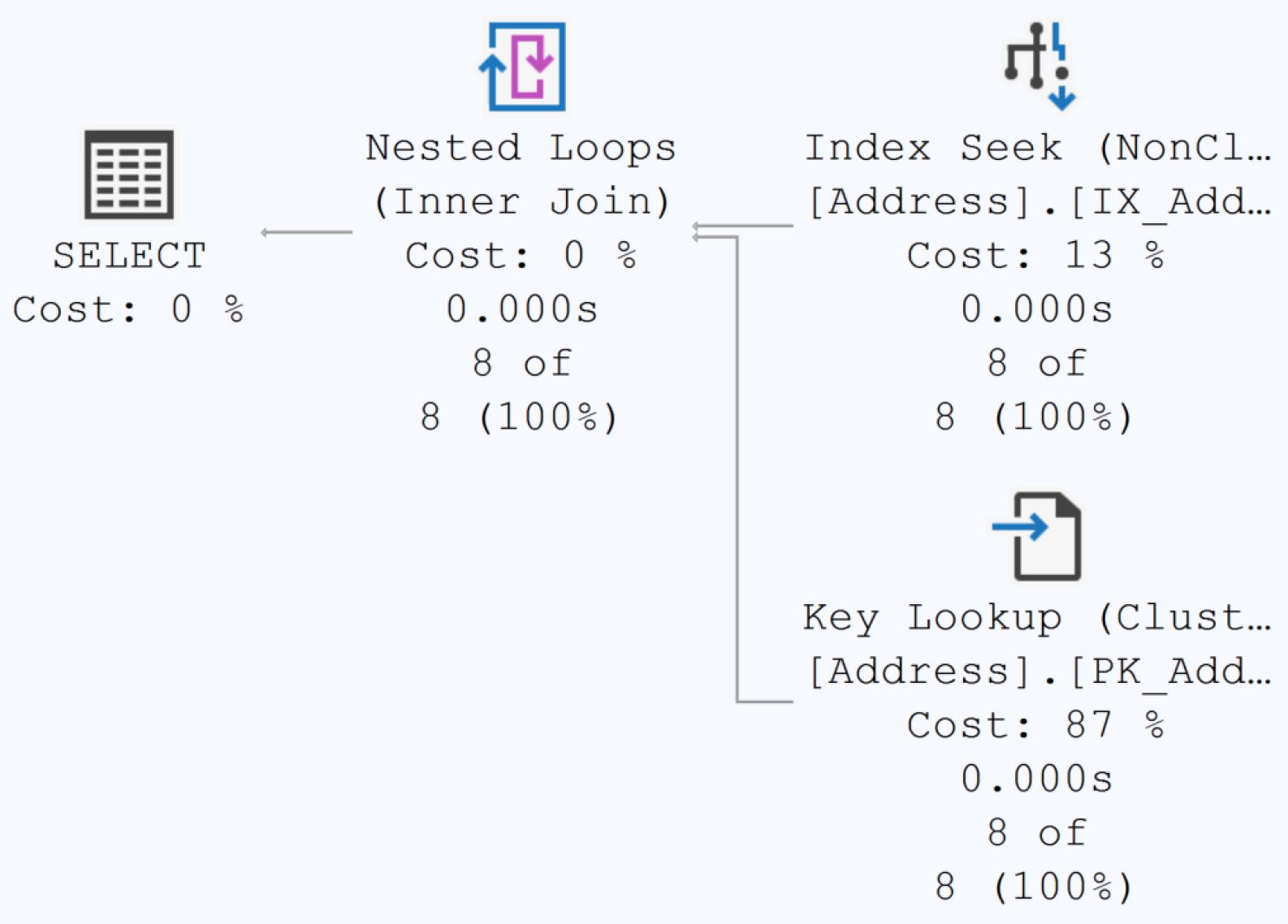
Figure 10-1: Execution plan for a query without a covering index

Figure 10-2: Execution plan for the query with a covering index
Pseudoclustered index:把所有欄位都 INCLUDE 進去,等同建第二個 clustered index。但每次 DML 都要更新兩份結構,維護成本可能極高。
反過來:若該欄位需做過濾或排序,加進 key 比 INCLUDE 更有用。
覆蓋索引的取捨#
- 加越多欄位 → 索引越胖 → page 裝得下的列越少 → I/O 增加
- 別把所有欄位都拉進來,根據查詢需要設計
Index Intersection#
當多個索引各覆蓋部分查詢條件時,優化器可同時使用兩條索引並合併結果。書中範例:
SELECT soh.SalesPersonID, soh.OrderDate
FROM Sales.SalesOrderHeader AS soh
WHERE soh.SalesPersonID = 276
AND soh.OrderDate BETWEEN '4/1/2013' AND '7/1/2013';- 無 OrderDate 索引:Clustered Index Scan,2.7ms / 686 reads
- 加上
IX(OrderDate)後:兩個 index seek + Hash Match,1.8ms / 10 reads - 改成複合索引
IX(SalesPersonID, OrderDate):直接 seek,165μs / 2 reads
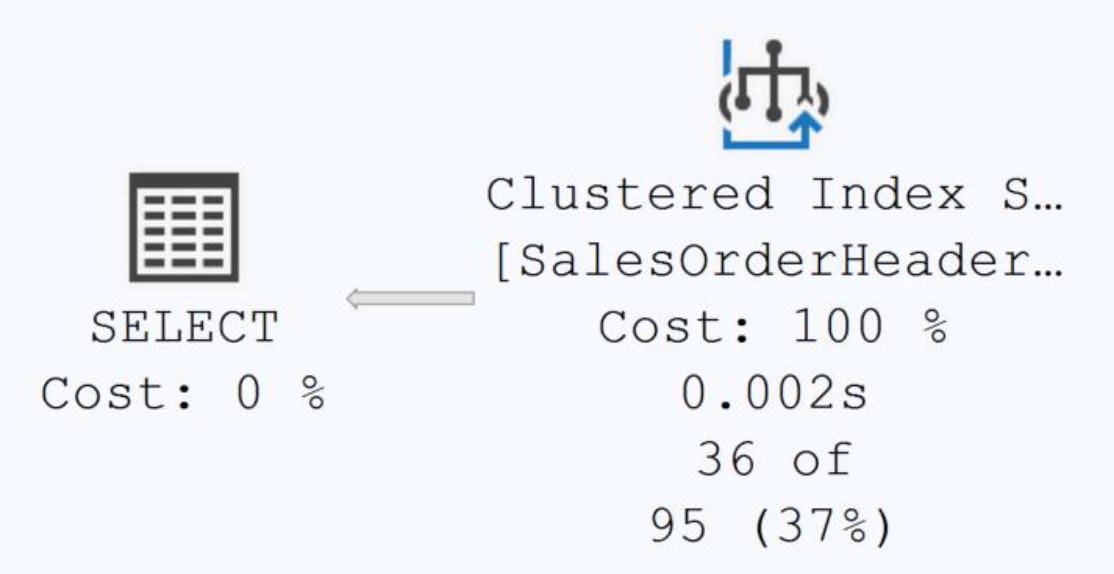
Figure 10-3: No indexes help the query, so a scan ensues

Figure 10-4: An index intersection

Figure 10-5: Replacing the index intersection
Index intersection 在實務中 罕見,且效率通常不如直接設計一條覆蓋的複合索引。看到 Hash Match 結合多個 index seek 時,先想想是否能用一條複合索引取代。
Index Join#
Index intersection 的近親——優化器把兩條索引透過 Nested Loops 或 Merge Join 接起來。
SELECT poh.PurchaseOrderID, poh.RevisionNumber
FROM Purchasing.PurchaseOrderHeader AS poh
WHERE poh.EmployeeID = 261
AND poh.VendorID = 1500;優化器各取一條 IX(EmployeeID) 與 IX(VendorID) 走 Index Seek + Merge Join。但因 RevisionNumber 沒被任何索引涵蓋,會多一個 Key Lookup 回 clustered index 拿值。
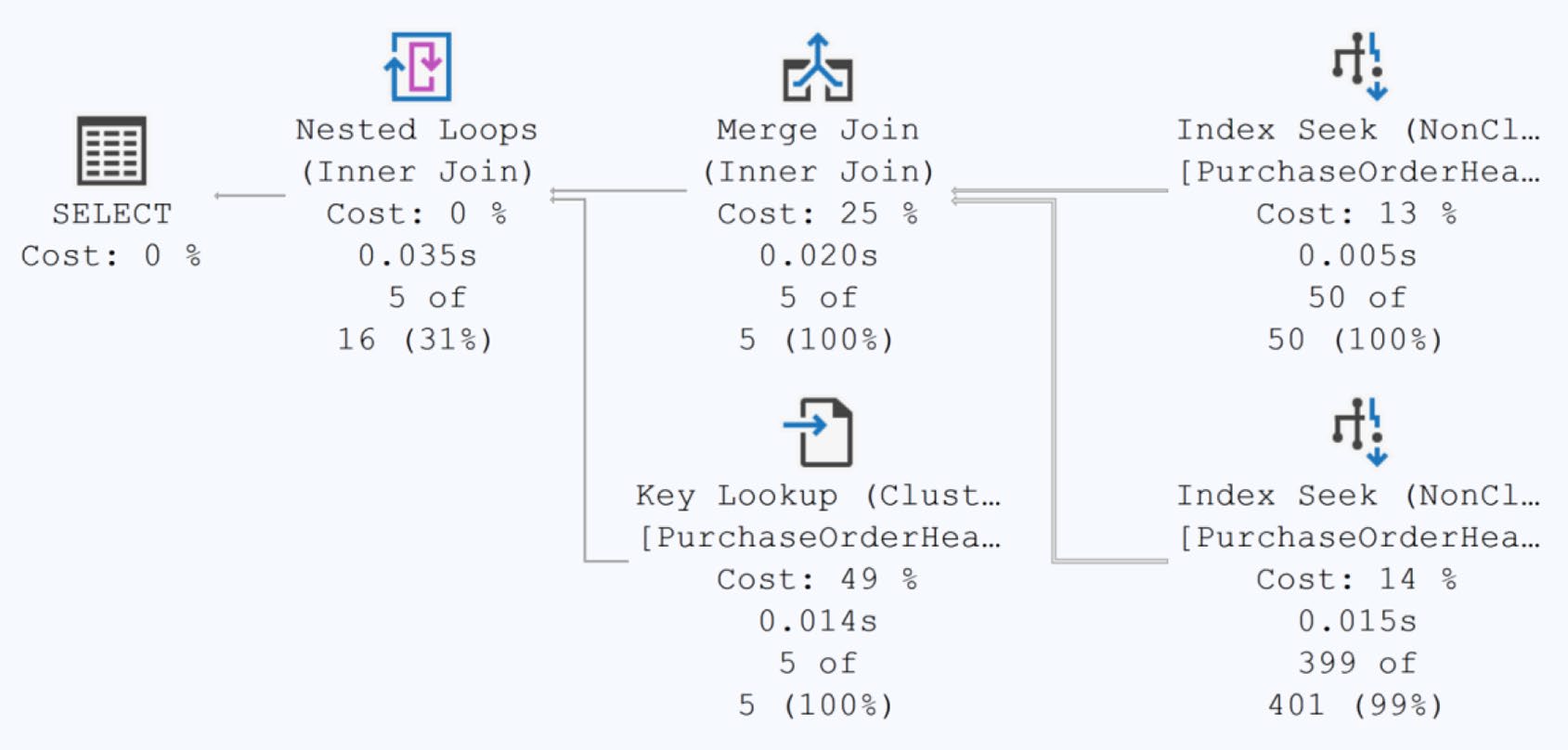
Figure 10-6: An index join
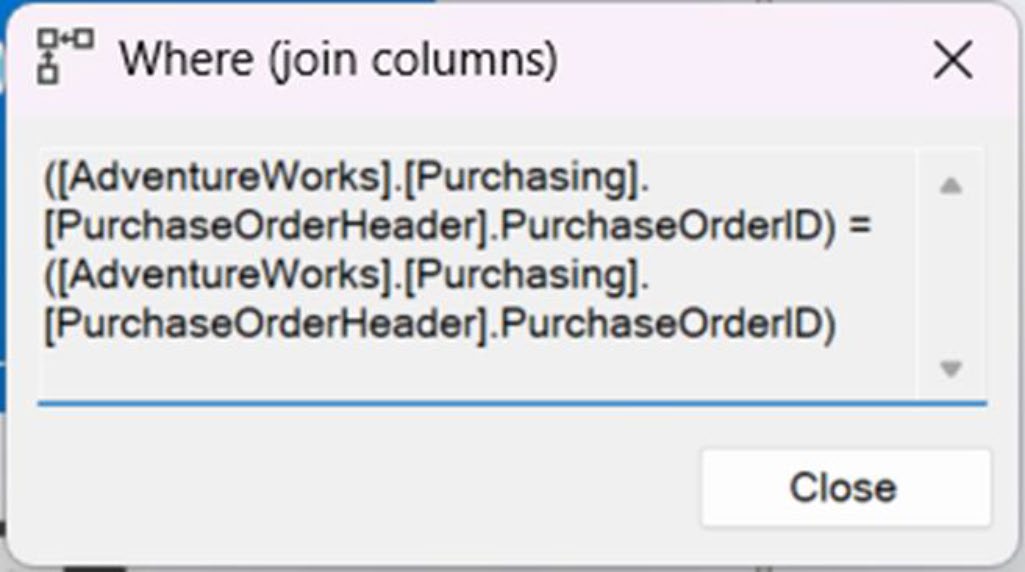
Figure 10-7: Join criteria in the Where (join columns) property
Index join 與 index intersection 的差異:
- Intersection:用 Hash Match 結合,兩索引 必須 構成覆蓋
- Join:用 Nested Loops 或 Merge Join,可容許 lookup
兩者都是 較窄索引、彈性組合 的設計選擇——當無法把所有欄位塞進一條索引時的折衷方案。
Filtered Index(過濾索引)#
帶 WHERE 子句的 nonclustered rowstore index——只索引符合條件的子集。
CREATE NONCLUSTERED INDEX IX_Test
ON Sales.SalesOrderHeader
(
PurchaseOrderNumber,
SalesPersonID
)
INCLUDE (OrderDate, ShipDate)
WHERE PurchaseOrderNumber IS NOT NULL
AND SalesPersonID IS NOT NULL;適用情境#
- 大量 NULL 的欄位(用
IS NOT NULL過濾掉) - 經常存取的特定子集(例如「活躍用戶」、「未結案訂單」)
- 比 indexed view 簡單、維護負擔較低
書中對 30,000 列、其中 27,000+ NULL 的 SalesOrderHeader 測試,過濾掉 NULL 後從 533μs / 5 reads 進一步降到 317μs / 4 reads。
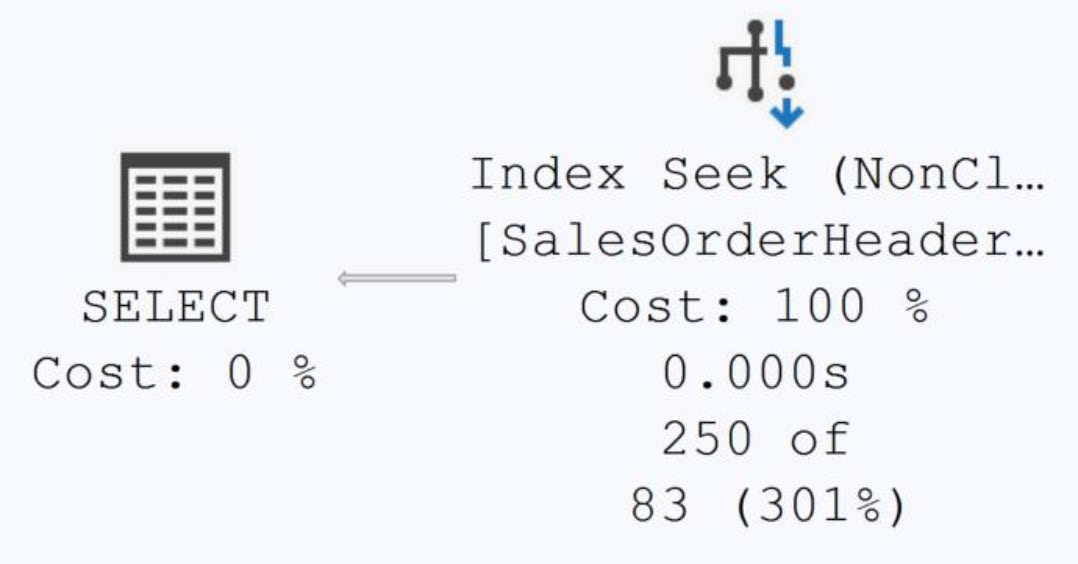
Figure 10-8: The scan is gone, and an index seek is operating
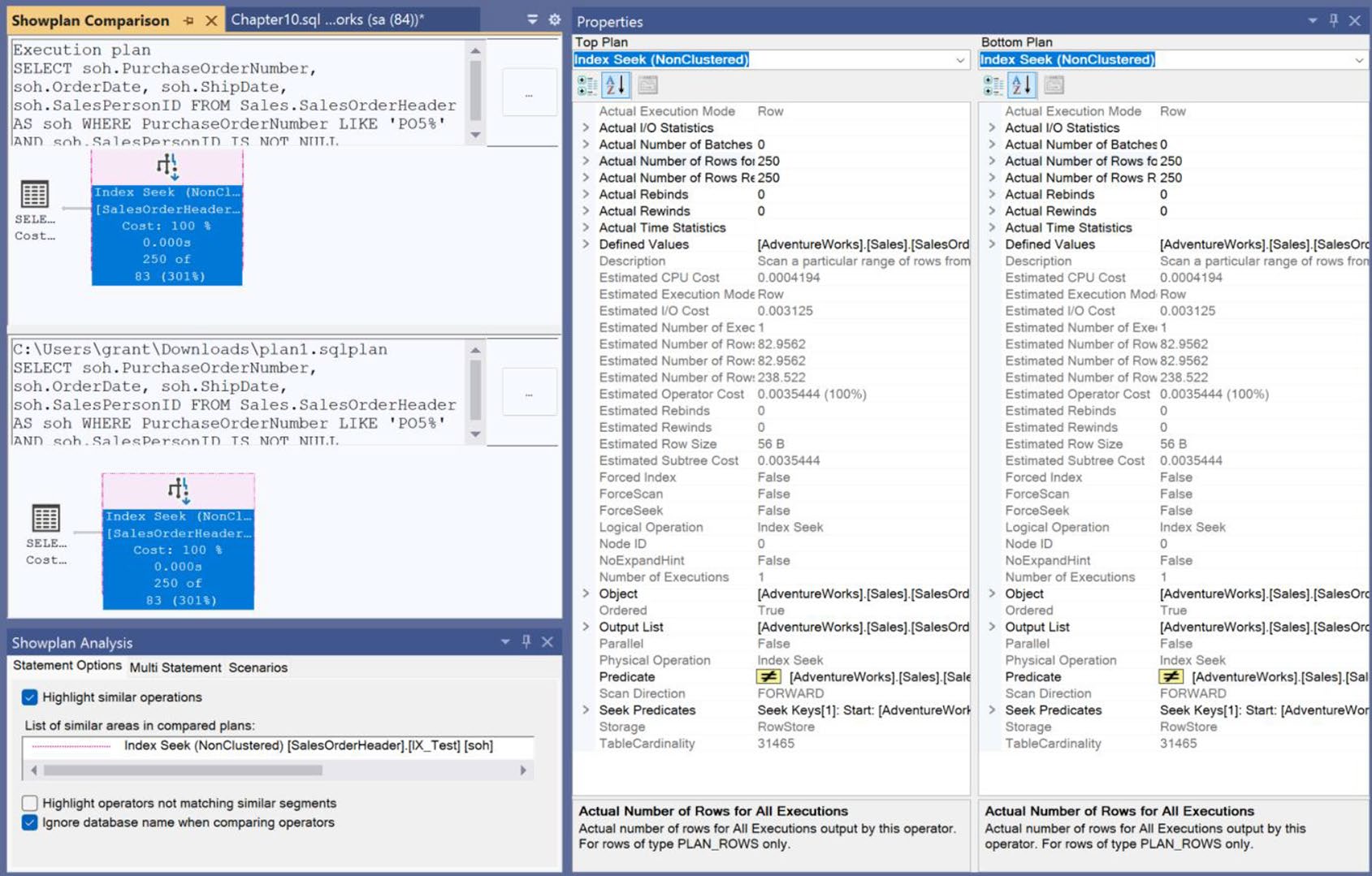
Figure 10-9: Comparison between two nearly identical execution plans
限制與注意#
- 必須有特定 SET 選項:
- ON:
ANSI_NULLS、ANSI_PADDING、ANSI_WARNINGS、ARITHABORT、CONCAT_NULL_YIELDS_NULL、QUOTED_IDENTIFIER - OFF:
NUMERIC_ROUNDABORT
- ON:
- 參數化查詢的 WHERE 條件如果跟 filter 不完全吻合,索引就用不到
- 統計資訊仍以整表為基礎,不是只統計過濾後的子集
Indexed View(索引化檢視表)#
普通 view 只是儲存的 SELECT 語句、不存資料。indexed view(materialized view)則:
- 在 view 上建一個 unique clustered index
- 結果集 持久化 到磁碟,等同一張表
- 之上還可建 nonclustered index
好處#
- 可預先計算 aggregation
- 可預先做 join,省去執行時計算
- 對 reporting / analysis 工作量特別有效
代價與限制#
- 底層表變動 → indexed view 必須同步更新(寫入成本顯著上升)
- 額外儲存
- 必須是 deterministic(同樣輸入永遠同樣結果)的查詢
- 必須 schema bound 到底層表——表的結構不能再改
- 必須先建 unique clustered index 才能再建 nonclustered
- 只能引用同資料庫的 base table,不能引用其他 view
Enterprise / Developer Edition 才有「自動 view matching」——優化器即使沒寫 view 名稱,也能自動利用 indexed view。其他版本必須在程式碼中明確 reference view 名稱。
對於分析型工作,columnstore index 通常比 indexed view 更划算。indexed view 仍是工具箱裡的一員,但不是首選。
OLTP 系統若頻繁寫入 base table,indexed view 的更新成本可能毀掉整體效能。先估算「節省的查詢時間 vs. 多付的寫入成本」。

Figure 10-10: The use of an indexed view in a query
索引特性#
Unique Index#
- 唯一索引讓優化器知道「最多只匹配一列」——大幅改善 join、search 的計畫品質
- 唯一性違反時 INSERT / UPDATE 會失敗——同時也是資料完整性保證
Ascending vs. Descending Key#
key 預設 ASC。若查詢 ORDER BY col DESC,且常用,可指定 DESC 避免 Sort 運算子。
複合索引欄位順序#
- 高選擇性欄位放前面(histogram 在首欄才有效)
- 多查詢共用時,看哪個欄位最常用於等值過濾
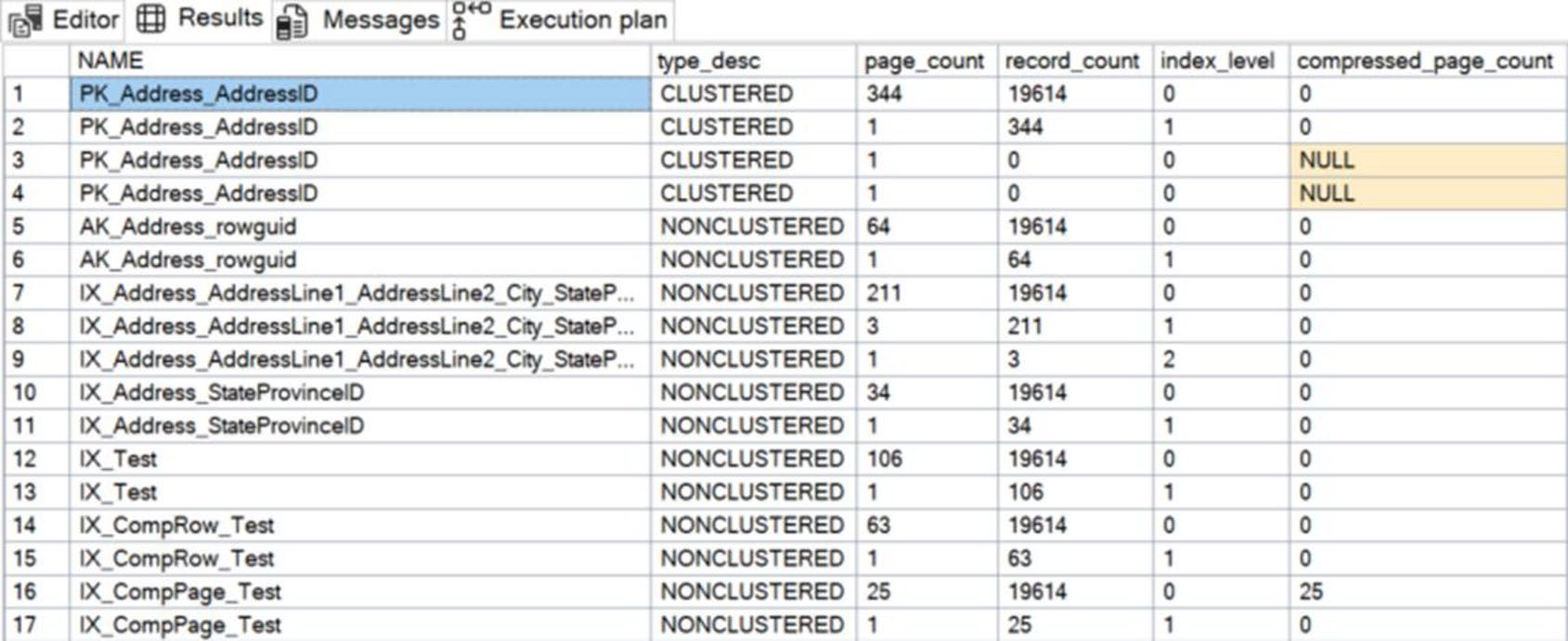
Figure 10-11: Pages being used by indexes on the Address table

Figure 10-12: The execution plan for a CREATE INDEX statement
特殊索引類型#
Spatial Index#
針對 geometry、geography 資料型別。SQL Server 把空間切成多層 grid 加速範圍 / 鄰近查詢。
XML Index#
針對 xml 資料型別。需先建 primary XML index,可選擇性再建 path / value / property secondary index。維護成本高,僅在大量 XML 路徑查詢時才考慮。
Full-Text Index#
由 SQL Server full-text engine 維護,支援自然語言搜尋(CONTAINS、FREETEXT)。
Vector Index(SQL Server 2025)#
針對 AI 應用的向量資料型別,加速向量相似度搜尋——用於 RAG、語意搜尋等場景。
Hash / Memory-Optimized Nonclustered#
僅用於 memory-optimized table,第 19 章詳述。
本章定調#
- 覆蓋索引把 Key Lookup 拿掉,是 OLTP 最常見的優化手段
- Index intersection / join 是「無法改現有索引時的折衷」,首選仍是設計合適的複合索引
- Filtered index 對「大量 NULL」「特定子集」有效,且比 indexed view 輕量
- Indexed view 適合分析型;OLTP 寫入頻繁時要謹慎
- 特殊索引類型對應特殊資料;不要為了用而用
下一章將深入 Key Lookup——這個常見的執行計畫運算子如何形成、如何透過索引設計消滅它。