為什麼索引這麼重要#
正確的索引可能是 SQL Server 中 單一影響最大 的效能調校手段。從 SQL Server 2016 開始,我們有兩種主要的儲存模型:
- Rowstore(傳統列式儲存)
- Columnstore(欄式儲存)
兩者各有 clustered 與 nonclustered 兩種形式,可混用:在 clustered columnstore 上加 nonclustered rowstore,或在 clustered rowstore 上加 nonclustered columnstore。
索引到底是什麼#
書本後面的索引是個好類比——你想找「deadlock」,不必翻過每一頁,從索引就能直接定位。
SQL Server 中也有兩種設計:
- Clustered index:把整張表 依鍵值排序儲存——資料本身就是索引;每張表只能有一個
- Nonclustered index:另外建一份排序好的鍵值,指回原始資料(指回 clustered key 或 heap 的 RID)
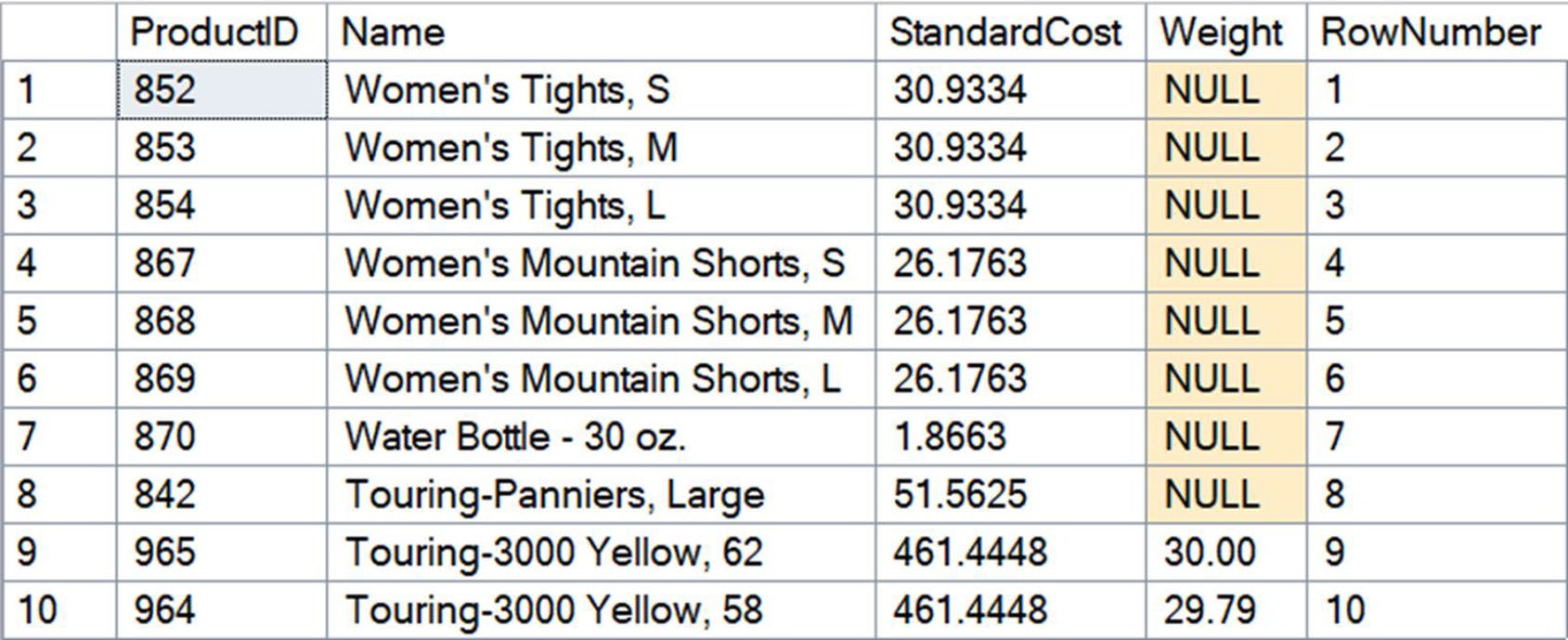
Figure 9-1: Data ordered and numbered by Product.Name
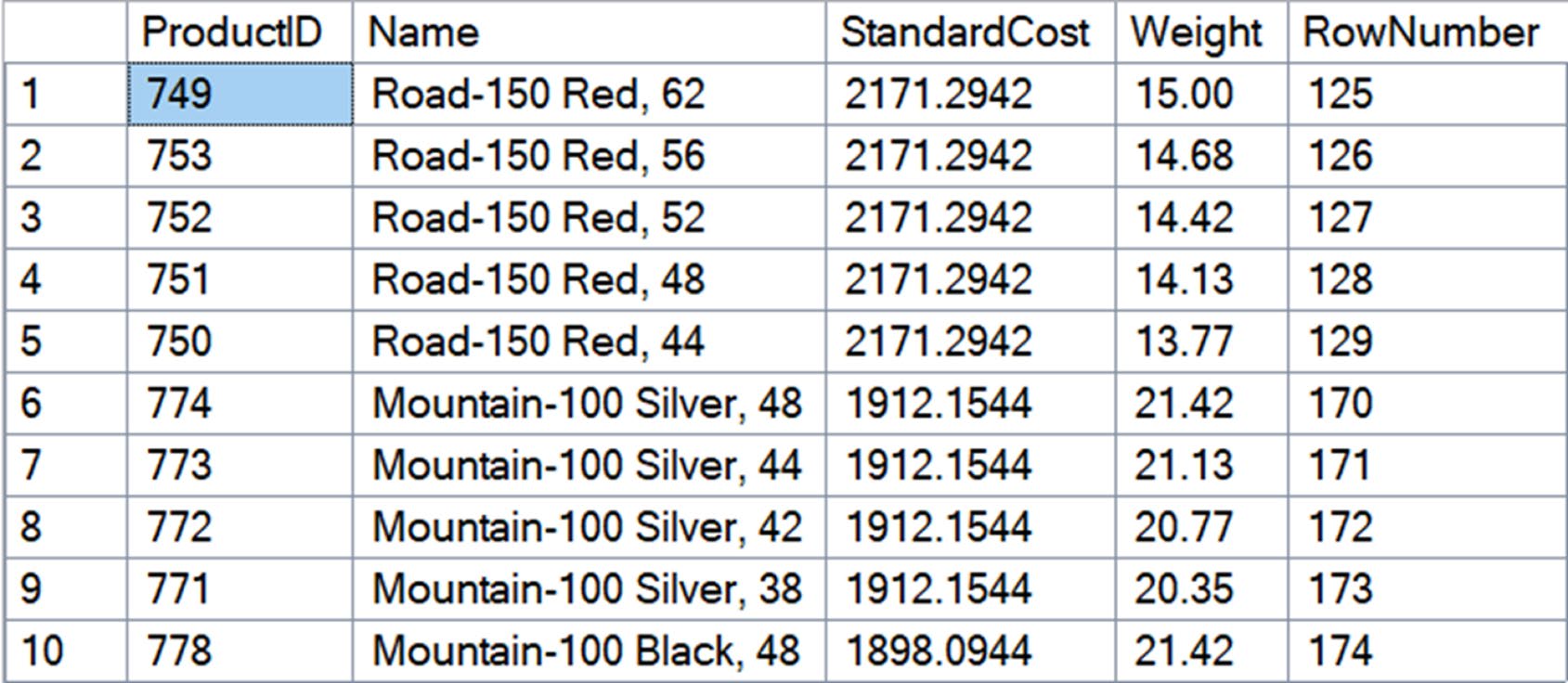
Figure 9-2: Data reordered by StandardCost
SQL Server 的整套儲存引擎是圍繞 clustered index 設計的。clustered index 的選擇是最重要的索引決策。
Heap:沒有 clustered index 的表#
沒有 clustered index 的表稱為 heap。
- 資料無序儲存,由 RID(row identifier)定位
- 任何搜尋都需 table scan——逐列讀
- 比 clustered index 表更難維護、Fragmentation 處理也更麻煩
Rowstore B-Tree 結構#
所有 rowstore 索引都以 B-Tree(balanced tree) 形式儲存:
- Root node:起始頁
- Branch nodes(intermediate):中介頁
- Leaf nodes:實際存放資料 / 鍵值的頁
SQL Server 的最小 I/O 單位是 8KB page。B-Tree 的目標是讓任何一筆資料在 少數幾次 page 讀取 內找到。
例如 27 列資料分散在 9 個 page:
- 無索引:scan 9 頁
- 有索引但只是排序:找到後仍要再判斷邊界,最壞 9 頁
- B-Tree:root → branch → leaf,3 頁 即達

Figure 9-3: Twenty-seven rows in a random order stored in pages

Figure 9-4: Twenty-seven rows stored in sorted order on the pages

Figure 9-5: Twenty-seven rows stored in a B-Tree
leaf nodes 之間是 doubly linked list——範圍掃描時不用回頭爬 root,可直接相鄰移動。
索引的好處與成本#
好處#
- 排序好的儲存讓搜尋更快
- nonclustered index 欄位窄,每頁裝得下更多列,I/O 更省
- nonclustered index 可放在不同磁碟,加速搜尋
- B-Tree 把可能的 page 讀取降到對數級
成本#
- 儲存與記憶體成本增加
- DML 變慢:INSERT / UPDATE / DELETE 必須同步維護所有受影響索引
- 索引太多時,data modification 可能比沒索引更慢
但別忘了:UPDATE / DELETE 自己也要先「找到那一列」。一條好的索引能讓 找列 變快——常常 抵消 維護成本,甚至比沒索引還快。
書中實測:對 10,000 列表執行
UPDATE WHERE C2 = 1:
- heap:29 reads
- 加 clustered index 但
C2上無索引:42 reads(變多——資料要重排)- 再加
C2上的 nonclustered index:15 reads(最少)
觀察索引行為的 DMV#
sys.dm_db_operational_stats:鎖、I/O 等操作行為sys.dm_db_index_usage_stats:累積使用次數,看哪些索引從沒人用過
量測時若同時開 STATISTICS IO 與 TIME,IO 的擷取與傳輸會干擾 TIME 的精度。多數情況用 Extended Events 即可,需要物件層級 I/O 才用 STATISTICS IO。
Columnstore:欄式儲存#
把資料 依欄而非依列 儲存,主要為 分析型查詢(aggregation、count、scan-heavy)設計。
為什麼快#
- 大量 aggregation 不需把整列讀進來
- 只挑需要的欄位讀(不必載入整列)
- 預設壓縮儲存——磁碟 / 記憶體都更省
兩種形式#
- Clustered columnstore index:整張表的資料儲存形式
- Nonclustered columnstore index:另加在 heap 或 rowstore clustered index 上
限制#
- 不支援 binary、
text、varchar(MAX)、CLR、XML 等型別 - 不能建在 sparse column 上
- 有 clustered columnstore 的表 不能有 constraints(含 PK / FK)
- SQL Server 2016 前 nonclustered columnstore 不可更新
內部結構#
- 不是 B-Tree
- 資料以 rowgroup(約 102,400 列)為單位 pivoted、壓縮後儲存
- 修改 / 新增進來的列先收進 deltastore(內部 B-Tree),到 102,400 列再壓進新的 rowgroup
- 刪除列不會立即移除,而是另一個內部 B-Tree 標記 deleted;rebuild / reorganize 時才實體清除
純 batch load 時 deltastore 幾乎用不到。但若是 nonclustered columnstore 在 rowstore 表上、或頻繁小批量更新,就該定期 rebuild 來壓縮 rowgroup 並清掉刪除標記。
Columnstore 對 小資料量 反而沒優勢。一般建議 超過 100,000 列 才看得到明顯收益。
以及:columnstore 對 single-row lookup / 小範圍查詢 顯著比 rowstore 慢——OLTP 主路徑不該用 columnstore。

Figure 9-18: Execution plan for an aggregate query without columnstore indexes
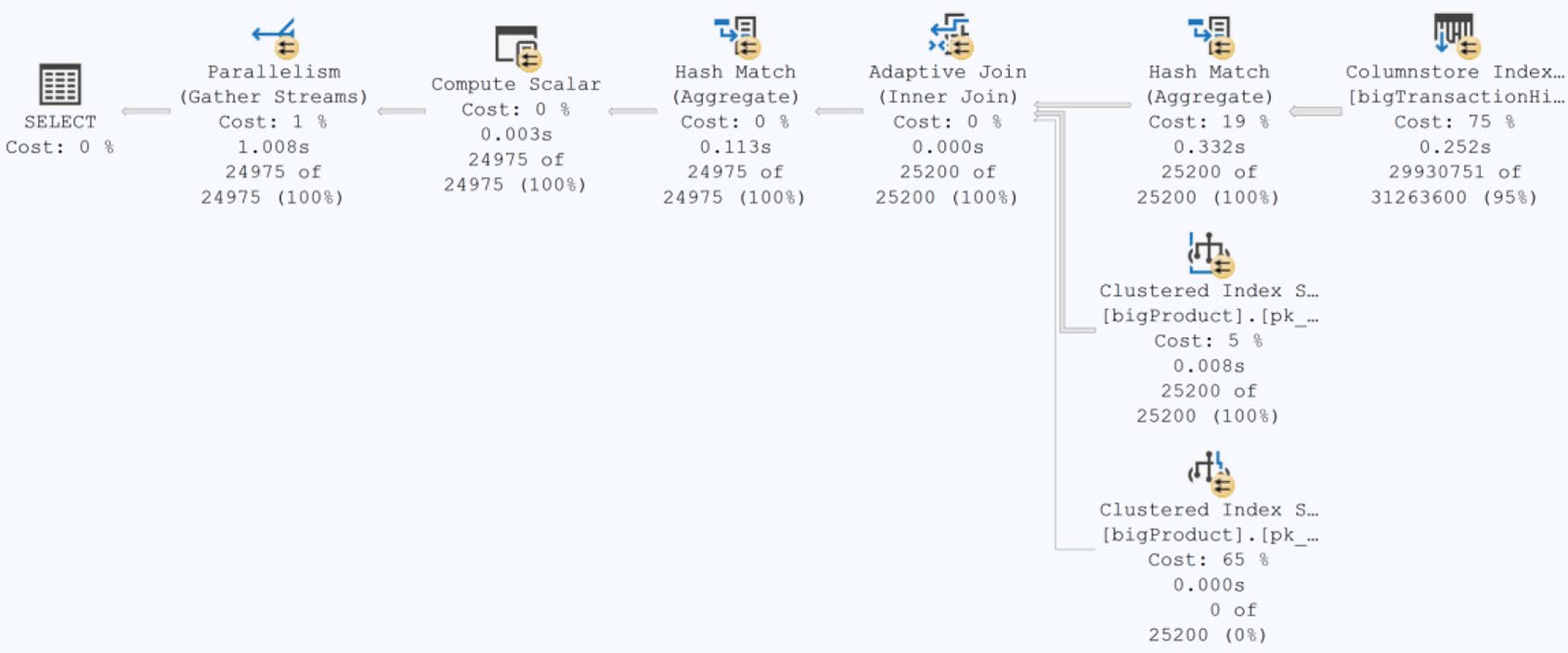
Figure 9-19: Columnstore indexes in an execution plan

Figure 9-20: Columnstore Index Scan of bigTransactionHistory
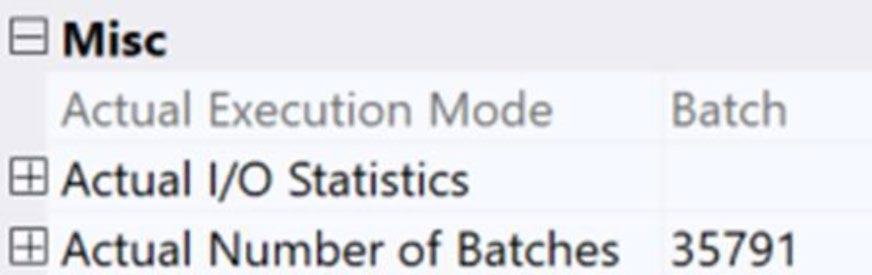
Figure 9-21: Batch-mode processing and the number of batches

Figure 9-22: Showing the Locally Aggregated Rows
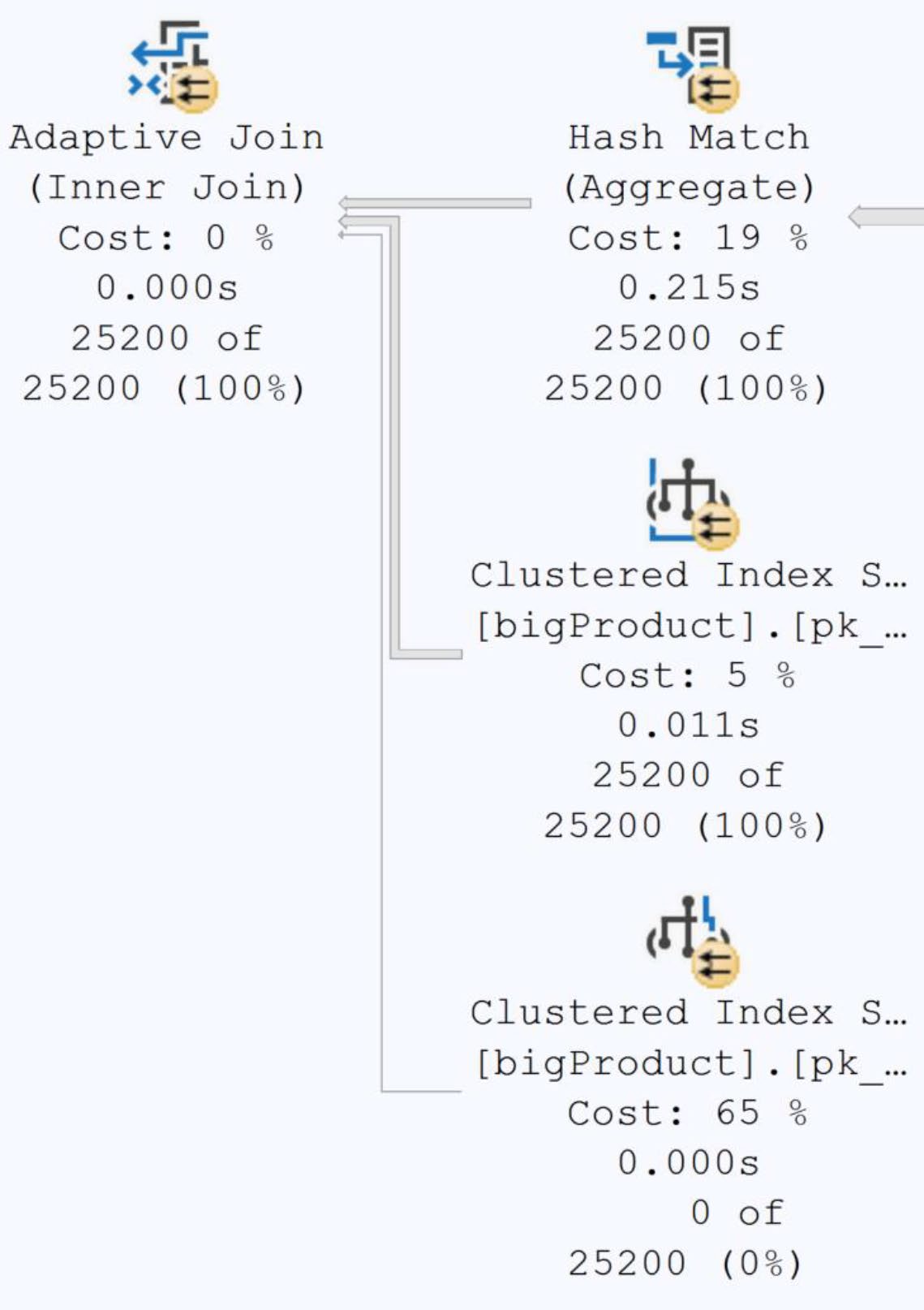
Figure 9-23: The Adaptive Join operator
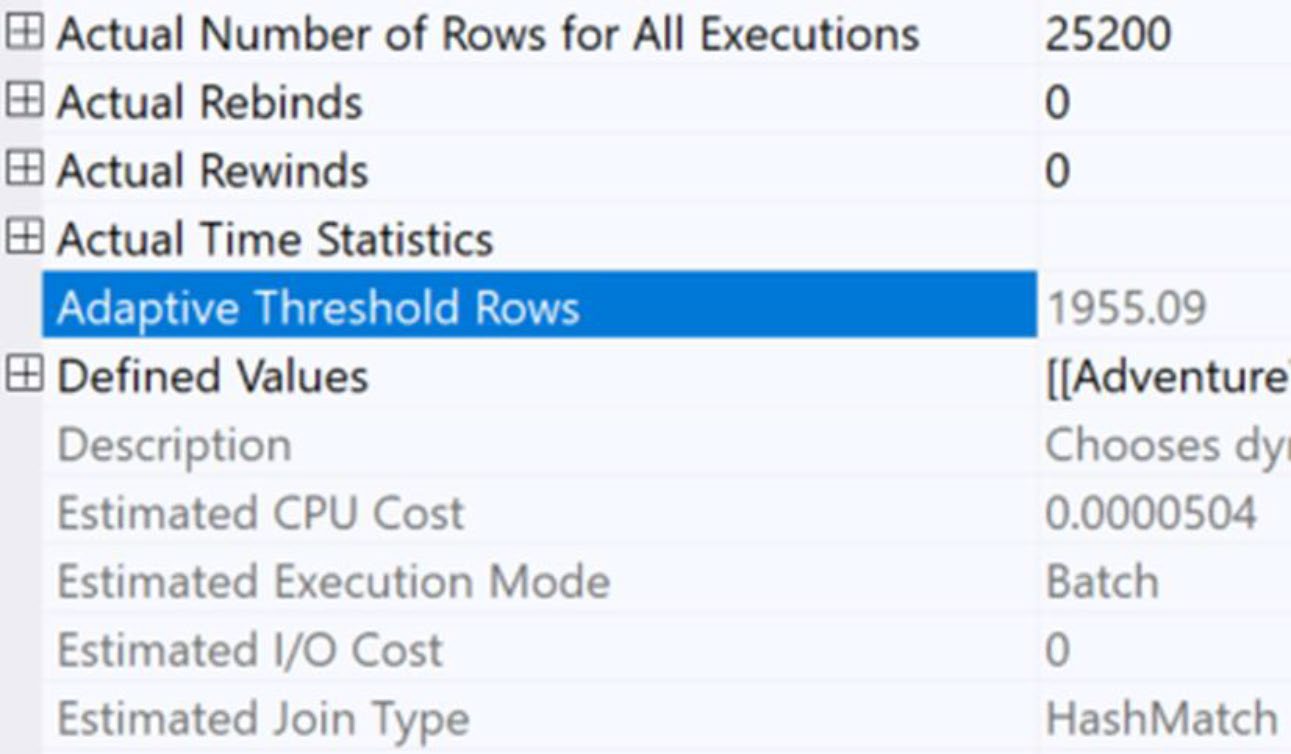
Figure 9-24: Properties of the Adaptive Join operator
索引設計建議#
Fritchey 列出八項考量:
- 查詢處理類型(OLTP vs. analytical)
- 過濾條件
- 使用窄索引(narrow)
- 資料的選擇性(selectivity)
- 資料型別
- 欄位順序
- 資料儲存方式
- 必要時 詢問 AI
1. 依查詢類型決定主索引#
- 主要 OLTP(point lookup、小範圍 scan)→ rowstore clustered
- 主要 analytical(aggregation 為主)→ columnstore clustered
- 之後再依需要疊加另一種類型的 nonclustered index
2. 過濾條件決定索引價值#
優化器選擇索引的流程:
- 找出 WHERE / JOIN / HAVING 中用到的欄位
- 找出這些欄位上的索引
- 用統計算選擇性(會回多少列)
- 沒索引的欄位另尋自動建立的統計
- 評估 constraints(FK、check constraint)
- 算出最便宜的取得方式
無 WHERE 子句的查詢:必然是 Clustered Index Scan / table scan。加上一個高選擇性的 WHERE 條件後,計畫會切換成 Index Seek——書中實測 reads 從 15 降到 2、執行時間 534μs → 132μs。
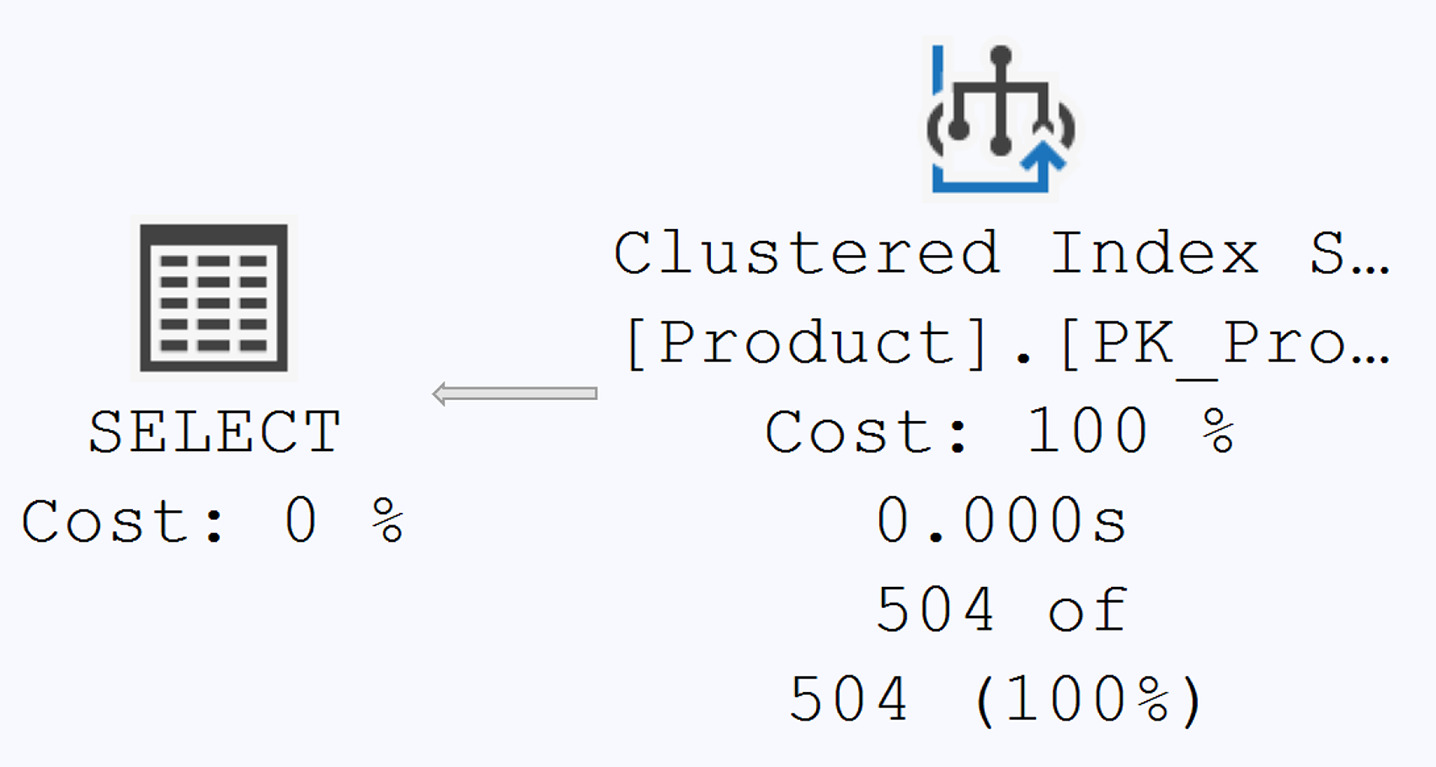
Figure 9-6: A Clustered Index Scan to retrieve all data
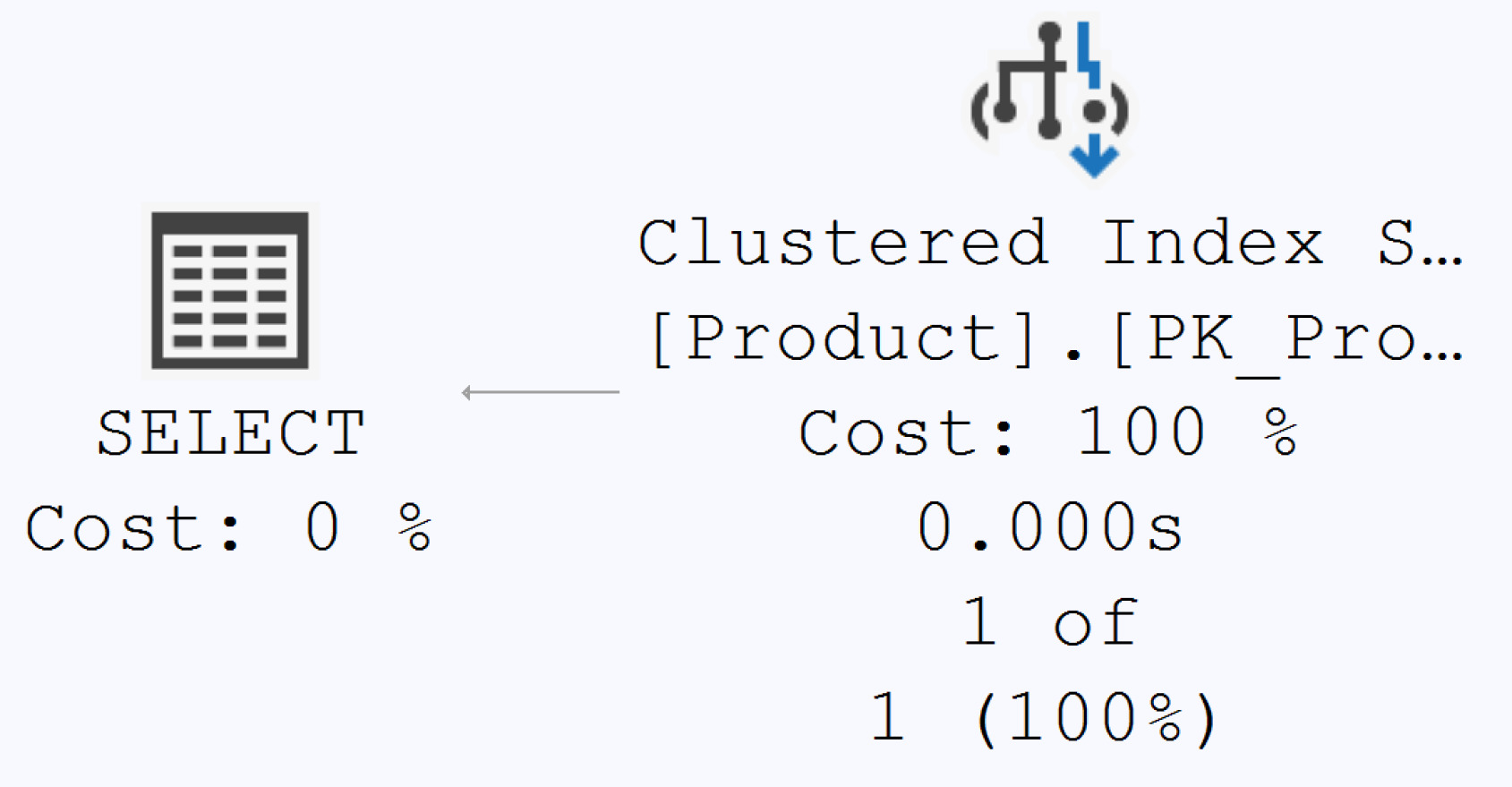
Figure 9-7: A Clustered Index Seek because of the WHERE clause
3. 用窄索引#
「窄」指 資料型別小:INT(4 bytes)比 VARCHAR(50) 窄、比 CHAR(500) 窄太多。
- 8KB page 裡可放更多列 → I/O 更少
- 更好的快取行為
書中對 20 列的測試表:INT key 索引只佔 1 個 page;改成 CHAR(500) 後變多頁。

Figure 9-8: Number of pages for a narrow index

Figure 9-9: Number of pages for a wider index
若必須用寬欄做索引,可考慮加一個窄的 surrogate key 欄位(例如 INT IDENTITY)並在它上面建索引——犧牲少量空間換查詢效能。
4. 選擇性(Selectivity)#
選擇性 = DISTINCT 值 / 總列數。越接近 1 越好。
SELECT COUNT(DISTINCT E.MaritalStatus) AS DistinctColValues,
COUNT(E.MaritalStatus) AS NumberOfRows,
(CAST(COUNT(DISTINCT E.MaritalStatus) AS DECIMAL)
/ CAST(COUNT(E.MaritalStatus) AS DECIMAL)) AS Selectivity,
(1.0 / COUNT(DISTINCT E.MaritalStatus)) AS Density
FROM HumanResources.Employee AS E;例:MaritalStatus 只有 ‘M’ / ‘S’,選擇性極低。單獨在它上面建索引,優化器寧可選 Clustered Index Scan。
5. 鍵值順序與覆蓋(Covering)#
書中經典範例:查 WHERE MaritalStatus = 'M' AND BirthDate = '1982-02-11'。
| 索引 | 行為 | 結果 |
|---|---|---|
IX(MaritalStatus) | Clustered Index Scan | 9 reads, 336μs |
強制走 IX(MaritalStatus) | Index Seek + Key Lookup | 294 reads, 466μs(更慢) |
IX(BirthDate, MaritalStatus) | Index 直接覆蓋 | 2 reads, 211μs |
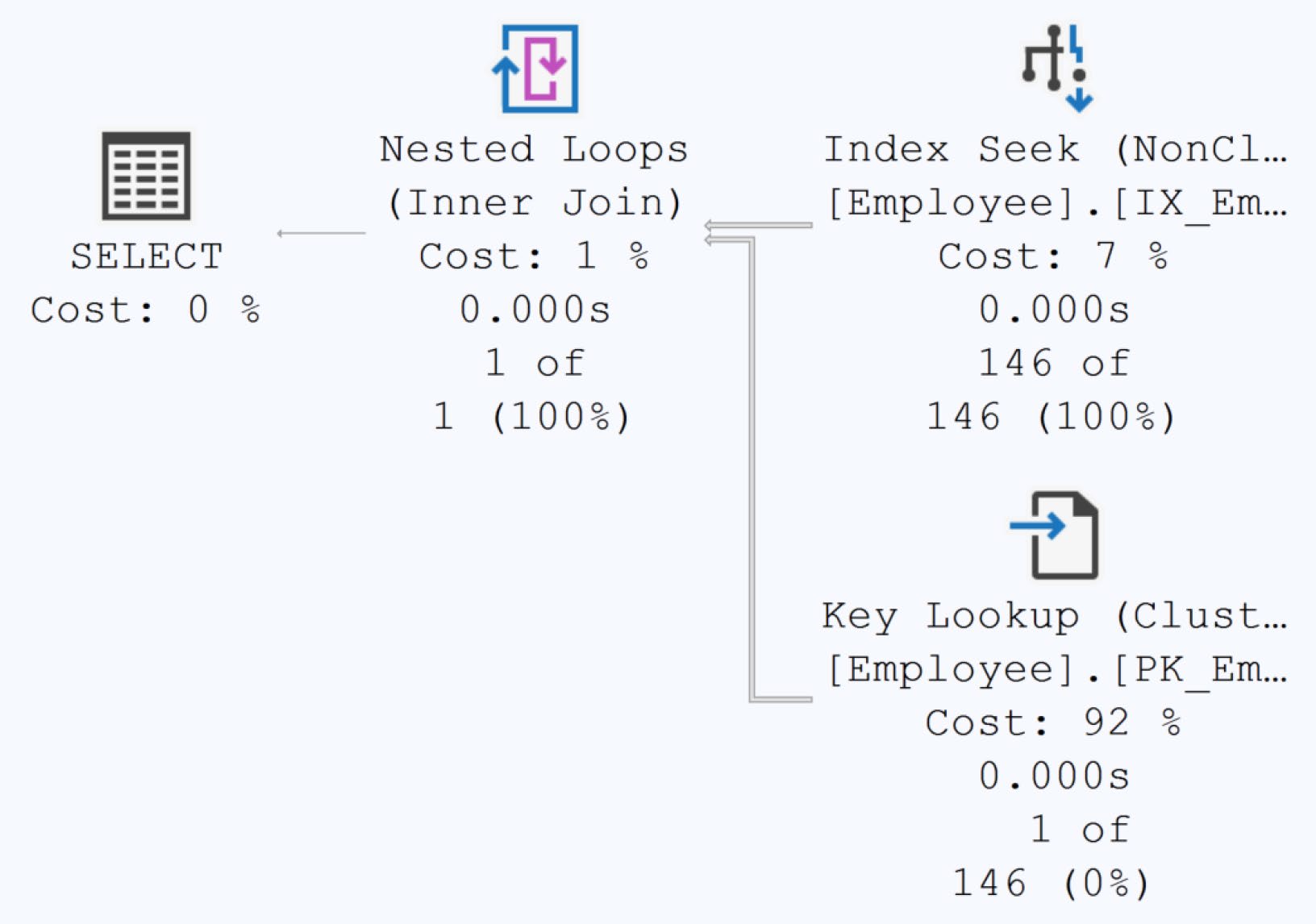
Figure 9-10: Forcing an index seek
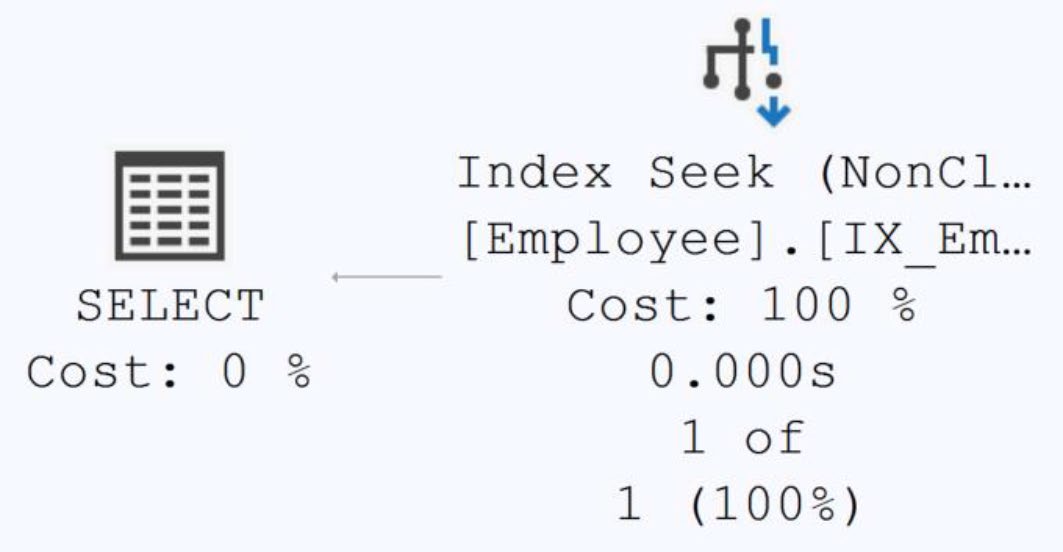
Figure 9-11: Index is now covering the query

Figure 9-12: Execution plan that can use the index created
Figure 9-13: The index could not be fully used

Figure 9-14: An RID lookup is needed to satisfy the query
選擇性高的欄位放前面。複合索引的順序決定首欄 histogram 的有效性。
把整個查詢需要的欄位都加到索引裡(key 或 INCLUDE),就形成 覆蓋索引(covering index)——免去回查 clustered index 的 Key Lookup(第 11 章)。
6. 資料型別#
int、bigint、datetime 等明確型別比 nvarchar、varchar(MAX) 等更適合做索引。
把日期 / 數字存成字串會讓索引能力大打折扣,並出現大量隱式型別轉換警告。

Figure 9-16: The size of indexes with a narrow key

Figure 9-17: Wider indexes mean more pages
7. AI 輔助#
新版內容指出:可請 AI 協助評估索引建議。但仍需以實測驗證——AI 幻覺與不了解你的工作負載是真實風險。
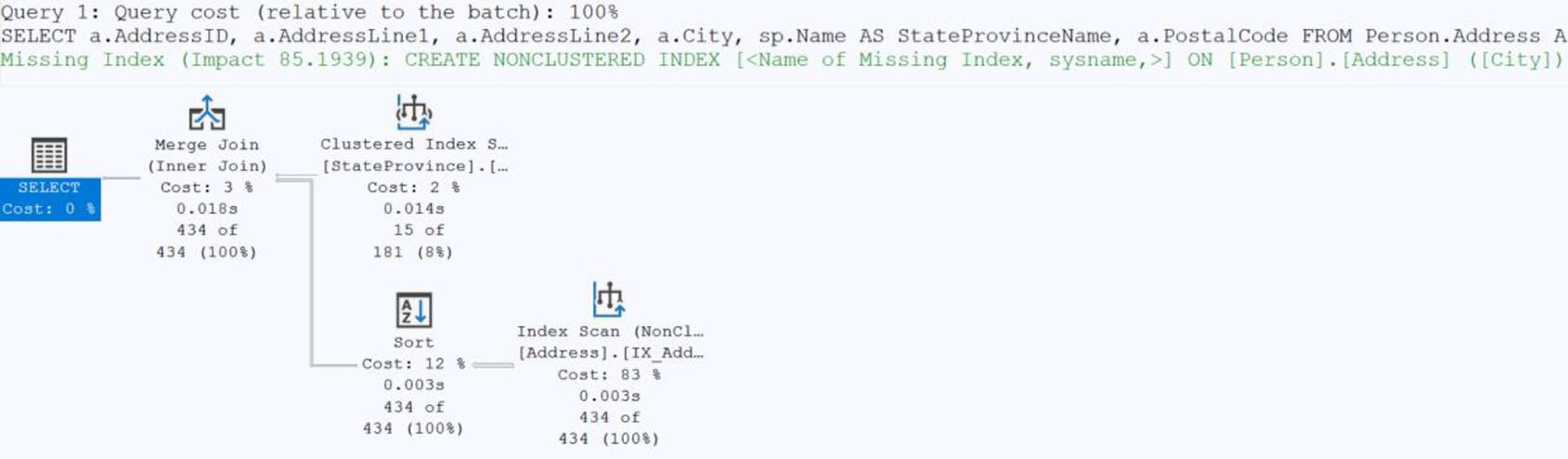
Figure 9-25: An execution plan with a Missing Index suggestion
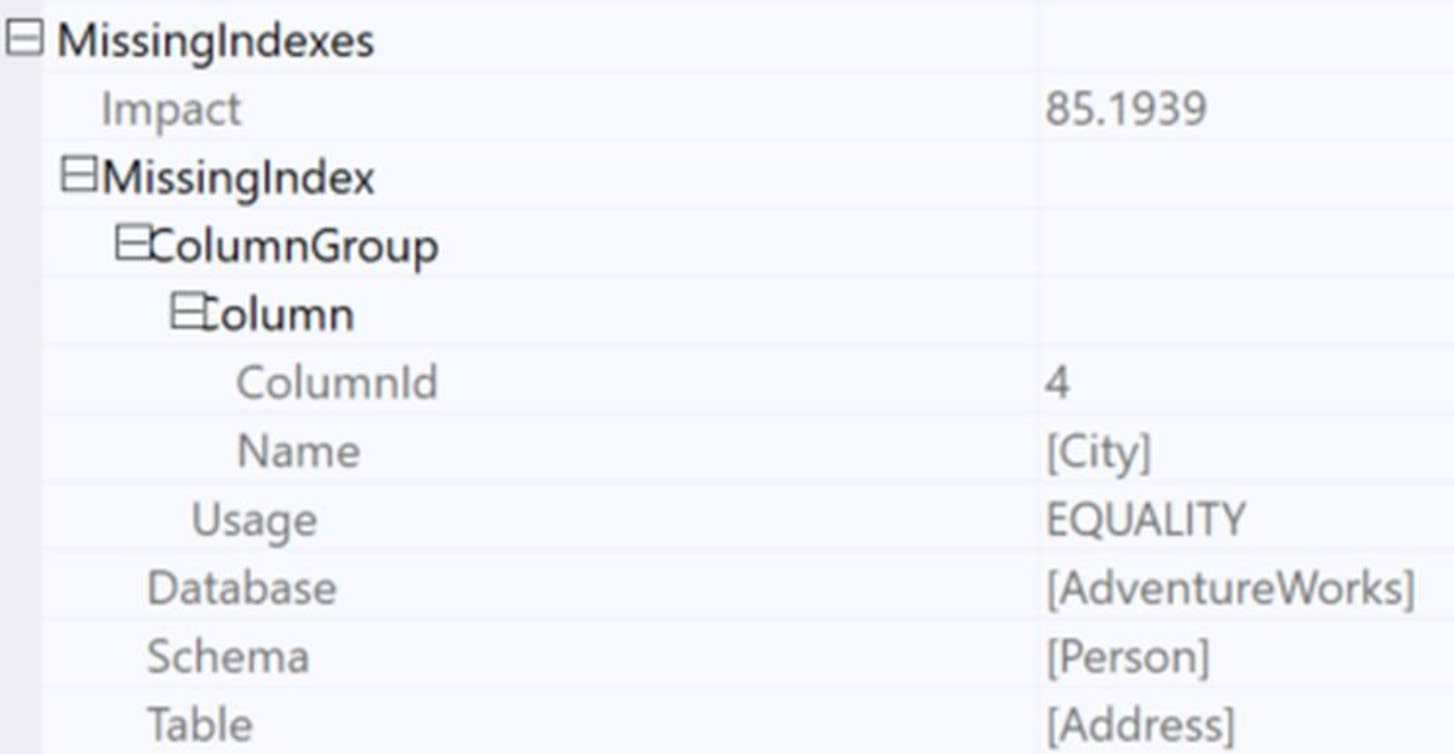
Figure 9-26: The Missing Index properties in an execution plan
其他索引類型(Chapter 10 / 19 探討)#
- Hash、Memory-Optimized Nonclustered:記憶體最佳化表 → 第 19 章
- Spatial、XML、Full-Text、Vector Index:特殊資料 → 第 10 章
本章定調#
- 對的索引省 90% 的事;錯的索引讓 DML 變慢、讓查詢更糟
- Clustered index 的選擇是最重要的索引決策
- B-Tree 把搜尋成本壓到對數級;columnstore 把分析型 aggregation 壓到極致
- 優先決定主儲存(rowstore vs. columnstore),再用對方類型的 nonclustered 補強
- 設計索引時:對的型別、夠窄、選擇性高、鍵值順序合理、覆蓋必要欄位
下一章將深入 索引行為——含 unique、filtered、partitioned、INCLUDE、各種特殊索引。