為什麼計畫快取重要#
優化過程很貴。SQL Server 把產出的執行計畫保留在記憶體中——這塊空間就是 plan cache。每次查詢進來,引擎會優先從快取找對應計畫,找到就直接重用,省下 CPU 與記憶體。
計畫重用率(plan reuse)是 OLTP 系統效能的關鍵指標之一。短查詢的編譯成本可能比執行還高;無法重用 → 系統把寶貴 CPU 浪費在重複編譯。
查 Plan Cache#
最基本的入口:sys.dm_exec_cached_plans。
SELECT decp.refcounts,
decp.usecounts,
decp.size_in_bytes,
decp.cacheobjtype,
decp.objtype,
decp.plan_handle
FROM sys.dm_exec_cached_plans AS decp;| 欄位 | 意義 |
|---|---|
refcounts | 多少物件引用此計畫,至少 1 |
usecounts | 計畫被「查詢」的次數(不必然等於使用次數) |
size_in_bytes | 計畫大小 |
cacheobjtype | 計畫類型(Compiled Plan / Plan Stub 等) |
objtype | 物件類型(Adhoc / Prepared / Proc…) |
plan_handle | 用來 join sys.dm_exec_query_plan、sys.dm_exec_sql_text |
計畫不會永遠在快取——重啟、failover、detach、記憶體壓力、老化都可能踢出。被踢出後 DMV 也看不到。
兩種查詢分類#
從計畫重用角度看,所有查詢可分兩大類:
- Ad hoc:硬寫值或本機變數,未明確參數化
- Prepared:明確使用參數(stored procedure、
sp_executesql、prepare/execute)
清理 Plan Cache 的兩種方法#
-- 全伺服器(謹慎!)
DBCC FREEPROCCACHE;
-- 僅該資料庫
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;兩者都可以指定 plan_handle 只清單一計畫(後者需 SQL Server 2019+)。
在 production 上執行
DBCC FREEPROCCACHE不指定 handle,等同強迫所有查詢重新編譯——可能引發瞬間 CPU 高峰、長尾 timeout。務必只清理目標計畫。
Ad Hoc 查詢的問題#
任何 hard-coded 值改變都產生新計畫,而且 連空白與換行都得一字不差 才能重用。
例:
WHERE soh.CustomerID = 29690 -- plan A
WHERE soh.CustomerID = 29500 -- plan B(新計畫)兩個計畫獨立佔用記憶體。系統若有大量 ad hoc 查詢,plan cache 會被洗掉。

Figure 7-1: Results of one execution of an ad hoc query

Figure 7-2: A second execution shown for the ad hoc query

Figure 7-3: The existing plan was not reused
Optimize for Ad Hoc Workloads#
啟用後,第一次 執行 ad hoc 查詢只儲存一個 plan stub(迷你佔位);第二次 才把完整計畫放進快取。
EXEC sp_configure 'show advanced option', 1;
RECONFIGURE;
EXEC sp_configure 'optimize for ad hoc workloads', 1;
RECONFIGURE;書中實測:同個查詢 stub 只佔 456 bytes,完整計畫佔 131,072 bytes——只跑一次的 ad hoc 直接省 99% 記憶體。

Figure 7-4: Results from sys.dm_exec_cached_plans showing size_in_bytes

Figure 7-5: The plan stub has been replaced by a compiled plan
Fritchey 在所有測試中都認為這個設定是 幾乎沒下風險的優化,建議大多數系統開啟。但仍建議在自家環境驗證。
簡單參數化(Simple Parameterization)#
優化器會嘗試把 ad hoc 查詢的 hard-coded 值替換成參數,自動轉成 prepared 計畫。例:
SELECT a.AddressLine1, a.City, a.StateProvinceID
FROM Person.Address AS a
WHERE a.AddressID = 42;實際儲存的計畫文字會變成:
(@1 tinyint)SELECT [a].[AddressLine1] ... WHERE [a].[AddressID]=@1objtype 變成 Prepared。注意:
- 參數的型別取決於原始字面值——
42→tinyint、32509→smallint、超過則int - 型別不同 → 新計畫(同一個查詢可能在快取裡有 2-3 份)
- 優化器可能把
BETWEEN 40 AND 60改寫成>= 40 AND <= 60——而你之後用相同寫法時,會直接命中前面參數化好的計畫
簡單參數化採取保守策略——任何 JOIN、複雜條件都不會走簡單參數化。實務 OLTP 場景中很少自動觸發,因此光靠它不夠。

Figure 7-6: Before creating the

Figure 7-7: A change in the simple parameterization

Figure 7-8: The prepared plan has now been used twice

Figure 7-9: Changes to the query result in changes in the cache

Figure 7-10: Reuse of the parameterized query
強制參數化(Forced Parameterization)#
需要更積極的參數化時:
ALTER DATABASE AdventureWorks SET PARAMETERIZATION FORCED;更多查詢會被強制參數化,但仍有限制:
INSERT ... EXECUTE- 已是 prepared 的 stored procedure / trigger / UDF 內部語句
- Client-side prepared statement
- 帶
RECOMPILE的查詢 LIKE中的 pattern 與 escape 引數
Forced parameterization 雖然能拉高重用率,但 可能加劇 bad parameter sniffing(第 13 章)。若資料分佈嚴重不均,同一計畫對所有參數值都用,反而效能更糟。務必先在測試環境驗證。
恢復為簡單模式:
ALTER DATABASE AdventureWorks SET PARAMETERIZATION SIMPLE;
Figure 7-11: A query has gone through forced parameterization
Prepared Workload#
明確使用參數的三種方式:
- Stored Procedure:包一段 T-SQL 接受參數
sp_executesql:執行帶參數的 T-SQL,不必先建立 procedure- Prepare/Execute Model:客戶端(如 Entity Framework)要 SQL Server 預先產生參數化計畫,再多次以不同參數執行
觀察 Plan Caching 的 Extended Events#
| 事件 | 意義 |
|---|---|
sp_cache_hit | 找到快取中的計畫 |
sp_cache_miss | 沒找到 |
sp_cache_insert | 新計畫加入快取 |
sp_cache_remove | 計畫被踢出 |
Stored Procedure 的細節#
Stored procedure 何時被編譯?#
Stored procedure 不是在 CREATE 時編譯——這是一個流傳已久的迷思。
CREATE PROCEDURE只做語法檢查與保存定義;計畫是 第一次執行時才產生。因此:你可以建立一個引用尚未存在資料表的 procedure,CREATE 不會錯,EXECUTE 時才會錯。
Stored procedure 的效能優勢#
stored procedure 不天生比 ad hoc 快——對 SQL Server 來說查詢就是查詢。但它帶來幾個間接好處:
- 計畫重用:同名同參數宣告的 procedure 重用率高
- 參數探嗅(parameter sniffing):第一次執行時,優化器會用該次參數值搭配統計資訊,產出特定化的計畫(好處與風險並存——詳見第 13 章)
- 業務邏輯靠近資料:對純資料聚合場景,把運算搬進 SQL Server 端能減少資料搬移
- 減少網路流量:呼叫 procedure 只傳名稱與參數,比送一段大 T-SQL 划算
非效能類好處#
- 應用程式對結構變動更不敏感:data shape 改變時可在 procedure 內吸收
- 單一管理點:邏輯集中在資料庫
- 安全性:使用者只開放執行 procedure 權限,可隱藏底層資料結構
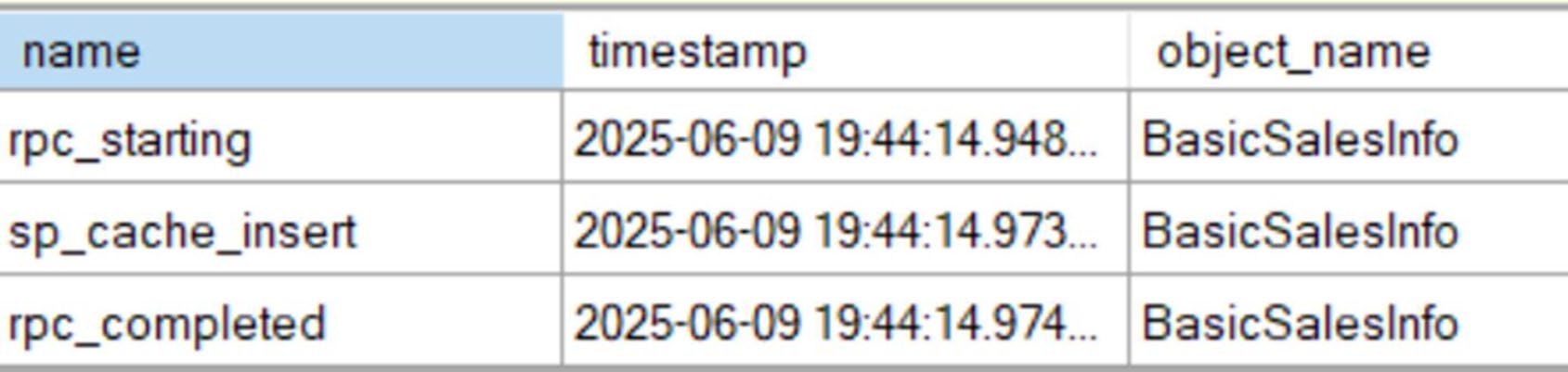
Figure 7-12: Adding a stored procedure to cache
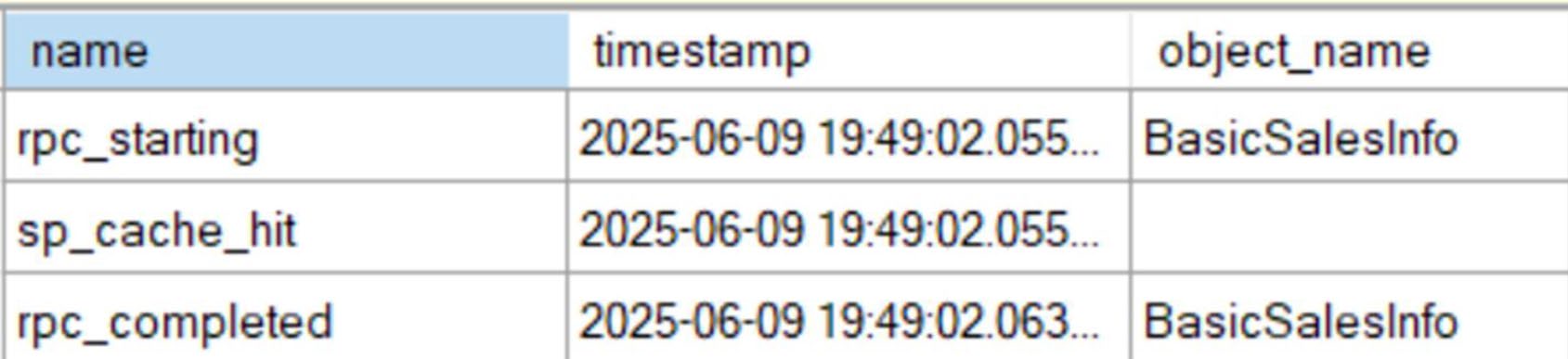
Figure 7-13: The stored procedure was found in cache
sp_executesql 與 Prepare/Execute#
兩者皆能達成 prepared 計畫重用:
sp_executesql @stmt, @params, @value1, @value2:T-SQL 字串可內含@param,配合@params宣告型別- Prepare/Execute:客戶端 driver(ADO.NET、ODBC、JDBC…)呼叫
sp_prepare/sp_execute;Entity Framework 等 ORM 預設走這條路
動態 SQL 拼接(concatenation)必殺:直接把使用者輸入拼進 SQL 不只是 SQL Injection 風險,也徹底破壞計畫重用。請改用
sp_executesql或 ORM 的參數化機制。

Figure 7-14: A prepared statement built by sp_executesql

Figure 7-15: Second use of the prepared plan from sp_executesql

Figure 7-16: A new prepared plan is created
計畫重用的條件#
要從快取拿到並重用計畫,必須滿足:
- 查詢文字 + 參數定義 完全相符(連空白)
- ANSI / SET 選項相同(不同會話可能因 SET 不同而拿到不同計畫)
- 物件 schema 名稱要明確(
dbo.Foovs.Foo可能算不同計畫) - 物件未變更(CREATE / ALTER / DROP 引用物件會使計畫失效)
在程式中固定使用 完整的兩段式名稱(two-part name)
schema.object,是提升重用率的低成本做法。

Figure 7-17: Retrieving the hash values from cache

Figure 7-18: A new query_hash value

Figure 7-19: Changes to the query_plan_hash value
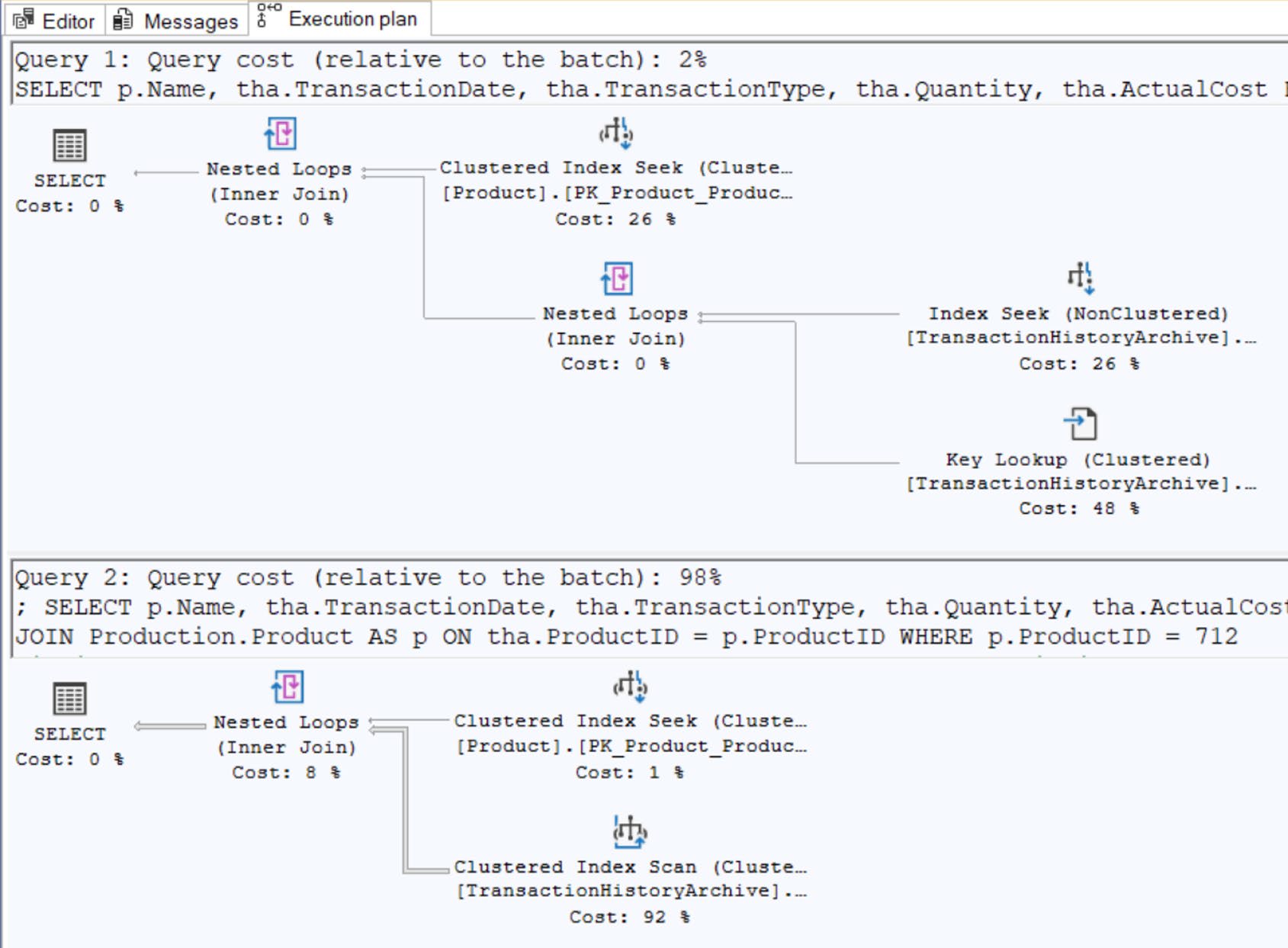
Figure 7-20: Radically different execution plans
Query Store 與 Plan Cache 的互動#
Query Store 不取代 plan cache,兩者各自獨立:
- Plan cache:執行時的記憶體區域
- Query Store:歷史的持久儲存
但兩者交互處:
- Plan forcing:Query Store 釘住的計畫會在編譯後 override plan cache 的選擇
- 計畫即使被踢出 plan cache,Query Store 仍保留它,可重新讀回並 force
本章定調#
- Plan reuse 是 OLTP 效能的核心;avoid pure ad hoc workloads
- 開 Optimize for Ad Hoc Workloads 對多數系統有益
- Forced parameterization 是雙面刃,先驗證 parameter sniffing 風險
- Stored procedure 不天生快,但搭配 set-based 設計、明確 schema、明確參數化,是長期最穩的做法
- Query Store 是 plan cache 的歷史層,兩者互補
下一章將深入 查詢重新編譯(recompilation)——理解計畫為什麼從快取消失、為什麼重新編譯,以及如何避免不必要的 recompile。