為什麼統計資訊決定一切#
優化器(query optimizer)走的是 基於成本的決策,而成本估算的核心輸入是 列數估算(row count estimate)。SQL Server 不可能每次都重新計算所有列數,因此它在欄位上維護一份「資料分佈摘要」——這就是 統計資訊(statistics)。
沒有統計、或統計不準確時,優化器只能猜——而且猜得通常很糟。「Estimated rows」上看到怪數字、計畫選錯運算子、Index Scan 莫名其妙出現,最常見原因都是統計問題。
需要統計的欄位是 用於過濾的欄位:WHERE、HAVING、JOIN ON。SELECT 子句裡的欄位不需要。
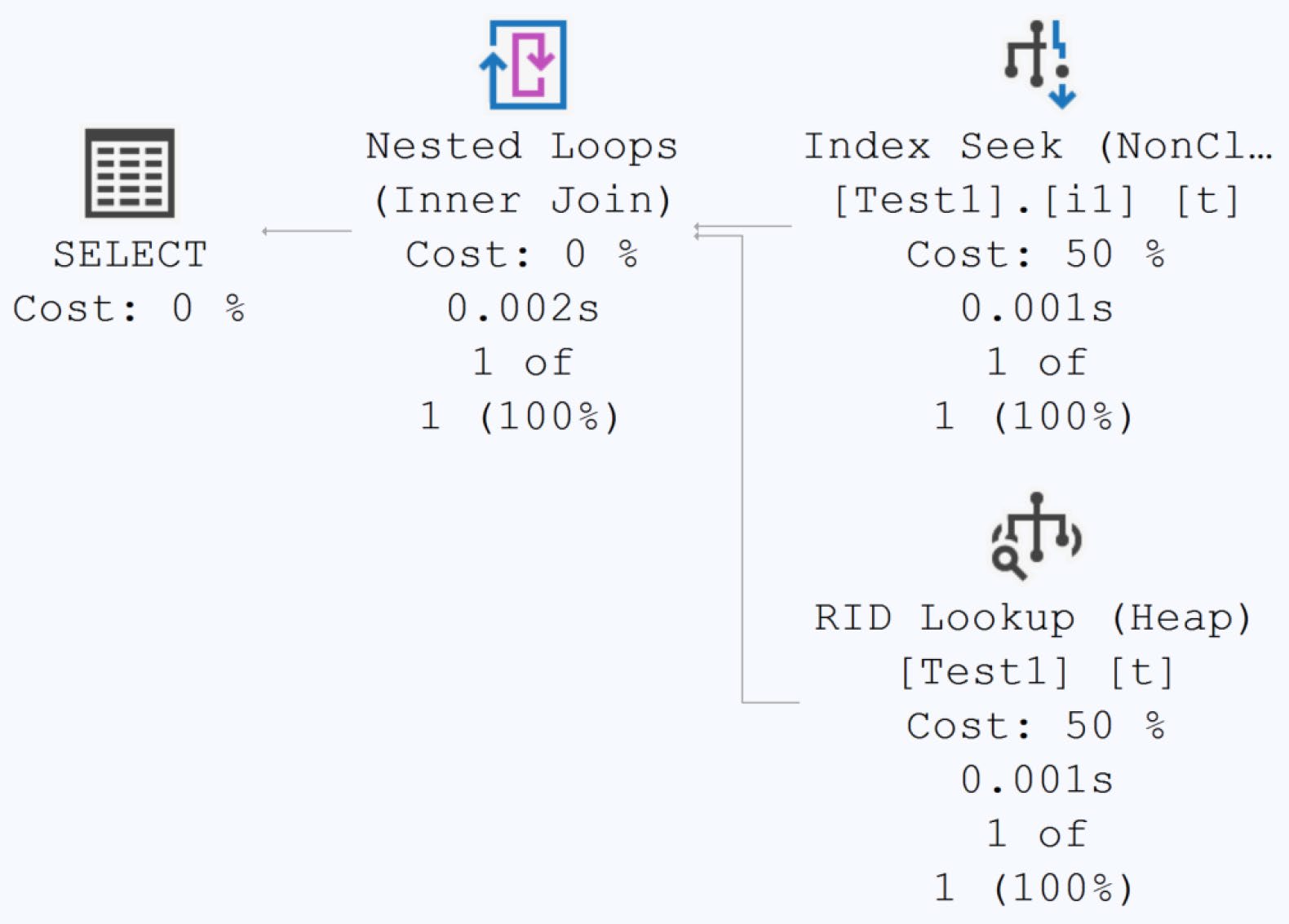
Figure 5-1: An Index Seek is used to retrieve data
統計如何被建立#
- 建索引時自動建立:建立 rowstore 索引一定會自動產出對應統計,無法關閉
- 過濾欄位上自動建立:未建索引的欄位若被用於過濾,預設會自動產生統計
- columnstore 索引:預設無統計,可手動加;但建在 columnstore 上的 nonclustered 索引仍是 rowstore,仍有統計
自動建立的統計命名規則為
_WA_Sys_<欄位序號>_<唯一值>。_WA來自 Microsoft 總部所在的 Washington 州,認真不騙。
自動更新(Auto Update Statistics)#
SQL Server 預設會在資料變動時自動更新統計。從 SQL Server 2016 起的 新門檻演算法 對大表更友善:
| 表類型 | 列數範圍 | 更新門檻 |
|---|---|---|
| Temporary | < 6 | 6 次變動 |
| Temporary | 6–500 | 500 次變動 |
| Permanent | < 500 | 500 次變動 |
| Both | > 500 | MIN(500 + 0.2*n, SQRT(1000*n)) |
大表用平方根公式門檻低很多。例如 5,000,000 列的表,舊演算法要超過 1,000,500 次變動才會更新;新演算法只要 70,710 次。
舊演算法只有改 compatibility level 才會啟用,強烈建議用新門檻。

Figure 5-4: Session output including the auto_stats event
同步 vs. 非同步更新#
預設 同步:當查詢觸發統計更新,查詢會等更新完才繼續。
可以改 非同步:
- 觸發查詢用舊統計繼續執行
- 統計在背景被更新
- 後續查詢看到的是更新後的版本
非同步更新適用於「統計更新本身造成 timeout」的情境。但要注意:觸發更新的那次查詢仍用舊計畫執行,可能跑得很糟。
不要關掉
AUTO_UPDATE_STATISTICS。Fritchey 強調:「極少系統會被自動維護傷到,多數系統會受惠。」
過時統計造成的後果#
書中以一個簡單範例展示傷害:
- 建一張 1,500 列的表,建 nonclustered 索引
- 關掉自動更新統計
- 加進 1,500 列同樣
C1 = 2的資料(共 30,001 列裡有 1,502 列符合C1 = 2) - 跑
SELECT ... WHERE C1 = 2

Figure 5-2: Extended Events output showing no statistics updates
結果優化器仍以為只會回傳 2 列,於是選了 Index Seek + Nested Loops——但實際上要回傳 1,501 列:
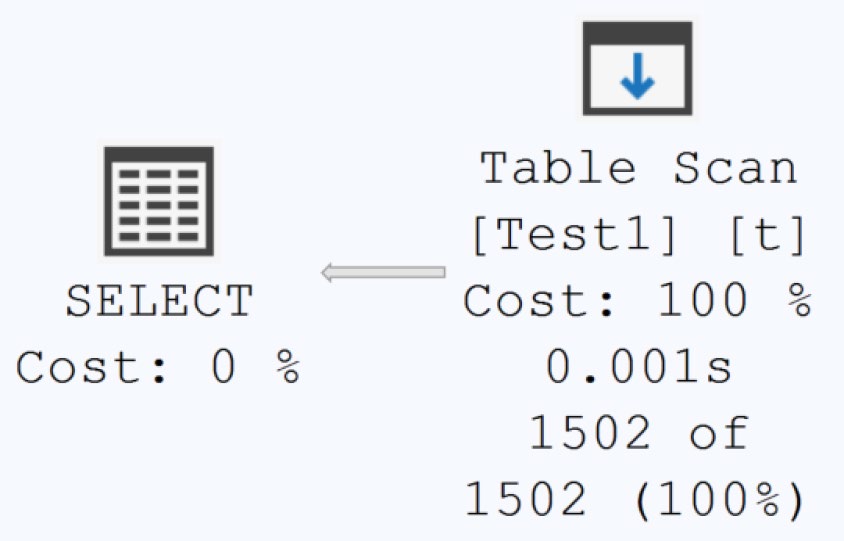
Figure 5-3: Execution plan showing a table scan
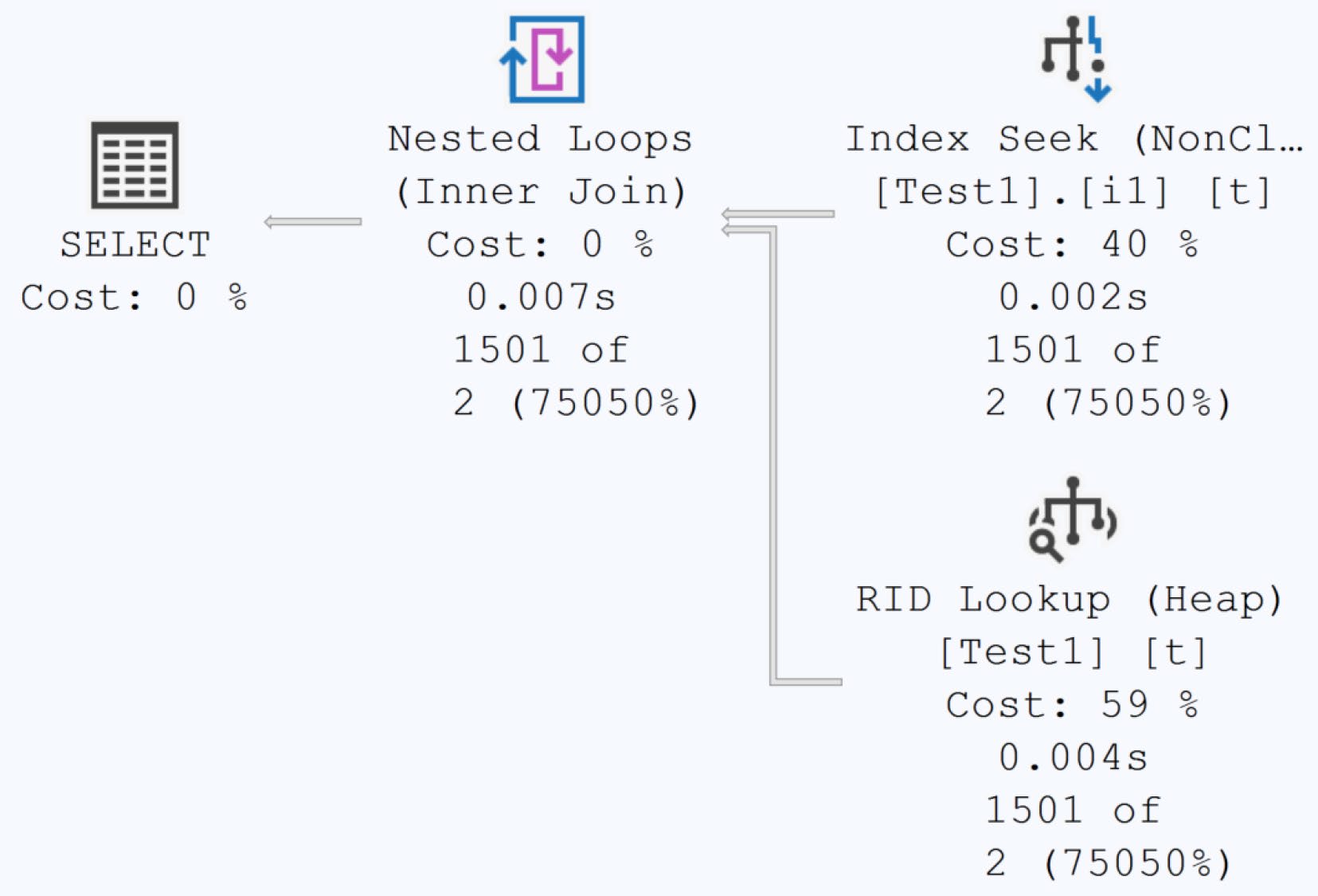
Figure 5-5: Inaccurate execution plan due to out-of-date statistics
| 統計狀態 | Avg. Duration | Reads |
|---|---|---|
| Up to date | 44.2 ms | 11 |
| Out of date | 63.6 ms | 1,510 |
同樣的查詢、同樣的結果集,只因為統計過時,I/O 就增加超過百倍。
非索引欄位的統計#
很常見的情境:欄位沒有索引但被用在 JOIN / WHERE。SQL Server 預設會 自動為這類欄位建立統計,因為即使沒索引可走,優化器仍需要列數估算來決策——例如選擇哪張表當 inner table、要不要用 Hash Join。
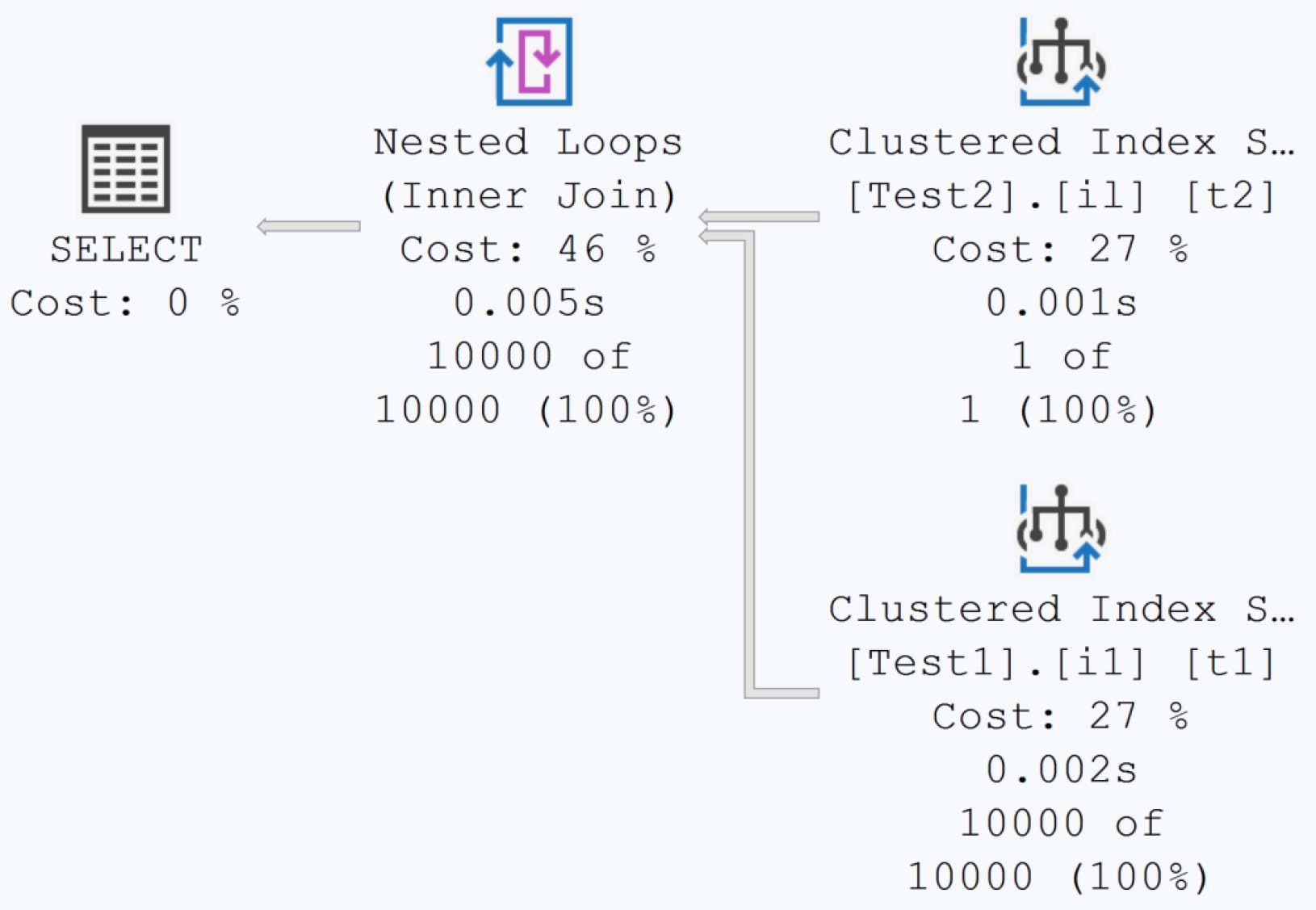
Figure 5-6: Execution plan on two tables without indexes

Figure 5-7: Extended Events session showing auto_stats events

Figure 5-8: Automatic statistics created for table Test1
沒統計時會發生什麼#
關掉 AUTO_CREATE_STATISTICS 並執行同樣 join 查詢,計畫會出現:
- Columns With No Statistics 警告
- No Join Predicate 警告(因為優化器假設一切都要全配對)
- 多出 Table Spool(試圖以暫存減少重複掃描)
- 估算列數預設為 100——一個盲猜值
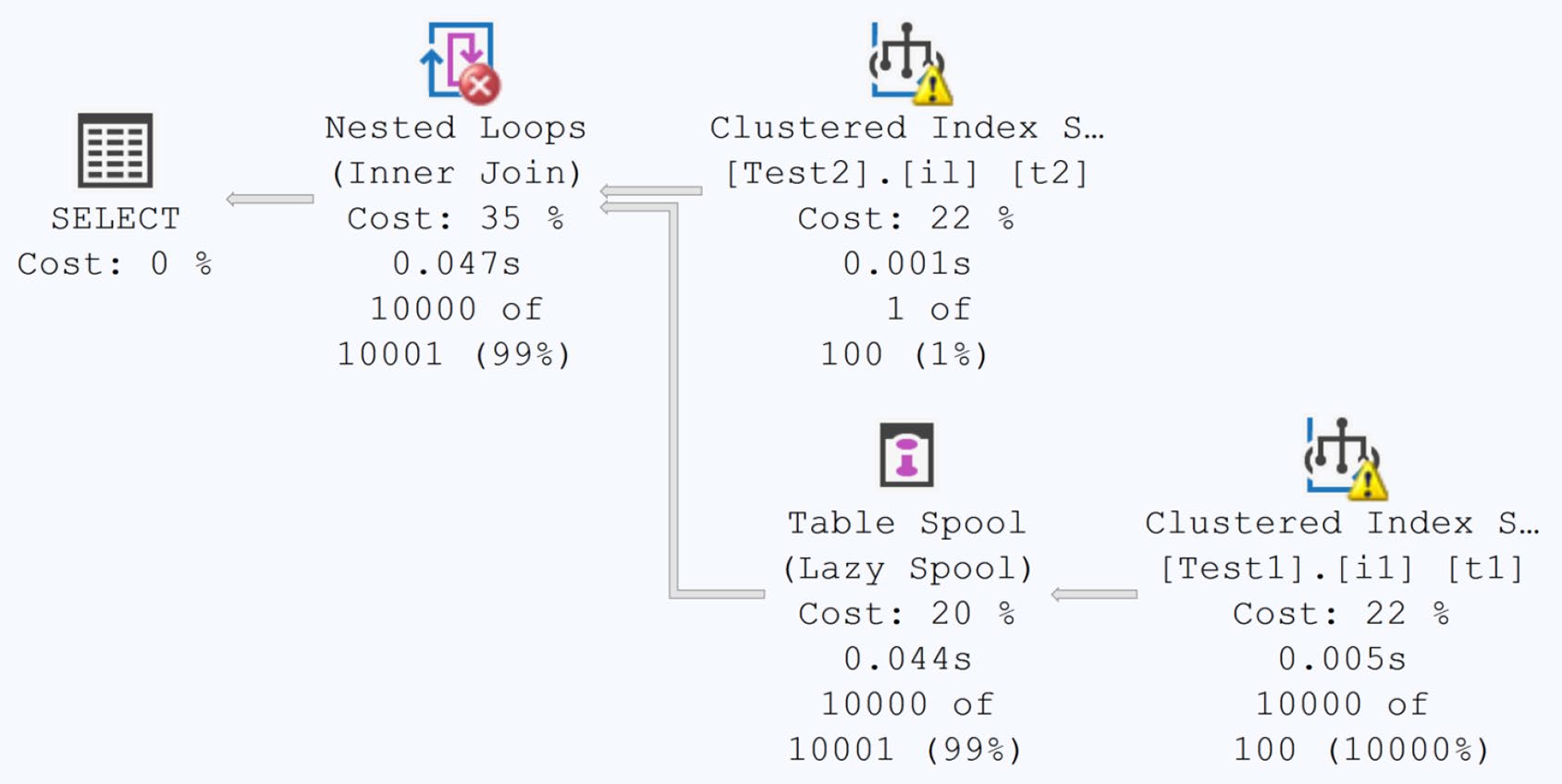
Figure 5-10: Execution plan with a number of warnings
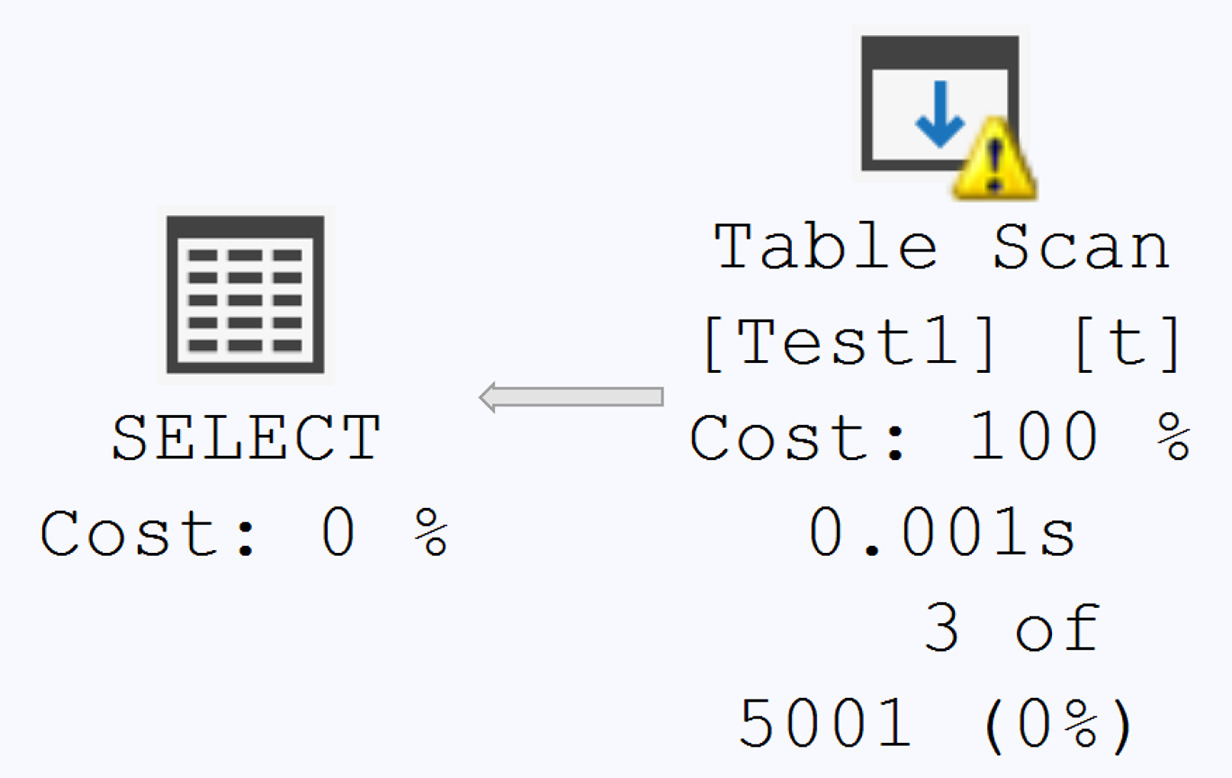
Figure 5-22: Index scan caused by missing statistics
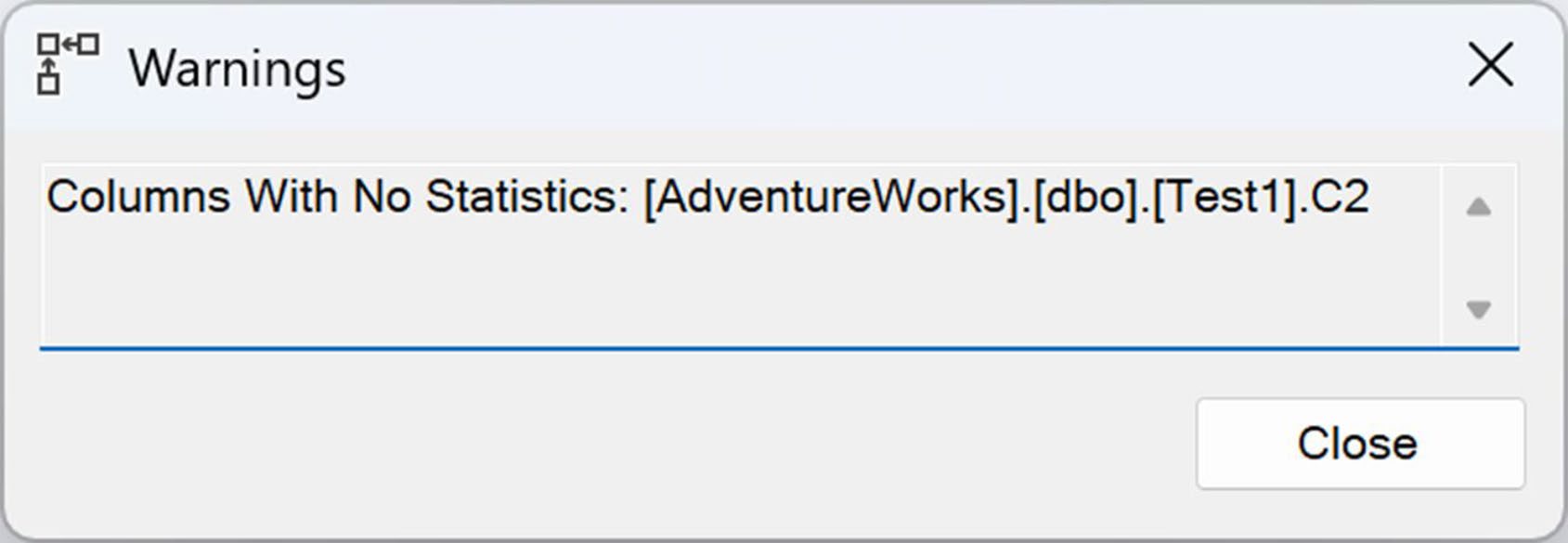
Figure 5-23: Property values from the warning in the Table Scan operator
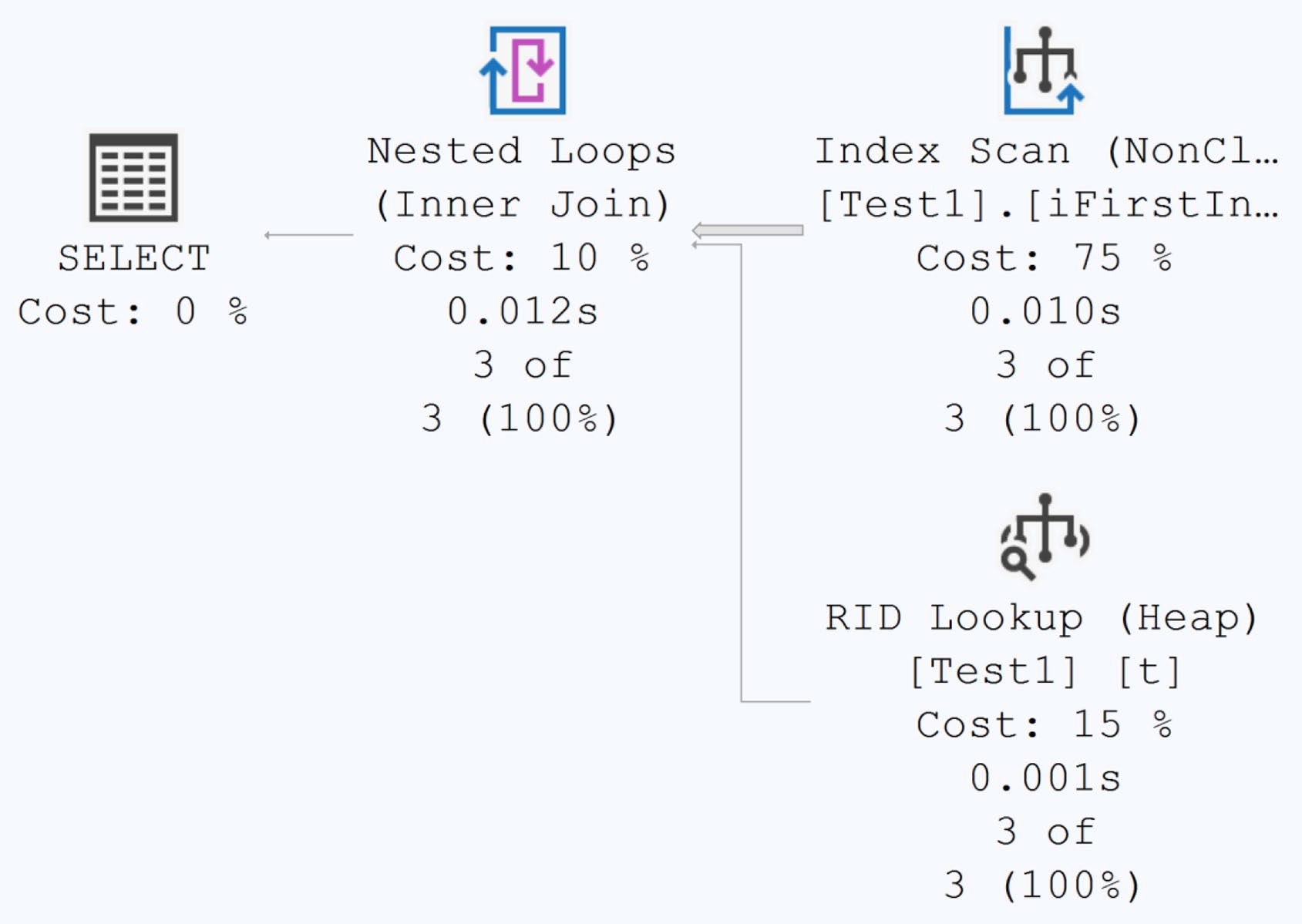
Figure 5-24: A different execution plan, thanks to statistics
| 統計狀態 | Avg. Duration | Reads |
|---|---|---|
| 有統計 | 57.9 ms | 48 |
| 無統計 | 72.5 ms | 20,248 |
真要關
AUTO_CREATE_STATISTICS,請追蹤 Extended Events 中的missing_column_statistics事件,掌握有多少查詢正在受害。但對絕大多數系統來說:保持預設開啟就對了。
一份統計資訊的內容#
執行 DBCC SHOW_STATISTICS(<table>, <stats_name>); 會看到三個結果集:
- Header:統計的元資料
- Density Graph:基於選擇性(selectivity)的密度數值
- Histogram:實際資料分佈直方圖

Figure 5-11: Statistics on index FirstIndex
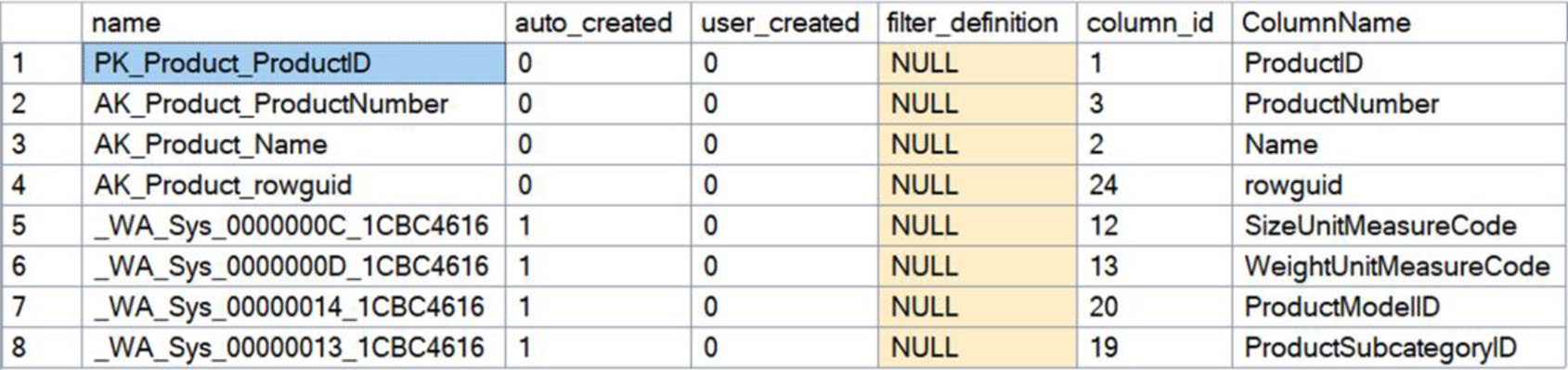
Figure 5-15: List of statistics on the Product table
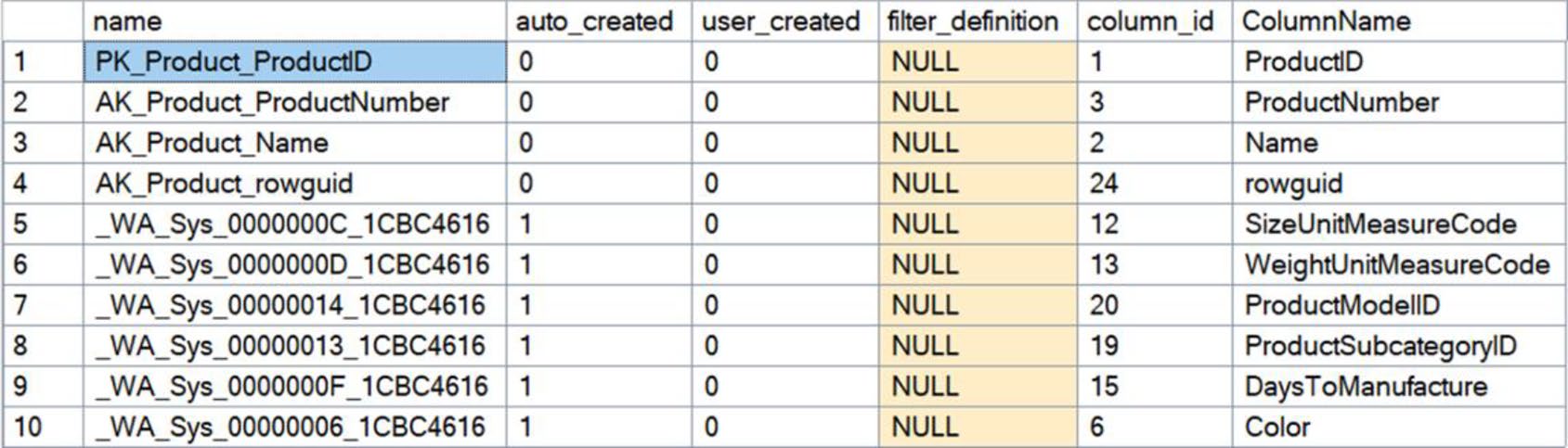
Figure 5-16: Added statistics to the Product table
Header#
關鍵欄位:
- Name、Updated:何時建立或更新
- Rows:建立時的總列數
- Rows Sampled:實際抽樣多少列
- Steps:直方圖步階數(最多 200)
- Density:索引鍵的平均長度(與後面 density vector 不同概念)
Density(密度)#
Density = 1 / 該欄位 distinct value 數量
值落在 (0, 1] 之間。越低越好——代表選擇性越高,越適合做索引鍵。
SELECT 1.0 / COUNT(DISTINCT C1) FROM dbo.Test1;當直方圖無法覆蓋(例如多欄位統計的「非首欄」),優化器會用 density × 列數來估算。
唯一索引(unique index)的選擇性最高,density 接近 1/n。
反之,若某欄位只有 2 種值,density = 0.5,意味平均一查就會回傳一半的表——這時 nonclustered index 通常比 table scan 還慢,優化器會避開它。
Histogram(直方圖)#
最常被用到的部分。每個 step 描述一段值域內:
- 邊界值
- 等於邊界的列數
- 邊界以下其他值的總列數
- 邊界以下的 distinct value 數
最多 200 個 step(含 NULL 則 201 個)。Steps 是依資料分佈隨機抽樣產生的,不是均分。
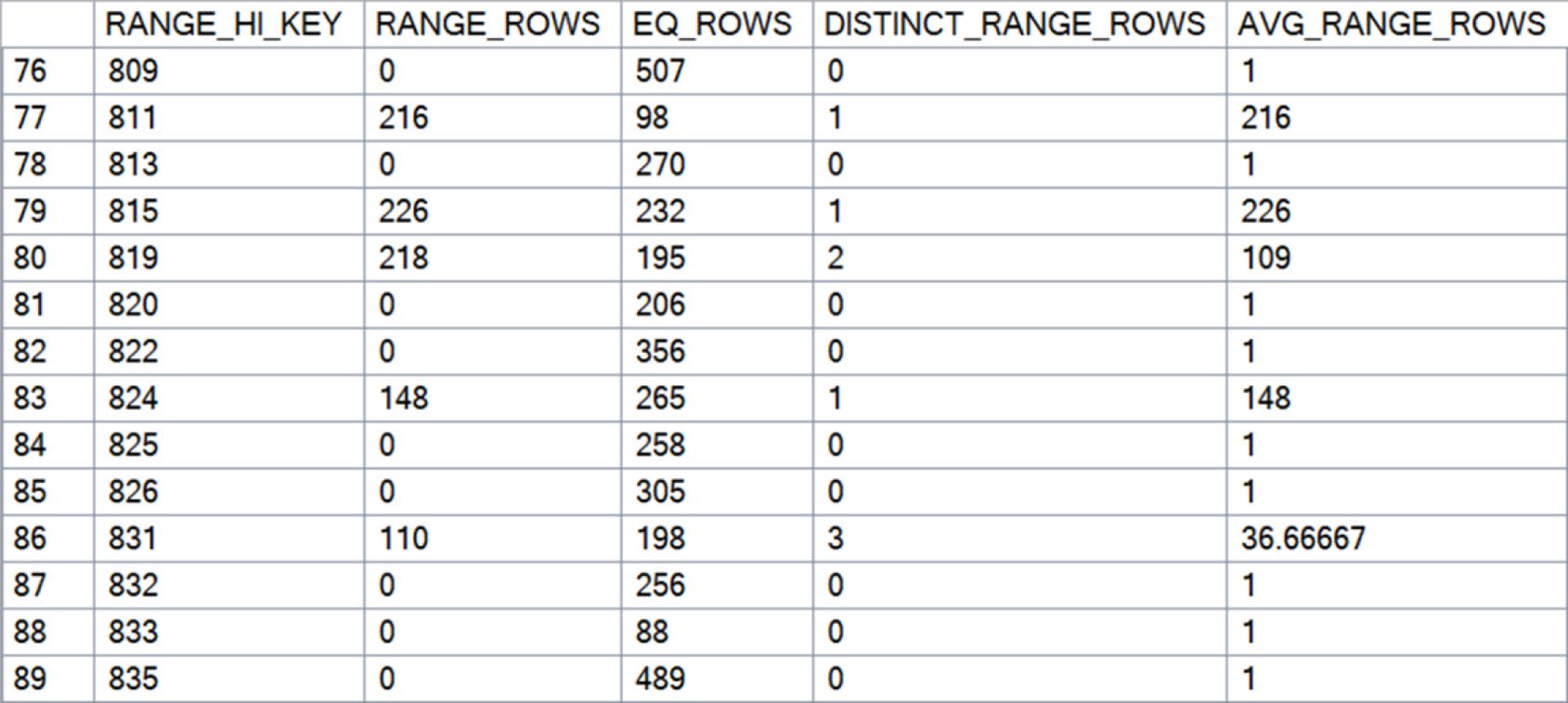
Figure 5-12: Histogram from the IX_SalesOrderDetail_ProductID statistics
因為 step 上限只有 200,資料分佈非常不均勻(skew)的欄位會丟失精度,這也是 parameter sensitive plan(第 13 章)問題的根源之一。
多欄位統計(Compound Statistics)#
複合索引或手動建的多欄位統計會多一份 density vector:
- 第 1 欄的 density
- (第 1 欄, 第 2 欄) 的 density
- (第 1 欄, 第 2 欄, 第 3 欄) 的 density
- …
當查詢條件未涵蓋首欄時,histogram 派不上用場——這時優化器會走 density vector 估算。
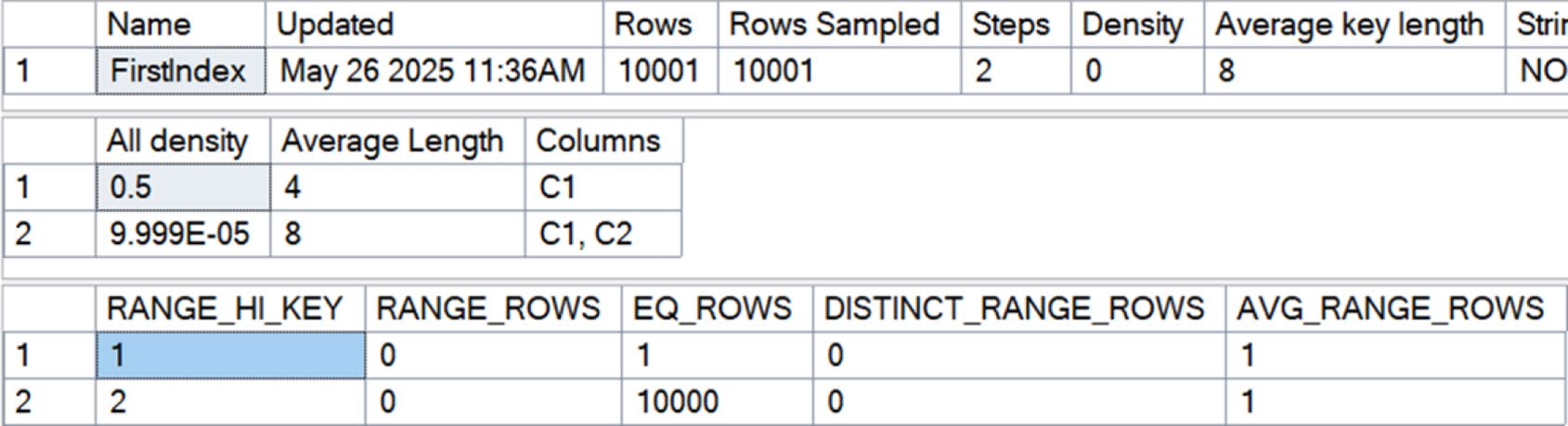
Figure 5-17: Statistics with a multicolumn density graph
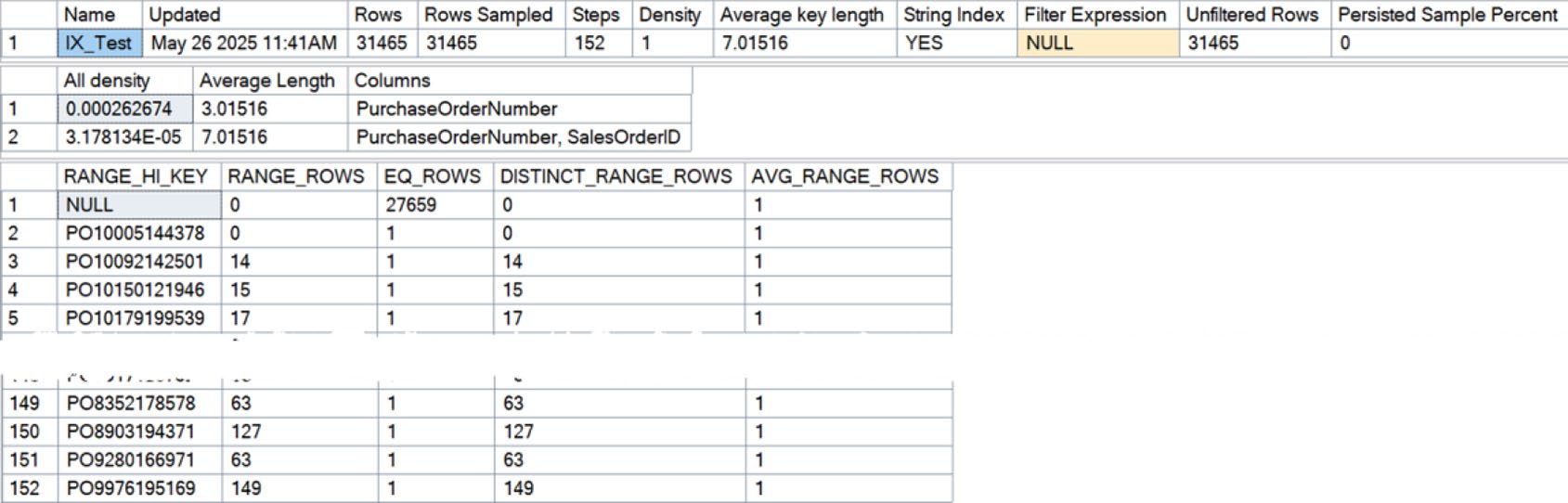
Figure 5-18: Statistics on an unfiltered index
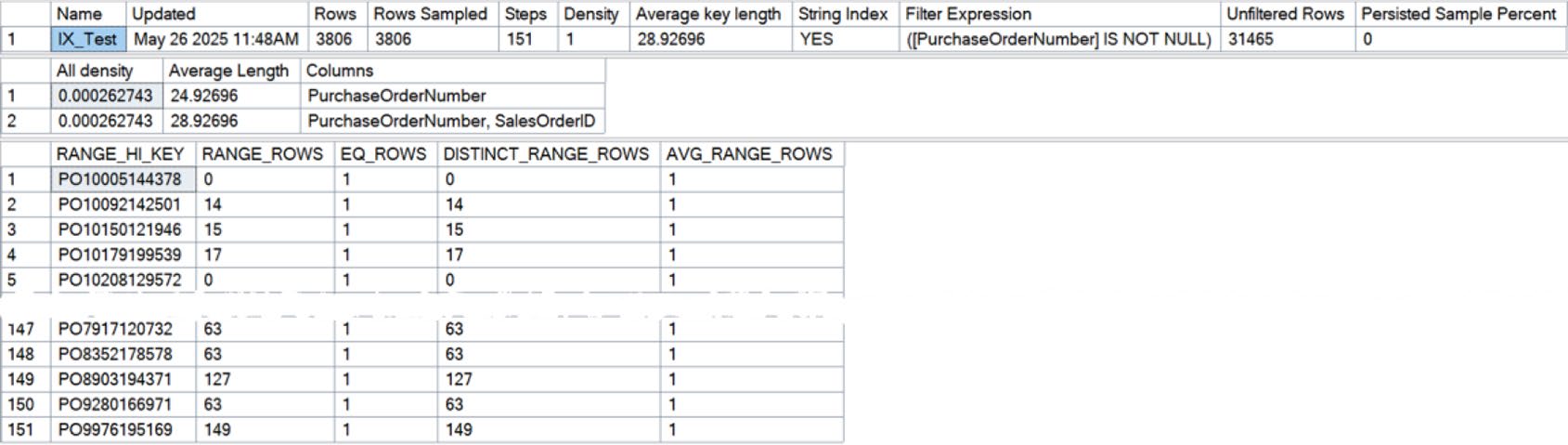
Figure 5-19: New statistics based on the filtered index
多欄位統計的 首欄 才有 histogram。所以在規劃複合索引鍵的順序時,選擇性高的欄位放前面 通常較有利。
基數估算(Cardinality Estimation, CE)#
「基數」就是某個運算結果的列數。優化器整個計畫的好壞,直接取決於 CE 是否準確:
- 統計 + histogram + density 提供原始素材
- CE 演算法把這些素材轉成估算
SQL Server 在 2014 大改寫了 CE。新版 CE 對多重 predicate 的獨立性假設不同——舊 CE 假設條件高度相關,新 CE 假設更接近獨立。實務上要驗證再選擇是否切換 compatibility level。
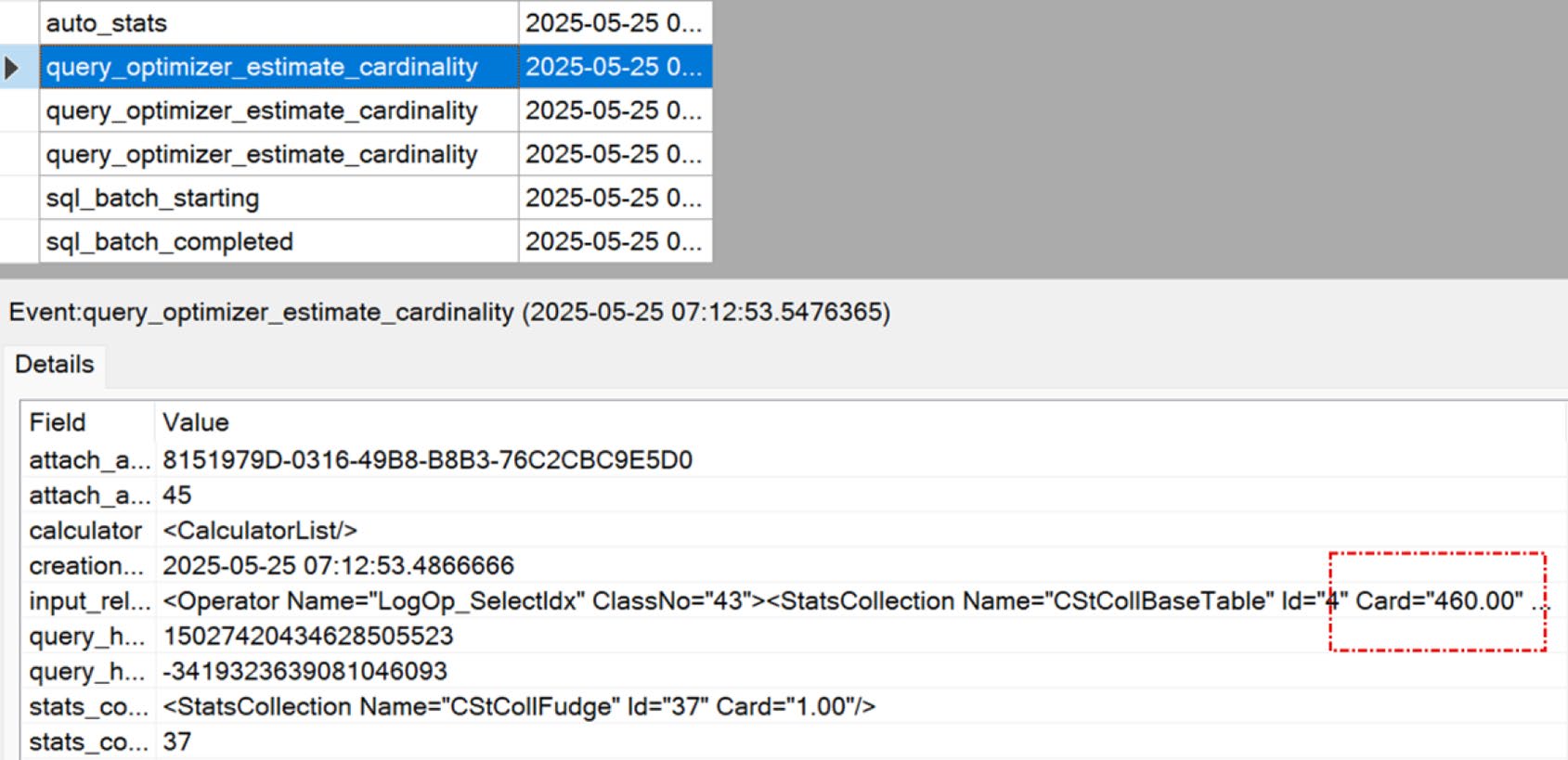
Figure 5-13: Session showing output from the query_optimizer_estimate_
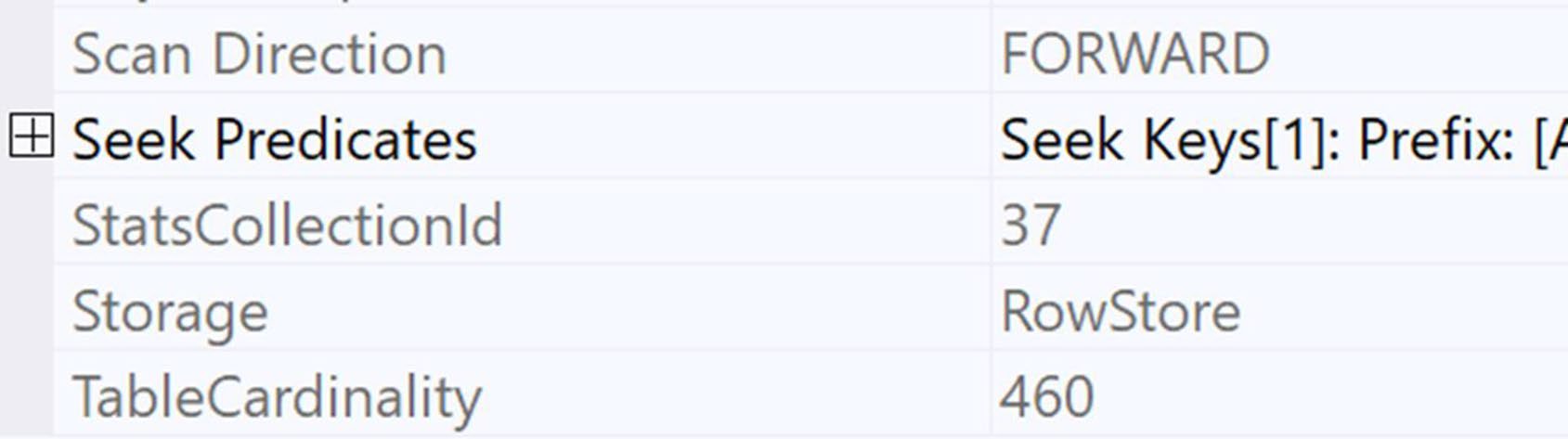
Figure 5-14: StatsCollectionId matching the operator to the properties
Figure 5-20: All Database Scoped Configuration settings

Figure 5-21: Execution plan property showing the cardinality estimation engine
維護策略#
- 預設啟用
AUTO_CREATE_STATISTICS與AUTO_UPDATE_STATISTICS - 大表 / 高變動表可考慮 手動定期更新(例如夜間排程
UPDATE STATISTICS WITH FULLSCAN) - 自動更新走的是抽樣,FULLSCAN 較準但較慢
- 若見到 query 在白天因統計更新觸發 timeout,可開啟 非同步更新
不要為了「統計準」而強制把每張表每晚跑 FULLSCAN。對 TB 級資料庫這代價龐大;先看計畫是否真的因統計問題受害再下手。

Figure 5-25: Statistics for iFirstIndex
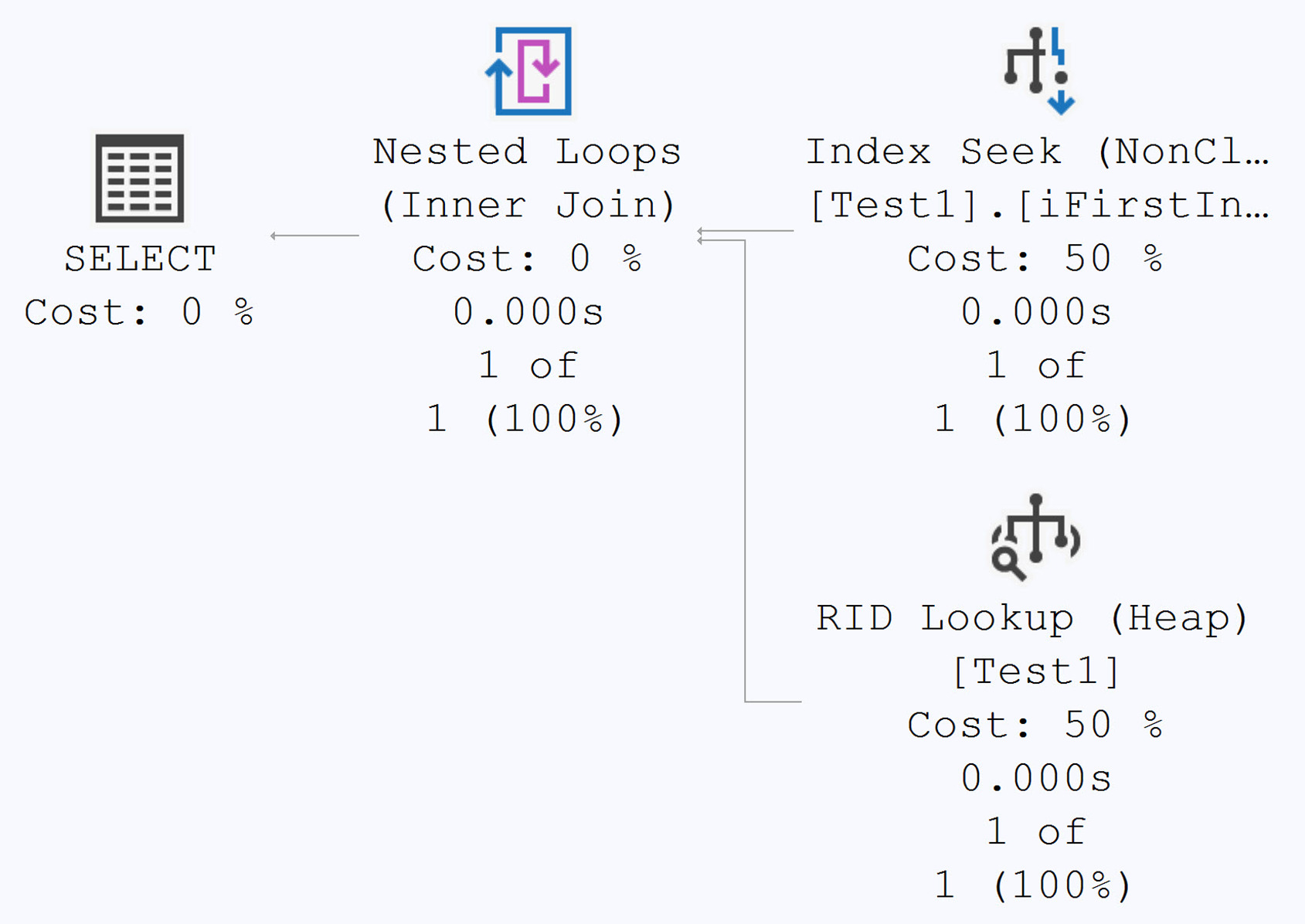
Figure 5-27: Reads: 4
本章定調#
- 統計是優化器決策的根基;統計不準 → 計畫錯 → 效能崩
- 預設自動建立、自動更新對絕大多數情境是對的
- 過時 / 缺失統計帶來的代價往往大於更新本身的成本
- 直方圖只有 200 個 step;對 skew 嚴重的資料要意識到精度限制
- 多欄位統計只有首欄有 histogram,density vector 是輔助
下一章將進入 Query Store——把這些查詢效能與計畫資訊長期保存與回溯的官方工具。