為什麼從優化器開始講#
SQL Server 內所有效能議題的起點與終點,幾乎都在 查詢優化器(query optimizer)。優化器產出的成果是一份 執行計畫(execution plan)——它既是查詢引擎執行的路徑,也是我們窺視優化器決策的主要窗口。
優化過程本身相當吃資源,特別是 CPU,並會佔用查詢的執行時間。SQL Server 試著把這份成本攤回去:把產出的計畫存進 計畫快取(plan cache),下次同樣模式的查詢就能直接重用。
本章三大主題:
- 查詢優化的整體流程
- 執行計畫與計畫快取
- 影響並行(parallel)計畫產生的因素
查詢優化整體流程#
優化器採取 基於成本的分析(cost-based analysis):對「該用哪條索引、表怎麼 join、要不要排序」等大量選擇進行估算,並選出成本最低的組合。除了統計資訊(statistics),它也會考量資料庫結構:
- 欄位資料型別
- 主鍵(primary key)與外鍵(foreign key)
- 各種約束(constraints)
優化器追求的是「夠好(good enough)」,不是完美。它用數學模型在「達到不錯的計畫」與「使用最少資源、最快結束」之間取得平衡。
優化前的準備工作#
優化前,查詢會先經過三步預處理:
- 解析(parsing)
- 繫結(binding)
- 優化(optimization)
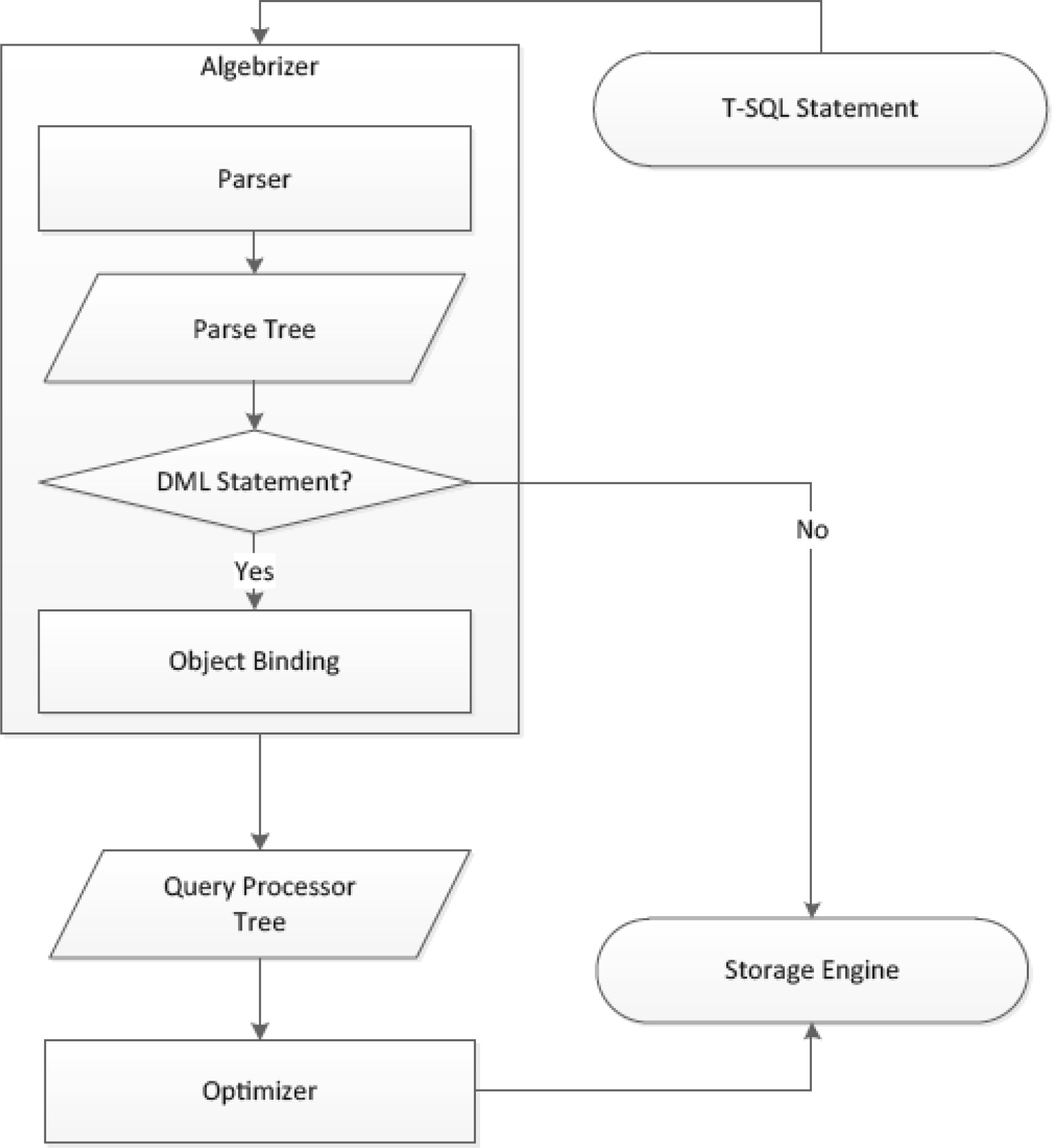
Figure 2-1: Steps leading up to the optimization process
解析(Parsing)#
查詢首先進入 關聯式引擎(relational engine),由所謂的 algebrizer 進行語法檢查。
- 任何語法錯誤會立刻中斷整個批次(batch),即使後面還有正確語句
- 多重語法錯誤只會回報第一個——這是優化器降低成本的設計之一
- 通過後產生內部結構:parse tree
繫結(Binding)#
利用 parse tree 識別查詢中所有物件——表、欄位、索引等——並做下列工作:
- 確認資料型別
- 規劃彙總(aggregations)與其他運算
- 自動加入 隱式型別轉換(implicit data conversion)
- 套用語法層級的優化(例如把
BETWEEN改寫為>=與<=) - 對單純查詢套用 簡單參數化(simple parameterization),將字面值改成
@1、@2
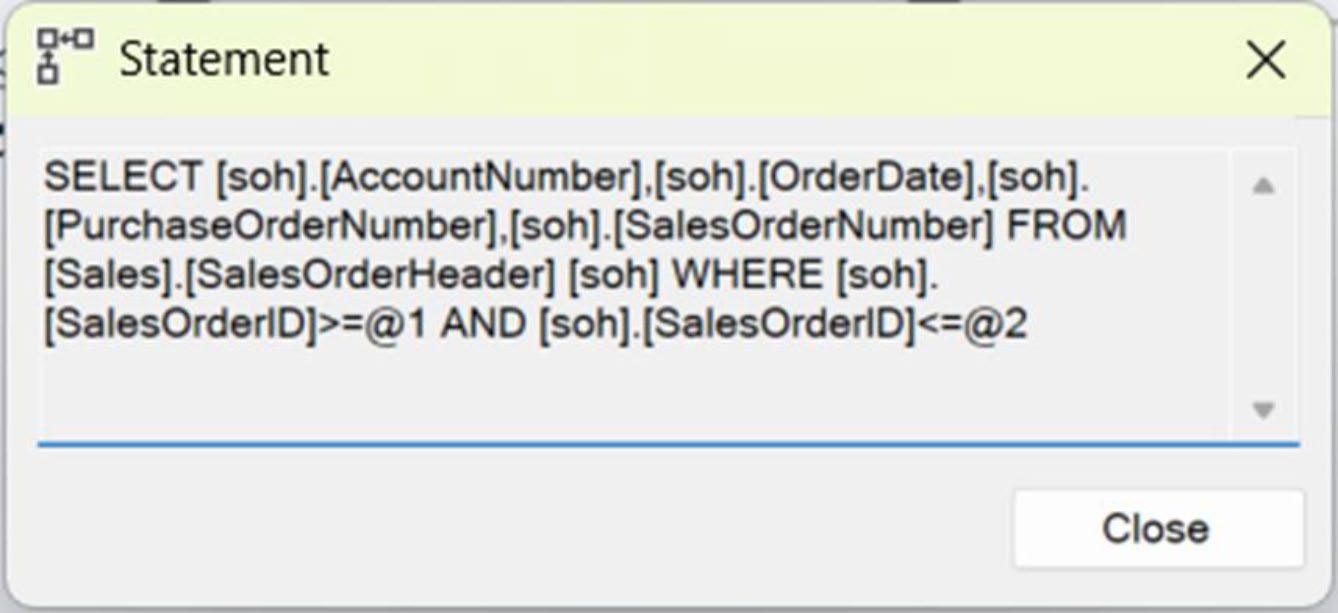
Figure 2-2: Syntax-based optimization at work
繫結完成後產生另一個內部結構:query processor tree,這就是優化的起點。
執行計畫上看到驚嘆號(warning indicator)通常代表型別轉換(type conversion)可能影響 cardinality 估算。務必檢查警告所在欄位是否真的用在 WHERE / JOIN / HAVING 中。
例如 AdventureWorks 中的
SalesOrderNumber是由SalesOrderID(int)轉成字串拼接而成;當這個欄位實際未用於篩選時,警告可以安全忽略。

Figure 2-3: A warning indicator on an execution plan
DDL(Data Definition Language)大多沒有執行計畫。
CREATE TABLE、CREATE PROCEDURE都不走優化流程;唯一例外是CREATE INDEX,因為優化器可利用既有索引提升建立效率。
優化階段#
簡化(Simplification)#
優化的第一步:
- 確認每個被引用的物件確實有用
- 開始蒐集統計與列數
- 利用 constraint(如 foreign key)刪去多餘的 join
例:四表 join 中只有兩張被引用,且透過 constraint 可推得另兩張不影響結果,那兩張會被刪除。
Trivial Plan 比對#
對極端簡單的查詢(例如沒有任何索引的 heap 表只能 table scan),可直接套用 Trivial Plan,整個優化過程被跳過。可在執行計畫屬性中查看計畫是否標記為 Trivial。
三階段優化搜尋#
不命中 Trivial Plan 時,優化器會走多階段搜尋,每階段儘量做最少工作:
- Search 0 / Transaction:簡單 OLTP 查詢,少量 join,無需重排
- Search 1 / Quick Plan:開始進行 join 重排與其他轉換
- Search 2 / Full Optimization:複合索引使用、子查詢解套(subquery unnesting)等複雜評估
優化器可依查詢複雜度跳階——例如直接從 Quick Plan 進到 Full Optimization。
優化器主要決策依據是 列數估算(row count),而列數來自 ON / HAVING / WHERE 上的統計資訊。
估算 CPU、記憶體、I/O 後得到一個總成本——這個成本不是針對你的硬體,而是優化器內部的數學構造。
提早終止(Early Termination of Optimization)#
優化器並非窮舉所有可能:
- 達到「夠好」就會停下,即使還有更佳計畫
- 達到計算的迭代上限就會 Timeout
這兩種情況都會在執行計畫屬性的 Reason for Early Termination 顯示。
屬性中
Optimization Level = FULL不一定代表跑完了 Search 2,只代表這不是 Trivial Plan。
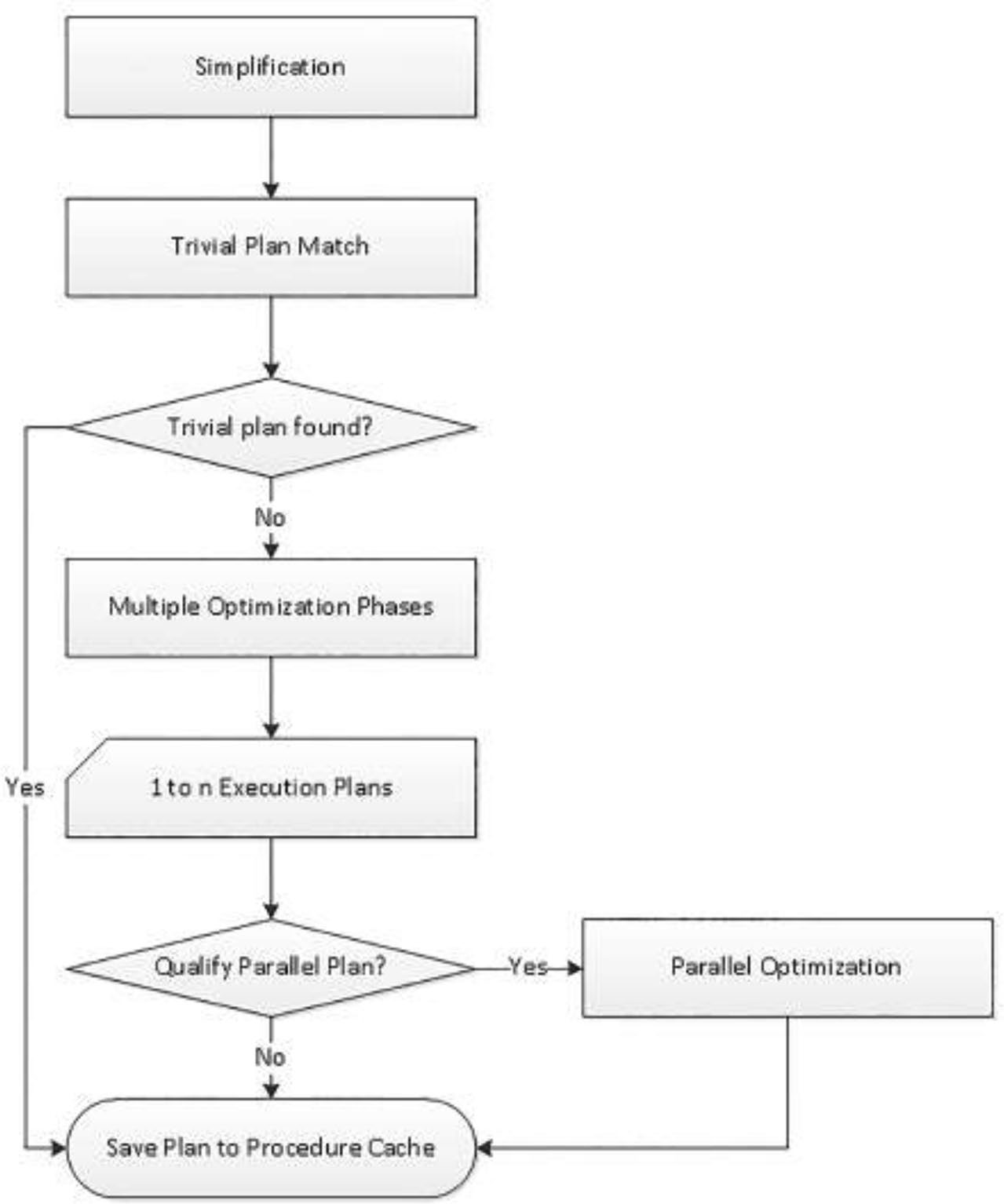
Figure 2-4: The optimization process
從執行計畫看優化器行為#
執行計畫最左側的 SELECT 運算子,其屬性視窗會揭露優化過程的關鍵資訊:

Figure 2-5: Execution plan from the complex query
- CompileCPU:編譯計畫所花 CPU 時間
- Estimated Number of Rows Per Execution:優化器估算的列數
- Estimated Subtree Cost:整個計畫的 CPU + I/O + 記憶體估算總和
- Optimization Level 與 Reason for Early Termination
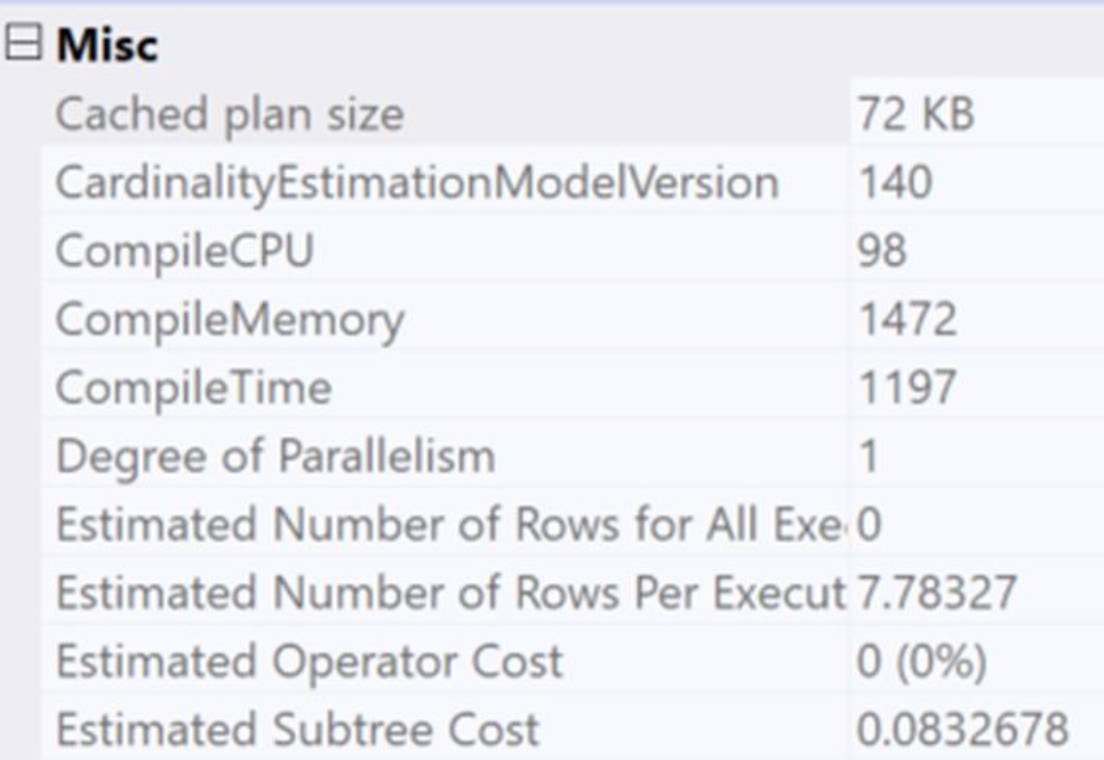
Figure 2-6: Optimizer behaviors on display in the execution plan properties

Figure 2-7: Additional properties showing optimizer behaviors
也可以透過 DMV 觀察整體優化負載:
SELECT deqoi.counter,
deqoi.occurrence,
deqoi.value
FROM sys.dm_exec_query_optimizer_info AS deqoi;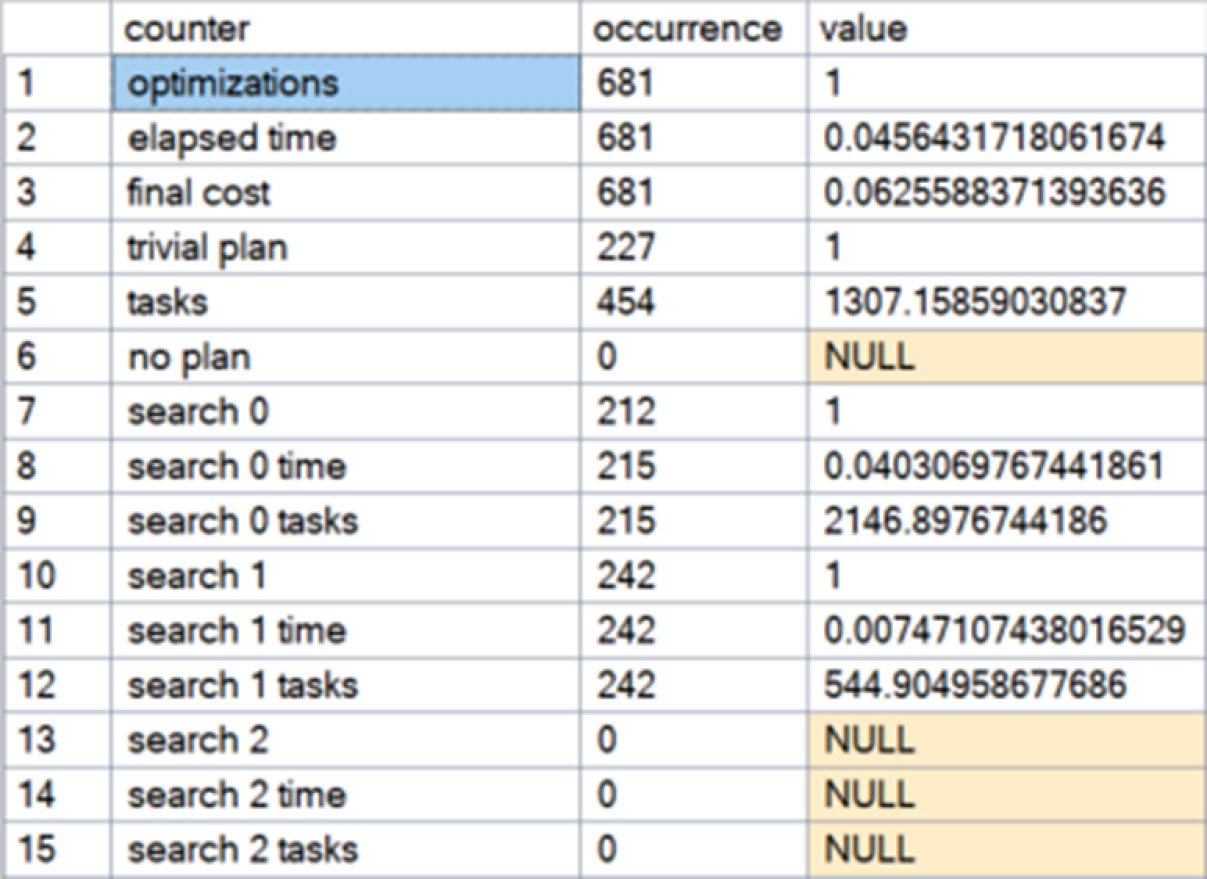
Figure 2-8: Aggregated information about the optimization processes
這份資料是整體聚合。要量測單一查詢的優化行為,必須在隔離環境執行查詢前後比對,不然會被其他查詢汙染。
並行執行計畫(Parallel Execution Plans)#
複雜查詢可由多個 CPU 共同處理,但並行 不是免費的:
- 並行本身有額外開銷(協調、合併)
- 不需要並行的查詢被強制並行反而更慢
- 並行會吃更多 CPU 與 記憶體
優化器決定是否走並行時會考量:
- SQL Server 可用的 CPU 數量
- SQL Server 版本(edition)
- 可用記憶體
- Cost Threshold for Parallelism
- 查詢內容、預估列數、目前並行連線數
- Max Degree of Parallelism (MAXDOP)
其中三項最關鍵:CPU 數量、Cost Threshold for Parallelism、MAXDOP。
設定 MAXDOP#
USE master;
EXEC sp_configure 'show advanced option', '1';
RECONFIGURE;
EXEC sp_configure 'max degree of parallelism', 2;
RECONFIGURE;不要把 MAXDOP 設為 1(會完全停用並行);預設值 0(用所有 CPU)通常也不適合一般 production 工作負載。
可在單一查詢層級用提示控制:
OPTION (MAXDOP 2),但 query hint 應極為謹慎使用。
設定 Cost Threshold#
預設值 5 對絕大多數系統都太低。作者強烈建議調高:
EXEC sp_configure 'cost threshold for parallelism', 35;
RECONFIGURE;合理值的判斷方式之一:撈出 plan cache 中所有計畫的估算成本作為依據。
直接查詢 plan cache 並解析 XML 的成本不低,避免在 production 高峰期執行。
並行執行的限制#
- 所有 DML 都是序列化執行的——
SELECT內含於INSERT、或UPDATE/DELETE的WHERE子句可以走並行,但實際的資料變更永遠是序列 - 系統承壓時,SQL Server 會自動降低或放棄並行
- 執行階段才決定使用的 thread 數,整個查詢生命週期不變;下次執行可能又不同
執行計畫快取(Plan Cache)#
優化結束後產生的執行計畫會放進 plan cache——這是 SQL Server 為了避免重複優化所做的另一層優化。
老化機制(Aging)#
plan cache 與資料頁共享 buffer cache。為避免無限膨脹:
- 每個計畫進入快取時設一個 age 欄位,初值等於該計畫的編譯成本
- Lazy writer 定期掃描,未被重用的計畫成本逐步遞減
- 一旦成本降到 0,就成為被踢出的候選
- 記憶體承壓時,所有成本為 0 的計畫會被釋放
當計畫被重用時,age 會被重新拉回最大成本。所以即使昂貴計畫被重用得不頻繁,因為起始值高,仍可能比便宜計畫更晚被淘汰。
想理解計畫被重用 / 被踢出的行為,要記住兩個方向的力:重用會把成本拉滿、lazy writer 會讓成本下降。兩者拉鋸決定計畫在快取中的壽命。
本章定調#
理解優化器並不需要看原始碼。掌握以下幾個關鍵心智模型即可解釋大部分查詢效能行為:
- 解析 → 繫結 → 優化的三段預處理
- Trivial Plan、三階段搜尋、Early Termination 的取捨
- 列數估算驅動所有成本計算
- 並行不是萬靈丹,需審慎開啟
- 計畫被快取,但會在記憶體壓力下被踢除
下一章將進入「怎麼量測查詢效能」——找出你該調哪一個查詢的工具與方法。