為什麼沒有「跑快一點」的開關#
到了 2025 年,SQL Server 仍然沒有一個按下去就能讓查詢飛起來的魔法開關。Fritchey 在第一章開宗明義地強調:
唯一可以「不費力」加快效能的辦法,是花更多錢——買更大的伺服器、升上更高的雲端服務層。但預算總有上限,超過之後就只能靠時間換成果。
近期還多了一條捷徑:詢問大型語言模型(LLM)/ AI。這的確可以提供方向,但你仍須理解它說了什麼,並驗證它的建議是否真的有效。這正是查詢效能調校工作真正開始的地方。
不論你是在自建機房(on-prem)、Google Cloud SQL、Amazon RDS、Azure SQL Database,還是 Kubernetes / VM 上跑 SQL Server,本書介紹的方法在所有環境通用。
本書的核心任務#
作者不打算給「看到 A 就做 Z」的速查表,因為這種公式並不存在。他將本書聚焦在兩件事:
- 理解(understanding):SQL Server 引擎內部如何運作
- 方法論(methodology):怎麼系統性地找出「到底哪裡出了錯」
書中會涵蓋的主要工具與主題:
- 用 Extended Events 觀察查詢行為
- 識別與處理封鎖(blocking)
- 讀懂執行計畫(execution plan)
- 統計資訊(statistics)的運作與運用
- 現代化的索引技巧,例如 columnstore
- 重新編譯(recompilation)的成因與處理
- 用 Query Store 找出與修正慢查詢
- 優化器自動化的協助
- 適合運用 AI 的場景
- 整合以上元素的查詢調校方法論
查詢效能調校流程#
實務上,調校是一個持續循環的過程。作者把核心流程濃縮為五步:
- 找出瓶頸(identify the bottleneck)
- 修正它(fix it)
- 驗證修正(validate the fix)
- 量測影響與目前效能
- 下一個瓶頸——回到第 1 步
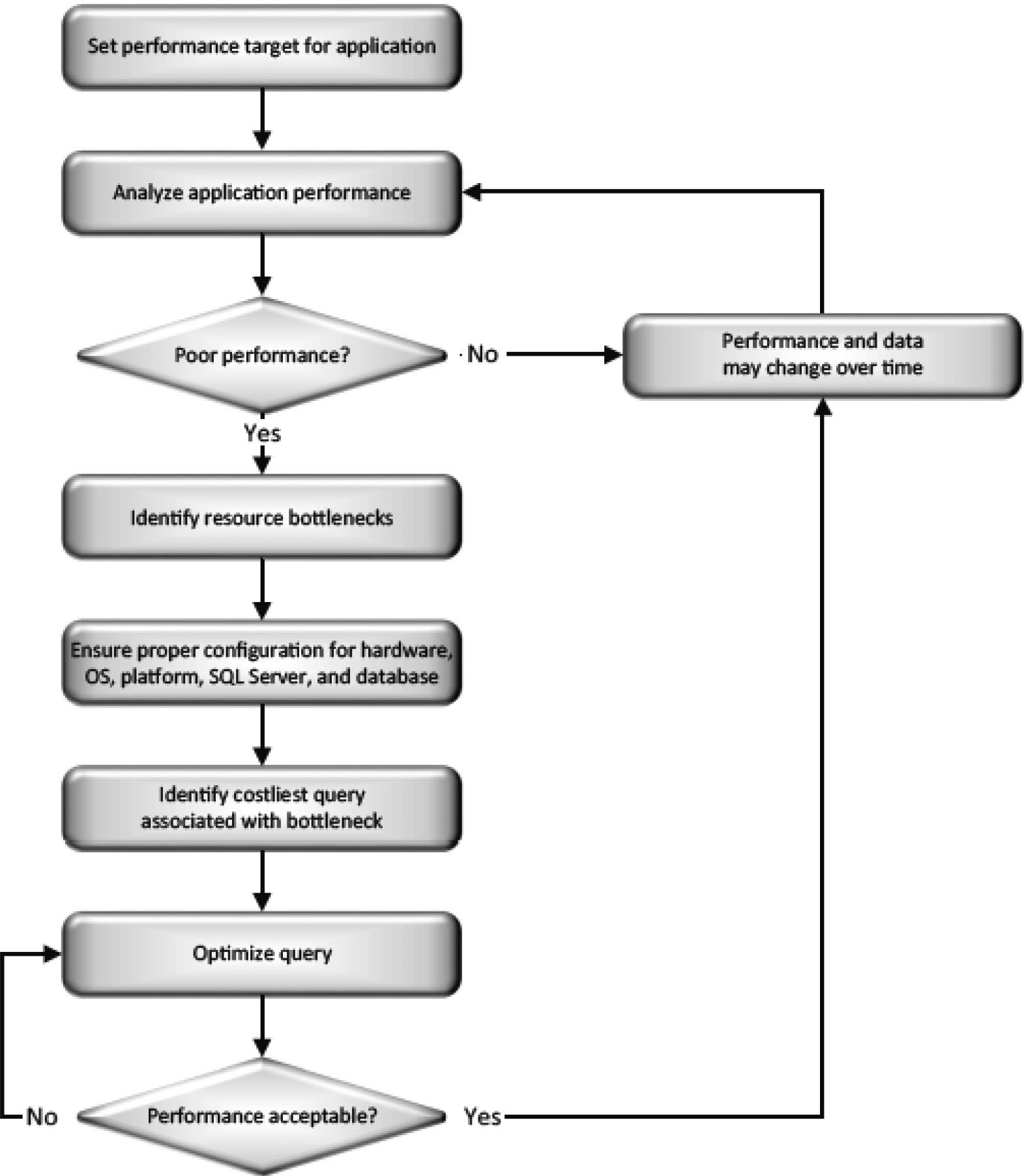
Figure 1-1: The core performance tuning process
每次只改一件事(change only one thing at a time)。任何結構或程式碼的更動都可能波及其他查詢,逐一更動才能精準量測哪一項真正帶來改善、哪一項其實是退步。
例如新增一條索引也許能讓某個 SELECT 變快,卻會:
- 讓其他原本走別的索引的查詢被迫改走新索引而變慢
- 讓所有 INSERT / UPDATE / DELETE 因為要維護額外索引而變慢
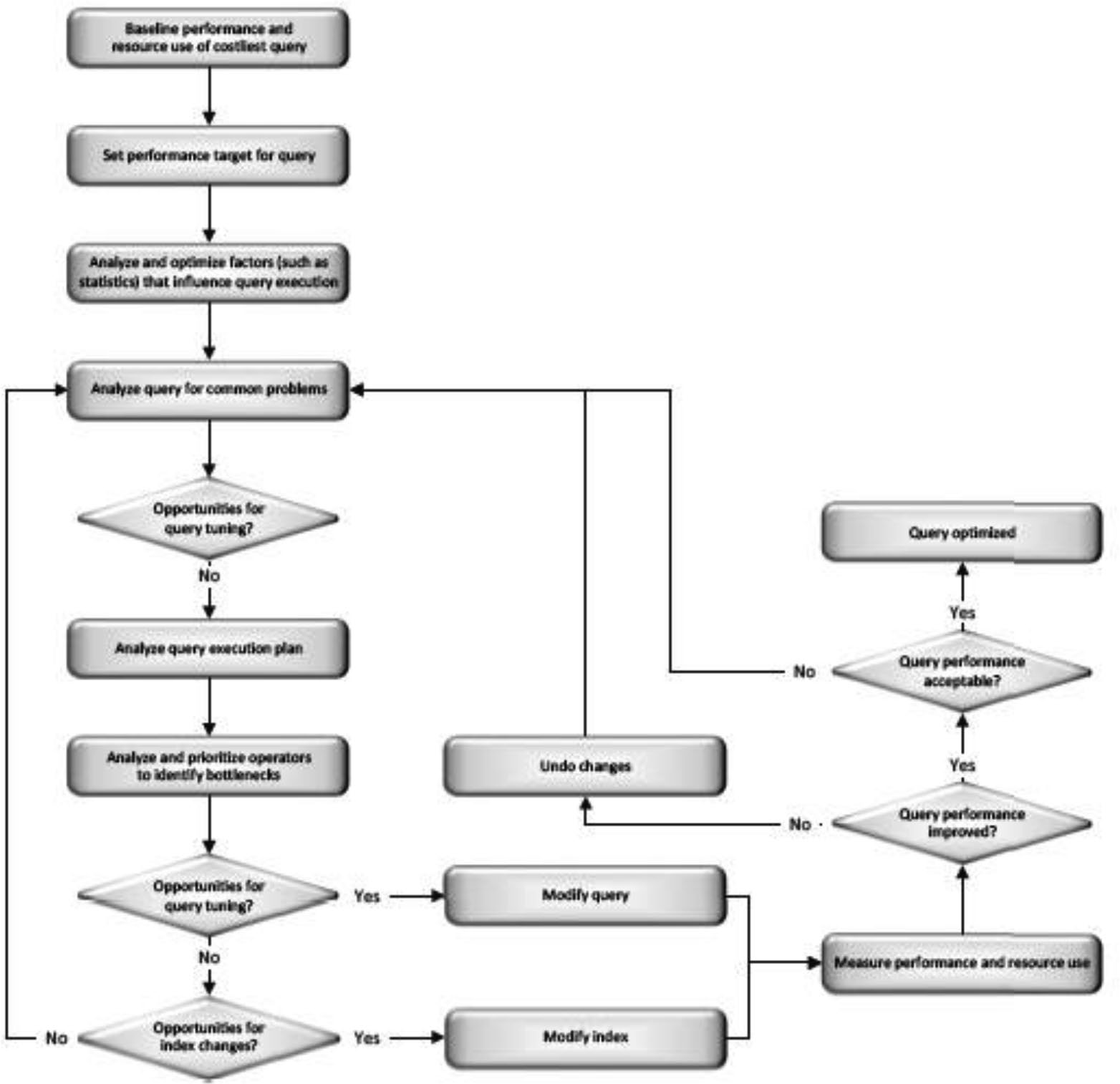
Figure 1-2: The core query tuning process
提交給公開 AI 的查詢可能含有機密資料,請小心。並且 不要盲信 AI 的建議——AI 幻覺(hallucination)真的會發生。所有建議都應與書中內容一樣,自行測試與驗證。
查詢以外的效能殺手#
效能問題不一定出在查詢與索引。Fritchey 列出可能的「外部因素」:
- 雲端服務層級不足(service tier inadequate)
- 同伺服器上其他應用程式吃資源
- SQL Server 服務本身的設定錯誤
- 硬體 / VM 的容量不足
- 網路硬體或設定問題(路由器、線材、Wi-Fi)
- 應用程式或報表設計沒最佳化
- 容器(container)資源管理錯誤
- 資料庫設計(normalization、資料型別)不當
- 關聯式資料庫並非合適選擇(例如大量 IoT、半結構化資料)
物件關聯對映(Object Relational Mapping, ORM)能加速開發,但設定錯誤時會產出「噩夢級查詢」。請與開發團隊建立 ORM 使用的最佳實踐。
什麼叫做「夠好(good enough)」#
優化器(optimizer)本身採用「good enough」策略——不追求完美,只求足夠優化而不耗費過多資源。Fritchey 建議調校工作也應採同樣思維:
- 不可能也不值得把每個查詢調到極限的最後一個微秒
- 一個跑 10ms 的查詢若每分鐘被呼叫上千次,少 1ms 就是救命;同樣 30ms 但一小時只跑幾次的查詢,去調根本浪費時間
- 時間成本才是關鍵——監測、解讀、讀計畫、測試解法都需要時間,把時間花在真正影響系統的查詢上
建立比較基準(comparison points)#
要驗證調校是否有效,必須有「之前」與「之後」可以對照。作者建議的比較基準有:
- 系統內所有查詢(甚至到單一語句)的完整量測
- 應用程式 / 報表的端到端往返時間(round-trip time)
- 從 plan cache 取得的近期查詢行為
- 直接執行查詢觀察當下表現(不建議對已嚴重負載的系統或資料修改查詢這樣做)
- 在非 production 環境執行——慢查詢仍是慢查詢
不要只看「執行時間」這一項指標。CPU、磁碟 I/O、記憶體 同樣重要。有時候讓查詢「稍微變慢但少吃 I/O / 記憶體」反而是整體系統的勝利,端看瓶頸在哪。
最常見的效能問題#
作者引述 Paul Randal 數年前進行的調查(至今仍適用),指出 64% 的效能問題集中在程式碼、索引、資料結構與統計資訊 這幾項。常見十大問題:
- 索引不足或不佳(insufficient or poor indexes)
- 統計資訊不準或缺失(inaccurate or missing statistics)
- 糟糕的 T-SQL
- 問題執行計畫(problematic execution plans)
- 過度封鎖(excessive blocking)
- 死結(deadlocks)
- 非集合式運算(non–set-based operations,例如游標)
- 資料庫設計錯誤
- 執行計畫重用率低(poor execution plan reuse)
- 頻繁重新編譯(frequent recompilation)

Figure 1-3: Root causes of poor performance
重點解讀#
- 索引太多也是病:每多一條索引,所有 INSERT / UPDATE / DELETE 都要額外維護,SELECT 在索引更新期間也會被擋。
- 統計資訊大多自動維護:但資料異動劇烈時仍可能過時,或被人為關閉自動更新功能。
- T-SQL 寫法決定一切:再好的索引與統計,也救不了一個搬太多資料、寫法導致無法走索引、或過於複雜讓優化器無從下手的查詢。
- 「壞執行計畫」其實不存在:優化器產出的計畫都「能用」,只是有的好有的差。多數能透過改寫程式碼、更新統計、加索引修正;參數探嗅(parameter sniffing)出問題時則需特別處理(第 13 章)。
- 封鎖與死結是不同主題:死結是因封鎖而起,但要分開思考。死結最痛的不是查詢失敗,而是被選為犧牲者那一方的回滾(rollback)成本與後續重送。
- 逐列處理是效能殺手:游標、迴圈會強迫 SQL Server 用 row-by-row 模式,違反集合式(set-based)設計初衷。
- 設計與索引是同一件事:clustered index 與 clustered columnstore 直接決定資料儲存與取回方式;資料型別放錯(例如把日期存成字串)會直接拖垮效能與索引可用性。
完整的關聯式資料庫設計議題作者推薦另一本書:Louis Davidson, Pro SQL Server Relational Database Design and Implementation(Apress, 2020)。
本章定調#
這一章不教任何具體的技術操作,而是建立後續所有章節共用的心智框架:
- 量測 → 比較 → 修正 → 驗證 → 再量測 是反覆的循環
- 每次只動一件事
- 不追求完美,追求「夠好」
- 把時間花在影響大的查詢上
- 同時觀察時間、CPU、I/O、記憶體
下一章將深入優化器(query optimizer)的運作機制,並介紹執行計畫——它正是我們用來窺視優化器決策的窗口。