Continuous Integration#
Continuous Integration(CI)的傳統定義是「團隊成員頻繁整合各自的工作,每次整合都透過自動化建置(含測試)來儘早偵測整合錯誤」。簡單來說,CI 的核心目標是自動且儘早地攔截有問題的變更。
在現代分散式系統中,「整合」的範圍遠不止版本庫中的程式碼。微服務、資料更新、機器學習模型、作業系統、雲端平台、裝置等都是依賴項,它們各自由不同團隊甚至不同公司擁有,並按獨立的時程部署。隨著微服務趨勢興起,破壞應用程式的變更不太可能出現在專案本身的程式碼庫中,反而更可能來自網路呼叫對面那些鬆散耦合的微服務。依賴關係從函式呼叫堆疊轉移到了 HTTP 請求或 RPC。
因此,本章提出更全面的定義:
Continuous Integration:持續地組裝並測試我們整個複雜且快速演進的生態系。
從測試的角度看,CI 是一套決策框架,用來回答兩個問題:
- 在開發與發布流程的哪個階段,該執行哪些測試?
- 在每個階段中,受測系統(SUT)應如何組成,以平衡保真度(fidelity)與建置成本?
例如,哪些測試在 presubmit 執行?哪些留到 post-submit?哪些延後到 staging 部署?各階段對 SUT 的需求可能截然不同——presubmit 的 SUT 若與真正的正式後端溝通可能帶來安全與配額風險,但 staging 環境通常可以接受。
CI 帶來可驗證且及時的品質保證,讓團隊不必仰賴每位工程師都謹慎無誤,而是透過自動化機制在建置到發布的各階段確保應用程式的正常運作,進而提升產品信心、品質與團隊生產力。
CI 核心概念#
快速回饋迴圈(Fast Feedback Loops)#
如第 11 章所述,bug 越晚被發現,修復成本呈近指數級增長。下圖呈現一個有問題的程式碼變更在生命週期中可能被攔截的各個階段。
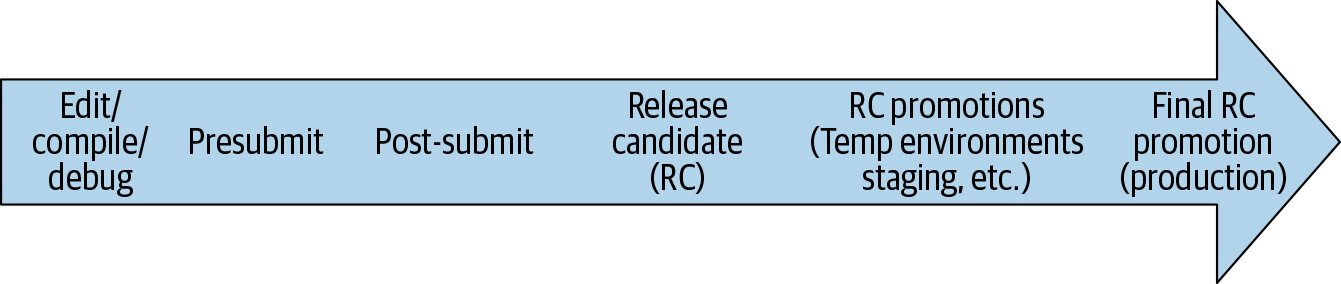
Figure 23.1: Life of a code change
越往右方發現問題,代價越高,原因包括:
- 需要一位不熟悉該變更的工程師進行分類(triage)
- 變更作者要花更多時間回想並調查
- 對其他工程師甚至終端使用者造成負面影響
CI 鼓勵使用快速回饋迴圈。每次將變更整合至測試情境並觀察結果,就是一個新的回饋迴圈。常見的回饋形式(由快到慢)包括:
- 本地開發的 edit-compile-debug 迴圈
- Presubmit 時自動測試結果回報給變更作者
- Post-submit 整合測試偵測到兩個專案之間的相容問題
- 上游微服務部署新版後,QA 在 staging 環境發現不相容
- 內部使用者(搶先於外部使用者啟用功能)的 bug 回報
- 外部使用者或媒體回報的 bug 或故障
Canarying(先部署到一小部分正式環境)能縮小影響範圍,以一個「正式環境子集」的初始回饋迴圈來先行驗證。然而,canarying 在多版本同時部署時可能引發 version skew——分散式系統中存在多個互不相容的程式碼、資料或配置版本的狀態。
Experiments 與 feature flags 則是極為強大的回饋機制,可將變更隔離在可動態切換的模組化元件中,降低部署風險。大量依賴 feature flag 是 Continuous Delivery 的常見範式。
可取得且可行動的回饋(Accessible and Actionable Feedback)#
CI 回饋必須具備兩項特質:
- 廣泛可見:Google 有統一的測試報告系統,任何人都能查閱任何建置或測試的日誌與歷史紀錄(排除使用者 PII),包含每次建置的切割點、執行位置與執行者。這種可見性讓不同團隊能共同診斷並從系統間的整合失敗中學習。
- 可行動:回饋要能幫助工程師快速定位並修復問題,而非僅告知「失敗了」。透過改善測試輸出的可讀性,等於自動化了對回饋的理解。
此外,Google 有 flake classification 系統,利用統計方法在全公司層級分類不穩定測試(flaky tests),讓工程師無需自行判斷測試失敗是否與自己的變更有關。Bug 也是全公司公開的(排除客戶 PII),包含完整的評論歷史供所有人查閱與學習。
自動化(Automation)#
自動化開發相關任務在長期內能節省工程資源。因為自動化流程是以程式碼定義的,check in 時的 peer review 可降低錯誤機率。自動化流程當然也會有 bug,但有效實施時,仍比手動操作更快、更容易且更可靠。
CI 具體而言自動化了建置與發布流程,包含 Continuous Build 和 Continuous Delivery,並在整個流程中施加 Continuous Testing。
Continuous Build(CB)#
Continuous Build 整合最新的 head 程式碼,執行自動化建置與測試。「破壞建置」或「建置失敗」包含編譯失敗和測試失敗兩者。
Head 是 monorepo 中最新版本的程式碼。在其他工作流程中也稱為 master、mainline 或 trunk。在 head 整合也稱為 trunk-based development。
變更提交後,CB 執行所有相關測試。通過則標記為「綠色」(green)。此流程引入了兩個版本的 head:
- True head:最新提交的變更
- Green head:最近一個通過 CB 驗證的變更
工程師通常同步 green head 以取得經 CB 驗證的穩定開發環境,但提交流程要求先同步到 true head。
Continuous Delivery(CD)#
Continuous Delivery 的第一步是發布自動化(Release Automation),持續從 head(Google 多數團隊選擇 green head)組裝最新的程式碼與配置為 Release Candidate。
Release Candidate(RC):由自動化流程建立的、可部署的內聚單元,包含通過 Continuous Build 的程式碼、配置及其他依賴項。
RC 中包含配置至關重要——大量正式環境 bug 來自「愚蠢的」配置問題,因此靜態配置需與程式碼一起測試,並隨 RC 一起晉升(promote)。這不代表要將配置編譯進 binary——動態配置(如 experiments 或 feature flags)在許多場景中更為推薦。但靜態配置確實應納入版本控制,與程式碼經歷相同的 code review 流程。Version skew 經常在 RC 晉升過程中被捕獲。
CD 的完整定義為:
Continuous Delivery(CD):持續組裝 release candidate,接著在一系列環境中晉升並測試這些 candidate——有時到達正式環境,有時則不會。
對於希望從正式環境中持續獲得新變更回饋的團隊(即 Continuous Deployment),持續推送通常很大的整個 binary 並不可行。因此,透過 experiments 或 feature flags 進行選擇性的 Continuous Deployment 是常見策略。
RC 在環境間推進時,其產出物(binary、container)理想上不應重新編譯或重建。使用 Docker 等容器技術有助於確保 RC 從本地開發到各環境的一致性;使用 Kubernetes(或 Google 的 Borg)等編排工具有助於確保部署間的一致性。透過強制發布與部署的一致性,可實現更高保真度的早期測試,減少正式環境的意外。
Continuous Testing(CT)#
下圖展示 CB 與 CD 如何搭配 Continuous Testing,在程式碼變更的整個生命週期中提供持續測試。
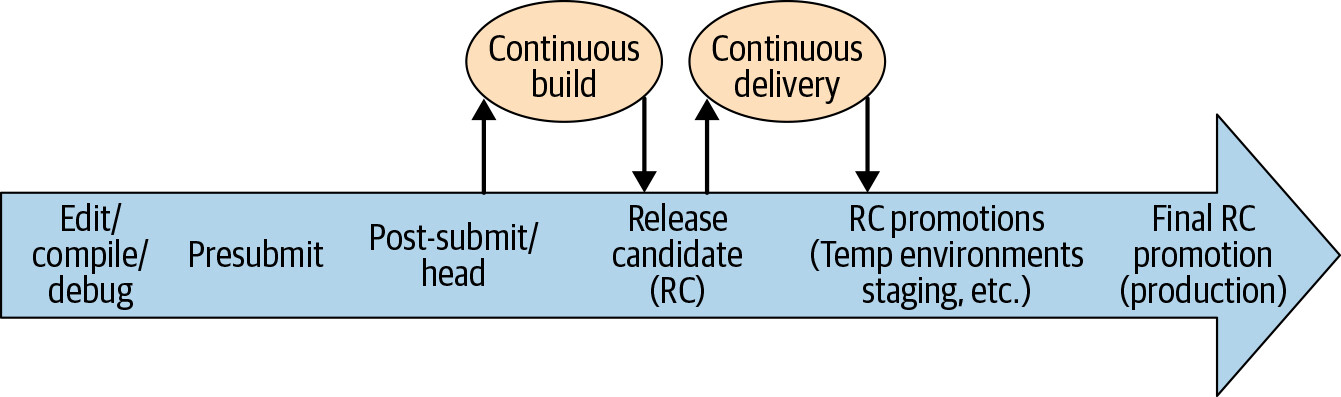
Figure 23.2: Life of a code change with CB and CD
向右的箭頭表示單一程式碼變更從本地開發到正式環境的推進。CI 的關鍵目標之一便是決定在此推進過程中的每個階段該測試什麼。隨著變更往右推進,它將接受範圍逐漸增大的自動化測試。
為何只靠 Presubmit 不夠#
在 presubmit 跑所有測試的代價太高。工程師生產力極為珍貴,等待太久會嚴重影響開發節奏。移除 presubmit 必須窮盡的限制後,反而能帶來效率提升——例如限定測試範圍,或根據預測模型選擇最可能偵測到失敗的測試。
不穩定測試在 presubmit 造成的阻塞代價也很高——許多工程師為同一個與自己變更無關的問題消耗時間。
另一個問題是空中碰撞(mid-air collision):在 presubmit 測試期間,底層 repository 可能已發生不相容的變更。兩個觸及完全不同檔案的變更仍可能導致測試失敗。在 Google 的規模下,這種情況幾乎每天都發生。較小的 repository 或專案可透過序列化提交來避免此問題。
Presubmit vs. Post-submit#
經驗法則:presubmit 只執行快速且可靠的測試。可接受 presubmit 有些微覆蓋率損失,但需在 post-submit 捕獲遺漏的問題,並接受少量回滾。在 post-submit,可接受較長執行時間和一定程度的不穩定性,只要有適當的機制處理。
Google 多數團隊在 presubmit 執行小型測試(如單元測試)——它們通常最快且最可靠。較大範圍的測試是否在 presubmit 執行因團隊而異。Hermetic testing 是降低大範圍測試固有不穩定性的有效方法;另一種做法是允許大範圍測試在 presubmit 不穩定,但在開始頻繁失敗時積極停用。
不要為了等待慢測試或太多測試而浪費工程師的生產力。Google 通常將 presubmit 測試限制在變更所在專案的測試,並以並行方式執行,資源分配也是決策的一部分。
Release Candidate 測試#
程式碼變更通過 CB 後(若有失敗可能需多個週期),將被納入待發布的 RC。CD 建置 RC 時,會對整個 candidate 執行更大規模的測試。RC 測試透過在一系列環境(包含沙箱化的臨時環境和 dev/staging 等共用環境)中晉升 RC 並逐一部署驗證來進行,也常包含對 RC 的手動 QA。
即使 CB 已在 post-submit 跑過相同的測試套件(假設 CD 從 green head 切割),對 RC 重跑仍有其價值:
- 健全性檢查(Sanity check):確保程式碼在 RC 中切割與重編譯時沒有異常
- 可稽核性(Auditability):測試結果與 RC 直接關聯,工程師無需翻查 CB 日誌
- 支援 Cherry pick:若對 RC 施加 cherry-pick 修復,原始碼已與 CB 最新測試的版本分歧
- 緊急推送(Emergency push):CD 可從 true head 切割並執行最少量必要測試,無需等待完整 CB 通過
正式環境測試(Production Testing)#
持續自動化測試流程延伸到最終部署環境——正式環境。應在正式環境執行與 RC 相同的測試套件(有時稱為 probers),以驗證兩件事:(1) 正式環境依據測試顯示的運作狀態,以及 (2) 測試本身依據正式環境顯示的攸關性。
各階段的持續測試(各有其取捨)體現了縱深防禦(defense in depth) 的價值——品質與穩定性不依賴單一技術或政策,而是多種測試方法的組合。
CI 即是警報(CI Is Alerting)#
CI 和正式環境監控/警報服務的目的相同——儘快識別問題。CI 關注開發流程的前端(透過測試失敗來發現問題),警報關注後端(透過監控指標並在超過閾值時通報)。兩者都是「自動且儘早發現問題」的手段。
良好的 CI 系統確保建置處於健康狀態(程式碼可編譯、測試通過、隨時可部署新版本),正如良好的警報系統確保 SLO 達標。兩者的最佳實踐都聚焦於 fidelity 和 actionable alerting:
- 測試應只在重要不變量被違反時失敗,而非因脆弱或不穩定
- 每隔幾次 CI 就失敗的 flaky test,如同每幾分鐘就觸發的假警報一樣有害
- 不可行動的就不該發出警報;不違反 SUT 不變量的就不該算測試失敗
CI 和警報在失敗模式上也有共通之處。脆弱的 cause-based alert 基於任意閾值(例如過去一小時的重試次數)觸發,而該閾值未必與終端使用者感受到的系統健康有根本關聯。脆弱的測試基於任意的測試要求或不變量失敗,而該不變量未必與軟體正確性有根本關聯。兩者都只是整體健康/正確性的粗略代理,未能捕捉整體行為。
在實際故障發生時,兩者仍有除錯價值。SRE 除錯中斷時,「一小時前使用者開始遇到更多失敗請求,同時重試次數也開始上升」這類 cause-based 資訊是有用的。同樣地,「影像渲染管線開始輸出亂碼,其中一個單元測試顯示 JPEG 壓縮器回傳了不同的位元組」也能協助定位問題。
將 CI 視為警報的「左移(left shift)」,可引出實用的策略思考:
- 追求 CI 100% 綠燈如同追求正式服務 100% uptime,代價極高。最大的問題之一是測試與提交之間的競爭條件
- 不是所有測試失敗都預示正式環境問題——如同正式環境警報觸發但服務未受實際影響時應靜音警報,CI 中已知與問題無關的失敗測試也應更靈活地停用
- 「最新 CI 非綠即禁止提交」的政策可能過於僵化——失敗確實應調查,但若根本原因已明確且不影響正式環境,一律封鎖提交並不合理
這個「CI 即是警報」的洞見尚屬新穎。SRE 領域在監控與警報方面已投入大量思考,而 CI 過去常被視為「奢侈品」。未來幾年的軟體工程任務是看看既有的 SRE 實踐能否在 CI 領域重新概念化,或者測試的最佳實踐是否能反過來釐清監控與警報的目標和政策。
CI 的挑戰#
實施 CI 時常見的額外挑戰包括:
- Presubmit 最佳化:在已知的生產力干擾(不穩定、緩慢、衝突或過多的測試)限制下,決定哪些測試在 presubmit 執行、如何執行
- 元兇定位與失敗隔離(Culprit finding and failure isolation):哪個變更或系統導致了問題?在分散式架構中,「整合上游微服務」是一種隔離方法——將自己穩定的伺服器與上游微服務的新版一起部署於 staging 環境中測試。然而 version skew 使這些環境常常不相容,還可能遇到偽陽性
- 資源限制:測試需要計算資源,大型測試可能非常昂貴;在整個流程中插入自動化測試的基礎設施成本也相當可觀
失敗管理(Failure management) 是另一大挑戰。大型端對端測試天生容易壞或不穩定,難以除錯。需有機制暫時停用並追蹤這些測試,以免阻礙發布。Google 常用 bug hotlist 記錄,由 on-call 或 release engineer 建立並分派至相應團隊。某些大型產品(如 Google Web Server 和 Google Assistant)甚至能自動產生與歸檔這些 bug。Hotlist 需妥善整理——阻礙發布的 bug 必須立即修復,非阻礙項也應排定優先順序,以免測試套件淪為一堆停用的舊測試。事實上,端對端測試失敗所揭露的問題,往往出在測試本身而非程式碼。
Flaky tests 會侵蝕對測試套件的信心,類似壞掉的測試,但找出可回滾的變更更困難,因為失敗不會每次發生。某些團隊使用工具暫時從 presubmit 移除 flaky test,在調查修復期間維持信心。允許多次重試也是常見的應對策略,可在測試配置或測試程式碼中的各個層級引入。
Hermetic Testing#
由於與 live 後端溝通本質上不可靠,較大範圍的測試經常使用 hermetic 後端——這在 presubmit(穩定性至關重要時)尤其有用。
Hermetic tests:在完全自包含的測試環境中執行的測試,不依賴任何外部依賴(如正式後端)。
Hermetic tests 具備兩個重要特性:
- 確定性(Determinism / Stability):雖然仍可能受系統時間、亂數產生和 race condition 等不確定性來源影響,但測試的輸入不會因外部依賴而改變。以相同的應用程式碼和測試碼執行兩次,應得到相同結果。若 hermetic test 失敗,你知道原因在應用程式碼或測試碼的變更(極少數例外是 hermetic 測試環境本身的結構變更)。
- 隔離性(Isolation):正式環境問題不影響這些測試,反之亦然。這些測試通常在同一台機器上執行,無需擔心網路連線問題。測試結果也不應受執行者影響,任何人都能重現 CI 系統執行的測試。
實現 hermetic testing 的方式包括:
- Fakes(參見第 13 章):比真實後端便宜但需維護,保真度有限
- 完全沙箱化(Fully sandboxed):啟動整個技術堆疊進行測試。適合較小應用,但 Google 也有大規模案例——DisplayAds 在每次 presubmit 以及持續在 post-submit 從零啟動約 400 台伺服器。不過後來 record/replay 已成為大型系統更受歡迎的方式,通常也較便宜
- Record/Replay(參見第 14 章):錄製 live 後端回應、快取並在 hermetic 環境中重播。能有效降低不穩定性,但需在兩端之間取得平衡:
- 偽陽性(False positives):命中快取過多,測試通過但不該通過,錯過了真正的問題
- 偽陰性(False negatives):快取命中不足,測試失敗但不該失敗,需更新回應(耗時且常阻礙提交)
理想情況下,record/replay 系統應只在請求以有意義的方式改變時才觸發 cache miss。實務上,在大型且持續變化的系統中判斷「什麼是有意義的改變」極為困難。
Google Assistant 的 Hermetic 實踐:Google Assistant 團隊將 presubmit 測試全面轉為 hermetic 後,執行時間縮短了 14 倍,幾乎消除了不穩定性。之前使用非 hermetic 測試時,某些天有超過 50 個變更繞過並忽略測試結果。轉為 hermetic 後仍會出現失敗,但這些失敗通常容易定位並回滾。
非 hermetic 測試被推到 post-submit 後,失敗開始在那裡累積。除錯端對端測試仍然困難,某些團隊甚至直接停用它們——這比阻止所有人的開發好,但可能導致正式環境故障。團隊持續面臨的挑戰包括:微調快取機制以在 presubmit 攔截更多問題,以及在 Assistant 日益去中心化為微服務架構的情況下進行 presubmit 測試。
對於 post-submit 失敗隔離,團隊採用了一個巧妙策略:為 N 個微服務各自執行一個環境,其中該微服務使用 head 版本建置,其餘 N-1 個服務使用正式版本。透過 hotswapping(允許請求指示伺服器替換呼叫的後端位址)將 O(N^2) 成本降至 O(N)。
Hermetic testing 可同時降低大範圍測試的不穩定性並幫助隔離失敗——解決了前述兩項重要的 CI 挑戰。然而,hermetic 後端也更耗資源且啟動較慢。許多團隊在測試環境中混合使用 hermetic 與 live 後端。
Google 的 CI 實務#
TAP:全球持續建置系統#
TAP(Test Automation Platform)是 Google 的大規模持續建置系統,負責整個 monorepo 的測試。作為 monorepo 的直接結果,TAP 是 Google 幾乎所有變更的閘道。每天處理超過 50,000 個獨立變更,執行超過 40 億個測試案例。
概念上流程非常簡單:工程師嘗試提交程式碼時,TAP 執行相關測試並回報成功或失敗。測試通過則允許變更進入程式碼庫。
Presubmit 最佳化#
為了儘早且一致地攔截問題,確保每個變更都有測試執行是重要的。沒有 CB 時,執行測試通常取決於個別工程師的自覺,結果往往是少數有幹勁的工程師嘗試跑完所有測試並跟上失敗。
為避免長時間等待,Google 的 CB 允許可能有問題的變更先進入 repository(一旦提交就立即對全公司可見)。每個團隊需建立一組快速的 presubmit 測試子集(通常是專案的單元測試,常在送出 code review 前執行)。經驗顯示,通過 presubmit 的變更有 95% 以上的機率通過所有後續測試,因此樂觀地允許其整合,讓其他工程師可以開始使用。
提交後,TAP 非同步執行所有可能受影響的測試,包括較大且較慢的測試。平均等待提交時間約 11 分鐘,通常在背景執行。
Build Cop#
當變更在 TAP 中導致測試失敗時,快速修復以避免阻塞其他工程師至關重要。Google 建立了一項文化規範,強烈反對在已知失敗測試之上繼續提交新工作(雖然 flaky tests 增加了這方面的難度)。
每個團隊設有 Build Cop 角色,負責維護專案中所有測試的通過狀態——不論是誰破壞了它們。收到失敗通知後,Build Cop 放下手邊工作立即處理——通常是識別問題變更並決定回滾(首選方案)或向前修復(風險較高的做法)。
元兇定位(Culprit Finding)#
在 Google 的大型測試套件中,定位具體是哪個變更破壞了測試是一大問題。TAP 每天需評估如此多的變更(每秒超過一個),已無法對每個變更逐一執行每個測試,因此回退到批次處理相關變更以減少需執行的獨立測試總數。雖然加快了測試執行,但可能掩蓋批次中究竟是哪個變更導致測試失敗。
為加速失敗識別,Google 採用兩種方法:
- TAP 自動將失敗的批次拆分為個別變更,對每個變更單獨重跑測試
- 提供 culprit finding 工具,讓開發者可在一批變更中進行二分搜尋,找出可能的元兇
失敗管理(Failure Management)#
隔離出問題變更後,儘快修復至關重要。失敗測試的存在會迅速侵蝕對測試套件的信心。回滾是 Build Cop 最有效的工具——它能快速將系統恢復到已知良好的狀態。TAP 近期已升級為在高度確信元兇時自動回滾變更。
Google 程式碼庫中的任何變更,只需兩次點擊即可回滾。快速回滾與測試套件相輔相成——測試給予變更的信心,回滾給予復原的信心。沒有測試,回滾無法安全執行;沒有回滾,壞掉的測試無法快速修復。
資源限制#
雖然工程師可在本地執行測試,但大多數測試執行發生在名為 Forge 的分散式建置測試系統中,利用 Google 的資料中心最大化平行性。即便擁有大量計算資源,Forge 和 TAP 仍受資源限制。
TAP 判定哪些測試需執行的主要機制是分析每個變更的下游依賴圖(downstream dependency graph)。Google 的分散式建置工具 Forge 和 Blaze 維護近乎即時的全域依賴圖並提供給 TAP,使其能快速判定哪些測試位於任何變更的下游,並執行最少量的測試集。
另一個影響因素是測試速度:觸發較少測試的變更通常比觸發較多測試的變更更快被執行。等待時間的差異(在繁忙日可達數十分鐘)鼓勵工程師撰寫小而精確的變更——這對所有人都是雙贏。
CI 案例研究:Google Takeout#
Google Takeout 始於 2011 年的資料備份與下載產品,倡導「資料解放」(data liberation)理念——使用者應能輕鬆帶走自己的資料。最初團隊自行整合少數 Google 產品,產出使用者照片、聯絡人清單等的封存檔案供下載。但 Takeout 很快壯大,從單一產品的後端發展為 Google 內部廣泛使用的資料擷取與歸檔平台,為 Google Drive、Gmail 等至少 10 個產品提供 API,並整合超過 90 個產品的外掛程式。
情境一:持續壞掉的 Dev Deploy#
問題:隨著 Takeout 成為 Google 廣泛使用的資料工具,愈來愈多團隊要求 API 整合。團隊將每個新 API 部署為客製化的執行個體,使用相同 binary 但配置不同(例如 Drive 批次下載環境擁有最大機隊、最多的 Drive API 配額,以及允許未登入使用者下載公開資料夾的自訂身份驗證邏輯)。為一個 instance 新增的 flag 經常破壞其他 instance,安全性與 ACL 配置也需要隔離(例如消費者 Drive 下載服務不應存取加密企業 Gmail 匯出的金鑰)。配置迅速變得複雜,導致幾乎每晚部署失敗。
做法:團隊為每個 instance 建立臨時沙箱化的迷你環境,在 presubmit 階段測試所有伺服器能否正常啟動。
成效:
- 防止了 95% 因錯誤配置導致的伺服器啟動失敗
- 每晚部署失敗率降低 50%
端對端測試無法在 presubmit 執行(測試帳號仍受到與真實帳號相同的安全與隱私保護,重新設計為 presubmit friendly 的工程量太大)。團隊改為每兩小時在 post-submit 環境中執行,重用 presubmit 的沙箱環境,並從 green head 建立 RC 執行與 dev 環境相同的端對端測試套件。
教訓:更快的回饋迴圈能預防 dev deploy 問題。將端對端測試從「每晚部署後」提前到「post-submit 兩小時內」,有效將嫌疑變更集(culprit set)縮小了 12 倍。
情境二:難以解讀的測試日誌#
問題:隨著整合產品增至 90 多個,端對端測試將所有失敗傾倒到日誌中。即使 post-submit CI 加速了測試頻率,多個失敗仍堆疊在一起,難以檢閱且容易遺漏。翻閱日誌成為令人沮喪的時間黑洞,且測試幾乎總是失敗。
做法:團隊將測試重構為動態、基於配置的測試套件(使用 parameterized test runner),搭配更友善的 UI 清楚呈現個別測試結果(綠/紅),不再需要翻閱日誌。失敗訊息中直接顯示除錯資訊與日誌連結——例如,若 Takeout 無法從 Gmail 擷取檔案,測試會動態建構一個搜尋該檔案 ID 的 Takeout 日誌連結,直接嵌入失敗訊息中。
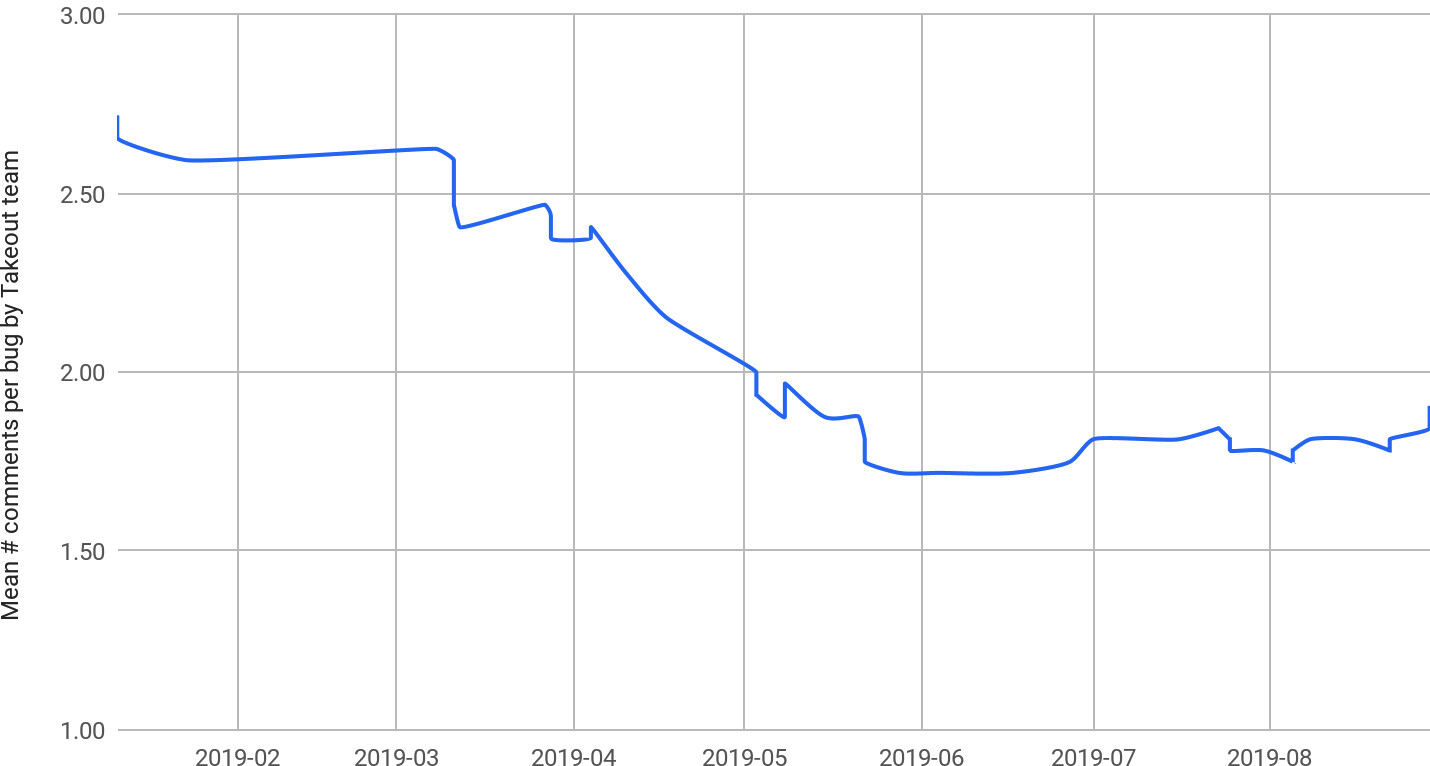
Figure 23.3: The team's involvement in debugging client failures
教訓:可取得、可行動的 CI 回饋能減少測試失敗並提升生產力。這些改進將 Takeout 團隊參與除錯客戶端(產品外掛程式)測試失敗的次數降低了 35%。
情境三:替「整個 Google」除錯#
問題:一個意料之外的副作用——由於 Takeout CI 以封存檔案的形式驗證 90 多個面向終端使用者的產品輸出,它實質上在測試「整個 Google」,能捕獲與 Takeout 完全無關的問題。這對 Google 產品整體品質是好事,但 Takeout 團隊需要更好的失敗隔離能力來區分問題是在自己的建置中(這是少數)還是在所呼叫的產品 API 背後的鬆散耦合微服務中。
做法:團隊在正式環境中持續執行與 post-submit CI 完全相同的測試套件。實施成本低,且能有效區分哪些失敗是新建置引入的、哪些已存在於正式環境中(例如 Google 內某個其他微服務發布造成的)。
教訓:對 prod 和 post-submit CI(使用新建置的 binary 但相同的 live 後端)執行相同測試套件,是隔離失敗來源的低成本方法。
未來改進方向:在 post-submit CI 中引入 hermetic testing 與 record/replay,理論上可消除後端產品 API 的失敗浮出在 Takeout CI 中,使套件更穩定並更有效地捕獲近兩小時 Takeout 變更中的問題。
情境四:保持綠燈#
問題:產品外掛程式持續增加,端對端測試套件幾乎永遠是壞的。許多失敗來自團隊無法控制的外掛程式 binary bug,且並非所有失敗都需要阻擋發布——低優先級的 bug 和測試碼中的 bug 不應封鎖發布,較高優先級的 bug 則需要。另一個常見失敗來源是功能 rollout:例如 YouTube 外掛程式的播放清單擷取功能可能在 dev 環境啟用數月後才在正式環境啟用,而測試只知道一種預期結果。
做法:
- 為失敗的測試標記關聯的 bug 並分派給負責團隊。測試框架抑制已標記的失敗,讓套件保持綠燈,同時確信其他一切(除了已知問題外)是通過的
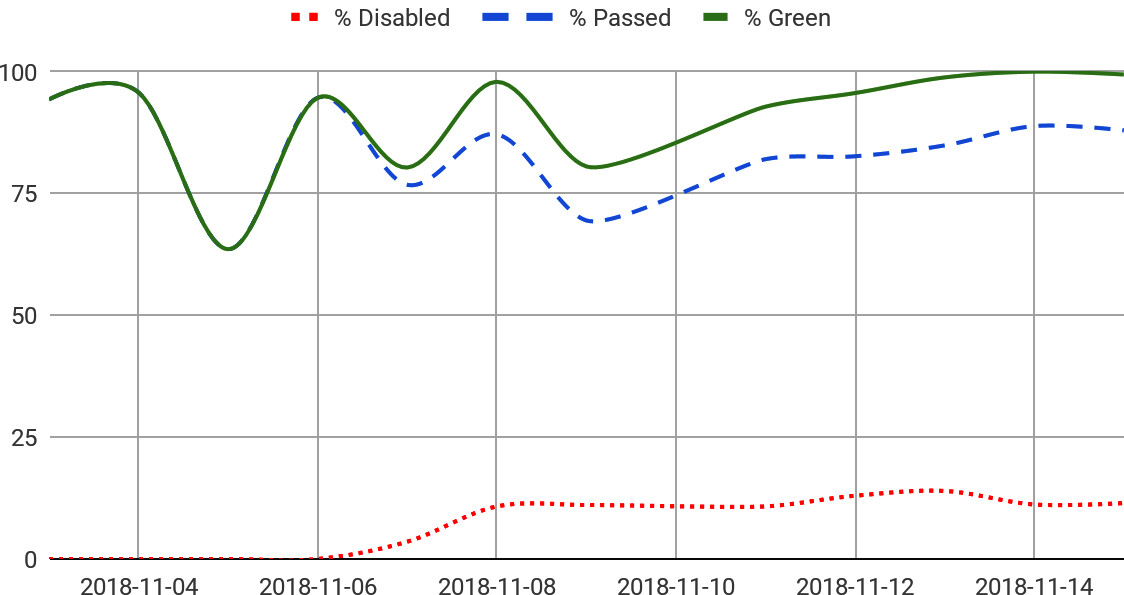
Figure 23.4: Achieving greenness through (responsible) test disablement
- 針對功能 rollout 問題,允許工程師指定 feature flag 名稱或啟用該功能的變更 ID,以及有無該功能時的預期輸出。測試會查詢環境判斷功能是否啟用,並據此驗證
- 自動清理機制:測試透過 bug 系統 API 檢查 bug 是否已關閉。若已標記為失敗的測試實際通過且持續通過超過設定時間,系統會提示清理標記(並標記 bug 為已修復)。Flaky test 例外——標記為 flaky 的失敗不會因偶爾通過而觸發清理提示
這些變更打造出一個大部分能自我維護的測試套件。
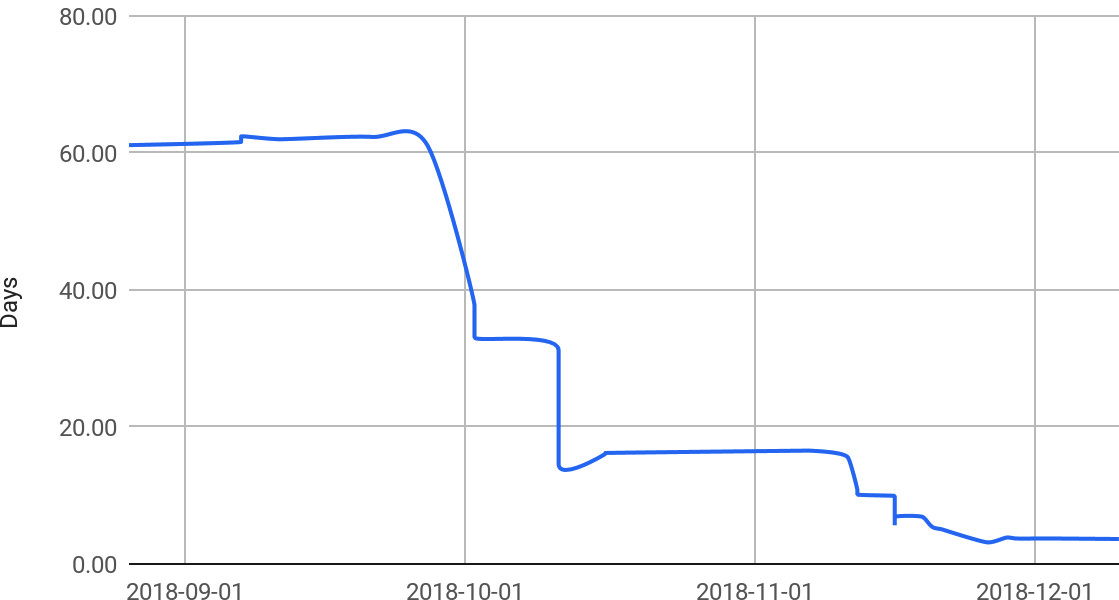
Figure 23.5: Mean time to close bug, after fix submitted
教訓:負責任地停用無法立即修復的測試是保持套件綠燈的務實方法,讓團隊有信心掌握所有測試失敗的狀況。自動化套件維護(包括 rollout 管理和追蹤已修復測試的 bug 更新)能保持套件乾淨並防止技術債累積。圖 23-5 所呈現的指標在 DevOps 術語中可稱為 MTTCU(Mean Time To Clean Up)。
「我負擔不起 CI」#
Google 承認自身擁有的資源可能超過一般新創公司。但許多 Google 產品成長得太快,也沒來得及建立足夠的 CI 系統。
應思考:你目前為在正式環境中發現和處理問題所付出的代價是多少?頻繁的 production fire-fighting 令人疲憊且打擊士氣。CI 的建置成本並非全新的支出,而是將成本左移到更早、更理想的階段,降低問題在過晚階段發生的頻率與代價。CI 帶來更穩定的產品,以及工程師更有信心、更專注於功能開發而非修復問題的團隊文化。
結論#
沒有完美的 CI 系統——CI 系統本身也是軟體,永遠不會「完成」,而需持續調整以滿足應用程式與工程團隊不斷演進的需求。Takeout 案例的演進和指出的未來改進方向正說明了這一點。
TL;DRs#
- CI 系統決定何時使用哪些測試
- 隨著程式碼庫老化與規模增長,CI 系統變得越來越不可或缺
- CI 應在 presubmit 優化更快、更可靠的測試,在 post-submit 執行較慢、較不確定的測試
- 可取得、可行動的回饋讓 CI 系統更加高效