Chapter 21: Dependency Management#
依賴管理(Dependency Management)是軟體工程中最不被充分理解、也最具挑戰性的問題之一。它聚焦於一個核心問題:如何管理我們無法控制的函式庫、套件與依賴網路? 如何在版本之間升級?如何描述版本?當依賴來自外部組織時,我們該如何決策?
與原始碼控制(Source Control)相比,依賴管理在時間與規模兩個維度上增加了複雜度。原始碼控制處理的是「程式碼放在哪裡」這類相對單純的問題;而依賴管理則必須面對在組織邊界之外、缺乏完整可見性與協調機制的情況下,如何應對變更帶來的破壞。上游依賴無法與你的私有程式碼協調,因此更容易破壞你的建置並導致測試失敗。
規模讓所有問題更加複雜。我們真正面對的不是單一依賴的匯入,而是一整個外部依賴網路。當我們開始處理網路時,很容易建構出這樣的場景:你的組織對兩個依賴的使用在某個時間點變得無法滿足——因為其中一個依賴在沒有某個需求的情況下無法運作,而另一個依賴與該需求不相容。
原始碼控制與依賴管理之間的分界線在於:「我們的組織是否控制這個子專案的開發/更新/管理?」 如果控制,那是原始碼控制問題;如果不控制,那就是依賴管理問題。本章最強烈的建議是:在其他條件相同的情況下,優先選擇原始碼控制問題而非依賴管理問題。
本章作者坦承:Google 在依賴管理方面投入了大量思考,但仍無法宣稱已找到在組織間大規模運作的完美解法。本章更多是整理「哪些方法行不通」以及「哪裡可能有更好的出路」。
隨著開源軟體(OSS)模型持續擴展,許多熱門專案的依賴圖也不斷膨脹。現代軟體建立在高聳的依賴之柱上;但我們能堆砌這些柱子,不代表我們已經知道如何讓它們長期穩定。
為什麼依賴管理如此困難?#
許多半成品方案只關注「如何匯入一個套件讓本地程式碼使用」,但這只是必要條件而非充分條件。真正的挑戰在於:如何管理一整個依賴網路及其隨時間的變化? 網路中部分節點是你的第一方程式碼直接需要的,部分只是被傳遞性依賴拉入。但在足夠長的時間內,網路中的每個節點都會有新版本,而其中某些更新至關重要(例如安全漏洞修補、棄用通知等)。
衝突需求與鑽石依賴#
依賴管理的核心難題可以用**鑽石依賴問題(Diamond Dependency Problem)**來說明。當依賴網路中的兩個節點有衝突需求,而你的組織同時依賴它們時,問題就出現了。這可能源自平台考量(作業系統、語言版本、編譯器版本等),也可能是更常見的版本不相容。這個問題至少需要三層依賴結構:
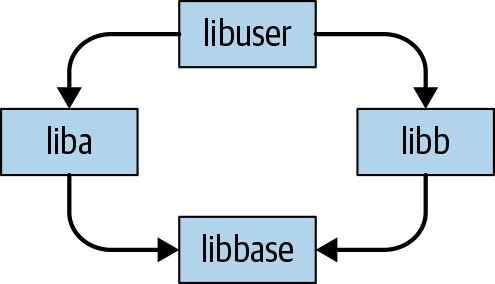
Figure 21.1: The diamond dependency problem
在這個簡化模型中:
libbase被liba和libb同時使用liba和libb又被更高層的libuser(即你的程式碼)使用- 當
libbase引入不相容變更時,liba和libb作為不同組織的產物,不一定會同步升級 - 若
liba依賴新版libbase,而libb仍依賴舊版,libuser就無法同時滿足兩者的需求
這個鑽石可以在任何規模形成:在你的整個依賴網路中,只要存在一個底層節點需要同時以兩個不相容版本出現(因為從某個高層節點到這兩個版本有兩條路徑),就會產生問題。
不同程式語言對鑽石依賴的容忍度不同。Java 提供了較成熟的機制(稱為 shading 或 versioning)來重新命名依賴提供的符號,允許在同一個建置中嵌入多個隔離版本的依賴。C++ 則幾乎零容忍——在正常建置中極可能觸發未定義行為(Undefined Behavior),因為明確違反了 C++ 的 One Definition Rule。
但無論何種語言,當依賴之間需要傳遞型別時,這些變通方案都會失效。例如,在 libbase v1 中定義的 map 根本無法以語意一致的方式傳遞給 libbase v2 提供的 API。
當遇到衝突需求問題時,唯一容易的解法是在版本中前進或後退,找到相容的組合。當這不可行時,就必須在本地 patch 依賴——這特別困難,因為不相容的原因通常不為第一個發現問題的工程師所知。
依賴管理的政策與技術,歸根結底就是在回答一個問題:「如何在允許非協調群體各自變更的同時,避免衝突需求?」如果你有一個方案能解決鑽石依賴問題的一般形式,同時允許在網路各層級持續變更需求,你就描述了依賴管理解法的核心部分。
匯入依賴#
重用現有基礎設施顯然優於從零開發——這是技術進步的基本動力。只要你下載的不是木馬程式,而外部依賴滿足你的需求,就應該使用它。
但當我們把時間納入考量,情況就變得複雜了。即使匯入依賴時無意升級,已發現的安全漏洞、變化的平台、演進的依賴網路都可能強迫你升級。
相容性承諾#
不同專案對相容性的承諾天差地別,作者建議依賴提供者應更清楚地表明其立場:
- C++ 標準函式庫:近乎無限期的向後相容性,包含 API 相容與 ABI(Application Binary Interface)相容。在 Linux 上使用 gcc 的使用者,大約可以在十年範圍內順利運作。標準透過 Standing Document 8(SD-8)定義了版本間允許的小範圍變更類型。Java 也類似:語言版本間原始碼相容,舊版的 JAR 檔可以與新版搭配使用
- Go:明確承諾大多數版本間的原始碼相容性,但不承諾二進位相容性。你無法用一個版本的 Go 編譯函式庫,再連結到另一個版本編譯的 Go 程式中
- Abseil(Google 的 C++ 函式庫):不承諾 ABI 相容,但承諾有限的 API 相容——任何破壞性 API 變更都會附帶自動化重構工具,讓使用者能透明地遷移。內部已有約 2.5 億行 C++ 程式碼依賴此函式庫,所以不會輕率做 API 變更,但必須保留這個可能性
- Boost:不承諾版本間的相容性。它的定位是實驗性的試驗場(proving ground),而非長期穩定的基礎設施。Boost 的開發者與標準函式庫的開發者同樣專業——這純粹是專案目標與優先順序的差異
相容性問題是軟體工程問題而非程式設計問題。你可以下載沒有相容性承諾的 Boost 嵌入關鍵系統——它現在能正常運作。但所有擔憂都在於:這些依賴隨時間如何變化、如何跟上更新、以及如何讓開發者關心維護而不只是讓功能「能動就好」。
更廣泛地說:依賴管理在「程式設計任務」與「軟體工程任務」中有截然不同的本質。如果你純粹是為了今天開發解決方案、不需要更新任何東西,隨意使用依賴完全合理。但如果你的問題空間涉及長期維護,依賴管理就變得困難。
匯入時的考量#
Google 鼓勵工程師在匯入依賴前,先問以下問題:
外部評估:
- 專案是否有可執行的測試?測試是否通過?
- 誰在提供這個依賴?(C++ 標準函式庫 vs. GitHub 或 npm 上的隨機專案,差異巨大。聲譽不是一切,但值得調查)
- 專案追求什麼層級的相容性?有沒有定義預期的使用方式?
- 專案有多受歡迎?多常引入破壞性變更?
- 我們會依賴這個專案多久?
內部評估:
- 在 Google 內部自行實作的複雜度有多高?
- 我們有什麼動機持續保持這個依賴的更新?
- 誰會負責執行升級?升級預計有多困難?
作者坦言,無法給出完美的公式來決定何時匯入、何時自行實作——Google 自己在這方面也常常判斷失誤。
Google 如何處理依賴匯入#
簡短的回答是:做得還不夠好。
Google 絕大多數依賴都是內部開發的,因此大部分的「依賴管理」實際上只是原始碼控制——這是刻意的設計。當提供者和消費者屬於同一個組織、擁有完整可見性和持續整合(CI),大多數依賴管理問題就不再是問題。
外部 OSS 依賴被放入 monorepo 的 third_party 目錄。書中以一個典型場景說明問題:
- Alice 是 Google 的軟體工程師,發現一個 OSS 套件能解決她的問題。為了趕在休假前完成 demo,她把套件加入
third_party - 流程是一份簡單的 checklist:確認能用 Google 的建置系統編譯、確認沒有重複的套件、至少有兩位工程師簽名成為 OWNERS。她找同事 Bob 當共同維護者,兩人都不熟悉套件的實作細節
- 套件開始對其他 Google 團隊可用。新增依賴的行為對 Alice 和 Bob 完全透明——他們可能完全不知道這個套件已變得熱門。即使監控直接使用,也不一定會注意到傳遞性使用的增長
- Charlie 從 Search 基礎設施中新增了對此套件的依賴,使其從無害的 demo 工具一躍成為關鍵基礎設施。但 Charlie 在考慮新增依賴時,沒有任何特別的訊號被呈現
- 某天安全漏洞被揭露,必須緊急升級。但 Bob 已轉任管理職、Alice 早已換團隊,沒人有升級經驗。數千個專案間接依賴此套件——無法直接刪除。多年的 Hyrum’s Law 隱性依賴已經累積
- 結果:一次代價高昂的緊急升級,涵蓋從初次引入到安全揭露之間所有較小版本的差異,且沒人理解實作細節,安全團隊還在施壓要求立即解決
Google 坦承其
third_party政策在這類常見場景中並不適用。他們理解需要更高的維護門檻、讓定期更新更容易(且更有回報),並防止重要套件同時處於「無人維護」狀態。但難處在於:很難對開發者說「不,你不能用這個完美解決你問題的東西,因為我們沒有資源持續更新大家的版本。」
像 Boost 這類熱門但不承諾相容性的專案風險特別高:開發者可能非常熟悉在 Google 外部使用它解決程式設計問題,但讓它融入有著數十年預期壽命的程式碼庫是一個重大風險。
依賴管理理論#
任何好的依賴管理方案都必須能在動態的生態系統中避免衝突需求,包括鑽石依賴版本衝突,即使新的依賴或需求可能在網路的任何節點被加入。它還需要意識到時間的影響:所有軟體都有 bug,部分是安全關鍵的,因此某些依賴在足夠長的時間內必然需要更新。
一個穩定的依賴管理方案必須在時間與規模上都具有彈性:不能假設任何特定節點無限期穩定,也不能假設不會有新依賴被加入。
目前已知的四種方案:
1. 永不變更(Static Dependency Model)#
最簡單的方式:不允許任何 API 變更、行為變更——什麼都不變。Bug 修復只有在不破壞使用者程式碼的情況下才被允許。
- 優點:如果約束一開始可滿足,就能無限期維持
- 缺點:長期而言這是個謊言,而且沒有明確指標告訴你何時會破滅。我們沒有長期的早期預警系統來偵測安全漏洞或其他可能強迫你升級的關鍵問題
- 適用場景:大多數新組織的起點——在證明專案壽命夠長之前,假設什麼都不變是合理的。這對大多數新組織來說可能是正確的模型
- 版本選擇:不存在決策,因為不存在版本
2. 語意化版本(Semantic Versioning / SemVer)#
當前管理依賴網路的事實標準。使用三段式版本號(如 2.4.72):
- Major:對現有 API 的變更,可能破壞既有用法
- Minor:純粹新增功能,不應破壞既有用法
- Patch:不影響 API 的實作細節與 bug 修復,被視為特別低風險
版本需求通常表示為「任何較新版本,排除主版本號變更」。例如「需要 libbase >= 1.5」表示接受 1.5.x、1.6.x,但不接受 1.4.x(缺少 1.5 中引入的 API)或 2.x(某些 API 已不相容地變更)。
如果將這些需求形式化,我們可以把依賴網路概念化為軟體元件(節點)與它們之間需求(邊)的集合。由於整個網路隨時間非同步變化,找到一組滿足所有傳遞性需求的相互相容依賴可能非常具挑戰性。事實上,SemVer 約束應用於依賴網路已被證明是 NP 完全問題。
套件管理器的版本選擇本質上是一個 SAT 求解器問題——尋找滿足所有版本需求約束的版本指派。當找不到解時,就是所謂的「依賴地獄(Dependency Hell)」。
3. 打包發行模型(Bundled Distribution)#
一個組織收集一系列依賴、找到相互相容的組合、作為單一單元發行。典型範例是 Linux 發行版。低層依賴通常比高層依賴更舊一些,以便有時間進行整合。
這個模型引入了新角色——發行商(Distributors)。儘管各個依賴的維護者可能對彼此所知甚少,但發行商負責找到、修補並測試一組互相相容的版本。
對外部使用者而言,只要能完全依賴單一打包發行版,這個模型運作得很好。這等於把依賴網路轉換為一個聚合依賴並給它一個版本號:不是說「我依賴這 72 個函式庫的各個版本」,而是「我依賴 RedHat N 版」或「我依賴 NPM 圖在時間 T 的快照」。
版本選擇由專門的發行商處理。
4. Live at Head#
Google 內部倡導的模型,是 trunk-based development 在依賴管理上的延伸。它明確嘗試從依賴管理中移除時間與選擇的因素:
- 永遠依賴所有東西的最新版本
- 永遠不以讓依賴者難以適應的方式做變更
- 依賴提供者在提交變更前,必須透過 CI 測試整個下游生態系統
- 不使用 SemVer,不釘選版本
- 無意中改變 API 或行為的變更會被下游依賴的 CI 攔截,因此不應該被提交
- 對於必須發生的破壞性變更(例如安全原因),必須先更新下游依賴或提供自動化工具進行就地更新
這個模型中,變更不被簡化為 SemVer 的「我認為這是否安全」。而是用測試與 CI 系統對可見的依賴者進行實驗性測試,以確定變更有多安全。對於只改變效率或實作細節的變更,所有受影響的測試可能都會通過。對於修改 API 可觀察部分的變更,可能會產生數百甚至數千個測試失敗——由變更的作者決定解決這些失敗所需的工作是否值得。
這個模型將成本與激勵放在正確的位置:API 提供者被激勵以易於遷移的方式做變更;API 消費者被激勵維持測試通過,避免被標記為低訊號測試而遭跳過。
版本選擇:「所有東西的最新穩定版本是什麼?」如果提供者負責任地做出變更,一切都會順利運作。
Live at Head 在理論上是健全的,但對參與者施加了新的、高昂的負擔。它目前在 OSS 生態系統中完全沒有先例,如何從現狀過渡到這個模型仍不明朗。在 Google 的組織邊界內,它代價高昂但有效。
SemVer 的局限性#
SemVer 是當前的事實標準,但作為如此普遍的方法,值得深入檢視其潛在缺陷。
一個根本問題:SemVer 的版本號到底是承諾還是估計?當維護者選擇 major/minor/patch 時,他們是在說什麼?從 1.1.4 升級到 1.2.0 是否可證明安全且容易?當然不是——有太多行為不當的使用者可能做出導致建置中斷或行為改變的事情。從根本上說,僅考慮原始碼 API 無法證明任何相容性;你必須知道你在問與什麼東西的相容性。
然而,當我們談論依賴網路和應用於這些網路的 SAT 求解器時,這種「估計」的概念就開始動搖了。傳統 SAT 圖中的節點值是 True 或 False;而依賴圖中的版本值是維護者提供的相容性估計。我們在一個不穩固的基礎上建構所有的版本滿足邏輯,把估計和自我證明當作絕對值。
SemVer 可能過度約束(Overconstrain)#
想像 libbase 只有兩個函式 Foo 和 Bar,而 liba 和 libb 都只使用 Foo。若維護者對 Bar 做了破壞性變更,依照 SemVer 規則必須 bump 主版本號。此時 SemVer 求解器會拒絕讓 liba、libb 使用新版——但實際上它們完全不受影響,因為只有 Bar 改了,而 Bar 未被使用。
「我做了破壞性變更,必須 bump 主版本號」這個壓縮在不是以單一原子 API 為粒度時就是有損的。任何經歷過升級時依賴地獄的人都可能發現這特別令人惱火:其中相當大比例的工作其實是完全徒勞的。
SemVer 可能過度承諾(Overpromise)#
SemVer 假設變更可以完美分為三類:破壞性(修改或移除)、純新增、不影響 API。但現實中:
- 為時間敏感的 API 增加一毫秒延遲算什麼類別?
- 改變日誌輸出格式呢?
- 改變匯入外部依賴的順序呢?
- 改變「無序」串流的回傳順序呢?
- 如果文件寫了「這可能在未來改變」呢?
這直接觸碰了 Hyrum’s Law:「當使用者數量足夠多時,系統的每一個可觀察行為都會被某人所依賴。」理論上安全的 patch 版本變更,在規模化後必然會打破某些消費者的假設。
同樣重要的是:存在理論上是破壞性但實際上安全的變更(移除一個從未被使用的 API),也存在理論上安全但實際上破壞客戶端程式碼的變更(任何前述的 Hyrum’s Law 例子)。
一個變更本身不是「破壞性」或「非破壞性」的——這個判斷只能在使用情境中評估。SemVer 的制定中缺少了這個關鍵資訊:下游使用者究竟如何消費這個依賴?
激勵機制問題#
SemVer 不一定能激勵穩定程式碼的產生:
- 大多數使用者是間接使用者——他們不會訂閱郵件列表或發行通知,對即將到來的變更毫無察覺
- 無論有多少使用者會因為不相容變更而受到影響,維護者只承擔版本 bump 帶來的極小比例成本
- 對同時也是使用者的維護者而言,破壞性變更甚至有吸引力——在沒有歷史包袱的情況下設計更好的介面總是更容易
這也是為什麼作者認為專案應該發布關於相容性、使用方式和破壞性變更的清晰意圖聲明。即使這些是盡力而為、非約束性的,也能作為評估破壞性變更「是否值得」的起點。
Go 和 Clojure 的做法較為合理:在它們的標準套件管理生態系統中,主版本號 bump 等同於發布一個全新套件。如果你願意拋棄向後相容,為什麼還要假裝這是同一組 API?重新包裝和重新命名一切,似乎是對提供者要求的合理工作量。
最後還有人為可錯性的問題。SemVer 版本 bump 應該同時應用於語意變更和語法變更。雖然有可能開發工具來評估某個版本是否涉及公共 API 的語法變更,但判斷是否有有意義的語意變更在計算上是不可行的。如果你的依賴網路下有數千個依賴,你應該準備好面對純粹來自人為錯誤的混亂。
最小版本選擇(Minimum Version Selection / MVS)#
2018 年,Google 的 Russ Cox 在為 Go 語言建構套件管理系統的系列文章中,提出了一個有趣的 SemVer 變體。傳統做法是在更新依賴時選擇最新可用版本(畢竟,遲早要更新到那些新版本,對吧?);MVS 則反其道而行:當 liba 要求 libbase >= 1.7 時,直接使用 1.7,即使 1.8 已可用。
MVS 產出「高忠實度建置,使用者建置的依賴盡可能接近作者開發時使用的依賴」。這揭示了一個關鍵事實:當 liba 說它需要 libbase >= 1.7,幾乎可以確定 liba 的開發者安裝的就是 libbase 1.7。假設維護者在發布前至少做了基本測試,我們至少有軼事證據表明 liba 的這個版本與 libbase 1.7 的互操作性已被測試過。
MVS 的核心洞見是:在缺乏 100% 精確預測未來的輸入約束下,最好盡可能做最小的前進跳躍。就像通常提交一小時的工作比一次傾倒一年的工作更安全,依賴更新中較小的步伐也更安全。
MVS 內在地承認:即使版本號理論上說相容,更新的版本在實踐中仍可能引入不相容。這認識到了 SemVer 的核心問題。MVS 是否能讓 SemVer「夠好用」而不修復基本的理論和激勵問題,陪審團仍未做出裁決。但作者相信它代表了 SemVer 約束當前應用方式的明顯改進。
SemVer 有效嗎?#
SemVer 在有限規模下運作良好,前提是:
- 依賴提供者準確且負責任(避免版本號的人為錯誤)
- 依賴足夠細粒度(避免因不相關 API 變更而過度約束,以及由此產生的不可滿足 SemVer 需求風險)
- 所有 API 使用都在預期範圍內(避免被假定相容的變更意外破壞,無論是直接還是在你傳遞性依賴的程式碼中)
然而 Google 的經驗表明,在大規模下,這三個前提幾乎不可能同時維持。規模往往是暴露 SemVer 弱點的因素。當依賴網路規模擴大時,SemVer 中累積的忠實度損失開始主導,表現為假陽性(實際相容但理論上不應運作的版本)和假陰性(被 SAT 求解器禁止但實際上相容的版本,以及由此產生的依賴地獄)。
無限資源下的依賴管理#
一個有用的思想實驗:如果我們擁有無限運算資源,依賴管理會是什麼樣子?也就是說,如果我們不受資源限制、只受限於組織間的可見性和弱協調,最好的結果是什麼?
目前業界依賴 SemVer 有三個原因:
- 只需要本地資訊(API 提供者不需知道下游使用者的細節)
- 不假設測試的可用性、運行測試的運算資源或監控測試結果的 CI 系統的存在
- 這是現行慣例
但「本地資訊」的需求其實不是真正必要的,因為依賴網路往往只在兩種環境中形成:單一組織內部,或 OSS 生態系統中(原始碼是可見的)。在這兩種情況下,下游使用的大量資訊其實是可用的,即使目前沒有被揭露或採取行動。
如果運算不是問題,我們可以用實際證據取代估計:對每個提議的變更,執行所有受影響下游依賴的測試。測試通過就是安全的——不管這是 API 影響、bug 修復還是其他任何東西,不需要分類或估計。
即使沒有正式的 CI 應用於整個 OSS 生態系統,我們也可以利用依賴圖和其他次要訊號做更有針對性的預提交分析:優先測試大量使用的依賴、維護良好的依賴、有良好測試歷史的依賴。
要實現這個願景,OSS 生態系統需要的改變:
- 所有依賴都必須提供單元測試
- 依賴網路的圖結構必須被索引且可查詢(包含反向邊——dependents,而不只是 dependencies)
- CI 運算資源必須廣泛可用
- 依賴不能以釘選方式表達(否則無法對下游跑測試)
- 可能需要將歷史與聲譽納入 CI 計算——一個有長期測試通過歷史的專案中的 breakage,與一個剛加入且經常因無關原因而失敗的專案中的 breakage,提供不同形式的證據
在無限資源下,最佳策略實際上就是 Live at Head——永遠測試最新穩定版本。懸而未決的問題是:這個模型是否能在更實際的資源可用性下有效運作,以及 API 提供者是否願意承擔更大的責任來測試其變更的實際安全性。
匯出依賴#
到目前為止只討論了取用依賴;但也值得思考如何建構可被他人作為依賴使用的軟體。一個看似無害且出於善意的行為——「開源一個函式庫」——可能以兩種方式成為組織的損失:
- 聲譽損失:實作品質不佳或維護不當。如 Apache 社群的說法:應優先考慮「社群重於程式碼」(community over code)
- 工程效率稅:無法保持內外版本同步時,所有的分叉(fork)隨時間都會變得昂貴
案例:開源 gflags#
2006 年左右,Google 開源了 C++ 命令列旗標函式庫 gflags。看似對開源社群的純粹善行,然而多重因素導致這個善舉反噬:
- 當時缺乏大規模重構能力,內部使用此函式庫的所有程式碼必須保持原樣——無法遷移到新位置
- 倉庫被分為「內部開發」與「可能有法律/授權問題」兩區;若 OSS 專案接受外部開發者的貢獻,原始專案方不擁有該貢獻,只有使用權
- 外部貢獻的 patch 因法律問題無法被內部採納,使得 gflags 注定成為「拋過牆」的發行或斷裂的分叉
- 隨著 Google 聚焦於自有工具鏈與生產環境,維護跨平台可攜性變得幾乎不可能。內部工具根本不支援那些平台
- 原始作者與支持者轉職離開,最終無人維護——沒有任何團隊能把支持外部 gflags 專案與自身的優先事項掛鉤
結果:內外版本緩慢分歧,外部開發者最終 fork 了這個專案自行維護。更糟的是,2008 至 2017 年間,某些需要跨環境建置的內部團隊發現了內外版本的「共同 API 子集」,並悄悄依賴它。後來當內部 C++ 函式庫團隊修改了內部旗標實作的可觀察但未文件化的細節時,所有依賴於未支持外部分叉穩定性的團隊都發現他們的建置和發行突然崩壞。一個價值數千個 Google 叢集 CPU 的優化機會被顯著延遲——不是因為更新 2.5 億行程式碼依賴的 API 很困難,而是因為少數專案依賴了未承諾且意料之外的東西。
案例:AppEngine#
Google AppEngine 允許使用者在框架上編寫應用程式,由 Google 的生產基礎設施管理擴展。最初的 Python 支援是使用舊版 Python 直譯器的 32 位元建置。2014 年 Google 開始同步升級 Python runtime 與 C++ 編譯器和標準函式庫,將「使用當前 C++ 編譯器的程式碼」與「使用更新 Python 版本的程式碼」綁定在一起。
然而許多付費客戶無法或不願升級——他們不想承受 Python 版本變更,或負擔不起從 32 位元轉 64 位元的資源消耗變化。因為部分客戶支付了大量費用,AppEngine 能提出強而有力的商業論據延遲強制升級。這意味著 AppEngine 傳遞性依賴閉包中的每一段 C++ 程式碼都必須與舊版編譯器和標準函式庫版本相容:任何 bug 修復或效能優化都必須跨版本相容。這個狀況持續了近三年。
對外釋出 API 會讓你暴露在競爭優先順序與不可預見約束之下。外部使用者的維護成本遠高於內部使用者。當你從原始碼控制轉向依賴管理、失去對程式碼使用方式的可見性,或受到外部群體(尤其是付費客戶)競爭優先順序的影響時,純工程取捨變得更加困難。
結論#
依賴管理本質上充滿挑戰——我們要管理複雜的 API 表面與依賴網路,而各依賴的維護者之間幾乎沒有協調假設。SemVer 作為當前事實標準,提供了一種有損的風險摘要。它預設我們能在不知道 API 如何被消費的情況下,先驗地預測變更的嚴重程度——Hyrum’s Law 告訴我們這行不通。然而,SemVer 在小規模下運作得夠好,搭配 MVS 方法時更佳。隨著依賴網路規模增長,Hyrum’s Law 問題和 SemVer 的忠實度損失使版本選擇越來越困難。
然而,業界有可能朝著一個方向邁進:以經驗驅動的證據(執行受影響下游套件的測試)取代維護者提供的相容性估計(SemVer 版本號)。如果 API 提供者承擔更大的測試責任並清楚公告預期的變更類型,我們就有可能在更大規模上建立更高忠實度的依賴網路。
TL;DRs#
- 優先選擇原始碼控制問題而非依賴管理問題:如果能讓更多程式碼納入組織內部以獲得更好的透明度與協調,這是重要的簡化
- 新增依賴並非免費:建立「持續性信任關係」的複雜度很高,匯入依賴需要理解其長期支援成本
- 依賴是一種契約:提供者與消費者各有權利與義務。提供者應清楚說明其長期承諾
- SemVer 是有損壓縮的簡寫估計:搭配 SAT 求解器使用時,估計被當作絕對值,可能導致過度約束(依賴地獄)或不足約束(理論相容但實際不相容)
- 測試與 CI 提供實際證據,證明一組版本是否能協同運作
- 最小版本選擇策略(MVS)忠實度更高:雖然仍依賴人類對版本風險的判斷,但顯著提高了 API 提供者與消費者之間連結已被專家測試過的機率
- 單元測試、CI 與廉價運算資源有潛力改變我們對依賴管理的理解與方法:這個範式轉移需要業界在依賴管理問題及提供者與消費者的責任上做根本性的思維轉變
- 提供依賴也不是免費的:「丟過牆就忘」會損害聲譽並造成相容性挑戰;承諾穩定性會限制自身選擇並使內部使用退化;不承諾穩定性則可能因 Hyrum’s Law 被外部重要群體所依賴,打亂你的計畫