建構系統與建構哲學#
本章由 Erik Kuefler 撰寫,探討 Google 如何從零打造自己的建構系統(build system),以及背後的設計哲學。Google 內部的建構工具 Blaze 在 2015 年以 Bazel 之名開源,其核心思想深刻影響了現代建構系統的發展方向。
建構系統的目的#
建構系統的根本任務是將工程師撰寫的原始碼轉換為機器可執行的二進位檔。一個好的建構系統會針對兩個關鍵屬性進行最佳化:
- 速度(Fast):開發者只需輸入一行指令,幾秒內就能取得建構結果。
- 正確性(Correct):無論哪位開發者在哪台機器上執行建構,只要輸入相同,結果就應該相同。
許多舊式建構系統在速度與正確性之間做取捨,Bazel 的核心目標正是避免這種二擇一,確保建構同時兼顧效率與一致性。
建構系統不僅服務於人類,也讓機器能自動化地進行建構。事實上,Google 大多數的建構是自動觸發的。以下是仰賴自動化建構系統的幾個關鍵工作流程:
- 程式碼自動建構、測試並部署到正式環境,無需人工介入(參見第 24 章)。
- 開發者的變更在送出 code review 時自動測試,讓作者與審查者即時看到問題(參見第 19 章)。
- 變更在合併到主幹前再次測試,大幅降低提交破壞性變更的風險。
- 底層函式庫的作者能在整個程式碼庫中測試變更的安全性。
- 工程師可以進行大規模變更(LSC),一次修改數萬個原始檔,同時仍能安全提交與測試(參見第 22 章)。
沒有建構系統會怎樣?#
只靠編譯器就夠了嗎?#
對於剛學程式的人來說,直接呼叫 javac *.java 或 gcc 就能完成編譯。但隨著程式碼規模成長,問題迅速浮現:
javac雖然能在子目錄中尋找 import 的程式碼,但無法找到存放在檔案系統其他位置的共用函式庫(例如多個專案共享的函式庫)。- 大型系統由多種語言撰寫,各部分之間有複雜的依賴關係,單一語言的編譯器不可能建構整個系統。
- 當需要處理多語言或多編譯單元時,建構不再是一步驟的過程。必須思考程式碼依賴什麼,並以正確順序建構,每個部分可能需要不同的工具集。
- 外部依賴(如第三方 JAR 檔)的管理完全靠手動:從網路下載、放到
lib目錄、設定編譯器路徑。時間一久,很容易忘記放了哪些函式庫、來源為何、是否仍在使用。
Shell Script 也救不了你#
用 shell script 自動化建構在初期可行,但隨著專案成長會遇到一系列問題:
- 繁瑣:維護建構腳本的時間幾乎與寫正式程式碼一樣多,除錯 shell script 非常痛苦,一層又一層的 hack 不斷疊加。
- 緩慢:為確保沒有依賴過期的函式庫,每次都得重新建構所有依賴。想加入偵測哪些部分需要重建的邏輯?這對腳本來說太過複雜且容易出錯。
- 發布困難:需要記住傳給打包指令的所有參數、上傳到中央儲存庫的步驟、更新文件、發送通知——每個環節可能又需要另一個腳本。
- 災難復原困難:硬碟損壞時,原始碼在版本控制中,但那些手動下載的函式庫呢?能找回完全相同的版本嗎?腳本依賴的工具路徑和環境變數還能重現嗎?
- 新人入職痛苦:每位新加入的工程師都得經歷同樣的環境設定過程。不同人的系統總有微妙差異,經常需要花數小時除錯工具路徑或函式庫版本的不同。
- 自動化困難:在 CI 機器上設定自動建構後,每天早上都發現夜間建構失敗——因為某位開發者做了在他們機器上能跑但在 CI 上不能跑的變更。
- 無法擴展:建構速度隨專案成長而持續變慢,而你只能望著度假同事閒置的電腦,卻無法利用那些浪費的運算資源。
這是典型的規模化(scale)問題。對於單一開發者處理幾百行程式碼的短期專案,編譯器就夠了;shell script 可以再撐一段時間。但當需要跨多位開發者及多台機器協調時,即使是完美的 shell script 也無法應對機器間的細微差異。此時就需要一個真正的建構系統。
現代建構系統#
一切都是關於依賴#
回顧前述問題,反覆出現的主題是:管理自己的程式碼相對簡單,但管理依賴(dependency)才是真正的困難所在(第 21 章有更深入的探討)。依賴有多種形式:
- 任務依賴:「發布文件後才能標記 release 完成」
- 產物依賴:「需要最新版的電腦視覺函式庫才能編譯我的程式碼」
- 內部依賴:程式碼庫中另一部分的程式碼
- 外部依賴:其他團隊或第三方擁有的程式碼或資料
無論哪種形式,「我需要先有那個,才能做這個」是建構系統設計中反覆出現的核心概念,而管理依賴可能是建構系統最根本的職責。
基於任務的建構系統(Task-Based Build Systems)#
Ant、Maven、Gradle、Grunt、Rake 等都是基於任務的建構系統。其基本單元是 任務(task),每個任務本質上是一段可執行任意邏輯的腳本,並透過依賴關係形成有向無環圖(DAG)。
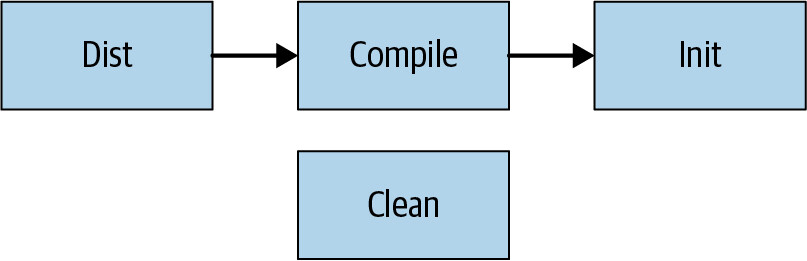
Figure 18.1: An acyclic graph showing dependencies
以 Ant 為例,當使用者執行 ant dist 時,系統會:
- 解析
build.xml,建立依賴圖。 - 找到
dist任務,發現它依賴compile。 - 找到
compile任務,發現它依賴init。 - 按照
init→compile→dist的順序依序執行。
這比純 shell script 進步不少——可以在不同目錄建立新的 buildfile 並互相連結,輕鬆新增依賴現有任務的新任務,只需傳入單一任務名稱就能自動解析整個依賴鏈。
Ant 是 2000 年發布的老工具,後來的 Maven 和 Gradle 增加了自動管理外部依賴和更簡潔的語法(不再使用 XML),但本質不變:讓工程師以模組化方式撰寫建構腳本作為任務,並提供執行任務與管理依賴的工具。然而,工程師定義的仍然是如何建構(imperative),而非要建構什麼(declarative)。
基於任務建構系統的黑暗面#
由於任務可以執行任意邏輯,系統無法得知腳本實際在做什麼,因此產生三大根本問題:
1. 難以平行化建構步驟
假設任務 A 依賴任務 B 和 C,而 B 和 C 之間沒有依賴。理論上可以平行執行 B 和 C,但系統無法確認它們是否會存取相同資源。為了避免難以除錯的競爭條件,系統通常只能限制為單執行緒執行,浪費了多核心機器的效能,也完全排除了分散式建構的可能性。
2. 難以實現增量建構
任務可以做任何事(下載檔案、寫入時間戳等),系統無法判斷任務是否需要重新執行。為確保正確性,通常每次都得重新執行所有任務。工程師嘗試設定條件式重建規則,但這比想像中困難得多,常見的捷徑會導致使用過期結果。最終開發者養成每次建構前先 clean 的習慣,增量建構形同虛設。
3. 難以維護與除錯腳本
建構腳本本身就是程式碼,容易藏匿 bug:
- 任務 A 依賴任務 B 的輸出檔案,但 B 的維護者不知情而改了輸出路徑。
- 間接依賴斷裂:A 依賴 B,B 依賴 C 提供的檔案,當 B 移除對 C 的依賴時 A 就壞了。
- 任務隱含假設特定機器環境(工具路徑、環境變數)。
- 非確定性行為(下載檔案、時間戳)導致建構結果不可重現。
在基於任務的框架下,這些效能、正確性與可維護性問題無法從根本上解決。只要工程師能在建構期間執行任意程式碼,系統就缺乏足夠資訊來保證快速且正確的建構。解決之道是將系統的角色從「執行任務」轉變為「產生產物」。
基於產物的建構系統(Artifact-Based Build Systems)#
基於產物的建構系統(如 Blaze、Bazel、Pants、Buck)採取完全不同的設計哲學:不再讓工程師定義任意任務,而是由系統定義少量的建構規則,工程師以宣告式方式指定要建構什麼,建構的方式則交給系統決定。
Bazel 的 BUILD 檔案是宣告式的 manifest,而非命令式腳本:
java_binary(
name = "MyBinary",
srcs = ["MyBinary.java"],
deps = [":mylib"],
)
java_library(
name = "mylib",
srcs = ["MyLibrary.java", "MyHelper.java"],
visibility = ["//java/com/example/myproduct:__subpackages__"],
deps = [
"//java/com/example/common",
"//java/com/example/myproduct/otherlib",
"@com_google_common_guava_guava//jar",
],
)每個 target 對應一個可由系統產生的產物:java_binary 產生可執行檔,java_library 產生函式庫。每個 target 宣告名稱(name)、原始碼(srcs)與依賴(deps)。依賴可以是同一 package 內的(如 ":mylib")、同一 workspace 不同 package 的(如 "//java/com/example/common"),或第三方外部產物(如 "@com_google_common_guava_guava//jar")。每個 workspace 由根目錄下的 WORKSPACE 檔案標識。
函數式程式設計的類比#
基於產物的建構系統與函數式程式設計有天然的相似性。傳統命令式語言逐步執行指令(如同基於任務的系統),而函數式語言描述要計算什麼,將執行細節交給編譯器。建構系統本質上就是一個數學函數:輸入原始碼與工具,輸出二進位檔。因此以函數式理念設計建構系統非常合理。
Bazel 的建構流程#
當使用者執行 bazel build :MyBinary 時:
- 解析 workspace 中所有 BUILD 檔案,建立依賴圖。
- 計算 MyBinary 的傳遞性依賴(transitive dependencies)。
- 按順序建構每個依賴,已無依賴的 target 先建構,並可安全地平行執行。
- 最終建構 MyBinary,連結所有已建構的依賴。
關鍵差異在於步驟 3:因為 Bazel 知道每個 target 只會產生 Java 函式庫,它確定可以安全地平行執行這些步驟。在多核心機器上,這可以帶來一個數量級的效能提升,而這只有在基於產物的系統掌控自身執行策略、能對平行性做出更強保證時才可能。
但好處不僅限於平行化。當開發者不做任何修改就再次執行 bazel build :MyBinary 時,Bazel 能在不到一秒的時間內告知 target 已是最新狀態。這是因為我們之前談到的函數式程式設計範式——Bazel 知道每個 target 只是執行 Java 編譯器的結果,而 Java 編譯器的輸出只取決於其輸入,所以只要輸入不變,輸出就可以重用。這種分析在每一層都有效——若只有 MyBinary.java 改變,Bazel 僅重建 MyBinary 而重用 mylib。若 //java/com/example/common 的某個原始檔改變,Bazel 知道要重建該函式庫、mylib 和 MyBinary,但可以重用 //java/com/example/myproduct/otherlib。因為 Bazel 瞭解每個步驟所使用工具的性質,它能夠每次只重建最小的產物集合,同時保證不會產生過期的建構結果。
將建構過程從任務重新定義為產物,雖然看似微妙,卻威力強大。透過減少暴露給程式設計者的彈性,建構系統能更了解每個步驟在做什麼,從而實現平行化和結果重用。這些正是分散式、高擴展性建構系統的基石。
Bazel 的其他巧妙設計#
工具作為依賴(Tools as Dependencies):每個 java_library 隱含地依賴 Java 編譯器。Bazel 會在建構時檢查指定編譯器是否存在,不存在則自動下載。若編譯器版本變更,所有依賴它的產物都會重建。Bazel 進一步透過 toolchain 機制解決跨平台問題。
擴充建構系統(Extending the Build System):Bazel 內建支援數種常見程式語言的 target 類型,但工程師總是想做更多的事——基於任務系統的優勢之一正是其支援任何建構過程的彈性。Bazel 透過允許新增自訂規則(custom rules)來保留這種彈性。規則作者宣告該規則需要的輸入(以 BUILD 檔中的 attributes 形式傳入)和固定的輸出集合,並定義 actions。每個 action 宣告其輸入和輸出,執行特定的可執行檔或將字串寫入檔案,並可透過輸入和輸出與其他 action 串連。Action 是建構系統中最底層的可組合單元——只要 action 使用其宣告的輸入和輸出,它可以做任何事,Bazel 會負責排程和快取。雖然無法完全防止 action 開發者引入非確定性行為,但將濫用的可能性壓縮到 action 層級,大幅減少了出錯機會。支援常見語言和工具的規則已廣泛可在網路上取得,大多數專案永遠不需要定義自己的規則。
環境隔離(Isolating the Environment):Action 是否會遇到與其他系統中任務相同的問題——例如兩個 action 同時寫入同一檔案而產生衝突?Bazel 透過 sandbox 使這種衝突不可能發生。在支援的系統上,每個 action 都透過檔案系統沙箱隔離。每個 action 只能看到一個受限的檔案系統視圖,僅包含它宣告的輸入和它產生的輸出。這在 Linux 上透過 LXC(Docker 的底層技術)實現。因此 action 之間不可能發生衝突——它們無法讀取未宣告的檔案,而寫入但未宣告的檔案在 action 結束後會被丟棄。Bazel 也使用沙箱限制 action 透過網路通訊。
外部依賴的確定性(Making External Dependencies Deterministic):依賴 workspace 外部的檔案存在風險——這些檔案可能隨時變更,如果遠端檔案在 workspace 原始碼未改變的情況下被修改,就會導致不可重現的建構。Bazel 要求在 workspace 層級的 manifest 檔案中列出每個外部依賴的加密雜湊值(cryptographic hash)。雜湊值是一種簡潔地唯一代表檔案的方式,不需要將整個檔案簽入原始碼控制。當新增外部依賴時,其雜湊值會被加入 manifest;建構時 Bazel 會比對實際雜湊與預期雜湊,不符則重新下載。若下載的產物雜湊值與 manifest 宣告不符,建構就會失敗,除非更新 manifest 中的雜湊值——而這項變更必須經過審批並簽入原始碼控制。這確保了外部依賴的每次更新都有記錄可查,檢出舊版本的原始碼時也保證使用當時的依賴版本。
依賴外部來源的產物存在固有風險。若第三方伺服器遭入侵,攻擊者可能替換依賴檔案,注入惡意程式碼。建議將所有依賴鏡像(mirror)到自己控制的伺服器上,並在原始碼庫中要求指定每個第三方產物的雜湊值。
分散式建構(Distributed Builds)#
Google 的程式碼庫超過二十億行,依賴鏈可能非常深,簡單的 binary 可能依賴數萬個 build target。在這種規模下,單機建構不可能在合理時間內完成。唯一的出路是分散式建構——將建構工作分散到任意數量的機器上。
遠端快取(Remote Caching)#
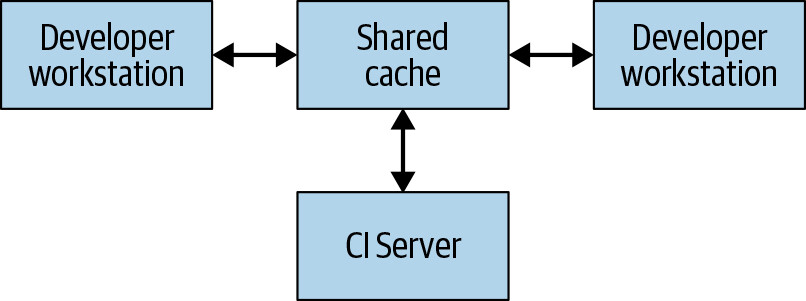
Figure 18.2: A distributed build showing remote caching
最簡單的分散式建構形式是遠端快取。所有執行建構的系統(開發者工作站和 CI 系統)共享一個遠端快取服務(如 Redis 或 Google Cloud Storage)。建構產物時,系統先檢查快取中是否已有該產物:有就直接下載,沒有就本地建構後上傳到快取。這意味著不常變更的底層依賴只需建構一次,即可在所有使用者之間共享。
遠端快取的前提是建構必須完全可重現(reproducible)——相同輸入必須在任何機器上產生完全相同的輸出。這是確保下載產物等同於自行建構的唯一方式。快取中每個產物以 target 和輸入雜湊值為 key,確保不同工程師對同一 target 的不同修改不會互相干擾。
當然,遠端快取只有在下載產物比建構它更快時才有意義。尤其當快取伺服器離建構機器很遠時,未必如此。Google 的網路和建構系統經過精心調校以快速共享建構結果。在自己的組織中設定遠端快取時,務必考慮網路延遲並進行實驗,確保快取確實提升了效能。
遠端執行(Remote Execution)#
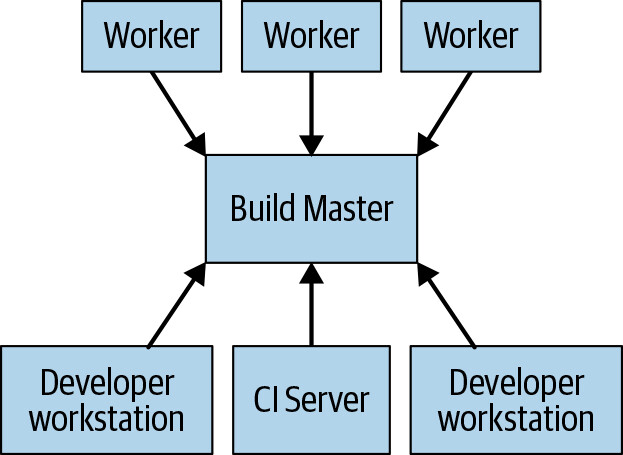
Figure 18.3: A remote execution system
遠端快取並非真正的分散式建構——若快取遺失或需全面重建,仍得在本機執行。真正的目標是遠端執行:將實際的建構工作分配到任意數量的 worker 上。
使用者機器上的建構工具將請求發送到中央 build master。Build master 將請求拆解為 actions 並排程到可擴展的 worker pool。每個 worker 執行指定的 action,將結果寫入分散式快取,供其他 worker 或使用者取用。
實現這種系統最棘手的部分是管理 worker、master 與使用者本機之間的通訊。Worker 可能依賴其他 worker 產生的中間產物,最終輸出需要傳回使用者本機。解決方式是建立在前述的分散式快取之上:每個 worker 將結果寫入快取、從快取讀取依賴。Master 會阻擋 worker 直到它所有依賴都完成,屆時就能從快取讀取輸入。最終產物也被快取,供本機下載。此外還需要一種機制將使用者本地的原始碼變更匯出,讓 worker 能在建構前套用這些變更。
這種架構要求建構環境完全自描述(self-describing),使得 worker 能在無人工介入的情況下啟動。建構過程必須完全自包含(self-contained),因為每個步驟可能在不同機器上執行。輸出必須完全確定性(deterministic),使得每個 worker 能信任其他 worker 的結果。這些保證對基於任務的系統來說幾乎不可能提供,因此很難在其上建構可靠的遠端執行系統。
Google 的分散式建構系統#
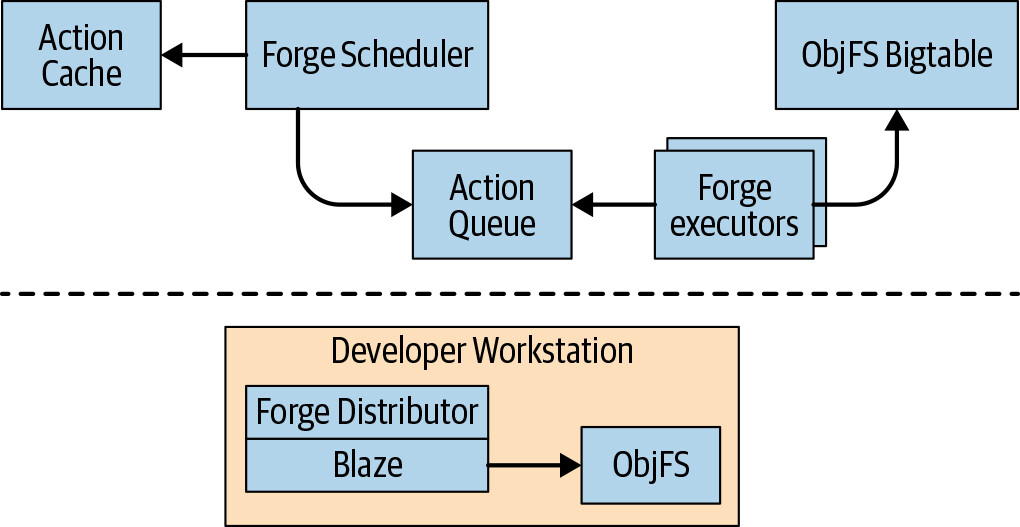
Figure 18.4: Google's distributed build system
自 2008 年起,Google 使用同時具備遠端快取與遠端執行的分散式建構系統:
- ObjFS(遠端快取):後端將建構輸出儲存在分散式 Bigtable 中,前端透過 FUSE daemon(
objfsd)掛載在每位開發者的機器上。開發者可以像瀏覽一般檔案一樣存取建構輸出,但檔案內容只在實際被請求時才按需下載。這種設計大幅降低了網路和磁碟使用量,建構速度比將所有輸出存在本機磁碟快了兩倍。 - Forge(遠端執行):Blaze 中的 Distributor 客戶端將每個 action 的請求發送到資料中心的 Scheduler。Scheduler 維護 action 結果的快取,若結果已存在則直接回傳;否則將 action 放入佇列。大量的 Executor 持續從佇列讀取 action、執行並將結果存入 ObjFS Bigtable。
Google 的建構規模非常驚人:每天執行數百萬次建構、運行數百萬個測試案例,從數十億行原始碼產生 PB 級的建構輸出。如今開源工具已足夠成熟,任何組織都可以實現類似的系統。
時間、規模與取捨#
建構系統的選擇本質上是取捨:
| 建構方式 | 適用場景 | 取捨 |
|---|---|---|
| DIY(shell script) | 極小型專案、短期專案 | 無法擴展,無法跨機器重現 |
| 基於任務的系統 | 中型專案 | 需撰寫建構檔,隨規模增長遇到效能與正確性瓶頸 |
| 基於產物的系統 | 中大型專案 | 彈性受限,但獲得平行化、分散式建構與可重現性 |
對於特別小型的專案(如只包含單一原始檔的專案),基於任務系統的額外開銷可能不值得。但基於任務系統在專案進一步擴展時會遇到根本性問題,這些問題可以透過基於產物的建構系統來解決。基於產物的系統解鎖了全新的擴展層級,因為大型建構可以分散到多台機器上,數千名工程師可以更有信心地確保其建構是一致且可重現的。取捨在於缺乏彈性:基於產物的系統不允許使用通用程式語言撰寫任意任務,而要求在系統的約束內工作。這對於從一開始就設計為配合基於產物系統的專案通常不是問題,但從既有的基於任務系統遷移可能很困難。
Google 認為幾乎所有新專案都應從一開始就採用基於產物的建構系統(如 Bazel)。在 Google 內部,從微小的實驗性專案到 Google Search,全部使用 Blaze 建構。變更建構系統的成本隨專案規模而增加,因此越早做出正確選擇越好。
管理模組與依賴#
細粒度模組與 1:1:1 規則#
使用基於產物建構系統的專案被拆分為許多模組。模組粒度涉及效能與可維護性的取捨:
- 粗粒度(整個專案一個模組):幾乎不需維護 BUILD 檔,但系統無法平行化或快取部分建構結果。
- 細粒度(每個檔案一個模組):系統擁有最大的平行化與快取彈性,但工程師需花更多心力維護依賴清單。
Google 傾向使用明顯更細粒度的模組。一個典型的正式 binary 可能依賴數萬個 target,中等規模的團隊可能擁有數百個 target。對於 Java 這類有強封裝概念的語言,通常每個目錄包含一個 package、一個 target 和一個 BUILD 檔(Pants 稱此為 1:1:1 規則)。
細粒度 target 的優勢在規模化後更加明顯:更快的分散式建構、更少的重建需求,以及在測試階段能更精準地只跑受影響的測試子集。Google 也投資開發了自動管理 BUILD 檔的工具,減輕開發者的負擔。
最小化模組可見性#
Bazel 允許每個 target 指定可見性(visibility):一個屬性用於宣告哪些其他 target 可以依賴它。Target 可以是 public(workspace 中任何 target 都可引用)、private(僅同一 BUILD 檔內可引用),或只對明確定義的其他 target 清單可見。可見性本質上是依賴的反面:如果 target A 想依賴 target B,target B 必須讓自己對 target A 可見。
就像大多數程式語言中的存取控制一樣,最佳實踐是盡可能最小化可見性。
Google 的一般做法:
- 只有廣泛使用的函式庫才設為 public。
- 需要協調的團隊維護允許引用的 target 白名單。
- 團隊內部的實作 target 限制為僅團隊擁有的目錄可存取。
- 大多數 BUILD 檔中只有一個 target 不是 private。
管理依賴#
內部依賴(Internal Dependencies)#
內部依賴從原始碼建構而非以預建產物下載,因此沒有「版本」概念——target 及其所有內部依賴總是在同一個 commit 下建構。
傳遞性依賴(Transitive Dependencies) 是需要特別注意的議題。假設 target A 依賴 B,B 依賴 C:A 是否能使用 C 中定義的 class?

Figure 18.5: Transitive dependencies
技術上沒問題,因為 B 和 C 都會連結到 A 中。但 Google 在成長過程中發現這會造成嚴重問題:若 B 重構後不再需要 C,移除 B 對 C 的依賴會破壞 A。target 的依賴實質上成了其公開契約的一部分,永遠無法安全修改,導致依賴不斷累積、建構日益緩慢。
Google 最終引入了 嚴格傳遞性依賴模式(strict transitive dependency mode):Blaze 偵測到 target 引用了未直接依賴的符號時會報錯,並提供一個可直接執行的 shell 指令來自動插入缺失的依賴。將這項變更推廣到 Google 整個程式碼庫、重構數百萬個 build target 使其明確列出所有依賴,是一項多年的工程,但非常值得——建構速度顯著提升(因為 target 不再有不必要的依賴),工程師也能放心移除不需要的依賴而不用擔心破壞依賴它們的 target。
一如既往,嚴格傳遞性依賴涉及取捨:BUILD 檔變得更冗長,因為常用的函式庫需要在許多地方明確列出而非被間接引入,工程師也需要花更多心力在 BUILD 檔中新增依賴。Google 後來開發了工具來自動偵測許多缺失的依賴並自動新增到 BUILD 檔中,減少了這方面的苦工。但即使沒有這些工具,這個取捨也是值得的:在 BUILD 檔中明確新增依賴是一次性成本,而處理隱含的傳遞性依賴問題則會在 build target 存在期間持續造成困擾。Bazel 預設對 Java 程式碼強制執行嚴格傳遞性依賴。
外部依賴(External Dependencies)#
外部依賴與內部依賴的最大差異在於:外部依賴有版本,且版本獨立於專案原始碼。
手動 vs. 自動依賴管理:手動管理時,buildfile 明確列出要從 artifact repository 下載的版本,通常使用語意化版本字串(如 "1.1.4")。自動管理時,原始檔指定可接受的版本範圍,建構系統總是下載最新的版本(如 Gradle 允許宣告 "1.+" 表示接受主版本為 1 的任何版本)。
自動管理對小專案方便,但對中大型專案是災難——無法控制版本更新時機,無法保證第三方不會做出破壞性更新(即使他們宣稱使用語意化版本控制),昨天還能動的建構今天可能就壞掉,且沒有簡單的方法偵測什麼改變了或回滾到可運作的狀態。即使建構沒壞,也可能有難以追蹤的微妙行為或效能變化。
相比之下,手動管理的依賴因為需要在原始碼控制中做出變更,可以輕鬆發現和回滾,也可以檢出舊版本的程式碼庫來使用舊版依賴。Bazel 要求所有依賴版本都必須手動指定。在中等以上的規模下,手動版本管理的額外開銷完全值得其帶來的穩定性。
One-Version Rule:理論上,同一外部依賴的不同版本可以用不同的名稱同時宣告在建構系統中,讓每個 target 自行選擇使用哪個版本。但 Google 發現這在實務上會造成大量問題,因此在內部程式碼庫中強制執行嚴格的單一版本規則(One-Version Rule)。
最大的問題是菱形依賴(diamond dependency):假設 target A 依賴 target B 並使用某外部函式庫 v1。若 B 後來被重構為依賴同一函式庫的 v2,target A 就會隱含地同時依賴同一函式庫的兩個不同版本而壞掉。實際上,只要某個第三方函式庫存在多個版本,就永遠不安全為任何 target 新增對該函式庫的依賴——因為該 target 的使用者可能已經依賴不同版本。單一版本規則使這種衝突不可能發生:如果一個 target 新增對第三方函式庫的依賴,所有現有依賴已經是同一版本,可以和平共存。
傳遞性外部依賴:Maven Central 等 artifact repository 允許 artifact 指定對其他 artifact 特定版本的依賴。Maven 或 Gradle 等工具預設會遞迴下載所有傳遞性依賴——新增一個依賴可能導致數十個 artifact 被下載。這很方便,但由於不同函式庫可能依賴同一第三方函式庫的不同版本,這種策略必然違反單一版本規則,導致菱形依賴問題。當你的 target 依賴兩個使用同一依賴不同版本的外部函式庫時,無法預知最終會用到哪個版本。
Bazel 不自動下載傳遞性依賴,而是要求一個全域檔案列出所有外部依賴及其明確版本。Bazel 提供工具可從一組 Maven artifacts 自動生成此初始檔案,之後可手動調整各依賴版本。這又是便利性與擴展性之間的取捨:小型專案可能偏好自動管理,但隨著組織和程式碼庫成長,手動管理依賴的成本遠低於處理自動依賴管理引發的問題。
以遠端快取取代依賴產物化:有些組織將內部程式碼發布為 artifact 供其他部分引用,理論上可加速建構但引入大量管理開銷。更好的方式是使用支援遠端快取的建構系統——從原始碼建構但自動共享快取結果,兼顧效能與一致性。這正是 Google 內部採用的策略。
外部依賴的安全性與可靠性:依賴第三方 artifact 存在固有風險。可用性方面,如果第三方來源(如 artifact repository)當機,而你無法下載外部依賴,整個建構可能停擺。安全性方面,如果第三方系統遭攻擊者入侵,攻擊者可以將被引用的 artifact 替換為自己設計的版本,將任意程式碼注入你的建構環境。這類「軟體供應鏈攻擊(software supply chain attack)」正變得越來越常見。
兩個問題都可以透過將所有依賴鏡像(mirror)到自己控制的伺服器來緩解,並阻止建構系統存取 Maven Central 等第三方 artifact repository。取捨是這些鏡像需要額外的維護資源。安全問題也可以透過要求在原始碼庫中指定每個第三方 artifact 的雜湊值來完全防範。
另一種完全繞過此問題的做法是 vendor 化——將所有依賴(無論是原始碼或二進位檔)簽入原始碼控制,與專案原始碼並列存放,實質上將所有外部依賴轉為內部依賴。Google 內部採用此方法,將所有第三方函式庫放在程式碼庫根目錄的 third_party 目錄中。不過這在 Google 可行是因為其原始碼控制系統是專門打造來處理超大型 monorepo 的,對其他組織來說 vendor 化未必可行。
結論#
建構系統是工程組織最重要的基礎設施之一。每位開發者每天可能與它互動數十甚至數百次,它往往是決定生產力的瓶頸因素。
Google 學到的一個出乎意料的教訓是:限制工程師的權力與彈性反而能提升生產力。Google 並非賦予工程師自由定義建構方式的權力,而是開發了一個高度結構化的框架,限制個人選擇,將大部分有趣的決策交給自動化工具。工程師並不因此感到不滿——相反,他們喜歡系統自動運作,讓他們專注於撰寫應用程式而非糾纏建構邏輯。能夠信任建構系統是一種強大的能力——增量建構「就是能用」,幾乎不需要清除快取或執行 clean。
Google 以此洞見為基礎,創造了全新的基於產物建構系統,與傳統基於任務的系統形成對比。將建構核心從任務轉向產物,正是 Google 的建構能擴展到如此龐大組織規模的關鍵。在極端情況下,它允許分散式建構系統利用整個運算叢集的資源來加速工程師的生產力。即使組織規模不夠大到需要如此投資,基於產物的建構系統同樣能在向下擴展時發揮價值:即使是小型專案,Bazel 等工具在速度和正確性方面也能帶來顯著效益。
TL;DRs#
- 隨著組織規模擴大,功能完備的建構系統對維持開發者生產力不可或缺。
- 權力與彈性伴隨代價。適當限制建構系統的彈性,反而能讓開發者更輕鬆。
- 圍繞產物組織的建構系統比圍繞任務的系統更具擴展性與可靠性。
- 定義產物與依賴時,應追求細粒度模組。細粒度模組更能利用平行化與增量建構的優勢。
- 外部依賴應在原始碼控制下明確指定版本。依賴「最新版」是災難和不可重現建構的根源。