Code Search#
Code Search 是 Google 內部用於瀏覽與搜尋程式碼的工具,由前端 UI 與多個後端元件組成。它最初誕生於對大型程式碼庫進行 grep 搜尋的需求,結合了內部 grep 工具與外部 Code Search 的排名和 UI。後來整合了 Kythe(提供交叉引用與符號定義跳轉的服務),使其從「搜尋程式碼」的工具轉變為「瀏覽與理解程式碼」的核心平台。
Code Search 最早的前身 GSearch 曾跑在 Jeff Dean 的個人電腦上,有一次他去度假把電腦關了,導致了全公司的困擾。
Code Search 的設計哲學是「一次點擊回答下一個關於程式碼的問題」。諸如「這個符號定義在哪?」「誰在使用它?」「如何引入它?」「它何時被加入程式碼庫?」甚至「在整個機群中,它消耗了多少 CPU 週期?」等問題,都能在一兩次點擊內得到解答。
與 IDE 不同,Code Search 專為大規模閱讀、理解與探索程式碼而優化,並大量依賴雲端後端來進行搜尋與交叉引用解析。本章將深入探討 Code Search 的細節,包括 Googler 如何在開發者工作流程中使用它、為何選擇開發獨立的 Web 工具,以及它如何應對在 Google 倉庫規模下搜尋和瀏覽程式碼的挑戰。
Code Search UI#
搜尋框是 Code Search UI 的核心元素,類似於網頁搜尋,它提供「建議」(suggestions)功能讓開發者快速導航到檔案、符號或目錄。對於更複雜的用例,會返回包含程式碼片段的結果頁面。
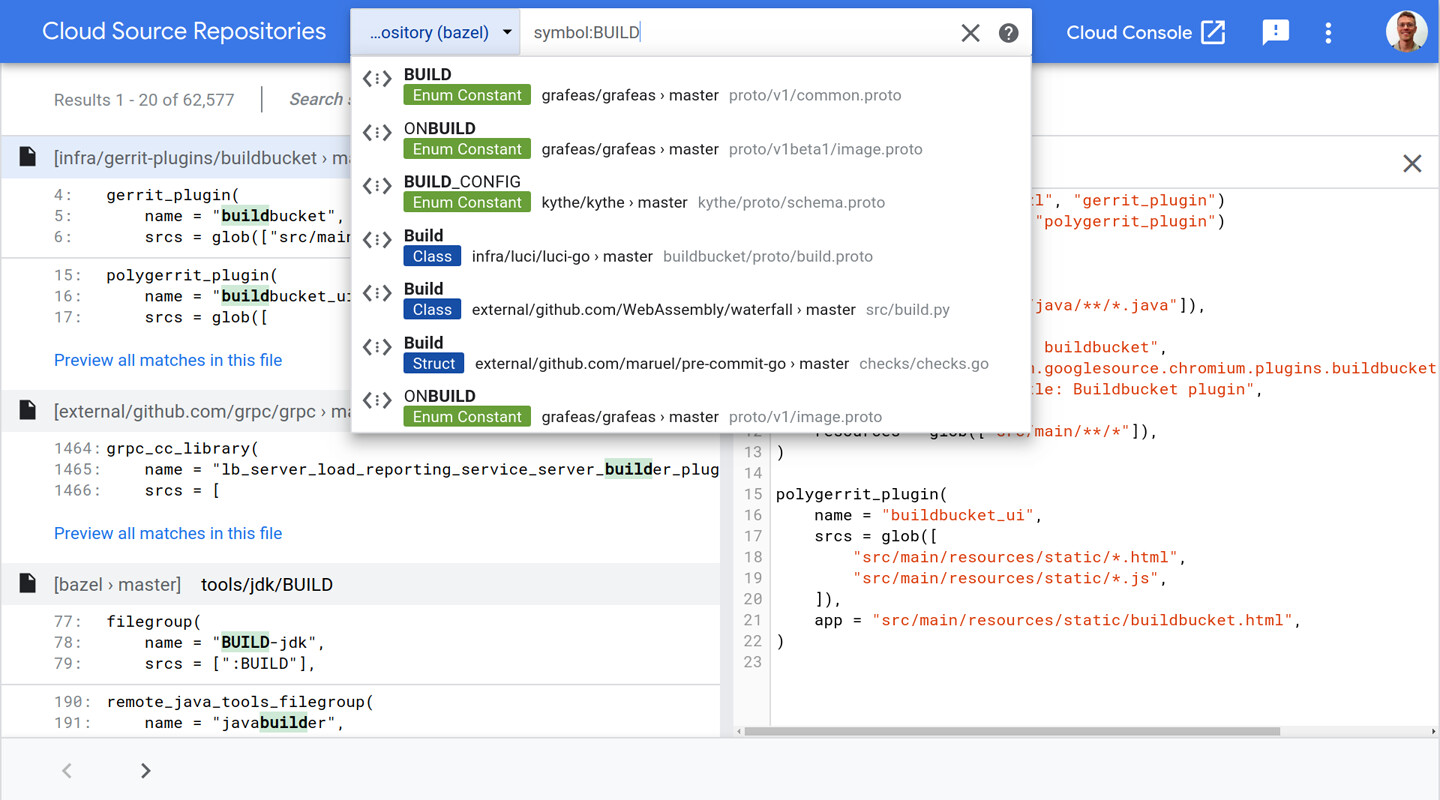
Figure 17.1: The Code Search UI
搜尋本身可以理解為即時的「在檔案中尋找」(類似 Unix 的 grep 指令),但加上了相關性排名以及程式碼特有的增強功能:
- 適當的語法高亮(syntax highlighting)
- 範圍感知(scope awareness)
- 註解與字串字面值的辨識
- 可透過命令列使用,也可透過 RPC API 整合到其他工具中
當結果集過大不適合人工檢視,或需要後處理時,RPC API 特別有用。
在瀏覽單一檔案時,大多數 token 都是可點擊的,讓使用者能快速導航到相關資訊:
- 函式呼叫:連結到函式定義
- 匯入的檔案名稱:連結到實際原始檔案
- 註解中的 Bug ID:連結到對應的 Bug 報告
這些功能由 Kythe 等基於編譯器的索引工具驅動。點擊符號名稱會開啟面板,顯示該符號的所有使用位置;將滑鼠懸停在區域變數上,則會高亮該變數在函式實作中的所有出現處。
Code Search 也透過與 Piper(版本控制系統,見第 16 章)的整合顯示檔案歷史,包括:
- 查看檔案的舊版本
- 查看哪些變更影響了該檔案,以及誰撰寫了這些變更
- 跳轉至 Critique(Code Review 工具,見第 19 章)
- 不同版本之間的差異比較(diff)
- 經典的 blame 視圖
- 即使是已刪除的檔案,也能從目錄視圖中看到
Googler 如何使用 Code Search?#
儘管類似功能在其他工具中也有,Googler 仍然大量使用 Code Search 的 UI 進行搜尋、檔案瀏覽,以及最終的程式碼理解。工程師使用 Code Search 完成的任務可以歸納為「回答關於程式碼的問題」,主要有以下五種反覆出現的意圖。
普遍使用的程式碼瀏覽工具會形成一個有趣的良性循環:鼓勵撰寫容易瀏覽的程式碼。這包括不要將層次結構嵌套太深(否則從呼叫點到實作需要多次點擊),以及使用命名型別而非通用的 string 或 integer(因為這樣更容易找到所有用法)。
Where?(在哪裡?)#
約 16% 的搜尋是為了找到特定資訊在程式碼庫中的位置,例如函式定義、設定檔、API 的所有用法,或某個檔案在倉庫中的位置。這些問題非常有針對性,可以透過搜尋查詢或跟隨語義連結(如「跳轉到符號定義」)來精確回答。這類問題常在重構、清理或與其他工程師協作時出現,因此高效解決這些小型知識缺口至關重要。
Code Search 透過兩種方式協助:結果排名與豐富的查詢語言。排名處理常見情況,而查詢語言可以非常精確地限定搜尋(例如限定程式碼路徑、排除特定語言、只考慮函式)以處理較罕見的情況。
此外,Code Search 的 UI 讓分享搜尋結果變得容易——在 Code Review 中可以直接附上連結,例如「你有沒有考慮用這個專門的 hash map:cool_hash.h?」這在文件、Bug 報告和事後檢討中也非常有用,是 Google 內部引用程式碼的標準方式。即使是程式碼的舊版本也能被引用,因此連結在程式碼庫演進後仍然有效。
What?(是什麼?)#
約 25% 的搜尋是經典的檔案瀏覽,目的是了解程式碼庫中某個部分在做什麼。這類任務通常更具探索性,而非尋找特定結果——是在修改前閱讀原始碼以深入理解,或是為了理解別人的變更。
為此,Code Search 引入了呼叫層次瀏覽(call hierarchies)以及相關檔案間的快速導航(例如在標頭檔、實作檔、測試檔和建構檔之間切換)。核心理念是透過輕鬆回答開發者在查看程式碼時產生的每一個問題來理解程式碼。
How?(怎麼做?)#
最常見的用例——約佔 三分之一 的搜尋——是查看別人如何做某件事的範例。典型場景是開發者已找到某個 API(例如如何從遠端儲存讀取檔案),想看看如何將它正確應用到特定問題上(例如如何建立穩健的遠端連線並處理特定類型的錯誤)。Code Search 也用於找到適合特定問題的正確程式庫(例如如何高效計算整數值的指紋),然後選擇最合適的實作。這類任務通常結合搜尋和交叉引用瀏覽來進行,是搜尋與瀏覽功能交互使用的典型場景。
Why?(為什麼?)#
約 16% 的搜尋試圖回答某段程式碼為何被加入、或為何以特定方式運作。這類問題常在除錯時出現——例如,為什麼在這些特定情況下會發生錯誤?
一個重要的能力是能夠搜尋和探索程式碼庫在特定時間點的確切狀態。除錯生產環境問題時,可能需要查看數週或數月前的程式碼狀態;而除錯新程式碼的測試失敗,通常涉及僅幾分鐘前的變更。兩者在 Code Search 中都是可能的。
Who and When?(誰與何時?)#
約 8% 的搜尋試圖回答誰在何時引入了某段程式碼,透過與版本控制系統的互動實現。例如,可以查看某一行何時被引入(類似 Git 的 blame),並跳轉到相關的 Code Review。歷史面板也非常適合用來找到最適合詢問該程式碼或審查相關變更的人選。
鑑於機器產生的變更的提交頻率,單純的 blame 追蹤在 Google 的價值不如在更抗拒變更的生態系統中。
為何需要獨立的 Web 工具?#
在 Google 之外,上述大部分調查工作通常在本地 IDE 中完成。那為什麼 Google 還要另外打造一個工具?
規模(Scale)#
Google 程式碼庫之大,使得完整的本地副本——大多數 IDE 的前提——根本無法放在單一機器上。即使在觸及這個根本限制之前,為每位開發者建構本地搜尋和交叉引用索引也有成本,而這通常在 IDE 啟動時支付,拖慢開發速度。若沒有索引,臨時搜尋(如用 grep)會變得極其緩慢。
集中式搜尋索引意味著只做一次前期工作,對基礎設施的投資惠及所有人。例如,Code Search 的索引會隨每次提交增量更新,使索引建構的成本為線性。
在一般的網頁搜尋中,快速變化的時事內容與變化較慢的穩定頁面(如 Wikipedia)混合在一起。相同的技術可以延伸到程式碼搜尋:使索引建構增量化,降低成本並讓程式碼庫的變更即時對所有人可見。當提交一個程式碼變更時,只有實際被修改的檔案需要重新索引,允許對全域索引進行平行且獨立的更新。
不幸的是,交叉引用索引無法以相同方式即時更新。對它來說增量化是不可能的,因為任何程式碼變更都可能影響整個程式碼庫,實務上經常影響數千個檔案。幾乎所有 Google 的完整二進位檔都需要被建構(或至少被分析)才能確定完整的語義結構。產生每日索引需要大量的運算資源。即時搜尋索引與每日交叉引用索引之間的差異,是使用者遇到的罕見但反覆出現的問題來源。
對比之下,「每位開發者在自己的 IDE 上建構索引」的模式大致以二次方(quadratic)擴展:開發者每單位時間產生的程式碼量大致恆定,因此程式碼庫線性增長,而線性數量的 IDE 各自做線性增長的工作——這不是良好的擴展方案。
零設置的全域程式碼視圖#
能夠即時且有效地瀏覽整個程式碼庫,意味著很容易找到可重用的程式庫和好的範例可供參考。對於在啟動時建構索引的 IDE,存在縮小專案或可見範圍的壓力,以減少啟動時間並避免自動完成等工具被噪音淹沒。
使用 Code Search 的 Web UI 無需任何設置(不需要專案描述、建構環境等),因此學習任何位置的程式碼都非常快速且簡單,提升開發者效率。也不會有遺漏程式碼依賴的風險——例如在更新 API 時,可以減少合併和程式庫版本問題。
專業化(Specialization)#
也許令人意外,Code Search 不是 IDE 這件事反而是一個優勢。UX 可以專門為瀏覽和理解程式碼而優化,而非為編輯程式碼服務(編輯通常佔 IDE 的大部分功能,包括鍵盤快捷鍵、選單、滑鼠點擊,甚至螢幕空間)。
例如,因為沒有編輯器的文字游標,每次滑鼠點擊符號都可以被賦予有意義的操作(顯示所有用法或跳轉到定義),而不只是移動游標。這個優勢大到開發者極其常見地同時開啟多個 Code Search 分頁和編輯器。
與其他開發者工具的整合#
Code Search 作為查看原始碼的主要方式,是展示程式碼相關資訊的理想平台。它讓工具開發者不需要為結果建立獨立的 UI,也能確保整個開發者社群都能看到他們的成果,無需額外宣傳。許多分析工具會定期掃描整個 Google 程式碼庫,其結果通常在 Code Search 中呈現。例如,對於許多語言,可以偵測「死碼」(uncalled code)並在瀏覽檔案時標記出來。
反過來,Code Search 的原始碼檔案連結被視為其「規範位置」(canonical location),這對許多開發者工具非常有用。
日誌檢視器整合:日誌檔案的每一行通常包含產生該日誌語句的檔案名稱和行號。生產環境的日誌檢視器使用 Code Search 連結,將日誌語句連回產生它的程式碼。根據可用資訊,這可以是直接連結到特定修訂版本的檔案,或是帶有對應行號的基本檔案名稱搜尋。如果只有一個匹配檔案,它會在對應行號處開啟;否則會渲染每個匹配檔案中目標行的程式碼片段。
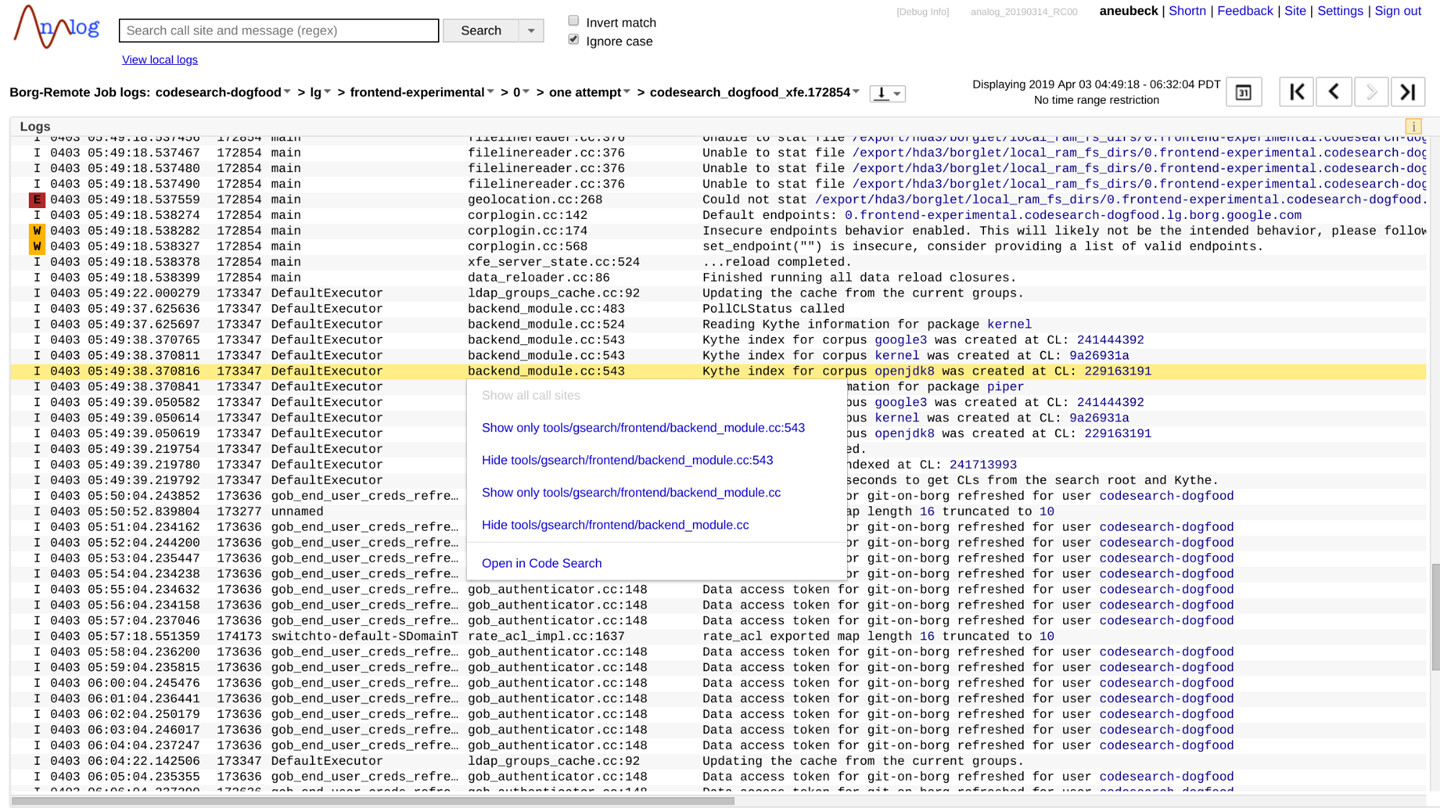
Figure 17.2: Code Search integration in a log viewer
堆疊追蹤整合:堆疊框架(stack frames)會連結回原始碼,無論是在崩潰報告工具中還是日誌輸出中。根據程式語言不同,連結會利用檔案名稱或符號搜尋。由於已知建構崩潰二進位檔時的倉庫快照,搜尋可以精確限制在該版本,使連結在程式碼重構或刪除後仍長期有效。
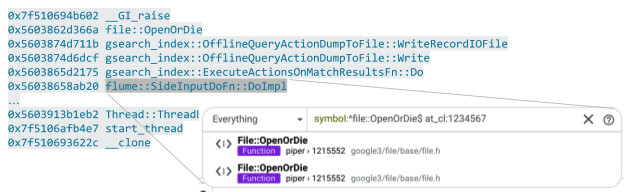
Figure 17.3: Code Search integration in stack frames
編譯錯誤和測試整合:編譯錯誤和測試通常也會引用程式碼位置(例如,檔案中第 X 行的測試 Y)。即使是尚未提交的程式碼也可以被連結,因為大部分開發都在 Code Search 可搜尋的特定雲端可見工作區中進行。
文件整合:Codelab 和其他文件可以引用 API、範例和實作。這些連結可以是參照特定類別或函式的搜尋查詢,即使檔案結構變更也依然有效。程式碼片段可以將 head 上最新的實作直接嵌入文件頁面,無需在原始檔案中加入額外的文件標記。
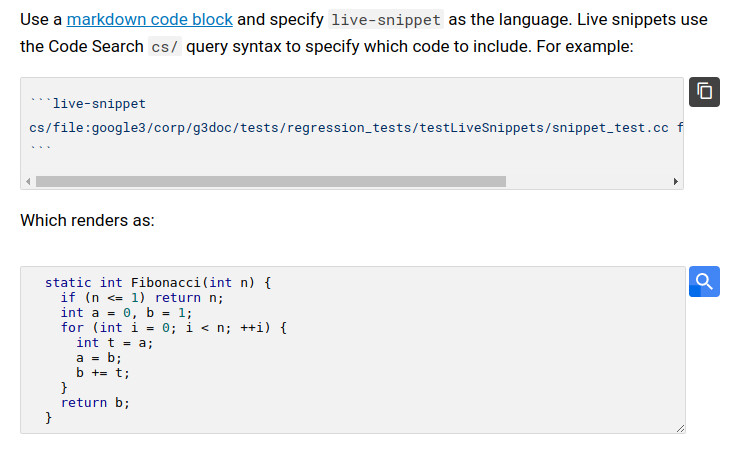
Figure 17.4: Code Search integration in documentation
API 開放#
Code Search 將其搜尋、交叉引用和語法高亮 API 開放給外部工具使用,讓工具開發者能將這些能力整合到自己的工具中,無需重新實作。同時也開發了 vim、emacs、IntelliJ 等編輯器的外掛,恢復因無法在本地索引程式碼庫而損失的部分能力,回饋一些開發者生產力。
規模對設計的影響#
前面我們探討了 Code Search UI 的各個面向以及為何值得擁有一個獨立的程式碼瀏覽工具。接下來我們深入實作背後,首先討論主要挑戰——規模擴展——然後是大規模如何使打造好的程式碼搜尋和瀏覽產品變得複雜。
搜尋程式碼最大的擴展挑戰是語料庫(corpus)大小。對於幾 MB 的小型倉庫,grep 暴力搜尋即可;數百 MB 時,簡單的本地索引能加速一個數量級以上;當需要搜尋 GB 或 TB 級的原始碼時,就需要多機器的雲端方案來維持合理的搜尋時間。集中式方案的效用隨使用者數量和程式碼空間的增大而增加。
由於查詢之間是獨立的,更多使用者可以透過增加更多伺服器來應對。
搜尋查詢延遲#
Google 的 Code Search 每天處理超過一百萬次開發者搜尋查詢。以一百萬次查詢計算,每次搜尋增加一秒延遲,相當於每天浪費約 35 位全職工程師的時間。相比之下,搜尋後端的建構和維護只需要大約這個數字十分之一的工程師。這意味著大約每天 100,000 次查詢(對應不到 5,000 名開發者)時,僅延遲一秒的論點就已經接近損益平衡點。
生產力損失並非隨延遲線性增加。延遲 200 ms 以下,UI 被認為是有回應的。超過一秒,開發者的注意力開始漂移。再過十秒,開發者很可能完全切換上下文(context switch),而這普遍被認為具有高昂的生產力成本。維持開發者「心流」(flow)狀態的最佳方式,是將所有頻繁操作的端到端延遲控制在 200 ms 以下,並投資於相應的後端基礎設施。
大量 Code Search 查詢是為了程式碼導航。理想情況下,「下一個」檔案只需一次點擊(例如被包含的檔案或符號定義),但對於一般導航,與其使用經典的檔案樹,直接搜尋目標檔案或符號通常快得多——只需幾次按鍵即可,而且不需要完整輸入,系統會為部分文字提供建議。隨著程式碼庫(和檔案樹)的增長,這一點愈發明顯。
為了提升搜尋效果,可以向後端提供搜尋上下文(例如當前查看的檔案)。上下文可以將搜尋限制在特定專案的檔案,或通過偏好與當前檔案或目錄相近的檔案來影響排名。在 Code Search UI 中,使用者可以預定義多個上下文並根據需要快速切換。在編輯器中,已開啟或正在編輯的檔案會被隱式用作上下文來優先排列搜尋結果。
索引延遲#
大多數時候,開發者不會注意到索引過時。他們只關心程式碼的一小部分,對於這部分通常也不知道是否有更新的版本。然而,當他們自己撰寫或審查了對應的變更時,不同步會造成極大的困惑——無論是小修正、重構還是全新的程式碼,開發者都期望看到一致的視圖,就像在小型專案的 IDE 中一樣。
撰寫程式碼時,期望修改過的程式碼能被即時索引。新增的檔案、函式或類別若無法被搜尋到,會令人沮喪並打斷習慣完美交叉引用的開發者的正常工作流程。搜尋替換式的重構也是如此——移除的程式碼不只是應該方便地立即從搜尋結果中消失,而且後續的重構必須考慮到新狀態。使用集中式版本控制系統時,如果前一個變更已不再屬於本地修改的檔案集,開發者可能需要已提交程式碼的即時索引。
反過來,有時能夠回溯到過去的程式碼快照也很有用——換言之,某個發布版本。在事故除錯期間,索引與運行中程式碼之間的差異可能特別成問題,因為它會隱藏真實原因或引入無關的干擾。這對交叉引用來說是個問題,因為以 Google 的規模建構索引的現有技術需要數小時,而且複雜性意味著只保留一個「版本」的索引。雖然可以做一些修補來將新程式碼與舊索引對齊,但這仍然是一個待解決的問題。
Google 的實作#
搜尋索引(Search Index)#
Google 的程式碼庫因其龐大規模而成為 Code Search 的特殊挑戰。早期採用了 trigram 方案,Russ Cox 隨後開源了簡化版本。目前,Code Search 索引約 1.5 TB 的內容,每秒處理約 200 次查詢,伺服器端搜尋延遲中位數低於 50 ms,索引延遲(從程式碼提交到在索引中可見的時間)中位數低於 10 秒。
粗略估算暴力搜尋的資源需求:RE2 正則表達式程式庫在 RAM 中的處理速度約為 100 MB/秒。在 50 ms 的時間窗口內,需要 300,000 個核心才能處理 1.5 TB 的資料。即使用每秒 1 GB 的特殊子字串搜尋替代正則匹配,核心數可減少十倍。但考慮到每秒 200 個請求中有 10 個在 50 ms 窗口內同時活躍,仍然回到 300,000 核心——僅用於子字串搜尋。這充分展示了所涉及的規模,以及 Code Search 團隊為何持續投資改進索引。
索引技術的演進:
- Trigram 索引:最初方案
- 自訂 Suffix Array 索引:中間方案
- Sparse N-gram 索引:當前方案,比暴力搜尋高效超過 500 倍,同時能以極快速度回應正則表達式搜尋
從 suffix array 轉向 token-based n-gram 方案的原因,是為了利用 Google 的主要索引與搜尋基礎架構。透過使用「標準」技術,Code Search 受益於核心搜尋團隊在反向索引建構、編碼和服務方面的所有進展,包括即時索引(instant indexing)功能。依賴標準技術是實作簡潔性與效能之間的取捨——雖然基於標準反向索引,但實際的檢索、匹配和評分都是高度客製化和優化的。
為了索引檔案修訂歷史,團隊設計了一種自訂壓縮方案,索引完整歷史僅增加 2.5 倍的資源消耗。
早期 Code Search 從記憶體提供所有資料。隨著索引增長,反向索引移到了 Flash 儲存。Flash 的成本比記憶體便宜至少一個數量級,但存取延遲至少高兩個數量級,因此適用於記憶體的索引方案可能不適用於 Flash。例如,原始的 trigram 索引需要從 Flash 取得大量且體積龐大的反向索引。N-gram 方案可以同時減少反向索引的數量和大小,代價是索引本身更大。
對於本地工作區(workspace),多台機器執行簡單的暴力搜尋。工作區資料在首次請求時載入,之後透過監聽檔案變更保持同步。記憶體不足時,會從機器中移除最久未使用的工作區。未變更的文件則使用歷史索引來搜尋,因此搜尋會隱式限制在工作區同步到的倉庫狀態。
排名(Ranking)#
對於非常小的程式碼庫,排名不會帶來太多好處,因為結果本就不多。但程式碼庫越大,結果越多,排名就越重要。在 Google 的程式碼庫中,任何短字串都會出現數千甚至數百萬次。沒有排名,使用者要麼檢查所有結果,要麼不斷精煉查詢——兩者都浪費時間。
排名從一個評分函式(scoring function)開始,將每個檔案的一組特徵(「信號」)映射為一個分數:分數越高,結果越好。搜尋的目標是儘可能高效地找到前 N 個結果。信號分為兩類:
查詢無關信號(Query Independent Signals)
這些信號可以離線計算,因此運算成本不是主要考量(儘管可能很高)。
- 檔案瀏覽次數:表示開發者認為哪些檔案重要,因此更可能想要找到。例如基礎程式庫的工具函式通常有很高的瀏覽量,無論該程式庫是否仍在積極開發。最大的缺點是它會產生回饋迴路——經常瀏覽的文件獲得更高分數,進而增加被瀏覽的機率,減少其他文件進入前 N 的機會(exploitation vs. exploration 問題)。實務上,過度展示高分項目似乎並無太大害處:不相關時會被忽略,需要通用範例時會被採用。但對新檔案是個問題,因為它們尚未有足夠的信號資訊
- 檔案引用數:類似原始的 PageRank 演算法,用各語言中的 include/import 語句替代網頁連結。概念可向上延伸至建構依賴(程式庫/模組層級),向下延伸至函式和類別層級。這種全域相關性通常被稱為文件的「優先級」(priority)
使用引用進行排名時須注意兩個挑戰。首先,必須能可靠地提取引用資訊——早期 Google 的 Code Search 用簡單的正則表達式提取 include/import 語句並用啟發式方法轉換為完整檔案路徑,但隨著程式碼庫複雜度增長,這些啟發式方法變得容易出錯且難以維護,最終被 Kythe 圖的正確資訊取代。
大規模重構(如將核心程式庫開源)不會在單次更新中原子性地發生,而是需要分階段推出。通常會引入間接層(indirections),例如隱藏檔案的移動。這些間接層會降低被移動檔案的 page rank,使開發者更難發現新位置。加上檔案瀏覽記錄在移動時通常會遺失,問題更加嚴重。由於這種全域性的程式碼庫重整相對罕見,最簡單的解決方案是在過渡期間手動提升(boost)檔案排名,或等待遷移完成讓自然過程在新位置重新提升排名。
查詢相關信號(Query Dependent Signals)
這些信號必須為每個查詢計算,因此需要低運算成本,限於查詢本身和從索引中快速可取得的資訊。
- Token 匹配品質:與網頁搜尋不同,Code Search 不只匹配 token。但如果有乾淨的 token 匹配(搜尋詞周圍有空白等分隔符),會獲得額外加分,並考慮大小寫敏感性。例如,搜尋 “Point” 對 “Point *p” 的評分高於對 “appointed to the council”
- 匹配類型:預設搜尋同時匹配檔案名稱、qualified symbols(限定名稱,如
absl::Monitor::Alert)和實際檔案內容,使用者不需要指定特定匹配類型。符號和檔案名稱匹配的評分高於一般內容匹配,以反映開發者的推測意圖 - 路徑匹配:查詢常以檔案名稱提示來「限定」(如 “base” 或 “myproject”)。當查詢的大部分內容出現在結果的完整路徑中時,該結果會被提升排名
檢索(Retrieval)#
在文件被評分之前,需要先找到可能匹配搜尋查詢的候選文件,這個階段稱為檢索(retrieval)。由於不可能檢索所有文件,但只有被檢索的文件才能被評分,檢索和評分必須良好配合以找到最相關的文件。
一個典型的例子是搜尋一個類別名稱。根據該類別的流行度,它可能有數千個用法,但可能只有一個定義。如果搜尋未被明確限制在類別定義,固定數量的檢索結果可能在到達包含唯一定義的檔案之前就停止了。隨著程式碼庫的增長,這個問題越來越具挑戰性。
主要挑戰是在大量不太有趣的檔案中找到少數高度相關的檔案。一個有效的方案是補充檢索(supplemental retrieval):將原始查詢改寫為更專門的查詢。例如,補充查詢會限制搜尋範圍只看定義和檔案名稱,並將新檢索的文件加入檢索階段的輸出。在簡單的實作中,需要評分更多文件,但從補充檢索獲得的部分評分資訊可以用來只完整評估檢索階段中最有希望的文件。
結果多樣性(Result Diversity)#
搜尋的另一個面向是結果的多樣性——嘗試在多個類別中提供最佳結果。一個簡單的例子是:對於一個簡單的函式名稱,同時提供 Java 和 Python 的匹配結果,而非讓某一種語言填滿整個第一頁。
當使用者意圖不明確時,這一點尤其重要。多樣性的挑戰在於,結果可以分為許多不同的類別——函式、類別、檔案名稱、本地結果、用法、測試、範例等——但 UI 中沒有足夠的空間來展示所有類別或所有組合。Google 的 Code Search 在這方面做得不如網頁搜尋,但下拉建議列表(類似網頁搜尋的自動完成)經過調整,提供多樣化的頂部檔案名稱、定義和使用者當前工作區中的匹配。
選定的取捨#
完整性:倉庫的 Head 版本#
較大的程式碼庫對搜尋有負面影響:索引更慢更貴、查詢更慢、結果更嘈雜。能否透過犧牲完整性來降低成本——換言之,將某些內容排除在索引之外?答案是可以,但需謹慎:
- 非文字檔案(二進位、圖片、影片、聲音等)通常不是給人閱讀的,除檔案名稱外被丟棄,節省大量資源
- 混淆後的生成式 JavaScript 檔案由於混淆和結構喪失幾乎不可讀,排除它們能減少索引資源和噪音
- 超大檔案(數 MB 以上)很少包含對開發者有用的資訊,排除極端案例可能是正確的選擇
從索引中丟棄檔案有一個很大的缺點:為了讓開發者依賴 Code Search,他們需要能信任它。不幸的是,如果被丟棄的檔案根本沒被索引,就無法對特定搜尋給出不完整結果的回饋。由此造成的困惑和生產力損失是為節省資源付出的高昂代價。因此,Google 選擇寧可索引過多,設定相當高的限制,這些限制主要是為了防止濫用和保證系統穩定性,而非為了節省資源。
另一方面,生成式檔案不在程式碼庫中但索引它們通常是有用的。目前尚未索引,因為整合生成工具和設定會帶來大量的複雜性、困惑和延遲。
完整性:全部結果 vs. 最相關結果#
一般搜尋為了速度犧牲完整性,本質上是賭排名會確保頂部結果包含所有期望的結果。對於 Code Search,排名搜尋是更常見的情況——使用者在可能數百萬個匹配中尋找一個特定項目(如函式定義)。但有時開發者需要所有結果——例如在重構時找到某符號的所有出現。需要所有結果的情況在分析、工具製作和重構(如全域搜尋替換)中很常見。這是與網頁搜尋的根本差異,後者可以採用許多捷徑,例如只考慮高排名項目。
對查詢的分析顯示,約三分之一的使用者搜尋結果少於 20 個。
為了用一個架構同時達成兩個目標,Code Search 將程式碼庫分片(shard),檔案按優先級排序。通常只需考慮每個分片中高優先級檔案的匹配結果,類似網頁搜尋的做法。但如果請求,Code Search 可以從每個分片取得所有結果,保證找到完整結果集。這樣典型搜尋不會因為偶爾需要的完整結果功能而變慢。結果也可以按字母順序而非排名順序返回,這對某些工具很有用。
因此這裡的取捨是更複雜的實作和 API 換取更大的能力,而非更明顯的延遲 vs. 完整性。能夠傳遞完整結果集對工具製作至關重要,也是開發者信任搜尋結果的基礎。
完整性:Head vs. 分支 vs. 全部歷史 vs. 工作區#
是否應該索引不止當前程式碼快照(head)?如果索引超過單一檔案修訂版本,系統複雜度、資源消耗和整體成本會急劇增加。據所知,沒有 IDE 索引當前版本以外的程式碼。觀察 Git 或 Mercurial 等分散式版本控制系統,其效率很大程度來自歷史資料的壓縮,但建構反向索引時這種壓縮優勢會消失。另一個問題是,高效索引圖結構(分散式版本控制系統的基礎)是困難的。
儘管索引多個版本的倉庫很困難,但這樣做允許探索程式碼的變化歷史和尋找已刪除的程式碼。Google 的 Code Search 索引 Piper 的(線性)歷史,使得程式碼庫可以在任意快照處被搜尋、搜尋已刪除的程式碼,甚至搜尋特定作者撰寫的程式碼。
一大好處是廢棄程式碼現在可以直接從程式碼庫刪除——以前,程式碼經常被移到標記為「obsolete」的目錄中以便日後查找。完整歷史索引也為在開發者的工作區(未提交的變更)中有效搜尋奠定了基礎。對於未來,歷史索引開啟了使用有趣信號進行排名的可能性,例如作者身份、程式碼活躍度等。
工作區(workspace)與全域倉庫非常不同:
- 每位開發者可以有自己的工作區
- 工作區中通常只有少量變更的檔案
- 正在開發的檔案頻繁變動
- 工作區只存在相對短暫的時間
為了提供價值,工作區索引必須精確反映工作區的當前狀態。這與全域索引的需求形成對比——全域索引追求的是廣度和歷史深度,而工作區索引追求的是即時性和精確性。
表達力:Token vs. Substring vs. Regex#
規模的影響很大程度上取決於所支援的搜尋功能集。Code Search 支援正則表達式(regex)搜尋,這為查詢語言增加了強大能力,允許指定或排除整組術語,且可用於任何文字——對於缺乏更深層語義工具的文件和語言尤其有幫助。開發者已習慣在其他工具(如 grep)中使用正則表達式,因此不會增加認知負擔。但這種能力是有代價的——建構高效查詢正則表達式的索引具有挑戰性。
替代方案的比較:
- Token-based 索引:擴展性好,因為只儲存原始碼的一小部分,且被標準搜尋引擎良好支援。但處理程式碼時,許多在一般 tokenization 中被忽略的字元(如括號、運算子)在程式碼中具有意義。例如搜尋
function()vs.function(x)或(x ^ y)或=== myClass在大多數 token-based 搜尋中是困難或不可能的。識別符號的 tokenization 也定義不明確(CamelCase、snake_case、或直接連在一起),大小寫不敏感和詞幹化(如將 “searching” 和 “searched” 歸為同一 token)更是重大問題。Tokenization 也使得搜尋空白或其他分隔符(逗號、括號)變得不可能 - Substring 索引:可搜尋任意字元序列,是搜尋能力的一大進步。Trigram 索引是一種高效實作方式,結果索引大小仍遠小於原始碼。但較小的大小以相對較低的召回率為代價——非匹配項需要從結果集中過濾掉,導致查詢較慢。在索引大小、搜尋延遲和資源消耗之間需要找到良好的平衡,這取決於程式碼庫大小、可用資源和每秒搜尋量
- 正則表達式索引:如果有 substring 索引,很容易擴展以支援正則表達式搜尋。基本思路是將正則表達式自動機轉換為一組子字串搜尋。由於不存在完美的 regex 索引,總是可能構造出導致暴力搜尋的查詢。但鑑於只有一小部分使用者查詢是複雜的正則表達式,實務上透過 substring 索引近似的效果非常好
結論#
Code Search 從一個有機的 grep 替代品,發展成為提升開發者生產力的核心工具,沿途利用了 Google 的網頁搜尋技術。這對你意味著什麼?如果你在一個小專案上工作,能輕鬆放進 IDE 中,可能影響不大。但如果你負責較大程式碼庫上工程師的生產力,可能有一些值得借鑑的見解。
對於讀者的啟示:
- 理解程式碼是開發和維護的關鍵,投資於程式碼理解工具的回報雖然難以量化但確實存在。Code Search 新增的每一項功能都被開發者用於日常工作
- 最重要的兩個功能——Kythe 整合(語義程式碼理解)和尋找可運作的範例——都與理解程式碼直接相關(而非找到它或查看它的變更歷史)
- 工具的可見性同樣重要:再好的工具,不知道它存在的人也無法使用。在 Google,Code Search 是新進工程師(Noogler)入職培訓的一部分
- 無論規模大小,設定標準的 IDE 索引設定檔、分享
egrep知識、執行ctags,或建立自訂索引工具,幾乎都會被使用——而且使用方式往往超出預期,你的開發者將因此受益
TL;DRs#
- 幫助開發者理解程式碼能大幅提升工程生產力。在 Google,實現這一目標的關鍵工具是 Code Search
- Code Search 作為其他工具的基礎平台,以及所有文件和開發者工具連結的中央標準位置,具有額外價值
- Google 程式碼庫的巨大規模使得自訂工具(而非
grep或 IDE 索引)成為必要 - 作為互動式工具,Code Search 必須快速,支援「問答」式工作流程。在各方面都期望低延遲:搜尋、瀏覽和索引
- 只有被信任才會被廣泛使用,而只有索引所有程式碼、給出所有結果、並優先顯示期望結果時才會被信任。然而,早期功能較少的版本只要其限制被充分理解,同樣是有用且被廣泛使用的