大型測試#
前面章節談到 Google 如何建立測試文化,以及小型單元測試如何成為開發者日常工作流程的基礎。但其他種類的測試呢?事實上 Google 大量使用「大型測試」(larger tests),它們是健全軟體工程所需風險緩解策略的重要組成部分。不過這些測試也帶來額外挑戰,必須確保它們是有價值的資產,而非資源黑洞。
什麼是大型測試?#
Google 對測試大小(test size)有明確定義:小型測試限制在一個執行緒、一個行程、一台機器。大型測試則沒有這些限制。同時 Google 也區分測試範疇(test scope)——單元測試的範疇必然小於整合測試,而最大範疇的測試(end-to-end 或系統測試)通常涉及多個真實依賴、較少的 test doubles。
大型測試具備以下特性:
- 可能很慢:預設 timeout 為 15 分鐘或 1 小時,有些甚至執行數小時乃至數天
- 可能非封閉(nonhermetic):可能與其他測試或真實流量共享資源
- 可能不具確定性(nondeterministic):一旦非封閉,幾乎無法保證確定性
那為什麼還需要大型測試?單元測試能給你對個別函式、物件和模組的信心,但大型測試提供的是對整體系統如預期運作的信心,而且自動化測試的擴展性遠優於手動測試。
保真度(Fidelity)#
大型測試存在的首要原因是為了處理保真度問題。保真度是指測試反映被測系統(SUT, System Under Test)真實行為的程度。
從環境角度來看,單元測試將測試與一小段程式碼綁在一起執行,與正式環境的運作方式差異很大;正式環境本身自然是保真度最高的測試場域,而中間存在一系列過渡選項。大型測試的關鍵在於找到適當的平衡點,因為提高保真度同時意味著提高成本,甚至增加失敗風險。

Figure 14.1: Scale of increasing fidelity
測試內容的真實程度也很重要。手工打造的測試資料若看起來不切實際,往往會被工程師忽視。從正式環境複製的資料更貼近真實,但如何在新程式碼上線前就建立真實的測試流量,仍是一大挑戰。單元測試的資料大多是手工產生的,覆蓋範圍有限且容易帶有作者的偏見,未覆蓋的情境構成測試中的保真度缺口。
單元測試常見的覆蓋缺口#
以下是單元測試無法有效覆蓋的領域:
不忠實的 Test Doubles(Unfaithful doubles)
單元測試中的 mock 通常由撰寫受測程式碼的同一位工程師定義其行為。但該工程師往往不是被 mock 的元件的作者,可能對其實際行為有誤解。此外,mock 會隨時間過時——如果真實實作改變了,而 mock-based 的測試不在真實實作作者的可見範圍內,就不會收到需要更新的訊號。
組態問題(Configuration issues)
單元測試涵蓋二進位檔內的程式碼,但二進位檔的執行通常依賴部署組態或啟動腳本。如果組態檔或組態與二進位檔之間存在相容性問題,可能導致重大使用者問題。在 Google,組態變更是重大服務中斷的頭號原因。例如 2013 年曾因一個未經測試的網路組態推送,造成全球性服務中斷。
負載下的問題(Issues under load)
效能、負載和壓力測試通常需要對二進位檔發送大量流量(可能高達每秒數千甚至數百萬次查詢),這在典型的單元測試模型中很難實現。
未預期的行為與副作用
單元測試受限於撰寫者的想像力,只能測試預期的行為與輸入。根據 Hyrum’s Law,真正的公開 API 不只是聲明的契約,而是所有可見的行為。
湧現行為與「真空效應」
單元測試刻意排除真實依賴、網路和資料的混亂以求速度與可靠性,但這也意味著它遺漏了某些缺陷類別。
為什麼不全用大型測試?#
開發者友善的測試需具備三個特性:
- 可靠(Reliable):不會是 flaky 的,提供有用的通過/失敗訊號
- 快速(Fast):不中斷開發者工作流程
- 可擴展(Scalable):能高效地執行所有受影響的測試
大型測試往往違反以上所有特性——更容易 flaky、更慢、更難擴展。此外還有兩個額外挑戰:
- 所有權問題:大型測試跨越多個元件與團隊,若無明確的所有者,測試將逐漸腐化
- 缺乏標準化:不同團隊使用不同的平台、語言、基礎設施和測試框架,導致大規模變更時大型測試常被跳過
Google 的大型測試實務#
Google 在 2003 年 GWS 強制要求自動化測試之前,就已使用自動化的大型測試。例如 AdWords 在 2001 年建立了端對端測試,Search 在 2002 年撰寫了索引程式碼的回歸測試。
當 TAP(Google 的持續建置系統)取代 C/J Build 時,它只能處理符合資格要求的測試——在時間限制內可建置且封閉的測試。大多數大型測試不符合這些要求,但這並沒有消除對其他類型測試的需求。
大型測試與時間#
隨著程式碼預期壽命增長,適合的測試類型也會改變。對於分鐘級的小腳本,手動測試最常見;但隨著壽命增長,自動化大型測試的價值也隨之增加,主要的考量變成可維護性。
時間的影響可能也是「冰淇淋甜筒」(ice cream cone)測試反模式形成的原因之一。當開發始於手動測試(認為程式碼只會存活幾分鐘),那些手動測試會累積並主導整體測試組合。更糟的是,如果程式碼一開始就難以進行單元測試,唯一能寫的自動化測試就是端對端測試,等於在幾天內就製造了「遺留程式碼」。
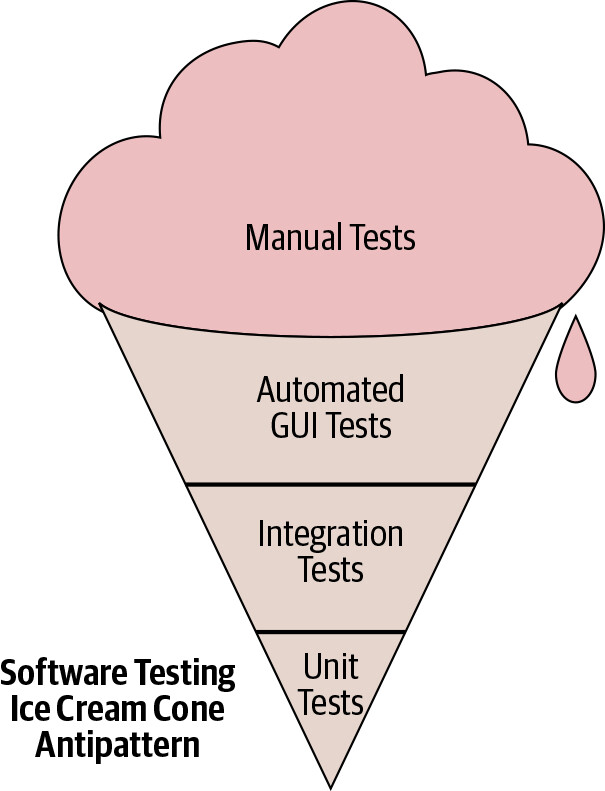
Figure 14.2: The ice cream cone testing antipattern
在開發初期幾天內就應該朝測試金字塔(test pyramid)邁進,先建立單元測試,之後引入自動化整合測試,逐步取代手動端對端測試。
大型測試與 Google 的規模#
在由微服務組成的系統中,互連模式呈圖形結構。每新增一個節點,通過它的不同執行路徑數量就會乘數增長。端對端測試的情境增長可能是指數級或組合級的,因此系統越大,越需要找到替代的大型測試策略。
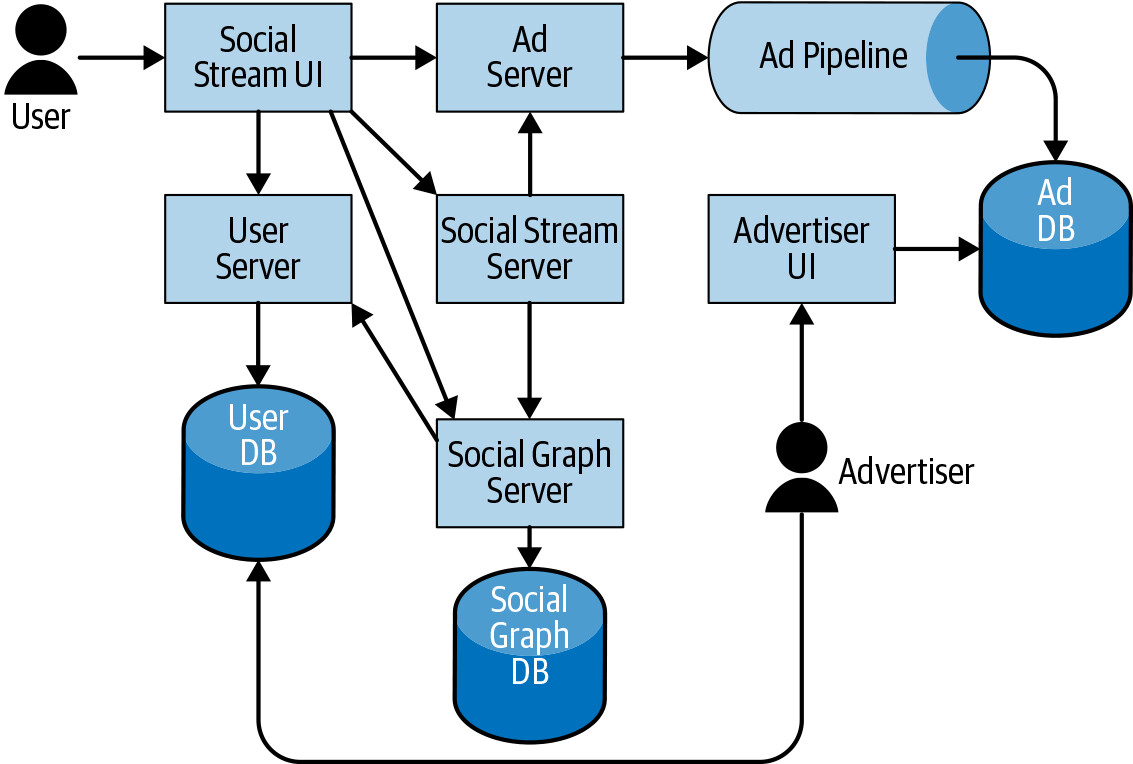
Figure 14.3: Example of a fairly small SUT: a social network with advertising
但大型測試的價值也隨規模增長。如果 service doubles 的保真度為 1 - ε,當所有元件組合在一起時,出現 bug 的機率隨 N 呈指數成長。例如,如果兩個 doubles 的準確率各為 10%,出 bug 的機率就高達 99%。因此,實現在此規模下可行且保真度合理的大型測試至關重要。
「最小可行測試」原則:即使是整合測試,越小越好——幾個大型測試勝過一個巨型測試。由於測試範疇常與 SUT 範疇耦合,縮小 SUT 有助於縮小測試。一種方法是將使用者旅程拆分為多個較小的成對整合測試,透過「鏈式測試」(chained tests)將一個測試的輸出作為另一個測試的輸入。

Figure 14.4: Chained tests
大型測試的結構#
大多數大型測試遵循共通的工作流程:
- 取得被測系統(Obtain a system under test)
- 植入必要的測試資料(Seed necessary test data)
- 對被測系統執行操作(Perform actions)
- 驗證行為(Verify behaviors)
被測系統(The System Under Test)#
單元測試聚焦於一個類別或模組,測試程式碼與受測程式碼在同一行程中執行。大型測試的 SUT 則通常是一個或多個獨立行程,測試程式碼也常在自己的行程中。
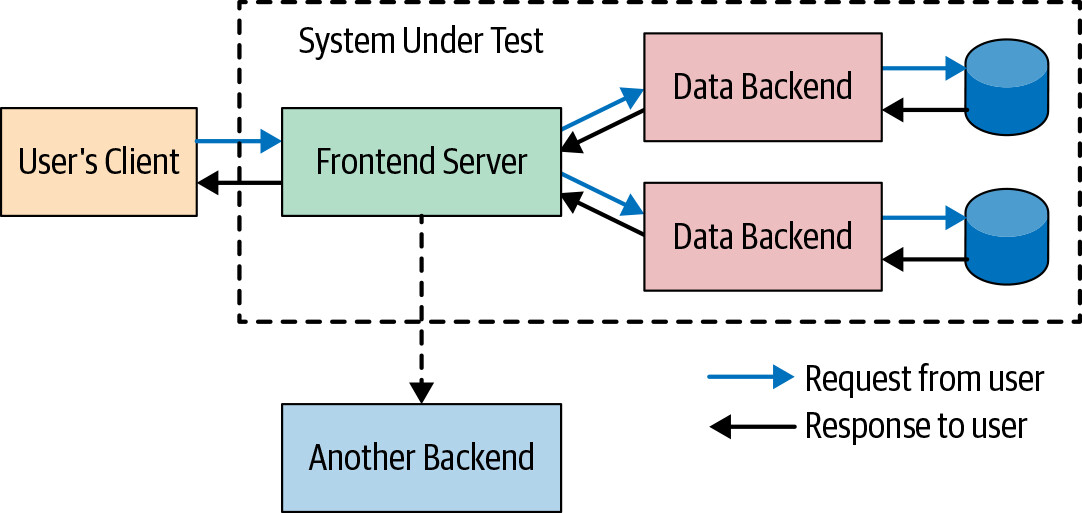
Figure 14.5: An example system under test (SUT)
SUT 的範疇由兩個主要因素決定:
- 封閉性(Hermeticity):SUT 與其他元件的隔離程度。高封閉性減少並行與基礎設施 flakiness 的影響
- 保真度(Fidelity):SUT 反映正式系統的準確程度。高保真度意味著使用接近正式環境的二進位檔、組態和拓撲
這兩個因素往往彼此衝突。Google 使用的 SUT 形式包括:
- 單行程 SUT(Single-process):整個系統打包在單一二進位檔中。封閉性最高,但保真度最低
- 單機 SUT(Single-machine):多個獨立二進位檔在同一台機器上執行,用於「中型」測試
- 多機 SUT(Multimachine):分散在多台機器上,接近正式雲端部署,保真度更高但更容易受網路和機器 flakiness 影響
- 共享環境(Shared environments):使用 staging 或正式環境,成本最低但可能與其他使用者衝突
- 混合型(Hybrids):受測部分明確啟動,但其後端使用共享環境
封閉 SUT 的優勢
正式環境測試無法在程式碼到達該環境前執行,因此無法阻止程式碼發布——SUT 來得太晚。共享 staging 環境也有類似限制,且不隨工程師和服務數量增長而擴展。雲端隔離或機器封閉的 SUT 能避免這些衝突和預約需求。
在正式環境測試的風險:Webdriver Torso 事件。Google 為驗證 YouTube 的影片渲染品質,在名為 Webdriver Torso 的公開頻道自動產生並上傳測試影片。該頻道被 Wired 等媒體報導,引發大眾揣測。最終 Google 以幽默方式(包含 Rickroll 和彩蛋)回應。這提醒我們:必須考慮到正式環境測試資料被終端使用者發現的可能性。
在問題邊界處縮小 SUT
某些測試邊界特別痛苦,值得避開。前端加後端的測試尤其痛苦,因為 UI 測試以不可靠且昂貴聞名——UI 外觀變動容易讓測試變脆弱,且 UI 常有難以測試的非同步行為。
較好的做法是在 UI/API 邊界分割測試:用公開 API 驅動端對端測試。對於第三方依賴也應如此——避免讓自動化測試使用真實的第三方 API。
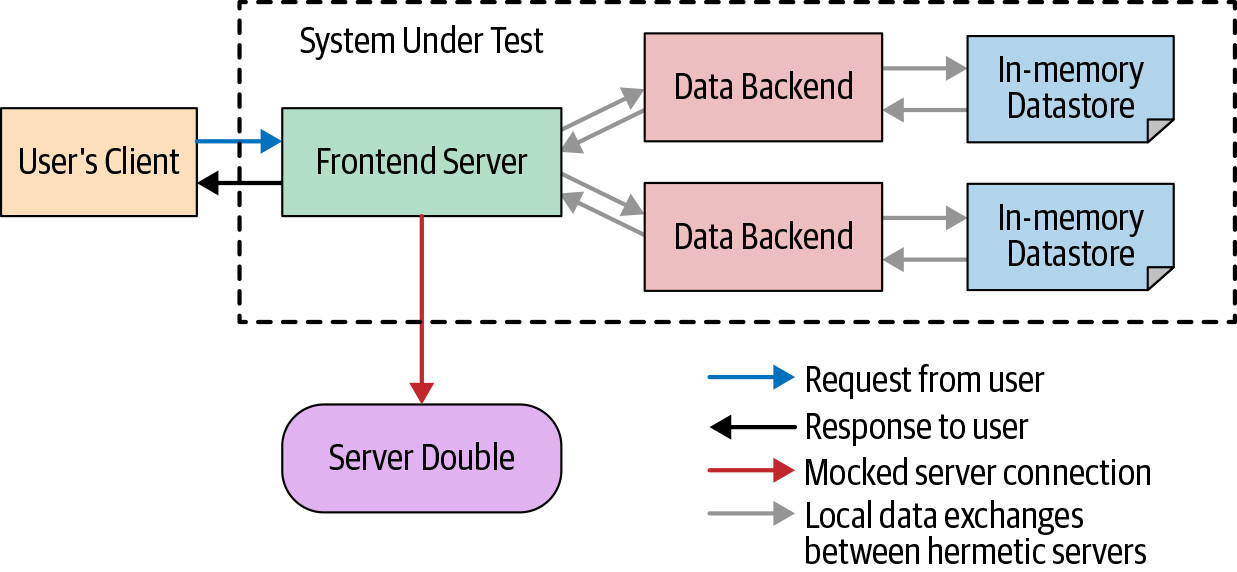
Figure 14.6: A reduced-size SUT
透過以記憶體資料庫取代實際資料庫、移除範疇外的伺服器,可以縮小 SUT 使其更可能在單機上執行。關鍵在於識別保真度與成本/可靠性之間的取捨,找到合理的邊界。
Record/Replay 代理#
如何確保 test double 確實反映了依賴服務的實際行為?Google 外部流行的做法是使用 consumer-driven contract tests(如 Pact、Spring Cloud Contracts),由客戶端和服務提供者共同定義契約。
Google 的做法有所不同:使用大型測試在 Record Mode 下錄製對外部服務的流量,再於 Replay Mode 下回放來執行較小的測試。Record Mode 持續在 post-submit 上執行以產生流量日誌;Replay Mode 則用於開發和 presubmit 測試。
當客戶端行為大幅改變時,請求可能無法匹配已錄製的流量,此時工程師必須重新以 Record Mode 執行測試。因此讓 Record 測試易於執行、快速且穩定非常重要。
測試資料(Test Data)#
大型測試需要兩種資料:
- 種子資料(Seeded data):測試開始前預先初始化到 SUT 中的資料
- 測試流量(Test traffic):測試執行期間發送給 SUT 的資料
SUT 的狀態初始化工作通常比單元測試的 setup 複雜數個數量級,涉及領域資料(domain data)、寫實基線(realistic baseline)以及複雜的資料植入 API。
資料可透過以下方式產生:
- 手工打造:最直覺但工作量大
- 從正式環境複製:更貼近真實,但資料量可能過大
- 取樣:減少資料量以縮短測試時間,「智慧取樣」可用最少資料達到最大覆蓋
驗證(Verification)#
- 手動驗證:人工與 SUT 互動,執行回歸測試計畫或探索性測試。但手動測試不會次線性擴展
- 斷言(Assertions):如
assertThat(response.Contains("Colossal Cave")),與單元測試類似的明確檢查 - A/B 比較(Differential):執行兩份 SUT、發送相同資料、比較輸出,再由人工確認差異是否符合預期
大型測試的類型#
結合不同的 SUT、資料和驗證方式,可組成各種大型測試:
一或多個二進位檔的功能測試#
- SUT:單機封閉或雲端隔離部署
- 資料:手工打造
- 驗證:斷言
測試多個二進位檔(如微服務環境)之間的真實互動,透過公開 API 與由所有相關二進位檔組成的 SUT 互動。
瀏覽器與裝置測試#
Web UI 和行動應用的測試是功能測試的特例。雖然可以對底層程式碼做單元測試,但對終端使用者而言,公開 API 就是應用本身。透過前端以第三方角度互動的測試提供額外的覆蓋層。
效能、負載與壓力測試#
- SUT:雲端隔離部署
- 資料:手工打造或從正式環境多工複製
- 驗證:差異比較(效能指標)
負載和壓力處理是系統的「高度湧現」特性——屬於整體系統而非個別成員。因此這些測試應盡量接近正式環境。為消除效能測試中的雜訊,可調整部署拓撲:最佳做法是在同一台機器上執行新舊兩個版本;若不可行,則透過多次執行並移除峰值和谷值來校準。
部署組態測試#
- SUT:單機封閉或雲端隔離
- 資料:無
- 驗證:斷言(不會崩潰)
本質上是 SUT 的冒煙測試——如果 SUT 成功啟動,測試就通過。
探索性測試(Exploratory Testing)#
- SUT:正式環境或共享 staging
- 資料:正式環境或已知測試宇宙
- 驗證:手動
經過訓練的使用者/測試員透過公開 API 嘗試新的使用情境,尋找行為偏離預期或存在安全漏洞的地方。探索性測試發現的缺陷應以自動化測試複製,因為手動測試不會次線性擴展。
Bug Bash 是一種常見做法:團隊安排一個「會議」,所有人在該期間手動測試產品,目標是透過足夠的互動多樣性來發現可疑行為和明確的 bug。
A/B Diff 回歸測試#
- SUT:兩個雲端隔離環境
- 資料:通常從正式環境多工複製或取樣
- 驗證:A/B diff 比較
這可能是 Google 最常見的大型測試形式,概念可追溯至 1998 年。測試將流量發送到公開 API,比較新舊版本的回應,任何行為偏差都必須確認是預期的還是回歸。
變體包括 A-A 測試(比較系統與自身以識別不確定性行為和雜訊)以及 A-B-C 測試(同時比較上一正式版本、基線建置和待提交變更)。
限制:需要有人理解結果以判斷差異是否預期;雜訊會增加人工調查成本;產生足夠有用的流量具挑戰性;同時維護兩個 SUT 可能使複雜度加倍。
使用者驗收測試(UAT)#
- SUT:機器封閉或雲端隔離
- 資料:手工打造
- 驗證:斷言
由特定終端客戶或客戶代理(如產品經理)定義的自動化測試,透過公開 API 確保特定使用者旅程的整體行為符合預期。公開框架如 Cucumber 和 RSpec 可讓測試以使用者友善的語言撰寫。Google 實際上並不大量使用自動化 UAT,因為定義產品行為的人通常本身就精通程式語言。
Probers 與 Canary Analysis#
- SUT:正式環境
- 資料:正式環境
- 驗證:斷言與 A/B diff(指標)
Probers 是對正式環境執行的功能測試,通常執行已知的、確定性的唯讀操作。例如在 google.com 執行搜尋並驗證有回傳結果(但不驗證結果內容),本質上是正式系統的冒煙測試。
Canary Analysis 在發布推送到正式環境時執行,比較 canary 服務與基線部分的健康指標,確保沒有偏差。
限制:在此時間點抓到的問題已經影響了終端使用者。若 prober 執行可變動(寫入)操作,會修改正式環境狀態,可能導致不確定性、斷言失敗或使用者可見的副作用。
災難復原與混沌工程#
- SUT:正式環境
- 資料:正式環境及使用者設計的故障注入
- 驗證:手動與 A/B diff(指標)
Google 每年進行名為 DiRT(Disaster Recovery Testing)的演習,向基礎設施注入幾乎行星級規模的故障——模擬從資料中心火災到惡意攻擊的各種情境。一次著名案例中,Google 模擬地震完全隔離了 Mountain View 總部,不僅暴露技術缺陷,還揭示了所有關鍵決策者無法聯繫時營運公司的挑戰。
混沌工程(chaos engineering)則是更持續性的做法,由 Netflix 帶動流行。它持續在系統中引入背景級的故障以觀察反應。Google 內部使用名為 Catzilla 的系統,每週執行數千次混沌測試。
限制:DiRT 成本高昂、執行頻率低。在正式環境中產生此等級的中斷會造成實際痛苦並影響員工效能。
使用者評估(User Evaluation)#
- SUT:正式環境
- 資料:正式環境
- 驗證:手動與 A/B diff(指標)
透過正式環境的測試可收集大量使用者行為資料:
- Dogfooding:透過限定發布讓內部員工使用新功能並提供回饋
- 實驗(Experimentation):對部分使用者啟用新行為,比較實驗組與對照組的指標差異。這是 Google 極其重要的方法
- 評分員評估(Rater evaluation):由人類評分員判斷哪個結果「更好」,對不確定性系統(如機器學習)尤為關鍵
大型測試與開發者工作流程#
即使大型測試不適用標準的單元測試基礎設施,將其整合進開發者工作流程仍然至關重要。Google 的做法包括為大型測試設置獨立的 post-submit 持續建置,並鼓勵在 presubmit 階段執行以直接向作者提供回饋。
對於需要手動確認差異的 A/B diff 測試,可以將其納入 code review 流程——在核准變更前須先核准 UI 中的差異。
撰寫大型測試#
撰寫大型測試的最佳方式是擁有清楚的程式庫、文件和範例。Google 除了重用斷言程式庫外,還建立了用於與 SUT 互動、執行 A/B diff、植入測試資料和編排測試工作流程的程式庫。
A/B diff 測試之所以受歡迎,原因之一是在驗證步驟上的人力成本較低。同樣地,正式環境 SUT 比隔離封閉 SUT 的維護成本更低。但必須從整體角度衡量——如果手動對帳差異或保障正式環境測試的成本超過節省的部分,就會變得不划算。
執行大型測試#
加速測試
工程師不會等待慢測試。加速測試的最佳方式通常是縮小範疇或拆分為可平行執行的較小測試。其他技巧包括:
- 用**輪詢(polling)**取代固定的 sleep,搭配 timeout 值
- 實作事件處理器(event handler)
- 訂閱通知系統等待事件完成
- 降低內部系統超時和延遲:正式系統假設分散部署拓撲,但測試 SUT 可能在單機上執行
- 最佳化測試建置時間:對非核心依賴使用已知良好版本的預建置二進位檔
消除 Flakiness
Flakiness 對大型測試的傷害比對單元測試更大,可能使測試完全無法使用。最小化 flakiness 的策略:
- 縮小測試範疇——封閉 SUT 避免多使用者和真實世界的 flakiness
- 使測試具備反應性或事件驅動,取代定時 sleep
- 識別內部系統超時的取捨:對終端使用者可容忍的最大超時 vs 處理 flaky 執行行為
- 確保失敗模式明確,讓工程師容易判斷是真正的 bug 還是 flaky timeout
讓測試結果可理解
好的大型測試在失敗時應該:
- 清楚識別失敗是什麼:提供有脈絡的訊息,而非只有 “Assertion failed” 和 stack trace
- 最小化識別根本原因所需的努力:在大型測試中 stack trace 不太有用,因為呼叫鏈可能跨越多個行程邊界。應產生跨呼叫鏈的追蹤紀錄(如 Google 的 Dapper 框架)
- 提供支援與聯絡資訊:讓測試執行者容易取得協助
擁有大型測試#
大型測試必須有明確記載的擁有者,否則測試將面臨:
- 貢獻者更難修改和更新測試
- 測試失敗的解決時間更長
- 測試最終腐化
元件整合測試應由專案負責人擁有;功能導向測試應由「功能擁有者」擁有。Google 使用以下機制自動化所有權管理:
- 常規程式碼所有權:利用 monorepo 中已有的 OWNERS 資訊
- 逐測試標註(Per-test annotations):以結構化標註記錄每個測試方法的擁有者
結論#
完整的測試套件需要大型測試,以確保測試的保真度與被測系統相稱,並覆蓋單元測試無法充分處理的問題。由於大型測試本質上更複雜且執行更慢,必須確保其有明確的擁有者、良好的維護,並在必要時執行(例如部署到正式環境前)。整體而言,大型測試仍須盡可能地小(在保持保真度的前提下),以避免開發者摩擦。
TL;DRs#
- 大型測試涵蓋了單元測試無法覆蓋的領域
- 大型測試由被測系統(SUT)、資料、操作和驗證組成
- 好的設計包含一份識別風險並以大型測試緩解風險的測試策略
- 必須額外努力確保大型測試不會在開發者工作流程中造成摩擦