Nothing is built on stone; all is built on sand, but we must build as if the sand were stone. — Jorge Luis Borges
軟體工程與程式設計的區別#
Google 內部有一句話:「軟體工程就是程式設計對時間的積分」(Software engineering is programming integrated over time)。程式設計是產生新軟體的行為,但軟體工程還涵蓋了對程式碼的修改與維護。兩者之間的關鍵差異可以歸納為三個面向:
- 時間(Time):軟體的預期壽命有多長?需要面對多少變化?
- 規模(Scale):有多少人參與開發與維護?組織如何高效運作?
- 取捨(Trade-offs):面對不完美的資訊,如何做出合理的決策?
程式碼的預期壽命差異可達十萬倍——從只用幾分鐘的腳本,到需要運行數十年的系統。壽命短的程式基本不受時間影響,不需要考慮底層函式庫、作業系統或語言版本的升級問題。但隨著壽命拉長,幾乎所有的依賴——無論是顯性還是隱性的——都會發生變化。這個認知正是軟體工程與純粹程式設計之間的根本差異。
軟體的可持續性(Sustainability):如果在軟體的預期壽命內,你有能力對任何有價值的技術或商業變化做出回應,那麼你的專案就是可持續的。關鍵在於「有能力」——你可以選擇不升級,但不能是「無法升級」。
從規模的角度來看,程式設計通常是個人的創作行為,而軟體工程則是團隊協作。早期對軟體工程的一個定義是:「多人開發的多版本程式」(The multiperson development of multiversion programs)。團隊組織、專案組成,以及軟體專案的政策和實踐,都是軟體工程在規模面向上的複雜性體現。
從決策的角度來看,軟體工程師需要在多條前進路徑之間評估取捨,通常面對的是高風險且資訊不完整的情境。軟體工程師或工程領導者的職責,就是在組織、產品和開發流程中追求可持續性並管理規模化成本,然後基於這些考量做出理性決策。
Google 的經驗是基於數十年壽命的軟體、數萬名工程師,以及全球規模的運算資源。書中的做法不一定完全適用於所有組織,但大多數在大規模下必要的實踐,在小規模下同樣適用。
時間與變化#
軟體壽命的光譜#
在學習程式設計時,寫出的程式碼壽命通常只有幾小時或幾天。這些程式是「寫完就丟」的,不需要重構,更不需要長期維護。在業界,行動應用程式的壽命也往往較短,完整重寫相當常見。早期新創公司的工程師可能合理地選擇專注於眼前目標而非長期投資。
而在光譜的另一端,有些成功專案的壽命實際上是無限期的:Google 搜尋、Linux 核心、Apache HTTP 伺服器——我們無法合理預測這些專案的終點。
考慮圖 1-1,它展示了「預期壽命」光譜兩端的軟體專案。對於壽命只有幾小時的程式,如果作業系統出了新版本,你該放下手邊工作去升級嗎?當然不。但如果 Google 搜尋還在使用 1990 年代的作業系統版本,那顯然就是個嚴重問題。
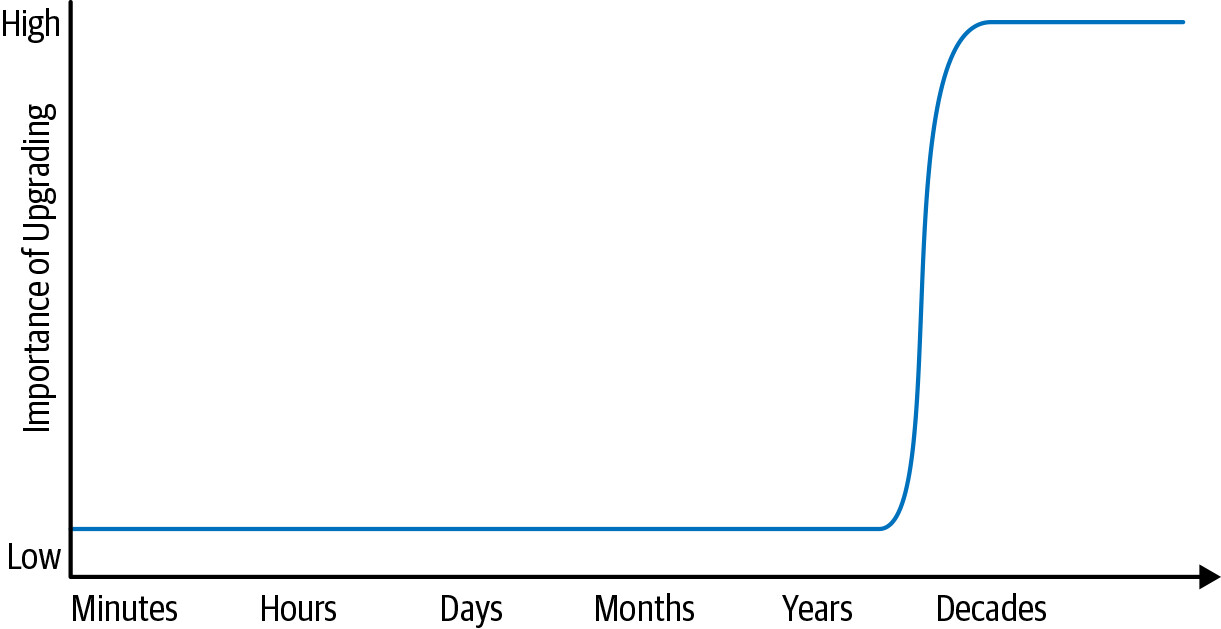
Figure 1.1: Life span and the importance of upgrades
升級的痛點與可持續性#
在這個光譜之間存在一個轉換點:專案必須開始回應外部變化。對於從一開始就沒有規劃升級的專案,這個轉換會特別痛苦,原因有三:
- 這是專案從未執行過的任務,隱含了更多未被發現的假設
- 嘗試升級的工程師缺乏這類任務的經驗
- 升級的規模往往比正常情況大得多——一次要消化好幾年份的升級
經歷過一次痛苦的升級後,團隊很容易高估後續升級的成本,而決定「再也不升級了」。這些公司最終要麼選擇全部重寫,要麼承諾永不升級。然而,比起一味逃避痛苦的任務,更負責任的做法有時是投資讓升級變得不那麼痛苦。
可持續性的本質:不僅是完成第一次大升級,更要達到能夠可靠地持續保持最新狀態的程度。這需要規劃並管理必要變更的影響。
長期來看,我們需要更加注意「恰好能用」(happens to work)和「可維護」(is maintainable)之間的差異。沒有完美的方法來識別這些問題,保持軟體的長期可維護性是一場持續的戰鬥。
Hyrum 定律#
如果你維護的專案有其他工程師在使用,關於「能用」與「可維護」最重要的一課就是 Hyrum 定律(Hyrum’s Law):
Hyrum 定律:當一個 API 擁有足夠多的使用者時,你在契約中承諾什麼已經不重要了——你的系統的所有可觀察行為都會被某些人所依賴。
Hyrum 定律就像熵(entropy)一樣,是討論軟體隨時間變化時的主導因素。熵永遠不會減少,但這不代表我們不該追求效率;Hyrum 定律一定會適用,但這不代表我們不能為它做規劃、嘗試更好地理解它。我們可以減緩它的影響,但永遠無法完全消除。
作為 API 的擁有者,明確介面承諾可以獲得一些靈活性,但實務上,一項變更的複雜度和難度還取決於使用者對你 API 某些可觀察行為的依賴程度。給予足夠的時間和足夠多的使用者,即使是最無害的變更也會破壞某些東西。
範例:Hash 排序#
考慮雜湊迭代順序(hash iteration ordering)的例子。把五個元素放入一個基於雜湊的集合中,取出時的順序是什麼?
>>> for i in {"apple", "banana", "carrot", "durian", "eggplant"}: print(i)
...
durian
carrot
apple
eggplant
banana大多數程式設計師知道雜湊表的順序是不確定的,但很少有人知道他們所使用的特定雜湊表是否打算永遠提供那個特定的排序。過去十幾二十年間,業界的經驗已經演變:
- 雜湊洪水攻擊(Hash flooding)提供了更多使迭代順序非確定性的誘因
- 對改進雜湊演算法或容器的研究可能帶來效率提升,但需要改變迭代順序
- 根據 Hyrum 定律,如果程式設計師有能力依賴雜湊表的遍歷順序,他們就會這麼做
對於短期程式來說,依賴容器的迭代順序不會造成技術問題。但對軟體工程專案而言,這種依賴是一種風險——只要時間夠長,就會有理由需要改變那個迭代順序。有些語言甚至在不同版本之間刻意隨機化雜湊排序,試圖防止依賴——但即使如此,還是有程式碼把雜湊迭代順序當作低效的隨機數產生器來使用。
思考「現在能用」與「永遠能用」兩種心態的差異,可以得出清晰的關係:依賴脆弱的、未公開特性的程式碼通常被稱為「hacky」或「clever」;而遵循最佳實踐並為未來做規劃的程式碼則更可能被描述為「clean」和「maintainable」。在 Google 我們說:「如果 ‘clever’ 是讚美,那就是程式設計;如果 ‘clever’ 是指控,那就是軟體工程。」
為何不直接追求「什麼都不變」?#
大多數專案面臨的底層技術遠比純 C 語言環境更容易變化。程式語言和執行環境的變動頻率遠高於 C。安全漏洞可能出現在任何層級的技術中——從處理器到網路函式庫到應用程式碼。如果你因為假設「什麼都不會變」而無法部署 Heartbleed 補丁、或無法緩解 Meltdown 和 Spectre 這類推測性執行問題,那就是一場高風險的賭博。
效率改進使情況更加複雜。早期 Google 時代的演算法和資料結構在現代硬體上可能效率低下:鏈結串列(linked list)或二元搜尋樹仍然能用,但 CPU 週期與記憶體延遲之間不斷擴大的差距,改變了「高效程式碼」的定義。向後相容性確保舊系統仍能運作,但不保證舊的最佳化仍然有幫助。
對長期專案而言,不投資可持續性的風險很大。變化本身不一定是好事——我們不應該為了變化而變化。但我們確實需要具備變化的能力。如果我們承認這種最終的必要性,就應該考慮是否投資讓這種能力變得廉價。
規模與效率#
可擴展性的挑戰#
程式碼庫的可持續性意味著:你的組織有能力安全地改變所有應該改變的東西,並且能在程式碼庫的整個生命週期中持續做到。隱藏在「能力」這個概念中的還有成本問題:如果一項變更的成本過高,它很可能被推遲。如果成本隨時間超線性增長(superlinearly),那麼這項作業顯然不具可擴展性。
需要考慮擴展性的不只是人力成本:
- 軟體本身需要在運算、記憶體、儲存和頻寬等傳統資源上良好擴展
- 軟體的開發過程也需要擴展——包括人力時間投入和支持開發工作流程的運算資源
- 程式碼庫本身也需要擴展——建構系統或版控系統若超線性增長,終將無法繼續
許多問題(如「完整建構需要多久?」、「拉取儲存庫新副本需要多久?」、「升級到新語言版本的成本是多少?」)變化緩慢,容易像溫水煮青蛙一樣被忽視。只有全組織的意識和對擴展性的承諾,才能控制這些問題。
核心原則:組織中所有用來產出和維護程式碼的事物,都應該在整體成本和資源消耗方面具有可擴展性。特別是,所有需要重複做的事情,都應該在人力投入方面具有可擴展性。
不具擴展性的政策#
要辨識具有不良擴展特性的政策,可以考慮將組織規模放大 10 倍或 100 倍時,單一工程師的工作量會如何變化。
棄用(Deprecation)的傳統做法是一個典型反例。當開發出新的 Widget 後,專案負責人宣佈「我們將在 8 月 15 日刪除舊 Widget,請確保已遷移」。這種做法在小型環境可能有效,但隨著依賴圖的深度和廣度增加,很快就會失敗。
Google 在 2012 年制定了 Churn Rule(變動規則):基礎設施團隊必須自行將內部使用者遷移到新版本,或以向後相容的方式就地更新。這個政策的擴展性更好:
- 依賴專案不再需要花費越來越多的精力僅僅為了跟上變化
- 一組專家執行變更的效率優於要求每個使用者自行維護
- 專業知識的擴展性優於分散式勞動:專家花時間深入了解整個問題後,將專業知識應用於每個子問題
開發分支(Development branches)的傳統使用方式也有內建的擴展問題。每個團隊或功能使用獨立的開發分支,在合併時會觸發其他仍在開發分支上工作的工程師進行昂貴的重新同步和測試。對 5 到 10 個分支的小型組織可能可行,但隨著組織和分支數量增長,開銷會不斷增加。
具有良好擴展性的政策#
Google 最受歡迎的內部政策之一是 Beyonce Rule(乘勝追擊規則):「如果產品因基礎設施變更而發生故障,但該問題未被持續整合(Continuous Integration, CI)系統中的測試揭露,那就不是基礎設施變更的錯。」更口語化的說法是:「如果你喜歡它,你就該為它寫 CI 測試。」
從擴展性的角度來看,Beyonce Rule 意味著那些複雜的、一次性的、不在通用 CI 系統中觸發的客製測試不算數。沒有這條規則,基礎設施團隊的工程師可能需要追蹤每個受影響的團隊,詢問如何運行他們的測試——在一百人的規模下或許還做得到,在更大規模下絕對承受不起。
專業知識與共享溝通論壇也能隨著組織規模良好擴展。當工程師在共享論壇中討論和回答問題時,知識會自然傳播。如果你有一百個寫 Java 的工程師,一位樂於助人的 Java 專家很快就能讓這一百個工程師寫出更好的 Java 程式碼。知識是有傳染性的,專家是傳播者。
範例:編譯器升級#
2006 年 Google 歷史上最著名的編譯器升級清楚說明了這些原則。當時 Google 已運作數年,擁有數千名工程師,但大約五年沒有更新過編譯器。大多數工程師沒有編譯器變更的經驗,大多數程式碼只接觸過單一編譯器版本。升級非常痛苦——許多 Hyrum 定律問題已悄悄滲入程式碼庫,加深了對特定編譯器版本的依賴。當時還沒有 Beyonce Rule,也沒有普及的 CI 系統,所以很難事前知道變更的影響。
這次痛苦的經歷促使 Google 開始專注於技術和組織變革,將規模轉化為優勢:
- 自動化(Automation):讓單一人員能做更多事
- 整合與一致性(Consolidation/Consistency):讓底層變更的影響範圍受限
- 專業知識(Expertise):讓少數人員能做更多事
越頻繁地更新基礎設施,更新就越容易。在經歷過多次升級的生態系統中,程式碼不再依賴底層實作的細微差異,而是依賴語言或作業系統保證的實際抽象層。
通過這些經驗,Google 歸納出影響程式碼庫靈活性的多個因素:
- 專業知識(Expertise):對某些語言,已完成數百次跨平台的編譯器升級
- 穩定性(Stability):因為更頻繁地採用新版本,版本之間的變化更少
- 一致性(Conformity):因為定期升級,未經升級的程式碼更少
- 熟練度(Familiarity):因為夠頻繁,可以發現流程中的冗餘並嘗試自動化
- 政策(Policy):有 Beyonce Rule 等流程,基礎設施團隊只需關注 CI 系統中可見的使用情況
核心教訓不是關於編譯器升級的頻率或難度,而是:一旦意識到某項任務是必要的,就要找到方法確保即使程式碼庫持續增長,仍能以固定數量的工程師完成該任務。停滯不前是一種選項,但往往不是明智的選項。
左移(Shifting Left)#
在開發者工作流程中更早發現問題通常能降低成本。考慮一個功能的開發時間線,從左到右依次為:構思與設計、實作、審查、測試、提交、金絲雀部署,以及最終的正式部署。將問題偵測「左移」到時間線的更早階段,修復成本會更低。
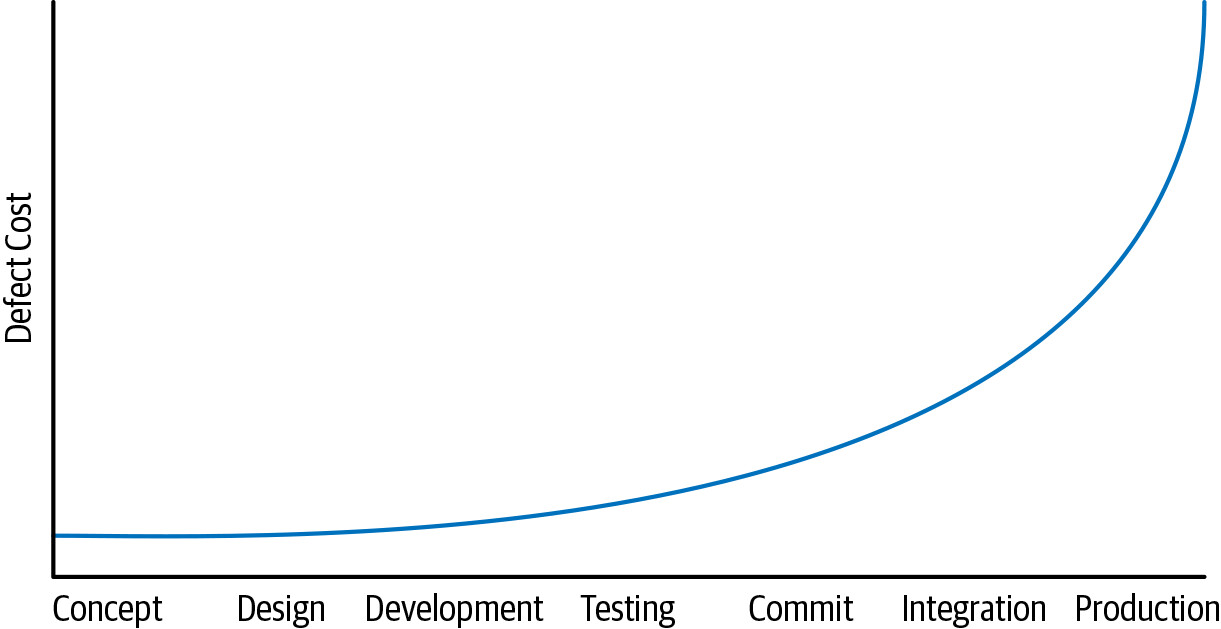
Figure 1.2: Timeline of the developer workflow
這個概念最初來自資安領域,呼籲「在安全性上左移」(shift left on security)。邏輯很簡單:
- 如果安全問題在產品上線後才被發現,代價極其昂貴
- 如果在部署到正式環境前被發現,修復仍然費工,但成本較低
- 如果在開發者提交到版控前就被發現,成本最低——開發者已經理解該功能,根據新的安全約束進行修訂,比提交後讓別人分類和修復要便宜得多
同樣的模式在本書中反覆出現:被靜態分析和程式碼審查在提交前攔截的 bug,比進入正式環境的 bug 便宜得多。提供在開發流程早期就能凸顯品質、可靠性和安全性的工具與實踐,是許多基礎設施團隊的共同目標。沒有任何單一流程或工具需要完美,因此可以採取縱深防禦(defense-in-depth)策略,盡可能在圖表的左側攔截更多缺陷。
取捨與成本#
成本的多重面向#
在 Google 內部,對「因為我說了算」有強烈的反感。每個議題都應該有一個決策者,當決策看似有誤時應有清晰的上報路徑,但目標是共識而非一致同意。一切決策都需要有理由——「就是這樣」、「因為我說了」或「因為大家都這麼做」都是隱藏錯誤決策的地方。
「成本」不僅僅是金錢,大致可以翻譯為「付出的努力」,涵蓋以下面向:
- 財務成本(Financial costs):金錢
- 資源成本(Resource costs):CPU 時間
- 人員成本(Personnel costs):工程師的努力
- 交易成本(Transaction costs):採取行動的代價
- 機會成本(Opportunity costs):不採取行動的代價
- 社會成本(Societal costs):對整體社會的影響
歷史上,社會成本特別容易被忽略。但 Google 等大型科技公司如今的產品可能有數十億使用者,即使是可用性、無障礙性、公平性或濫用可能性上的微小偏差,也會被放大——往往損害的是已經被邊緣化的群體。
在評估成本時還需注意偏誤:現狀偏誤(status quo bias)、損失規避(loss aversion)等。在軟體工程這樣高度創造性且高薪的領域中,財務成本通常不是限制因素——人員成本才是。讓工程師保持快樂、專注和投入所帶來的效率提升,可以輕易主導其他因素。
範例:白板筆#
在許多組織中,白板筆被視為珍貴物品,嚴格管控且總是供不應求。半數的筆是乾的、無法使用的。會議多常因缺乏可用的筆而中斷?思路多常因筆沒水而打斷?而這些筆的成本不到一美元。
Google 傾向在大多數工作區域放置不上鎖的辦公用品櫃,包括各色白板筆。這是一個明確的取捨:優化無障礙的腦力激盪,遠比防止有人拿走一堆筆重要得多。
決策的輸入#
在權衡資料時,有兩種常見情境:
所有量值都可測量或至少可估算:例如 CPU 與網路之間的取捨、美元與 RAM 之間的取捨、或花費兩週工程師時間以節省 N 個 CPU。軟體工程組織可以且應該建立一個轉換表:多少 CPU 等價於多少 RAM 或多少網路頻寬。有了這張表,每個工程師都能自行分析。
部分量值難以衡量:例如設計不良的 API 的工程成本是多少?一個產品選擇的社會影響是什麼?對這類決策,需要依靠經驗、領導力和先例。最好的建議是:承認不是所有事物都可測量或可預測,並以同等優先順序和更大的謹慎來對待這些決策。
Google 自稱是「資料驅動的文化」,但更精確的說法是:即使沒有資料,仍可能有證據、先例和論證。做出好的工程決策是權衡所有可用輸入並做出知情的取捨。有時基於直覺或公認的最佳實踐,但前提是已經用盡了嘗試測量或估算真實成本的方法。
最終,工程團隊的決策應歸結為兩種情況:
- 我們這麼做是因為必須這麼做(法律要求、客戶需求)
- 我們這麼做是因為這是我們目前能看到的最佳選項(基於當前證據,由適當的決策者決定)
決策不應該是「因為我說了算」。
範例:分散式建構#
在 2000 年代中期,Google 完全依賴本地建構系統。隨著程式碼庫增長,編譯時間越來越長,造成人員成本(浪費的時間)和資源成本(更大更強的本地機器)不斷增加。而且高性能桌面開發機器大部分時間都是閒置的。
Google 最終開發了自己的分散式建構系統(Distributed Build System)。開發成本不小:工程師時間、改變所有人的習慣和工作流程,以及額外的運算資源。但整體節省顯然值得:建構更快、工程師時間被回收、硬體投資可以聚焦於共享基礎設施而非越來越強大的桌面機器。
但故事還沒結束。分散式建構系統上線後,建構本身變得越來越臃腫。之前受個別工程師自我約束的問題(因為他們有切身利益保持本地建構速度),在分散式系統中失去了約束。臃腫或不必要的依賴變得司空見慣。這讓人想到 Jevons 悖論(Jevons Paradox):資源使用效率的提升反而可能導致消耗量增加。
即使是「花錢買運算資源來換取工程師時間」這樣相對簡單的取捨,也會產生無法預見的下游效應。需要重新審視系統的目標和約束、識別最佳實踐(小依賴、機器管理的依賴),並為新的生態系統提供工具和維護資金。
時間與規模的衝突#
大多數時候,時間和規模這兩個主題會重疊並協同運作。但偶爾它們會產生衝突,最明顯的就是這個基本問題:應該新增一個依賴,還是 fork/重新實作以更好地滿足本地需求?
為你的狹窄問題空間客製化的解決方案可能優於需要處理所有可能性的通用方案。Fork 或重新實作可以讓你更容易新增功能、更有信心地優化,更重要的是,將你與底層依賴的變化隔離。
但如果每個開發者都 fork 所有使用的東西而非重用既有的,可擴展性和可持續性都會受損。回應底層函式庫的安全問題不再是更新單一依賴的事,而是要識別每個易受攻擊的 fork 及其使用者。
權衡原則:
- 如果專案壽命短,fork 的風險較低
- 避免 fork 可能跨越時間或專案邊界的介面(資料結構、序列化格式、網路協議)
- 一致性有巨大的價值,但通用性也有其成本
重新審視決策,承認錯誤#
承諾資料驅動文化的一個鮮為人知的好處是:承認錯誤的能力和必要性。決策是基於當時可用的資料做出的。隨著新資料出現、情境改變或假設被推翻,可能會發現先前的決策是錯誤的,或者當時合理但現在不再適用。
對長期存續的組織而言,這一點尤其關鍵:時間不僅會觸發技術依賴和軟體系統的變化,也會改變用來驅動決策的資料。這意味著決策需要在系統的生命週期中不時地被重新審視。長期專案往往需要在初始決策後有能力改變方向。
決策者需要有承認錯誤的權利。違反某些人的直覺,承認錯誤的領導者會獲得更多尊重,而非更少。以證據為導向,但也要認識到無法衡量的事物可能仍有價值。
軟體工程 vs 程式設計#
軟體工程與程式設計的區分並不意味著價值高低的判斷。一個預計持續十年、由數百人組成的團隊開發的專案,不一定比只用一個月、由兩人打造的專案更有價值。重點在於這兩者代表不同的問題領域,具有不同的約束、價值觀和最佳實踐:
- 只持續幾天的專案可能不需要整合測試(Integration Tests)和持續部署(Continuous Deployment)
- 短期程式設計專案不需要擔心語意化版本控制(Semantic Versioning, SemVer)和依賴管理
- 反過來,長期專案則需要這些工具和實踐
程式設計是產生程式碼的即時行為。軟體工程則是讓程式碼在需要被使用的整個時間內保持有用、並允許跨團隊協作所必需的政策、實踐和工具的集合。
結論#
本書涵蓋了以上所有主題:組織和個人程式設計師的政策、如何評估和改進最佳實踐,以及可維護軟體所需的工具和技術。Google 致力於擁有可持續的程式碼庫和文化,雖然不認為自己的方法是唯一正確的方式,但它確實提供了可行性的範例。
TL;DRs#
- 軟體工程不同於程式設計的維度在於:程式設計是產生程式碼,軟體工程還包括在程式碼的有用壽命期間維護它
- 短期程式碼和長期程式碼的壽命差異至少有十萬倍,假設相同的最佳實踐能普遍適用於兩端是不切實際的
- 軟體是可持續的,當我們在程式碼的預期壽命內有能力回應依賴、技術或產品需求的變化——我們可以選擇不改變,但需要有能力
- Hyrum 定律:當 API 擁有足夠多的使用者時,契約中承諾什麼已不重要——系統的所有可觀察行為都會被某些人所依賴
- 組織中所有需要重複執行的任務,在人力投入方面都應該具有可擴展性(線性或更好)。政策是使流程可擴展的絕佳工具
- 流程低效和其他軟體開發任務傾向於緩慢地擴大。注意溫水煮青蛙問題
- 專業知識與規模經濟結合時回報特別高
- 「因為我說了算」是做事的糟糕理由
- 資料驅動是好的起點,但現實中大多數決策基於資料、假設、先例和論證的混合。最好的情況是客觀資料佔大多數輸入,但很少能是全部
- 隨著時間推移的資料驅動意味著當資料改變(或假設被推翻)時需要改變方向。錯誤或修訂計畫是不可避免的