Previous Approaches#
操作型資料(operational data)與分析型資料(analytical data)的分離是一個長期存在的問題。隨著架構風格的演進,處理資料的方式也隨之改變。
The Data Warehouse#
- 在早期的 client/server 時代,應用程式與資料開始分離到不同的實體系統上
- 架構師嘗試透過 Data Warehouse 模式提供可查詢的分析資料
- 核心問題:操作型資料與分析型資料的格式和 schema 不相容,無法直接互用
Data Warehouse 的主要特徵:
- 從多來源擷取資料:將各個操作型資料庫的資料萃取到一個大型的「倉庫」中
- 轉換為單一 schema:使用 Star Schema 進行維度建模(dimensional modelling),將不同系統的資料轉換為統一格式,並刻意反正規化以加速查詢
- 載入倉庫:透過資料庫內建的複製機制或專用工具,定期進行 ETL(Extract, Transform, Load)
- 分析在倉庫中進行:獨立的儲存與運算環境,將沉重的分析工作從操作型系統中卸載
- 由資料分析師使用:需要同時理解操作型系統與分析型系統的領域知識
- 產出 BI 報表和儀表板
- 提供類 SQL 介面:方便 DBA 使用熟悉的查詢語言
Star Schema 將資料語意分為 facts(可量化的資料)和 dimensions(描述性屬性),刻意反正規化以簡化查詢、加速聚合運算。
Data Warehouse 是 technical partitioning 的典型例子:將資料轉換為方便查詢的 schema,但失去了所有的領域分區(domain partitioning)。
Data Warehouse 的主要缺陷:
- Integration brittleness(整合脆弱性):注入階段的資料轉換需求造成系統脆弱,schema 變更會連鎖影響資料匯入邏輯
- Extreme partitioning of domain knowledge(領域知識的極端分割):架構師、開發者、DBA、資料科學家必須跨越截然不同的生態系統進行協調
- Complexity(複雜性):建立替代 schema 並維護持續的資料注入與轉換機制,增加大量複雜度
- Limited functionality for intended purpose(功能受限):大多數 data warehouse 無法提供與投入成本相稱的商業價值
- Synchronization creates bottlenecks(同步瓶頸):跨多個操作型系統同步資料,產生操作面和組織面的瓶頸
- Operational versus analytical contract differences(合約差異):分析系統的合約需求與操作型系統不同,pipeline 中的轉換引入了合約脆弱性
| Advantage | Disadvantage |
|---|---|
| 集中整合資料 | 領域知識的極端分割 |
| 專用分析孤島提供隔離 | 整合脆弱性 |
| 複雜性 | |
| 功能受限於預設用途 |
The Data Lake#
- Data Lake 是對 Data Warehouse 複雜性與失敗的反動,將設計鐘擺擺向另一端
- 保持集中化模型和 pipeline,但將 Data Warehouse 的「transform and load」反轉為「load and transform」
- 哲學:與其進行可能永遠用不到的無用轉換,不如讓使用者以原始格式存取資料,按需轉換
- 工作負擔從 proactive 變為 reactive
Data Lake 的特徵:
- 從多來源擷取資料:較少轉換,資料以「原始」或原生格式儲存
- 載入 lake:通常部署在雲端環境,從操作型系統定期傾倒資料
- 由資料科學家使用:在 lake 中自行發現、聚合、組合、轉換資料
Data Lake 的限制:
- 難以發現適當資產:資料關係的理解在倒入非結構化 lake 後消散,領域專家仍需介入
- PII 和敏感資料問題:將非結構化資料倒入 lake 可能暴露可拼湊的隱私資訊
- 仍是 technical partitioning 而非 domain partitioning:Data Warehouse 和 Data Lake 都依技術能力分區,而非依領域分區
架構師越來越重視圍繞 domain 而非 technical 進行分區設計。Data Warehouse 和 Data Lake 都將資料從其脈絡中分離,這與現代架構趨勢背道而馳。
| Advantage | Disadvantage |
|---|---|
| 比 Data Warehouse 結構更少 | 有時難以理解資料關係 |
| 較少前置轉換 | 需要臨時轉換 |
| 更適合分散式架構 |
The Data Mesh#
- Data Mesh 從微服務的領域導向解耦、service mesh、sidecar 等趨勢中衍生
- 由 Zhamak Dehghani 等人提出,將這些概念應用於分析資料管理
- Sidecar Pattern 提供了一種不糾纏的方式來組織 orthogonal coupling(正交耦合)
Definition of Data Mesh#
Data Mesh 是一種以去中心化方式分享、存取和管理分析資料的社會技術方法(sociotechnical approach),滿足報表、ML 訓練、洞察生成等各種分析用途。
Data Mesh 建立在四個原則之上:
- Domain ownership of data(資料的領域所有權):資料由最熟悉它的領域擁有和分享,允許以 peer-to-peer 方式分散式地分享和存取資料,無需集中化的 lake 或 warehouse
- Data as a product(資料即產品):將資料視為產品來服務,引入 data product quantum 這一新的架構量子,確保資料可被發現、可理解、及時、安全且高品質
- Self-serve data platform(自助式資料平台):提供宣告式建立資料產品、跨 mesh 發現資料產品、管理資料血緣和知識圖譜等能力
- Computational federated governance(計算化聯邦治理):儘管資料所有權去中心化,仍確保合規、安全、隱私、品質等組織級需求,透過聯邦式決策模型,將治理政策自動化並嵌入每個資料產品量子中
Data Product Quantum#
- Data Product Quantum(DPQ) 是 data mesh 的核心架構元素
- 類似 service mesh,團隊在其服務旁邊建構一個 DPQ,與服務相鄰但耦合
- DPQ 包含程式碼和資料,作為整體分析和報表系統的介面
DPQ 的類型:
- Source-aligned (native) DPQ:代表協作架構量子提供分析資料,通常作為 cooperative quantum
- Aggregate DPQ:從多個輸入聚合資料,可同步或非同步
- Fit-for-purpose DPQ:為特定需求量身打造,涵蓋分析報表、BI、ML 或其他支援能力
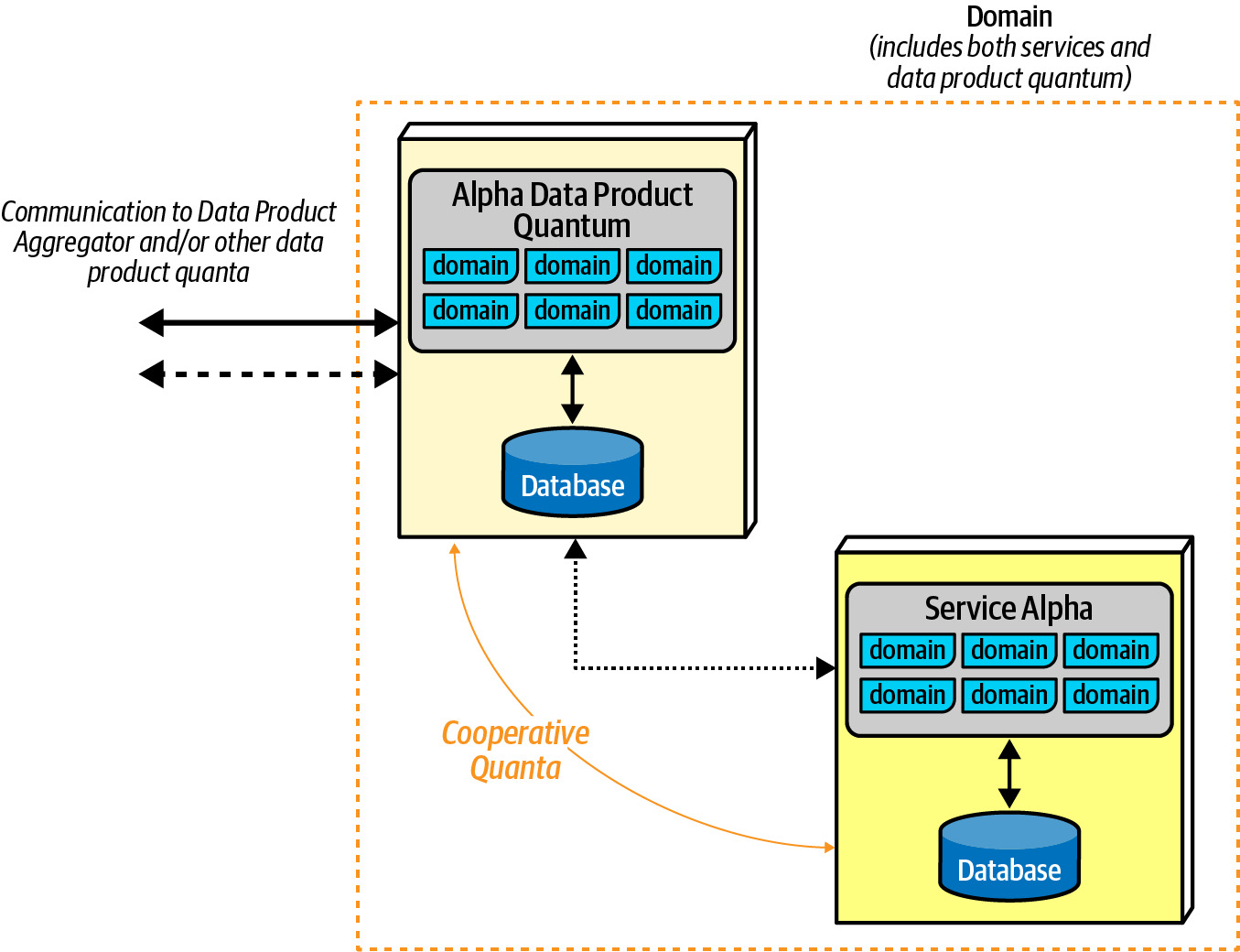
Figure 14.1: Structure of a data product quantum
DPQ 作為 cooperative quantum 的運作方式:
- 每個 DPQ 是操作上獨立的量子,透過非同步通訊和最終一致性與其合作者通訊
- 與合作者有 tight contract coupling,但與 analytics quantum 有 looser contract coupling
- 系統中會有專門的 analytics quantum 負責報表、分析、BI,透過 static quantum coupling 連接各個 DPQ
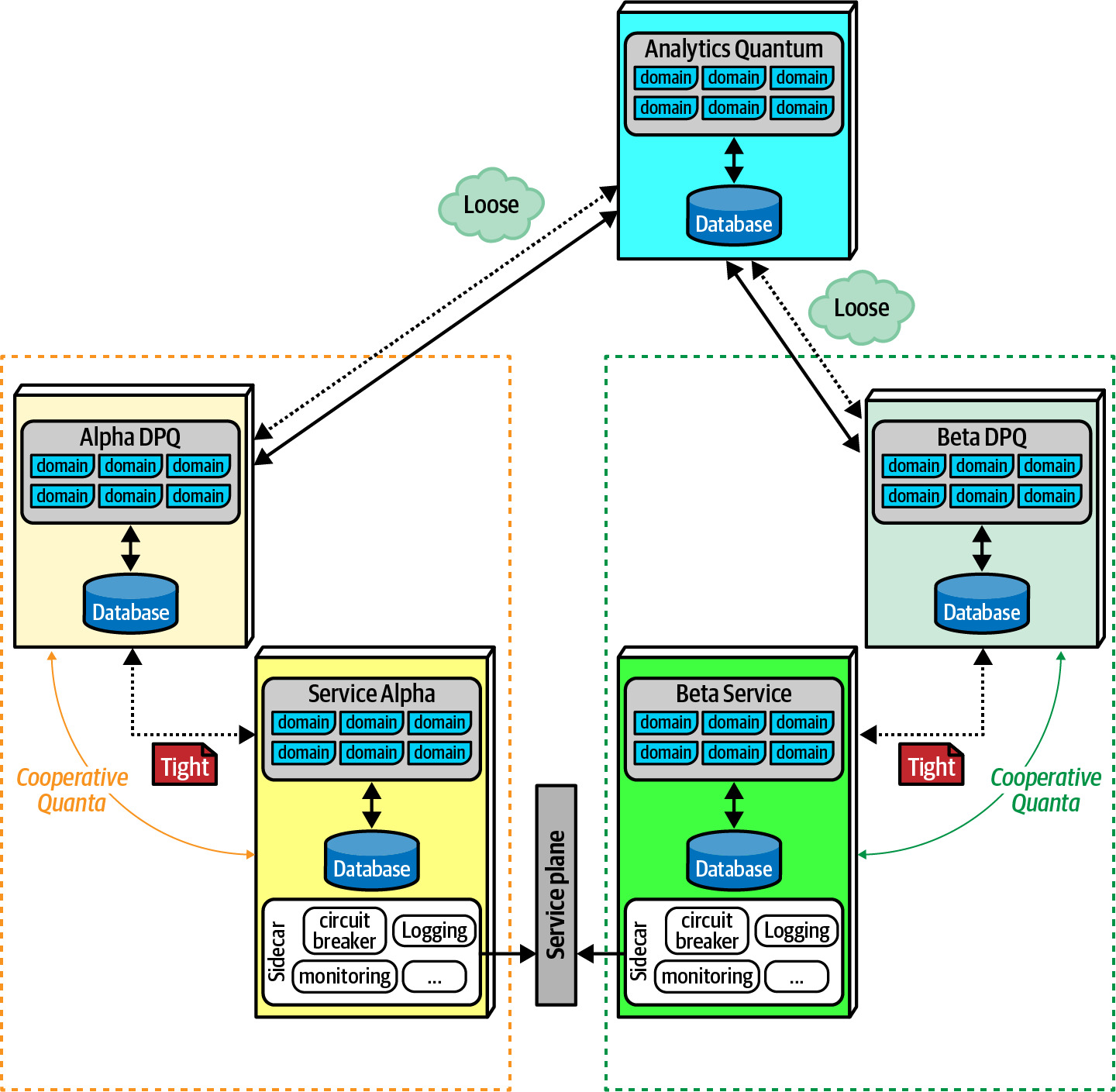
Figure 14.2: The data product quantum acts as a separate but highly coupled adjunct
Data Mesh, Coupling, and Architecture Quantum#
- DPQ 及其通訊實作屬於架構量子的 static coupling
- 像 service mesh 中的 Sidecar pattern,DPQ 應與服務內的實作變更 正交(orthogonal),維護與 data plane 的獨立合約
- Data sidecar 應始終實作具有最終一致性的通訊模式(如 Parallel Saga 或 Anthology Saga)
- 絕不應在操作型與分析型資料之間建立交易式同步需求,否則會破壞 DPQ 的正交解耦目的
- 與 data plane 的通訊一般應為非同步,以最小化對領域服務操作特性的影響
When to Use Data Mesh#
| Advantage | Disadvantage |
|---|---|
| 高度適合微服務架構 | 需要與 data product quantum 的合約協調 |
| 遵循現代架構原則和工程實踐 | 需要非同步通訊和最終一致性 |
| 出色地解耦分析型與操作型資料 | |
| 精心設計的合約允許分析能力的鬆耦合演進 |
Data Mesh 最適合具有良好交易自包含性和服務間良好隔離的現代分散式架構(如微服務)。它允許領域團隊決定資料消費的數量、節奏、品質和透明度。
- 在分析型與操作型資料必須始終保持同步的架構中,Data Mesh 較難適用
- 支援最終一致性(搭配嚴格合約)可以避免許多其他困難
Sysops Squad Saga: Data Mesh#
團隊需要實現資料驅動的專家供應規劃(expert supply planning),依不同地理位置和時間點預測技能需求。
實作方式:
- 每個新服務都包含一個 DPQ,由領域團隊負責運行和維護
- 例如 Ticket Management Business Domain 中:
- Ticket Maintenance 和 Ticket Assignment 服務各有自己的 DPQ
- Tickets DPQ 作為聚合點,提供每日檔案快照和表格快照
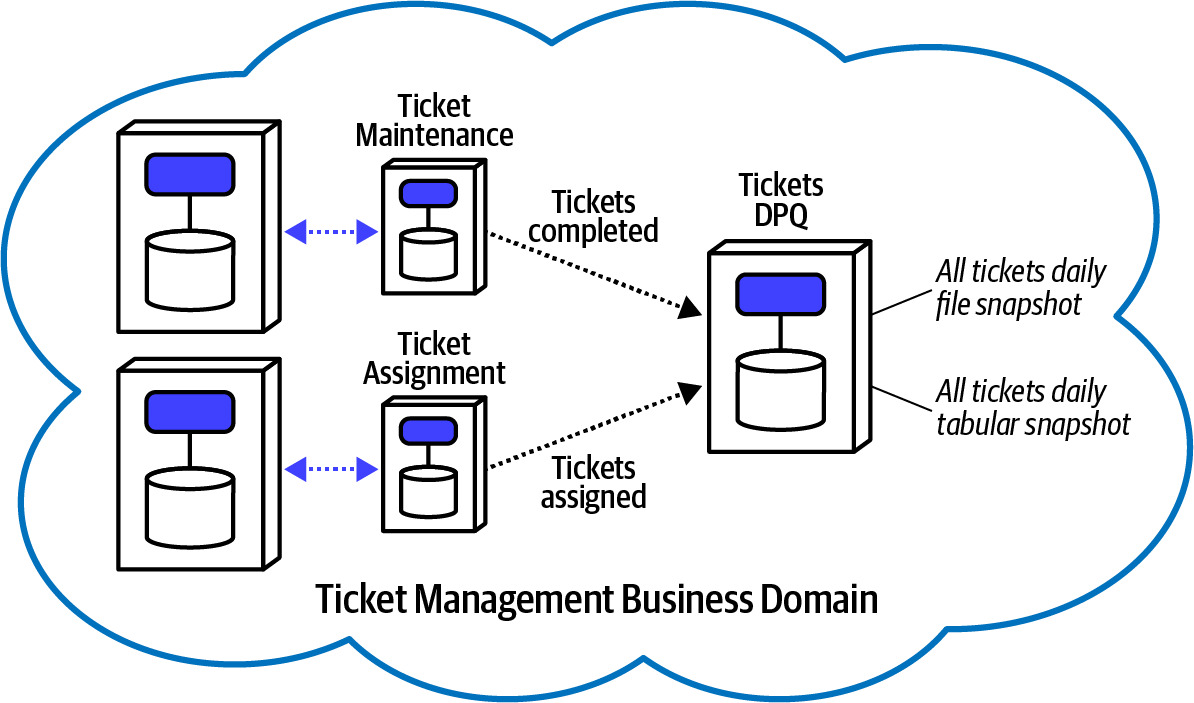
Figure 14.3: Ticket Management Domain, including two services with their own DPQs
Expert Supply DPQ 的設計:
- 建立新的 Experts Supply DPQ,從三個 DPQ 非同步取得輸入:
- Tickets DPQ:所有工單的長期檢視
- User Maintenance DPQ:所有專家檔案的每日快照
- Survey DPQ:所有客戶調查結果的紀錄
- 第一個資料產品為 supply recommendations,使用 ML 模型訓練,每日提供推薦
- Data mesh platform 團隊提供自助式能力,讓任何團隊都能搜尋、發現並連接現有的 DPQ
- 聯邦治理群組(由領域資料產品擁有者、平台產品擁有者、安全/法務/合規 SME 組成)決定 DPQ 的標準化事項
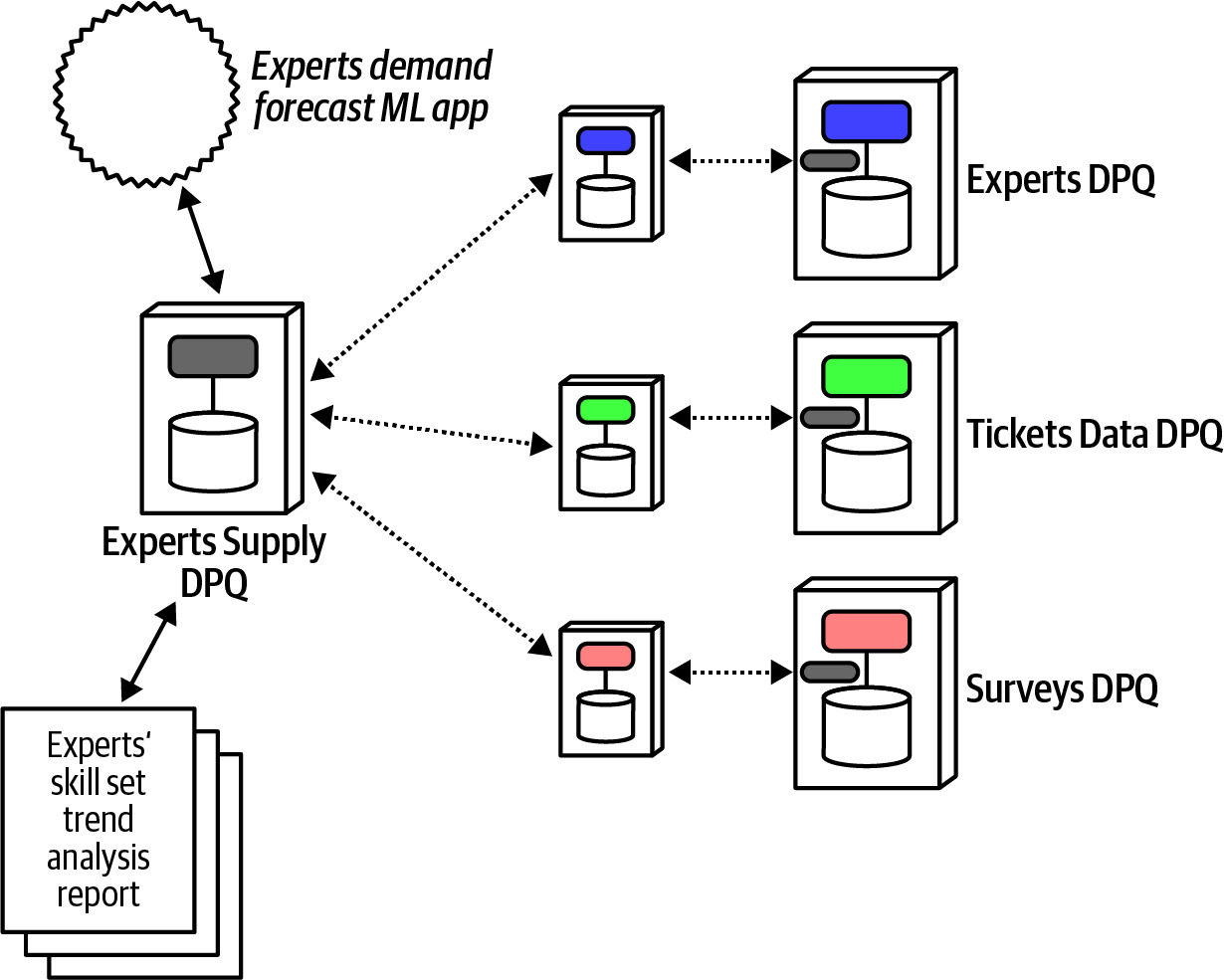
Figure 14.4: Implementing the Experts Supply DPQ
ADR:確保 Expert Supply DPQ 取得完整的每日資料或不取得任何資料
- Context:Expert Supply DPQ 對指定時間段進行趨勢分析,不完整的資料會扭曲結果
- Decision:每個資料來源必須提供完整的每日快照,否則該日不提供資料(標記為豁免)
- Consequences:若太多天因可用性問題被豁免,趨勢準確性將受負面影響
- Fitness functions:
- Complete daily snapshot:檢查訊息時間戳,超過一分鐘的間隔視為有缺口
- Consumer-driven contract fitness function:確保 Ticket Domain 的內部演進不會破壞 Experts Supply DPQ