Distributed Data Access#
在單體系統中,SQL table join 可以輕鬆取得所有所需資料。但當資料被拆分到不同資料庫或 schema 中,服務要讀取不屬於自身 bounded context 的資料就變得困難。本章介紹四種分散式資料存取模式:Interservice Communication、Column Schema Replication、Replicated Caching、Data Domain。
以 Wishlist Service 與 Catalog Service 為例:Wishlist Service 需要顯示 item_desc(商品描述),但該資料由 Catalog Service 的 Product table 擁有。
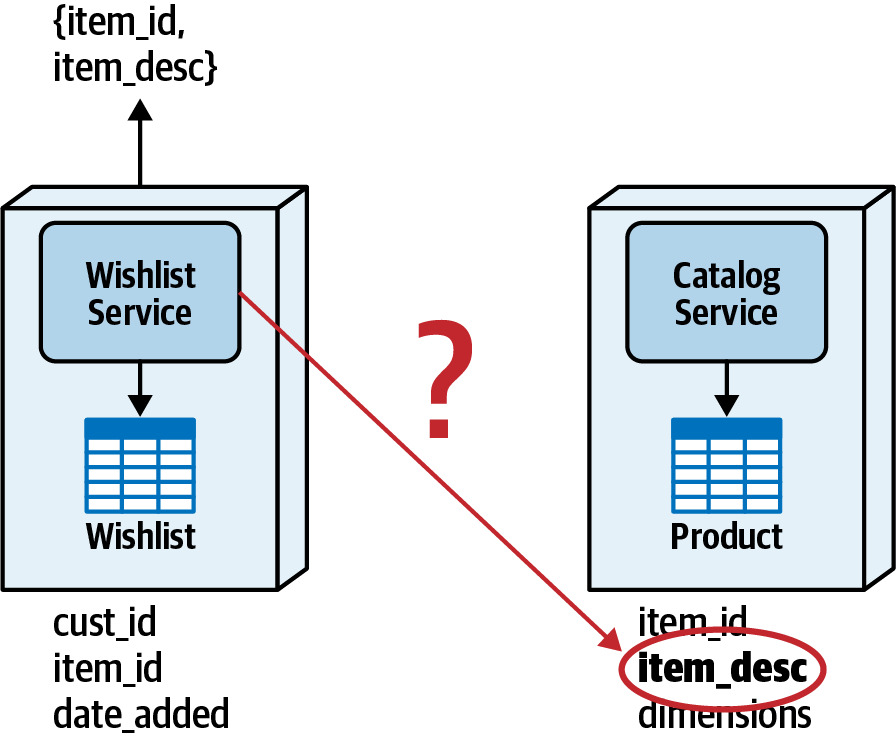
Figure 10.1: Wishlist Service needs item descriptions but doesn't have access to the data
Interservice Communication Pattern#
- 概念:需要資料的服務直接透過遠端存取協議(REST、gRPC 等)向擁有資料的服務請求
- 最常見也最簡單的模式
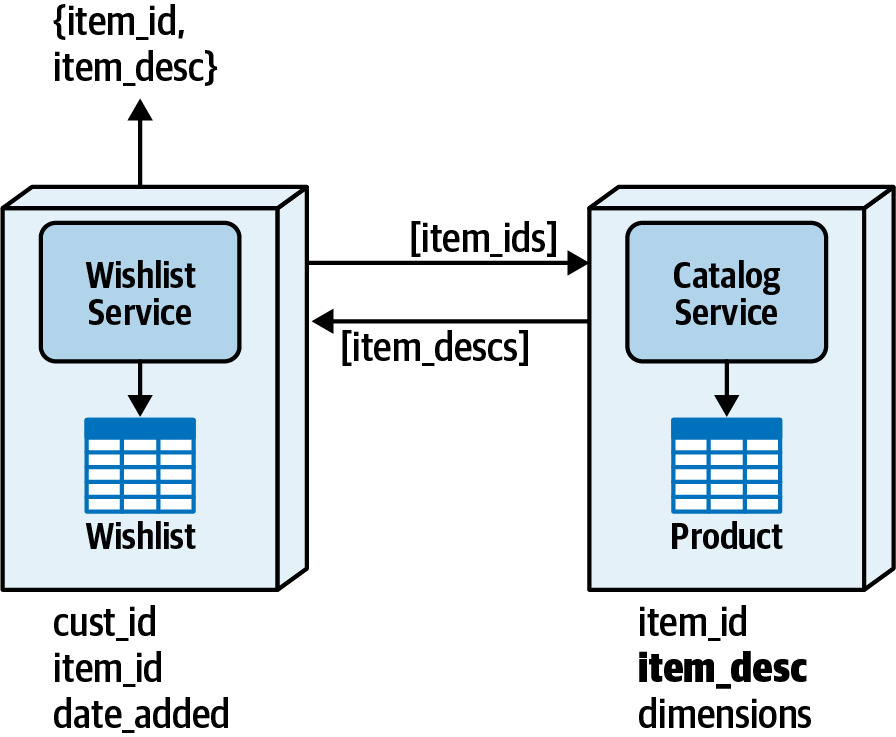
Figure 10.2: Interservice communication data access pattern
- 效能問題:每次請求都需要網路呼叫,引入三種延遲:
- Network latency(30-300 ms)
- Security latency(20-400 ms)
- Data latency(額外的資料庫查詢,10-50 ms)
- 服務耦合:Wishlist Service 與 Catalog Service 形成 semantic 與 static coupling;Catalog Service 不可用時 Wishlist Service 也無法運作
- 擴展性問題:Wishlist Service 擴展時,Catalog Service 也必須跟著擴展
Trade-Offs:
| 優勢 | 劣勢 |
|---|---|
| 簡單 | 網路、資料、安全延遲影響效能 |
| 無資料量問題 | 擴展性與吞吐量問題 |
| 無容錯(可用性問題) | |
| 需要服務間契約 |
Column Schema Replication Pattern#
- 概念:將所需欄位複製到需要資料的服務的表中(例如將
item_desc欄位加入 Wishlist table) - 服務可直接透過本地 SQL join 或查詢取得資料,無需跨服務呼叫
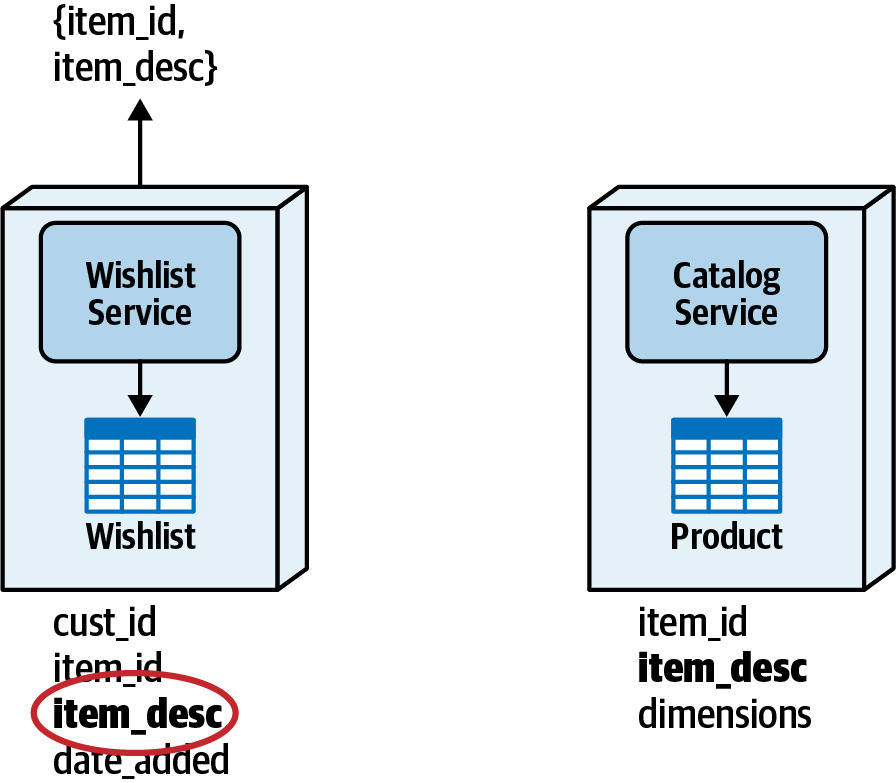
Figure 10.3: With the Column Schema Replication data access pattern, data is replicated
- 資料同步:資料來源變更時,通常透過非同步通訊(queues、topics、event streaming)通知複製方
- 資料擁有權治理困難:複製的資料存在於其他服務的表中,可能被那些服務修改,導致不一致
一般不建議用於像 Wishlist/Catalog 這類情境。較適合資料聚合、報表,或其他存取模式因資料量大、高回應性需求、高容錯要求而不適用的場景。
Trade-Offs:
| 優勢 | 劣勢 |
|---|---|
| 良好的資料存取效能 | 資料一致性問題 |
| 無擴展性與吞吐量問題 | 資料擁有權問題 |
| 無容錯問題 | 需要資料同步 |
| 無服務依賴 |
Replicated Caching Pattern#
- 概念:使用 replicated in-memory cache,讓所需資料在每個服務的記憶體中保持同步副本
- 與其他快取模型的差異:
- Single in-memory cache:每個服務各自的快取,不同步,無法用於跨服務資料共享
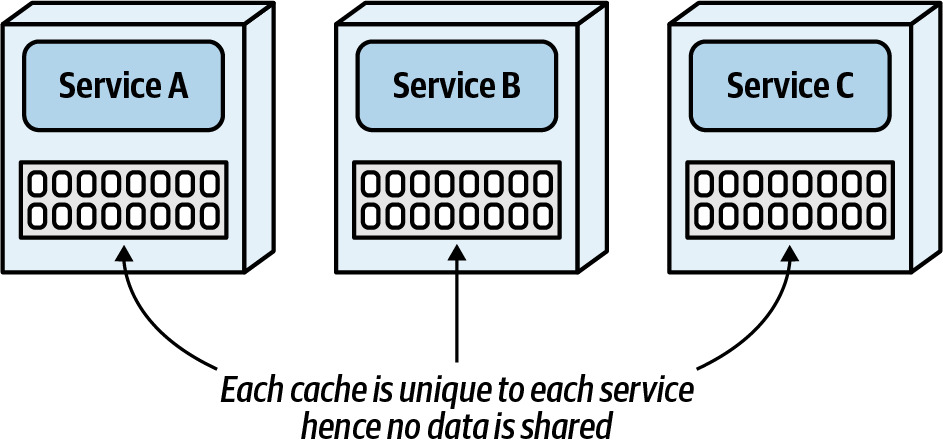
Figure 10.4: With a single in-memory cache, each service contains its own unique data
- Distributed cache:集中式外部快取伺服器,有網路延遲與容錯問題,不適合此模式
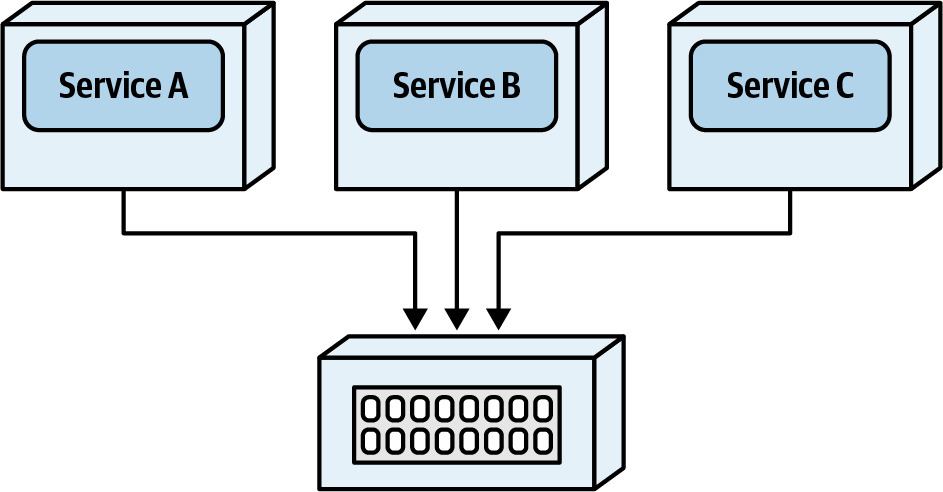
Figure 10.5: A distributed cache is external from the services
- Replicated cache:每個服務的 in-memory 資料保持同步,無外部依賴
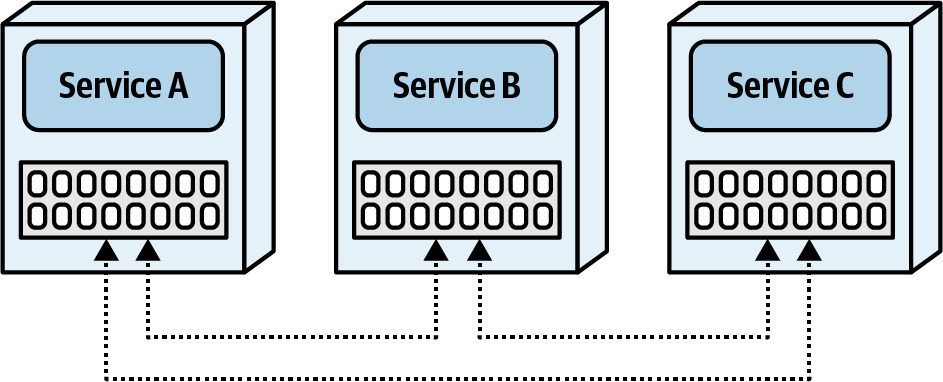
Figure 10.6: With a replicated cache, each service contains the same in-memory data
- 支援 replicated caching 的產品包括:Hazelcast、Apache Ignite、Oracle Coherence
- 資料擁有者(如 Catalog Service)擁有快取的寫入權,其他服務(如 Wishlist Service)持有唯讀副本
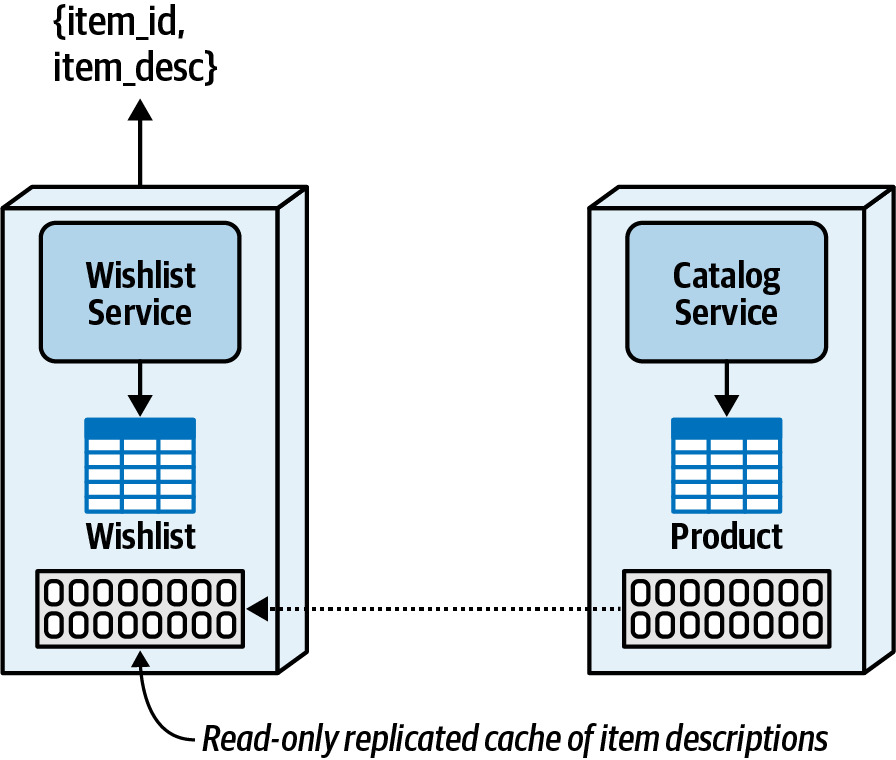
Figure 10.7: Replicated caching data access pattern
優勢:
- 回應性:資料直接在記憶體中,存取速度極快
- 容錯:即使 Catalog Service 停機,Wishlist Service 仍可使用快取中的資料繼續運作
- 擴展性:Wishlist Service 可獨立於 Catalog Service 進行擴展
Trade-Offs:
| 優勢 | 劣勢 |
|---|---|
| 良好的資料存取效能 | 雲端與容器化環境配置困難 |
| 無擴展性與吞吐量問題 | 不適合大量資料 |
| 良好的容錯性 | 不適合高更新頻率的資料 |
| 資料保持一致 | 初始服務啟動依賴 |
| 資料擁有權保留 |
啟動依賴是此模式的關鍵取捨:擁有快取的服務必須先啟動,需要快取資料的服務才能初始化。但一旦快取建立完成,擁有者服務可以停機而不影響使用者。
其他考量:
- 資料量:若快取超過 500 MB,考量到多實例的記憶體總需求(如 500 MB x 5 instances = 2.5 GB),可行性下降
- 變更頻率:高度動態的資料(如庫存數量)不適合,但相對靜態的資料(如商品描述)則非常適合
Data Domain Pattern#
- 概念:將多個服務需要的表放入同一個 shared schema(data domain),形成更寬廣的 bounded context
- 適用於 Interservice Communication、Column Schema Replication、Replicated Cache 都不可行的情境
- 服務可直接透過標準 SQL join 存取所需資料
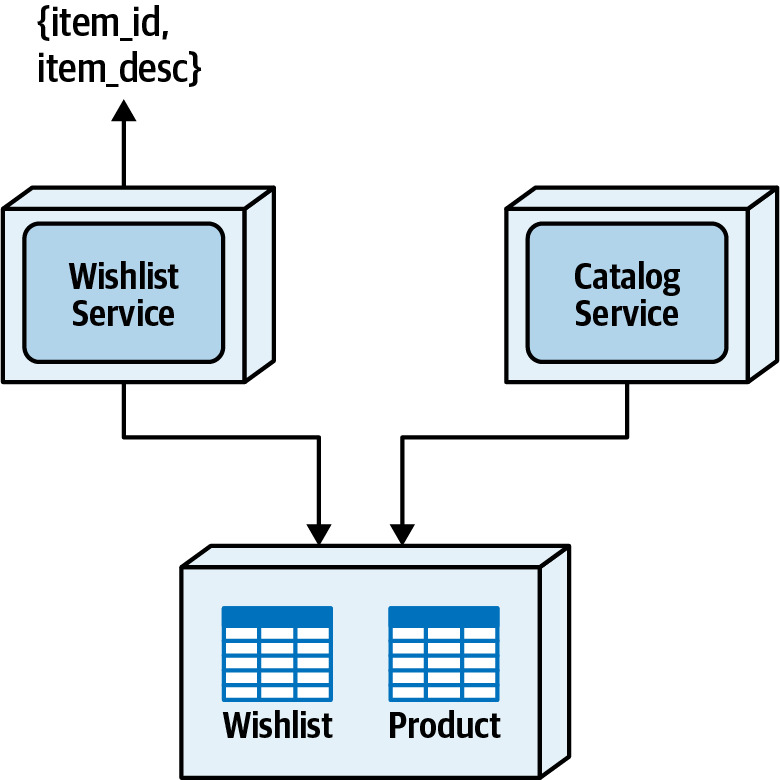
Figure 10.8: Data domain data access pattern
優勢:
- 服務完全解耦,無可用性依賴
- 回應性極佳,使用一般 SQL 查詢
- 資料一致性與完整性高,可使用 foreign key constraints、views、stored procedures、triggers
- 無需額外的服務間契約,表結構本身就是契約
Trade-Offs:
| 優勢 | 劣勢 |
|---|---|
| 良好的資料存取效能 | 更寬廣的 bounded context 增加資料變更管理 |
| 無擴展性與吞吐量問題 | 資料擁有權治理問題 |
| 無容錯問題 | 資料存取安全性問題 |
| 無服務依賴 | |
| 資料保持一致 |
Data domain 中的服務可存取 shared schema 中的所有資料,可能引發安全隱患。較緊密的 bounded context 與嚴格的服務擁有權可透過契約限制資料存取,避免此問題。
Sysops Squad Saga: Data Access for Ticket Assignment#
Ticket Assignment Service 需要存取由 User Management Service 擁有的 expert profile 資料(技能、服務區域、排程等),分析後排除了不適用的方案:
- Service Consolidation:兩個服務在完全不同的 domain,不適合合併
- Data Domain:Ticket Assignment Service 已連接 ticketing data domain,不可連接第二個 schema
- Interservice Communication:因 reliability 與 latency 問題不可行
- Column Schema Replication:因高資料一致性需求不可行
最終選擇 Replicated Caching,理由:
- 資料量小(約 900 位專家,每位約 1.3 KB,共約 1200 KB)
- 資料相對靜態
- 即使 User Management Service 停機,快取資料仍可用
- 記憶體需求低(最多 6 個實例 x 1.2 MB = 7.2 MB)
- 代價:User Management Service 必須先於 Ticket Assignment Service 啟動,以及快取產品的授權費用