Pulling Apart Operational Data#
拆解資料庫比拆解應用程式功能更困難。資料通常是公司最重要的資產,拆解或重組資料時,業務和應用程式中斷的風險更大。資料也傾向與應用程式功能高度耦合,使得在大型資料模型中難以識別清晰的拆分邊界。

Figure 6.1: Under what circumstances should a monolithic database be decomposed?
拆解應用程式所使用的技術同樣適用於拆解資料:元件對應資料領域、類別檔案對應資料庫表格、類別間的耦合點對應 foreign keys、views、triggers 或 stored procedures。
Data Decomposition Drivers#
拆解單體資料庫是一項艱鉅的任務,因此需要先了解何時以及是否應該分解資料庫。架構師可透過分析 data disintegrators(拆解驅動力)和 data integrators(整合驅動力)來做出判斷。
Data Disintegrators#
Data disintegrators 回答的問題是:「何時應該考慮拆解我的資料?」六個主要的拆解驅動力:
- Change control(變更控制)
- 有多少服務會受到資料庫表格變更的影響?
- 共享資料庫中的 breaking changes(如刪除表格、更改欄位名稱、變更欄位類型)需要協調所有相關服務一起更新、測試、部署
- 忘記更新某個服務會導致該服務在生產環境中持續失敗
- 將資料庫拆分為定義良好的 bounded contexts 可有效控制變更影響範圍
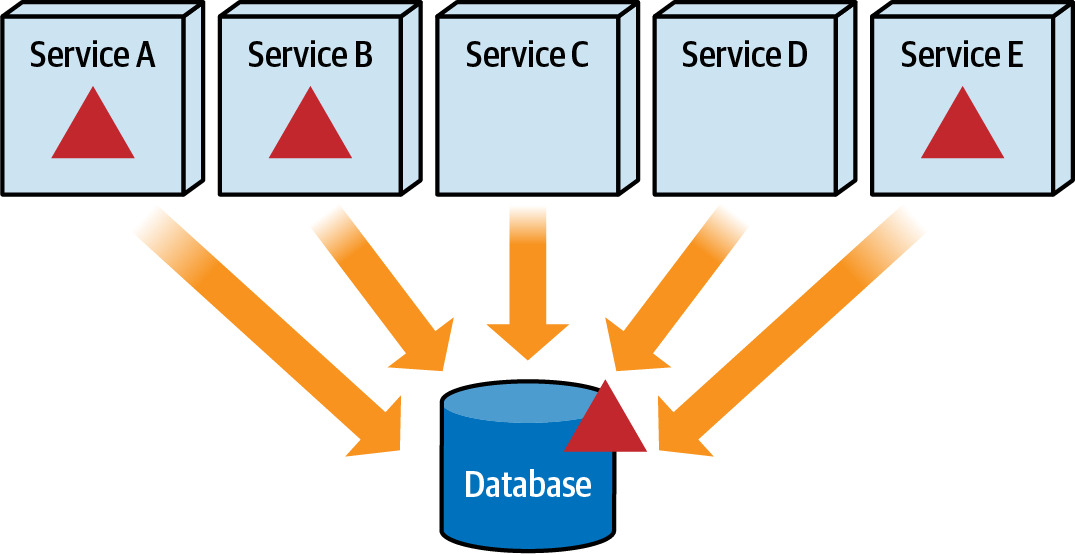
Figure 6.2: Services impacted by the database change must be deployed together
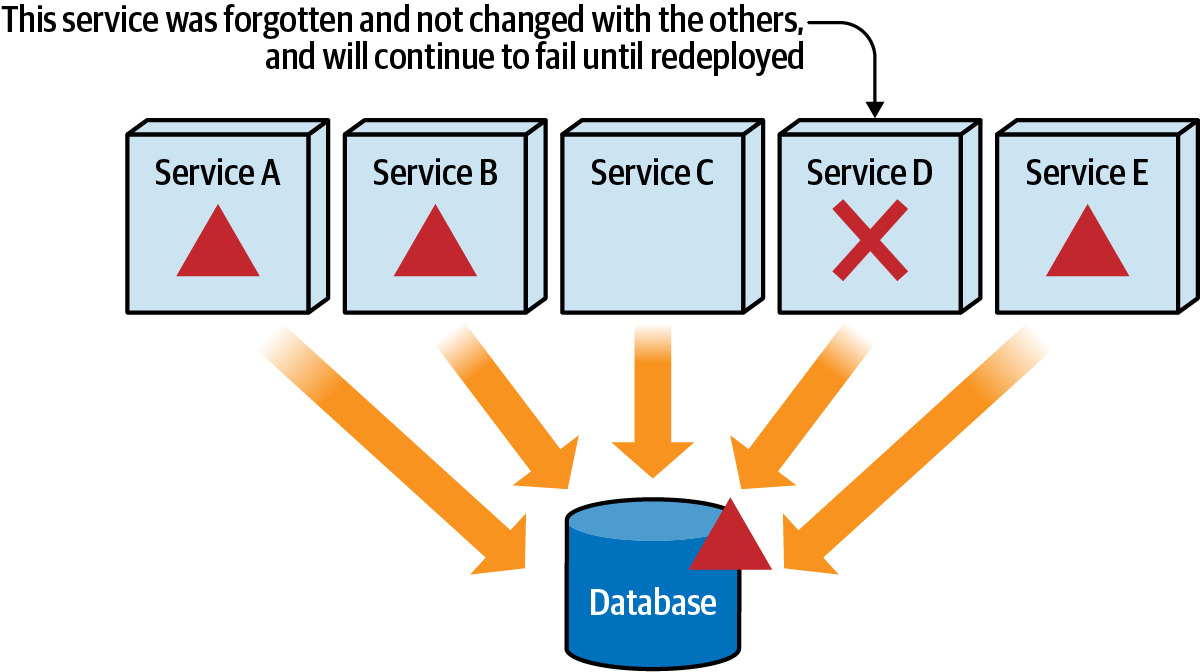
Figure 6.3: Services impacted by a database change but forgotten will continue to fail
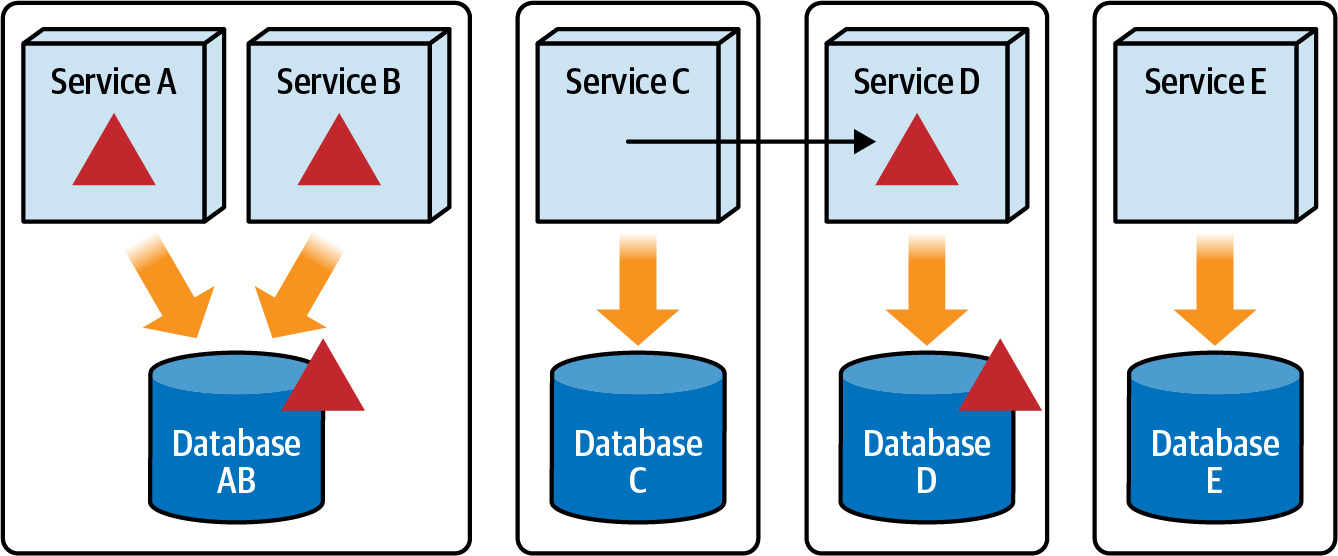
Figure 6.4: Database changes are isolated to only those services within the associated bounded context
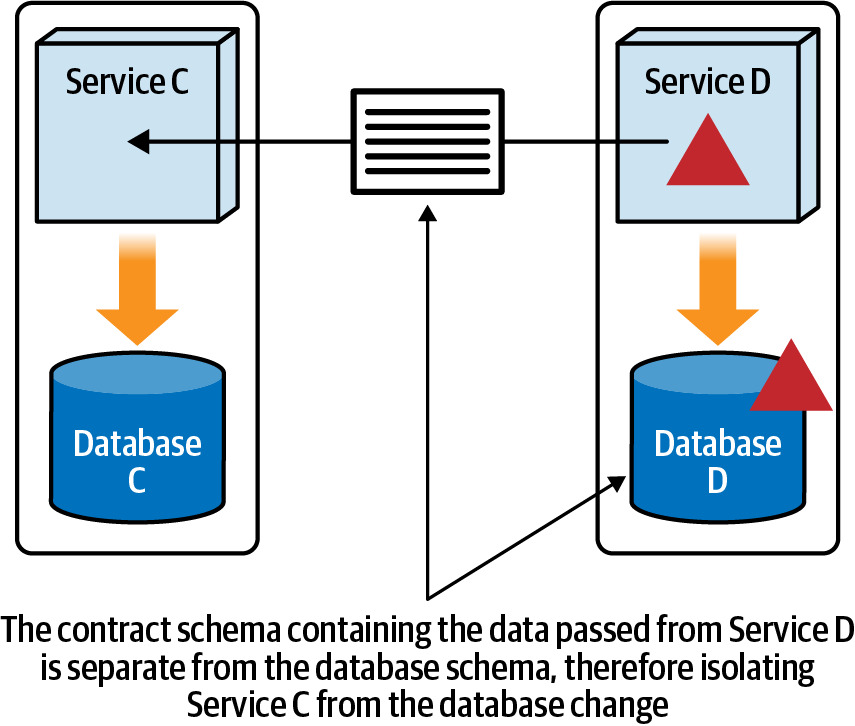
Figure 6.5: The contract from a service call abstracts the caller from the underlying database
- Connection management(連線管理)
- 資料庫是否能處理多個分散式服務所需的連線數量?
- 每個服務實例通常維護自己的連線池,大量服務共享同一資料庫可能導致連線耗盡
- 可透過降低連線池大小、使用資料庫複本(replicas)等方式緩解,但最終解決方案是拆分資料庫
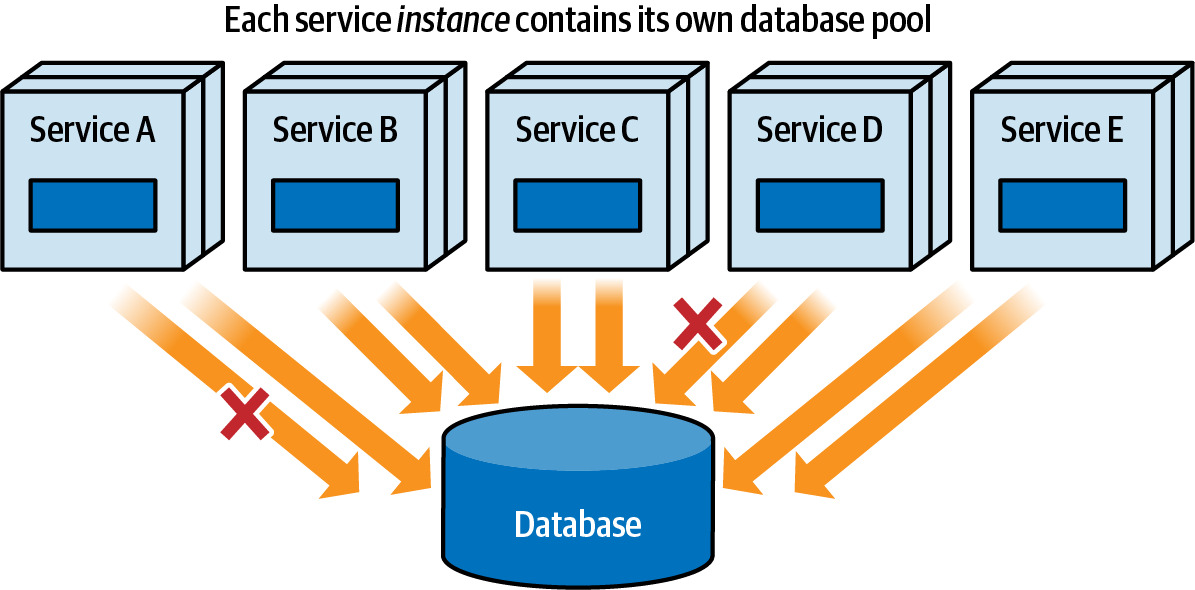
Figure 6.6: Database connections can quickly get saturated with multiple services
- Scalability(可擴展性)
- 資料庫是否能擴展以滿足所有存取它的服務的需求?
- 單一共享資料庫可能成為擴展瓶頸
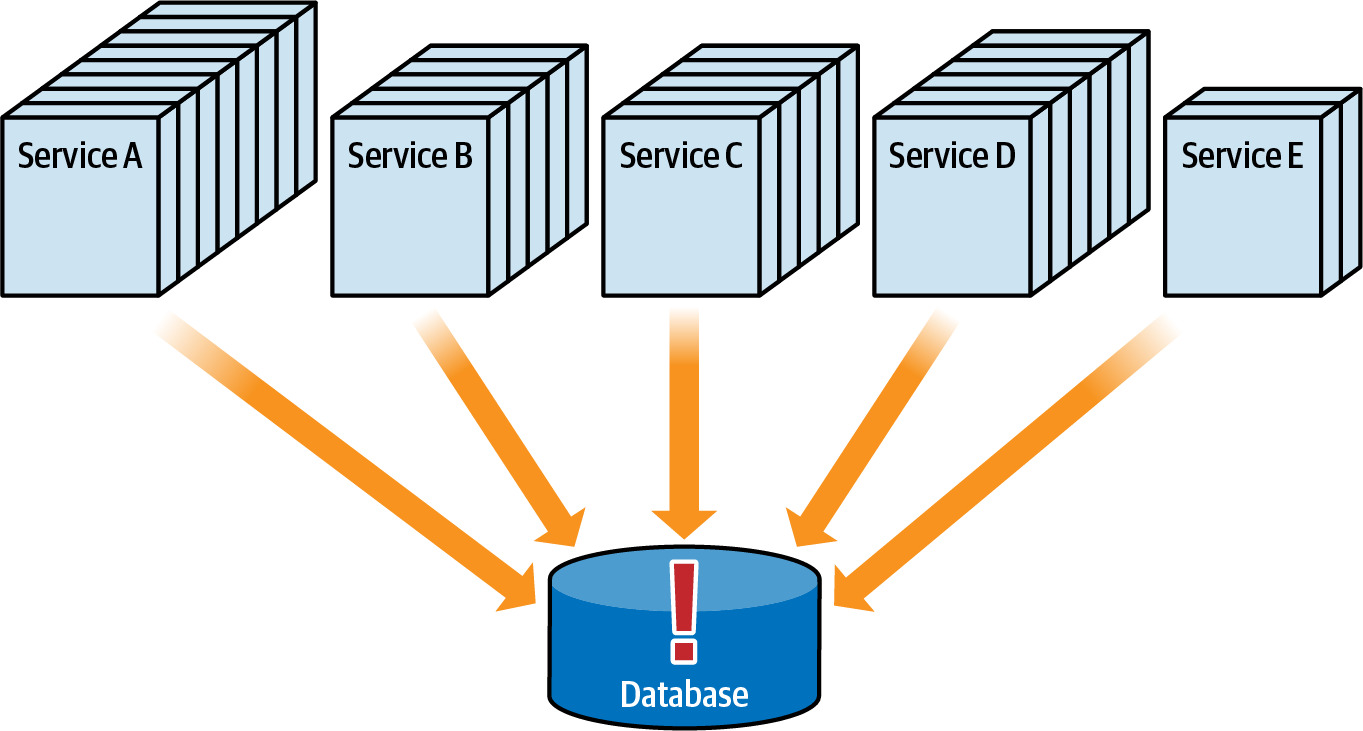
Figure 6.7: The database must also scale when services scale
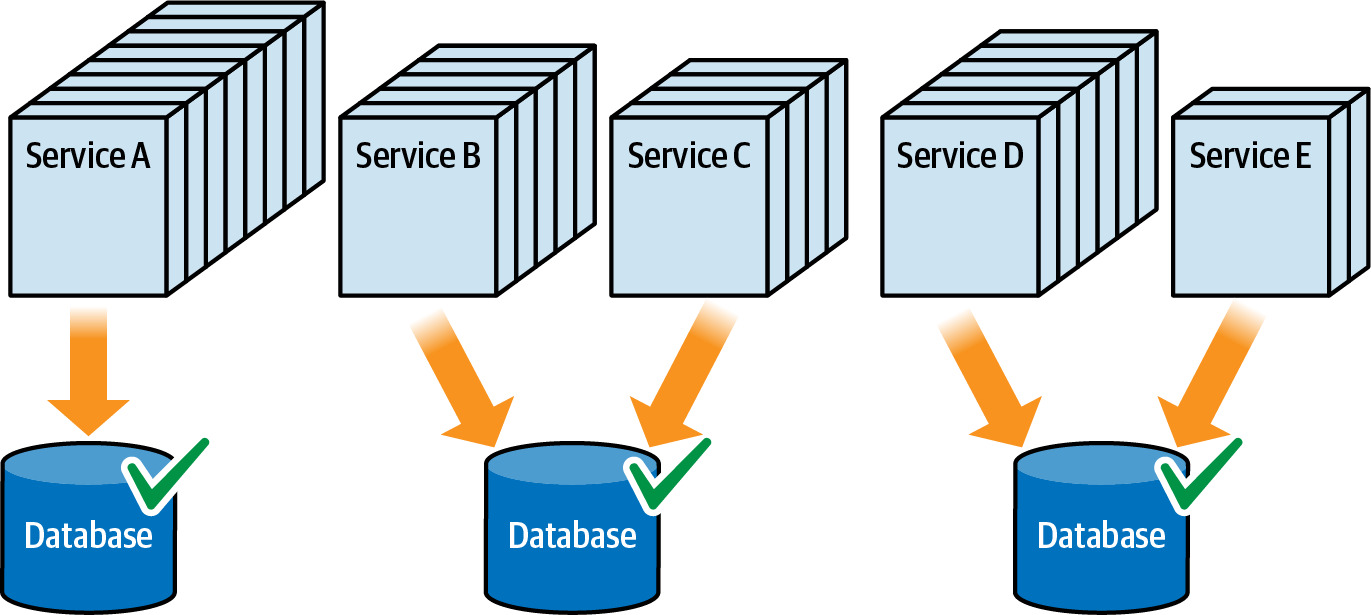
Figure 6.8: Breaking apart the database provides better database scalability
- Fault tolerance(容錯性)
- 有多少服務會因為資料庫當機或維護停機而受影響?
- 所有服務共享同一資料庫意味著資料庫故障會影響所有服務
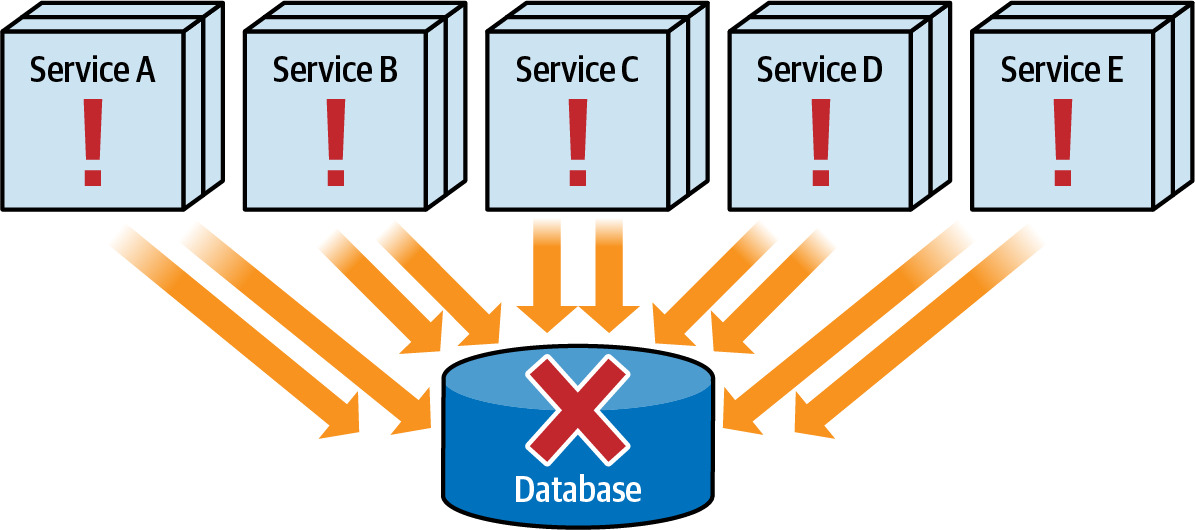
Figure 6.9: If the database goes down, all services become nonoperational
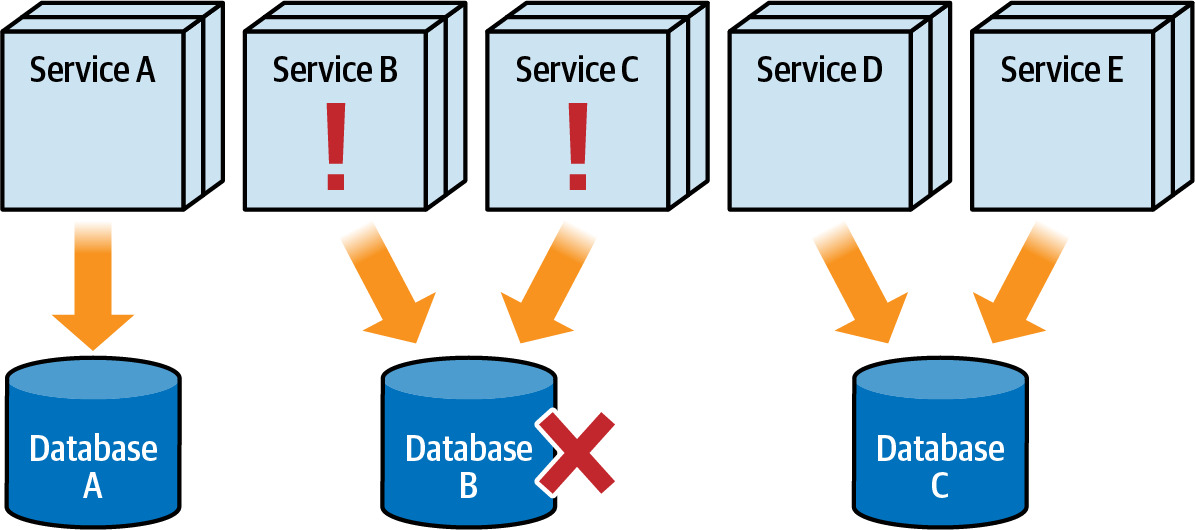
Figure 6.10: Breaking apart the database achieves better fault tolerance
- Architectural quanta(架構量子)
- 單一共享資料庫是否迫使系統成為不必要的單一架構量子?
- 拆分資料庫讓各服務可以獨立部署和運作
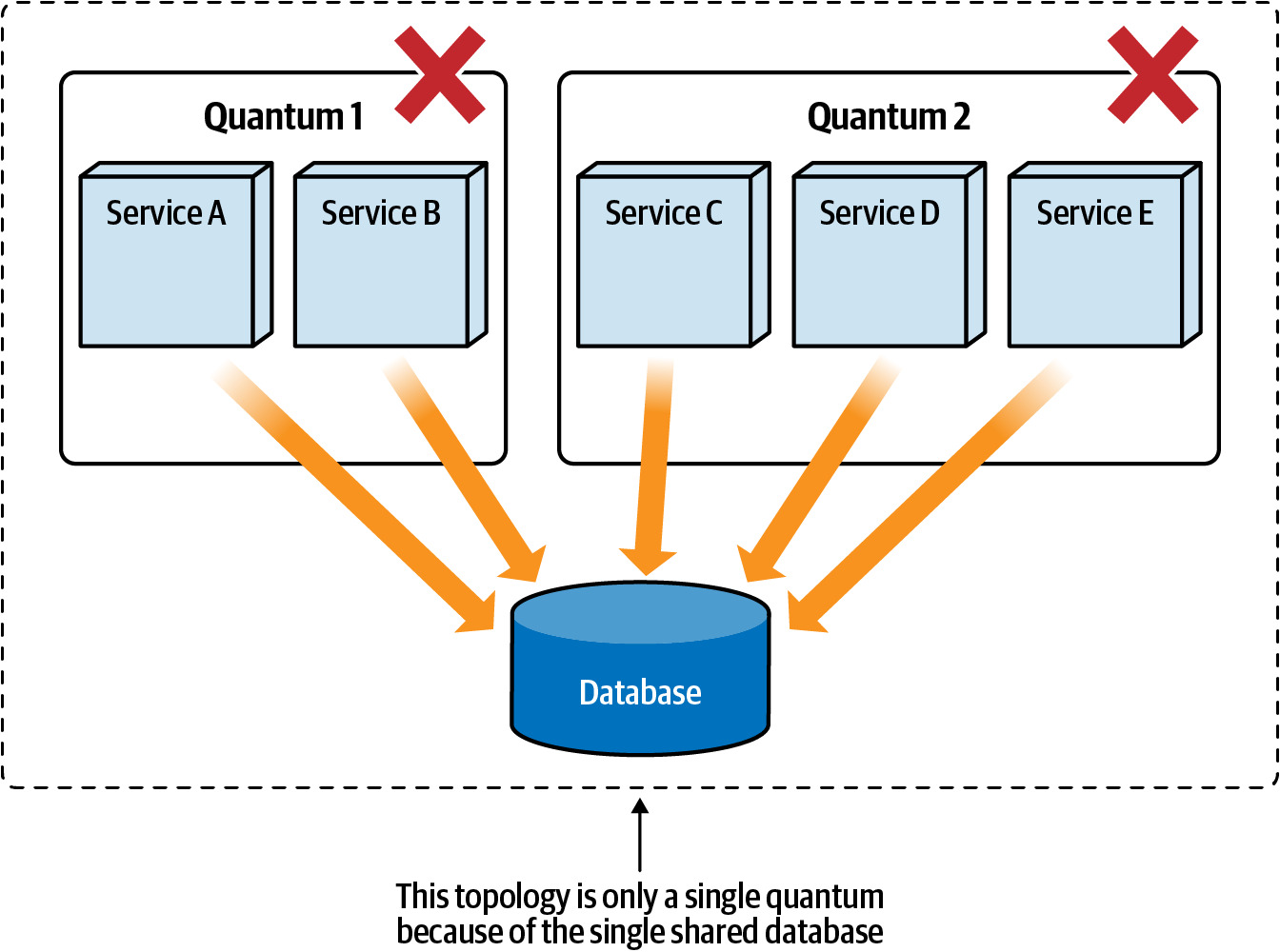
Figure 6.11: The database is part of the architectural quantum
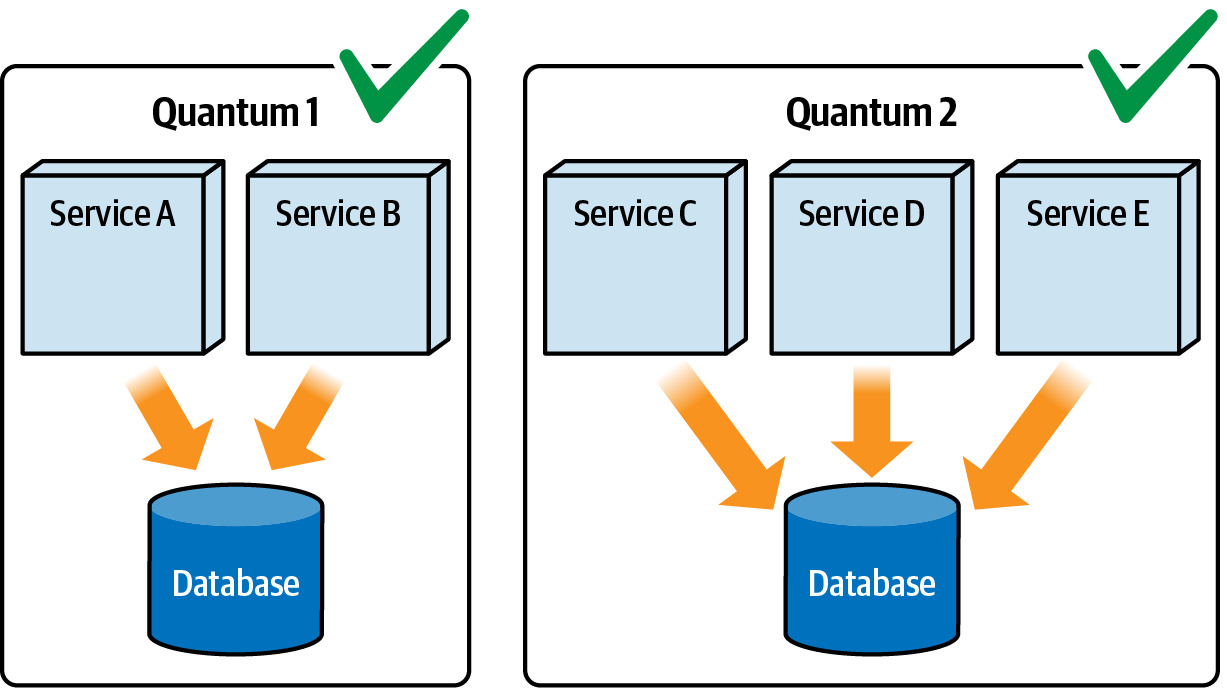
Figure 6.12: Breaking up the database forms two architectural quanta
- Database type optimization(資料庫類型最佳化)
- 是否能透過使用不同類型的資料庫來最佳化資料?
- 例如:某些資料更適合用 document database、graph database 等
Data Integrators#
Data integrators 回答的問題是:「何時應該考慮將資料保持在一起?」四個主要的整合驅動力:
- Data relationships(資料關係)
- 資料庫中各表格之間是否透過 foreign keys 緊密關聯?
- 關係越緊密,拆分越困難
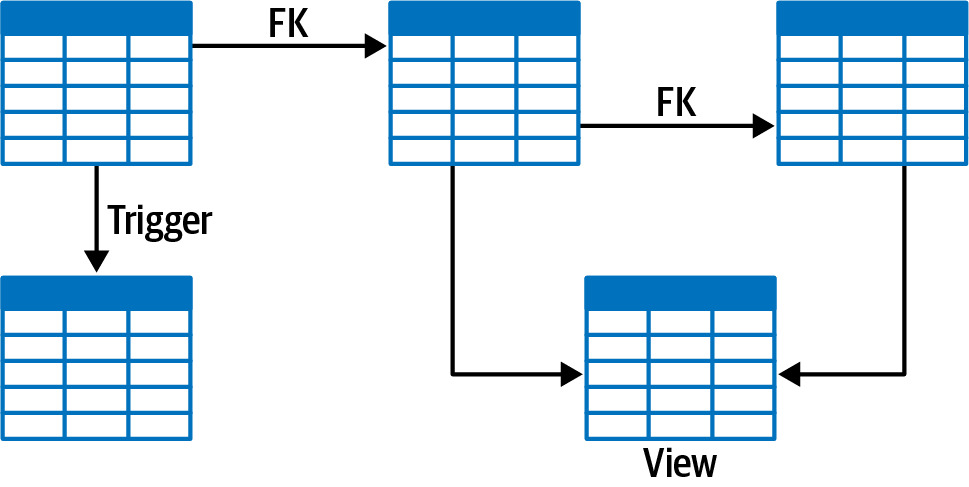
Figure 6.13: Foreign keys, triggers, and views create tightly coupled relationships
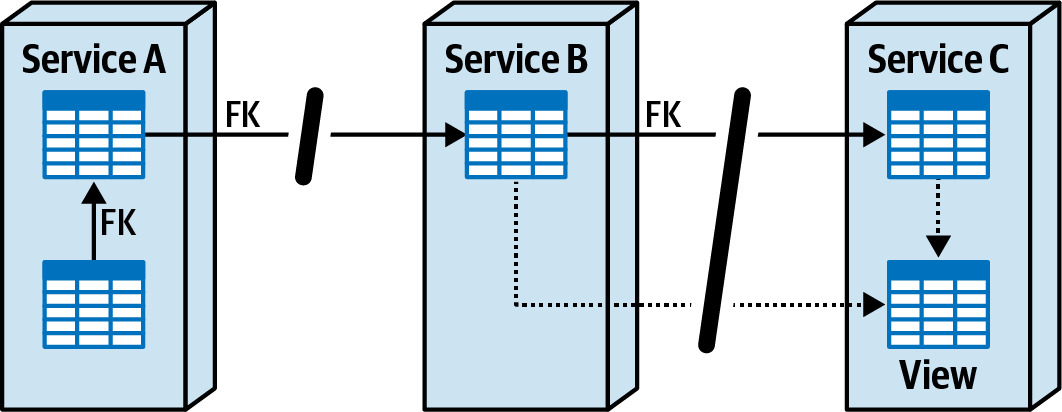
Figure 6.14: Data artifacts must be removed when breaking apart data
- Database transactions(資料庫交易)
- 是否需要跨多個表格的 ACID transactions?
- 拆分後將失去資料庫層級的交易保證,需要使用 eventual consistency 或 saga pattern 等替代方案
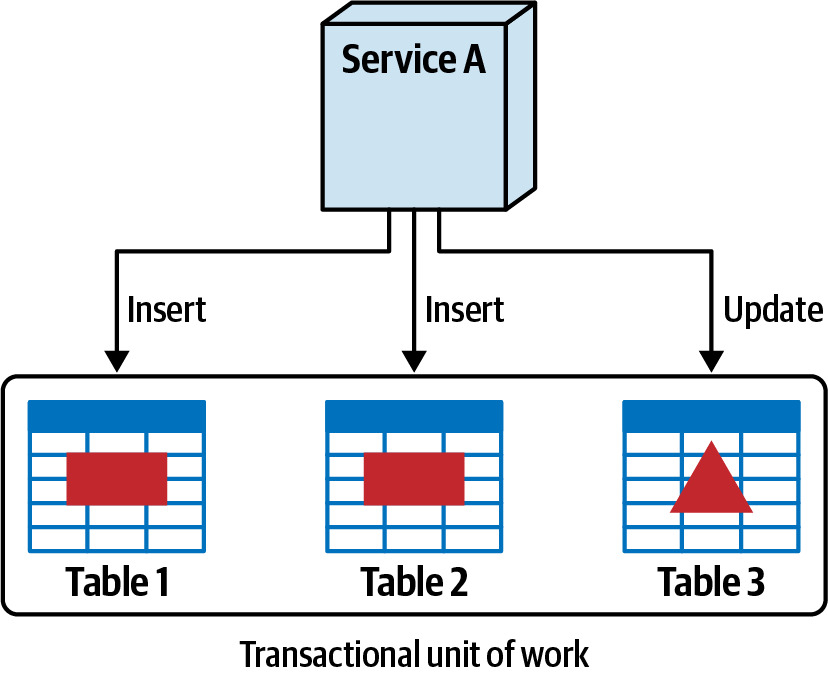
Figure 6.15: A single transactional unit of work exists when the data is together
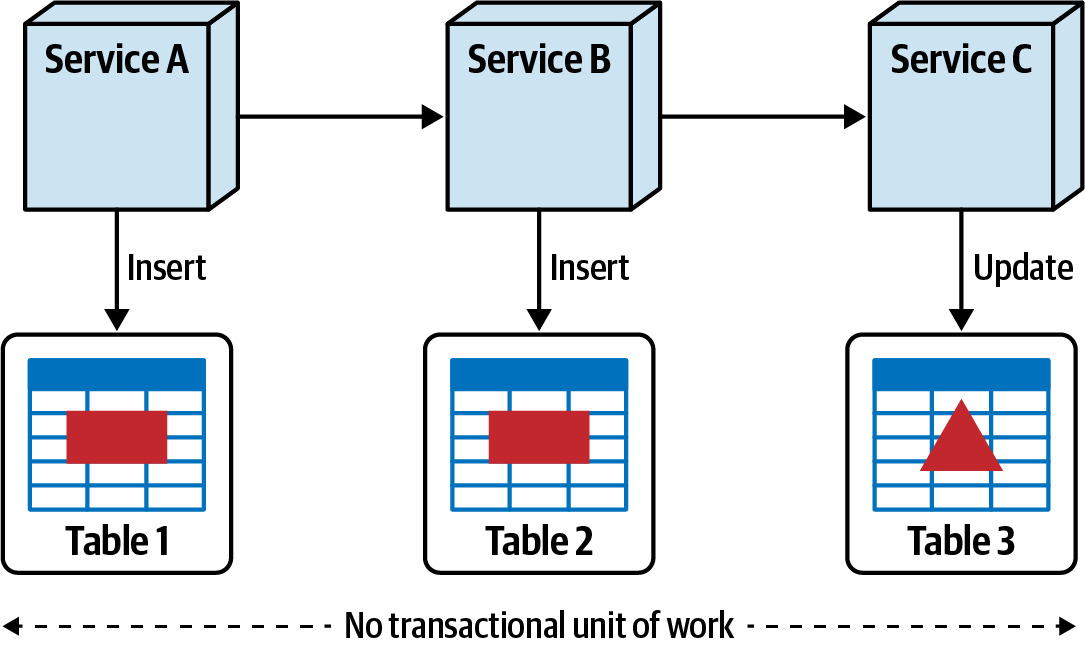
Figure 6.16: Single unit of work transactions don't exist when data is broken apart
分散式交易(distributed transactions)通常被認為是不可行的,因此若某些資料需要 ACID 交易保證,應該將它們保持在同一資料庫中。
Sysops Squad Saga: Justifying Database Decomposition#
- Addison 需要說服資料架構師 Dana 拆解 Sysops Squad 資料庫
- Dana 要求提供充分的業務理由
- Addison 分析了各項 data disintegrators 和 integrators,發現拆分的理由充分:
- 多個服務需要獨立變更資料庫結構
- 連線管理成為瓶頸
- 需要不同類型的資料庫來最佳化某些資料
- 最終 Dana 同意進行資料庫分解
Decomposing Monolithic Data#
將單體資料庫分解為獨立的資料領域需要五個步驟:
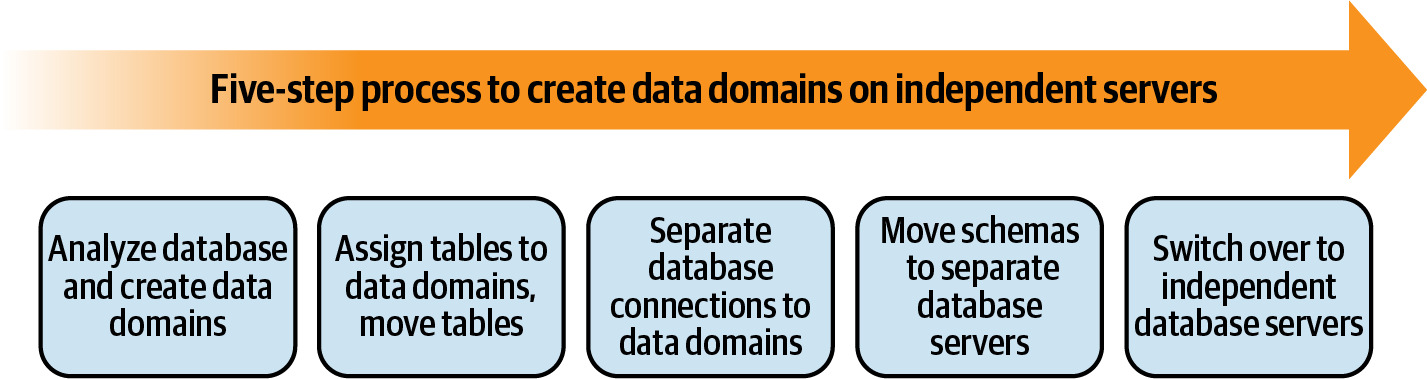
Figure 6.17: Five-step process for decomposing a monolithic database
Step 1: Analyze Database and Create Data Domains(分析資料庫並建立資料領域)#
- 識別資料庫中哪些表格屬於哪個資料領域
- 可利用之前建立的元件領域作為參考
- 建立資料領域與表格的對應關係
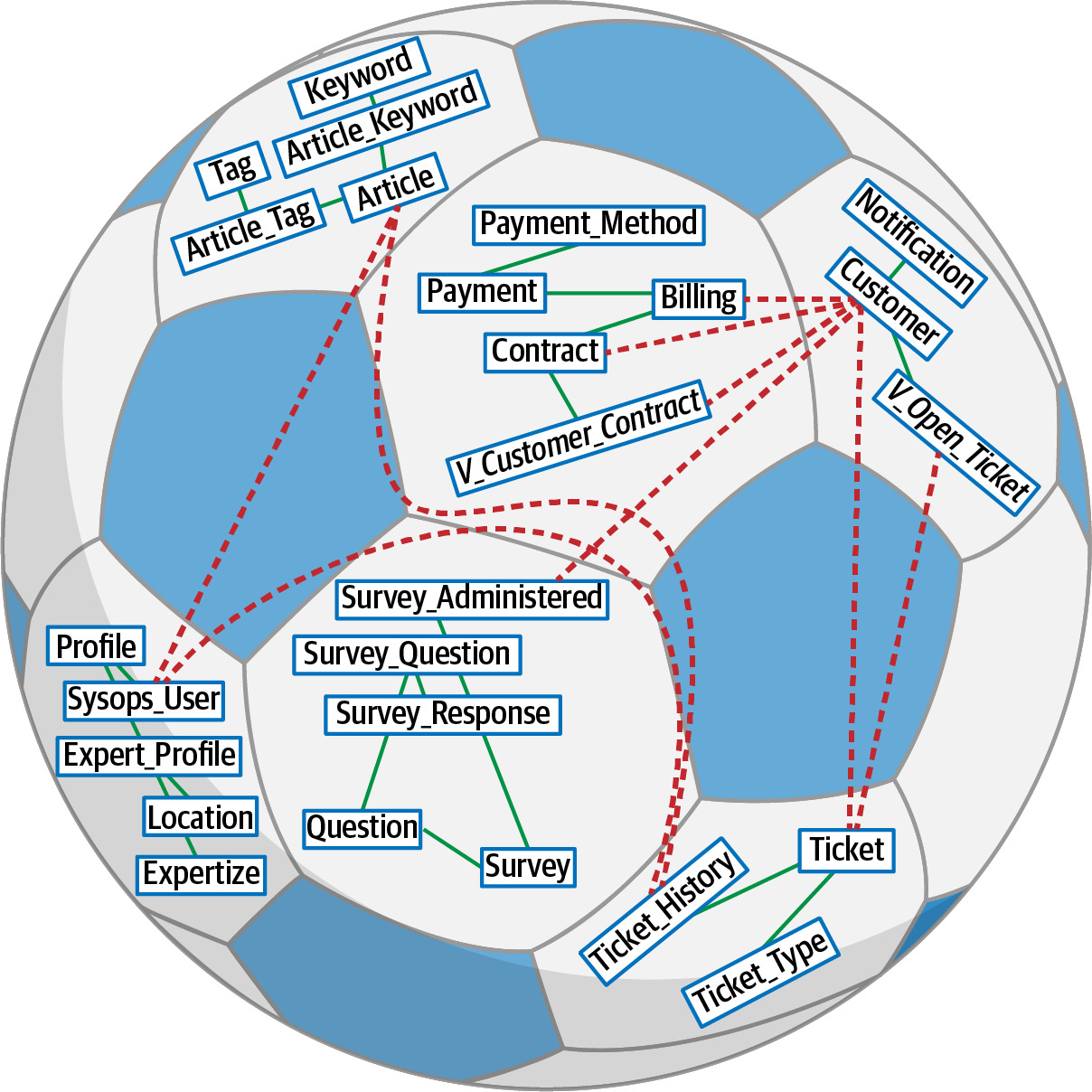
Figure 6.18: Database objects in a hexagon belong in a data domain
Step 2: Assign Tables to Data Domains(將表格分配到資料領域)#
- 將每個表格明確分配到一個資料領域
- 處理共用表格的歸屬問題
- 注意 foreign key 關係和 cross-domain 的資料存取
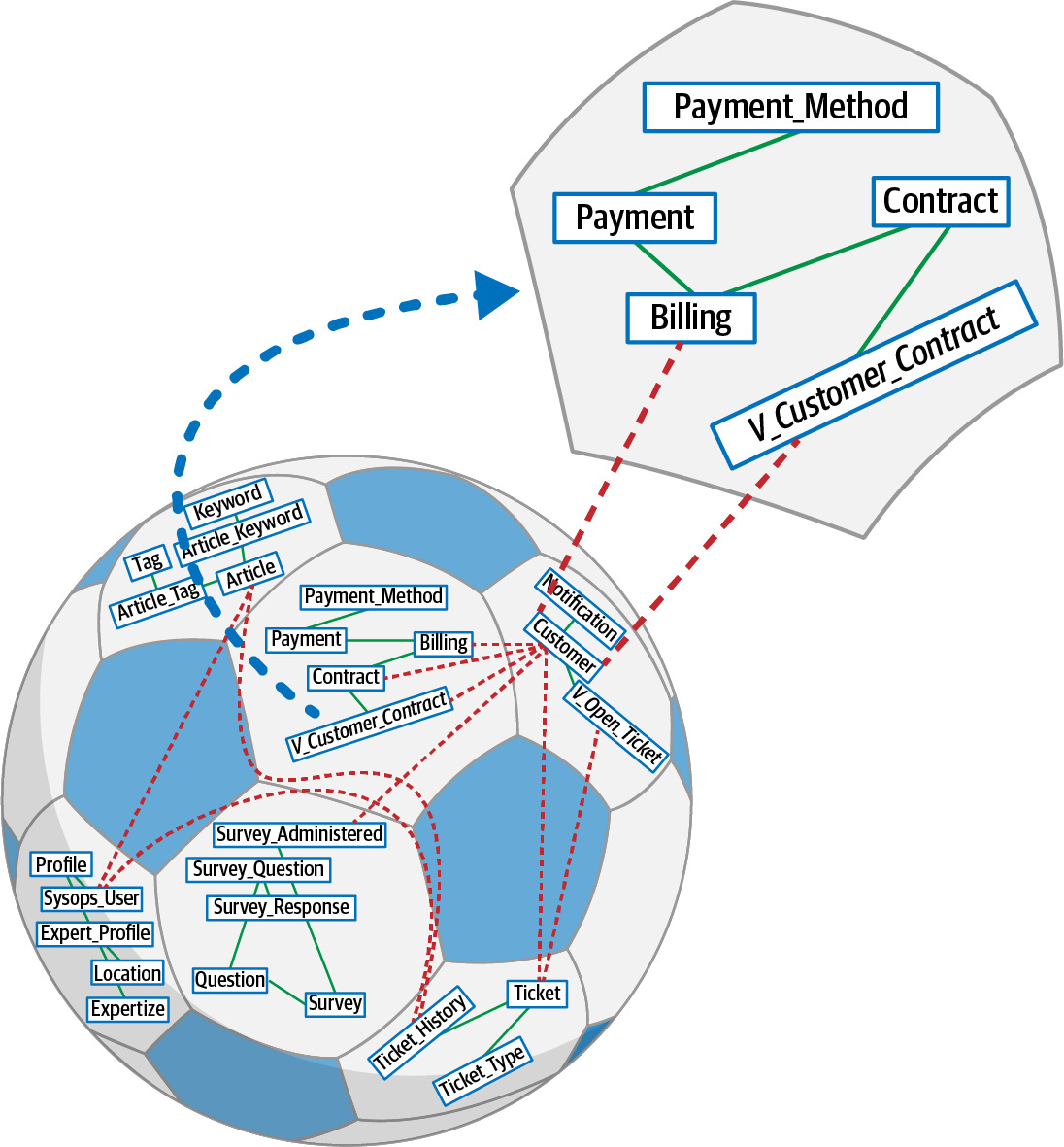
Figure 6.19: Tables belonging to data domains, extracted out, and connections that need attention
Step 3: Separate Database Connections to Data Domains(分離資料庫連線到各資料領域)#
- 建立每個資料領域的獨立連線
- 確保服務只存取屬於自己領域的表格
- 這一步可以在不實際拆分資料庫的情況下進行
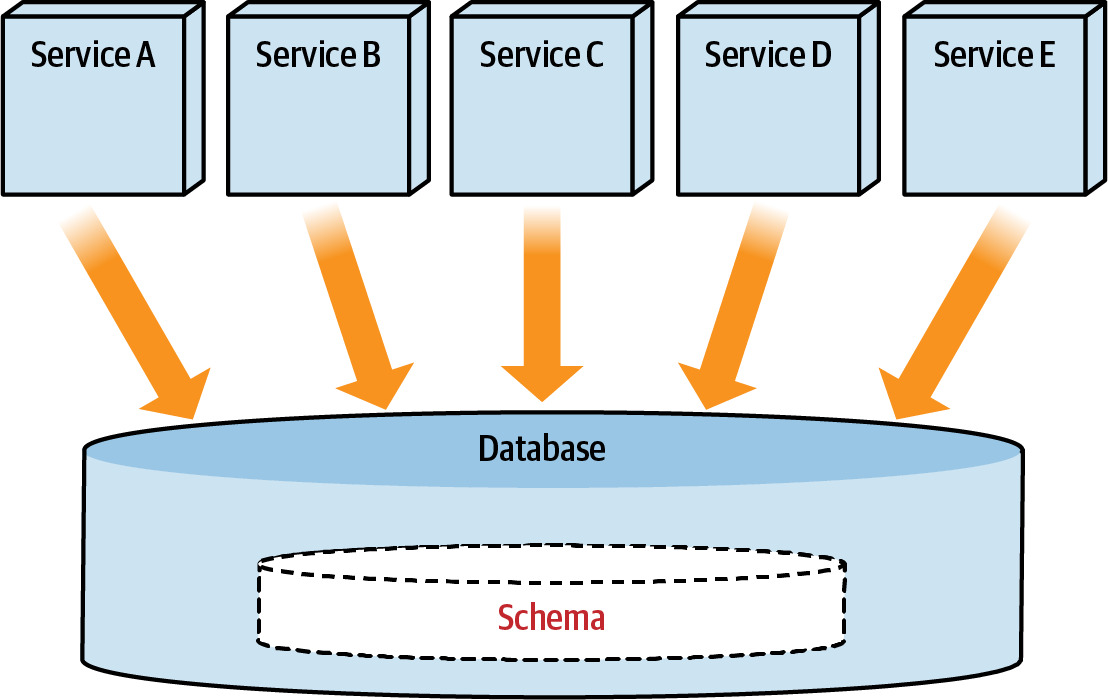
Figure 6.20: Multiple services use the same database, accessing all the tables necessary

Figure 6.21: Services use the primary schema according to their data domain needs
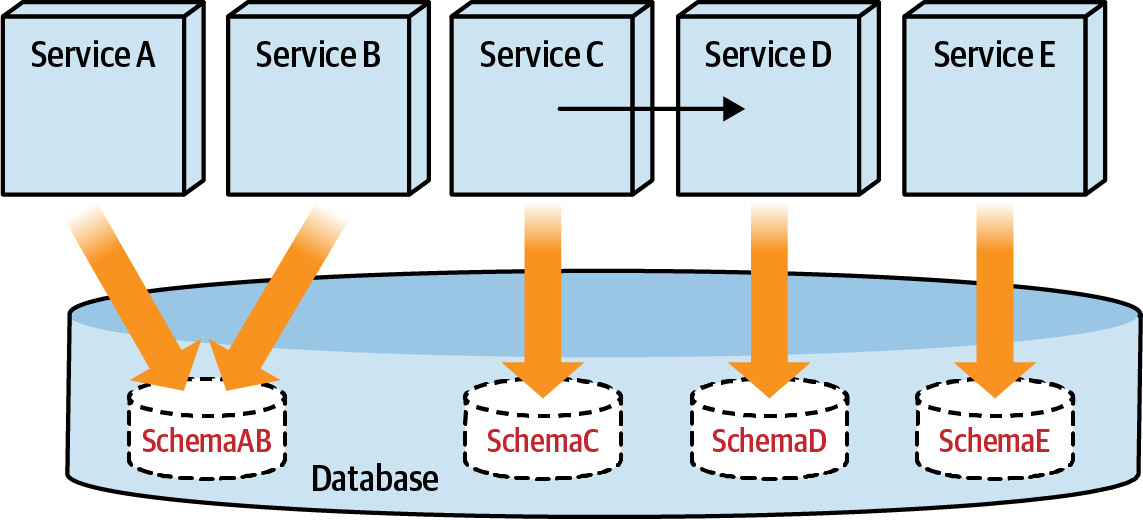
Figure 6.22: Move the cross-schema object access to the services
Step 4: Move Schemas to Separate Database Servers(將 Schema 搬移到獨立的資料庫伺服器)#
- 將各資料領域的 schema 實際搬移到獨立的資料庫伺服器
- 這是資料分解中最具風險的步驟
- 需要仔細規劃資料遷移策略
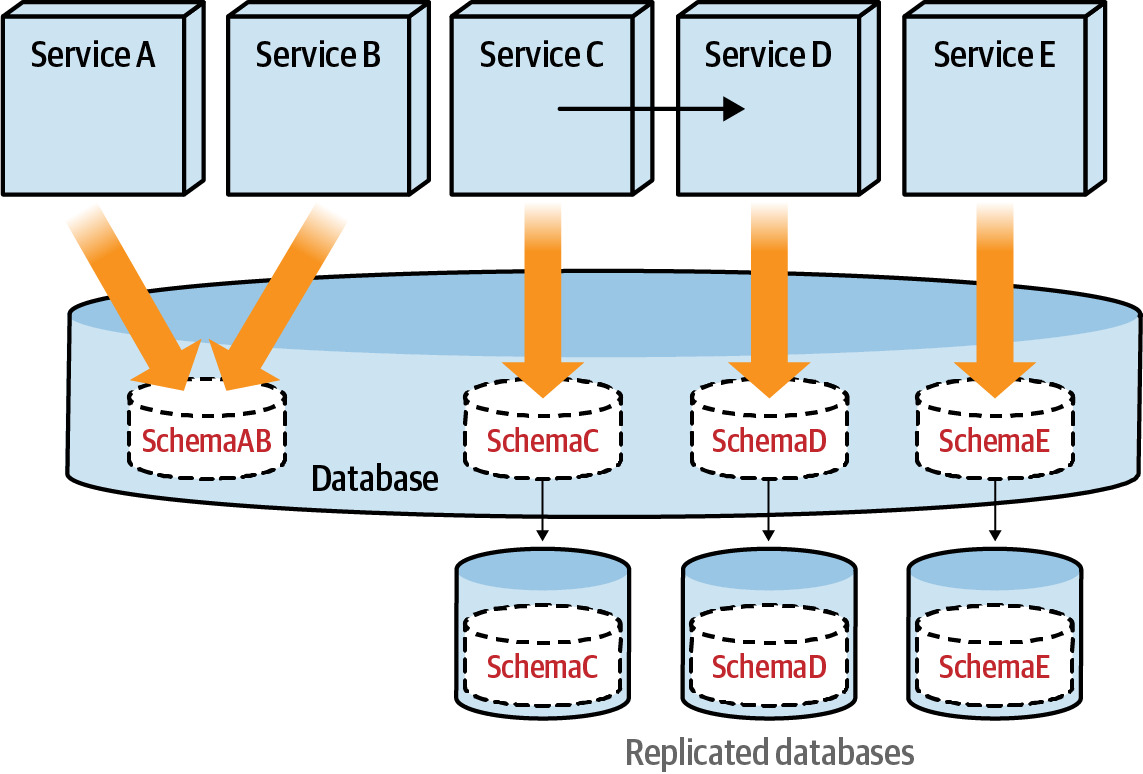
Figure 6.23: Replicate schemas to their own database servers
Step 5: Switch Over to Independent Database Servers(切換到獨立的資料庫伺服器)#
- 最後的切換步驟
- 確保所有服務正確連線到新的獨立資料庫
- 驗證資料一致性
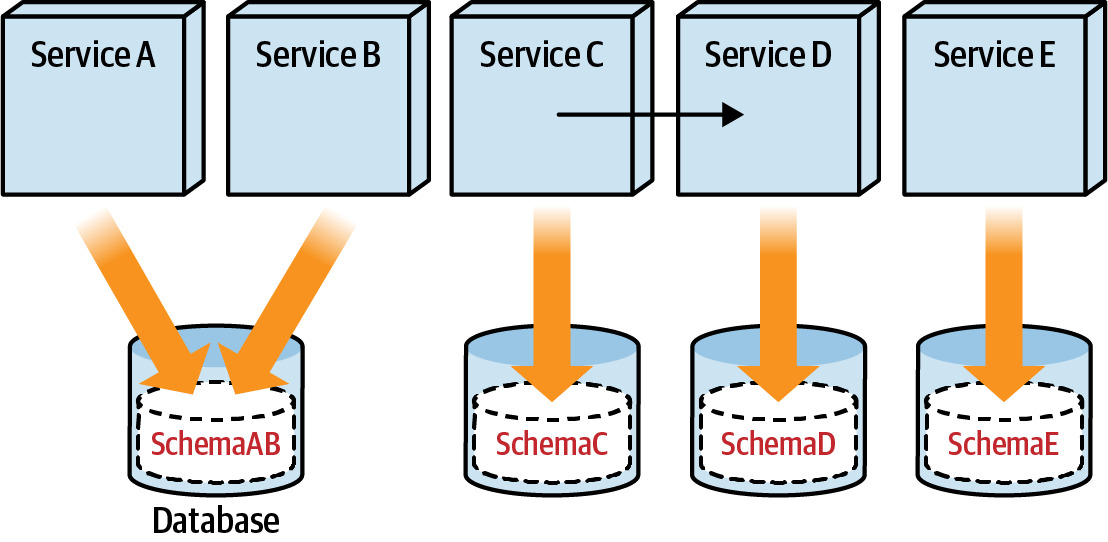
Figure 6.24: Independent database servers for each data domain
這五個步驟提供了一個漸進式的方法來分解單體資料庫,每一步都可以獨立驗證,降低風險。
Selecting a Database Type#
拆解單體資料庫時,不一定要繼續使用關聯式資料庫。根據資料特性選擇最適合的資料庫類型(polyglot databases)是更好的做法。以下是各種資料庫類型的特性比較:
Relational Databases#
- 代表產品:PostgreSQL、Oracle、Microsoft SQL Server
- 適用場景:需要 ACID 交易、結構化資料、複雜查詢
- 優勢:成熟穩定、SQL 支援完善、開發者熟悉度高
- 劣勢:水平擴展較困難、schema 變更成本高

Figure 6.25: Relational databases rated for various adoption characteristics
Key-Value Databases#
- 代表產品:Riak KV、Amazon DynamoDB、Redis
- 適用場景:簡單的鍵值查詢、快取、session 管理
- 優勢:極高的讀寫效能、容易擴展
- 劣勢:不支援複雜查詢、資料建模受限
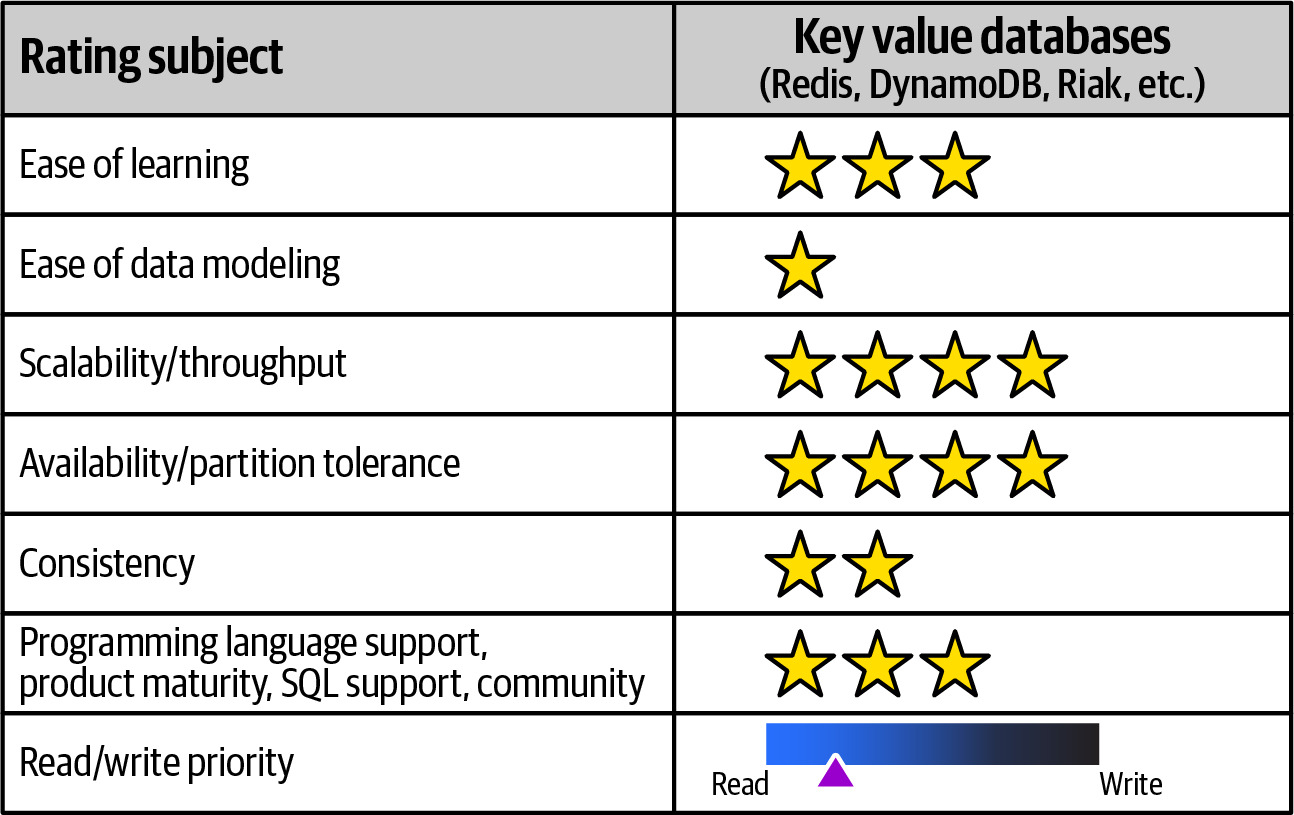
Figure 6.26: Key-value databases rated for various adoption characteristics
Document Databases#
- 代表產品:MongoDB、Couchbase、AWS DocumentDB
- 適用場景:結構靈活的資料、JSON 文件、內容管理
- 優勢:schema 靈活、易於開發、支援豐富查詢
- 劣勢:缺乏交易支援(部分產品已改善)、資料一致性較弱

Figure 6.27: Document databases rated for various adoption characteristics
Column Family Databases#
- 代表產品:Cassandra、Scylla、Amazon SimpleDB
- 適用場景:大量寫入、時間序列資料、高可用需求
- 優勢:極高的寫入效能、優秀的可擴展性和可用性
- 劣勢:學習曲線陡峭、資料建模複雜、不支援 join

Figure 6.28: Column family databases rated for various adoption characteristics
Graph Databases#
- 代表產品:Neo4j、Infinite Graph、Tiger Graph
- 適用場景:社交網路、推薦系統、知識圖譜、高度關聯的資料
- 優勢:關係遍歷效能極佳、支援複雜的關係查詢(如 Dijkstra 演算法、node similarity)
- 劣勢:不適合大量更新操作、學習曲線較高
- 支援的查詢語言包括 Gremlin 和 Cypher(Neo4j)

Figure 6.29: In graph databases, direction of the edge has significance when querying
在 graph database 中,變更 relationship type 是一個昂貴的操作,因為需要拜訪連接的節點、建立新邊、移除舊邊。因此 edge type 或 relationship type 需要謹慎設計。
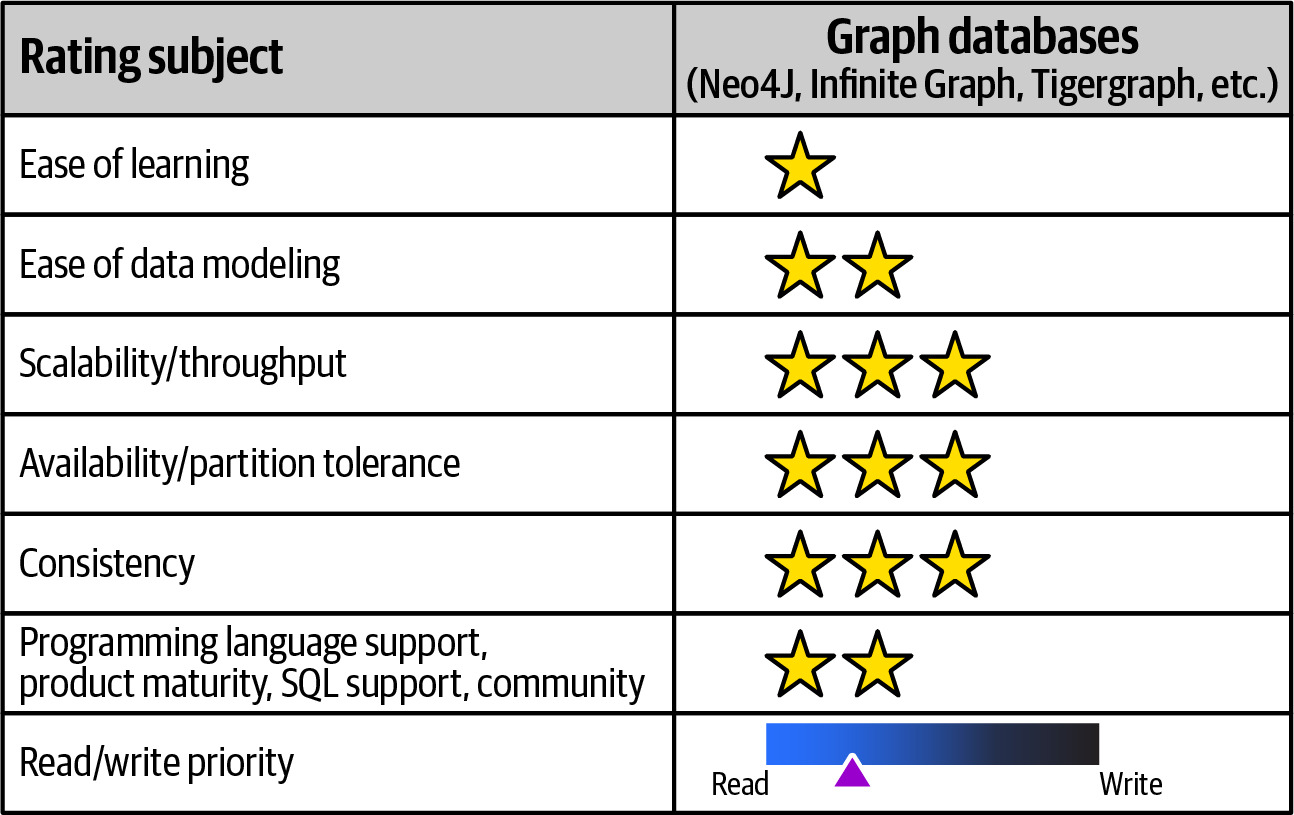
Figure 6.30: Graph databases rated for various adoption characteristics
NewSQL Databases#
- 代表產品:VoltDB、ClustrixDB、SimpleStore (aka MemSQL)
- 目標:結合 NoSQL 的可擴展性與關聯式資料庫的 ACID 特性
- 優勢:
- 支援 SQL 和 ACID transactions
- 自動化資料分區(partitioning)或分片(sharding)
- 多個 active nodes 設計,支援水平擴展
- 高可用性和分區容錯性(如 CockroachDB)
- 劣勢:部分僅以 DBaaS 形式提供、社群和工具成熟度較低
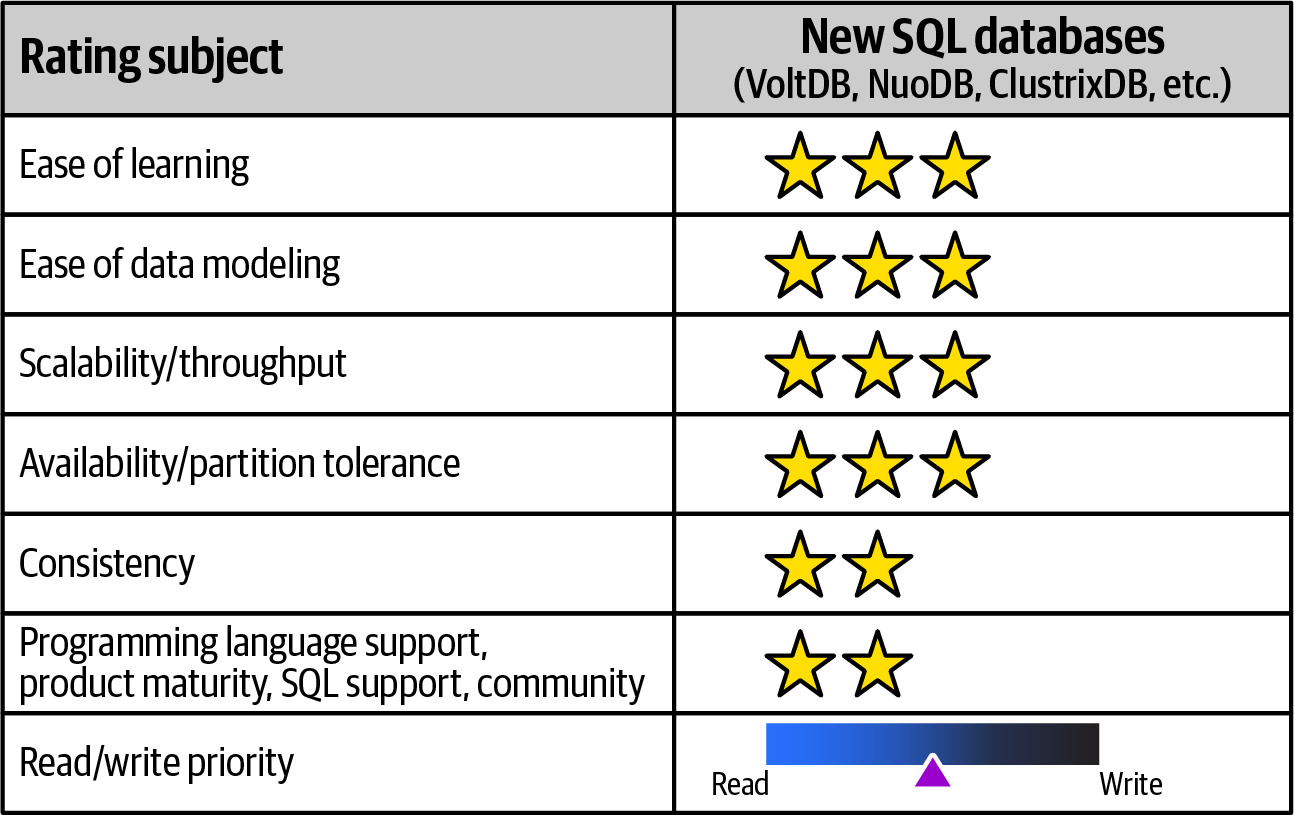
Figure 6.31: NewSQL databases rated for various adoption characteristics
Cloud Native Databases#
- 代表產品:Snowflake、Datomic、Amazon Redshift、Azure CosmosDB
- 優勢:
- 降低營運負擔、成本透明
- 容易擴展(雲端自動分配資源)
- 高可用性(使用 Production Topology 部署時無單點故障)
- 劣勢:
- 學習曲線因產品而異(如 Datomic 使用 immutable atomic facts 和 Clojure)
- 部分資料庫較新,社群支援有限
- Snowflake 和 Redshift 偏向資料倉儲型工作負載
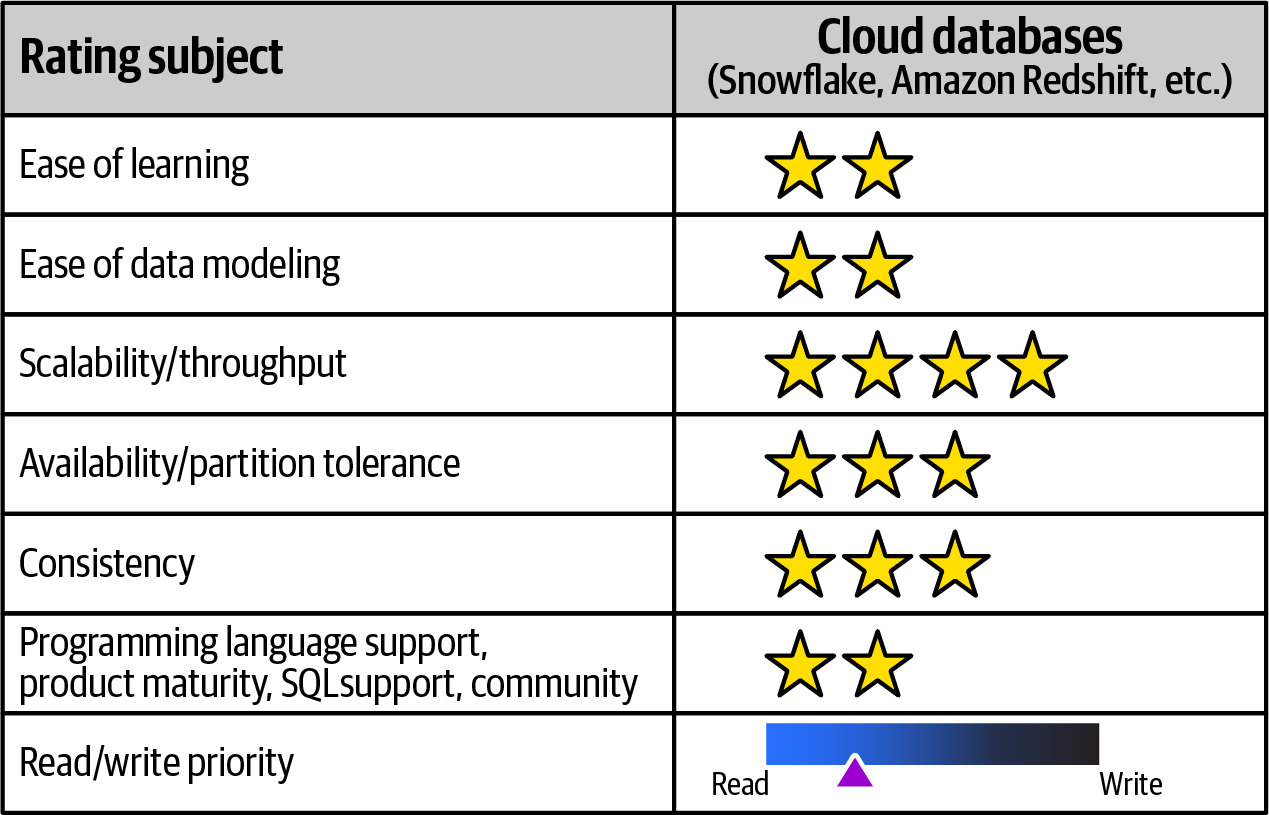
Figure 6.32: Cloud native databases rated for various adoption characteristics
Time-Series Databases#
- 代表產品:InfluxDB、kdb+、Amazon Timestream、TimescaleDB
- 適用場景:IoT、微服務可觀測性、自駕車資料、任何需要追蹤時間變化的資料
- 特性:
- 每個資料點附帶時間戳,資料幾乎只有寫入,不更新不刪除
- 是 append-only 的資料庫
- 不是通用型資料庫
- 優勢:極高的可擴展性和吞吐量
- 劣勢:學習曲線陡峭、資料建模方式特殊(使用 tags 而非欄位)
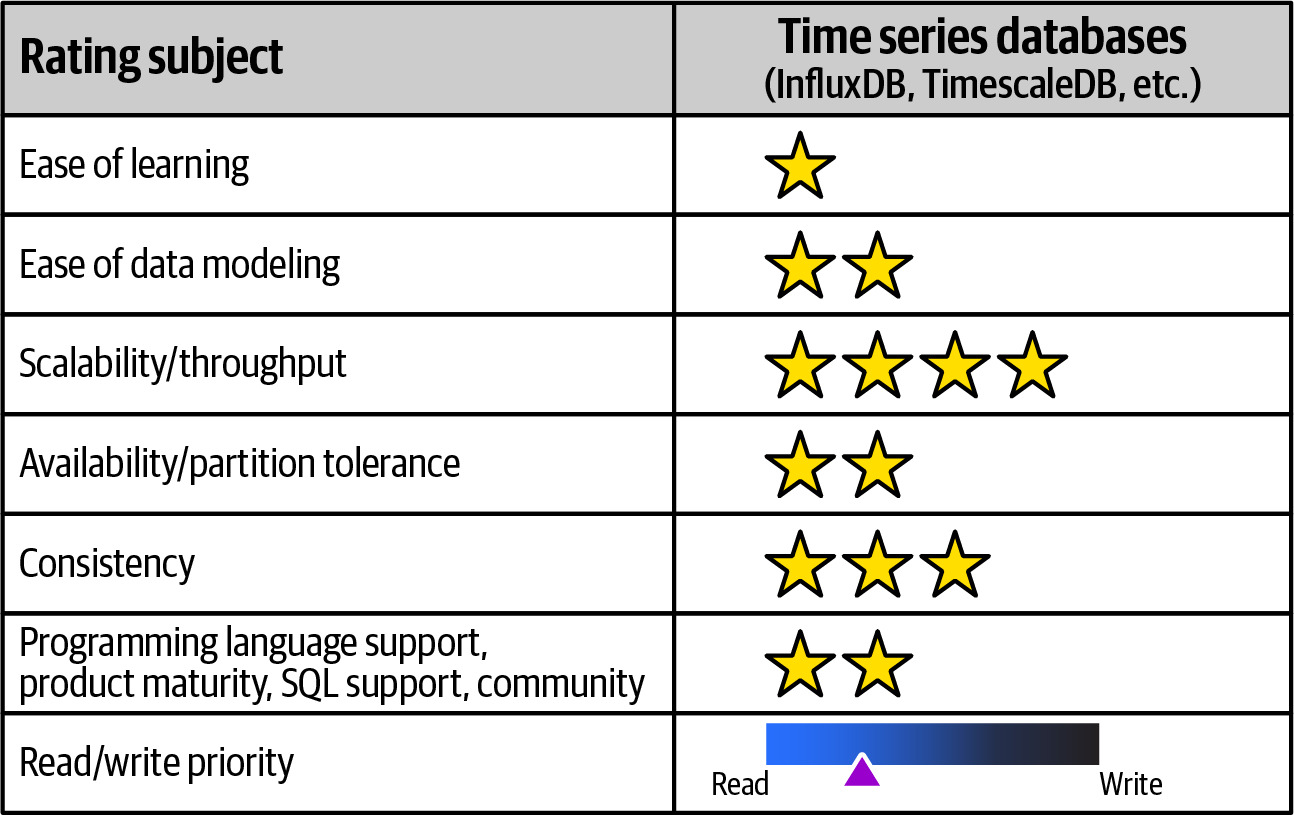
Figure 6.33: Time-series databases rated for various adoption characteristics
Sysops Squad Saga: Polyglot Databases#
- Devon 建議將客戶調查(customer survey)資料從關聯式資料庫遷移到 document database
- Dana(資料架構師)最初反對,認為沒有理由改變
- 團隊與產品負責人 Parker 會面,確認了業務需求:
- 行銷部門需要更高的靈活性和更快的變更回應時間
- 關聯式資料庫使得 UI 端的調查表呈現和變更都非常困難
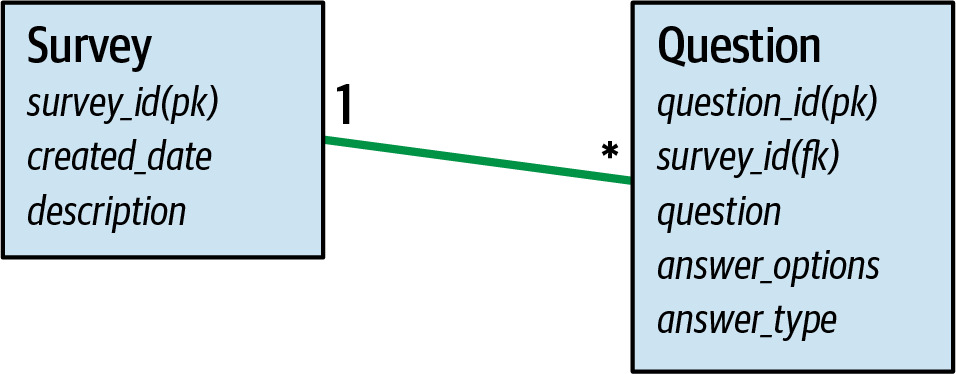
Figure 6.34: Tables and relationships in the sysops survey data domain
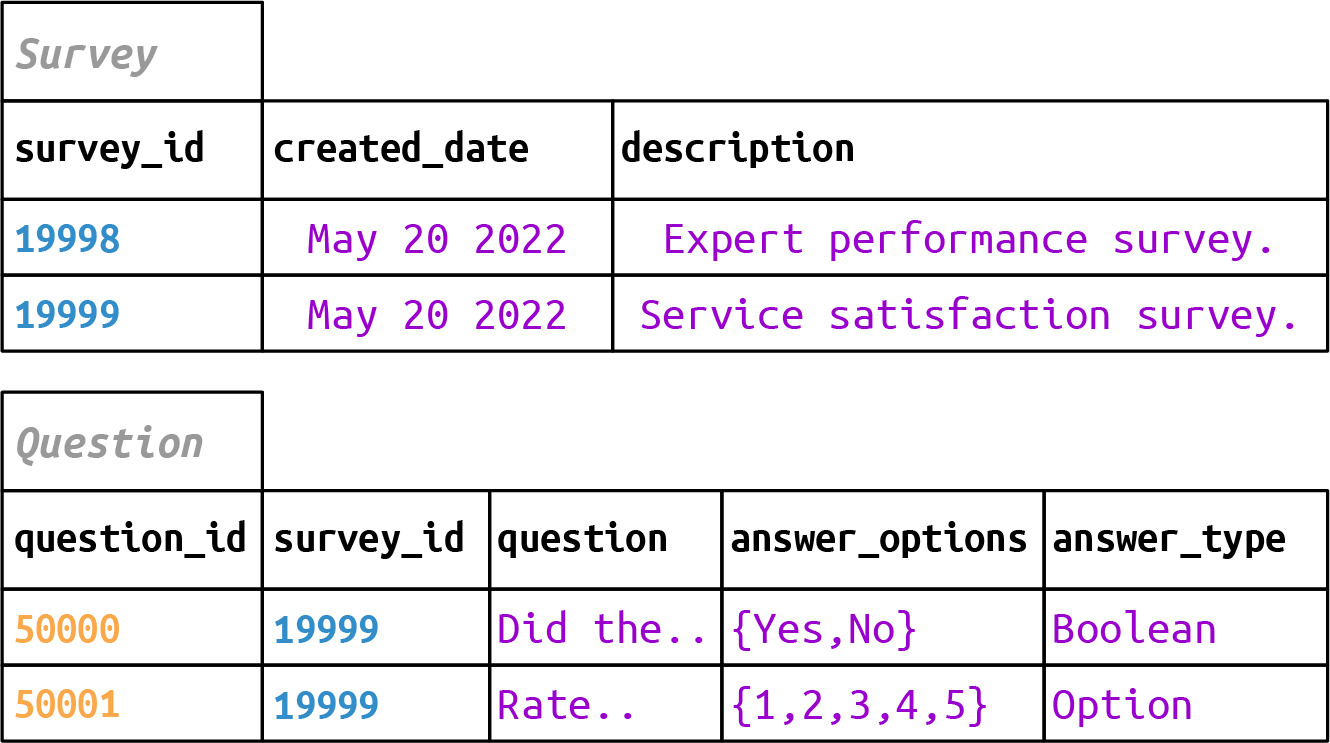
Figure 6.35: Relational data in tables for survey and question in the survey data domain
Document database 的兩種建模方式:
- Single aggregate(單一聚合):survey 和所有 questions 存為一個文件
- 優點:一次 get 即可取得完整調查資料,UI 渲染簡單
- 缺點:問題資料會在多個調查文件中重複
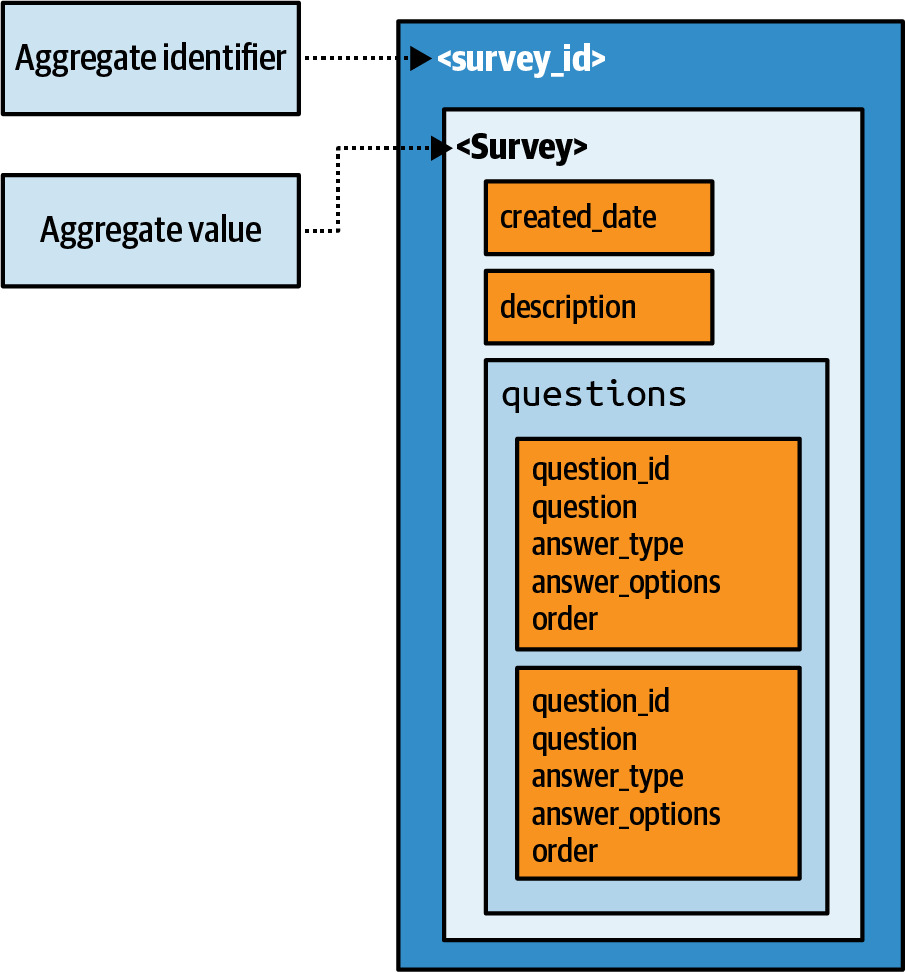
Figure 6.36: Survey model with single aggregate
- Multiple aggregates with references(帶引用的多重聚合):survey 和 question 分開存儲,survey 中包含 question 的引用
- 優點:問題可在多個調查中重複使用
- 缺點:需要多次查詢、UI 渲染較複雜
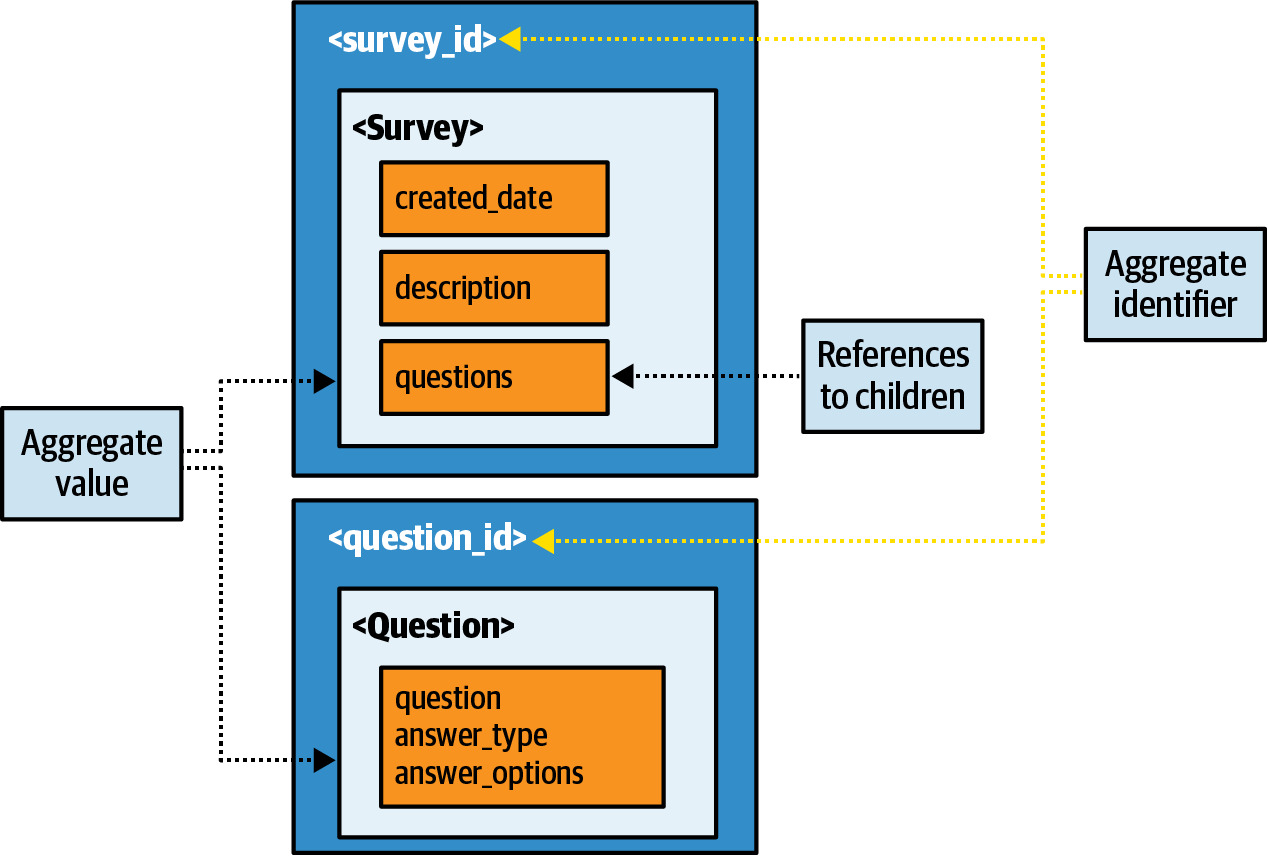
Figure 6.37: Survey model with multiple aggregates with references
- 團隊最終選擇 single aggregate 模式,因為只有五種調查類型,願意接受部分問題資料重複以換取 UI 的簡便性
- Addison 撰寫了 ADR 記錄此決定及其理由和後果