雲端基礎概念#
公有雲(Public Cloud)由雲端服務供應商擁有並營運,任何同意服務條款並付費的人都可以使用其基礎設施服務。在公有雲上建構的服務通常可透過公共網際網路存取,但也可以透過防火牆等機制限制可見性與存取。
私有雲(Private Cloud)則由組織自行擁有和營運,僅供組織成員使用。選擇私有雲的原因通常包括對控制權、安全性和成本的考量。混合雲(Hybrid Cloud)則是混合模式——部分工作負載在私有雲上運行,部分在公有雲上運行,常見於遷移過渡期或因法規要求(如 GDPR)需對特定資料進行更嚴格控管的情境。
從技術角度而言,私有雲與公有雲對架構師來說差異不大。本章聚焦在 IaaS(Infrastructure-as-a-Service)公有雲。
雲端資料中心的規模#
一個典型的公有雲資料中心擁有數萬台實體設備(接近 100,000 台)。資料中心的規模受限於電力消耗與散熱能力。每個機架包含超過 25 台電腦(各有多個 CPU),機架之間以高速網路交換器連接。

Figure 17.1: A cloud data center
區域與可用區#
雲端供應商將資料中心組織為區域(Region)。選擇區域時需考慮:
- 使用者距離:讓服務接近使用者以降低網路延遲
- 法規合規:如 GDPR 限制特定資料跨國傳輸
每個區域內的資料中心被分組為可用區(Availability Zone),不同可用區同時失敗的機率極低。選擇區域和可用區是重要的架構設計決策,攸關可用性與業務持續性。
管理閘道器#
所有對公有雲的存取都透過網際網路進行,主要有兩個閘道器:
- 管理閘道器(Management Gateway):負責分配、監控和銷毀 VM,收集計費資訊
- 訊息閘道器(Message Gateway):處理應用層訊息
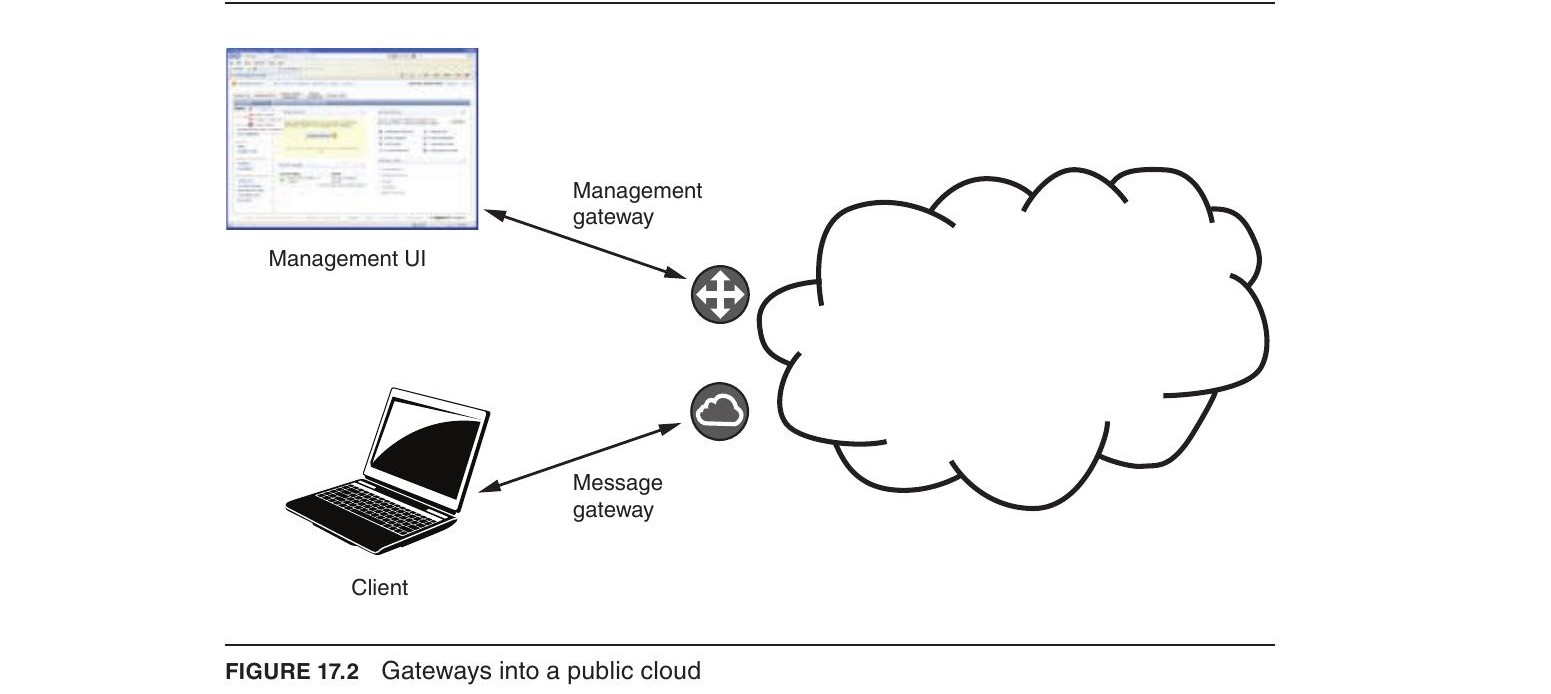
Figure 17.2: Gateways into a public cloud
當你請求分配一台 VM 時,需提供三個關鍵參數:雲端區域、實例類型(CPU 和記憶體規格)、以及 VM 映像檔 ID。管理閘道器會找到有足夠資源的 Hypervisor,建立新 VM 並回傳 IP 位址和主機名稱。管理閘道器可透過 API 訊息、命令列工具或 Web 介面存取。
雲端中的失敗#
當資料中心包含數萬台實體電腦時,每天幾乎必定有一台以上會故障。Amazon 報告指出,在約 64,000 台電腦(各有兩個旋轉硬碟)的資料中心中,每天約有 5 台電腦和 17 個磁碟故障。此外,網路交換器故障、資料中心過熱、自然災害等都可能導致系統中斷。
如果可用性對你的服務至關重要,你必須仔細思考要達到什麼等級的可用性,以及如何實現它。你應該假設:執行你服務的 VM 所在的實體機器終將會故障。
超時機制(Timeout)#
超時是分散式系統中偵測故障的核心策略(參見第 4 章可用性戰術)。使用超時時需注意以下幾點:
- 超時無法區分故障(電腦或網路連線中斷)與慢回應
- 超時不會告訴你故障發生在哪裡
- 當一個請求觸發連鎖的服務呼叫時,即使每個回應都只是略慢,整體延遲也可能被誤判為故障
超時偵測機制通常有兩個可調參數:
- 超時間隔:等待多久才判定回應失敗
- 錯過回應次數門檻:在更長的時間區間內,錯過幾次回應才觸發故障恢復
例如:超時設定為 200 毫秒,在 1 秒內錯過 3 次訊息才觸發恢復。對於單一資料中心內的系統,參數可以設定較為積極;對於廣域網路或行動網路,則應放寬以避免觸發不必要的恢復動作。
長尾延遲(Long Tail Latency)#
長尾延遲是雲端分散式系統的典型特性。下圖展示了 1,000 次 AWS「啟動實例」請求的延遲直方圖:

Figure 17.3: Long tail distribution of 1,000 requests to AWS
以此資料為例:
- 直方圖高峰在 22 秒
- 平均延遲為 28 秒
- 中位數為 23 秒
- 第 95 百分位為 57 秒——即 5% 的請求耗時為平均值的 2 至 10 倍
長尾延遲源自請求路徑上的壅塞或故障(伺服器佇列、Hypervisor 排程等),且通常不在服務開發者的控制範圍內。
處理長尾問題的兩種技術:
- Hedged Requests:發出比實際需求更多的請求,收到足夠回應後取消其餘。例如需啟動 10 個微服務實例,就發出 11 個請求,完成 10 個後終止未回應的那個。
- Alternative Requests:先發出 10 個請求,當 8 個完成後再發出 2 個額外請求,收到共 10 個回應後取消剩餘。
使用多實例提升效能與可用性#
當服務收到的請求超過單一實例的處理能力時,有兩種擴展策略:
- 垂直擴展(Vertical Scaling / Scaling Up):在更大的 VM 上執行服務,不改變設計,對應第 9 章的「增加資源」效能戰術
- 水平擴展(Horizontal Scaling / Scaling Out):部署多個服務副本,透過負載平衡器分發請求,對應「維護多個運算副本」戰術
負載平衡器(Load Balancer)#
負載平衡器解決的問題是:單一服務實例無法在可接受的延遲內處理所有請求。它作為獨立服務,將請求分發到多個實例。
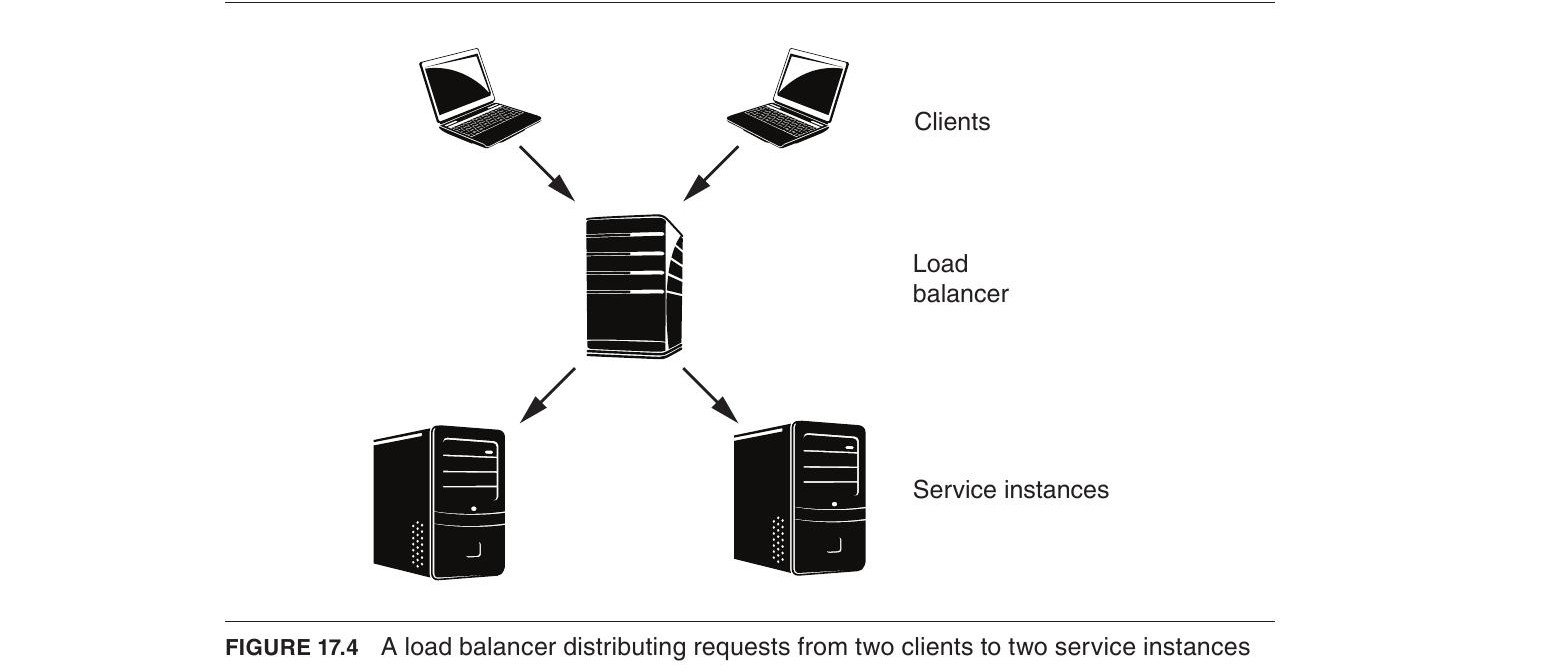
Figure 17.4: A load balancer distributing requests
關於負載平衡器的幾個重要觀察:
- Round-Robin 演算法:最簡單的分配方式,交替將訊息送到不同實例。僅在每個請求消耗相近資源時才能均勻分配負載,否則需採用其他演算法。
- 對客戶端透明:客戶端看到的是負載平衡器的 IP 位址,不需知道有多少實例或各實例的位址——這是第 8 章「使用中介者」的範例。
- 可巢狀:當負載平衡器本身過載時,可以用多層負載平衡器(Global Load Balancing)來處理。
健康檢查(Health Check)#
回覆訊息直接從服務實例返回客戶端,繞過負載平衡器,因此負載平衡器本身並不知道實例是否正常。健康檢查機制讓負載平衡器能定期確認實例狀態:
- 未通過健康檢查的實例被標記為不健康,停止接收新請求
- 實例可能在不健康與健康之間切換(例如佇列暫時過載後恢復)
- 負載平衡器會多次檢查才將實例移到不健康列表,並定期重新檢查不健康實例
服務實例池的大小應能容納一定數量的同時故障,同時仍能在期望延遲內處理所需的請求量。客戶端也應設計為在未收到及時回應時重送請求。
分散式系統中的狀態管理#
狀態(State)是指服務內部影響回應計算的資訊,取決於請求歷史。當服務有多個實例(或多執行緒)時,狀態存放位置至關重要:
- 有狀態服務(Stateful):歷史記錄保存在各服務實例中
- 無狀態服務(Stateless)——客戶端持有狀態:歷史記錄保存在客戶端
- 無狀態服務(Stateless)——外部資料庫持有狀態:歷史記錄保存在資料庫
常見實務是設計無狀態服務。有狀態服務在故障時會遺失歷史記錄,且恢復困難。無狀態設計讓新實例能立即處理請求並產生與其他實例一致的回應。
若確實需要有狀態行為,可使用:
- 直接會話(Direct Session):客戶端與特定實例建立直接連線
- 黏性會話(Sticky Session):負載平衡器將同一客戶端的後續請求導向同一實例
直接會話和黏性會話應僅在特殊情況下使用,因為存在實例故障和負載不均的風險。
分散式系統中的時間協調#
硬體時鐘每 12 天約會快或慢 1 秒。NTP(Network Time Protocol)用於同步網路上不同裝置的時鐘,在區域網路上精確到約 1 毫秒,公共網路上約 10 毫秒。雲端供應商(如 Amazon 和 Google)使用原子鐘提供極高精度的時間參考。
對架構師而言,關鍵問題是:你真的需要依賴精確的時鐘時間,還是確保正確的事件順序就已足夠?
- 大多數分散式系統使用向量時鐘(Vector Clock)等機制來判斷事件的先後順序,而非比較時間
- 裝置時間適用於觸發定期動作、記錄日誌時間戳等不需與其他裝置精確協調的場景
分散式系統中的資料協調#
考慮一個跨多台機器的資源鎖問題——例如銀行帳戶餘額的並行存取。在單機上,鎖的取得和釋放只是簡單的記憶體操作。但在分散式系統中:
- 傳統的兩階段提交協議需要透過網路傳送多個訊息,可能延遲或失敗
- 已取得鎖的服務實例可能在釋放前故障
解決方案是使用分散式協調演算法。Leslie Lamport 開發的 Paxos 是最早的此類演算法之一,依賴共識機制讓參與者即使在電腦或網路故障時也能達成一致。
分散式協調演算法極度複雜,不應自行實作。應使用現有的解決方案套件,如 Apache ZooKeeper、Consul 或 etcd。
自動擴縮(Autoscaling)#
自動擴縮是一項基礎設施服務,能在需求增長時自動建立新實例,在需求縮減時釋放多餘實例。它通常與負載平衡器搭配運作。
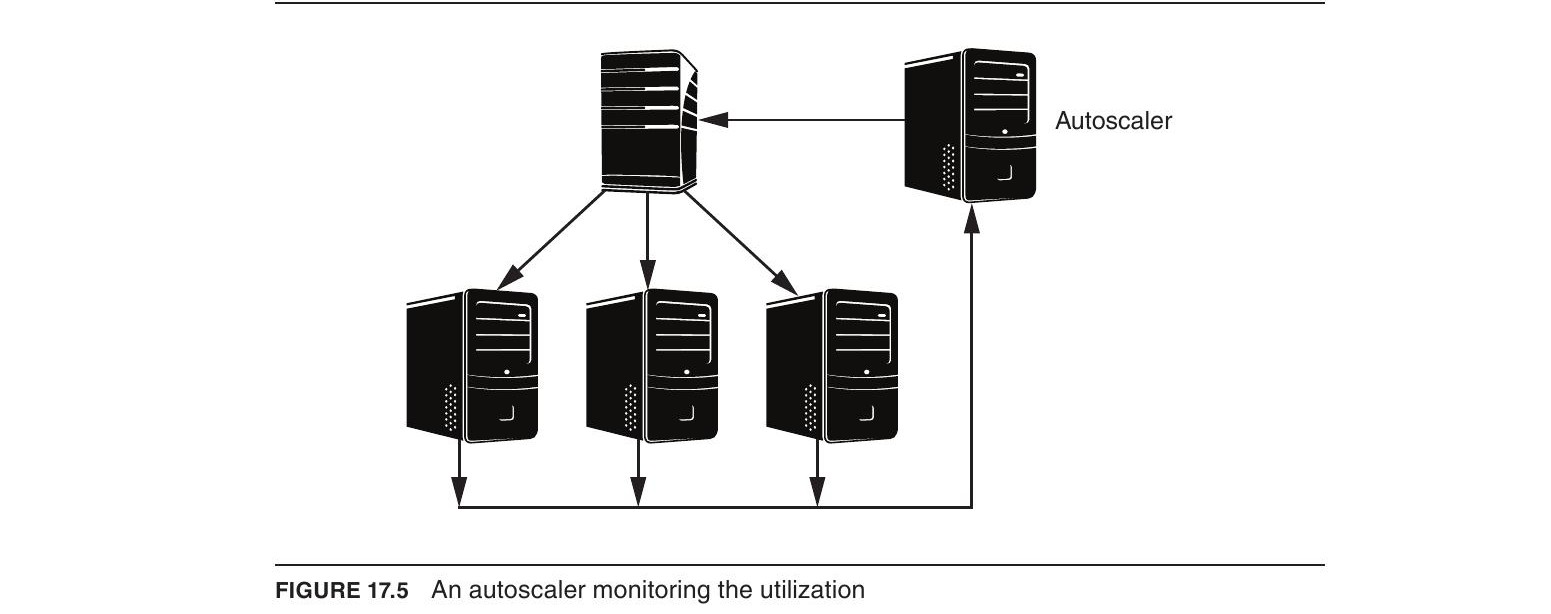
Figure 17.5: An autoscaler monitoring the utilization
VM 的自動擴縮#
架構師可設定一組規則來控制自動擴縮器的行為,包括:
- 新實例使用的 VM 映像檔與安全設定等配置參數
- CPU 使用率上限門檻:超過此值時建立新實例
- CPU 使用率下限門檻:低於此值時關閉現有實例
- 網路 I/O 頻寬門檻
- 實例數量的最小值與最大值
自動擴縮器不根據瞬時值做決策,因為:指標存在尖峰和低谷,需以合理時間區間的平均值為準;且分配和啟動新 VM 需要數分鐘。典型的規則形式如:「當 CPU 使用率在 5 分鐘內持續高於 80% 時,建立新 VM。」
此外,也可以根據時間排程預先分配資源,例如在工作日開始前增加 VM、下班後減少。
移除實例時不能直接關機。須先通知負載平衡器停止轉發請求,再通知實例終止活動並完成「排空」(Draining),最後才銷毀。服務開發者需實作對應的終止與排空介面。
Container 的自動擴縮#
容器執行在 VM 上的容器執行引擎中,因此擴縮涉及兩層決策:
- 判斷是否需要額外的容器(或 Pod)
- 判斷新容器能否在現有執行引擎上分配,還是需要新的 VM
控制容器擴縮的軟體獨立於控制 VM 擴縮的軟體,這使容器擴縮可跨不同雲端供應商移植。但若未來容器演進整合了兩種擴縮機制,可能會造成對特定雲端供應商的依賴。
本章小結#
- 雲端由分散式資料中心組成,透過管理閘道器進行 VM 的分配、監控和計費
- 資料中心內的電腦故障頻繁發生,架構師應假設 VM 終將故障,且請求會呈現長尾分佈
- 多實例服務透過負載平衡器分發請求,搭配健康檢查提升可用性
- 無狀態服務是最佳實務,便於故障恢復與新增實例;少量共享資料可使用分散式協調服務
- 自動擴縮根據規則自動建立或移除實例,實現雲端的彈性(Elasticity)