概述#
Deployability(可部署性)是指軟體能在可預測且可接受的時間與工作量內被部署至執行環境的特性。若新部署未達規格要求,也能在可預測的時間內完成 rollback(回滾)。隨著虛擬化與雲端基礎設施的普及,架構師有責任確保部署以高效且可預測的方式進行,將整體系統風險降到最低。
架構師主要關心部署是否具備以下三項特質:
- Granular(精細化):部署可針對整個系統或系統中的個別元素。架構若提供更細粒度的部署選項,便能降低特定風險。
- Controllable(可控制):架構應提供多層粒度的部署能力、監控已部署單元的運作狀態,以及回滾不成功部署的機制。
- Efficient(高效):架構應支援快速部署(及必要時的快速回滾),且所需的工作量合理。
持續部署#
Deployment(部署)是從撰寫程式碼開始,到真實使用者在 production 環境中與系統互動為止的完整流程。若此流程完全自動化(無人工介入),稱為 continuous deployment(持續部署);若自動化至將系統放入 production 之前、最後一步需人工介入,則稱為 continuous delivery(持續交付)。
Deployment Pipeline#
Deployment pipeline(部署流水線)是從程式碼提交至版本控制系統開始,到應用程式部署供使用者請求為止的工具與活動序列。流水線中各階段在不同的環境中執行:
- Development environment:開發者在此針對單一模組進行獨立單元測試。通過測試並經過審查後,程式碼提交至版本控制系統,觸發 integration 環境的建置活動。
- Integration environment:持續整合伺服器編譯新程式碼與其他相容版本,建構可執行映像檔。此環境執行單元測試與整合測試。通過後,服務被提升至 staging 環境。
- Staging environment:測試整體系統的各項品質(效能、安全性、授權合規等)。通過後以 blue/green 或 rolling upgrade 方式部署至 production。
- Production environment:服務上線後被密切監控,直到各方對其品質具備足夠信心。
虛擬化技術帶來了 environment parity(環境一致性)的好處——各環境在規模上可能不同,但硬體類型與基本結構保持一致,大幅減少「在 A 環境通過但在 B 環境失敗」的問題。
Pipeline 品質度量#
衡量 pipeline 品質的三項重要指標:
- Cycle time(週期時間):通過 pipeline 的速度。許多組織每天部署數次甚至數百次。
- Traceability(可追溯性):恢復導致問題的所有構件的能力,包含程式碼、依賴項、測試案例與工具版本。通常透過 artifact database 保存。
- Repeatability(可重複性):對相同構件執行相同動作時,獲得相同結果。
DevOps 是與持續部署密切相關的概念,目標是縮短從開發者提交變更到系統到達終端使用者手中的時間。其正式定義為:「一組旨在減少從提交變更到變更被放入正常 production 之間時間的實踐,同時確保高品質。」DevSecOps 則是將安全性方法融入整個流程的 DevOps 變體。
Deployability General Scenario#
Table 5.1 列出了 deployability 一般情境的各個要素:
| 情境要素 | 說明 | 可能的值 |
|---|---|---|
| Source | 觸發部署的角色 | 終端使用者、開發者、系統管理員、營運人員、元件市場、產品負責人 |
| Stimulus | 觸發原因 | 新元素可供部署(修復缺陷、安全補丁、升級元件/框架版本等);需要回滾 |
| Artifacts | 被變更的對象 | 特定元件或模組、系統平台、使用者介面、環境,或互操作的其他系統 |
| Environment | 部署環境 | Staging、production(全量部署或子集部署至指定的使用者、VM、容器、伺服器) |
| Response | 系統應執行的動作 | 整合新元件、部署新元件、監控新元件、回滾先前部署 |
| Response measure | 衡量指標 | 受影響構件數量與複雜度、平均/最壞情況工作量、時間、金錢成本、引入的新缺陷數、失敗部署數、可重複性、可追溯性、週期時間 |
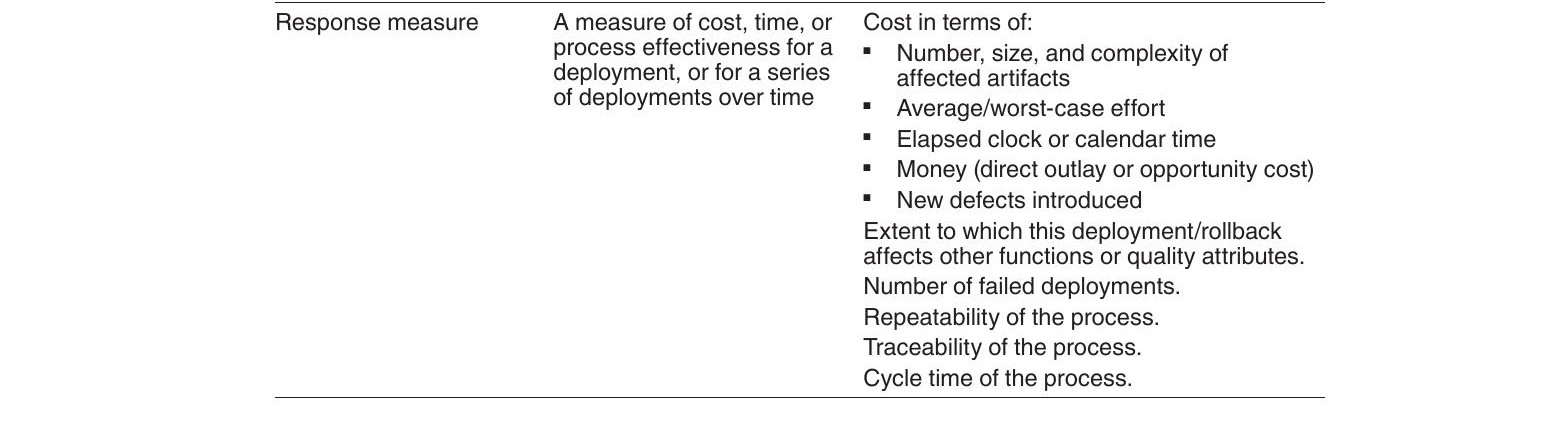
Figure 5.1: Sample concrete deployability scenario
上圖展示一個具體情境:元件市場發布了認證/授權服務的新版本,產品負責人決定納入。新服務在 40 小時內完成測試與部署,投入不超過 120 人時,且不引入缺陷、不違反 SLA。
Tactics for Deployability#
部署由新軟體或硬體元素的發布所觸發。若這些新元素在可接受的時間、成本與品質限制內完成部署,則該部署是成功的。

Figure 5.2: Goal of deployability tactics
Deployability 策略分為兩大類:管理部署流水線(Manage Deployment Pipeline)與管理已部署系統(Manage Deployed System)。在許多情況下,這些策略由購買的 CI/CD 基礎設施提供,架構師的工作是選擇與評估正確的策略組合。
Figure 5.3: Deployability tactics
Manage Deployment Pipeline#
- Scale rollouts(漸進式發布):不一次部署給所有使用者,而是逐步將新版本發布給受控的使用者子集。其餘使用者繼續使用舊版本。此策略需要一個路由機制,根據使用者身分將請求導向新版或舊版服務,以最小化部署有缺陷服務的負面影響。
- Roll back(回滾):若發現部署有缺陷或未達預期,可將其「回滾」至先前狀態。由於部署可能涉及多個服務與資料的協調更新,回滾機制必須追蹤所有更新或能反轉部署的所有後果,理想情況下是完全自動化的。
- Script deployment commands(腳本化部署命令):部署通常複雜且需要精確編排許多步驟,因此常以腳本實現。部署腳本應如同程式碼般被文件化、審查、測試與版控。腳本引擎自動執行部署腳本,節省時間並減少人為錯誤。
Manage Deployed System#
- Manage service interactions(管理服務互動):此策略因應同時部署與執行多個版本的系統服務。多個來自客戶端的請求可能被導向任一版本。多版本同時運作可能引入版本不相容問題,因此服務間的互動需要被調解以主動避免。
- Package dependencies(封裝依賴項):將元素及其依賴項一起封裝部署,確保依賴項版本在從開發到 production 的過程中保持一致。依賴項可能包含函式庫、作業系統版本與工具容器(如 sidecar、service mesh)。封裝方式包括 containers、pods 或 virtual machines。
- Feature toggle(功能開關):即使程式碼已通過完整測試,部署新功能後仍可能遇到問題。功能開關(或稱 kill switch)允許在 runtime 自動停用某功能,無需啟動新的部署,從而在不承擔重新部署風險與成本的情況下控制已部署的功能。
Tactics-Based Questionnaire#
以下是基於策略的問卷,用於快速了解架構在多大程度上運用了特定策略來管理 deployability:
| 策略群組 | 策略問題 |
|---|---|
| Manage Deployment Pipeline | 是否採用漸進式發布(scale rollouts),逐步推出新版本? |
| 是否能在發現服務運作不滿意時自動回滾(roll back)已部署的服務? | |
| 是否以腳本自動執行複雜的部署指令序列(script deployment commands)? | |
| Manage Deployed System | 是否管理服務互動(manage service interactions),使多版本服務可安全同時部署? |
| 是否封裝依賴項(package dependencies),讓服務與所有依賴的函式庫、OS 版本、工具容器一起部署? | |
| 是否使用功能開關(feature toggle),在新功能出問題時自動停用而非回滾整個服務? |
問卷答案應記錄是否支援(Y/N)、風險等級、設計決策與位置、以及理由與假設,作為後續文件調查、程式碼分析或逆向工程等活動的焦點。
Patterns for Deployability#
部署模式可分為兩大類:服務結構模式(結構化待部署的服務)與部署執行模式(如何部署服務),後者又可分為全量替換與部分替換。
Microservice Architecture#
Microservice architecture 將系統結構化為一組獨立可部署的服務,彼此僅透過服務介面的訊息通訊。不允許直接連結、直接讀取其他團隊的資料儲存、共享記憶體或任何後門。服務通常是 stateless 且相對較小,服務依賴為非循環的(acyclic),並透過 discovery service 路由訊息。
優點:
- 縮短上市時間:每個服務小且獨立可部署,修改後無需與其他團隊協調即可部署。
- 技術選擇自由:各團隊可為其服務選擇自己的技術,只要支援訊息傳遞即可,減少整合時的不相容錯誤。
- 容易擴展:各服務獨立,動態增加服務實例簡單直接,供給可更容易匹配需求。
取捨:
- 所有服務間通訊透過網路訊息,overhead 增加。Discovery service 可能成為效能瓶頸。
- 因分散式系統中同步活動的困難,不適合複雜交易。
- 技術自由的代價是組織必須維護多種技術及相應的經驗基礎。
- 大量微服務使智識控制困難,需要介面目錄與資料庫輔助。
- 設計具有適當職責與適當粒度的服務是一項艱鉅的設計任務。
Complete Replacement Patterns#
假設有 N 個 Service A 的實例需全部替換為新版本,且替換過程不降低服務品質(始終維持 N 個實例運行)。兩種模式皆為 scale rollouts 策略的實現:
Blue/Green Deployment: 建立 N 個新實例(green),安裝新版 Service A。全部就緒後,透過 DNS 或 discovery service 切換至新版本。確認運作正常後,才移除舊版實例(blue)。問題發生時,可迅速切回 blue 版本。
Rolling Upgrade: 逐一(或少量)替換 Service A 的實例。步驟為:分配新實例資源、安裝並註冊新版、開始導引請求至新版、讓舊實例完成處理後銷毀,重複直到全部替換完畢。
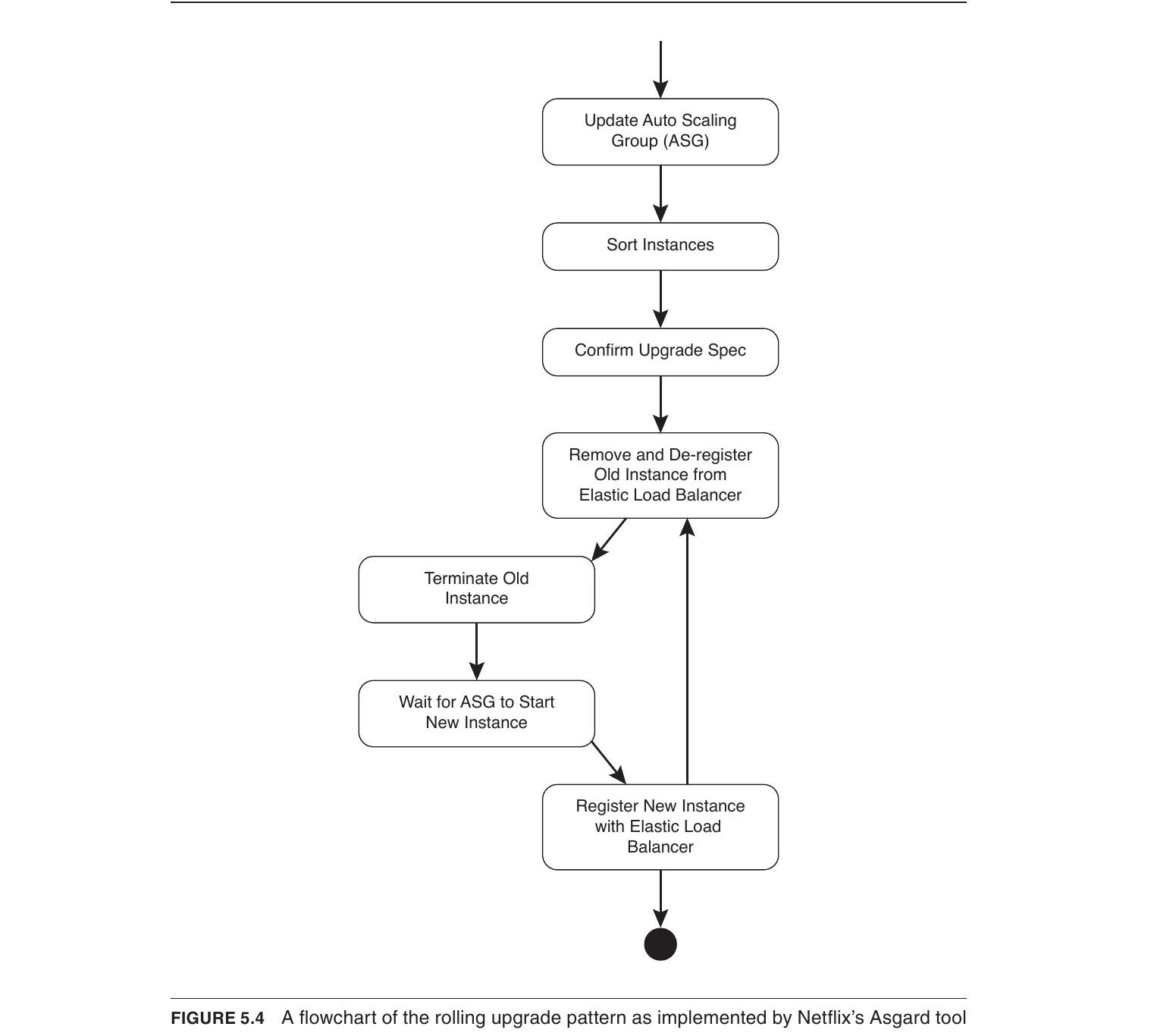
Figure 5.4: A flowchart of the rolling upgrade pattern
兩者比較:
| 面向 | Blue/Green | Rolling Upgrade |
|---|---|---|
| 峰值資源使用 | 2N 個實例 | N+1 個實例 |
| 錯誤發現時回滾 | 舊版可能已刪除,回滾耗時 | 舊版實例可能仍在,可更快發現錯誤 |
| 版本共存 | 任一時間只有一個版本活躍 | 新舊版本同時活躍 |
| 潛在問題 | 較少 | 可能出現 temporal inconsistency(時間不一致)與 interface mismatch(介面不匹配) |
Rolling upgrade 期間,客戶端的連續請求可能被不同版本處理,若版本行為不同會導致不一致結果。可使用 manage service interactions 策略來預防。介面不匹配則可透過擴展介面(而非修改既有介面)搭配 mediator 模式解決。
Partial Replacement Patterns#
有時並不希望替換所有實例。部分替換模式旨在同時為不同使用者群提供多個版本的服務:
Canary Testing(金絲雀測試): 在全面推出前,先讓一小群使用者測試新版本。這些測試者可能是 power users、預覽版使用者,或組織內部人員(如 Google 員工幾乎總是使用即將發布的版本作為測試者)。使用者透過 DNS 或 discovery service 被路由至適當版本。當測試重點在於新功能接受度時,稱為 dark launch。
- 優點:讓真實使用者以模擬測試無法達到的方式測試軟體;額外開發成本低;曝露於嚴重缺陷的使用者數最少。
- 取捨:需額外前期規劃與資源,以及結果評估策略。
A/B Testing: 行銷人員用來對真實使用者進行實驗,以確定哪個方案帶來最佳商業結果。一小部分有意義的使用者群接收不同的處理,差異可大可小。透過 DNS 與 discovery service 將客戶端請求導向不同版本,監控哪個版本在商業指標上表現最佳。
- 優點:讓行銷與產品開發團隊對真實使用者進行實驗並收集數據;可基於任意特徵定位使用者。
- 取捨:需實作替代方案(其中一個將被捨棄);需事先識別不同類別的使用者及其特徵。
小結#
Deployability 是現代軟體架構的關鍵品質屬性。透過 deployment pipeline 的自動化、適當的策略選擇(漸進式發布、回滾、腳本化部署、服務互動管理、依賴封裝、功能開關),以及合適的部署模式(microservice architecture、blue/green、rolling upgrade、canary testing、A/B testing),架構師能確保系統在持續變化的環境中高效、安全地演進。