概述#
可用性(Availability) 是指系統在需要時能夠正常運作並提供服務的能力。可用性關注的是系統對 故障(fault) 的預防與處理——當故障發生時,系統是否仍能繼續提供符合規格的服務。
建構高可用容錯系統最關鍵的任務之一,是理解運行期間可能出現的故障本質。一旦理解了這些故障,就能在系統中設計相應的緩解策略。
故障與失效的區別#
- 故障(Fault):系統內部的異常狀態,有可能導致失效
- 失效(Failure):系統不再提供符合規格的服務,且此偏差可被使用者觀察到
區分兩者的重要性在於:如果包含故障的程式碼被執行,但系統能夠自行恢復而不產生任何可觀察的行為偏差,我們就認為沒有發生失效。
可觀察性(Observability) 是判斷失效的關鍵標準:如果一個故障「可能被觀察到」,那它就是失效,無論實際上是否有人觀察到。
可用性的量化#
系統可用性可用以下公式衡量(源自硬體領域的穩態可用性):
MTBF / (MTBF + MTTR)
- MTBF(Mean Time Between Failures):平均故障間隔時間
- MTTR(Mean Time To Repair):平均修復時間
常見的可用性等級與對應的允許停機時間:
| 可用性 | 每 90 天停機時間 | 每年停機時間 |
|---|---|---|
| 99.0% | 21 小時 36 分 | 3 天 15.6 小時 |
| 99.9% | 2 小時 10 分 | 8 小時 46 秒 |
| 99.99% | 12 分 58 秒 | 52 分 34 秒 |
| 99.999% | 1 分 18 秒 | 5 分 15 秒 |
| 99.9999% | 8 秒 | 32 秒 |
高可用性(High Availability) 通常指可用性達到 99.999%(「五個九」)或更高的設計目標。只有非計畫停機才計入停機時間;計畫性維護停機不算在內。
系統的可用性需求通常透過 服務等級協議(SLA) 來規範,SLA 會載明保證的可用性等級以及違約時的罰則。例如 Amazon EC2 的 SLA 承諾每月正常運行百分比至少 99.99%,若未達標則提供服務抵免額度。
此外,偵測到的故障可依據嚴重程度(critical、major、minor)與服務影響(影響服務/不影響服務)進行分類,讓系統操作人員掌握即時且精確的系統狀態,並選擇適當的修復策略——自動化修復或人工介入。
可用性也與其他品質屬性密切相關:與可靠性(Reliability) 的差異在於可靠性側重「連續提供正確服務」,而可用性側重「在需要時可用」;與安全性(Safety) 的關聯在於安全性關注防止系統進入危險狀態。此外,當系統只是回應極度緩慢時,可用性也與效能(Performance) 難以區分。
可用性通用場景(General Scenario)#
可用性場景由以下六個部分組成:
- 來源(Source):故障來自何處——內部或外部的人員、硬體、軟體、實體基礎設施、實體環境
- 刺激(Stimulus):觸發場景的故障類型——遺漏(omission)、崩潰(crash)、不正確的時序(incorrect timing)、不正確的回應(incorrect response)
- 製品(Artifact):受故障影響的系統部分——處理器、通訊通道、儲存、行程
- 環境(Environment):故障發生時系統所處的狀態——正常運行、啟動、關閉、修復模式、降級運行、過載運行
- 回應(Response):系統期望的反應——阻止故障變成失效、偵測故障、記錄故障、通知相關實體、從故障中恢復、停用故障來源、以降級模式運行
- 回應度量(Response Measure):衡量指標——可用性百分比、故障偵測時間、故障修復時間、降級模式的持續時間與比例
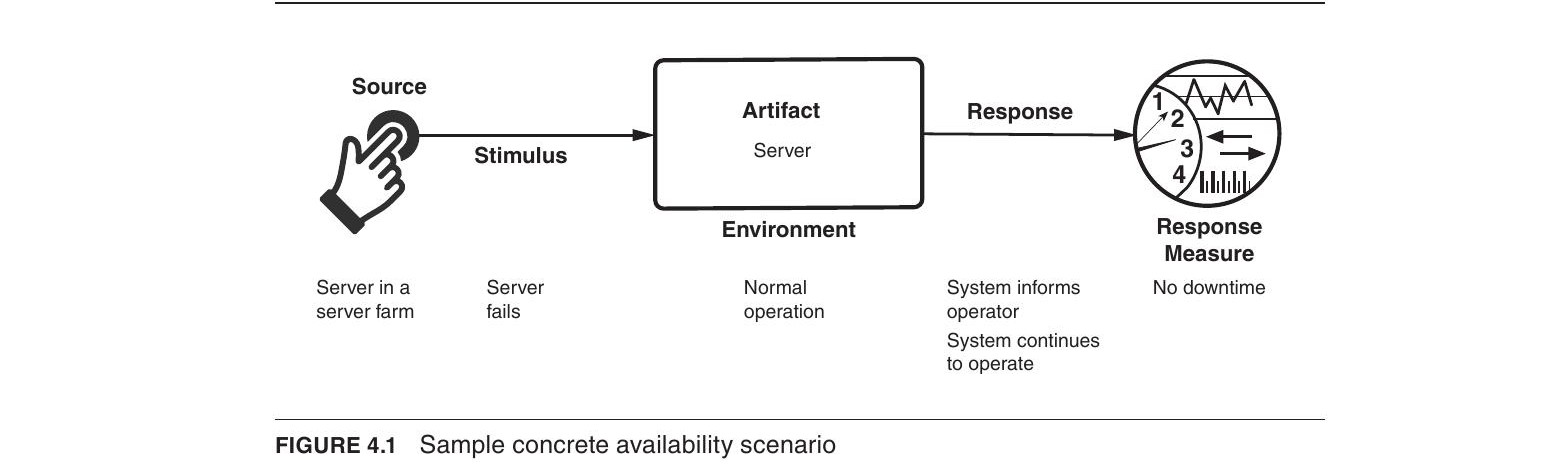
Figure 4.1: Sample concrete availability scenario
上圖展示了一個具體的可用性場景範例:伺服器農場中的一台伺服器在正常運行時發生故障,系統通知操作人員並繼續運行,不產生停機時間。
可用性策略(Tactics)#
可用性策略的目標是使系統能夠預防或承受故障,讓服務持續符合規格。這些策略會將故障控制在不至於變成失效的範圍內,或至少限制故障影響並使修復成為可能。

Figure 4.2: Goal of availability tactics
可用性策略分為三大類:故障偵測(Detect Faults)、故障恢復(Recover from Faults) 和 故障預防(Prevent Faults)。
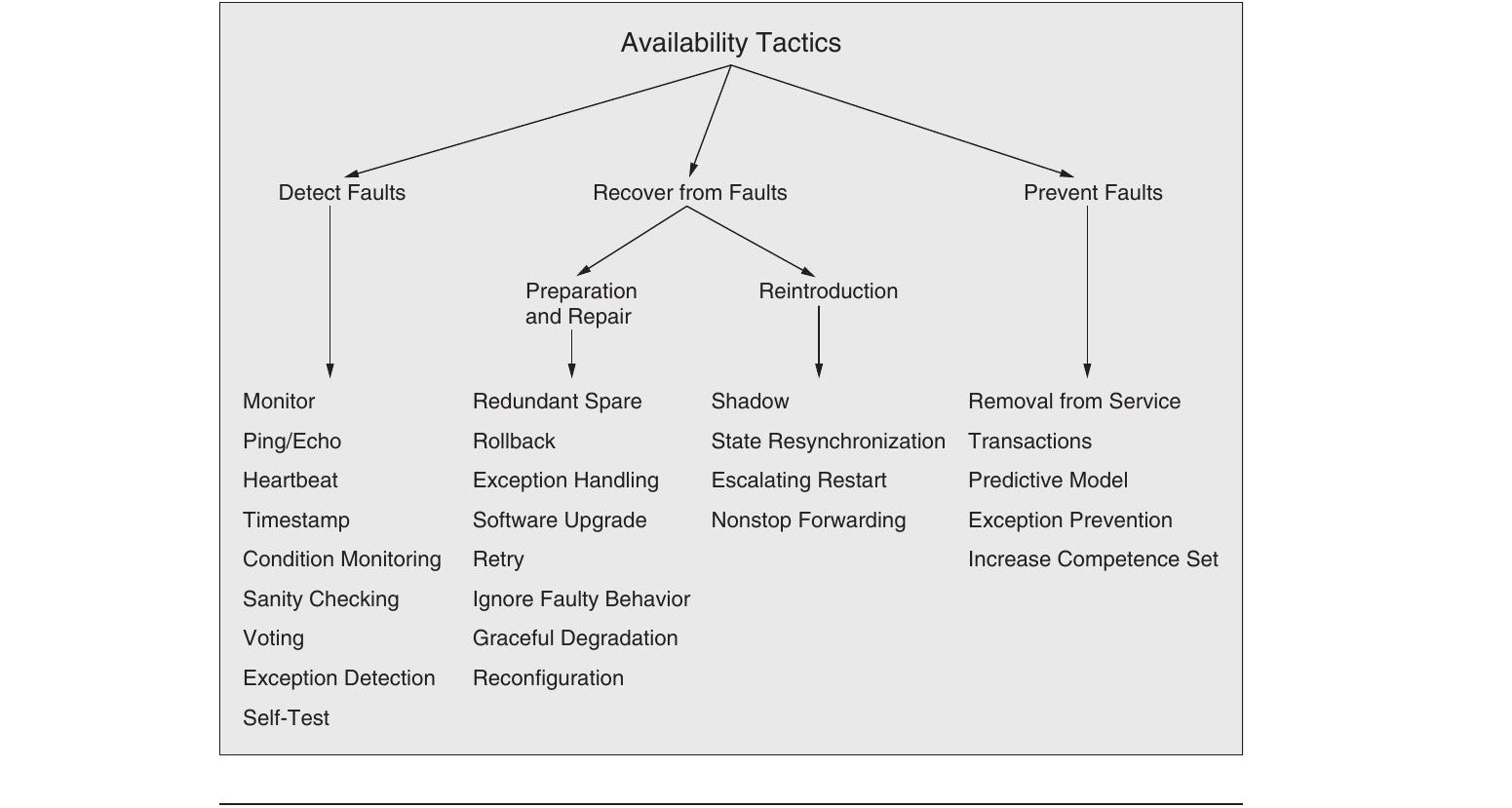
Figure 4.3: Availability tactics
這些策略通常由軟體基礎設施(如中介軟體)提供,因此架構師的工作往往是選擇和評估正確的策略組合,而非從頭實作。
故障偵測(Detect Faults)#
系統必須先偵測到故障,才能採取行動。偵測策略包括:
- 監控器(Monitor):監控系統各部分的健康狀態(處理器、行程、I/O、記憶體等),可協調其他偵測策略。當以計數器或計時器實作時,稱為 看門狗(Watchdog)
- Ping/Echo:透過非同步請求/回應訊息對來判斷節點的可達性與來回延遲。需設定逾時閾值,超過閾值即視為故障
- 心跳(Heartbeat):被監控的行程定期發送訊息給系統監控器。與 Ping/Echo 的差異在於由誰發起健康檢查——監控器(Ping/Echo)或元件本身(Heartbeat)
- 時間戳記(Timestamp):用於偵測分散式訊息傳遞系統中事件序列的不正確。也可使用序號替代
- 條件監控(Condition Monitoring):檢查行程或裝置的條件,或驗證設計假設。校驗和(Checksum) 是常見範例。監控器本身必須簡單且正確
- 合理性檢查(Sanity Checking):檢查元件特定操作或輸出的有效性與合理性,通常在介面層實施
- 投票(Voting):比較多個來源的計算結果。投票邏輯必須簡單且嚴格審查。投票來源的多樣性分為三種:
- 複製(Replication):完全相同的克隆元件,可防範硬體隨機故障,但無法防範設計或實作錯誤
- 功能冗餘(Functional Redundancy):以設計多樣性解決共模故障(Common-mode Failure) 問題,但仍受規格錯誤影響
- 分析冗餘(Analytic Redundancy):允許輸入輸出也具多樣性,能容忍規格錯誤。例如航空系統透過氣壓、雷達高度計、幾何計算等多種方式計算飛行高度
- 例外偵測(Exception Detection):偵測改變正常執行流程的系統狀態,包括系統例外、參數柵欄(Parameter Fence)(如
0xDEADBEEF模式偵測記憶體覆寫)、參數型別(Parameter Typing)、逾時(Timeout) - 自我測試(Self-Test):元件或子系統執行自我檢測程序,可由自身發起或由系統監控器觸發
故障恢復(Recover from Faults)#
故障恢復策略細分為兩個子類別:準備與修復(Preparation and Repair) 和 重新引入(Reintroduction)。
準備與修復#
- 冗餘備用(Redundant Spare):設定一個或多個備份元件,在主要元件故障時接手工作。這是 Hot Spare、Warm Spare、Cold Spare 模式的核心策略,差異在於備份元件在接管時的狀態更新程度
- 回滾(Rollback):偵測到失效時回復到先前已知的良好狀態(回滾線),然後繼續執行。通常與交易策略和冗餘備用策略搭配使用。回滾依賴檢查點(Checkpoint) 的儲存
- 例外處理(Exception Handling):偵測到例外後的處理機制,從簡單的函式回傳碼到包含故障名稱、來源、原因的例外類別
- 軟體升級(Software Upgrade):以不影響服務的方式進行線上升級,包括:
- 功能補丁(Function Patch):用於程序式程式設計
- 類別補丁(Class Patch):用於物件導向程式碼
- 無中斷線上軟體升級(Hitless ISSU):利用冗餘備用策略達成不影響服務的升級
- 重試(Retry):假設故障是暫時性的,重新嘗試操作。常用於網路和伺服器農場,應設定重試上限
- 忽略錯誤行為(Ignore Faulty Behavior):當判定特定來源的訊息為假性訊息時,直接忽略
- 優雅降級(Graceful Degradation):在元件故障時維持最關鍵的系統功能,放棄較不重要的功能
- 重新配置(Reconfiguration):將責任重新分配給仍在運作的資源或元件,盡可能維持功能
重新引入#
當故障元件修復後重新投入正常運行的策略:
- 影子模式(Shadow):將修復後的元件以「影子模式」運行一段預定義的時間,監控其行為正確性並逐步重建狀態,然後才恢復為主動角色
- 狀態重新同步(State Resynchronization):
- 搭配 主動冗餘 時,主動與備用元件平行處理相同輸入,狀態同步自然發生
- 搭配 被動冗餘 時,透過定期的狀態資訊傳輸(通常透過檢查點)進行同步
- 逐級重啟(Escalating Restart):透過不同粒度的重啟層級來恢復故障,從最小影響開始逐步升級:
- Level 0:殺掉並重建子執行緒(被動冗餘/Warm Spare)
- Level 1:釋放並重新初始化所有未受保護的記憶體
- Level 2:釋放並重新初始化所有記憶體
- Level 3:完全重新載入並重新初始化可執行映像
- 不間斷轉發(Nonstop Forwarding):源自路由器設計,將功能分為監督/控制平面 和資料平面。控制平面故障時,資料平面繼續沿已知路由轉發封包,同時控制平面執行「優雅重啟」逐步重建路由資料庫
故障預防(Prevent Faults)#
與其偵測後恢復,不如從一開始就預防故障發生:
- 移出服務(Removal from Service):暫時將元件置於離線狀態,清除潛在故障(如記憶體洩漏、碎片化、軟體錯誤累積),在問題影響服務前主動處理。又稱 軟體重生(Software Rejuvenation) 或 治療性重啟(Therapeutic Reboot)
- 交易(Transactions):利用交易語義確保分散式元件間的非同步訊息具備 ACID 特性(原子性、一致性、隔離性、持久性)。最常見的實作是兩階段提交(2PC) 協議,可防止競態條件
- 預測模型(Predictive Model):結合監控器,監測系統運行參數以預測故障的發生。監測指標包括連線建立率、閾值跨越(高低水位標記)、行程狀態統計、訊息佇列長度等
- 例外預防(Exception Prevention):在例外發生之前就加以預防的技術,例如錯誤校正碼(ECC)、智慧指標(Smart Pointer)進行邊界檢查與自動資源釋放、以及包裝器(Wrapper)防止懸空指標或信號量存取違規
- 擴大能力集(Increase Competence Set):擴展元件能正常處理的狀態範圍。能力集越大的元件,能在更多情境下正常運作而不需拋出例外。例如,與其在資源被鎖定時拋出例外,不如設計成等待存取或延後完成操作
策略導向的問卷(Tactics-Based Questionnaire)#
基於上述策略,可建立一組結構化的問卷來評估系統的可用性架構決策。問卷涵蓋四個策略群組,每個問題都要求記錄:
- 是否支援(Support Y/N)
- 風險(Risk)
- 設計決策與位置(Design Decisions and Location)
- 理由與假設(Rationale and Assumptions)
主要問題範疇包括:
故障偵測:
- 系統是否使用 Ping/Echo 偵測元件或連線故障?
- 系統是否使用監控器監測健康狀態?
- 系統是否使用心跳機制偵測故障?
- 系統是否使用時間戳記偵測分散式系統中的事件序列錯誤?
- 系統是否使用投票機制確認複製元件產生相同結果?
- 系統是否使用例外偵測?
- 系統是否能執行自我測試?
故障恢復(準備與修復):
- 系統是否採用冗餘備用?切換機制為何?切換需要多長時間?
- 系統是否採用例外處理?
- 系統是否採用回滾?
- 系統是否支援線上軟體升級?
- 系統是否會系統性地重試暫時性故障?
- 系統是否能忽略假性錯誤行為?
- 系統是否有降級策略?
- 系統是否有一致的重新配置策略?
故障恢復(重新引入):
- 系統是否支援影子模式?
- 系統是否採用狀態重新同步?
- 系統是否支援逐級重啟?
- 系統是否支援不間斷轉發?
故障預防:
- 系統是否能將元件移出服務進行預防性維護?
- 系統是否使用交易來確保 ACID 特性?
- 系統是否使用預測模型監控運行參數?
- 系統是否實施例外預防技術?
可用性模式(Patterns)#
冗餘備用模式群#
前三個模式都以冗餘備用策略為核心,差異在於備份元件的狀態與主動元件的同步程度:
- 主動冗餘(Active Redundancy / Hot Spare):保護群組中的所有節點平行接收並處理相同輸入,備用節點與主動節點維持同步狀態。故障時可在毫秒等級完成接管。一個主動節點搭配一個備用節點稱為 1+1 冗餘
- 被動冗餘(Passive Redundancy / Warm Spare):僅主動成員處理輸入流量,並定期向備用節點發送狀態更新。備用節點的狀態與主動節點是鬆耦合的,在可用性與成本之間取得平衡
- 冷備用(Cold Spare):備用節點保持離線,直到故障轉移發生時才啟動上電重置程序。由於修復時間長,不適用於高可用性需求
當元件為無狀態(Stateless) 時,Hot Spare 與 Warm Spare 兩種模式變得相同。
優點:系統在故障發生後僅經歷短暫延遲即可繼續正常運作,而非完全停止服務等待數小時甚至數天的修復。
取捨:需要額外的成本與複雜度來提供備用元件。三種模式之間的取捨在於恢復時間 vs. 運行時期的同步成本——Hot Spare 成本最高但恢復最快。
三重模組冗餘(Triple Modular Redundancy, TMR)#
廣泛使用的投票策略實作。三個元件接收相同輸入,各自產出結果交由投票邏輯判斷。當結果不一致時,投票器回報故障並決定使用哪個輸出(多數決或加權平均)。
- 優點:簡單易懂、易於實作,不關心造成差異的原因,只關注做出合理選擇讓系統繼續運作
- 取捨:三個元件在可用性與成本之間達到最佳平衡點,兩個以上元件同時故障的統計機率極低
斷路器(Circuit Breaker)#
搭配重試策略使用。當偵測到逾時或故障時,斷路器會在判定系統正在處理故障後中斷無止盡的重試迴圈,後續呼叫直接回傳而不傳送請求,直到斷路器被「重置」。
- 優點:
- 將重試策略從個別元件中抽離,統一管理
- 防止故障級聯——在分散式系統中,大量呼叫者反覆呼叫無回應的元件會導致自身也停止服務,使故障擴散到整個系統
- 取捨:逾時值的選擇至關重要。太長會增加不必要的延遲;太短會導致誤觸發(false positive),反而降低可用性與效能
斷路器的逾時值設定需要仔細校準:過長增加延遲,過短則會產生誤報,在不需要時切斷正常的服務呼叫。
其他可用性模式#
- 行程對(Process Pairs):採用檢查點與回滾策略。備份行程持續進行檢查點並在必要時回滾到安全狀態,隨時準備在故障發生時接管
- 前向錯誤恢復(Forward Error Recovery):不回退到先前狀態,而是向前移動到一個安全的(可能是降級的)狀態。通常依賴內建的錯誤校正能力(如資料冗餘),無需回退或重試即可修正錯誤
災難恢復(Disaster Recovery)是可用性的延伸議題。災難指地震、洪水、颶風等摧毀整個資料中心的事件。美國 NIST 在其 SP 800-34 中識別了八種不同類型的應變計畫,涵蓋從業務連續性到資訊系統應變的各個面向。
小結#
可用性是軟體架構中最根本的品質屬性之一。其核心在於理解故障的本質,並透過三層防線來應對:
- 偵測:盡早發現故障(監控、心跳、投票等)
- 恢復:將故障的影響降到最低(冗餘備用、回滾、優雅降級等)
- 預防:在故障發生前主動消除風險(移出服務、交易、預測模型等)
架構師的關鍵工作是根據系統的可用性需求(通常以 SLA 量化),選擇並組合適當的策略與模式,在可用性、成本與複雜度之間取得平衡。
值得注意的是,冗餘(Redundancy) 是實現高可用性最核心的策略——本章介紹的大多數模式與策略都以某種形式利用了冗餘。然而,可用性與其他品質屬性之間存在取捨:例如與可修改性(Modifiability) 和可部署性(Deployability) 的關係——對一個要求 24/7 可用的系統進行變更,必須在不中斷服務的前提下完成(如使用線上軟體升級或滾動更新策略)。故障偵測策略(如 Ping/Echo、Heartbeat、投票)也會帶來效能開銷,需在偵測精度與系統效能之間權衡。