資料處理是一個不斷演進的領域,面對更大的資料集、更密集的資料轉換,以及對快速、可靠且低成本結果的需求。資料處理管線(data processing pipeline)能將來自各種來源(行動裝置使用統計、感測器網路、網站應用日誌等)的無界、無序、全球規模的資料集,轉換為結構化、索引化的儲存,支撐關鍵業務決策或產品功能。本章涵蓋管線應用類型、需求識別與設計模式、開發生命週期最佳實踐,以及 Spotify 的事件交付系統案例研究。
管線應用類型#
管線可以包含多個階段(stage),每個階段是一個獨立的處理程序,彼此存在依賴關係。以下是幾種常見的管線應用:
ETL(Extract Transform Load)資料轉換#
ETL 模型是資料處理中的常見範式:從來源擷取資料、進行轉換(可能包含反正規化),然後重新載入到特定格式。轉換階段可以:
- 變更資料格式以新增或移除欄位
- 跨資料來源進行聚合計算
- 為資料建立索引,改善下游服務消費資料的特性
典型的 ETL 管線範例包括:機器學習或商業智慧的前處理、事件計數、帳單報告計算、以及驅動 Google 網頁搜尋的索引管線。
資料分析(Data Analytics)#
商業智慧(Business Intelligence)是指用於收集、整合、分析和呈現大量資訊的技術與實踐。本章以虛構的 Shave the Yak 手機遊戲為例:業務主管需要每月報告最常使用的功能,以規劃新功能開發。團隊將行動和網頁分析資料儲存在 BigQuery 中,每天由 Google Analytics 更新三次,並在新資料到達時觸發彙整作業。
機器學習(Machine Learning)#
ML 系統通常包含五個階段:
- 從大型資料集中擷取特徵(features)和標籤(labels)
- 使用 ML 演算法訓練模型
- 在測試資料集上評估模型
- 將模型提供給其他服務使用(serving)
- 其他系統根據模型回應做出決策
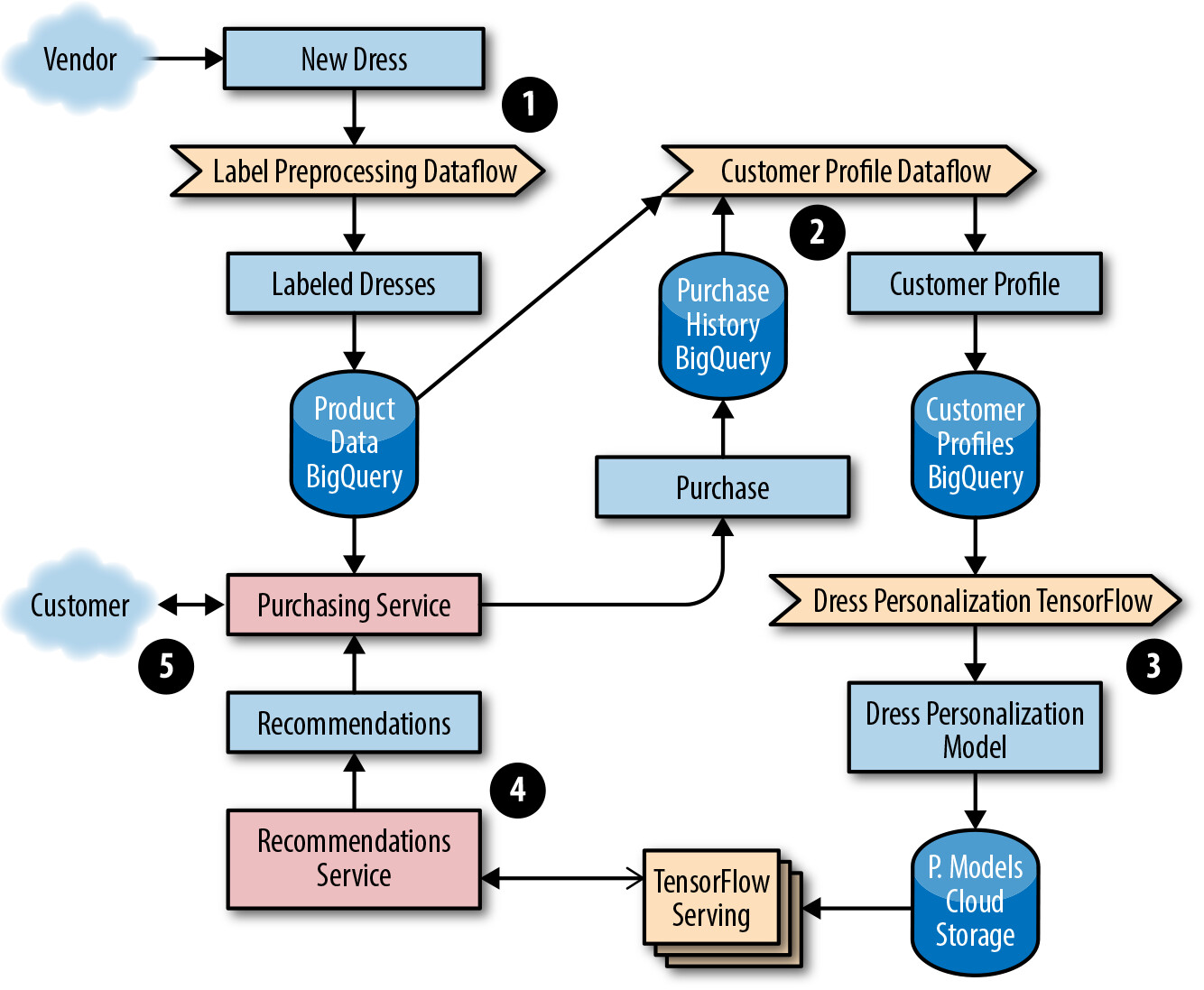
Figure 13.1: ML data processing pipeline
本章以虛構的線上洋裝公司 Dressy 為例,展示如何建構推薦系統管線。Dressy 選擇使用 clustering filter,透過 streaming Dataflow pipeline 前處理資料,再用 TensorFlow 訓練模型來提供個人化推薦。
當推薦結果不正確或過時時,應檢查:資料是否卡在管線中無法被前處理?ML 模型是否有軟體錯誤?生產環境是否在使用過時的模型版本?
管線最佳實踐#
定義與衡量 SLO#
自動偵測管線健康狀況並在超出 error budget 前收到通知,能最大限度減少對客戶的影響。
資料新鮮度(Data Freshness)SLO 格式:
- X% 的資料在 Y 秒/分/天內處理完成
- 最舊的資料不超過 Y 秒/分/天
- 管線作業在 Y 秒/分/天內成功完成
資料正確性(Data Correctness):
- 使用測試帳戶產生「golden data」,比較預期與實際輸出
- 設定例如每季度不超過 0.1% 的發票錯誤率
- 監控錯誤/差異並實施閾值告警
資料隔離/負載平衡(Data Isolation/Load Balancing):
- 高優先級資料應在資源受限時優先處理
- 可透過不同佇列、不同作業設定或不同資源配置的 worker 來實現
端到端衡量(End-to-End Measurement):
- 避免僅衡量每個階段的 SLO,因為客戶只關心所有階段總和的 SLO
- 僅衡量每階段的資料正確性可能會遺漏端到端的資料損壞錯誤
如果每個階段各自報告一切正常,但某階段引入了一個它期望下游處理的欄位,而下游卻丟棄了該資料,最終使用者就看不到資料。僅按階段監控無法捕捉這類問題。
規劃依賴故障#
- 確認是否過度依賴其他產品的 SLO/SLA
- 至少為其廣告的最大故障情境進行設計
- Google 透過 Disaster Recovery Testing (DiRT) 演練計畫性中斷,測試管線的自動故障轉移能力
建立與維護管線文件#
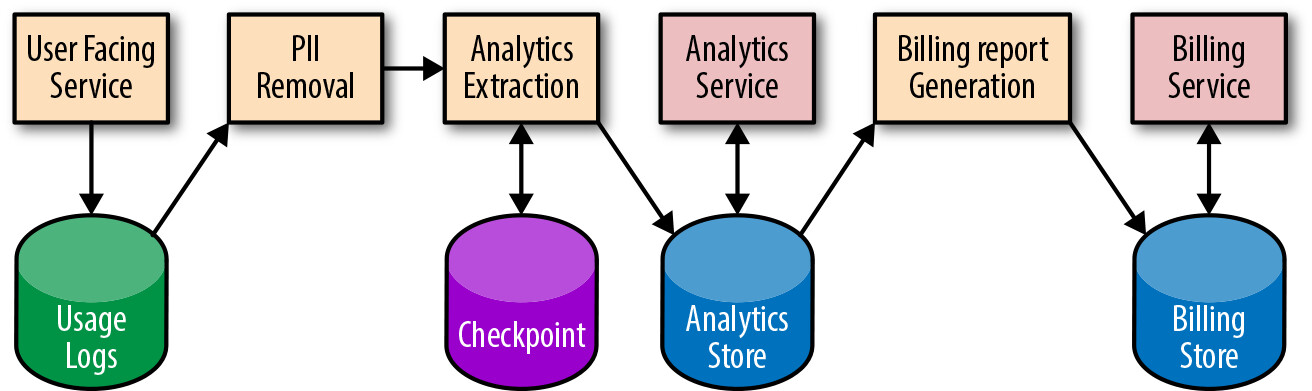
Figure 13.2: Pipeline system diagram (PII = personally identifiable information)
應維護三類文件:
- 系統圖(System Diagrams): 顯示每個元件(管線應用和資料儲存)及每步轉換,包含監控和除錯資訊的快速連結
- 流程文件(Process Documentation): 記錄常見任務(發布新版本、變更資料格式)和較少見的手動任務(初始服務啟動、區域關閉)
- Playbook 條目: 每個告警條件都應有對應的恢復步驟
對應開發生命週期#

Figure 13.3: Pipeline development lifecycle with release workflow
管線的開發生命週期包含以下階段:
- 原型開發(Prototyping): 驗證語義和業務邏輯表達能力,比較程式模型(如 Dataflow vs. MapReduce、batch vs. streaming)
- 1% Dry Run 測試: 使用生產資料在非生產環境中運行,逐步擴大規模並追蹤效能
- 預發布環境(Staging): 使用盡可能接近實際生產資料的環境,執行 A/B 比對
- 金絲雀部署(Canarying): 部分部署管線並監控結果,可使用 two-phase mutation 技術處理生產資料但跳過寫入生產儲存
- 部分部署(Partial Deployment): 對重大功能變更先在少量資料上測試(如 1%、10%、50%、100%)
- 部署到生產環境: 確認問題已排除後完全推廣,並確保能快速從已知良好狀態恢復
減少熱點(Hotspotting)#
熱點是資源因過度存取而超載導致操作失敗。常見範例包括:
- 多個 pipeline worker 同時存取單一 serving task 造成過載
- 單一機器上的資料因大量並行存取導致 CPU 耗盡
- 資料庫行級鎖競爭造成延遲
- 需要大量資源的大型工作單元
應對策略包括:重構資料或存取模式以均勻分散負載、降低負載、減少鎖粒度、建立緊急停止機制以隔離問題資料。
實施自動擴展與資源規劃#
- 使用自動擴展處理工作負載高峰,避免全時為峰值負載佈建資源
- 預測未來成長並分配容量,同時注意不僅是管線作業本身的成本,還包括跨區域資料複製和網路頻寬成本
- 雖然管線效能應以端到端 SLO 衡量,但資源使用應在每個階段個別衡量
遵循存取控制與安全策略#
- 避免在暫存儲存中存放 PII(個人識別資訊),若必要須加密
- 限制每個管線階段僅擁有讀取前一階段輸出所需的最小存取權限
- 對日誌和 PII 設定 TTL(Time to Live)限制
規劃升級路徑#
設計管線時應確保系統故障不會觸發 SLO 違規。當收到告警時,所有自動化措施應已用盡。擁有明確的 SLO、可靠的指標和告警偵測,能在客戶察覺前發出通知。
管線需求與設計#
推薦的管線功能特性#
管理資料處理管線時應最佳化的功能包括:
- 延遲(Latency): 支援串流、批次或兩者兼備的 API
- 資料正確性: Exactly-once 語義、two-phase mutations、windowing 函式
- 高可用性: 多區域部署(multihoming)、自動擴展
- MTTR(平均修復時間): 綁定程式碼變更到 release 以快速回滾、測試過的資料備份與還原程序
- MTTD(平均偵測時間): SLO 監控,基於症狀而非原因的告警
- 開發生命週期: 在金絲雀環境測試後再部署到生產
- 資源檢查與預測: 建立資源會計儀表板,建立成長關聯或預測指標
冪等與兩階段變更(Idempotent and Two-Phase Mutations)#
冪等變更(Idempotent Mutation): 可多次套用產生相同結果的變更類型,確保管線以相同輸入重新執行時總是產生相同結果。
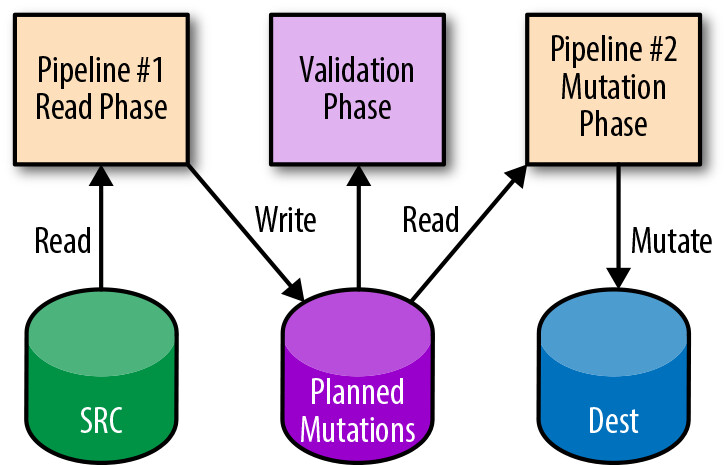
Figure 13.4: Two-phase mutation
兩階段變更(Two-Phase Mutation): 資料被讀取和轉換後,變更本身先儲存在暫存位置。一個獨立的驗證步驟針對這些潛在變更進行正確性驗證,通過後才套用到生產環境。這在金絲雀測試時特別有用。
檢查點(Checkpointing)#
管線是長時間運行的程序,若中途終止將失去狀態。檢查點技術讓管線能定期將部分狀態儲存,以便稍後恢復。這對建立 AI 模型的管線尤其重要,因為每次模型計算迭代都依賴先前的計算結果。
程式碼模式#
- 程式碼重用: 實作可重用的程式庫,讓監控指標能在一處新增並跨多個管線共享
- 微服務方式: 建立較小的管線而非單一巨型管線,使其可獨立發布和監控
管線成熟度矩陣(Pipeline Maturity Matrix)#
Google 使用管線成熟度矩陣作為管線技術選擇或設計的諮詢工具,衡量五個關鍵特性(每項從 1 到 5 分):
| 特性 | 1 - Chaotic | 3 - Functional | 5 - Continuous Improvement |
|---|---|---|---|
| 故障容忍 | 無故障轉移支援 | 支援 work unit 重試 | 多區域自動故障轉移、自動重試與隔離 |
| 可擴展性 | 無自動擴展,手動介入 | 使用額外工具自動擴展 | 內建自動擴展、動態重新分片、負載卸除 |
| 監控與除錯 | 無日誌,無法追蹤失敗 | 可識別失敗單元並擷取日誌 | 自動隔離與重播失敗單元、完整執行地圖視覺化 |
| 易用性與透明度 | 無可發現性,設定成本高 | 部分可重用元件 | 全域資料註冊服務、最小程式碼配置、完整文件 |
| 單元與整合測試 | 無測試框架 | 需長時間、資源密集 | 支援 sanitizer、程式碼覆蓋率、內建測試資料生成 |
管線故障:預防與回應#
常見故障模式#
延遲資料(Delayed Data):
- 管線輸入或輸出延遲時,下游作業可能在沒有必要資料的情況下開始運行
- 過時的資料幾乎總是比不正確的資料好
- 建立被所有階段遵守的資料依賴關係至關重要
損壞資料(Corrupt Data):
- 未偵測到的損壞資料可能導致使用者可見的問題
- 修復兩個主要步驟:防止更多損壞資料進入系統、從先前已知良好版本還原或重新處理
- 考慮選擇性重新處理,僅處理受影響的使用者或帳戶
潛在原因#
- 管線依賴: 儲存、網路系統或其他服務可能在限流或拒絕新資料
- 管線應用或設定: 瓶頸、程式錯誤、設定錯誤(如 CPU 密集處理、效能退化、記憶體不足)
- 意外的資源成長: 突然且非預期的系統負載跳升
- 區域級中斷: 單區域管線特別脆弱,多區域管線需注意資料可能被擱置或延遲
案例研究:Spotify 事件交付系統#
Spotify 每天從其應用程式中擷取並發布數千億個事件(使用者聽歌、點擊廣告、追蹤播放清單等),用途包括 A/B 測試分析、顯示播放次數、驅動個人化探索播放清單,以及向藝術家支付版稅。
事件交付#
所有已交付的事件按類型和發布時間分區。在任何給定小時內發布的事件被分組儲存在一個稱為 delivered hourly bucket 的指定目錄中,再按事件類型分組。
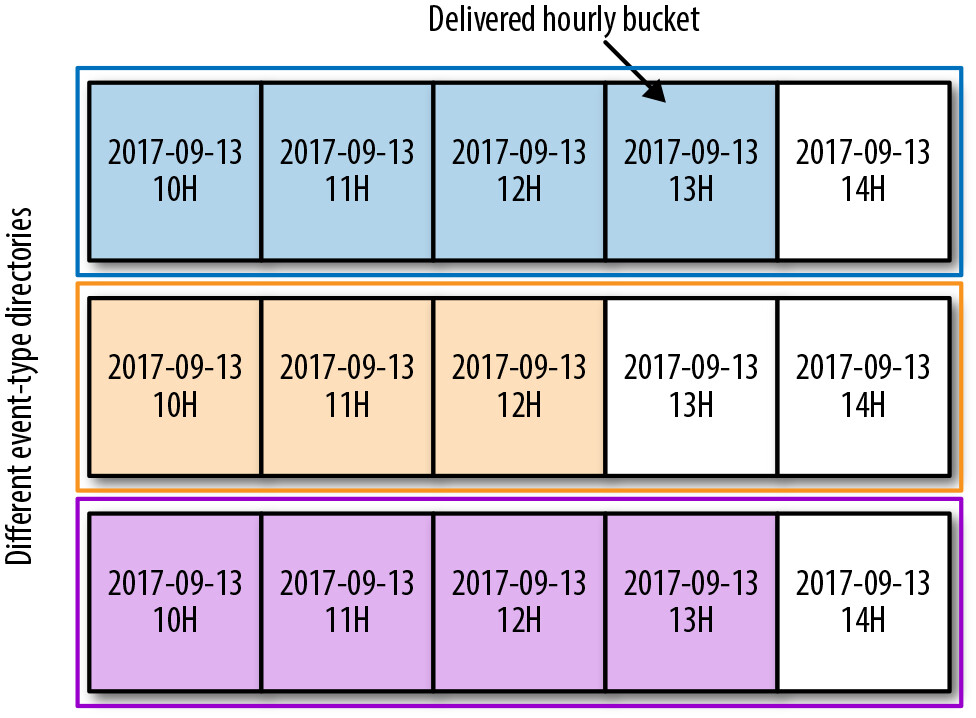
Figure 13.5: Delivered hourly buckets
事件交付系統架構#
系統設計的關鍵決策是將資料收集與資料交付解耦。使用 Google Cloud Pub/Sub 作為中間層,使兩者成為獨立的故障域,限制生產問題的影響範圍。
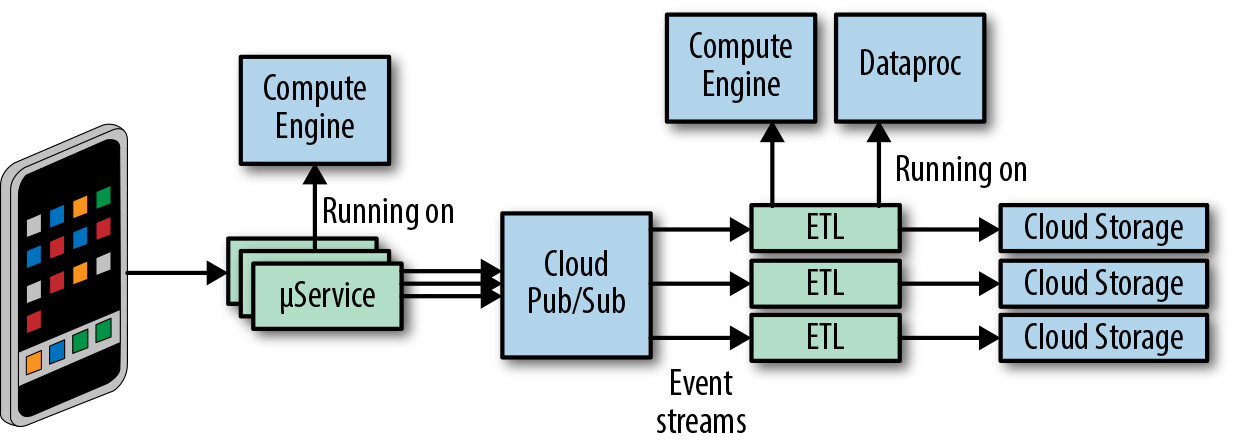
Figure 13.6: Event delivery system architecture
資料收集:
- 事件按事件類型分組,每種事件類型有完全的隔離
- 各事件類型發布到 Google Cloud Pub/Sub 中的專屬 topic
- 發布由運行在 Spotify 資料中心和 Google Compute Engine 上的微服務執行
ETL 流程:
- 專用微服務從事件串流中消費事件
- 另一個微服務將事件分配到其小時分區
- 運行在 Dataproc 上的批次作業對事件去重複並持久化到 GCS 上的最終位置
資料交付:
- 客戶(Spotify 內部工程團隊)透過簡單設定動態啟用或停用事件類型交付
- 使用 GCE Autoscaler 達成最佳資源利用
SLO 定義#
Spotify 為事件交付系統提供三種 SLO:
即時性(Timeliness):
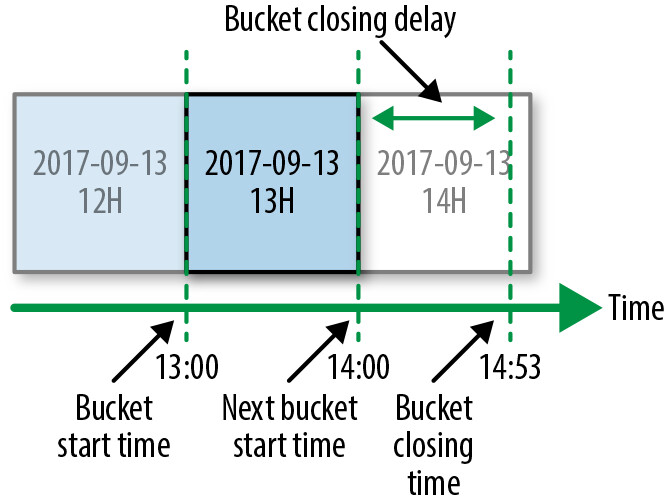
Figure 13.7: Event time partitioning
- 定義為交付一個小時資料桶的最大延遲
- 使用內部工具 Datamon 衡量和視覺化
Figure 13.8: Datamon for Spotify's data monitoring system
- SLO 分為三個優先級層:高、正常、低
- 下游資料作業在依賴的小時桶交付前無法開始處理
偏斜度(Skewness):
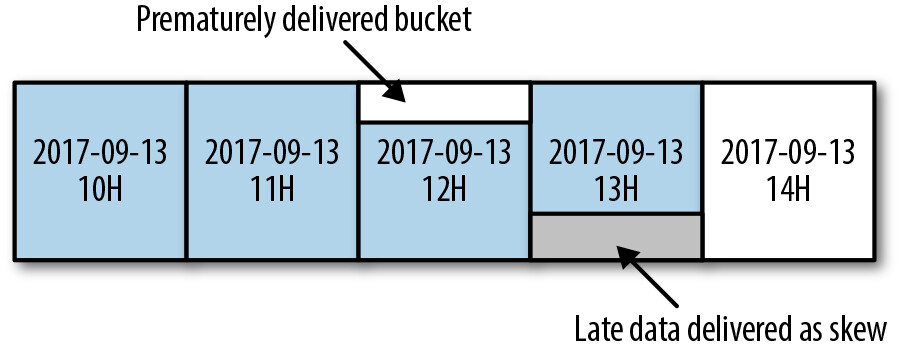
Figure 13.9: Delivery of skewed data
- 定義為每日可被錯置的最大資料百分比
- 由於系統使用啟發式方法判斷何時交付小時桶,已交付桶中未交付的事件可能被錯誤地交付到未來的小時桶
- 偏斜會導致某些時段先低報再高報數值
完整性(Completeness):
- 定義為事件成功發布到系統後被交付的百分比
- 每日報告偏斜度和完整性,使用內部審計系統比較所有已發布和已交付事件的計數
Spotify 使用伺服器端收到事件的時間戳而非客戶端產生的時間戳,因為使用者可能在離線模式下緩衝事件長達 30 天,且使用者可修改裝置系統時間。
客戶整合與支援#
- 完全託管服務: 隱藏系統複雜性,讓客戶專注於自身問題
- 有限功能: 僅支援特定的內部格式發布事件,僅交付到小時桶且使用單一序列化格式
- 顯式啟用: 客戶啟用事件交付時需定義是否為財務相關事件、即時性要求和事件擁有權
- 文件即產品: 所有支援請求被視為文件問題或產品問題
系統監控#
- SLO 監控提供系統整體健康的高階洞察,但 SLO 違規告警意味著客戶已受影響
- 需要足夠的操作監控以在 SLO 被破壞前解決或減輕問題
- 補充應用日誌,但注意避免過度記錄——對高流量元件記錄每個請求並無價值
容量規劃#
- 大多數元件基於 CPU 使用率進行容量規劃,佈建為尖峰時段 50% CPU 使用率
- 使用 GCE Autoscaler 改善資源利用
- Autoscaler 的陷阱:若 CPU 使用率與實際工作量失去關聯,Autoscaler 會無限擴展直到耗盡所有資源
- 防護措施:限制 Autoscaler 最大實例數、嚴格限制 daemon 的 CPU 使用、偵測到無用工作時積極節流
開發流程#
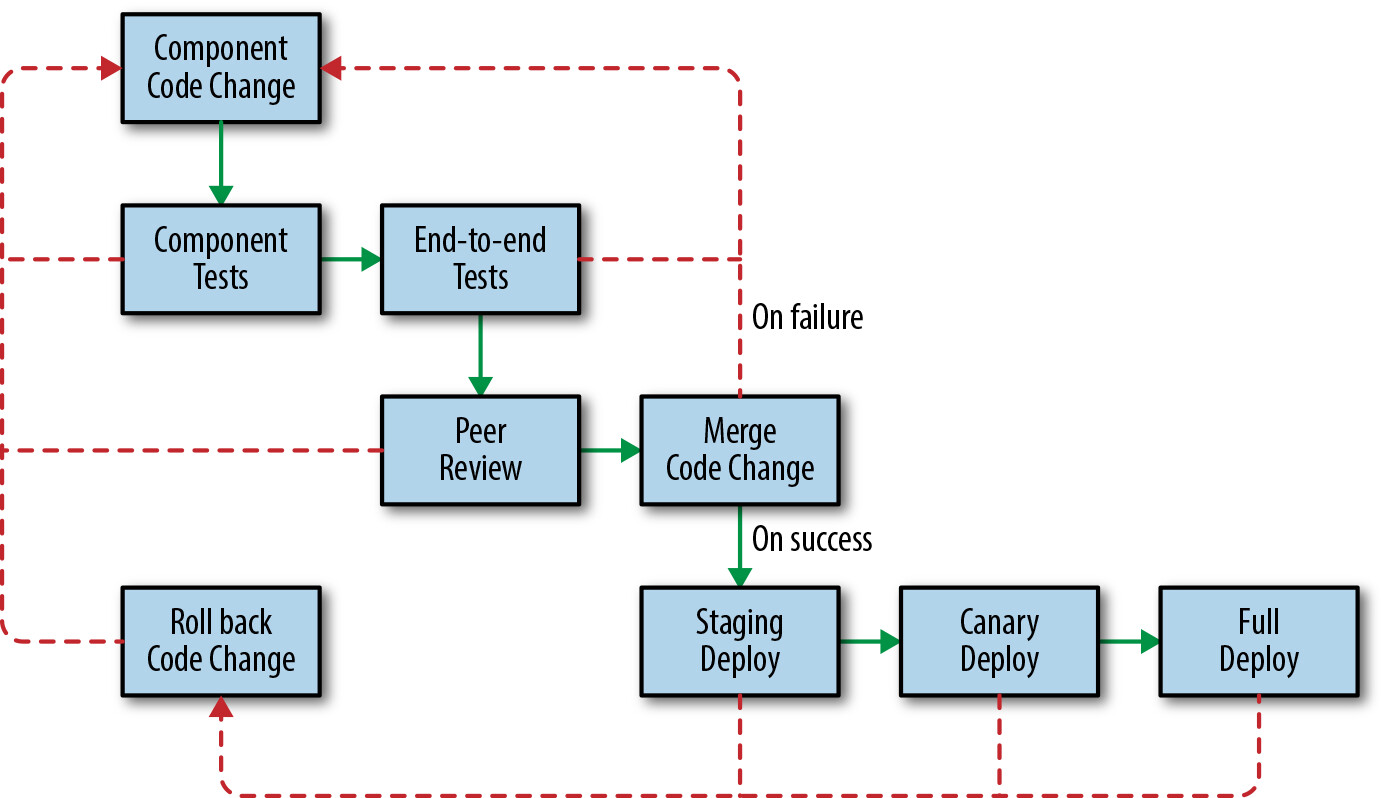
Figure 13.10: Development process
Spotify 採用 CI/CD 流程:
- 遵循「測試金字塔」哲學:大量單元測試、較少整合測試、系統級端到端測試
- 每次變更都經過同儕審查,所有測試在共用 CI/CD 伺服器上執行
- 部署採分階段策略,需手動審批才能進入下一階段:
- 部署到預發布環境(映射生產流量的代表性片段)
- 部署到少量生產實例(金絲雀)
- 完整生產部署
事件處理#
- 首要目標是減輕損害並恢復到穩定的先前狀態
- 事件期間避免部署重大變更,除非事件由近期部署的新程式碼引起
- 最常見的操作故障來源:系統故障(軟體錯誤或效能退化)和外部服務故障
- 若 資料新鮮度 SLO 被破壞:客戶只需等待資料到達
- 若 偏斜度或完整性 SLO 被違反:可能需要通知客戶,因為資料品質受損,需重新交付或重新整理事件
Spotify 的事件交付系統經過多年演進。先前版本遠不如現在可靠,工程師每幾個晚上就被叫醒。設計現行版本時,他們專注於建構模組化系統,做好一件核心事:交付事件。
結論#
將 SRE 最佳實踐應用於管線,有助於做出明智的設計選擇並開發自動化工具,使管線更易操作、更有效擴展且更可靠。關鍵要點包括:
- 了解需求並選擇 SLO,以此驅動設計決策
- 評估可用技術,根據管線成熟度矩陣衡量關鍵特性
- 建立完整的開發生命週期,從原型到金絲雀再到生產部署
- 為故障做好準備,包括資料延遲、資料損壞和區域級中斷
- 記錄設計並建立執行常見任務的文件,減少中斷時間
無論是直接擁有管線,還是擁有依賴管線產出資料的服務,都應確保 SRE 從早期階段就參與管線設計工作,以確保管線可以輕鬆發布、修改和運行而不會造成客戶問題。