本章介紹 Google 的 Non-Abstract Large System Design (NALSD) 方法論——一種迭代式系統設計方法,從問題陳述出發,逐步推演出具備高可用性與可擴展性的生產系統設計。NALSD 是 SRE 的核心技能之一,結合了容量規劃(capacity planning)、元件隔離(component isolation)和優雅降級(graceful degradation)等關鍵概念。
什麼是 NALSD?#
NALSD 描述了 SRE 評估、設計和評估大型系統的能力。實務上,NALSD 讓工程師能夠:
- 從白板上的基本系統圖開始
- 思考各種擴展和故障域(scaling and failure domains)
- 將設計具體化為資源提案
為何強調「非抽象」?#
所有系統最終都必須在真實的電腦、真實的資料中心和真實的網路上運行。Google 從慘痛經驗中學到,設計分散式系統的人需要不斷練習將白板設計轉換為具體資源估算的能力。前期多做一點工作,通常能減少因未預見的物理限制而導致的最後一刻設計變更。
NALSD 練習的價值在於結合多個不完美但合理的結果,以更好地理解設計。早期的假設會大幅影響計算結果,但完美的假設並非 NALSD 的要求。
AdWords 範例:設計流程#
本章以 Google AdWords 的 CTR(Click-Through Rate,點擊率) 報告系統為範例,展示 NALSD 的迭代設計過程。CTR 是廣告被點擊次數與被展示次數的比率,資料來源為搜尋日誌(query log)和點擊日誌(click log)。
設計流程的兩個階段#
NALSD 流程分為兩個階段,每個階段包含兩到三個關鍵問題:
基本設計階段:
- Is it possible? — 不考慮資源限制,設計能否滿足需求?
- Can we do better? — 能否讓系統更快、更小、更高效?
擴展階段:
- Is it feasible? — 在預算、硬體等限制下,設計是否可行?
- Is it resilient? — 設計能否優雅地處理故障?當元件失敗或整個資料中心故障時會發生什麼?
- Can we do better? — 是否還有改進空間?
初始需求#
- 每位廣告主可能有多個廣告,每個廣告以
ad_id為鍵 - 需要知道每個廣告和搜尋詞的展示次數與點擊次數
- SLO 目標:
- 99.9% 的儀表板查詢在 1 秒內完成
- 99.9% 的時間,CTR 資料延遲不超過 5 分鐘
- 支援數百萬廣告主,交易量假設為每秒 500,000 次搜尋查詢和每秒 10,000 次廣告點擊
迭代一:單機設計#
最簡單的起點是考慮在單台電腦上運行整個應用。
資源計算#
- 每筆 query log 約 2 KB(含 time、query_id、ad_id、search_term 等欄位)
- 每日 query log 量:
(5 x 10^5 queries/sec) x (8.64 x 10^4 sec/day) x (2 x 10^3 bytes) = 86.4 TB/day - click log 量僅為 query log 的 2%(平均 CTR 為 2%)
- 總計約需 100 TB 儲存空間
評估#
- IOPS 瓶頸: 以每個 HDD 200 IOPS 計算,需要約 2,500 個磁碟
- RAM 限制: 以每台機器 64 GB RAM 計算,需要約 1,563 台機器
- 單點故障(SPOF): CPU、記憶體、儲存、電源、網路、散熱都是單點故障,無法合理支撐 SLO
即使能將設計塞進單台機器,也不應該這樣做。簡單的電源重啟就會嚴重影響使用者。這個步驟雖不可行,卻提供了推理系統約束的寶貴資訊。
迭代二:分散式系統 — MapReduce#
方案#
使用 MapReduce 批次處理 query log 和 click log,產出按 ad_id 組織的 CTR 資料。
評估#
- MapReduce 能水平擴展,無論輸入多大,都可以透過增加機器完成
- 問題: 無法滿足 5 分鐘內資料可用的 SLO。小批次處理會導致跨批次的 query 和 click 無法關聯
迭代三:LogJoiner 設計#
核心概念#
由於點擊量遠小於查詢量,設計重點放在擴展較大的一方。引入以下元件:
- QueryStore: 儲存完整 query log,以
query_id為鍵(約 100 TB/天) - LogJoiner: 持續從 click log 串流中取得資料,與 QueryStore 中的 query 關聯
- ClickMap: 儲存關聯後的點擊資料,以
ad_id為鍵 - QueryMap: 直接從 query log 接收資料,以
ad_id為索引
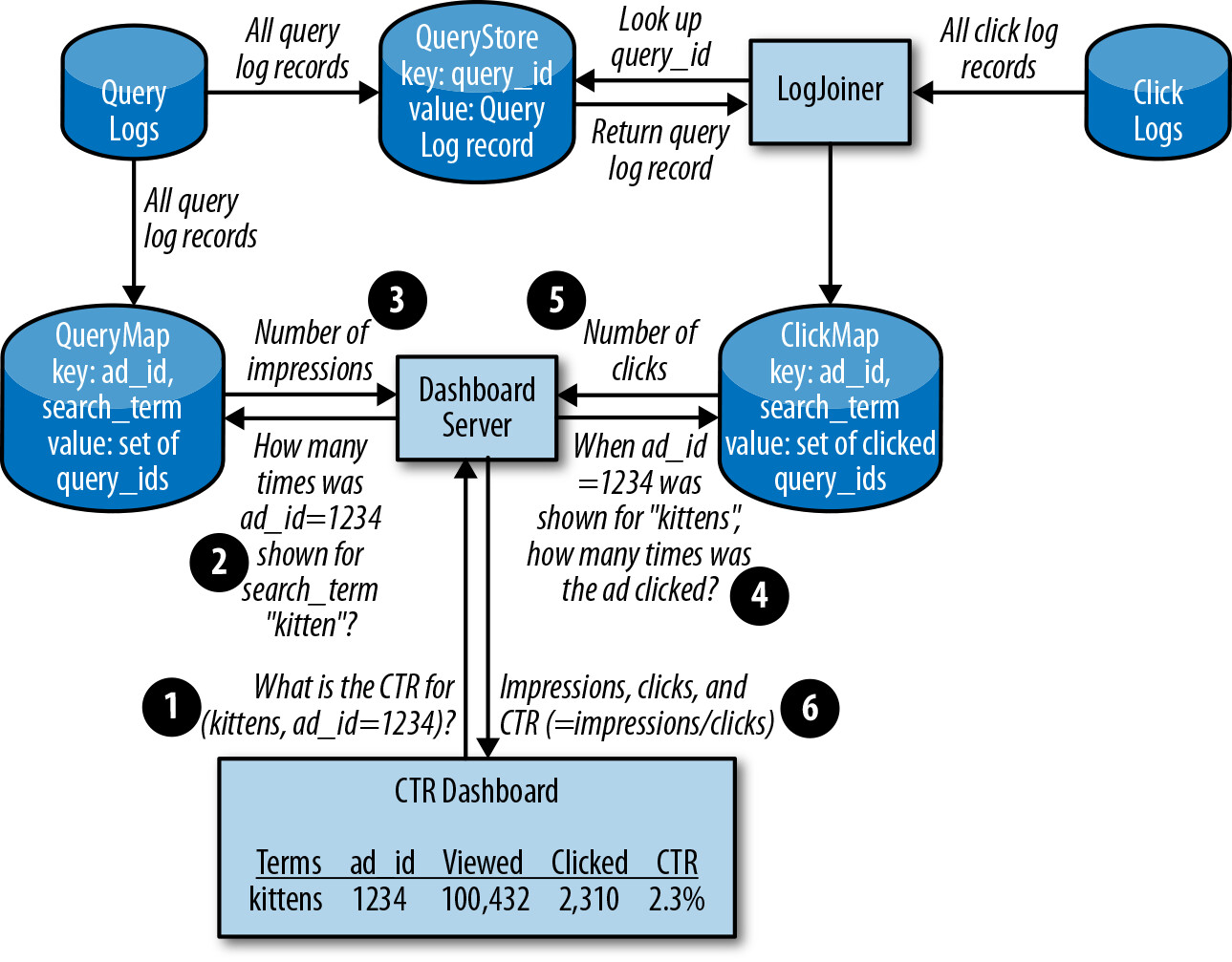
Figure 12.1: Basic LogJoiner design
資源計算#
- LogJoiner 網路吞吐量:click log 處理約 160 Mbps + QueryStore 查詢約 160 Mbps + 寫入 ClickMap 約 80 Mbps,合計約 400 Mbps,可管理
- ClickMap 每日約 20 GB
- QueryMap 每日約 2 TB(每筆 query 最多 3 個 ad_id)
當找不到某個 click 對應的 query 時,系統會暫時擱置並重試。超過時間限制後才丟棄該 click,這是一種務實的容錯策略。
迭代四:分片(Sharded)LogJoiner#
設計考量#
QueryMap 的 2 TB 對單機來說太大(超過 64 GB RAM),且 IOPS 需求過高。需要透過分片解決:
- 資料管理: 以
query_id為基礎進行分片,讓多個 LogJoiner 並行處理 - 可靠性: 機器隨時可能故障,需確保不遺失進行中的工作
- 效率: 以最小資源滿足需求
分片機制#
引入 log sharder 元件:
- 對每筆記錄的
query_id進行雜湊(hash) - 對結果取模 N(分片數量)加 1
- 將記錄發送到對應的分片
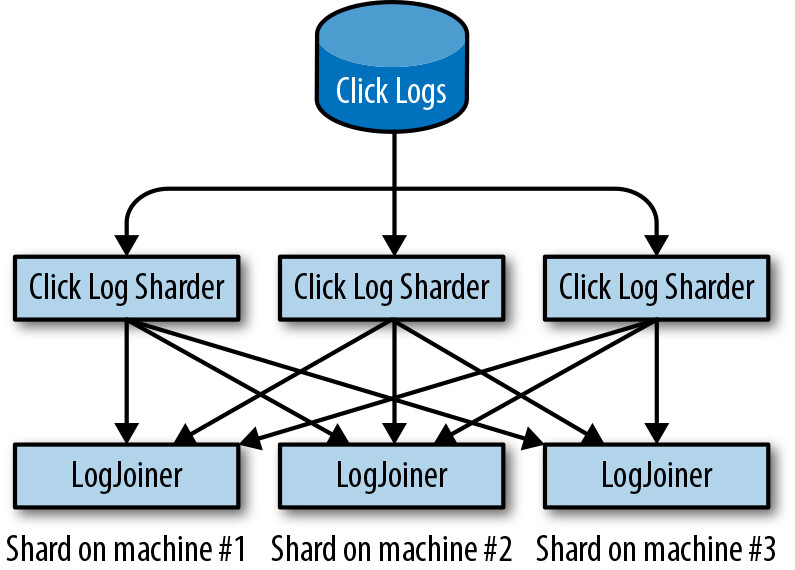
Figure 12.2: How should sharding work?
容錯設計#
- Log sharder 將重複的 log 發送到兩個分片(duplicate shards),減少故障時遺失已關聯日誌的風險
- 分散工作負載以確保沒有重複分片落在同一台機器上
- 若兩台機器同時故障且遺失兩份拷貝,可透過 error budget 覆蓋此風險,並透過重新處理日誌來恢復
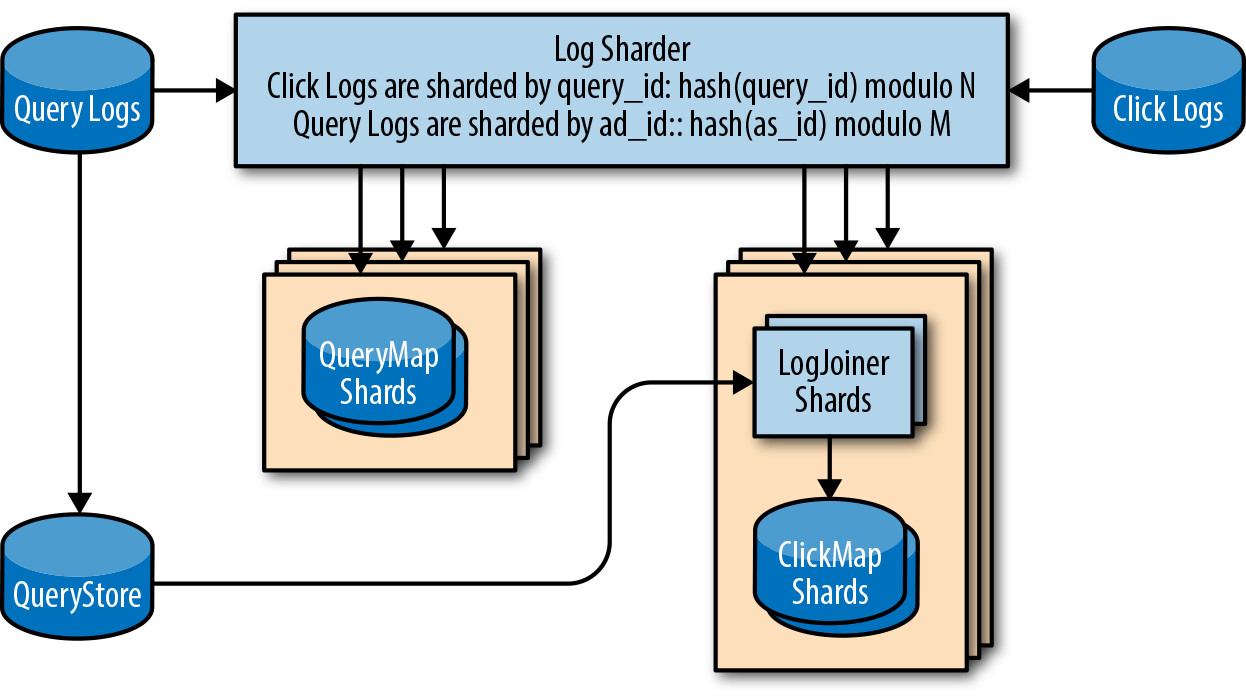
Figure 12.3: Sharding of logs with same query_id to duplicate shards
評估#
將所有分片元件託管在單一資料中心仍然是單點故障——若資料中心斷線,所有 ClickMap 工作遺失,使用者儀表板完全停止運作。
迭代五:多資料中心設計#
分散式共識#
跨地理位置的資料中心複製資料,可以抵禦災難性故障。解決方案使用 Paxos 共識演算法:
- 建立 3 或 5 個服務副本(如 ClickMap)
- 副本間使用共識演算法確保在資料中心級故障時仍能可靠儲存狀態
- 每次寫入操作至少需要一次跨節點的網路往返
資源計算#
- Paxos 延遲約 25 毫秒(資料中心相距數百公里),即每秒 40 次循序操作
- 最小任務數:
(1.02 x 10^6 queries/sec) / (40 ops/sec) = 25,500 tasks - 每個 task 記憶體:
(4 x 10^12 bytes) / (25,500 tasks) = 157 MB/task - 每台機器可容納:
(64 GB) / (157 MB) = 408 tasks/machine - 每個資料中心約需 64 台機器,使用約 4 TB RAM,僅佔用每台機器 25% 的網路頻寬
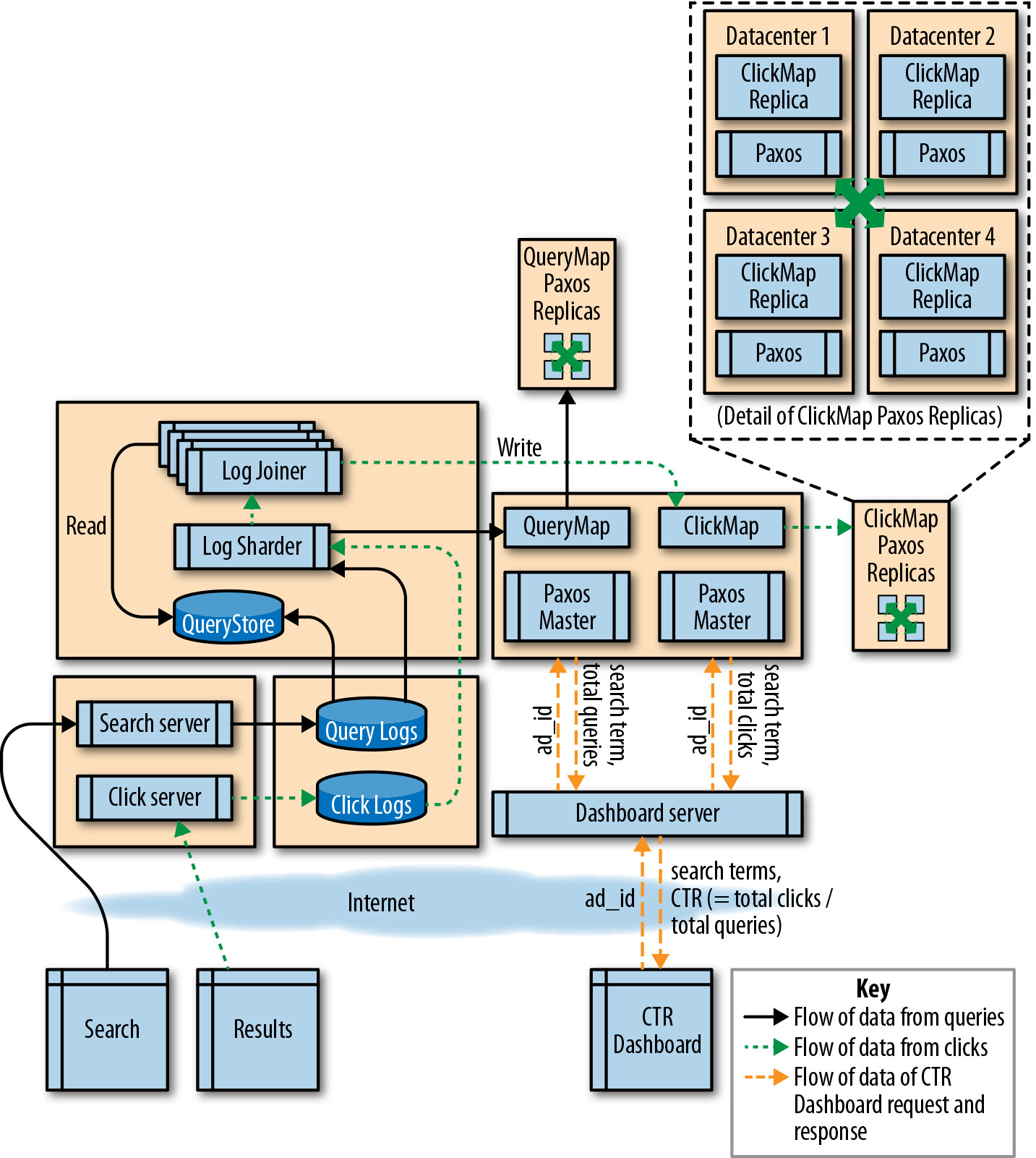
Figure 12.4: Multidatacenter design
最終驗證#
系統設計滿足所有需求:
- 10,000 ad clicks/sec — LogJoiner 可水平擴展處理所有點擊日誌
- 500,000 search queries/sec — QueryStore 和 QueryMap 設計可處理完整一天的資料
- 99.9% 儀表板查詢 < 1 秒 — CTR 儀表板從以
ad_id為鍵的 QueryMap 和 ClickMap 取得資料,交易快速且簡單 - 99.9% CTR 資料延遲 < 5 分鐘 — 每個元件都設計為可水平擴展,管線太慢時增加機器即可降低端到端延遲
結論#
NALSD 是 Google 用於生產系統的迭代式設計流程。透過將軟體拆解為邏輯元件並置入可靠的生產基礎設施中,可以達成合理的資料一致性、系統可用性和資源效率目標。
整個設計過程持續運用四個關鍵 NALSD 問題:
- Is it possible? — 能否不依賴「魔法」來建構?
- Can we do better? — 是否已盡可能簡化?
- Is it feasible? — 是否符合實際限制(預算、時間等)?
- Is it resilient? — 能否承受偶發但不可避免的中斷?
NALSD 是一項需要學習的技能。如同任何技能,需要定期練習以維持熟練度。Google 的經驗顯示,從抽象需求推理到具體資源估算的能力,對於建構健康且長壽的系統至關重要。